For quite some time, large language models have been constrained by how much text you could pass into them. This ‘context window’ was a significant barrier that prevented some use cases and made others much less ergonomic; compressing or clipping your data to make it fit was the name of the game. Over the past year, that context window has started increasing in size, first modestly and then massively. Google’s Gemini 1.5 model can ingest a mammoth 1 million tokens, to take the most prominent example.
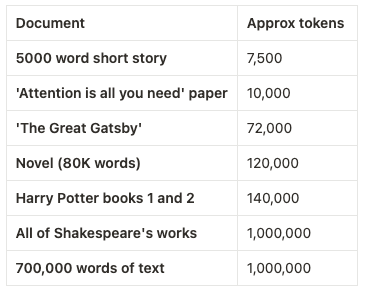
In case you’re wondering what you can do with a million tokens, here are some rough estimations to put that in context:
Open-source models have been a bit slower to increase that context window, but they’re catching up. A key evaluation test for these context windows’ performance checks that the model is equally capable across the entirety of the long context window; it’s not much use if things in the middle of the text are more likely to be ignored.
This year, and also this past week, have seen a number of research publications around the possibility that context windows could be extended effectively indefinitely:
- Meta introduced MEGALODON, a neural architecture designed for efficient sequence modeling with unlimited context length, which may be used in their upcoming Llama 3 model.
- Google researchers proposed Infini-Attention and Feedback Attention Memory (FAM) methods to enable Transformers to handle infinitely long contexts with bounded memory and computation.
- Microsoft Research developed LongRoPE, extending LLM context window to over 2 million tokens, and RHO-1, which uses Selective Language Modeling (SLM) to focus on desired tokens during pre-training.
- NVIDIA researchers created RULER, a benchmark to evaluate the efficiency of long-context language models across various task categories.
Clearly, the top researchers and research labs are all working to extend the context window. As context windows continue to grow, it’s natural to wonder how this will impact the future of RAG systems. RAG has been a popular approach for dealing with the limitations of context windows in large language models. By using a retrieval system to find the most relevant chunks of text and then passing those to the LLM, RAG allows for effectively working with much larger datasets than the context window would normally allow.
However, with the advent of models like MEGALODON, Infini-Attention, and LongRoPE, which promise effectively unlimited context windows, will RAG become obsolete? While it’s true that these new architectures could theoretically allow passing an entire dataset (or a significant portion of it) directly into the language model, there are still several reasons why RAG is likely to remain relevant and useful, at least in the near term.
Firstly, these new architectures are still in the research phase, and it will take some time before they are widely available and practical to use for most applications. Secondly, even with an unlimited context window, there may still be benefits to using a retrieval system to pre-select the most relevant information, as this could lead to more efficient and targeted responses from the LLM. Finally, RAG systems offer flexibility in terms of being able to easily update or expand the knowledge base without needing to retrain the entire language model.
So while the landscape is certainly evolving, RAG is likely to continue to play an important role even as context windows expand. With that in mind, let’s take a closer look at how RAG systems work. Our recently-published guide showcases how to use RAG to overcome the limitations of short context windows:
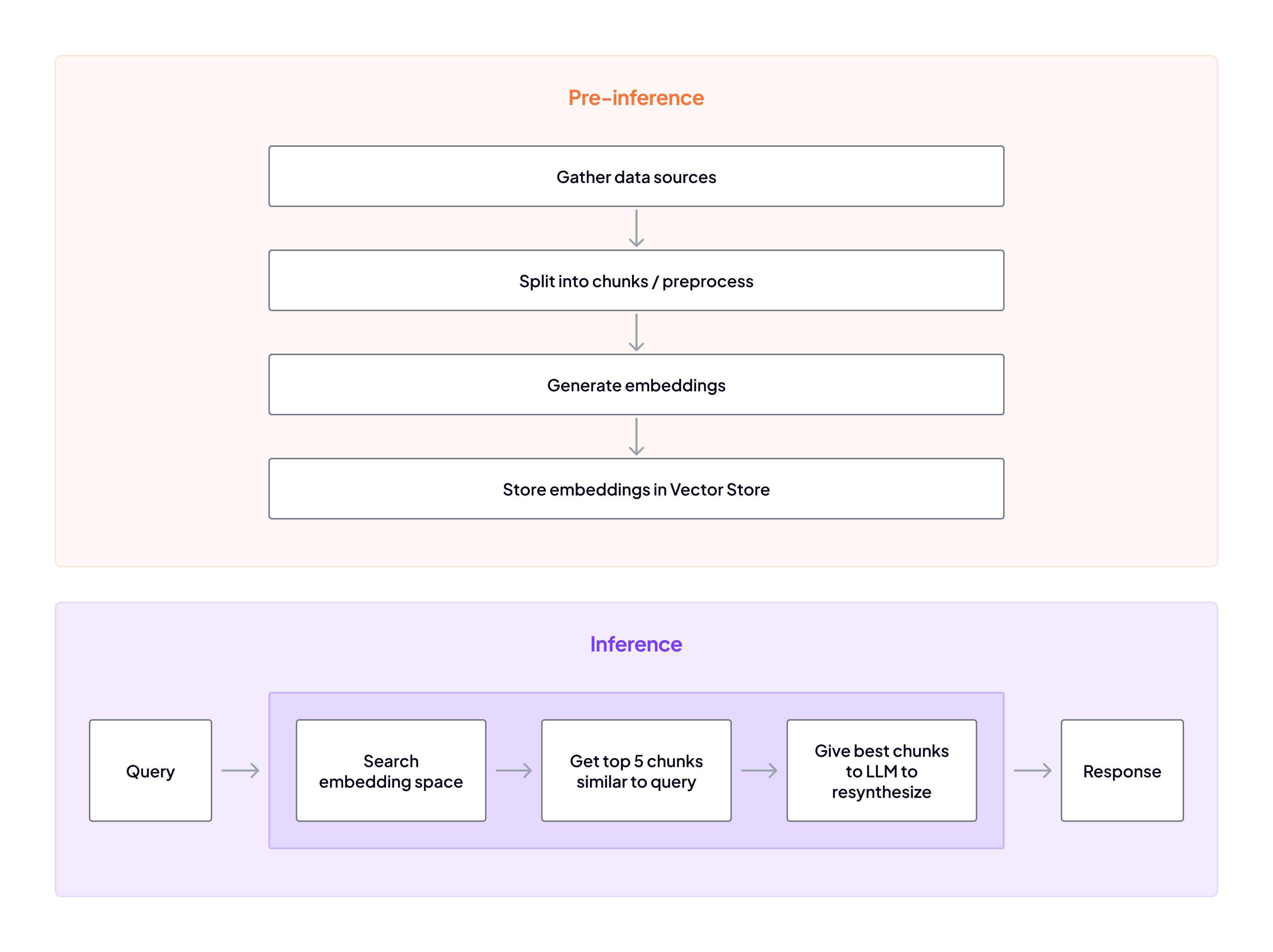
- you split your text data into small chunks (optionally attaching metadata alongside)
- you encode your chunks as vectors (helped by pre-made embedding models) and store them somewhere
- when you’re ready to use your RAG system, you encode a question as a vector and find other vectors that are similar.
- you take the most relevant handful of those context chunks and pass them to the LLM along with the original question to get a response to your question
In a world of infinite context window lengths, you can theoretically just pass your entire dataset (or a significant portion of it) into the language model and have it do the work of picking which parts are significant to your task. While the prospect of infinite context windows is exciting, there are several reasons why RAG systems will likely remain a valuable tool in the LLMOps toolkit.
Firstly, RAG systems are built from relatively simple, well-understood components. This makes them easier to understand, debug, and maintain compared to monolithic models with complex new architectures. The modular nature of RAG also allows for easy experimentation and optimization of each component separately.
Secondly, RAG systems can be built using smaller, more specialized models for each component (retrieval, encoding, generation). This can be more cost-effective and efficient than relying on a single massive model to handle everything. It also allows for more targeted fine-tuning or adaptation of each component to specific tasks or domains.
Thirdly, the composable nature of RAG makes it highly flexible and adaptable. Components can be swapped out or upgraded as better models become available, without needing to retrain or rearchitect the entire system. This modularity also enables introspection and interpretation at each stage of the process, which can be valuable for understanding and trusting the system’s outputs.
Finally, it’s worth remembering the original motivation behind RAG, as outlined in the original Facebook Research paper, was to enable language models to use large external knowledge bases effectively. Even with unlimited context windows, this goal remains relevant. RAG provides a framework for structuring and integrating external knowledge that can enhance the capabilities of language models in a controllable and interpretable way.
So while expanding context windows are an exciting development, RAG systems offer unique benefits in terms of simplicity, efficiency, flexibility, and interpretability. As such, they are likely to remain a valuable approach even as language models become capable of ingesting larger and larger amounts of text. The future of LLMOps will likely involve a mix of techniques, with RAG playing a key role in enabling language models to effectively utilize external knowledge.
Interested in learning how to implement your own RAG system with MLOps best practices? Sign up for our webinar at https://lu.ma/cqmna2a9