On this page
Deploying Huggingface models to AWS Sagemaker endpoints typically only requires a few lines of code. However, there’s a growing demand to not just deploy, but to seamlessly automate the entire flow from training to production with comprehensive lineage tracking. ZenML adeptly fills this niche, providing an end-to-end MLOps solution for Huggingface users wishing to deploy to Sagemaker. Below, we’ll walk through the architecture that ZenML employs to bring a Huggingface model into production with AWS Sagemaker. Of course all of this can be adapted to not just Sagemaker, but any other model deployment service like GCP Vertex or Azure ML Platform
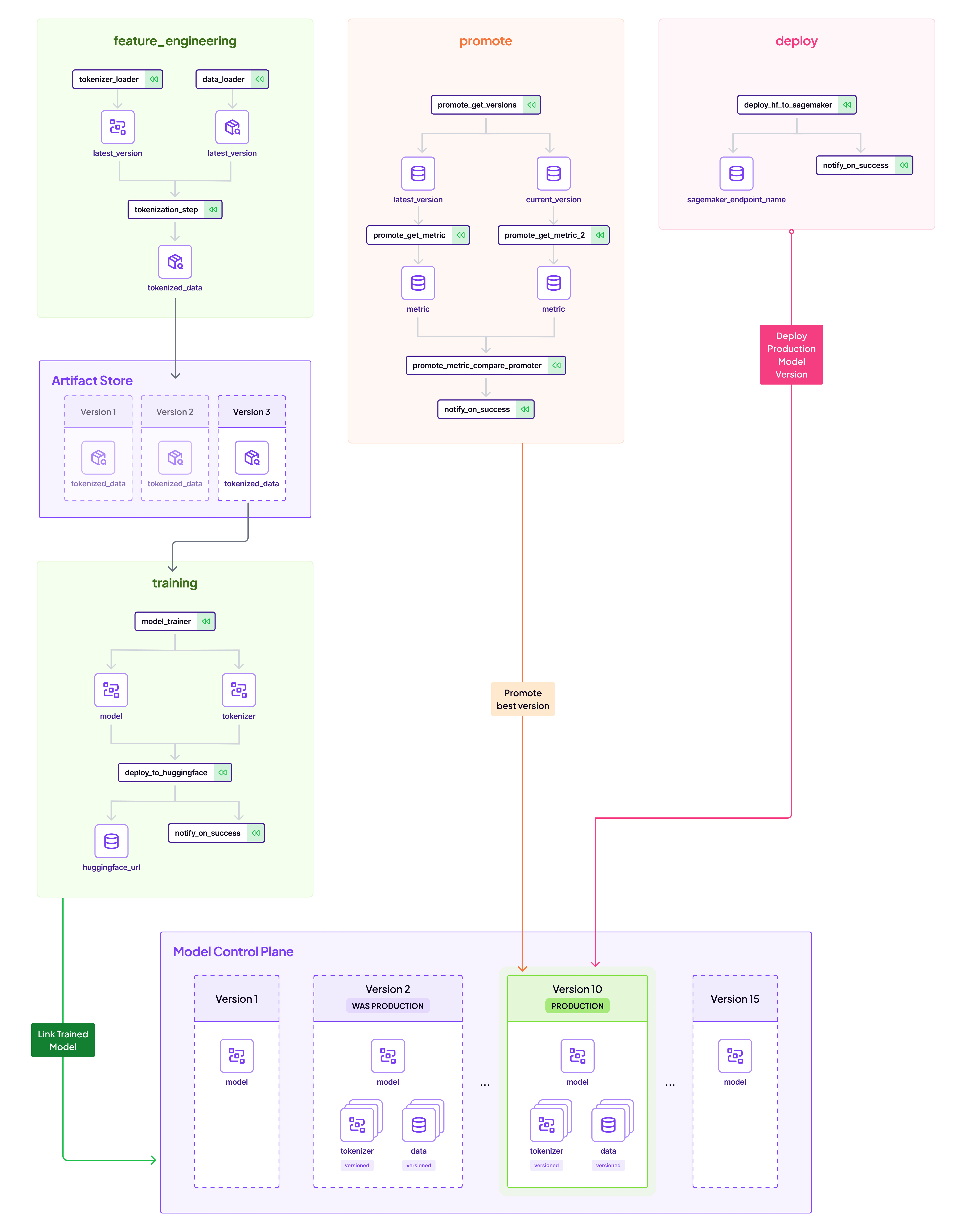
This blog post showcases one way of using ZenML pipelines to achieve this:
- Create and version a dataset in a feature_engineering_pipeline.
- Train/Finetune a BERT-based Sentiment Analysis NLP model and push to Huggingface Hub in a training_pipeline.
- Promote this model to Production by comparing to previous models in a promotion_pipeline.
- Deploy the model at the Production Stage to a AWS Sagemaker endpoint with a deployment_pipeline.
This blog post is accompanied by a YouTube series tutorial and a Github repository. Check them out if you’d like to see it in action with the code!
🍳Breaking it down
👶 Start with feature engineering
Watch the video of this section:
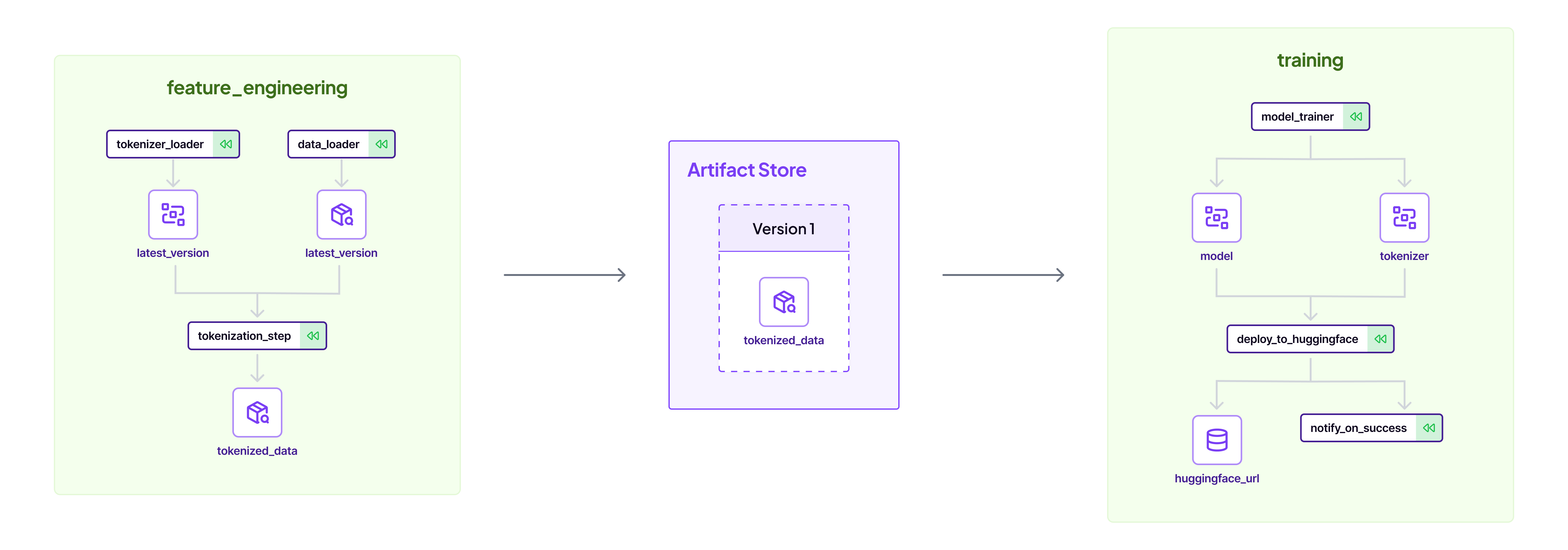
Automated feature engineering forms the foundation of this MLOps workflow. Thats why the first pipeline is the feature engineering pipeline. This pipeline loads some data from Huggingface and uses a base tokenizer to create a tokenized dataset. The data loader step is a simple Python function that returns a Huggingface dataloader object:
import numpy as np
from datasets import DatasetDict, load_dataset
from typing_extensions import Annotated
from zenml import step
@step
def data_loader() -> Annotated[DatasetDict, "dataset"]:
logger.info(f"Loading dataset airline_reviews... ")
dataset = load_dataset("Shayanvsf/US_Airline_Sentiment")
dataset = sample_dataset(dataset)
return datasetNotice that you can give each dataset a name with Python’s Annotated object. The DatasetDict is a native Huggingface dataset which ZenML knows how to persist through steps. This flow ensures reproducibility and version control for every dataset iteration.
💪 Train the model with Huggingface Hub as the model registry
Watch the video for this section:
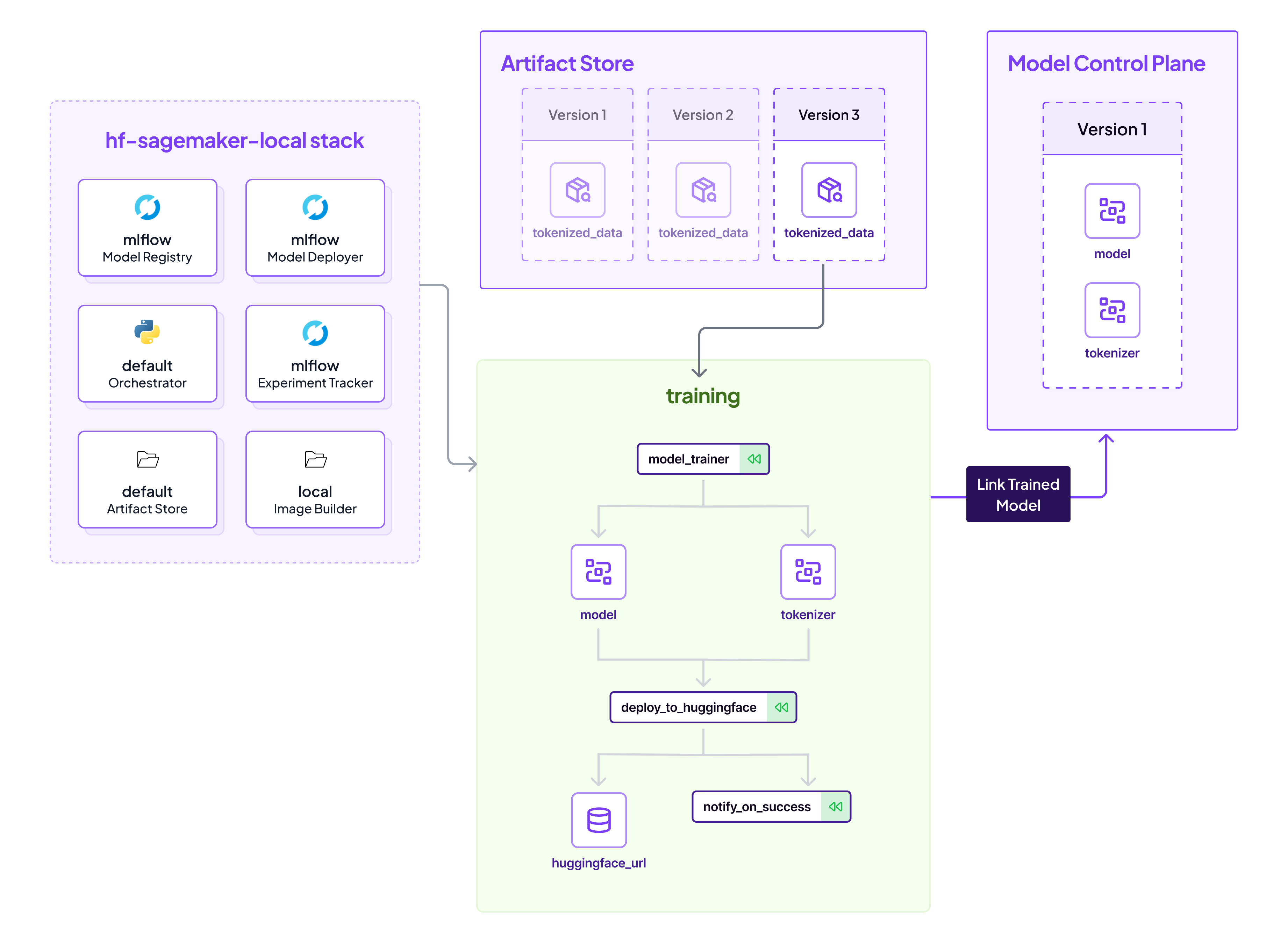
Once the feature engineering pipeline has run a few times, we have many datasets to choose from. We can feed our desired one into a function that trains the model on the data. Thanks to the ZenML Huggingface integration, this data is loaded directly from the ZenML artifact store.
On the left side, we see our local MLOps stack, which defines our infrastructure and tooling we are using for this particular pipeline. ZenML makes it easy to run on a local stack on your development machine, or switch out the stack to run on a AWS Kubeflow-based stack (if you want to scale up).
On the right side is the new kid on the block - the ZenML Model Control Plane. The Model Control Plane is a new feature in ZenML that allows users to have a complete overview of their machine learning models. It allows teams to consolidate all artifacts related to their ML models into one place, and manage its lifecycle easily as you can see from this view from the ZenML Cloud:
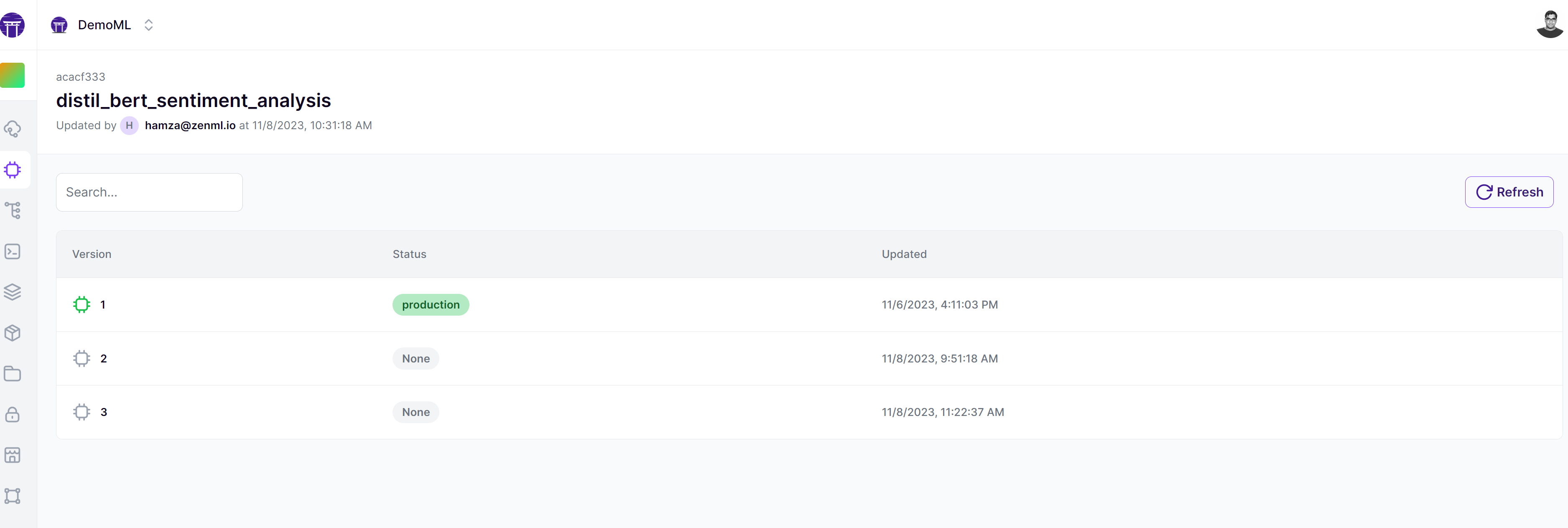
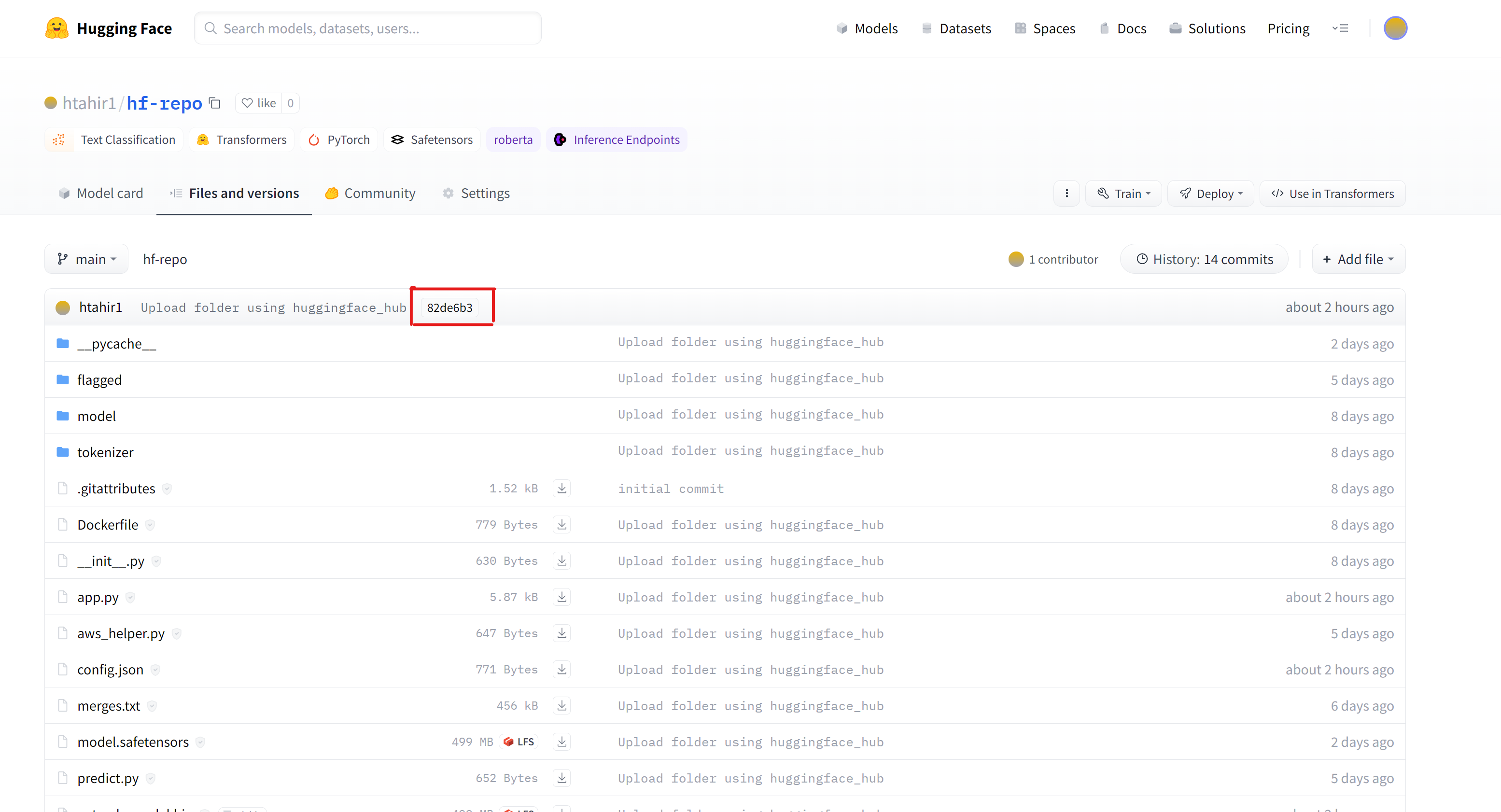
In this case, the training pipeline pushes the model into Huggingface each time its trained, and tracks the revision to establish lineage:
Interested in the Model Control Plane? Book a demo to see it in action.
🫅Promote the model to production
Watch the video of this section:
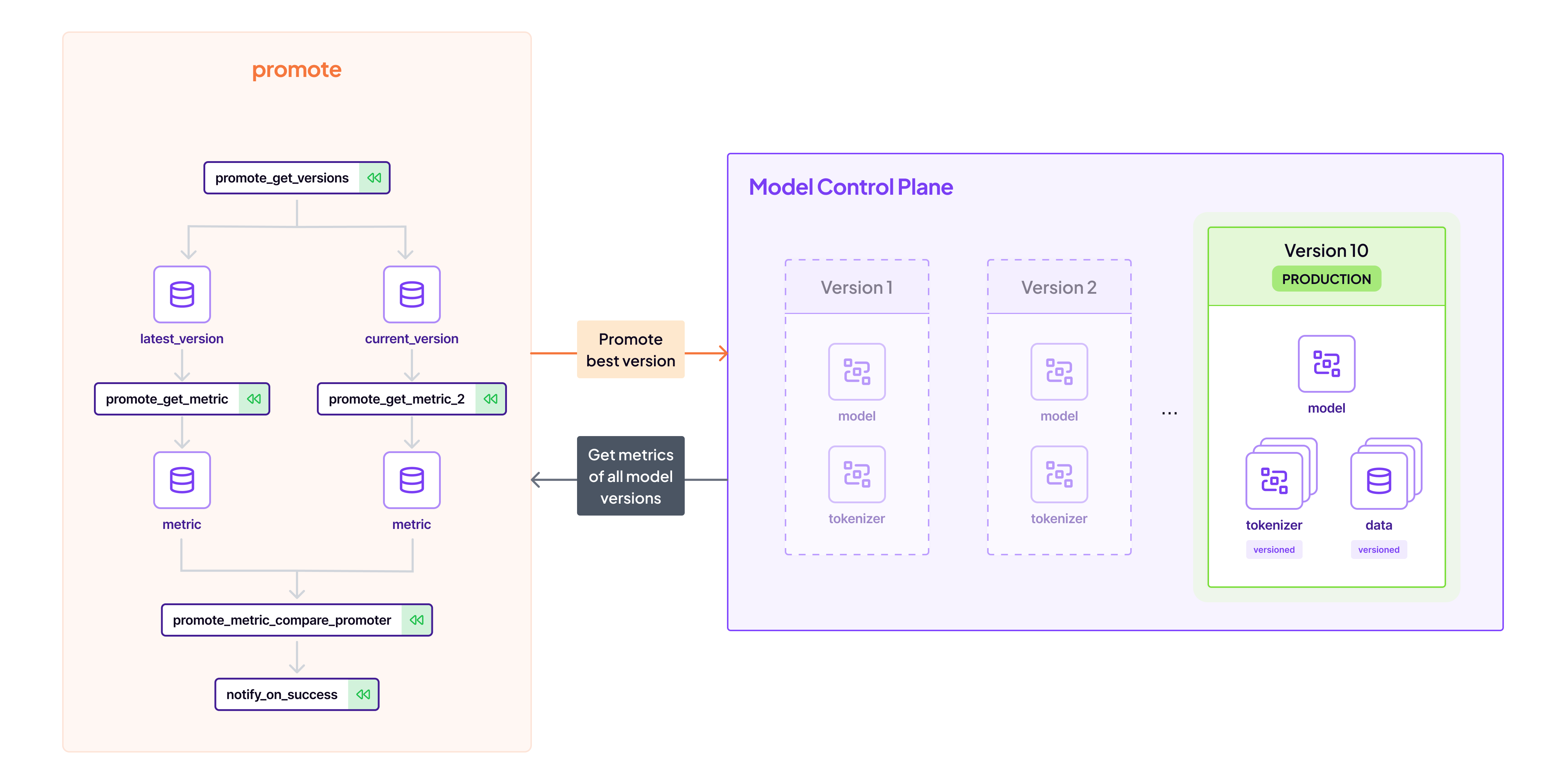
Following training, the automated promotion pipeline evaluates models against predefined metrics, identifying and marking the most performant one as ‘Production ready’. This is another common use case for the Model Control Plane; we store the relevant metrics there to access them easily later:
# Get the current model
current_model = get_step_context().model_version
# Get the production model
prod_model = ModelVersion(
name=current_model.name,
version="production",
)
# Get the current metrics
current_metrics = current_model.get_model_artifact(name="model").metadata["metrics"].value
# Get the previous best metrics
prod_metrics = prod_model.get_model_artifact(name="model").metadata["metrics"].value
# If current model is better promote it
if prod_metrics < current_metrics:
current_model.set_stage("production")💯 Deploy the model to AWS Sagemaker Endpoints
Watch the video of this section:
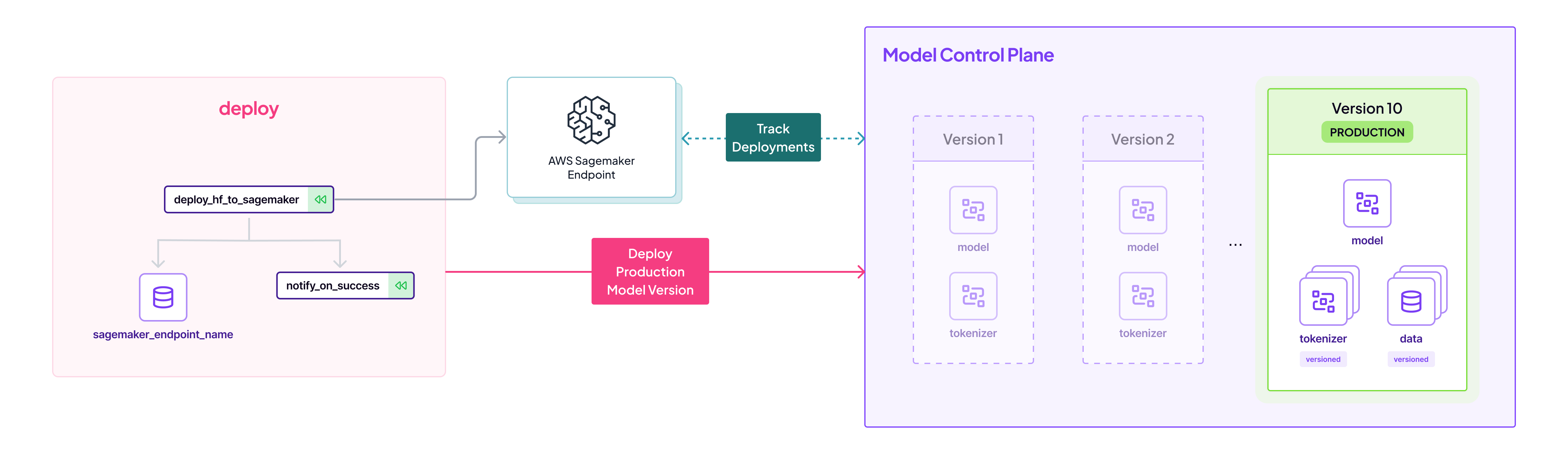
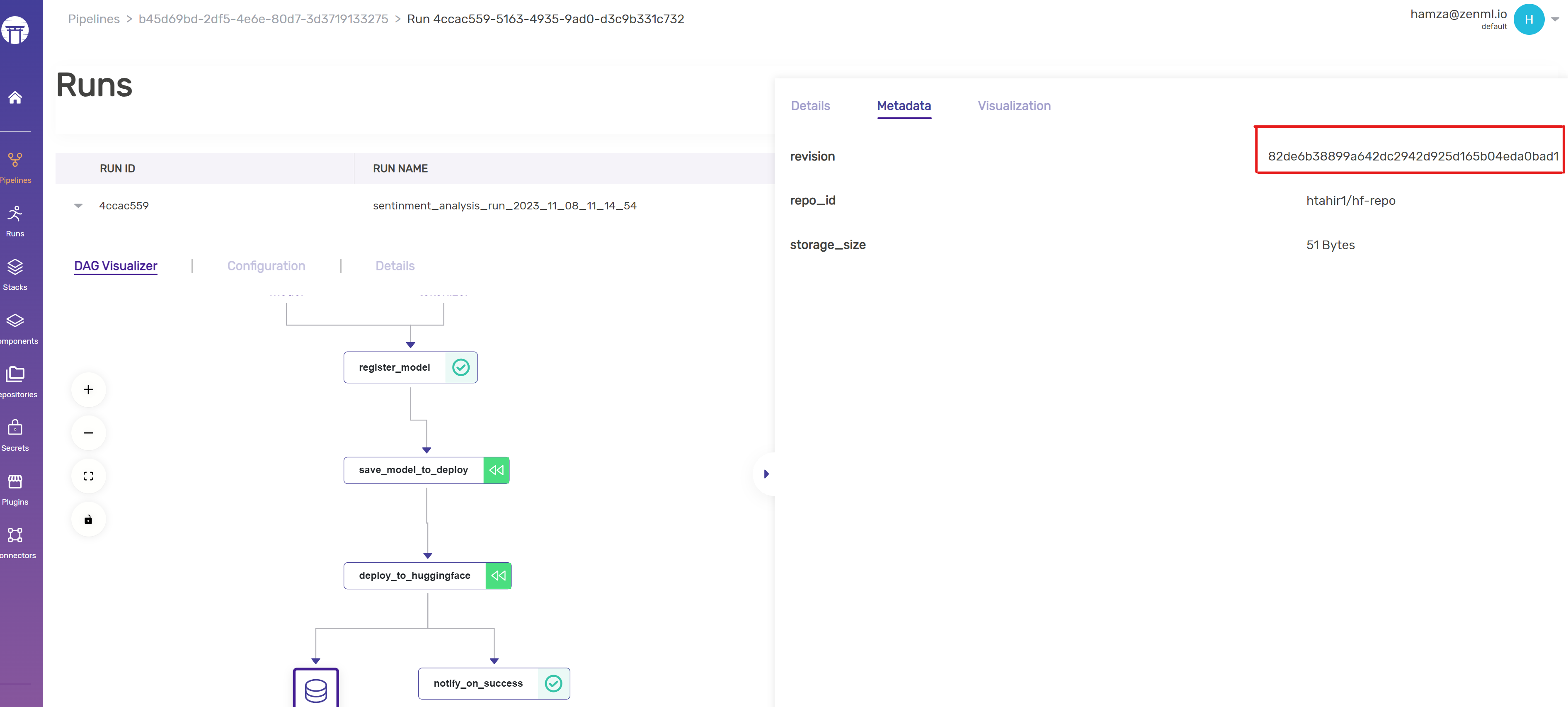
This is the final step to automate the deployment of the slated production model to a Sagemaker endpoint. The deployment pipelines handles the complexities of AWS interactions and ensures that the model, along with its full history and context, is transitioned into a live environment ready for use. Here again we use the Model Control Plane interface to query the Huggingface revision and use that information to push to Huggingface Hub:
# For the Production model, get the metadata of the Huggingface Model
repo_id = prod_model.metadata["repo_id"].value
revision = prod_model.metadata["revision"].value
# Use that to deploy directly to Sagemaker
hub = {
"HF_MODEL_ID": repo_id,
"HF_MODEL_REVISION": revision,
}
# Create the HF Model Class
huggingface_model = HuggingFaceModel(
env=hub,
...
)
# Deploy to sagemaker
huggingface_model.deploy(...)Gradio App - Interactive Demo After Deployment
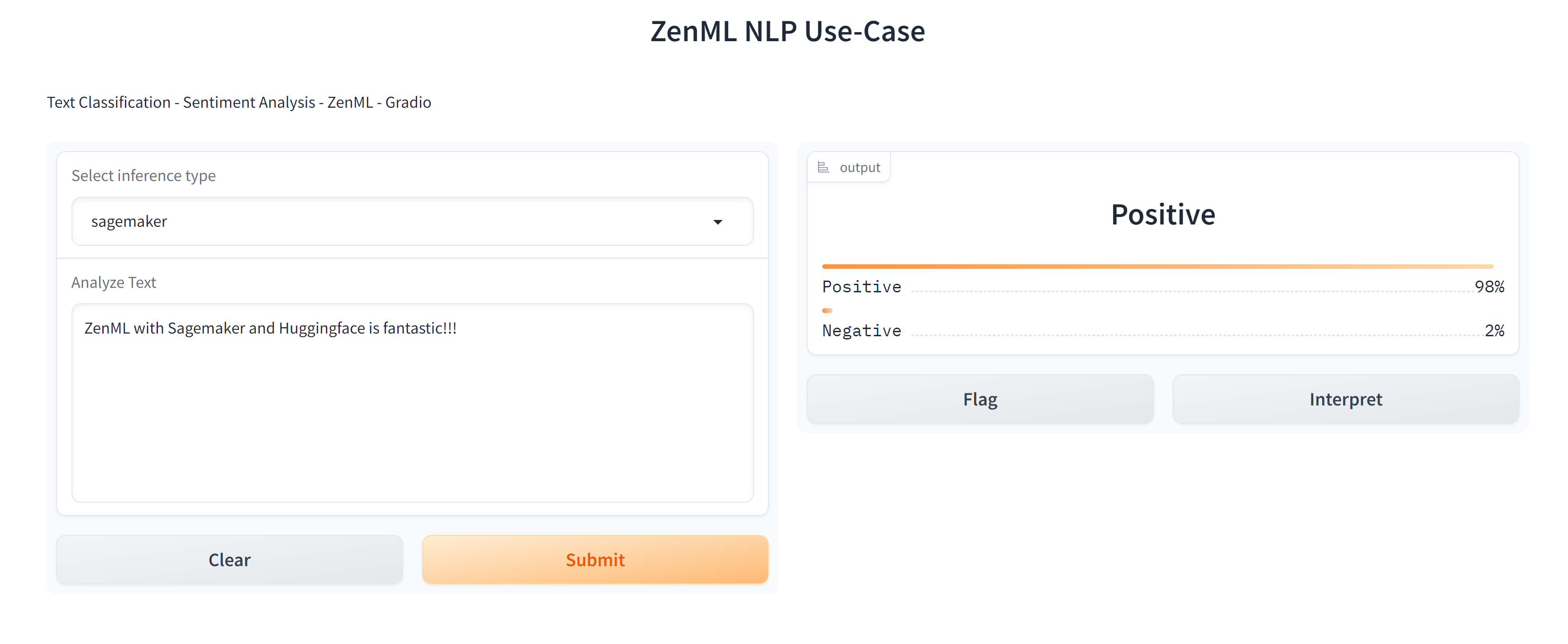
After deploying to Sagemaker, the repository ships with a Gradio app that uses the ZenML client to fetch the production model, and query the Sagemaker endpoint:
# Get the production model
prod_model = ModelVersion(
name="distil_bert_sentiment_analysis",
version="production"
)
# Get the sagemaker endpoint
endpoint_name = prod_model.metadata["sagemaker_endpoint_name"].value
# Use the endpoint to make the prediction
...The app is therefore decoupled from the other process, and running smoothly. It will always pick up the production version:
Conclusion
ZenML builds upon the straightforward deployment capability of Huggingface models to AWS Sagemaker, and transforms it into a sophisticated, repeatable, and transparent MLOps workflow. It takes charge of the intricate steps necessary for modern ML systems, ensuring that software engineering leads can focus on iteration and innovation rather than operational intricacies.
To delve deeper into each stage, refer to the comprehensive guide on GitHub: zenml-io/zenml-huggingface-sagemaker. Additionally, this YouTube playlist provides a detailed visual walkthrough of the entire pipeline: Huggingface to Sagemaker ZenML tutorial.
Interested in standardizing your MLOps workflows? ZenML Cloud is now available to all - get a managed ZenML server with important features such as RBAC and pipeline triggers. Book a demo with us now to learn how you can create your own MLOps pipelines today.