
Your GPUs Are Everywhere. Your Robot-Learning Loop Shouldn't Be.
Robotics compute is spreading across clouds and clusters. Learn how one portable pipeline layer can keep the robot-learning loop reproducible.
8 mins

Robotics compute is spreading across clouds and clusters. Learn how one portable pipeline layer can keep the robot-learning loop reproducible.

A practical comparison of Inngest, Temporal, and Kitaru for long-running AI agents, covering recovery, self-hosting, HITL waits, and what each one really costs.

In this article, we learn about all the different pricing plans Trigger.dev offers.

We tested 11 Camunda alternatives for agentic orchestration, from agent runtimes like Kitaru to durable execution tools like Temporal, Restate, DBOS, and Inngest.

In this Temporal pricing guide, we'll break down the platform's pricing plans and tell you whether the investment makes sense for your team.

This article compares Databricks vs Sagemaker vs ZenML on orchestration, features, GenAI, integrations, and pricing for ML platform teams.

Armin Ronacher's Absurd and Kitaru arrived at the same answers on replay semantics, ephemeral compute, and an agent-legible runtime. Here's why that matters.

Compare Dataiku vs Databricks vs ZenML across workflow orchestration, visualization, experiment tracking, governance, integrations, and pricing to choose the right ML platform.

What people call the agent stack is really four layers: model, harness, runtime, platform. Conflating them costs durability. The runtime layer, and one split inside it, gets the least attention.

We break down GPU scheduling, fractional GPU allocation, gang scheduling, integrations, and pricing to help you pick the right tool for your AI infrastructure.

In this Run:ai vs ClearML comparison, we break down GPU orchestration, workload scheduling, resource policies, RBAC, integrations, and pricing to help you pick the right platform for your AI infrastructure.

Kitaru is live: open-source infrastructure platform for running Python agents in production.
A production coding agent isn't a prompt and a while loop. It's eight stages, each with different failure modes, costs, and human touchpoints. Here's the full pattern.

ML pipelines were DAGs. Agents are loops. The orchestration layer that worked for training jobs doesn't work for autonomous systems, and the industry is scrambling to catch up.

We spent five years building ML pipeline infrastructure. Then agents showed up and we realized the next problem needed a new tool — not an extension of the old one.

Tracing shows you what went wrong. But what if you could go back, fix the input, and resume from where it failed — without re-running everything?

Every durable execution engine today forces your code to be deterministic. Kitaru takes a different approach — and it matters more than you think.

In this E2B vs Daytona guide, you will learn about how these two compare across sandbox lifecycle management, output handling, pricing, and more.

AI agents fail — they timeout, hit rate limits, crash on bad API responses. Without durable execution, every failure means starting over from scratch.

In this article, you learn about the best E2B alternatives to deploy AI sandboxes. We break down 10 options covering isolation, execution, pricing, and real-world agent workloads.

Durable execution engines were built for payment flows and order processing. AI agents need something different. Here's why.


In this article, you will learn about the best Comet alternatives for model evaluation.

Explore the 12 best MLOps tools for building and scaling your agentic AI systems.

Compare LangSmith, MLflow, and ZenML across pipeline orchestration, reproducibility, deployment, and pricing to choose the right production AI tool.


In this MLflow vs Airflow vs ZenML article, we determine which is the right tool for modern ML pipelines.

In this article, you learn about the best PromptLayer alternatives to version, test, and monitor prompts in ML workflows.

In this article, you learn about the best DVC alternatives that help you manage large datasets for your ML projects.

This Kubeflow vs SageMaker vs ZenML article helps you choose the framework best for batch and pipeline-driven ML systems.

This n8n vs Temporal vs ZenML guide helps you identify the right workflow engine for your AI system, based on your use case.

In this article, we compare n8n vs Make and understand if no-code workflow automations are as efficient as code-based frameworks or not.

In this MLflow vs SageMaker vs ZenML article, we compare their experiment tracking, model registry, evaluation, integration, and more such capabilities.

In this ClearML vs MLflow vs ZenML article, we compare the three MLOps frameworks and conclude which one is best suited for you.

In this Prefect vs Temporal vs ZenML article, we compare the three to see which one is the best for data and ML teams.

This Databricks vs Snowflake guide will compare both platforms, so you know which one fits your criteria as the right data intelligence platform.

Discover the 11 best LLMOps platforms to build AI agents and workflows.

In this article, you learn about the best n8n alternatives for workflow automation.

In this article, you will learn about the best ClearML alternatives for experiment tracking and building ML pipelines.

An Airflow vs Kubeflow vs ZenML guide that does a feature-by-feature comparison.

In this Slurm vs Kubernetes comparison guide, we compare their primary workflows, control planes, resource models, and scheduling policies.

Compare the 9 best Temporal alternatives for durable execution and AI agent workflows, from Kitaru and Restate to DBOS, Inngest, Hatchet, and more.

In this Neptune AI vs WandB vs ZenML, we compare these platforms’ features, integrations, and pricing.

In this Neptune AI vs MLflow vs ZenML article, we explain the difference between the three platforms by comparing their features, integrations, and pricing.

In this article, you will learn about the best Neptune AI alternatives to help you track your ML experiments better.

In this Temporal vs Airflow comparison, we break down the key differences in architecture, features, and use cases to help you decide which tool belongs in your stack.

Neptune AI is terminating its standalone SaaS solution. Switch to ZenML to track ML experiments and do much more.

In this article, you learn about the best Promptfoo alternatives that help you ship better AI agents.

Discover the 9 best prompt monitoring tools for ML and AI engineering teams.

Discover the 10 best LLM monitoring tools you can use this year.

In this article, you will learn about the best DeepEval alternatives that you can use for LLM evaluation.

In this Langfuse vs Phoenix guide, we conclude which open-source framework fits your LLMs stack by comparing features, integration, and pricing.

In this article, you learn about the best Langfuse alternatives for tracing, eval, prompt management, and metrics for LLM apps.

In this article, you learn about the best LangSmith alternatives you can use for full-stack observability.

In this Langfuse vs LangSmith, we conclude which observability platforms fit your LLMs stack by comparing features, integration, and pricing.

In this article, you learn about the best Datadog alternatives you can use for full-stack observability.
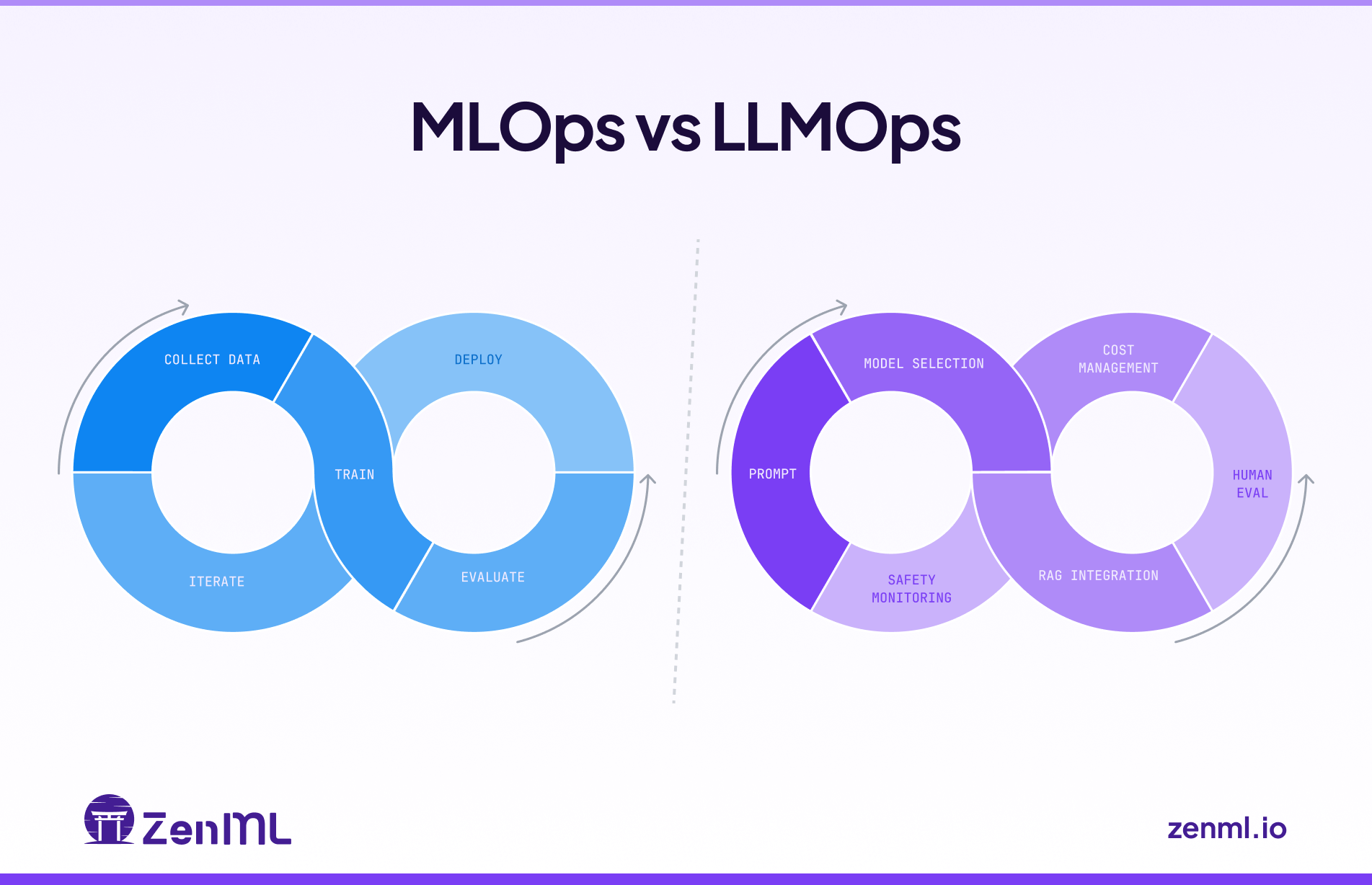
In this guide, we showcase the differences between MLOps and LLMOps and explain how to use them in tandem.

In this Pydantic AI vs CrewAI, we discuss which one is better at building production-grade workflows with generative AI.

ZenML's Pipeline Deployments transform pipelines into persistent HTTP services with warm state, instant rollbacks, and full observability—unifying real-time AI agents and classical ML models under one production-ready abstraction.

In this article, you will learn about the best AutoGPT alternatives to run your AI assistants flawlessly.
In this article, you learn about the best AutoGen alternatives to build AI agents and applications.

Discover the 9 best LLM orchestration frameworks for agents and RAG.

Discover the 9 best LLM evaluation tools to test your AI models before going live.

In this Langflow vs n8n, we compare both platforms’ features, pricing, and integrations.
Discover the 9 best data embedding models for RAG pipelines you build this year.

Discover the 10 best data vector databases for RAG pipelines.

In this Smolagents vs LangGraph, we explain the difference between the two and conclude which one is the best to build AI agents.

In this Haystack vs LlamaIndex, we explain the difference between the two and conclude which one is the best to build AI agents.

In this Google ADK vs LangGraph, we explain the difference between the two and conclude which one is the best to develop and deploy AI agents.

In this Agno vs LangGraph, we explain the difference between the two and conclude which one is the best to build multi-agent systems.

In this Pydantic AI vs LangGraph, we explain the difference between the two and conclude which one is the best to build AI agents.

In this Vellum AI pricing guide, we discuss the costs, features, and value Vellum AI provides to help you decide if it’s the right investment for your business.

Discover the best LLM observability tools currently on the market to build agentic AI workflows.

In this LlamaIndex vs LangChain, we explain the difference between the two and conclude which one is the best to build AI agents.

Discover the top 7 Flowise alternatives - code and no-code that you can leverage to build and deploy efficient AI agents.

Discover the top 8 Botpress alternatives - code and no-code that you can leverage as a complete AI agent platform.

In this LlamaIndex vs CrewAI, we explain the difference between the two and conclude which one is the best to build AI agents.

Discover the top 8 Semantic Kernel alternatives that will help you build efficient AI agents.

In this CrewAI vs n8n, we explain the difference between the two and conclude which one is the best to build AI agents.
Discover the top 8 Langflow alternatives you can leverage to build and deploy AI agents.

In this Semantic Kernel vs Autogen article, we explain the differences between the two frameworks and conclude which one is best suited for building AI agents.
Discover the 7 best Agentic AI frameworks to help you build smarter AI workflows this year.

In this LlamaIndex pricing guide, we discuss the costs, features, and value LlamaIndex provides to help you decide if it’s the right investment for your business.
Compare the best CrewAI alternatives for building production AI workflows, including LangGraph, AutoGen, Google ADK, OpenAI Agents SDK, Pydantic AI, Langflow, Flowise, and LlamaIndex.

FloraCast is a production-ready template that shows how to build a forecasting platform—config-driven experiments, model versioning/staging, batch inference, and scheduled retrains—with ZenML and Darts.

Discover the top 8 RAG tools for agentic AI you should try this year.

In this Crewai vs Autogen article, we explain the difference between the two and conclude which one is the best to build AI agents and applications.

In this CrewAI pricing guide, we discuss the costs, features, and value CrewAI provides to help you decide if it’s the right investment for your business.

In this Agentforce pricing guide, we discuss the costs, features, and value Agentforce provides to help you decide if it’s the right investment for your business.

Compare LangGraph vs n8n for building AI agents in 2025. Updated with LangGraph 1.0 stable release and n8n's new unlimited workflow pricing. Discover which framework fits your production AI stack.

This Langflow vs LangGraph article explains all the differences between these AI agentic systems.

In this LangGraph vs Autogen article, we explain the difference between these platforms and when to use which one for the best results.

In this LlamaIndex vs LangGraph article, we explain the differences between these platforms and when to use each one for optimal results.

In this Metaflow vs Kubeflow vs ZenML article, we explain the difference between these platforms and which one is the right ML pipeline tool for you.

Discover the top 7 Weights & Biases alternatives for better experiment tracking.

Discover the best Kedro alternatives to build production-grade data science pipelines.

Discover the top 8 Prefect alternatives for machine learning teams.

We're expanding ZenML beyond its original MLOps focus into the LLMOps space, recognizing the same fragmentation patterns that once plagued traditional machine learning operations. We're developing three core capabilities: native LLM components that provide unified APIs and management across providers like OpenAI and Anthropic, along with standardized prompt versioning and evaluation tools; applying established MLOps principles to agent development to bring systematic versioning, evaluation, and observability to what's currently a "build it and pray" approach; and enhancing orchestration to support both LLM framework integration and direct LLM calls within workflows. Central to our philosophy is the principle of starting simple before going autonomous, emphasizing controlled workflows over fully autonomous agents for enterprise production environments, and we're actively seeking community input through a survey to guide our development priorities, recognizing that today's infrastructure decisions will determine which organizations can successfully scale AI deployment versus remaining stuck in pilot phases.

Discover the top 7 LlamaIndex alternatives to build AI production agents with ease.

In this LangGraph vs CrewAI article, we explain the difference between the three platforms and educate you about using them efficiently inside ZenML.

In this LangGraph pricing guide, we discuss the costs, features, and value LangGraph provides to help you decide if it’s the right investment for your business.

Discover the top 8 LangGraph alternatives for scalable agent orchestration.

In this ClearML pricing breakdown, we discuss the costs, features, and value ClearML provides to help you decide if it’s the right investment for your business.

In this Prefect vs Airflow vs ZenML article, we explain the difference between the three platforms and educate you about using them in tandem.

Discover why production teams are treating agentic workflows as MLOps evolution, not revolution—plus how ZenML achieved 200x performance improvements for enterprise ML operations. Real insights from 130+ MLOps engineers on building reliable AI systems.
In this WandB pricing guide, we break down the costs, features, and value to help you decide if it’s the right investment for your business.

In this Flyte vs Airflow vs ZenML article, we explain the difference between the three platforms and educate you about using them in tandem.

A technical deep dive into the performance optimizations that improved ZenML's throughput by 200x

In this Metaflow vs MLflow vs ZenML article, we explain the difference between the three platforms and educate you about using them in tandem.

In this Outerbounds pricing guide, we break down the costs, features, and value to help you decide if it’s the right investment for your business.

Discover the top 8 Metaflow alternatives to streamline your ML workflows.

In this Prefect pricing guide, we break down the costs, features, and value to help you decide if it’s the right investment for your business.

Traditional banks face growing pressure to deploy machine learning rapidly while meeting strict regulatory requirements. This blog post explores how modern MLOps practices, like automated data lineage, validation testing, and model observability can help financial institutions bridge the gap. Featuring real-world insights from NatWest and an open-source ZenML pipeline, it offers a practical roadmap for compliant, scalable AI deployment.

In this MLflow vs Weights & Biases vs ZenML article, we explain the difference between the three platforms and educate you about using them in tandem too.

Discover the best MLflow alternatives designed to improve all your ML operations.

An in-depth analysis of retail MLOps challenges, covering data complexity, edge computing, seasonality, and multi-cloud deployment, with real-world examples from major retailers like Wayfair and Starbucks, and practical solutions including ZenML's impact in reducing deployment time from 8.5 to 2 weeks at Adeo Leroy Merlin.

Kubernetes powers 96% of enterprise ML workloads but often creates more friction than function—forcing data scientists to wrestle with infrastructure instead of building models while wasting expensive GPU resources. Our latest post shows how ZenML combined with NVIDIA's KAI Scheduler enables financial institutions to implement fractional GPU sharing, create team-specific ML stacks, and streamline compliance—accelerating innovation while cutting costs through intelligent resource orchestration.

Learn how ZenML unified MLOps across AWS, Azure, on-premises, and tactical edge environments for defense contractors like the German Bundeswehr and French aerospace manufacturers. Overcome hybrid infrastructure complexity, maintain security compliance, and accelerate AI deployment from development to battlefield. Essential guide for defense AI teams managing multi-classification environments and $1.5B+ military AI initiatives.

Discover the top 10 Databricks alternatives designed to eliminate the pain points you might face when using Databricks. This article will walk you through these alternatives and educate you about what the platform is all about - features, pricing, pros, and cons.

In this Kubeflow vs MLflow vs ZenML article, we explain the difference between the three platforms by comparing their features, integrations, and pricing.

Enterprises struggle with ML model management across multiple AWS accounts (development, staging, and production), which creates operational bottlenecks despite providing security benefits. This post dives into ten critical MLOps challenges in multi-account AWS environments, including complex pipeline languages, lack of centralized visibility, and configuration management issues. Learn how organizations can leverage ZenML's solutions to achieve faster, more reliable model deployment across Dev, QA, and Prod environments while maintaining security and compliance requirements.

ZenML 0.80.0 transforms tenant structures into workspace/project hierarchies with advanced RBAC for Pro users, while enhancing tagging, resource filtering, and dashboard design. Open-source improvements include Kubernetes security upgrades, SkyPilot integration, and significantly faster CLI operations. Both Pro and OSS users benefit from dramatic performance optimizations, GitLab improvements, and enhanced build tracking.

The OpenPipe integration in ZenML bridges the complexity of large language model fine-tuning, enabling enterprises to create tailored AI solutions with unprecedented ease and reproducibility.

Our monthly roundup: Hamza visits the US, a new course built on ZenML and why workflows are better than autonomous agents!
Our monthly roundup: AI Infrastructure Summit insights, new experiment comparison tools, and a deep dive into AI Engineering roles
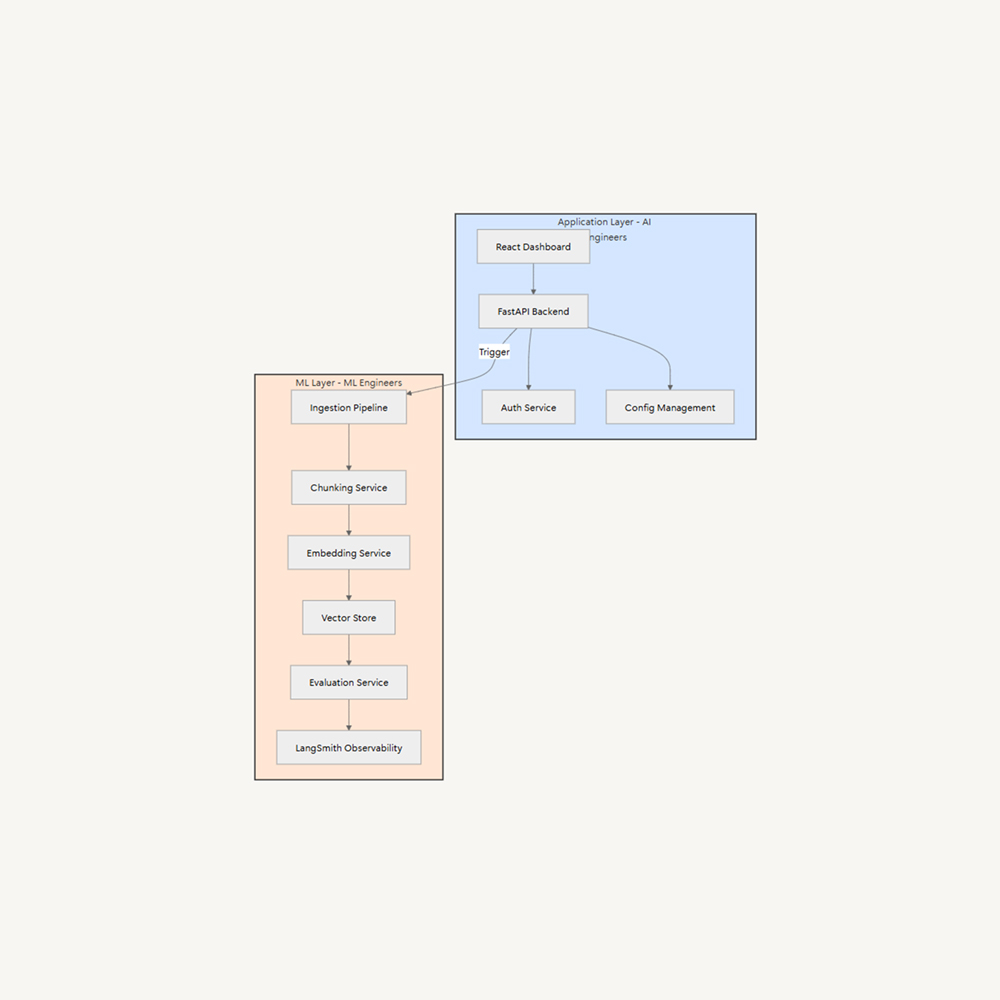
The rise of Generative AI has shifted the roles of AI Engineering and ML Engineering, with AI Engineers integrating generative AI into software products. This shift requires clear ownership boundaries and specialized expertise. A proposed solution is layer separation, separating concerns into two distinct layers: Application (AI Engineers/Software Engineers), Frontend development, Backend APIs, Business logic, User experience, and ML (ML Engineers). This allows AI Engineers to focus on user experience while ML Engineers optimize AI systems.

Why use ZenML alongside AWS / GCP / Azure MLOps platforms? Let's dive into why ZenML complements and enhance existing cloud MLOps infrastructure.
In the AI world, fine-tuning Large Language Models (LLMs) for specific tasks is becoming a critical competitive advantage. Combining Lightning AI Studios with ZenML can streamline and automate the LLM fine-tuning process, enabling rapid iteration and deployment of task-specific models. This approach allows for the creation and serving of multiple fine-tuned variants of a model, with minimal computational resources. However, scaling the process requires resource management, data preparation, hyperparameter optimization, version control, deployment and serving, and cost management. This blog post explores the growing complexity of LLM fine-tuning at scale and introduces a solution that combines the flexibility of Lightning Studios with the automation capabilities of ZenML.

The combination of ZenML and Neptune can streamline machine learning workflows and provide unprecedented visibility into experiments. ZenML is an extensible framework for creating production-ready pipelines, while Neptune is a metadata store for MLOps. When combined, these tools offer a robust solution for managing the entire ML lifecycle, from experimentation to production. The combination of these tools can significantly accelerate the development process, especially when working with complex tasks like language model fine-tuning. This integration offers the ability to focus more on innovating and less on managing the intricacies of your ML pipelines.

This blog post discusses the integration of ZenML and Comet, an open-source machine learning pipeline management platform, to enhance the experimentation process. ZenML is an extensible framework for creating portable, production-ready pipelines, while Comet is a platform for tracking, comparing, explaining, and optimizing experiments and models. The combination offers seamless experiment tracking, enhanced visibility, simplified workflow, improved collaboration, and flexible configuration. The process involves installing ZenML and enabling Comet integration, registering the Comet experiment tracker in the ZenML stack, and customizing experiment settings.
A new ZenML newsletter featuring Istanbul cooking adventures, faster docker builds, and more

The combination of ZenML and SkyPilot offers a robust solution for managing ML workflows.
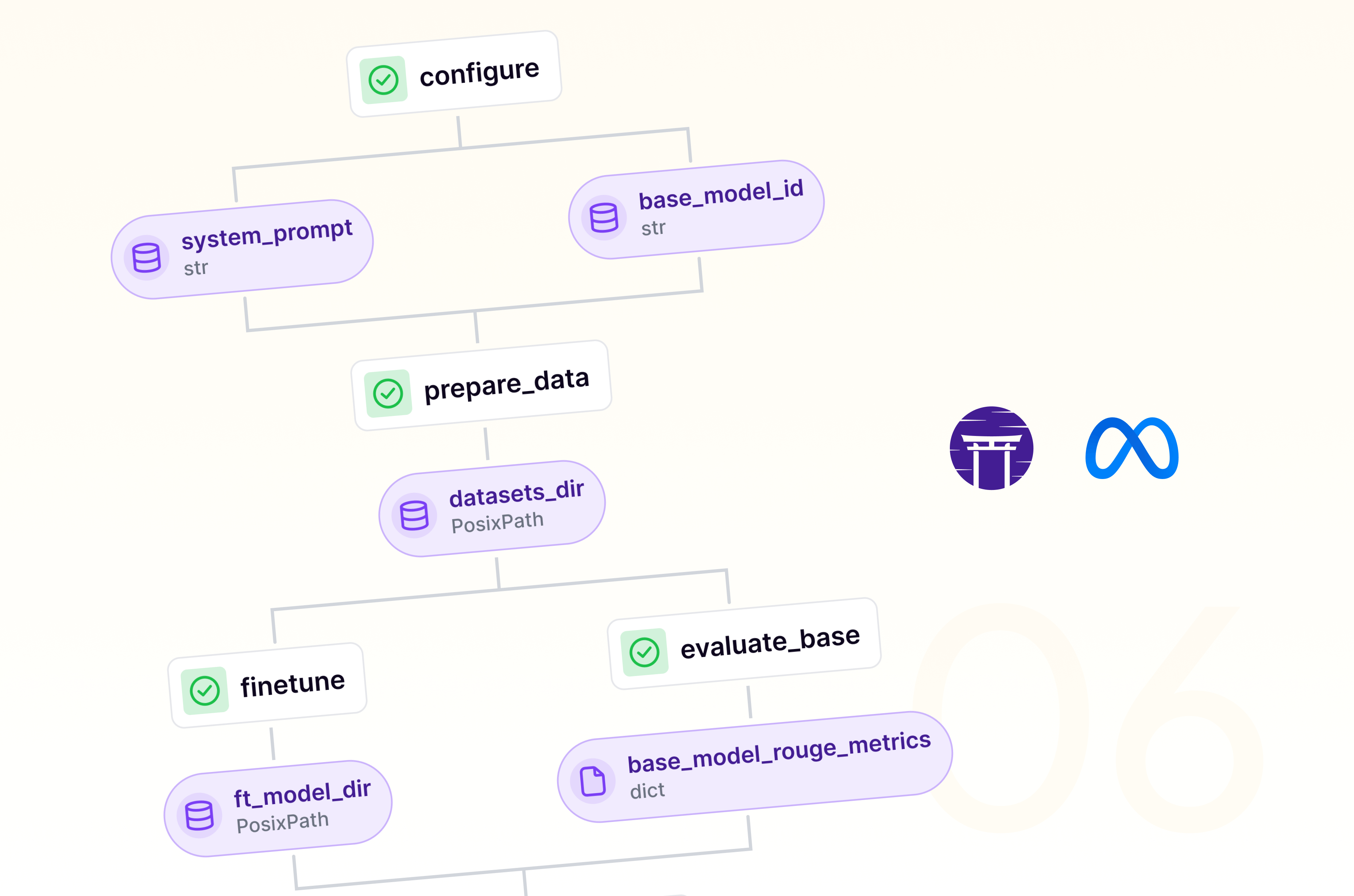
ZenML's new direction: Simplifying infrastructure connections for enhanced MLOps.
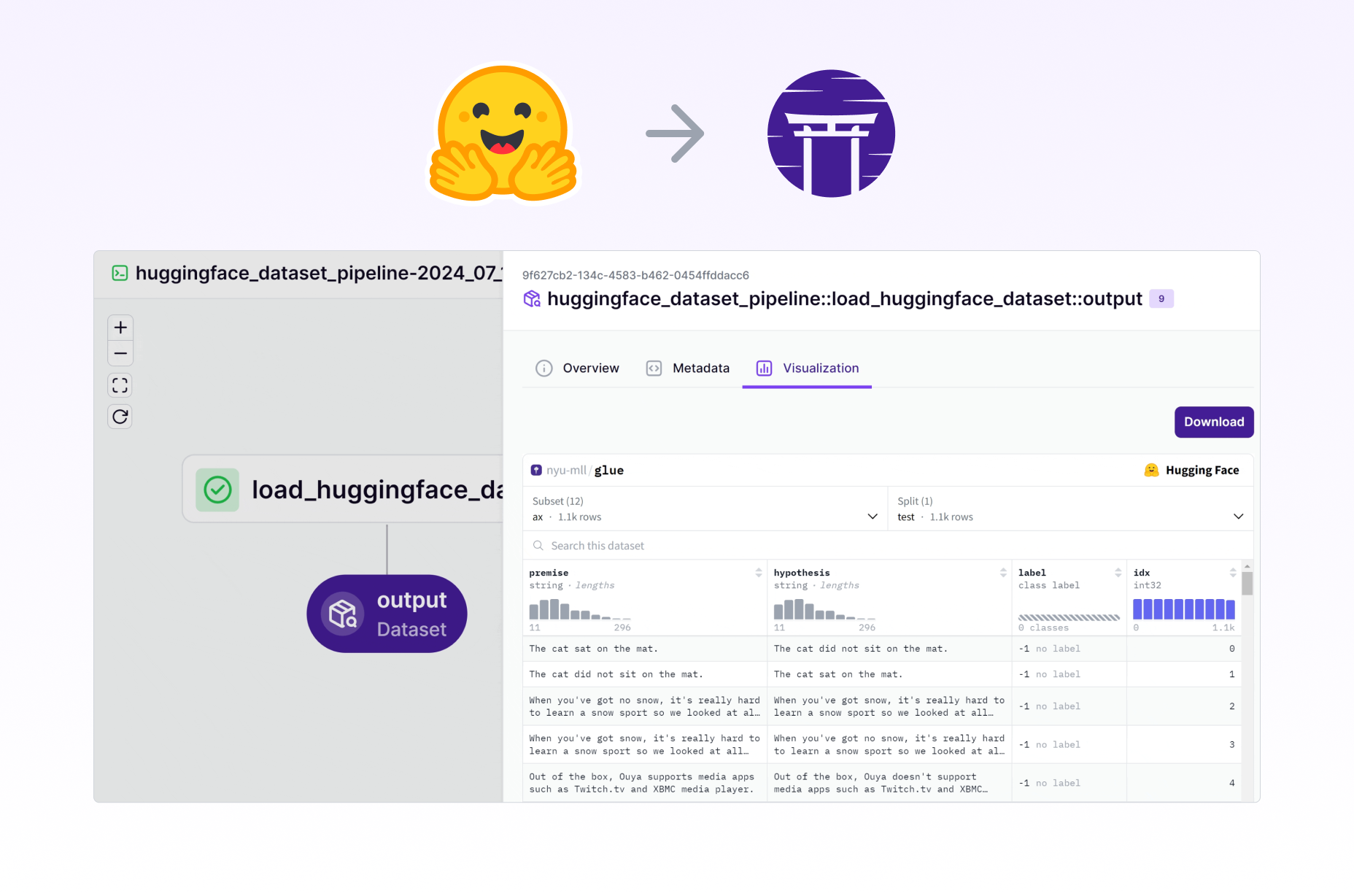
Shipping 🤗 datasets visualization embedded in the ZenML dashboard in a few hours

On the difficulties in precisely defining a machine learning pipeline, exploring how code changes, versioning, and naming conventions complicate the concept in MLOps frameworks like ZenML.

Exploring the evolution of MLOps practices in organizations, from manual processes to automated systems, covering aspects like data science workflows, experiment tracking, code management, and model monitoring.

How to use ZenML and dbt together, all powered by ZenML's built-in success hooks that run whenever your pipeline successfully completes.

Today, we're back to LLM land (Not too far from Lalaland). Not only do we have a new LoRA + Accelerate-powered finetuning pipeline for you, we're also hosting a RAG themed webinar.


Taking large language models (LLMs) into production is no small task. It's a complex process, often misunderstood, and something we’d like to delve into today.
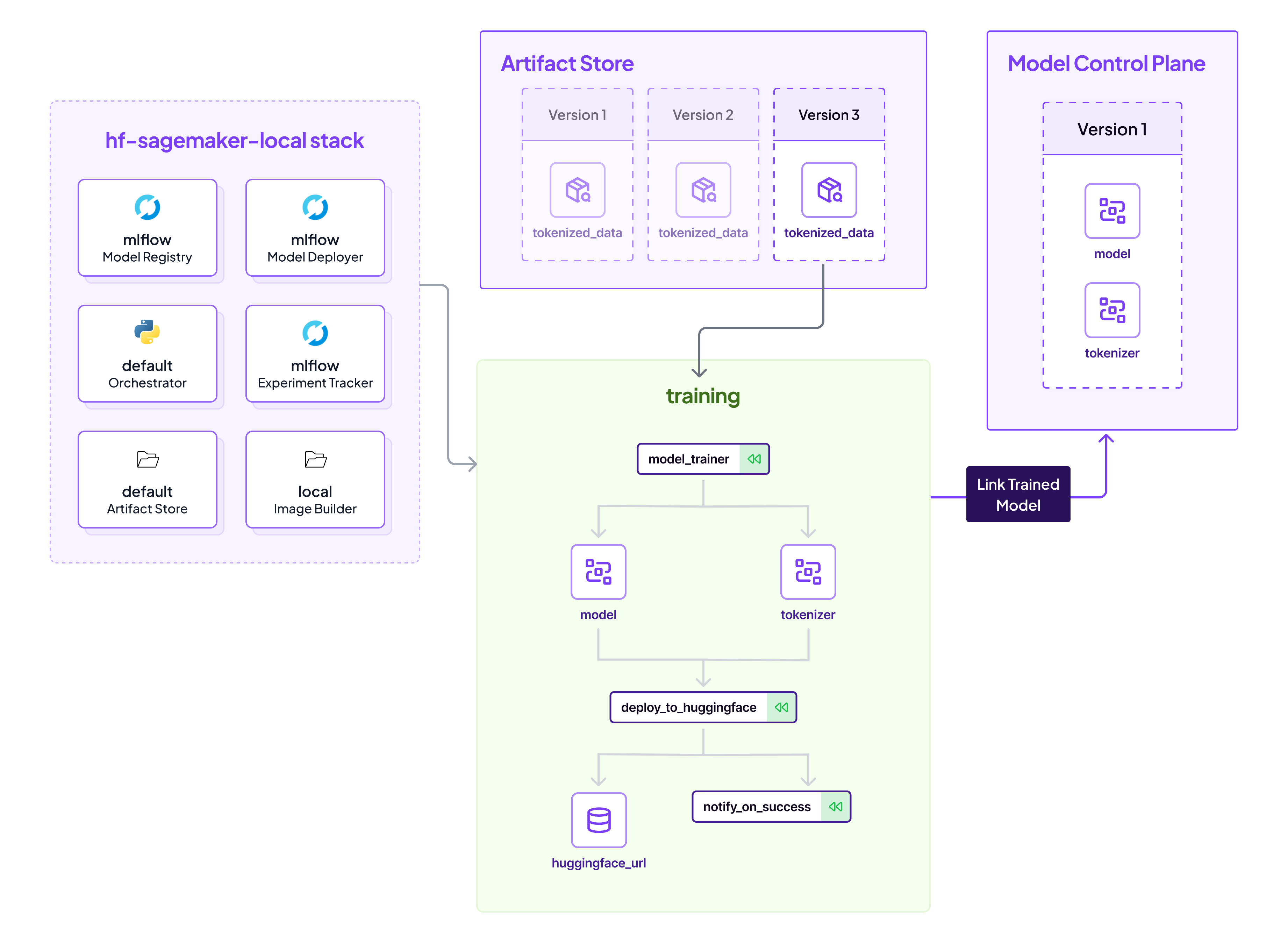
Deploying Huggingface models to AWS Sagemaker endpoints typically only requires a few lines of code. However, there's a growing demand to not just deploy, but to seamlessly automate the entire flow from training to production with comprehensive lineage tracking. ZenML adeptly fills this niche, providing an end-to-end MLOps solution for Huggingface users wishing to deploy to Sagemaker.

Explore how ZenML, an MLOps framework, can be used with large language models (LLMs) like GPT-4 to analyze and version data from databases like Supabase. In this case study, we examine the you-tldr.com website, showcasing ZenML pipelines asynchronously processing video data and generating summaries with GPT-4. Understand how to tackle large language model limitations by versioning data and comparing summaries to unlock your data's potential. Learn how this approach can be easily adapted to work with other databases and LLMs, providing flexibility and versatility for your specific needs.

ZenML 0.23.0 comes with a brand-new experiment tracker flavor - Neptune.ai! We dive deeper in this blog post.

The ZenML MLOps Competition ran from October 10 to November 11, 2022, and was a wonderful expression of open-source MLOps problem-solving.
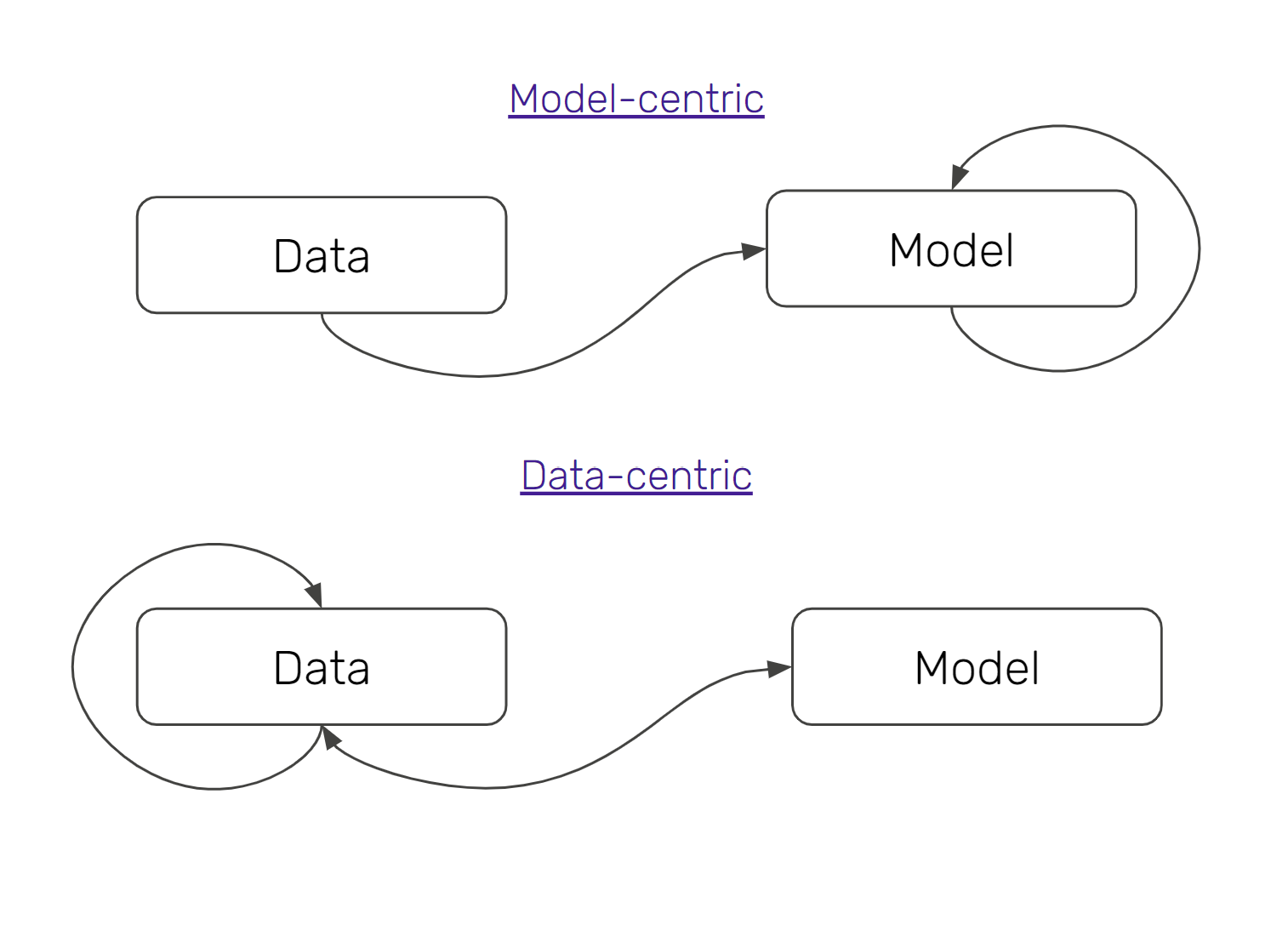
ML practitioners today are embracing data-centric machine learning, because of its substantive effect on MLOps practices. In this article, we take a brief excursion into how data-centric machine learning is fuelling MLOps best practices, and why you should care about this change.

With ZenML 0.6.3, you can now run your ZenML steps on Sagemaker, Vertex AI, and AzureML! It’s normal to have certain steps that require specific infrastructure (e.g. a GPU-enabled environment) on which to run model training, and Step Operators give you the power to switch out infrastructure for individual steps to support this.

Why data scientists need to own their ML workflows in production.

Eliminate technical debt with iterative, reproducible pipelines.

Short answer: not really, but it can become better!
![Why ML in production is (still) broken - [#MLOps2020]](https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/79950cfa/65316d2bc051413294285f1e_mlopsworldthumbnail.png)
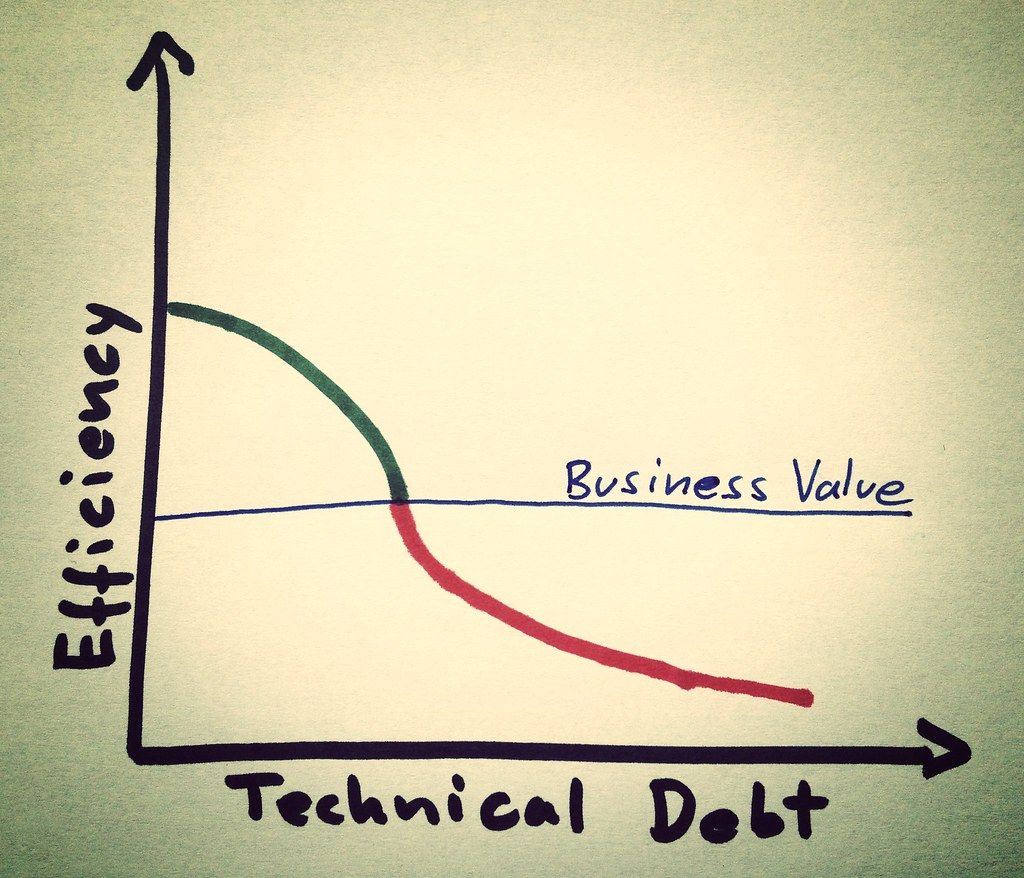
The MLOps movement and associated new tooling is starting to help tackle the very real technical debt problems associated with machine learning in production.
Pipelines help you think and act better when it comes to how you execute your machine learning training workflows.
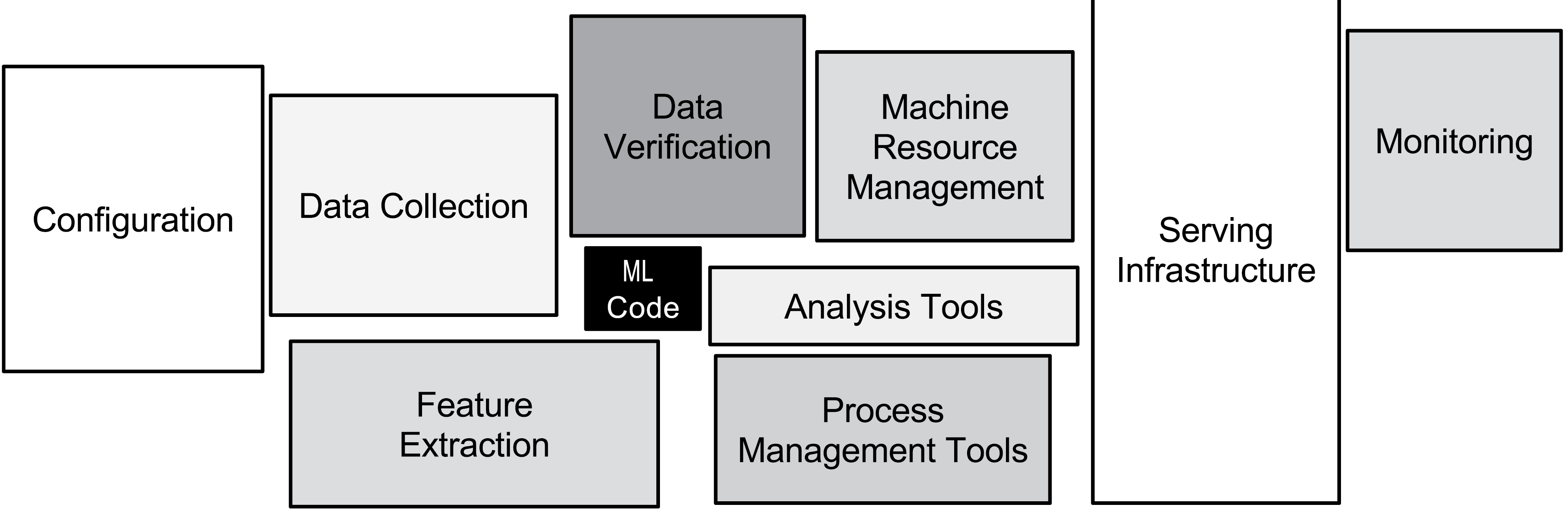
Software engineering best practices have not been brought into the machine learning space, with the side-effect that there is a great deal of technical debt in these code bases.