
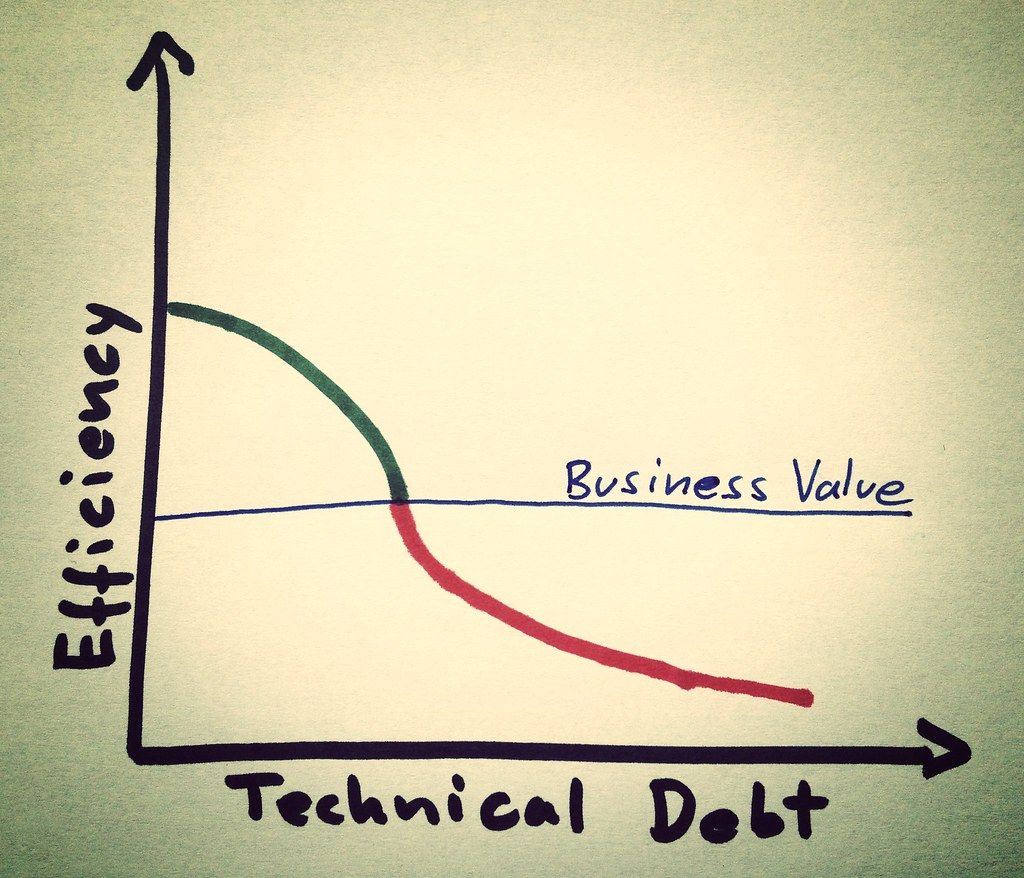
Last updated: November 3, 2022.
Okay, lets make it clear at the start: This post is NOT intended for people who are doing one-off, silo-ed projects like participating in Kaggle competitions, or doing hobby projects on jupyter notebooks to learn the trade. The value of throw-away, quick, diry script code is obvious there - and has its place. Rather, it is intended for ML practitioners working in a production setting. So if you’re working in a ML team that is struggling to manage technical debt while pumping out ML models, this one’s for you.
A typical workflow
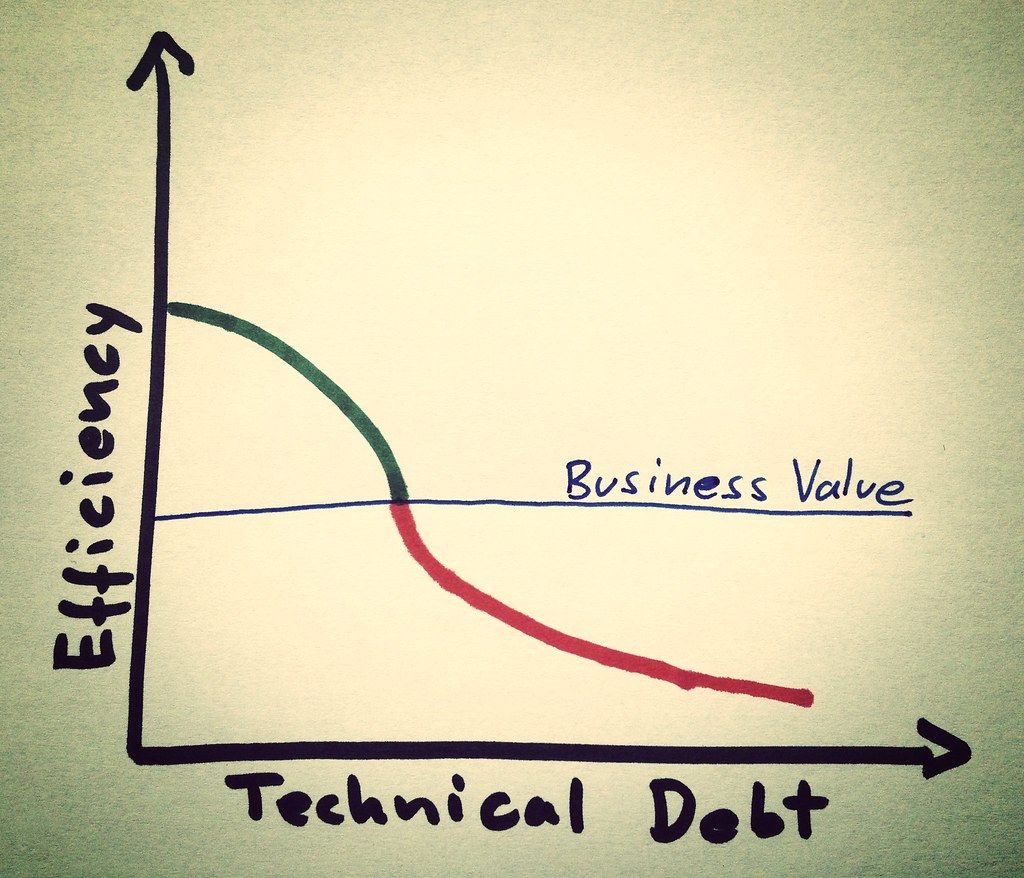
*Image Source: Michael Mayer on Flickr | Attribution License found *here
Here is the premise: You’re a ML/DL/AI engineer/analyst/scientist working in a startup/SME/enterprise. Its your job to take a bunch of random data from all over the place, and produce value. What do you do? You sit down, somehow get the data on to your local machine, and inevitably do something along the lines of:
jupyter notebookOr you go to a colab if you’re fancy and your teams privacy rules allow it.
Following is a story ive seen so many times before - pseudo-code of course.
import pandas as pd
import xyzlibraryforml
# CELL 1: Read
df = pd.read_*("/path/to/file.*")
df.describe()
# INSERT HERE: a 100 more cells deleted and updated to explore data.
# CELL 2: Split
train, eval = split_the_data() # basic
# INSERT HERE: trying to figure out if the split worked
# CELL 3: Preprocess
# nice, oh lets normalize
preprocess(train)
preprocess(eval)
# exploring preprocessed data, same drill as before
# CELL 4: Train
model = some_obfuscated_library.fit(train, eval) # not being petty at all
# if you're lucky here, just look at some normal metrics like accuracy. otherwise:
# CELL 5: Evaluate
complicated_evaluation_methods(model)
# INSERT HERE: do this a 1000 times
# CELL 6: Export (i.e. pickle it)
export_model()So you’re done right? That’s it - boom. Test set results are great. Lets give it to the ops guy to deploy in production. Lunch break and reddit for the rest of the day!
Okay, am I grossly exaggerating? Yes. Is this scarily close to the truth for some businesses? Also yes.
So, what’s the problem?
The problem is that this notebook above is a ball of technical debt that will keep growing, if not culled early enough. Lets break down what was wrong with it:
Not moving towards a bigger picture
When you put generalizable logic into non-versioned, throw-away notebook blocks, it is taking away the ability for your team to take advantage of it. For example, the logic of loading/extracting your data from your static datasource. Sure a pd.read_json is easy right now, but what happens if the format changes? Worse, what happens if the data grows and is split into multiple files? Even worse, what happens if it won’t fit into memory any more? What happens if your colleague runs into the same problem - she’ll probably go through the same loops as you did not even knowing its an already solved problem. Sure, there are solutions to all these problems but are you going to keep solving them in your local notebook?
The answer is probably no (unless you’re netflix or something). Usually, the logical thing to do is to extract the loading into a logically separate service. This way, you can abstract the actual extraction of data away from yourself and into a maintainable layer transparent to everyone. For example, this could be some form of feature store that collects all the various data streams in your organizations into one point, which can then be consumed in defined APIs by everyone in your team.
The same applies to the pre-processing, training and evaluation part of the script above.
Building logic locally (and therefore again and again)
As in the above example, when you write code to explore data, you generate tons of great stuff - visualizations, statistical dataframes, cleaned and preprocessed data, etc. The random, arbitrary order of execution of jupyter notebooks ensures that the path taken to realize these artifacts is forever lost in overridden local variables and spontaneous kernel restarts. Even worse, the logic has complex, easily overridden configurations embedded deep inside the code itself - making it much harder to recreate artifacts.
Look, I understand - I do it all the time. Data wrangling is a random, grinding process, and its gonna be messy. But setting up some framework to keep a track of your data exploration pipelines is going to pay off big time. Similar to commenting your code, the biggest beneficiary of keeping track is going to be yourself. Also, your team will be faster and avoid redundant work if these artifacts and mini-answers to questions were made transparent and clear to everyone automatically.
Not owning the deployment
The last part of this notebook is probably the most frustrating. I really do not believe that the job of the person writing that notebook ends with exporting the model for ops. It does not make any sense.
First of all, that preprocessing() function has to go with it, otherwise training-serve skew is going to crash your model from the get-go. Secondly, how on earth is the ops person supposed to know what assumptions you took while building the model? Are you going to write extensive documentation of what data goes in, how it should be preprocessed, and which shape it should be in when deploying to an endpoint? I mean there are now automated ways of doing this - so own the deployment!
One aspect lacking in the above script is a disregard for measuring the performance of a model. Most data scientists I know do not care how big the model is, how much memory it consumes for predictions, and how fast/efficient it is in deployment. The model does not produce value if it does not fulfill the performance criteria of the end application. Again, the person developing the models should have ownership of its end deployment.
Suggestions
The easiest way to fix the above is to develop a framework where a ML team can balance throw-away exploratory code development with maintainable, easy-to-share code. If you are to do this, you might want to keep the following in mind:
Create well-defined interfaces (i.e decompose into pipelines)
The split, transform, train, evaluate, deploy components of your workflow are logically independent entities/services. Architect a setup where individual components of your ML workflow are abstracted away from concrete implementations. This could be by defining actual interfaces object-oriented style, or simple ensuring that your repo has some form of structure that is easy for everyone to contribute to and extend. This does not have to be rocket-science at the start, but it will help enormously.
This is where the notion of ML pipelines come into play: Pipelines are abstract representations that define a series of data processing tasks. Thinking in pipelines would help your team separate out logical entities in their workflow, and have data flow through it independently. This would inevitably yield a more robust, maintainable codebase. Also, defining ML pipelines like this ensures you can automate continuous training of your stale models on new data as it comes in. However, you need to also track your data metadata for that (See below).
Make a plan for your ML Metadata
Every experiment you run yields ML metadata: who ran it, when was it run, what data went in, where are the results stored etc. Make sure you map these out and provide a convenient way to add to this store. Important to note: I am not just talking about experiment tracking either. There are many wonderful libraries out there that will help in tracking the model-centric metadata, i.e., metrics etc. However, what is often neglected is the data-centric metadata - especially if the data keeps changing. Stuff like data versioning, statistics, visualizations, what seed was used when random splitting - stuff like that. There should be an easy way to trace the various routes your data takes in your development.
Ensure that your workloads can run in any environment
Running a workload on a single machine is always going to be easier than making the same code run on any arbitrary environment. I know Docker is inapproachable and hard for many ML people, but at least make a requirements.txt and add a init.py! Ideally, containerize your code and run experiments on some form of orchestration framework. Doing this one step now will save a lot of pain when you scale and automate this whole thing to work on bigger data.
Do not separate deployment from training
This is perhaps the most no-brainiest of all no-brainer suggestions so far. End to end ownership lead to the whole DevOps revolutions 20 years ago, and that has not gone away in ML development either. Provide a smooth mechanism to transfer a trained model to an endpoint, and make sure the Ops people are sitting in the same room (not always literally) as your ML developers. Put in place processes where everyone understands the end goal in production. Automate things when possible.
Do not compromise on repeatability and traceability
You know when people start coding in Python and then move to C++ or Java and they do not understand concepts like pointers and static typing? They think: “What is the use of giving a variable a type, I know what it is so why am I forced to do this?”. Well, sorry to break it to you, but pointers and static typing have a purpose - knowing them protects your code from your own failings and ensures high quality robust output. Ultimate flexibility can be a bad thing, especially with developers who tend to err towards laziness (like me).
Something very similar happens in Jupyter notebooks - the freedom of running any arbitrary code in any order gives freedom but makes you lose the very important notion of repeatability and traceability, two corner-stones of any robust, production ready engineering discipline. Please, at least ensure that your notebooks are executable top-down and in a repeatable manner. Cluttered and randomly ordered jupyter notebooks should be punished with long rants like this one on Code Review meetings.
One way of ensuring both traits is to extract ‘settings’ of your code from the implementation. Which brings me to my next point…
Separate configuration from implementation
Separating configuration from actual code implementation is definitely a pain. Yet, this is another one of those ‘pays off in the long run’ sort of things. We’ve written about it before but to summarize: Separating your configuration allows you to automate repetitive tasks, increases predictability of results, and ensures reproducibility. Ideally, configuration should be treated as code, versioned, and maintained.
Conclusion
ML practitioners in many organizations are heavily incentivized to make quick-wins to product early results. However, this leads to accumulated technical debt which eventually slows down the team over time. The solution is to follow proper software engineering principles from the get-go, and lean on guidelines to strike a balance between rapid results and high quality software development.
The thoughts above are very personal lessons I have learnt over the last 3 years deploying models in production. As a result at zenml, we have created ZenML to provide a framework for ML developers to solve some, if not all, of the problems noted above. Reach out to me at [email protected] if you are interested in giving the platform a go. Head over to our docs to understand more how it works in more detail.


