
On this page
Last updated: April 7, 2022.
You start your day with jupyter lab, and look at the latest state of affairs from yesterday. The notebook springs up on port 8888 and you see your matplotlib graph from yesterday, annoyingly stuck at 80% accuracy. After a few hours of hard work, you finally find a hyperparameter that works. You set it, go through the cells, and suddenly you’re at 95% accuracy. You re-check it over and over, and after making sure you did everything right, you export your model into a file and hand over the code and model to engineering, a smile on your face, and with the assurance that you did your job well. Now you can sit back and see the bottom line growing. Right?
Wrong. Your engineer glares back at you and asks for your requirements.txt file. He cannot reproduce your results — there is an error on their machine. They ask what data you trained on, which operating system you developed on, and just generally about following “MLOps” principles. You go back and try to answer these questions but now you’re in a painful debugging loop.
Does any of this sound familiar? As classically-trained data scientists, we have been tuned to stay within a notebook environment and iterate on the code and model. Doing this can lead to unintended consequences and optimizing for the wrong result. Perhaps you would have faired better if you would have taken a slightly different approach to your model development, rooting yourself from the start in these MLOps principles engineers keep talking about.
There is an ever-increasing plethora of resources around MLOps (see the end of this article) and an increasing amount regarding the shift from model-centric to data-centric machine learning. However, few speak about the link between data-centric machine learning and how it is driving MLOps practices today. In this article, I go deeper into how a data-centric, pipeline-based approach to machine learning is one of the best ways to follow MLOps principles, and how you as a data scientist would benefit greatly from understanding why that is the case.
MLOps is not just about deploying models

When speaking about MLOps, developers often confuse it with the simple act of deployment. However, conversations such as the above do not simply refer to deploying models. Machine learning engineering tackles a broader set of challenges that span more than merely wrapping up a model in a server application and deploying it.
ML development may be broken down into the following (relatively) simple processes.
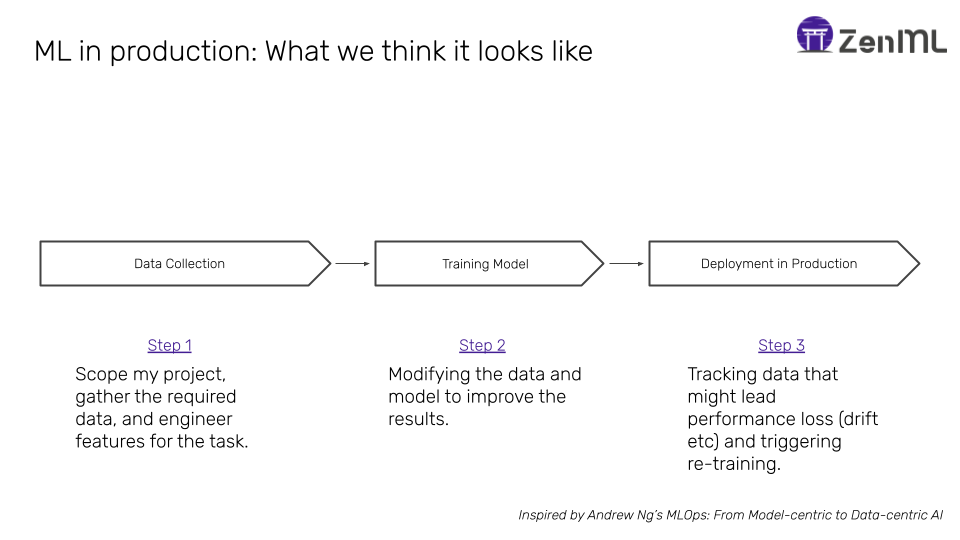
Taken as silos, these processes don’t sound too hard:
- Feature engineering is getting easier with feature stores such as Feast.
- The training loop is made easier by thousands of tools that help in the iterative process, from experiment tracking tools like MLflow and Weights & Biases to advanced training frameworks like PyTorch Lightning.
- Deploying models are also getting easier with the advent of advanced tooling such as Seldon Core, or managed services offered by all the major cloud providers.
However, the reality is that the process looks more like this:
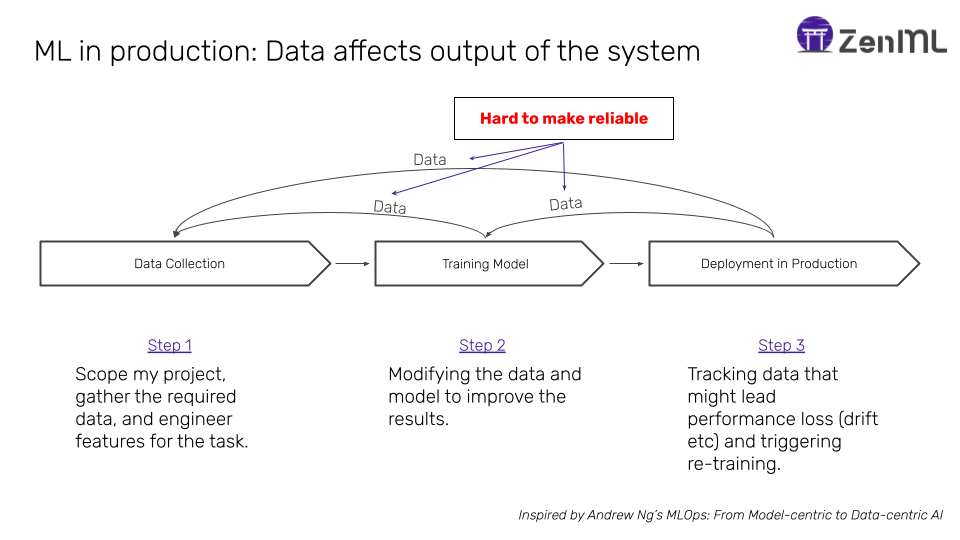
More than code, in machine learning data affects the output of the system directly. There are feedback loops that happen implicitly and often explicitly within the lifetime of a model that is deployed in production. While in classical software development one could simply test and vet code as it passes through various stages to production, it is more complex and difficult to this in a system affected by data.
It is in these feedback loops where MLOps ultimately lives. It is not enough to do this process once: A successful ML team needs to execute this process over and over again, and in a manner such that the system can be trusted.
Simply stated, MLOps is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently. This is including and beyond getting these models deployed into production.
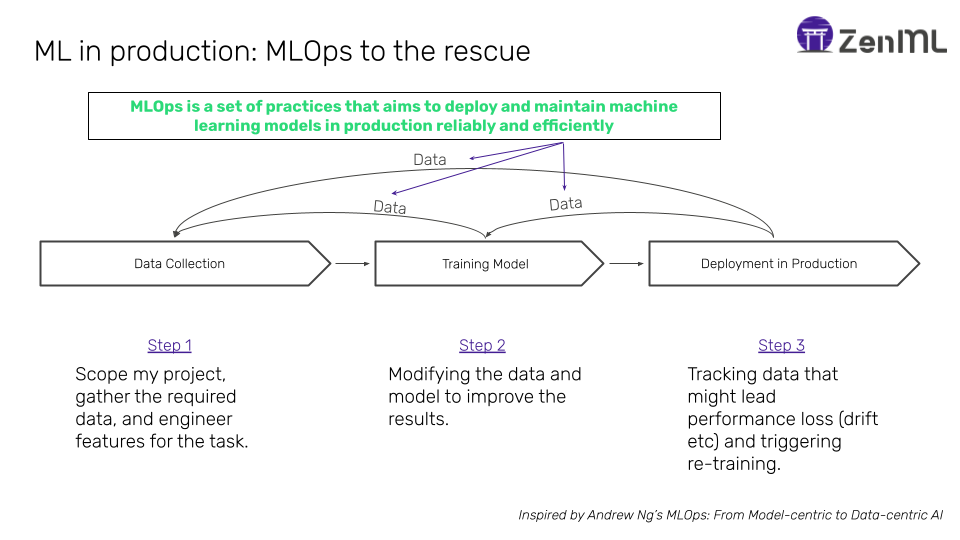
Post-deployment Woes
When looked at from this perspective, it is more intuitive to understand that the trouble starts after the first deployment. Here are just a few examples:
Latency problems:
If latency is not accounted for whilst developing ML models, it can have a huge impact on a business. You could lose half your traffic with a slow load-up of your application. This means that when employing models in production, one needs to be cognizant of latency requirements in production.
Maintaining fairness and avoiding bias
If left unchecked, bias can creep into a ML system very easily. Microsoft’s rogue racist Twitter bot is an example of not setting up systems to maintain fairness in ML development. If a model is not inspected closely (e.g. in terms of slicing metrics), then a practitioner risks that they might unintentionally model bias into the system. This is where examining data closely is critical to ensure a robust and fair system.
Lack of explainability and auditability
If fairness is not maintained in a system, then legislators will be in their full right to come after ML practitioners. The European Commission is already rolling out new laws and checks, and we can only expect this to grow over time. Practitioners should be able to answer questions such as why a certain prediction was made, how a certain model was trained, and on which slice of data. These audit trails are all parts of the MLOps workflow.
Painfully slow development cycles
Getting a model into production can take up to a year for many companies. That means going through the above process only once can cost hundreds of thousands of dollars, let alone having to do it again and again. Teams need to automate most of the tedious stuff away if they are to have any sort of argument for a legitimate return-on-investment for machine learning being applied in a business.
Model, concepts, and data drifts
The real world is not static. Training models on data that do not change are willingly ignoring the fact that this does not happen in the real world. The recent disaster at Zillow is illustrative of how drift can cost a business dearly. As the world changes, MLOps systems need to be robust to these changes and deal with them as they arise.
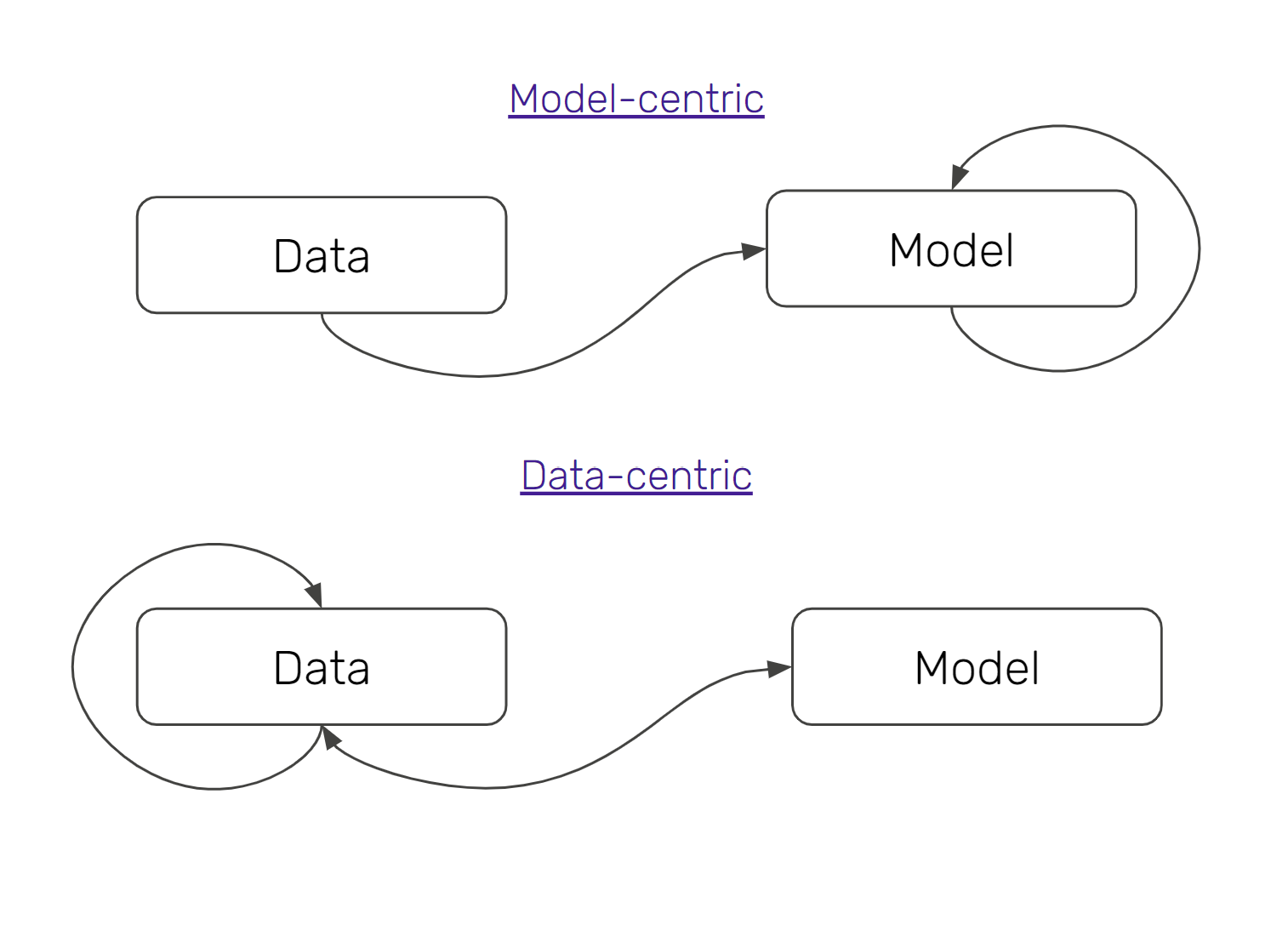
Model-centric vs Data-centric Machine Learning
Andrew Ng recently popularized the term data-centric machine learning with his excellent talk in 2020. Watch the full video below:
The essence of the talk is as follows: You can get a lot of bang for your buck from your data by being data-centric rather than model-centric. This means that rather than iterating on the model/code and holding the data static in ML development, it would pay more dividends if you were to hold the code/model static (or even start with a simple model) and try to simulate real-world behavior with the data. This of course is in stark contrast to how ML is taught in crash courses and universities, where the process usually starts in a notebook with reading a static, well-prepared dataset, and training a model on it.
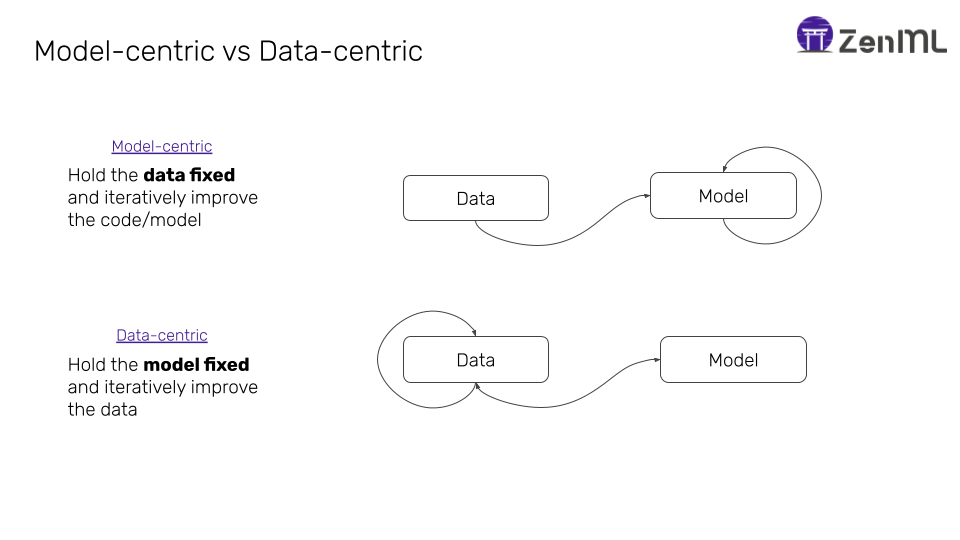
When taking a look at the challenges facing ML in production today, it is clear that a shift towards being data-centric is simply the natural mindset shift that is required. Latency problems can be solved by exposing data scientists to real-world data ingestion patterns. Fairness and bias can be avoided by inspecting the data at the moment of model training. Auditability trails can be kept if data is versioned and tracked as models are developed. The development cycle can also be accelerated vastly by creating data-centric workflows that can adapt to changing data. Finally, drift and data quality can be accounted for early on in the development process.
Here is an example of a model-centric decision vs a data-centric decision, that also showcases its link with MLOps. Let’s say a data scientist has a dataset for the last year and is tasked with developing a model. The model-centric way of approaching such a task would be to use the entire data to train the model with a little bit leftover as a test set to verify the model metrics. Perhaps hyperparameter tuning is applied to squeeze out the maximum accuracy from the model and data.
On the other hand, a data-centric decision, and a decision that would help ultimately in production, would be to partition the data in a way that a portion of it (let’s say the first three quarters of the year) is used for the training process, and the last quarter is used as a separate dataset to see how the model drifts over time. This would perhaps incur a slight loss in accuracy for the model, but give key information about the behavior of the model by simulating it being deployed out in the real world.
In the end, while being model-centric has its benefits, adding data-centric decisions into the mix is ultimately what is the best path forward when applying ML in the real world. With that, there is a natural synergy between this and the adoption of MLOps.
Towards data-centric ML(Ops): From scripting to pipelines
A concrete shift to data-centric machine learning often involves an ML team shifting focus from script-based development to pipeline-based development. Machine learning lends itself very nicely to developing in terms of pipelines because most development does consist of a sequence of steps carried out in order.
Here it is important to make a distinction between data-driven pipelines vs task-driven pipelines. This means that serious teams develop ML code as chunks of steps, using some form of tooling to isolate the orchestration of execution of steps from each other. This has the following benefits:
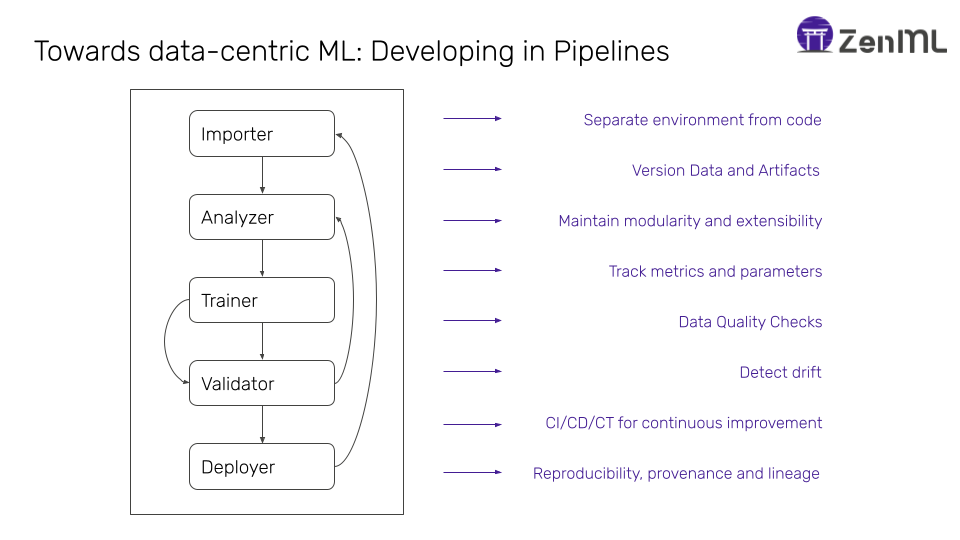
Often this means stepping out of a notebook environment or finding some way of transporting notebook code to such a paradigm.
Takeaways
So, in short, here is the link between MLOps and data-centric machine learning:
- ML in production is different from ML in research and has a different set of challenges.
- These challenges are growing in relevance as the adoption of ML increases.
- MLOps helps solve these problems.
- MLOps is rooted in being more data-centric than model-centric.
- Developing pipelines help in being more data-centric.
I hope that helps to clarify the link between these two popular terms and gives beginner MLOps practitioners an indication of where to take their efforts as they develop internal ML tooling for their organizations.
Shameless plug: If you’d like to start the shift towards data-centric machine learning by developing ML pipelines, then you might want to take a look at ZenML. It is designed with the following goals:
- Be simple and intuitive to give a simple path toward data-centric machine learning.
- Be infrastructure and tooling agnostic across the MLOps stack.
- Start writing your pipeline in a notebook and carry it easily into the cloud with minimum effort.
Resources
If you’d like to get more into MLOPs, I would recommend the following excellent resources to get started:
- MLOps Course MadeWithML
- CS 329S: Machine Learning Systems Design
- Full Stack Deep Learning
- ZenBytes - learn MLOps through ZenML
References
Some images inspired by Andrew Ng’s talk “From Model-centric to Data-centric AI” on YouTube


