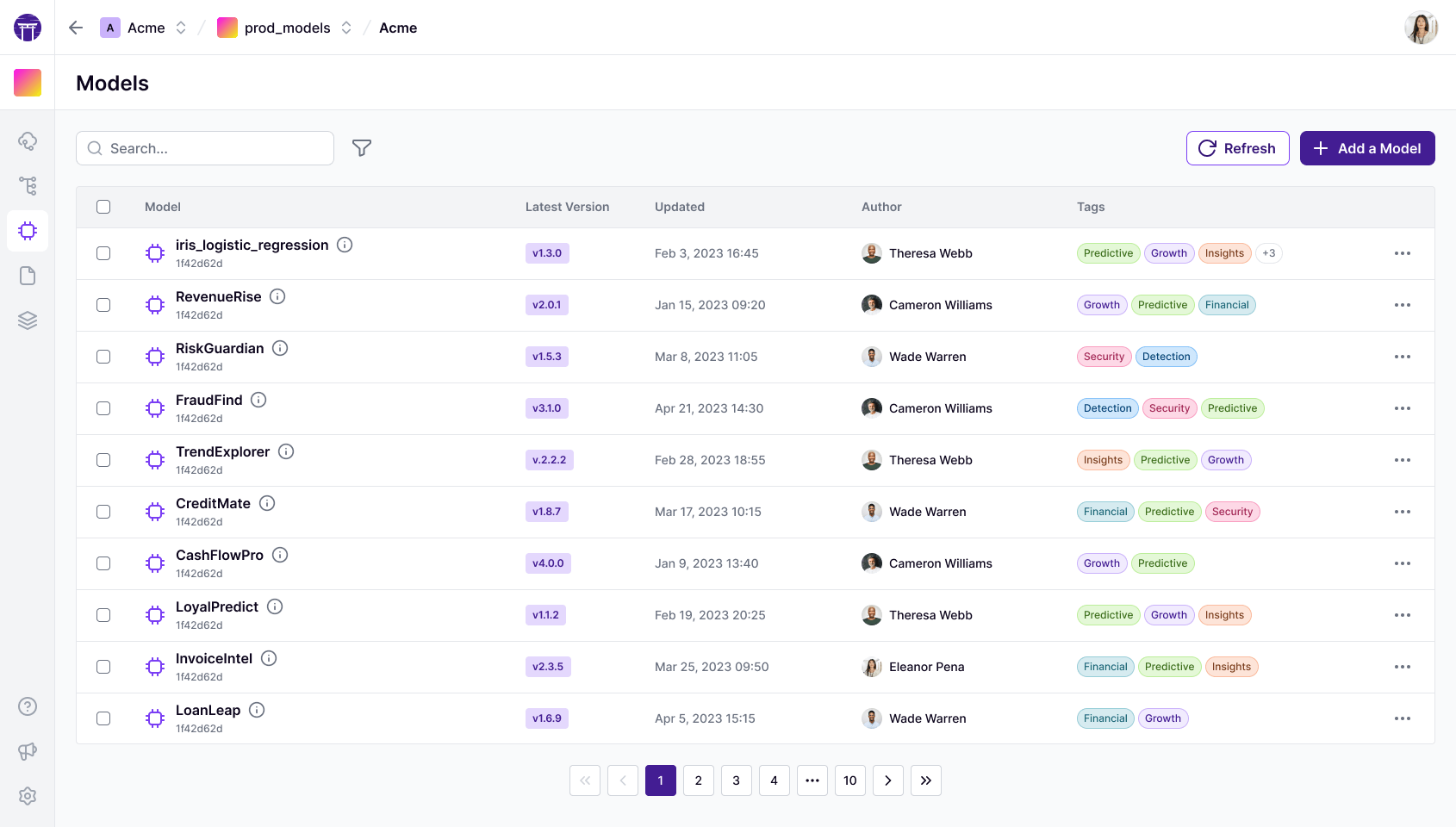
Speed
From Idea to Production at Warp Speed
Accelerate your ML workflow with seamless local-to-cloud transitions and smart caching
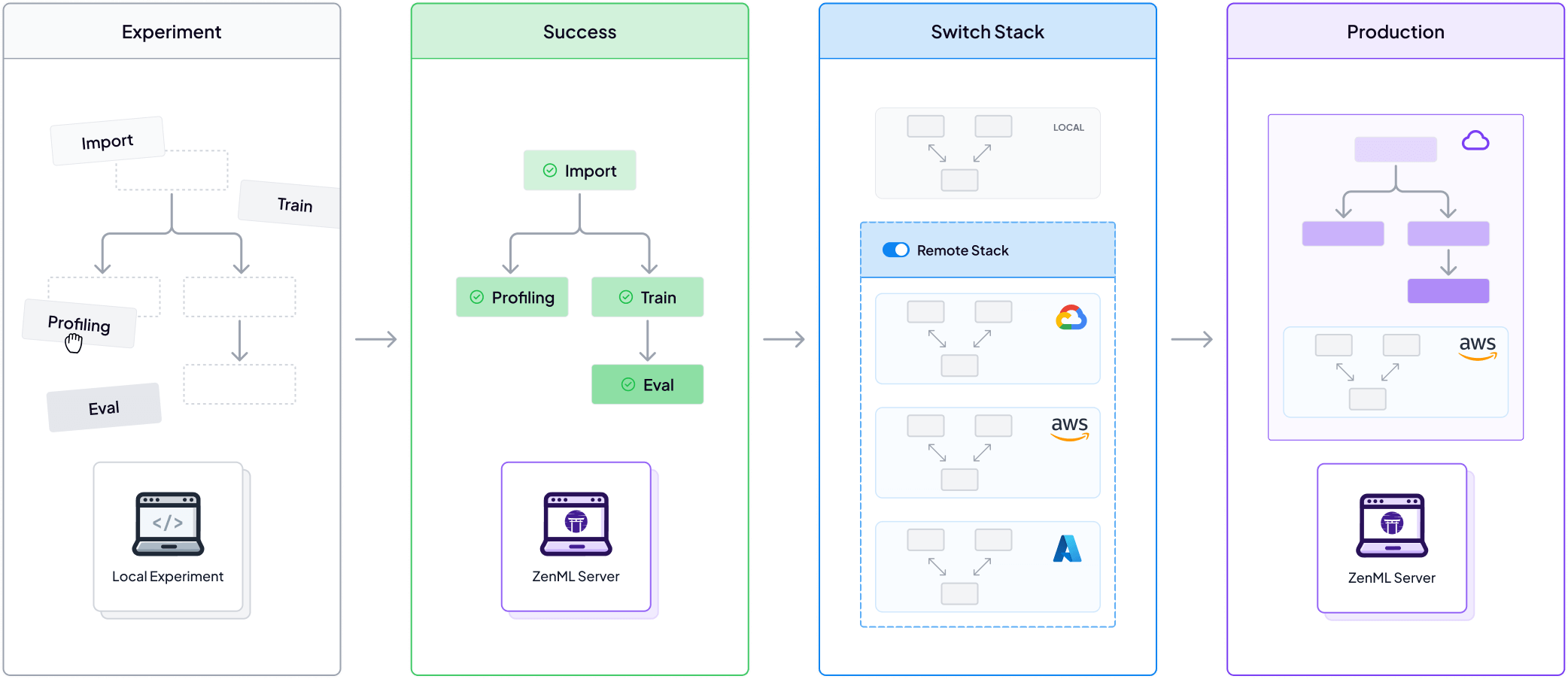
From Jupyter to the Cloud
Elevate your ML workflows from local experiments to production-grade deployments.
- Frictionless transition between development and production environments.
- Automated containerization ensures reproducibility across infrastructures.
- Schedule workflows seamlessly.
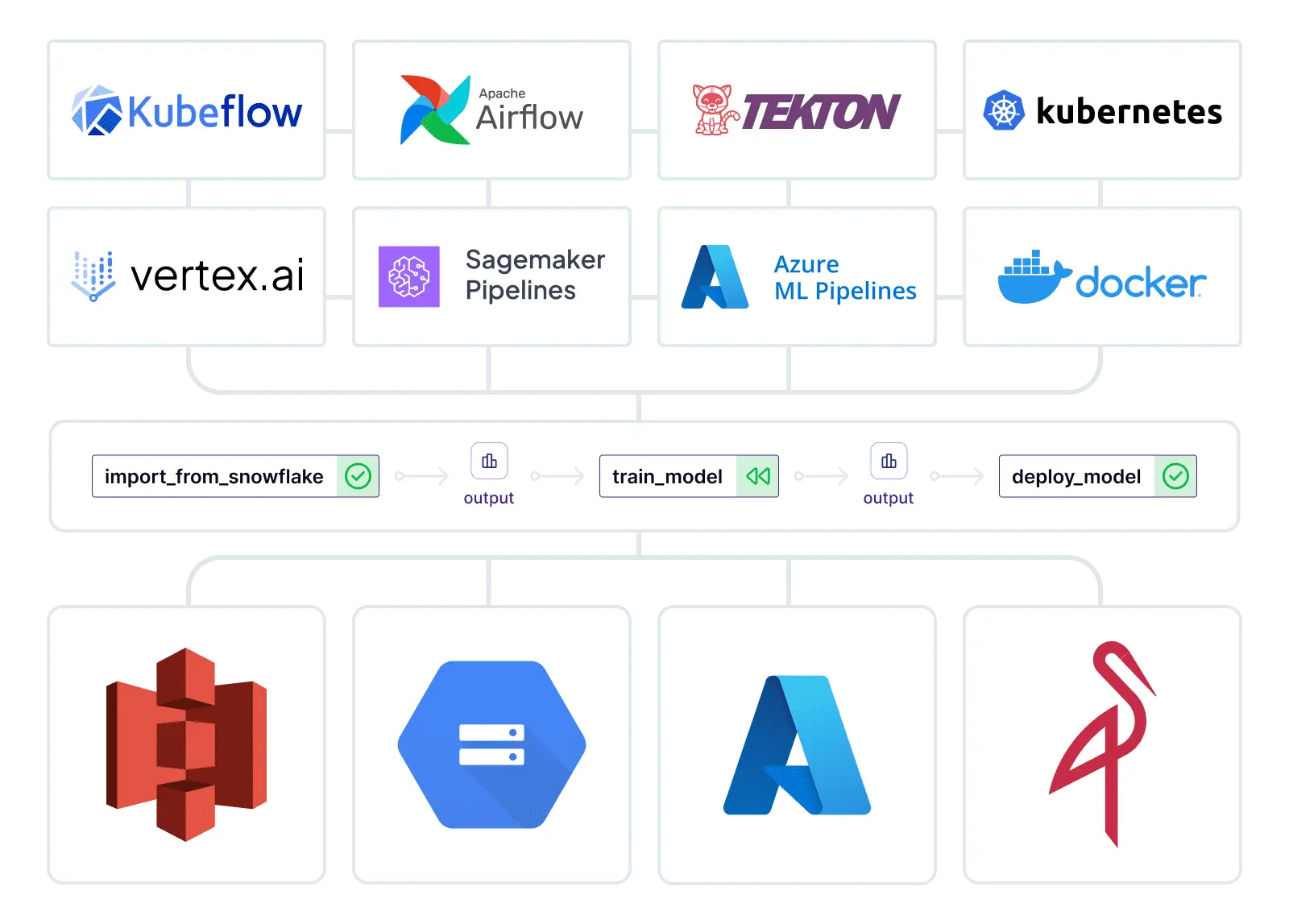
Simply Add Decorators To Existing code
Write once, run anywhere. Harness the power of decorators to transform your existing codebase.
- Simple Pythonic SDK that just works.
- Write once, deploy anywhere: from laptops to Kubernetes clusters.
- Accelerate team-wide adoption of MLOps best practices.
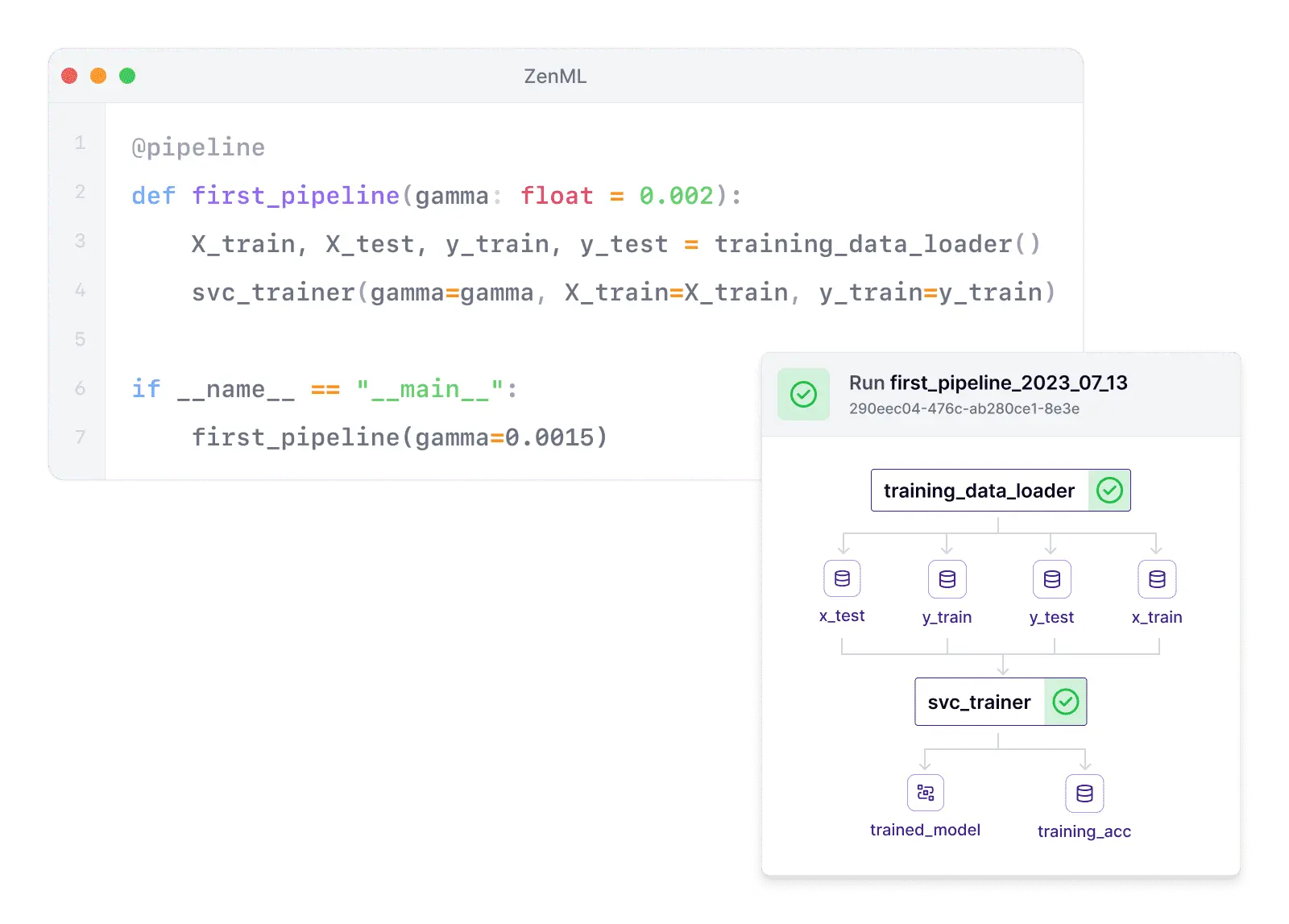
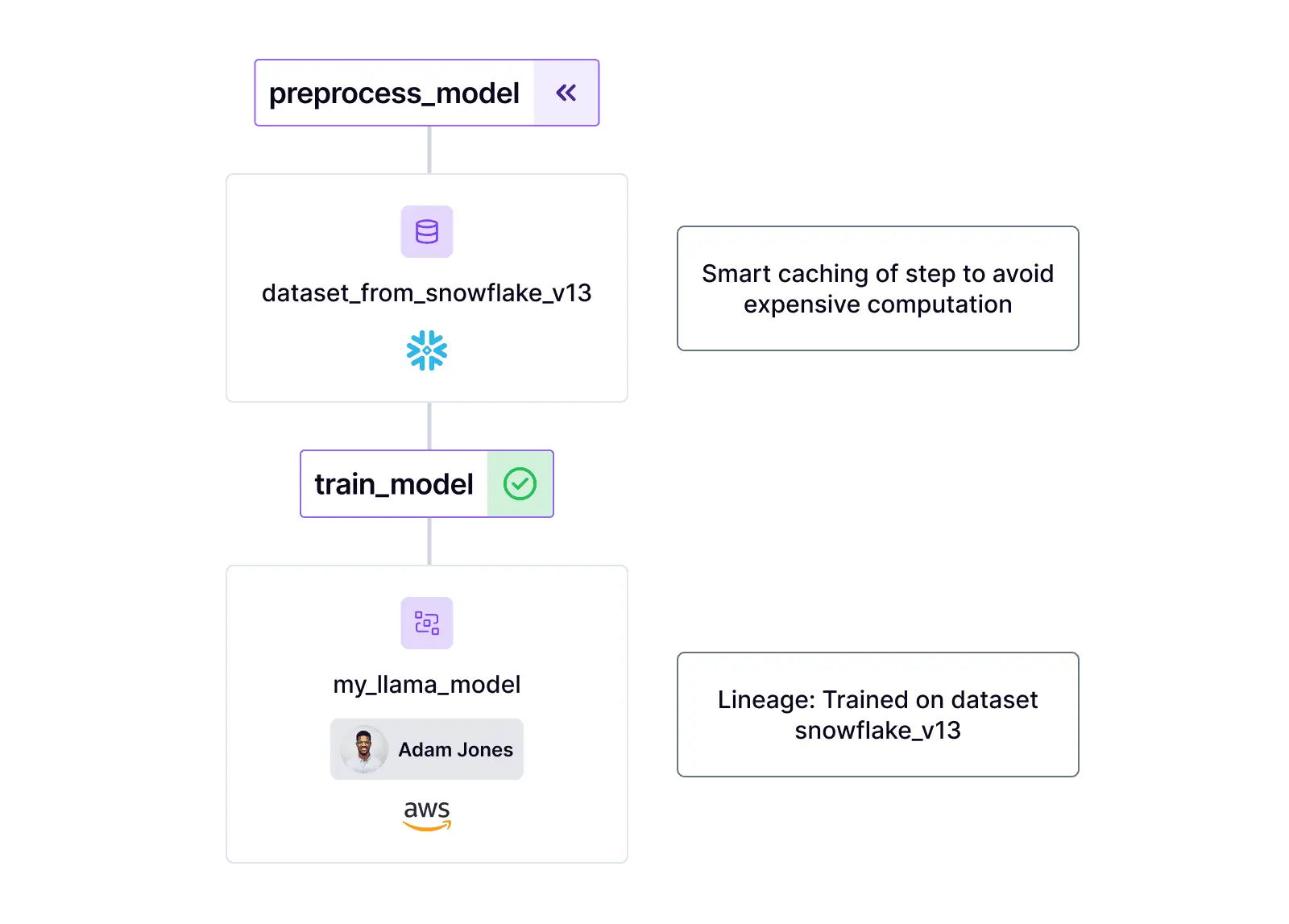
Smart caching for faster iterations
Maximize efficiency with smart, automated caching mechanisms.
- Slash compute costs across your organization.
- Blazing fast development speed with automated data versioning.
- Eliminate idle GPU time, optimizing resource utilization.

After a benchmark on several solutions, we choose ZenML for its stack flexibility and its incremental process. We started from small local pipelines and gradually created more complex production ones. It was very easy to adopt.
Clément Depraz
Data Scientist at Brevo
Ship agents you can prove, and pipelines you can trust.
- Open-source foundation, no vendor lock-in
- Works with any infrastructure
- Upgrade to managed Pro features