On this page
Last updated: November 3, 2022.
This article discusses the benefits of giving data scientists ownership of their workflows in a production environment. We also discuss ZenML, an open-source framework that is built specifically to facilitate this ownership.
Why do we need ML pipelines?
Let’s start with the most obvious question: Why do we need ML pipelines in the first place? Here are some solid reasons:
- ML pipelines are the best way to automate ML workflows in a repeatable, robust and reproducible manner.
- Organizations can centralize, collaborate, and manage workflows with a standardized interface.
- ML pipelines can be seen as a means of coordination between different departments.
However, awesome as ML pipelines are, they do come with some inherent questions which might prove problematic.
The Ownership Dilemma
One question that organizations developing machine learning need to answer is who owns ML pipelines in production? Is it the data scientist who creates the model? Is it the data engineer who deploys it in production? Is it someone else altogether?
Note: For an overview of the roles involved in the ML process, check out this part of UC Berkeley’s Full Stack Deep Learning Course.
The data dimension of ML makes it significantly more complex than other deployments in production. More often than not, data scientists do not have the skill set to reliably guide a model into production. Therefore, it is only natural for teams to organize in such a way that there is a shift of ownership from the training phase of development to the deployment phase in the direction of the engineering department (thrown over the wall).
Organizing this way makes it easy enough to get a model in production once. However, the ownership question really comes into play when things (inevitably) go wrong. This could be as the model/concept drifts, or something times out, or the data format changes, or a million other things that the engineering department would know nothing about as they didn’t produce the model.
Also, the farther away you push the data scientist from a production setting, the harder it is to establish a data-flywheel effect of consistent improvement of your models in production. The data scientist needs a wider context in order to be able to make the right calls when training the model. E.g. Should we sacrifice the AUROC a few percent, if that means the model might perform faster in production and yield higher revenue? There is no chance one can even ask that question if just looking at model metrics like AUROC.
Indeed, the further we push the data scientist from production, the less productive the overall ML process will get, and the higher the coordination costs and wait times will get. That’s a no-go for ML, which is supposed to be fast and iterative process.
Solving the Ownership Dilemma
Recently, there has been a lot of talk about how data scientists shouldn’t need to know Kubernetes, or the underlying production infrastructure needs to be necessarily abstracted from them to perform at a high level. I would not only agree with this, but also posit that we have to go one step further. We not only need to abstract the infrastructure from data scientists, but help them take ownership of their models all the way to production.
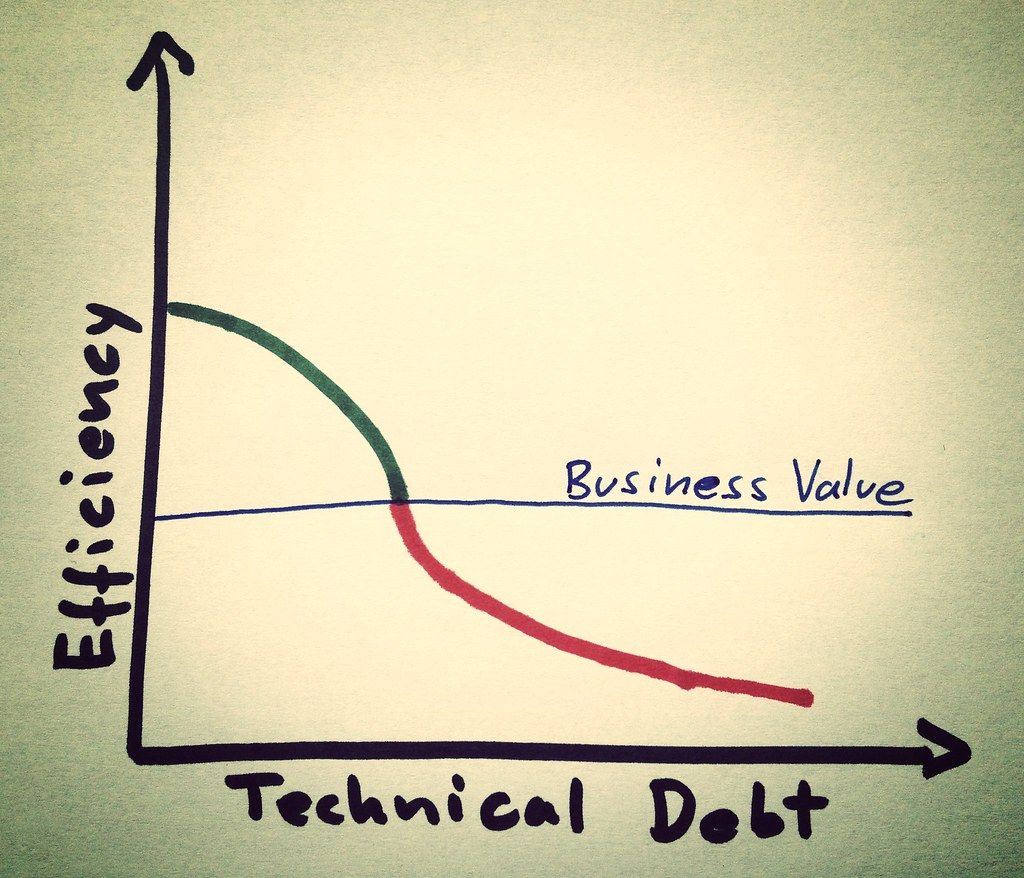
If a team leaves writing ML pipelines for later, they will quickly accrue technical debt. With the right abstractions, an organization can incentivize their data scientists to start writing end-to-end ML pipelines early in the development process. Once data scientists start writing their training/development workflows with easily ‘transferable’ ML pipelines, they would find themselves in a familiar environment once these same pipelines go into production. They would then have the tools necessary to also go into production systems and fix problems as they occur, or make improvements as time goes on.
Ideally, the pipeline becomes a mechanism through which the producers of the models (i.e. the data scientists) can take ownership of their models all the way to production.
Note that this does NOT mean that data scientists should now know every toolkit in the engineering toolbox (like complex deployments of Kubernetes clusters). Rather, the argument is that we need to set data scientists up so that they can take their code to production themselves, with the help required from necessary tooling.
Enter ZenML: A framework designed for modern MLOps
ZenML is an open-source MLOps Pipeline Framework built specifically to address the problems above. Let’s break it down what a MLOps Pipeline Framework means:
- MLOps: It operates in the domain of operationalizing machine learning, i.e., putting ML workflows in production.
- Pipeline: It does this by helping create pipelines, i.e., a sequence of steps performed in this case, specifically for a ML setting.
- Framework: Finally, it creates these pipelines software with abstractions providing generic functionality, which can be selectively changed by additional user-written code.
So it’s a tool that let’s you define pipelines but how is it different from the others? Here is what sets it apart:
Accommodating the Exploding ML Tooling Landscape
Everybody knows that we are now in the midst of an explosion in the ML/MLOps tooling landscape. ZenML is explicitly designed to have no opinions about the underlying infrastructure/tooling that you would like to use. Rather it exposes higher level concepts like Metadata Stores , Artifact Stores, and Orchestrators that have common interfaces. A ML team can then swap out individual components of their pipelines backends and it will ‘just work’.
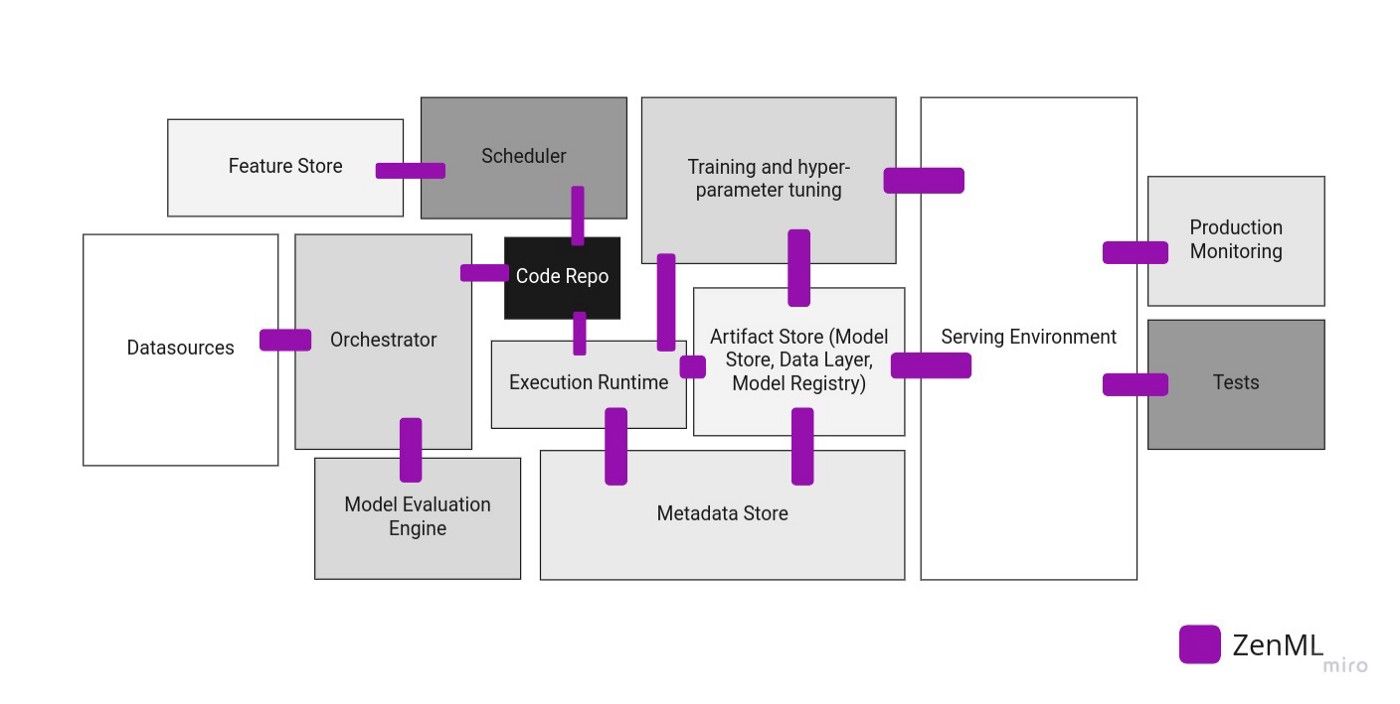
So, if you even want to use MLFlow to track your experiments, run the pipeline on Airflow, and then deploy a model to a Neptune Model Registry, ZenML will facilitate this MLOps Stack for you. This decision can be made jointly by the data scientists and engineers. As ZenML is a framework, custom pieces of the puzzle can also be added here to accommodate legacy infrastructure.
Focus on Machine Learning Workflows (at every phase)
There are many tools that let you define workflows as pipelines but few that focus explicitly on machine learning use-cases.
@trainer
def trainer(dataset: torch.Dataset) -> torch.nn.Module:
...
return modelAs an example, in the above code, ZenML will understand that this is not just a step in the pipeline, but a trainer step. It can use that information to aid in ML-specific use-cases like storing the result in a model registry, deploying this step on GPUs, hyper-parameter tuning etc.
Also notice that ZenML fully supports objects from common ML frameworks like torch.Dataset and torch.nn.Module. These objects can be passed between steps and results cached to enable faster experimentation.
Incentivizing the data scientist to write these pipelines
ZenML understands that pipelines are going to change over time. Therefore, it encourages running these pipelines locally to begin with and experimenting with the results as they are produced. You can query pipelines in a local Jupyter notebook, and materialize it with different pre-made visualizations like statistics visualizations and schema anomalies.

This is a different approach to pipeline development, and is more representative of how a data scientist would like to work in the earlier phases of a project → i.e. with fast, quick iterations and visualizations that help them to make informed decisions about experiments. We call this approach Pipelines As Experiments (PaE).
In short, ZenML allows you to create automated ML workflows with simple, extensible abstractions that lift the common pattern burden off of you. In doing so, it does not take opinions on the underlying infrastructure and aims to be cloud- and tooling-agnostic.
By helping the target audience, i.e. the data scientist, to write their code in ZenML pipelines early in the development lifecycle, the transition from the experimentation phase to the production phase is made much easier. The goal is that by the time the experimentation phase of the ML lifecycle is over, the data scientists can flip a switch to the production ML stack and get their pipelines running in production. At this moment, they would have complete ownership of these pipelines and can manage, update, and debug them as they please.
The Story So Far
To date, ZenML has received:
- 1336 GitHub Stars
- 10 Contributors
- ~200 Slack Members
It has been fantastic to see people’s interest in what was initially just a simple idea. We’re now building ZenML out in the open (no stealth here), and just made a major release with a complete refactor of the codebase. So, if any of the above appealed to you, it would be lovely if you gave ZenML a spin with an end-to-end example of deploying a pipeline in production. Feedback and contributions are welcome!
My sincerest thanks to Alex Strick and Adam Probst for helping edit this article.