On this page
Last updated: November 3, 2022.
Today, ZenML is announcing its first external investment round and it’s a special day for us. We are now backed by the most exciting investors in open-source and MLOps. Crane Venture Partners from London is leading our 2.7m USD round followed by AIX Ventures, a new AI fund from Palo Alto. We’re really looking forward to joining forces and their portfolios alongside H2O.ai, HuggingFace, or Weights & Biases.
In the following, we’d like to take you on our journey and why we are so excited for the future.
How it developed
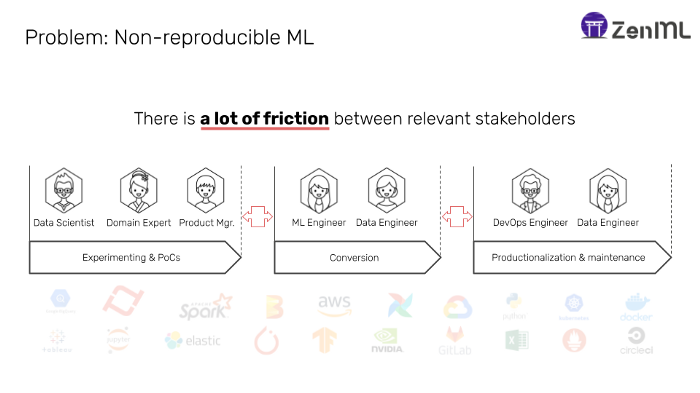
We didn’t wake up one day and get an epiphany: “Hey, let’s build an MLOps tool!”. In our first startup, we brought Machine Learning into production by hand for special use-cases, namely predictive maintenance for the commercial vehicle industry The projects looked very similar on the surface but we had to adapt quickly for every project. Different legacy tools, IT development processes and modalities required us to stay fully flexible. At the start, every pipeline we created was for one specific use case - this wasn’t scalable or reproducible. The handover points of data science teams, ML and DevOps engineers created a lot of friction during all processes - from experimentation to production. This lack of standardization caused us to consistently confront the ownership dilemma in MLOps.
There are an increasing number of tools for all personas across the ML pipeline. However, we noticed that most tools separate workflows into islands that mainly concentrate on the early development phase for data scientists, or the later deployment phase which is largely owned by engineering. This causes systemic failures in the entire system like a lack of reproducibility or provenance across the pipeline.
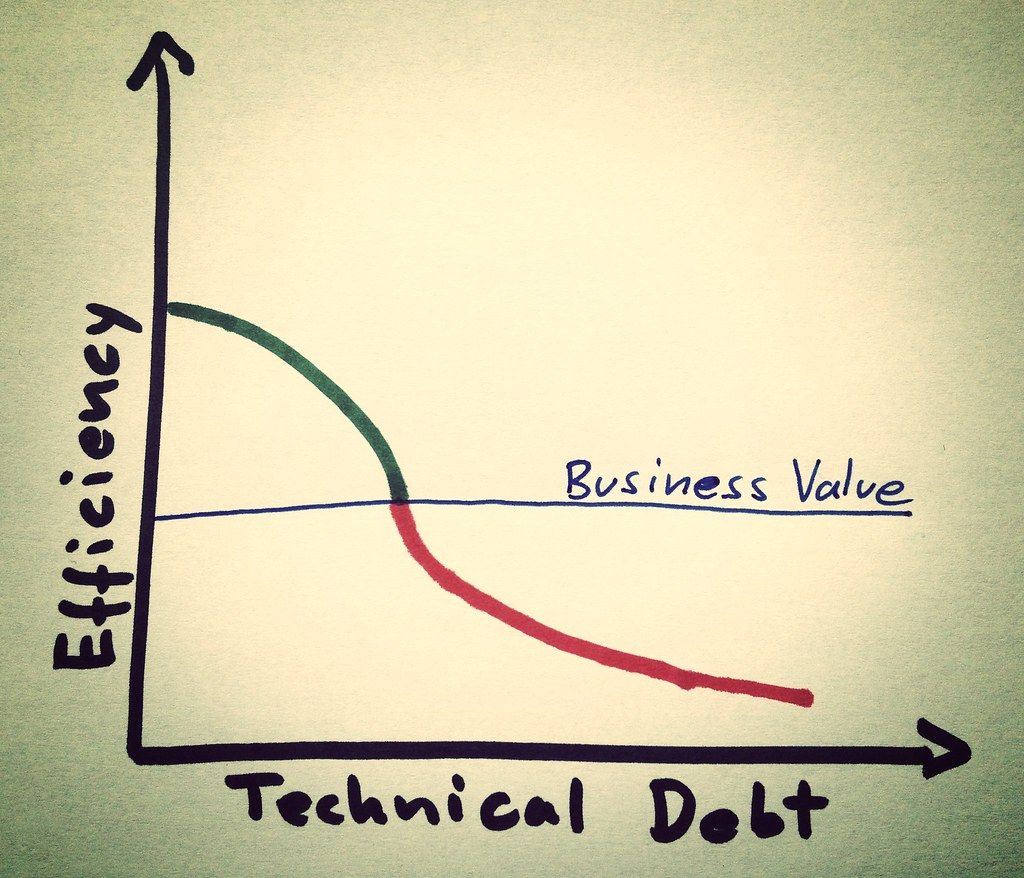
Older principles like the division of labor in the pin factory cannot be applied in machine learning as all inputs are changing constantly. We believe that the central focus should be the data scientist, the driving mind and the core creator of value of any ML project. Their skills concentrate on the creative stage of experimentation. But they are not trained to write, run, and maintain entire ML pipelines.
How does ZenML help?
ZenML is built to tackle the ownership dilemma within ML teams. It is designed with higher level abstractions that enable the data scientist to own the pipeline fully until production. The data scientist won’t need to understand the details of the infrastructure or deployment tools but will be able to use them through ZenML.
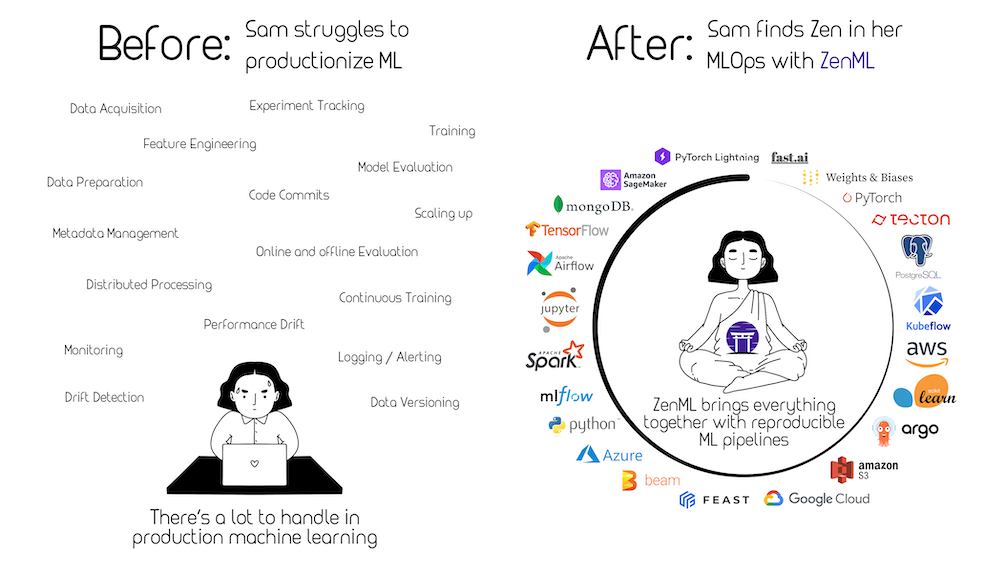
ZenML is written in Python, the lingua franca of data science. Workflows are standardized through simply Python functions linked together in a pipeline:
# pseudo-code
from zenml.integrations.awesome_validation_library.steps import validate
from zenml.integrations.awesome_deployment_library.steps import deploy
@step
def import_() -> Output(train_df=pd.Dataframe, test_df=pd.Dataframe):
...
return train_df, test_df
@step
def train() -> torch.nn.Module:
return model
@pipeline
def my_pipeline(importer, trainer, validator, deployer):
train_df, val_df = importer()
model = trainer(train_df)
# deploy if results are good
results = validator(model, val_df) deployer(model, results)
my_pipeline(import_, train, validate, deploy).run()There are of course other tools out there that look similar to the above, but because ZenML is focused on ML workflows, here are some key advantages:
- Pipelines are data dependent, rather than task dependent. This means that artifacts flowing through pipelines can be modeled in a specific way to enable features like caching and lineage.
- Artifacts flowing through pipeline steps can be standardized (adding a standard validation and deployment step for standard data and model artifacts).
- Steps can be standardized to enable the same effect. You can then enable special features for certain steps (e.g. distributed training for the trainer step).
- ZenML can materialize (read/write) common objects like Pandas dataframes and PyTorch modules automatically, regardless of the environment in which this pipeline is running (local or in the cloud). The data scientist can then use these objects natively as they always do.
This sets ZenML apart from tools like Airflow/Luigi/Prefect that are focused on data engineering use-cases and hard to implement for ML-specific tasks by both developers and data scientists.
All this is from the point of view of an application, but what about infrastructure? Even with all the advantages above, these pipelines and integrations need to work across varied environments and infrastructure requirements for any use-case. This is where the notion of a MLOps stack comes in.
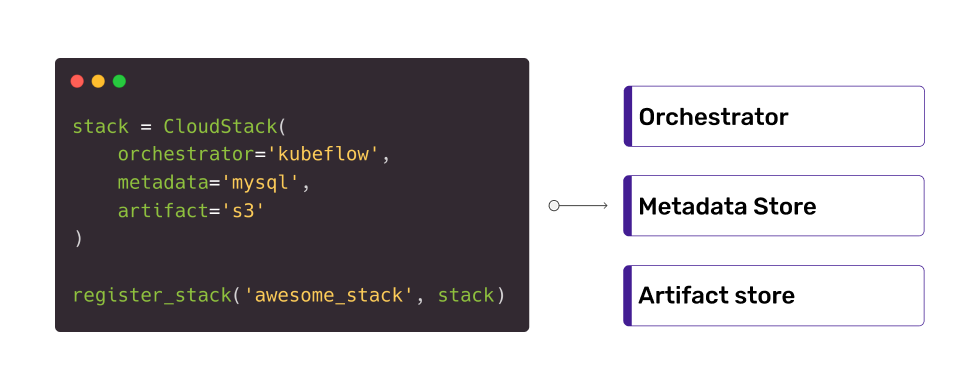
Right now, the stack consists of:
- an orchestrator, to manage running the workflows (e.g. Kubeflow)
- a metadata store, a database to track runs and artifacts across the artifact store
- an artifact store, a file system to store artifacts (AWS/GCP/Azure bucket)
We can then simply do:
zenml stack upThis spins up the infrastructure for you on a target of your choosing. In addition, ZenML takes care of deploying your pipelines to the relevant stack automatically. e.g. Try spinning up a Kubeflow-based stack on your local machine with this simple command. ZenML will build the container for you, create the Kubeflow pipeline, and run it automatically, with a simple command. In the future, we hope to expand this to include more complex deployments.
What’s next and what will we do with the funding?
In the last few months, we have rewritten the ZenML codebase to be more robust and user-friendly. We have also tripled our team in the space of a few months. Today, we released ZenML 0.5.5 that includes support for writing pipelines with standard artifacts like Tensorflow or PyTorch models with Kubeflow. Check out the full example in the docs.
A big part of our current efforts is focusing on integrating awesome third-party tooling libraries like Evidently / WhyLogs / GreatExpectations for validation and BentoML / Seldon / KServe for deployment. You can see our progress in our open community roadmap and/or our open list of integrations.
The challenges ahead are huge but we have motivation and now also the funds to let our vision become reality. We can’t do that without the support of an active community. If the goals of ZenML align with your vision of the future of MLOps, jump over to our Github, give us a star, and write your first ZenML pipeline today!