
On this page
Building LLM-powered retrieval-augmented generation (RAG) systems is easier than ever, but actually trusting those systems—especially in high-stakes domains like healthcare—is another story. Anyone can hook up a vector database and an LLM, but knowing whether your system is actually reliable is a much harder problem.
In this blog, I want to walk you through the Clinical-RAG demo project, where I set out to build a clinical Q&A pipeline and, just as importantly, treated evaluation as a first-class engineering challenge.
You might be wondering why I didn’t just use one of the many LLM evaluation frameworks that already exist—like RAGAS, TruLens, or LangSmith. It’s a fair question. For me, the point of this project wasn’t just to ship an evaluation pipeline, but to really understand how LLM and RAG evaluation works under the hood. I wanted to experience the design tradeoffs and pain points myself. So, I built a custom evaluation framework from scratch, closely aligned to my clinical use case. (That said, I plan to experiment with these frameworks next—thanks to ZenML’s modular pipeline design, it’s easy to swap them in and compare.)
Here’s what I learned about why custom evaluation matters so much for LLMs (especially in RAG pipelines), how I ended up designing a domain-specific, two-layer evaluation framework, and the ways ZenML made it possible to iterate, compare, and track real progress. I’ll also talk about where modern LLM evaluation is headed, and why “plug-and-play” metrics will never be enough if you care about trust.
Why Evaluation Matters More Than Ever ⚠️
When you’re dealing with clinical advice, “it sounds good” is nowhere near good enough. If you’re only testing your system by throwing a few hand-picked questions at it, you have no idea how it will behave in production—or, worse, where it will fail and why.
LLM and RAG systems usually fail in one of two big ways:
- Either the retriever drops the ball and the right info never gets fetched
- Or the LLM stumbles—maybe it hallucinates, maybe it just gets the facts wrong—even when the evidence is right there in front of it
If you want a system you (or any clinician) can actually trust, you have to separate and measure each of those failure points, use metrics that reflect real-world needs, and keep evaluating as you build.
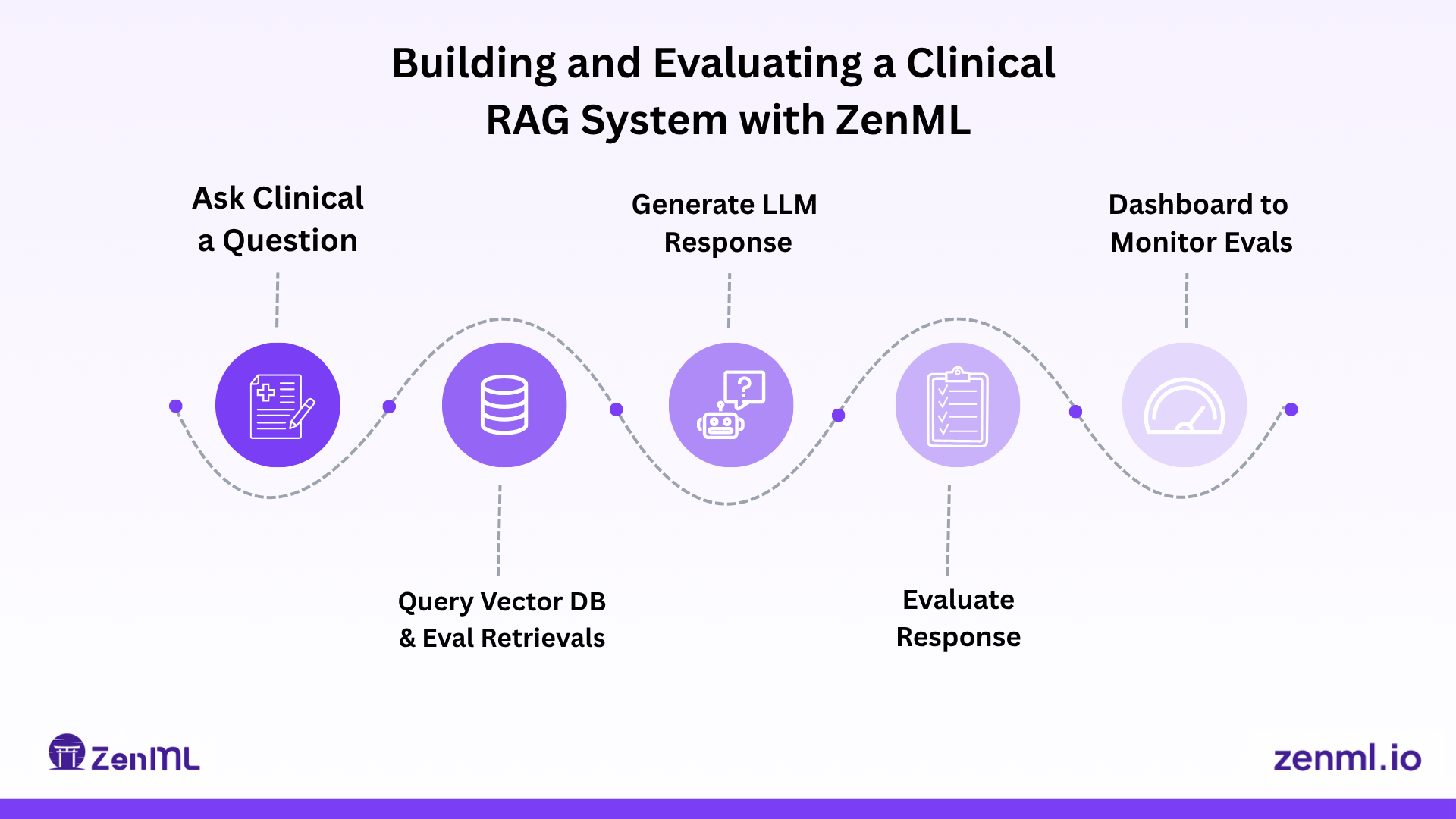
Project Overview: Clinical-RAG Demo 🔬

My demo focused on orthopedic physical therapy. The idea was simple: a clinician asks a question (for example, “How do you assess carpal tunnel syndrome?”) and the system does three things:
- First, it retrieves relevant chunks from a database of clinical documents—things like research papers and guidelines—using semantic search
- Second, it uses an LLM (OpenAI, Anthropic, or a local Llama via LiteLLM) to generate an answer
- And finally, it tries to cite the evidence
I built this stack around Postgres with pgvector for retrieval, sentence-transformers for embeddings, and ZenML to orchestrate the whole pipeline—from ingestion, to retrieval, to generation, and, most importantly, to evaluation.

My Evaluation Framework: Two Layers, Custom Metrics 📊
Retrieval Evaluation: Did I Find the Right Info? 🔎
Before anything else, I needed to know if the retriever was surfacing the information that actually answered the question. To test this, I had an LLM help me create a dataset of real clinical queries, each mapped to a “golden” answer chunk, and manually review the data set as I’m also a domain expert as orthopedic physical therapist. I then ran a few standard retrieval metrics: Hit Rate @ K (Recall@K), Precision @ 1, and Mean Reciprocal Rank (MRR) on the results.
If the retriever failed, the LLM never really had a chance. My first pass showed a Hit Rate@5 of about 40%. That’s not good enough for clinical use, so I dug into the results, tweaked chunking and overlap, tried different embedding models, and logged every change and result in ZenML. That made it easy to see exactly what worked and what didn’t.
Generation Evaluation: Is the Answer Correct, Useful, and Safe? ✅
This is where most LLM demos break down. You can’t just check if the answer looks similar to some reference text—metrics like BLEU or ROUGE fall flat in a domain like medicine. What really matters is factual accuracy, clinical safety, relevance, faithfulness to evidence, and whether the answer is genuinely useful to a practitioner.
So I built a custom, domain-driven rubric inspired by current research (and my own experience as a clinician). The rubric focused on three main areas:
- Clinical Accuracy: Is the medical info correct? Are recommendations appropriate? Is it safe to use in real care?
- Relevance: Does it directly address the question and actually help?
- Evidence Support: Are all claims backed up by the retrieved docs and are citations appropriate?
I used an LLM-as-a-Judge approach. I gave the judge model (sometimes GPT-3.5, GPT-4, or even a local model) the question, the answer, and the supporting evidence. Then I asked it to answer each rubric question with a “Yes” or “No,” and aggregated the results. I also implemented overlap checks to see how much of the answer was grounded in the retrieved evidence, which helped catch hallucinations or unsupported claims.
Handling Judge Model Issues ⚖️
One thing that surprised me: the quality of the judge model really matters. I did not extensively test this but even with my small number of tests I noticed a small Llama judge often scored the same answer much lower than GPT-3.5 did. There’s bias, inconsistency, and there was even a bit of self-criticism when a model evaluates its own output. My recommendation is to use the strongest judge you can, but always sanity-check results—ideally with an expert human on a sample.
Also, never trust LLMs to output structured formats perfectly. Even with clear instructions, judges sometimes missed rubric items or formatted their output inconsistently. I had to write robust parsers to extract and check the answers—always validate, never just assume the output will be well-formed.
ZenML: The Backbone of My Experimentation 🧪
Without ZenML, this project would have been a mess of notebooks, scripts, and copy-pasted results. ZenML gave me:
- Reproducibility: every run, every setting, every dataset version tracked
- Modularity: I could swap out embedding models, chunk sizes, judge or generator LLMs, all without rewriting pipelines
- Caching: so I didn't waste time recomputing embeddings or retrieval when nothing changed
I could visualize results, compare runs, and always trace back why a setting “got better”—which is critical if you care about reliability or regulation.
ZenML let me treat evaluation as a product requirement, not an afterthought. It turned what could have been an ad hoc mess into something systematic and trustworthy.
Lessons Learned & Best Practices 💡
Here’s what I wish I knew from the start:
- Custom, domain-specific evaluation isn't optional—generic metrics miss what matters most
- Build a rubric that matches your real-world needs and automate what you can, but always keep humans in the loop for tricky or high-stakes cases
- Don't chase end-to-end scores without understanding where you're failing. Separate retrieval from generation
- LLM-as-a-Judge is powerful, but it isn't magic—judge models come with their own biases
- Write parsers that can handle inconsistencies, not just fragile regexes
Most importantly, make evaluation a pipeline, not an event. Build it into your development process from day one. Use tools like ZenML to keep yourself honest and make iteration fast. Track everything—records, dataset versions, and run comparisons—otherwise, you’ll never know if you’re improving or just spinning your wheels.
Where Next? 🚀
Evaluation for LLMs and RAG is still evolving. Next steps might include:
- Pairwise answer comparisons for subjective quality
- Calibration or few-shot learning for judges
- More advanced hallucination checks
- Expanding evaluation sets with adversarial or user-generated queries
I know there are mature frameworks like RAGAS, TruLens, and LangSmith built for LLM evaluation. But for this project, I wanted to understand the entire process at a base level, so I intentionally built my own evaluation framework from scratch. This forced me to confront all the real-world details, tradeoffs, and edge cases—things you don’t always see when you use an out-of-the-box solution. The good news is that with ZenML, it’s easy to swap out parts of my pipeline, so my plan is to start plugging in some of those existing frameworks and see how they compare to what I built myself.
If you want to see the code or go deeper, check out the Clinical-RAG GitHub repo or reach out to me for details. 👨💻
Satya Patel is a software engineer with a background in physical therapy, specializing in building AI-powered applications and cloud infrastructure. Connect with him on LinkedIn.


