Creating a Unified AI Platform: How JetBrains Centralizes ML on Kubernetes with ZenML
A phased migration from Kubeflow and Prefect OSS to a single platform now managing a 170% month‑over‑month execution growth and complex 3,000+ node agentic pipelines.
🚀 At a Glance: The JetBrains Transformation
- The Challenge: A ~200‑person AI organization—with ~100 hands‑on ML practitioners—was fragmented across multiple systems, creating a high maintenance burden and blocking code reuse.
- The Solution: JetBrains adopted ZenML as its single, Kubernetes-native MLOps platform, enabling diverse teams to unify on one infrastructure.
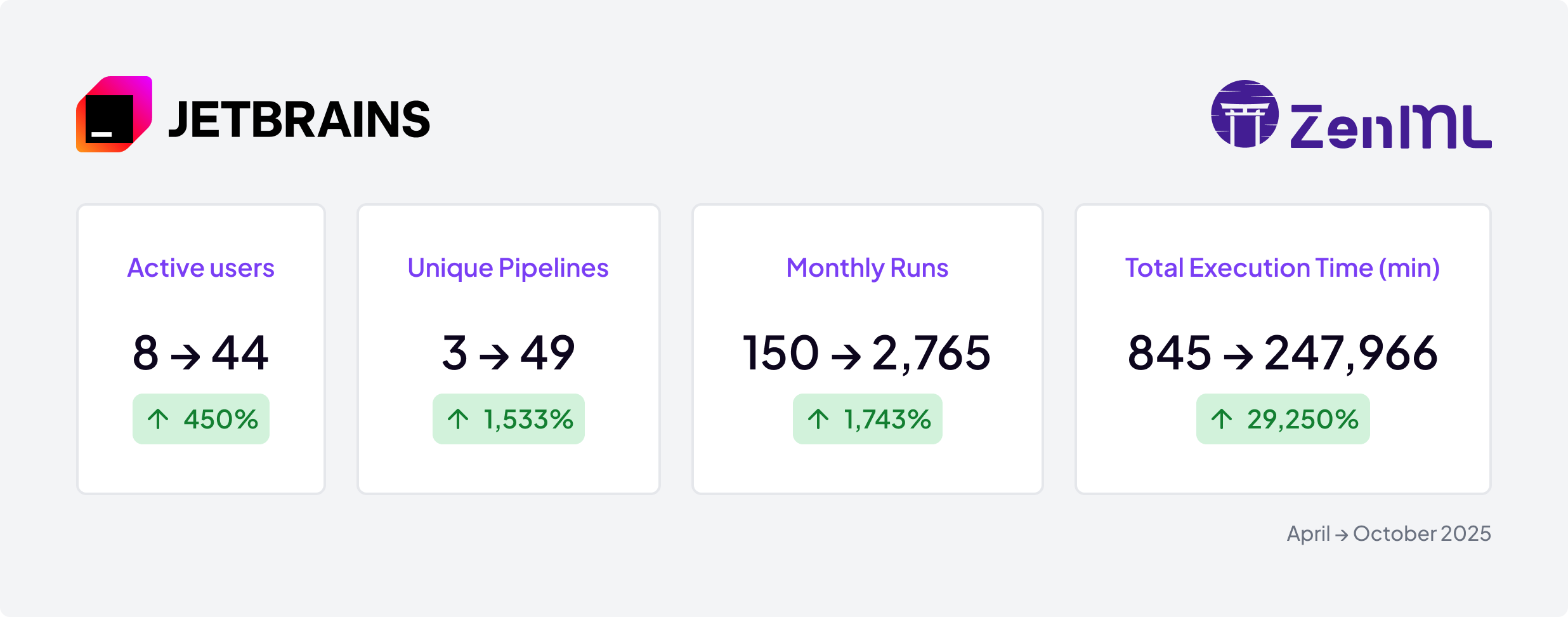
- The Impact: Grew from 8 to 44 active users (450%) in 6 months. ZenML now efficiently manages a 170% month‑over‑month increase in total execution time (Sep→Oct 2025), runs complex 3,000+ node agentic pipelines, and has completely replaced Kubeflow for key workloads—starting with the flagship pipeline—while consolidating work previously split between Kubeflow and Prefect OSS.
"ZenML has helped us to boost the collaboration and best practices exchange, while keeping the infrastructure burden as low as possible for the MLEs."

📊 Key Metrics of Change
Note: The +170% figure refers to the month‑over‑month change in total execution time from September to October 2025.
The Challenge: When Enterprise Scale Creates Chaos
The Orchestrator Sprawl
Before standardizing, JetBrains' MLOps team was managing a fragmented and costly collection of tools. This was not only inefficient but was creating a significant and growing maintenance burden at the same time. Different teams used different solutions for similar problems—Prefect OSS for classical ML and lightweight training, Kubeflow for LLM evaluation and data prep, and raw Kubernetes scripts for LLM training—which created a high-overhead environment where infrastructure support was fractured and best practices were impossible to enforce.
The Collaboration Crisis
This technical fragmentation created deep organizational silos. With a ~200‑person AI organization—and around 100 hands‑on ML practitioners—there was no unified platform to track models from training to evaluation, making lineage and reproducibility a manual, detective‑like process. As a result, code reuse was nearly impossible, and valuable time was lost as teams independently solved the same problems, unable to build on each other's work.
The Department Dilemma
Initially, the MLOps team’s mandate was to support multiple teams within a single department. Even within that boundary, teams followed entirely different rules and architectural patterns—from monorepos to dedicated repositories—making a one‑size‑fits‑all solution unrealistic. This diversity of environments and requirements made a one-size-fits-all solution impossible and which meant the current model was fundamentally unsustainable.
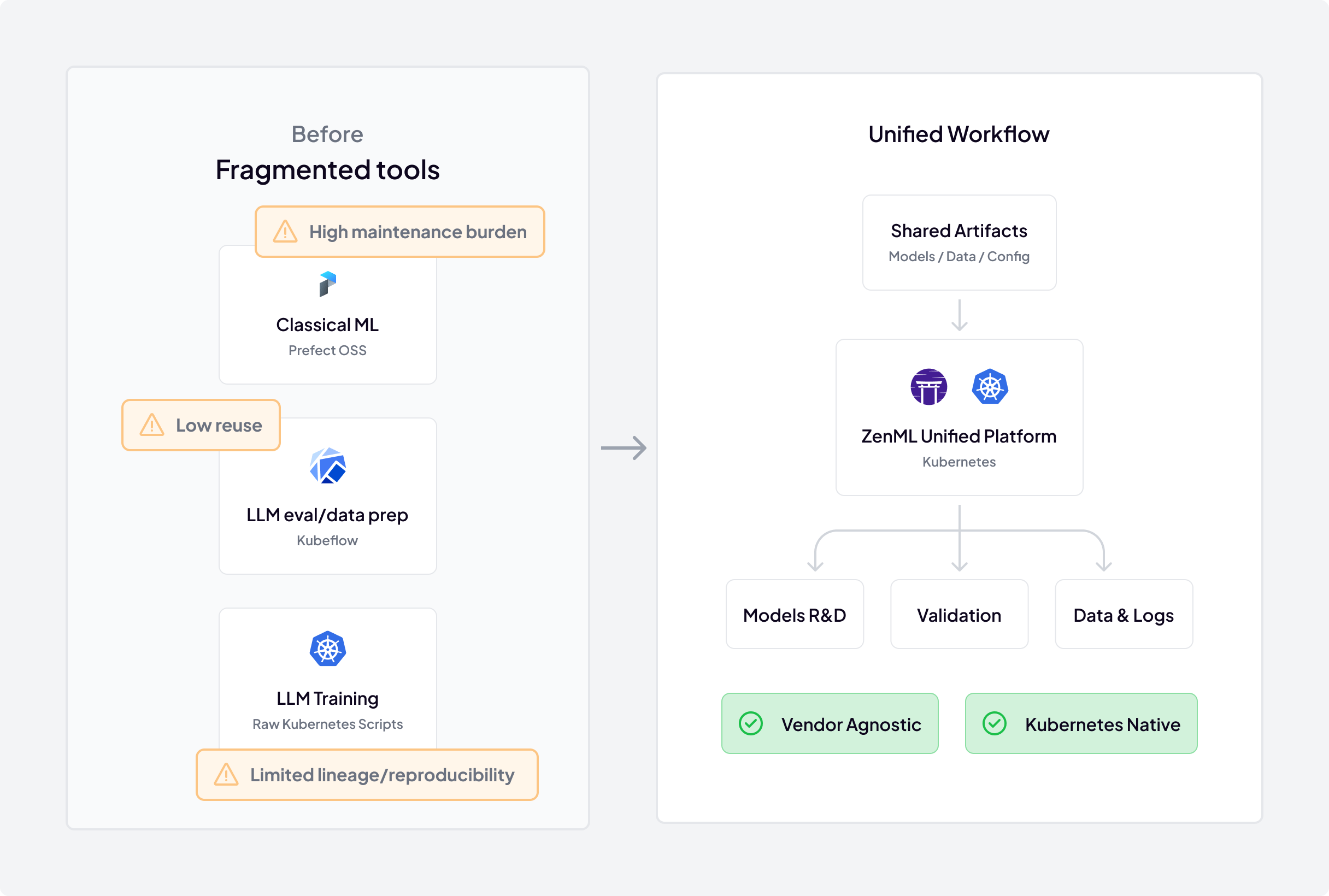
The Solution: Develop Locally, Scale on Kubernetes
Why ZenML Won the Evaluation
JetBrains ran a market-wide evaluation to find one platform that satisfied both advanced and casual users without increasing infra overhead. ZenML stood out on developer experience and platform fundamentals:
- Simple, Pythonic SDK and ease of use: Teams define pipelines as plain Python with minimal boilerplate and sensible defaults. This made it straightforward to move from scripts/notebooks and previously environment‑locked pipes to reproducible pipelines and accelerated onboarding.
- Proper artifact versioning and lineage: Outputs are versioned by default and lineage is tracked across steps and runs, enabling reliable reproducibility, side‑by‑side comparisons, and auditability. Shared artifacts also make reuse across teams practical.
- Run locally, scale on Kubernetes unchanged: The same code runs on a laptop for fast iteration and on internal GKE and external GPU Kubernetes clusters for scale. Local/inline runtimes tighten the dev loop and reduce cold‑start overhead.
- Incremental adoption with pragmatic migration: Teams migrated pipeline‑by‑pipeline—no big‑bang rewrite. Portions of existing training/eval code could often be wrapped as steps with some refactoring, while tightly coupled pipelines required deeper changes. Existing data stores and surrounding services were reused where feasible.
- Kubernetes‑first architecture: Native Kubernetes integration fits their internal and external clusters, supporting GPU workloads, namespace isolation, secrets management, and enterprise networking patterns.
- Vendor‑agnostic (no cloud lock‑in): Works across clouds and on‑prem, aligning with JetBrains’ strategy to avoid provider‑specific MLOps stacks.
- Cost‑effective enterprise footprint: Consolidates multiple orchestrators and homegrown glue into one platform, reducing maintenance burden while improving governance and observability.
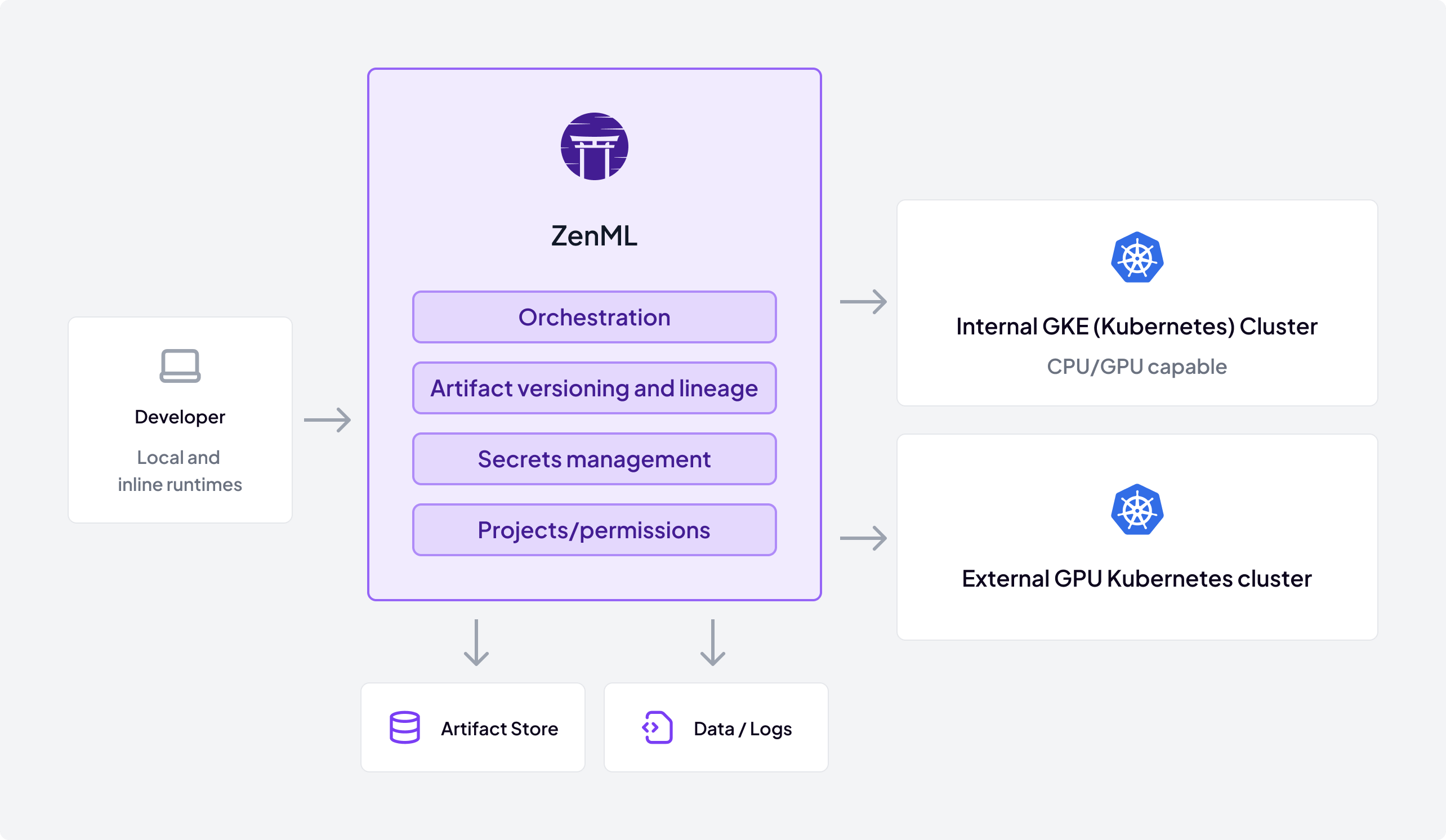
The Phased Implementation Journey
Implementation was a phased and strategic journey, not a "big bang" migration. After a successful proof-of-concept in early 2025, the JetBrains teams with support from the MLOps team began methodically migrating workloads and implementing new complex pipelines for agent use-cases and beyond.
They strategically targeted their most complex and widely-used "flagman" (flagship) pipeline from Kubeflow first. By proving the platform's value on this critical, high-visibility workload, they established best practices and built internal confidence. This strategy was a clear success, paving the way for wider adoption that grew from just 8 monthly active users in April to 44 by October.
An Architecture for Enterprise Scale
The team now manages a highly sophisticated architecture on ZenML, tailored to their enterprise scale.
- Logical Workload Separation: They organize work into distinct ZenML projects (e.g., Models R&D, Validation, Data/Logs) to cleanly manage the lifecycle and permissions for different teams.
- Advanced Orchestration: More advanced teams are able to work with more complex architectures to dynamically orchestrate complex GPU workloads.
- Proven for AI: The platform has proven it can handle this complexity, successfully running massive agentic AI pipelines with over 3,000 nodes in a single graph and multiple such graphs at the same time. One of these is used for evaluating their coding agent and runs popular agent benchmarks against their system to get a sense of how well it performs.
The Results: Compound Growth and Stability
The successful migration and internal development efforts have translated into measurable, compounding gains for JetBrains. The platform's stability and feature set have become a powerful draw for internal teams.
Explosive and Organic Adoption
The strongest proof of success has been the platform's rapid, organic adoption following internal advocacy. In a single month (September to October 2025), the number of monthly active users grew by 63%, driven by word-of-mouth and visible team successes. Concretely, unique monthly active users grew from 27 to 44 between September and October 2025 (+63% month‑over‑month), as additional teams started running real workloads. This demand is widespread, with a planned internal workshop on ML workflows attracting over 150 invites from across the organization, signaling massive interest in the new, standardized approach.
Technical and Migration Wins
With a unified platform, JetBrains has unlocked significant technical victories. The MLOps team is successfully migrating complex workloads off of Kubeflow and Prefect OSS, eliminating a major maintenance burden and unifying their infrastructure. New platform capabilities like inline runtimes shorten feedback loops for simple pipelines by skipping per‑step container cold starts; the orchestrator still initializes as usual. Combined with completed stability improvements, this has shifted internal perception from early “low‑maturity” concerns to a stable, production‑grade platform with good standing internally.

Looking Forward: A Strategic Partnership for the Next Wave of AI
The collaboration between JetBrains and ZenML has evolved from addressing initial infrastructure challenges to enabling future innovation. With a stable foundation, the focus is now on scaling the platform's impact across the entire company.
Scaling Knowledge
The partnership now includes deep collaboration on scaling best practices. Jointly-planned workshops for JetBrains' 150-person ML organization are designed to transfer knowledge efficiently, ensuring that teams can not only use the platform but also leverage its most advanced capabilities for complex AI workloads.
Scaling Adoption
ZenML is now the standard default platform for new ML projects at JetBrains, reducing the overhead of selecting and configuring disparate frameworks. Adoption and momentum continues to expand, with a large team currently onboarding. This promises even more significant growth in the coming months.
Scaling Innovation
With a stable and scalable foundation, the partnership is now focused on unlocking the next frontier of innovation. The MLOps team is no longer just managing complexity; they’re enabling simplicity at scale. The unified platform gives them the capacity to explore and productionize sophisticated agentic AI workloads and advanced model architectures, positioning JetBrains to stay at the vanguard of AI development.
Unify Your ML and LLM Workflows
- Open-source foundation, no vendor lock-in
- Works with any infrastructure
- Upgrade to managed Pro features