On this page
When teams talk about “shipping forecasting,” they often mean they’ve trained a single model that produced a decent chart in a notebook. That’s not forecasting in production.
Forecasting in production means answering harder questions:
- Which model version is in prod?
- Why did the forecast shift this week?
- Can we retrain weekly without rewriting half the pipeline?
- How do we run daily inference jobs without leaking experiments into production?
That’s why I built FloraCast: an opinionated, production-ready template for time-series forecasting using ZenML and Darts. It’s less about the model (we default to TFT, but you could swap it out) and more about the platform that wraps around it: YAML-driven experiments, real versioning, stage promotion, batch inference, and scheduled retrains.
Repo: github.com/zenml-io/zenml-projects/tree/main/floracast
The platform mindset
Models drift, data shifts. Leadership will ask “what’s in production?” and “why are we predicting less demand for next month?” If your workflow is a single notebook, you can’t answer that.
Mature orgs design for:
- Experiments you can reproduce and compare.
- Lineage of parameters, data, and artifacts.
- Promotion and rollback across environments — “promotion” means deciding when a newly trained model is good enough to replace the one currently serving. If it passes evaluation, it gets promoted to staging or production; if not, the older model stays. Rollback means you can demote a model if issues show up later.
- Schedules for daily inference and weekly retraining.
FloraCast encodes these concerns in code + YAML so you can get there on day one.
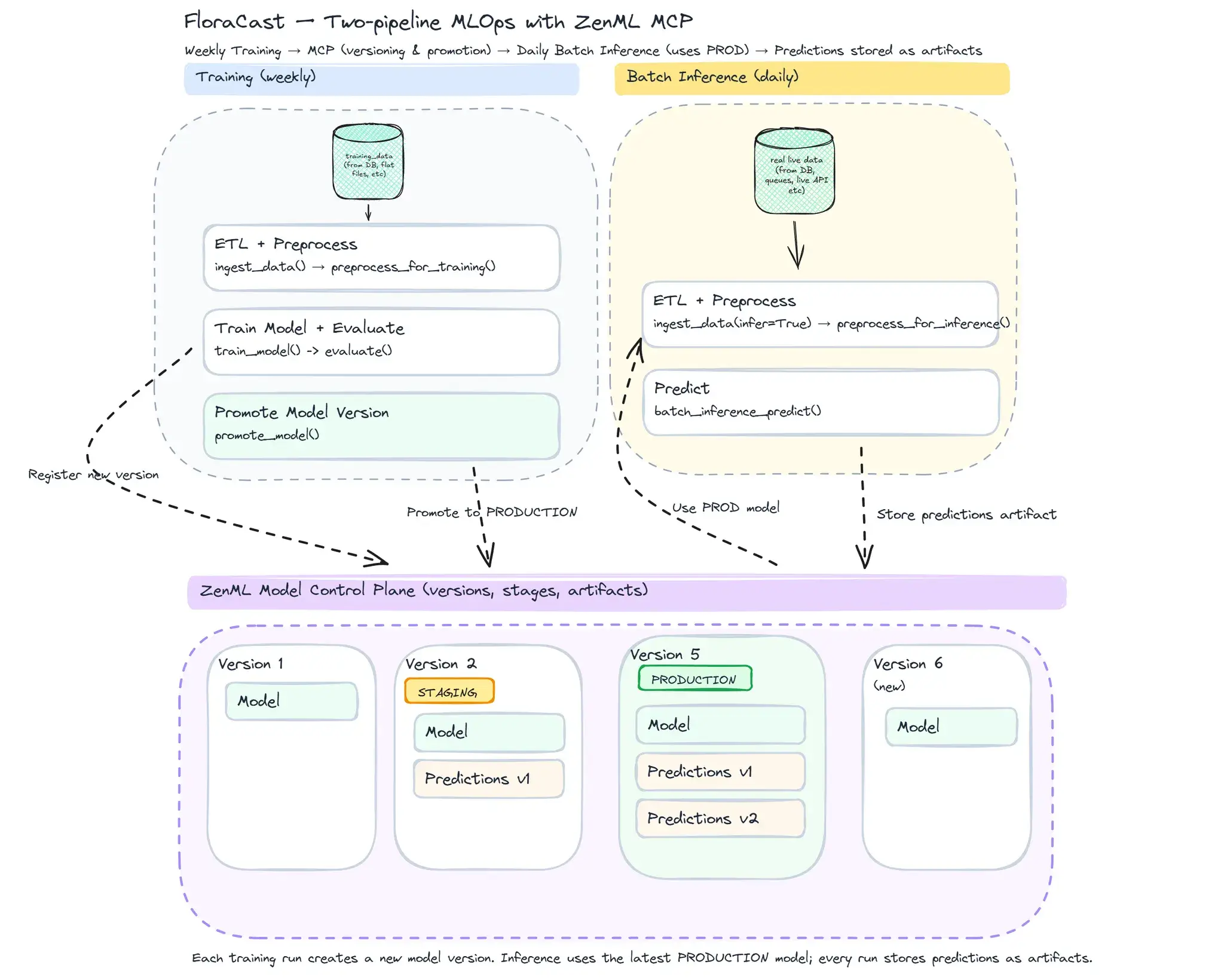
Setting up an MLOps flywheel with two pipelines
📣 We’ve seen similar patterns in other forecasting projects in ZenML, such as Retail Forecast. That project focuses on predicting retail sales across stores using simpler models (like Prophet and ARIMA) to show how ZenML pipelines structure experimentation. FloraCast builds on the same MLOps principles but takes it further with TFT, model promotion via MCP, and scheduled inference — a more production-ready pattern.
The repo gives you two pipelines that cover the day-2 realities:
1. Training (pipelines/train_forecast_pipeline.py)
ingest → preprocess → train → evaluate → promote
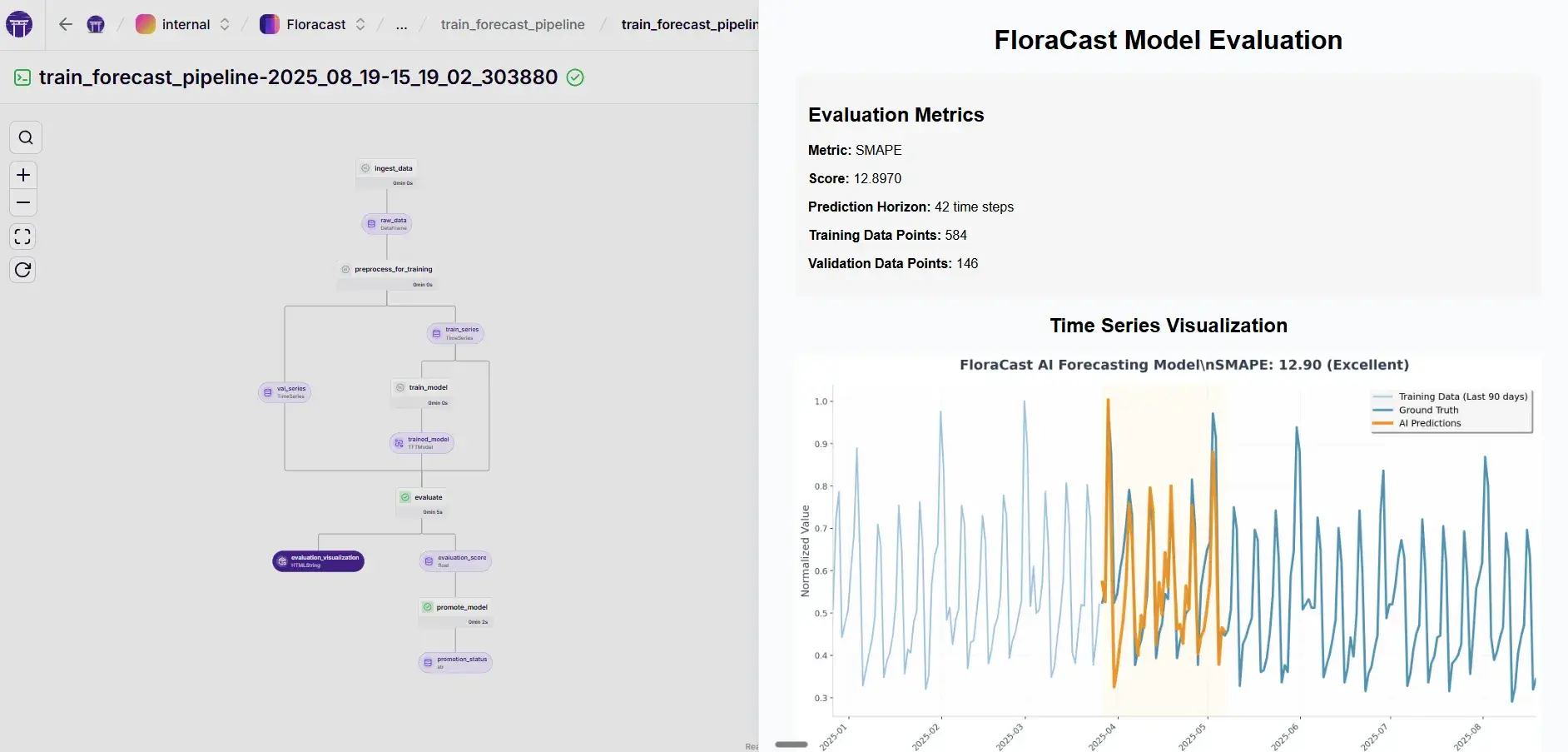
steps/train.py: trains a Darts Temporal Fusion Transformer (TFT) with YAML-driven hyperparams.steps/evaluate.py: computes **SMAPE** and logs an HTML visualization artifact so you can actually see how predictions track ground truth.steps/promote.py: compares the score to the current production model and promotes the new one if it’s better (you can also do this manually)
2. Batch inference (pipelines/batch_inference_pipeline.py)
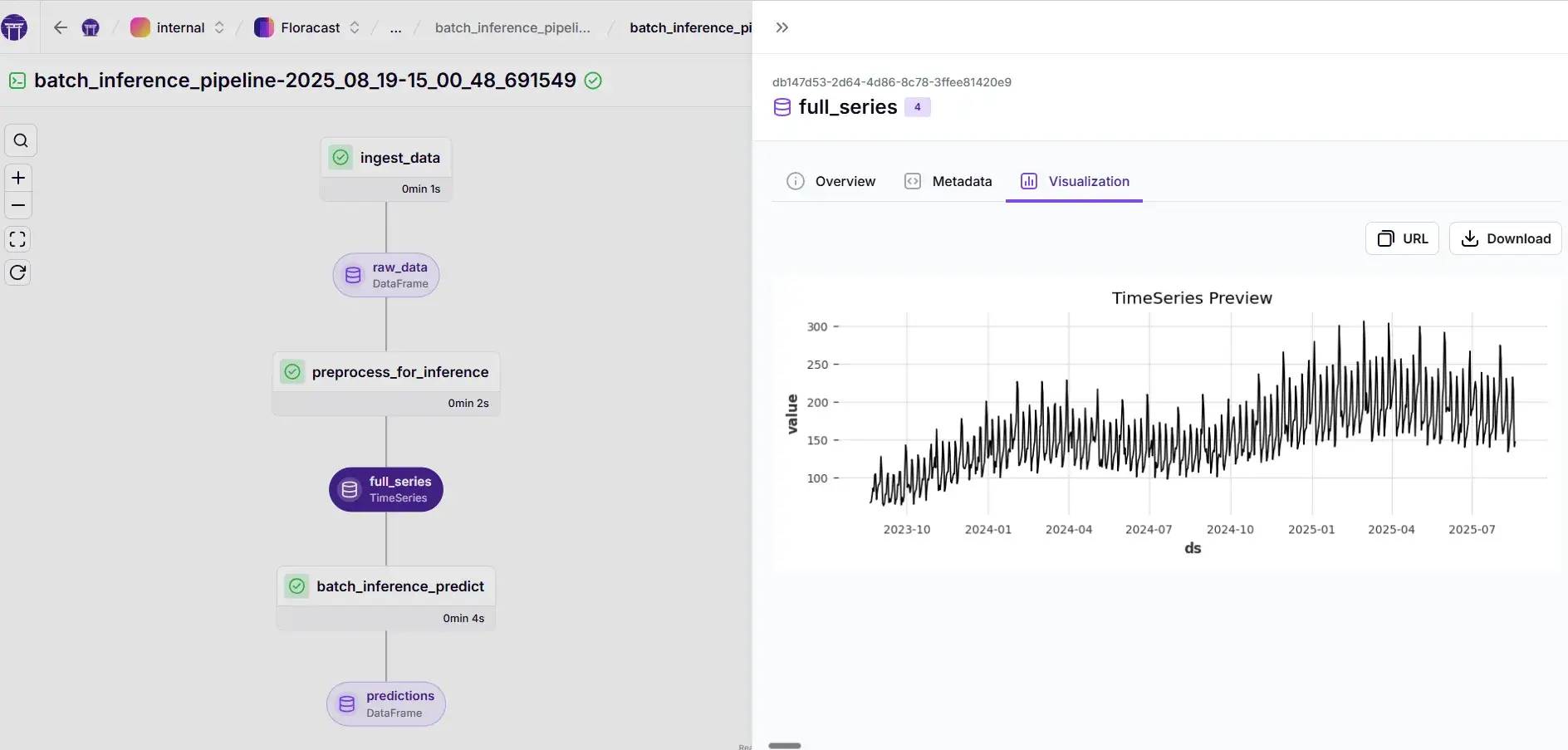
ingest → preprocess → predict using the active production model.
steps/batch_infer.py: loads the production model from the ZenML Model Control Plane (MCP) and produces a multi-step forecast DataFrame.
This separation is key: training is about experiments, inference is about stability.
ℹ️ You can see how ZenML’s artifact visualization comes in handy here. By creating custom materializers for Dart Timeseries, we’re able to plot out our timeseries and visualize them in the DAG. This pattern is very powerful and very useful while experimenting.
What I really like about this setup is the clean separation of concerns. The training pipeline’s only job is to produce a model and register it — nothing else. In fact, you could have one developer own training while another focuses entirely on inference, which in real life is often more complex: pushing results into a warehouse, publishing to a queue, or posting forecasts to an API. That division of labor makes collaboration across teams much easier, while still giving you a single control plane to observe everything end-to-end.
🎥 Watch the walkthrough
Sometimes code speaks louder than words. I recorded a walkthrough where I open up the FloraCast repo, explain the structure, and show how training, inference, and the Model Control Plane all fit together.
💡 Side note: configs for reproducibility
ZenML lets you wire parameters in two ways: directly in code (inline) or via external YAML configs.
In FloraCast, we lean on configs because they make retrains and comparisons reproducible — a small YAML diff becomes a new versioned run.
For example, tweaking TFT hyperparams doesn’t require touching pipeline code:
steps:
train_model:
parameters:
hidden_size: 256
n_epochs: 100This isn’t about forcing YAML on data scientists. If you’re iterating quickly, code-first is fine. But once you care about scheduled retrains, CI/CD, or auditing past experiments, configs make the workflow cleaner and easier to automate.
Versioning and promotion with MCP
ZenML’s Model Control Plane is the backbone here. Every training run registers a model version with its metrics and artifacts. You can resolve models by:
- Version number
- Stage alias (e.g.
production,staging)
In configs/inference.yaml, we pin version: production. So daily inference always uses the currently promoted model. No more “I think the last run was deployed.”
Promotion logic lives in steps/promote.py: if the new model beats the current prod score, it’s promoted automatically. If not, the old one stays.
This gives you traceability: what’s in prod, how it got there, and which artifacts back it up.
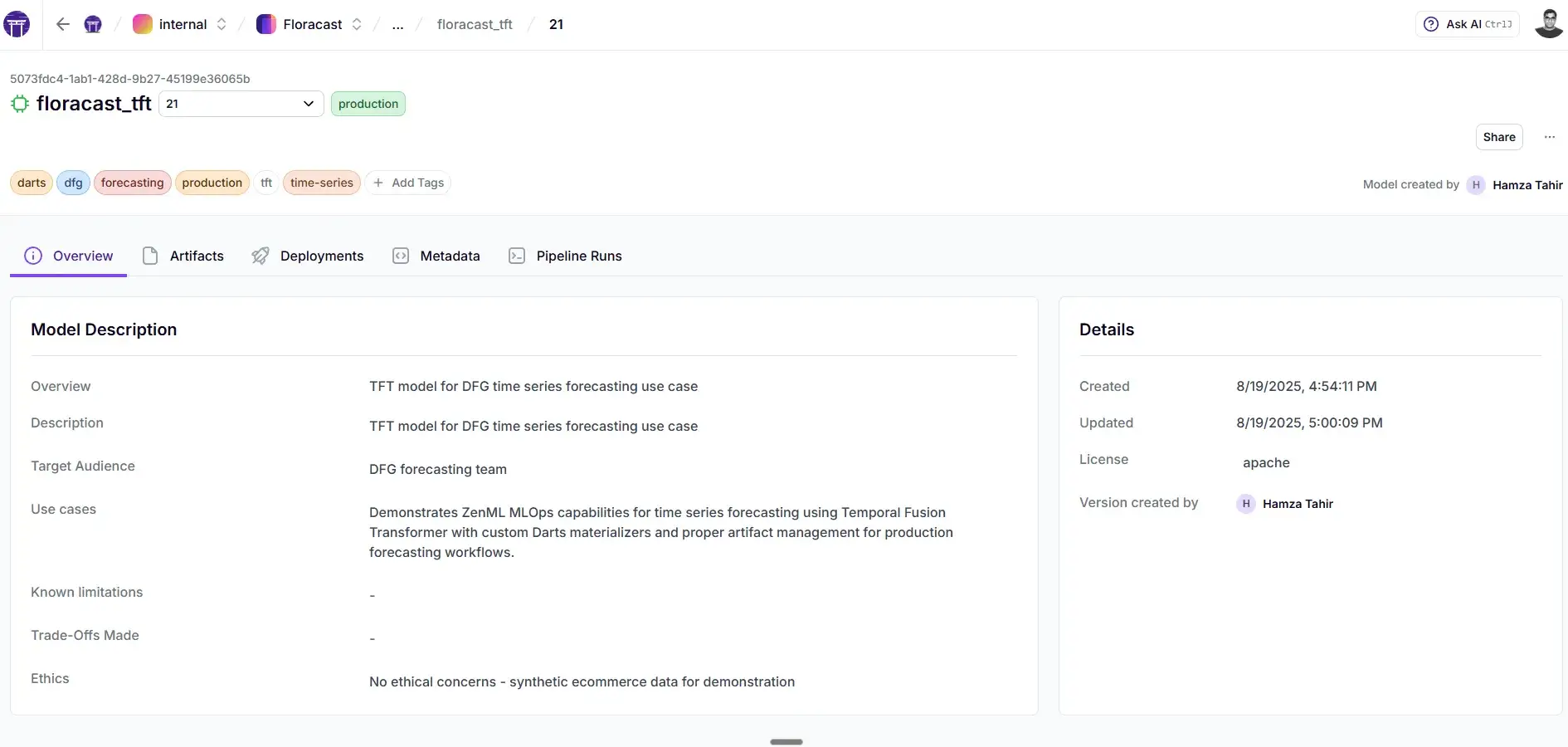
Every model version gets tracked with its stage (like staging or production), and every inference run produces artifacts stored here.
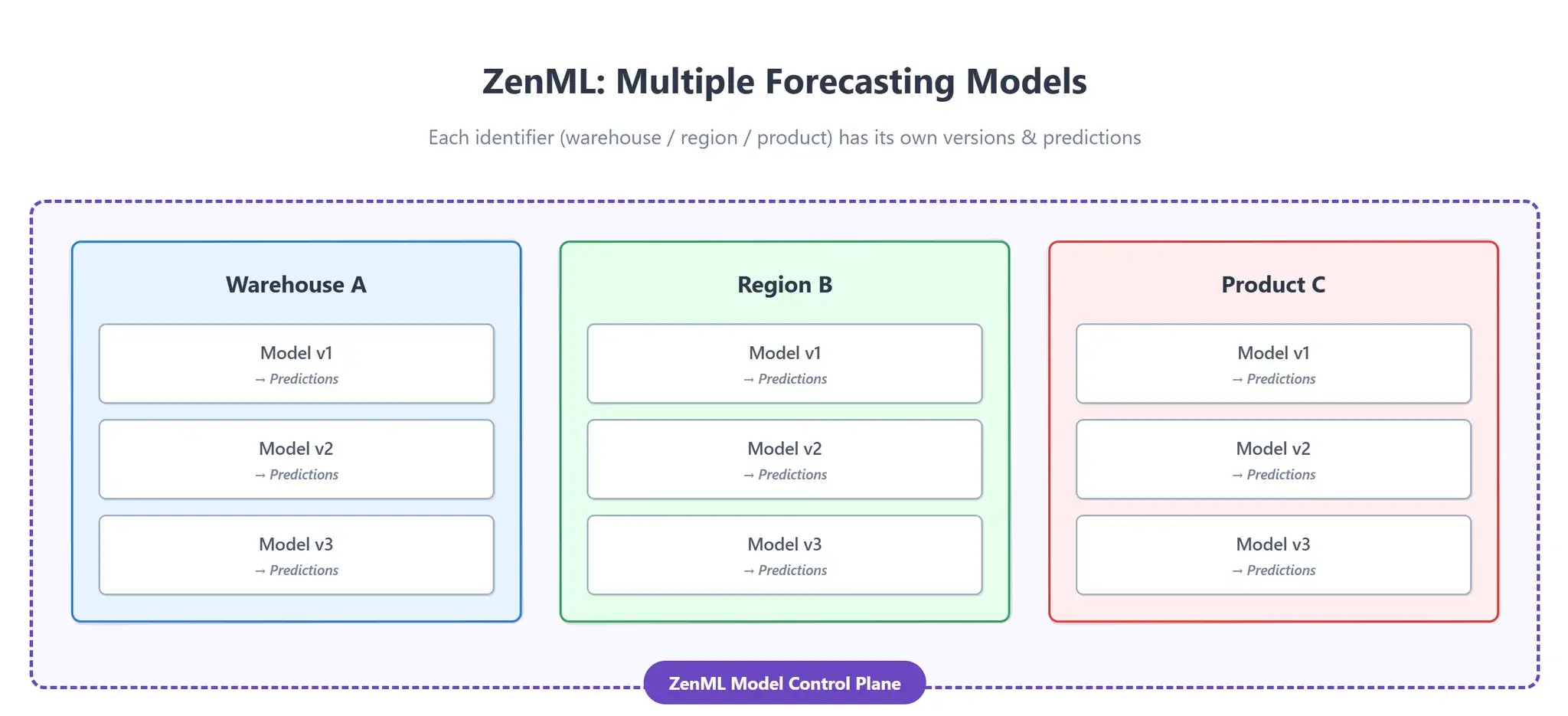
And here’s the really powerful part: if you want multiple forecasting models — say per warehouse, per region, or per product — you just create separate ZenML models with different identifiers.
Each one will have its own versions and predictions neatly tracked in ZenML. No chaos, no overwriting, everything versioned and auditable.
From dev to prod, and staying fresh
In real deployments you need two things: a safe way to promote models, and a way to keep them fresh without manual effort.
Stages and environments
With ZenML’s Model Control Plane you don’t just have “the latest run.” You have explicit stages like staging and production. That means you can train a model in your dev stack, promote it to staging for smoke tests, and only then escalate it to production. Inference configs cleanly reference different stages depending on where they’re running. This prevents accidental rollouts and makes it clear what’s actually in prod.
Keeping forecasts fresh
Forecasts go stale quickly. If someone has to rerun a notebook every Monday morning, trust in the system dies fast. With pipelines + schedules you can keep things current: inference runs daily to generate fresh predictions, retraining runs weekly to refresh the production model. Once configured, this happens automatically — no babysitting required.
Closing thoughts
FloraCast isn’t about the TFT model. It’s about encoding the things mature ML orgs build around forecasting:
- Separation of training and inference → different concerns, different owners, but unified visibility.
- Stages and environments → safe rollouts from dev → staging → production.
- Automation → daily forecasts and regular retrains without humans in the loop.
- Versioning and lineage → always know what’s in production, why it’s there, and what came before.
If you’re stuck in notebooks and want to move towards a platform, not just a model, this repo is a good starting point. Clone it, adapt it, wire it to your data sources, and you’ll be a lot closer to answering the hard questions that come up when forecasting actually matters.
👉 To try it out, head over to the FloraCast README — it has everything you need to run the training and inference pipelines yourself.