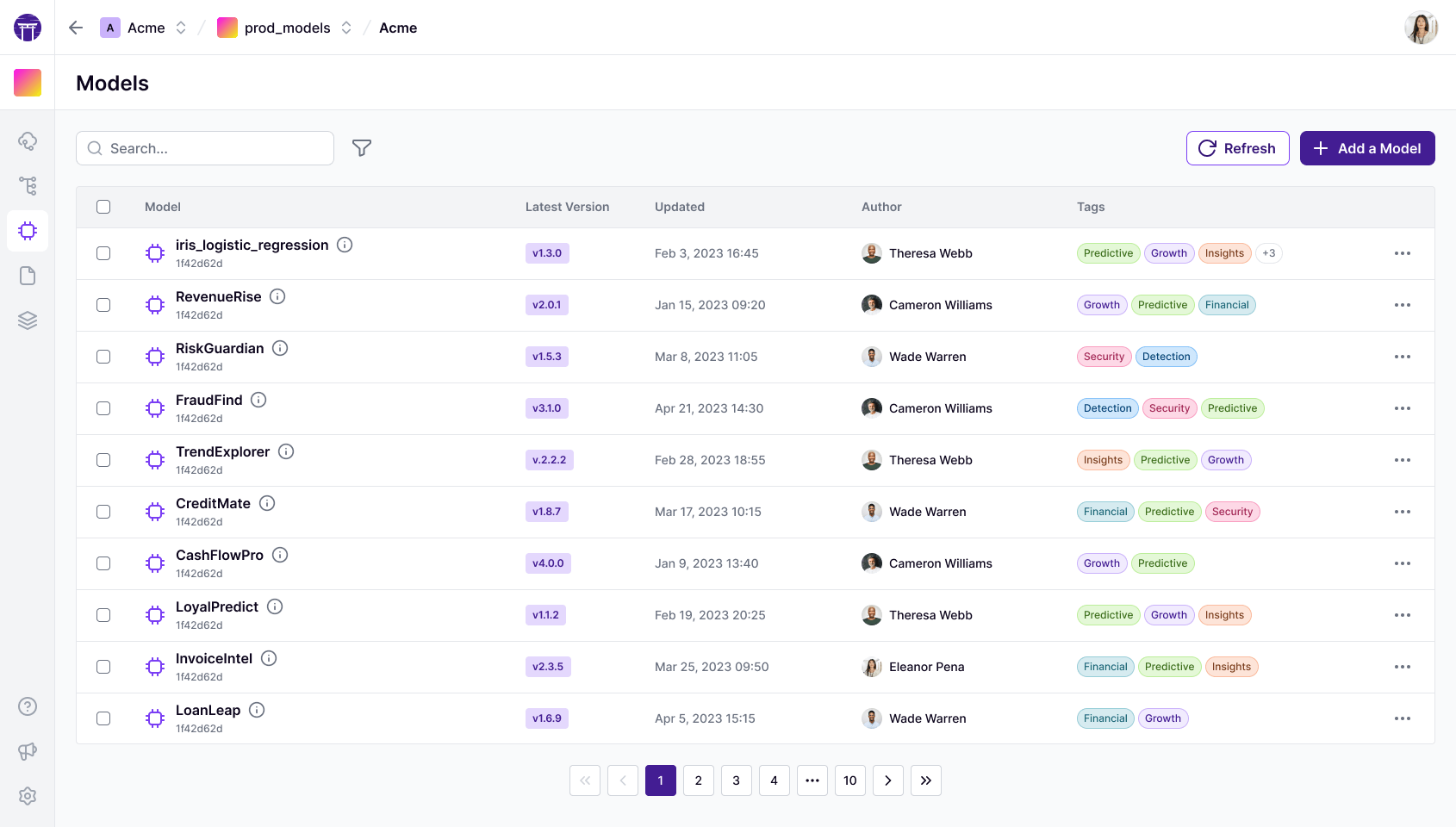
The unified layer for ML and AI
Reproducible ML pipelines with ZenML. Replayable agent evals with Kitaru. One platform, on the infrastructure you already use.
from typing import Annotatedfrom zenml import pipeline, step @stepdef simple_step(name: str = "World") -> Annotated[str, "greeting"]: return f"Hello, {name}! Welcome to ZenML!" @pipelinedef simple_pipeline(name: str = "World"): return simple_step(name=name)from zenml import pipeline, step @stepdef data_loader(random_state: int) -> pd.DataFrame: return load_breast_cancer(as_frame=True).frame @stepdef model_trainer(dataset_trn: pd.DataFrame) -> ClassifierMixin: return SGDClassifier().fit(dataset_trn.drop("target", axis=1), dataset_trn.target) @pipelinedef training(model_type: str = "sgd"): model_trainer(dataset_trn=data_loader(random_state=17))from zenml import pipelinefrom steps import prepare_data, finetune, evaluate_model, promote @pipelinedef llm_peft_full_finetune( base_model_name: str = "microsoft/phi-2", dataset_name: str = "gem/viggo",): datasets_dir = prepare_data(base_model_name, dataset_name) ft_model_dir = finetune(base_model_name, datasets_dir) evaluate_model(base_model_name, ft_model_dir, datasets_dir) promote(ft_model_dir)from zenml import pipelinefrom zenml.config import DeploymentSettingsfrom steps.inference import predict_churn @pipeline( on_init=init_model, settings={"deployment": DeploymentSettings( app_title="Churn Prediction API", dashboard_files_path="ui", )},)def churn_inference_pipeline(customer_features: Dict) -> Dict: return predict_churn(customer_features=customer_features)from zenml import pipelinefrom steps import load_coco_dataset, train_yolo, fiftyone_analysis @pipelinedef object_detection_training_pipeline( max_samples: int = 50, epochs: int = 1, model_name: str = "yolov8n.pt",): dataset = load_coco_dataset(max_samples=max_samples) model = train_yolo(dataset=dataset, epochs=epochs, model_name=model_name) fiftyone_analysis(dataset=dataset, model=model)import torchfrom zenml import step @step(enable_cache=False)def train_model( X: torch.Tensor, y: torch.Tensor) -> torch.nn.Module: model = torch.nn.Sequential( torch.nn.Linear(784, 256), torch.nn.ReLU(), torch.nn.Linear(256, 10), ) return model # auto-versioned by ZenMLimport tensorflow as tffrom zenml import step @step(enable_cache=False)def train_classifier( X_train: tf.Tensor, y_train: tf.Tensor) -> tf.keras.Model: model = tf.keras.Sequential([ tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax'), ]) return model # saved as SavedModel artifactimport pandas as pdfrom sklearn.ensemble import RandomForestClassifierfrom typing_extensions import Annotatedfrom zenml import ArtifactConfig, step @stepdef model_trainer( dataset_trn: pd.DataFrame,) -> Annotated[RandomForestClassifier, ArtifactConfig(is_model_artifact=True)]: model = RandomForestClassifier() model.fit(dataset_trn.drop('target', axis=1), dataset_trn['target']) return modelimport pandas as pdfrom sklearn.datasets import load_breast_cancerfrom typing_extensions import Annotatedfrom zenml import step @stepdef data_loader( random_state: int,) -> Annotated[pd.DataFrame, 'dataset']: df = load_breast_cancer(as_frame=True).frame df.reset_index(drop=True, inplace=True) return df # versioned DataFrame artifactfrom transformers import AutoModelForCausalLMfrom peft import get_peft_model, LoraConfigfrom zenml import step @step(enable_cache=False)def finetune_step( base_model_name: str, datasets_dir: str) -> str: model = AutoModelForCausalLM.from_pretrained(base_model_name) model = get_peft_model(model, LoraConfig(r=16, lora_alpha=32)) # trainer.train() — ZenML tracks the checkpoint return datasets_dirimport pandas as pdimport xgboost as xgbfrom zenml import step @stepdef train_xgb_model( df_train: pd.DataFrame, label_col: str = 'target') -> xgb.Booster: dtrain = xgb.DMatrix( df_train.drop(columns=[label_col]), df_train[label_col] ) return xgb.train({'max_depth': 6}, dtrain, num_boost_round=100)import lightgbm as lgbimport pandas as pdfrom zenml import step @stepdef train_lgbm( df_train: pd.DataFrame, label: str = 'target') -> lgb.LGBMClassifier: clf = lgb.LGBMClassifier(n_estimators=300, learning_rate=0.05) clf.fit(df_train.drop(columns=[label]), df_train[label]) return clfimport numpy as npfrom typing_extensions import Annotatedfrom zenml import step @stepdef normalize_features( X_raw: np.ndarray,) -> tuple[ Annotated[np.ndarray, 'X_norm'], Annotated[np.ndarray, 'mean'],]: mean = X_raw.mean(axis=0) return (X_raw - mean) / X_raw.std(axis=0), meanimport polars as plfrom typing_extensions import Annotatedfrom zenml import step @stepdef build_features( raw_path: str,) -> Annotated[pl.DataFrame, 'features']: return ( pl.scan_parquet(raw_path) .filter(pl.col('value') > 0) .collect() )import wandbfrom zenml import stepfrom zenml.integrations.wandb.flavors import WandbExperimentTrackerSettings @step( experiment_tracker='wandb_tracker', settings={'experiment_tracker.wandb': WandbExperimentTrackerSettings(tags=['training', 'v2'])})def train_and_log(X_train, y_train) -> float: wandb.log({'loss': 0.42, 'accuracy': 0.91}) return 0.91from kitaru import checkpoint, flow
@checkpoint
def gather_sources(topic: str) -> str:
return f"Source notes on {topic}."
@checkpoint
def summarize(notes: str) -> str:
return f"Summary: {notes.split(':')[0].lower()}."
@flow
def research_agent(topic: str) -> str:
notes = gather_sources(topic)
return summarize(notes)import kitaru
from kitaru import checkpoint, flow
@checkpoint
def write_draft(topic, outline):
return kitaru.llm(
f"Write a paragraph about {topic} from {outline}.",
model="fast", name="draft_call",
)
@flow
def llm_writer(topic: str) -> str:
outline = kitaru.llm(
f"Create a 3-bullet outline about {topic}.",
model="fast", name="outline_call",
)
return write_draft(topic, outline)from kitaru import checkpoint, flow
@checkpoint
def check_hr_compliance(prompt=HR_PROMPT):
return _run_domain_turn(prompt, domain="hr")
@checkpoint
def check_it_security(prompt=IT_PROMPT):
return _run_domain_turn(prompt, domain="it_security")
@checkpoint
def synthesize_report(hr, it, vendors, ins):
return _run_agent(SYNTHESIS_PROMPT.format(...))
@flow
def audit_company():
hr, it, v, ins = run_domain_checks()
return synthesize_report(hr, it, v, ins)import kitaru
from kitaru import checkpoint, flow
@checkpoint
def draft_release_note(topic: str) -> str:
return f"Draft about {topic}."
@flow
def wait_for_approval_flow(topic: str) -> str:
draft = draft_release_note(topic)
approved = kitaru.wait(
name="approve_release",
schema=bool,
question=f"Approve {topic}?",
timeout=3600,
)
if approved is False:
return f"REJECTED: {topic}"
return publish_release_note(draft, details)from kitaru import checkpoint, flow
from kitaru.adapters.pydantic_ai import KitaruAgent
from pydantic_ai import Agent
scout_agent = KitaruAgent(
Agent(MODEL, name="news_scout",
tools=[search_news, search_twitter,
investigate, fetch_url]),
granular_checkpoints=True,
)
@checkpoint
def publish_report(text: str) -> str:
return text
@flow
def news_scout(interests: list[str]) -> str:
result = scout_agent.run_sync(
build_user_prompt(interests),
)
return publish_report(result.output)Trusted by teams shipping ML pipelines and AI agents
ZenML — ML/AI Orchestration
The open-source platform for production ML systems.
Orchestrate workflows across your existing tools, clouds, and environments. Modular, agnostic, no lock-in.
- Pipelines and stacks across any cloud
- Model registry, lineage, and reproducibility built in
- Open source — your stack, your data, your governance
Kitaru — Agent Evals
Turn agent failures into regression tests.
Your agent’s real traces become frozen, replayable worlds. Score what happened, replay your real code against it, and keep every fix as a regression test. Self-hosted, framework-agnostic, no lock-in.
- Score thousands of traces — the agent never runs
- Replay with one thing changed — model, tool, or prompt
- Every fix becomes a regression test that guards CI

Pick your workspace and start shipping.
Open source at the core. ML pipelines, agent flows, or both — same plans, same control plane.
Whitepaper
ZenML as your Enterprise-Grade AI Platform
We have put down our expertise around building production-ready, scalable AI platforms, building on insights from our top customers.
Customer Stories
How engineering teams cut time-to-production and simplify their AI infrastructure.

Creating a Unified AI Platform: How JetBrains Centralizes ML on Kubernetes with ZenML

How ADEO Leroy Merlin decreased their time-to-market from 2 months to 2 weeks

How Brevo accelerated model development by 80% using ZenML
How Cross Screen Media Trains Models for 210 Markets in Hours, Not Weeks, with ZenML
Track production ML and AI deployments across the industry
See the LLMOps database →

ZenML offers the capability to build end-to-end ML workflows that seamlessly integrate with various components of the ML stack. This enables teams to accelerate their time to market by bridging the gap between data scientists and engineers.

Harold Gimenez
SVP R&D at HashiCorp

ZenML allows orchestrating ML pipelines independent of any infrastructure or tooling choices. ML teams can free their minds of tooling FOMO from the fast-moving MLOps space, with the simple and extensible ZenML interface.

Richard Socher
Former Chief Scientist Salesforce and Founder of You.com
ZenML allowed us a fast transition between dev to prod. It's no longer the big fish eating the small fish – it's the fast fish eating the slow fish.

François Serra
ML Engineer / ML Ops / ML Solution architect at ADEO Services
Many teams still struggle with managing models, datasets, code, and monitoring as they deploy ML models into production. ZenML provides a solid toolkit for making that easy in the Python ML world.

Chris Manning
Professor of Linguistics and CS at Stanford

Thanks to ZenML we've set up a pipeline where before we had only Jupyter notebooks. It helped us tremendously with data and model versioning.

Francesco Pudda
Machine Learning Engineer at WiseTech Global

ZenML allows you to quickly and responsibly go from POC to production ML systems while enabling reproducibility, flexibility, and above all, sanity.

Goku Mohandas
Founder of MadeWithML
News
Latest from ZenML & Kitaru
Updates, tutorials, and engineering posts from across both workspaces.
See all posts


No compliance headaches
Your VPC, your data
ZenML is a metadata layer on top of your existing infrastructure, meaning all data and compute stays on your side.



ZenML is SOC2 and ISO 27001 Compliant
We Take Security Seriously
ZenML is SOC2 and ISO 27001 compliant, validating our adherence to industry-leading standards for data security, availability, and confidentiality in our ongoing commitment to protecting your ML workflows and data.
Getting Ahead in Pipelines, Agents & Evals?
Subscribe to the ZenML newsletter and receive regular product updates, tutorials, examples, and more.
We care about your data in our privacy policy.
Support
Frequently asked questions
Everything you need to know about the product.
What is the difference between ZenML and other machine learning orchestrators?
Does ZenML integrate with my MLOps stack?
Does ZenML help in GenAI / LLMOps use-cases?
What is Kitaru?
How can I build my MLOps/LLMOps platform using ZenML?
What is the difference between the open source and Pro product?
Ship agents you can prove, and pipelines you can trust.
- Open-source foundation, no vendor lock-in
- Works with any infrastructure
- Upgrade to managed Pro features