On this page
ML engineers often have a hard time deciding which platform to go with when setting up MLOps pipelines - Kubeflow or MLflow.
Comparing Kubeflow, MLflow, and ZenML might seem a little unusual, with Kubeflow being fundamentally a container orchestration system, MLflow primarily an experiment tracking tool, and ZenML a combination of both; their growing capabilities have created significant overlap in the ML ecosystem. This article isn’t about pitting them against each other feature-by-feature, but understanding their unique strengths, compatibility, and how they can complement one another in diverse MLOps scenarios.
In this Kubeflow vs MLflow vs ZenML article, we explain the difference between the three platforms by comparing their features, integrations, and pricing.
PS. We built ZenML as an MLOps platform for your MLOps team. It offers a lightweight yet powerful framework that integrates cleanly with your existing ML infrastructure to build, deploy, and manage pipelines at scale.
Recently Updated (November 2025): This comparison has been refreshed with the latest platform developments, including Kubeflow 1.10’s LLM fine-tuning capabilities and MLflow 3’s production-ready GenAI features. All platform capabilities and use cases reflect the current MLOps and LLMOps landscape as of November 2025.
Kubeflow vs MLflow vs ZenML: Key Takeaways
🧑💻 Kubeflow is an open-source Kubernetes-native platform that automates and standardizes the full machine learning lifecycle – data preparation, training, hyperparameter tuning, serving, and monitoring. It does so via reusable pipelines, notebook environments, and scalable operators.
🧑💻 MLflow is also an open-source platform that optimizes the ML lifecycle by providing experiment tracking, reproducible project packaging, and model management. The tool integrates with any ML library and stores metrics and artifacts, version models, and enables seamless, collaborative deployments. It brings research to reliable production across clouds with auditable processes.
🧑💻 ZenML is a lightweight, extensible MLOps framework designed to create reproducible ML pipelines. The platform acts like a bridge between experimentation and production by providing a consistent way to design workflows that work across different environments. ZenML is perfect for teams seeking flexibility and ease of use without complex infrastructure setup.
Kubeflow vs MLflow vs ZenML: Features Comparison
A TL;DR for the feature comparison:
| Capability | Best-suited |
|---|---|
| Pipeline orchestration & workflow automation |
|
| Experiment tracking & metadata |
|
| Artifact versioning |
|
| Batch inference (offline scoring) |
|
| Real-time model serving |
|
| Integration |
|
| Ease of use/learning curve |
|
If you want to look at how we came to the conclusions above, read on.
We tried and tested these three platforms across various features. The three most important features common to these platforms are:
- Pipeline Orchestration and Workflow Automation
- Experiment Tracking, Metadata, and Artifact Versioning
- Model Serving and Deployment
We will now be comparing the above-mentioned features and tell you when to use which MLOps platform.
Feature 1. Pipeline Orchestration and Workflow Automation
Kubeflow
Kubeflow is built to orchestrate complex ML pipelines on Kubernetes. It includes Kubeflow Pipelines, a component that allows you to define multi-step workflows (as DAGs) and automate their execution in containerized environments.
This means Kubeflow can coordinate tasks like data prep, training, and evaluation as a sequence of containers, with Kubernetes handling scheduling and scaling.
What’s more, the platform excels at running distributed training jobs and hyperparameter tuning at scale, thanks to operators for TensorFlow and PyTorch. It can also parallelize workflows easily.
# Kubeflow Pipelines SDK
import kfp
from kfp import dsl
def preprocess_op(data_path):
return dsl.ContainerOp(
name='Preprocess Data',
image='preprocess-image:latest',
arguments=['--data_path', data_path]
)
def train_op(data):
return dsl.ContainerOp(
name='Train Model',
image='train-image:latest',
arguments=['--data', data]
)
@dsl.pipeline(
name='My ML Pipeline',
description='A sample ML pipeline'
)
def my_pipeline(data_path: str):
preprocess_task = preprocess_op(data_path)
train_task = train_op(preprocess_task.output)
# Compile and run the pipeline
kfp.compiler.Compiler().compile(my_pipeline, 'pipeline.yaml')
client = kfp.Client()
client.create_run_from_pipeline_func(my_pipeline, arguments={})MLflow
MLflow is primarily a tracking tool; it doesn’t schedule or run multi-step workflows on its own. If you need to orchestrate steps (for example, train, then validate, then deploy automatically), you would have to use MLflow in tandem with another orchestration tool (like Apache Airflow, Prefect, or even Kubeflow or ZenML itself).
The advantage of MLflow’s approach is its simplicity and flexibility. It’s easy to set up and use, making it accessible for data scientists without extensive infrastructure knowledge.
However, if you need comprehensive pipeline management for production ML workflows, MLflow alone may not be sufficient.
# MLflow manual usage
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("my_experiment")
with mlflow.start_run():
# Load and preprocess data
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Train model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Log parameters
mlflow.log_param("n_estimators", model.n_estimators)
mlflow.log_param("max_depth", model.max_depth)
# Log metrics
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
mlflow.log_metric("accuracy", accuracy)
# Log model
mlflow.sklearn.log_model(model, "random_forest_model")
# Retrieve and print the run ID
current_run = mlflow.active_run()
print(f"MLflow Run ID: {current_run.info.run_id}")ZenML
ZenML takes a pipeline-centric approach with an emphasis on ease of orchestration. It allows developers to build pipelines in Python and then execute them on various orchestrators interchangeably (local, Kubernetes, Airflow, etc.) without changing pipeline code.
Under the hood, ZenML abstracts the workflow engine – for example, you can switch from running a pipeline locally to running on Kubeflow or Airflow with minimal configuration.
ZenML integrates with Kubeflow as an orchestrator, which allows you to leverage Kubeflow’s capabilities with little to no learning curve. This isn’t an either/or decision – you can utilize Kubeflow through ZenML, gaining the benefits of both tools.
This flexibility gives you robust pipeline automation across environments without the steep learning curve of Kubeflow’s ecosystem.
# zenml integration install kubeflow
# zenml orchestrator register kf_orchestrator -f kubeflow ...
# zenml stack update my_stack -o kf_orchestrator
from zenml import pipeline, step
@step
def preprocess_data(data_path: str) -> str:
# Preprocessing logic here
return processed_data
@step
def train_model(data: str):
# Model training logic here
return model
@pipeline
def my_pipeline(data_path: str):
processed_data = preprocess_data(data_path)
model = train_model(processed_data)
# Run the pipeline
my_pipeline(data_path="path/to/data")Bottom line: For orchestration-heavy needs, Kubeflow offers the most robust native pipeline automation on Kubernetes, but it sure has a significant learning curve to it.
MLflow isn’t designed for pipeline orchestration at all, focusing elsewhere.
ZenML fills that gap by providing a flexible orchestration framework that bridges local development and scalable cloud workflows, delivering automation with less overhead than Kubeflow for most use cases.
Feature 2. Experiment Tracking, Metadata, and Artifact Versioning
Kubeflow
Kubeflow Pipelines integrates experiment tracking with its metadata store, capturing parameters, metrics, and artifacts for each pipeline run.
Artifacts such as datasets and models are tracked using the dsl.Artifact class, enabling lineage visualization through the Metadata UI.
While Kubeflow supports artifact tracking and lineage, its artifact versioning capabilities are more implicit, relying on the use of Persistent Volume Claims (PVCs) and Volume Snapshots to manage different versions of data and models.
The following training_component demonstrates the usage of both input and output artifacts using the traditional artifact syntax:
from kfp.dsl import Input, Output, Dataset, Model
@dsl.component
def training_component(dataset: Input[Dataset], model: Output[Model]):
"""Trains an output Model on an input Dataset."""
with open(dataset.path) as f:
contents = f.read()
# ... train tf_model model on contents of dataset ...
tf_model.save(model.path)
model.metadata['framework'] = 'tensorflow'Kubeflow 1.11 introduced a Model Catalog that enables teams to define validated, approved models for discovery and sharing across the org. Think of it as a governed model marketplace inside your cluster.
MLflow
MLflow excels in experiment tracking, offering a UI and APIs to log parameters, metrics, and artifacts. Each run is uniquely identified, and artifacts are versioned automatically upon logging.
The Model Registry further enhances version control by allowing you to register models, manage stages (Staging, Production), and track lineage across different versions. This structured approach facilitates reproducibility and collaborative model management.
More importantly, integration between ZenML and MLflow allows you to leverage MLflow’s powerful experiment tracking capabilities within your ZenML pipelines. This integration lets you effortlessly log and visualize models, parameters, metrics, and artifacts produced by your ZenML pipeline steps.
MLflow 3.10 added multi-workspace support, letting teams separate dev, staging, and production tracking within a single MLflow deployment. No more messy shared experiment namespaces.
ZenML
ZenML offers built-in artifact versioning and powerful experiment tracking through its robust metadata management. Every pipeline run in ZenML automatically tracks artifacts, parameters, and metrics, providing seamless reproducibility and version control.
With ZenML’s Model Control Plane, teams can centrally register, manage, and deploy models across environments, streamlining promotion from experimentation to production.
ZenML’s experiment tracker further simplifies comparisons and debugging by enabling interactive visualizations and metadata-driven insights directly within pipeline runs.
Additionally, the platform’s flexible deployment framework allows direct integration with popular serving tools like MLflow, Seldon Core, and BentoML. This means you can perform batch inference or deploy real-time models seamlessly from the same pipeline.
Bottom line: MLflow still provides the richest standalone tracking UI and structured model registry.
Kubeflow captures run metadata inside its Kubernetes‑first workflows with storage‑level versioning.
ZenML now offers artifact versioning and experiment tracking through its built-in metadata management and Model Control Plane. It simplifies moving models from experimentation to production, providing interactive metadata visualizations and flexible deployment integrations; all from one consistent pipeline experience.
Feature 3. Model Serving and Deployment
Kubeflow
Kubeflow includes KServe (formerly KFServing) for deploying and serving models on Kubernetes clusters. KServe now integrates with KEDA for event-driven autoscaling, giving you flexible scaling options beyond Knative and HPA. If your serving workload is event-driven (think: queue-based inference), this is a big deal.
With Kubeflow, you can deploy a trained model as a microservice (container) that auto-scales, has HTTP endpoints, and leverages Kubernetes features for resilience.
It’s the ideal choice if you want to serve predictions in a cloud-native way (for example, deploying a TensorFlow model onto Kubernetes with GPU support and autoscaling).
Kubeflow’s Model Serving component is part of the end-to-end pipeline: after training in Kubeflow, you can use the pipeline to push the model to KServe.

MLflow
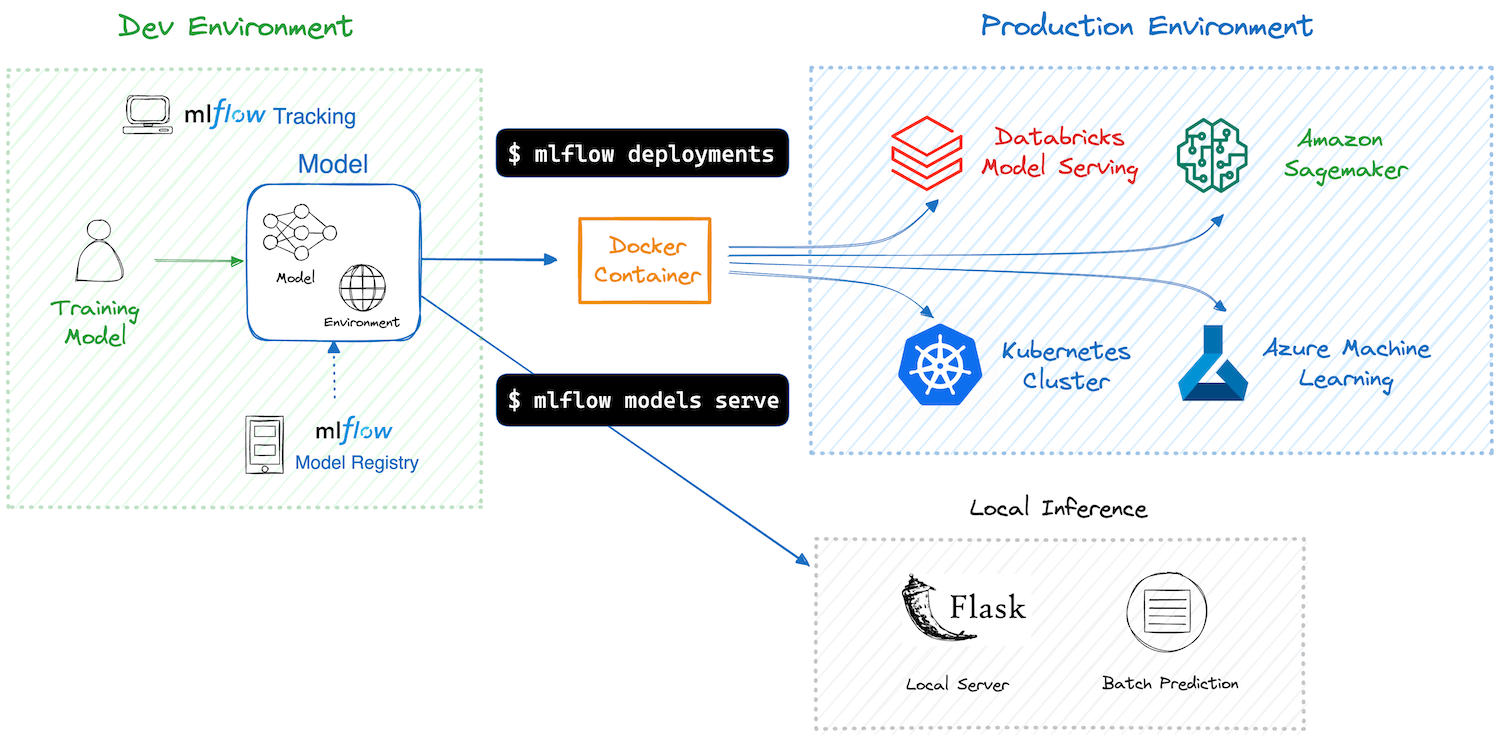
MLflow’s deployment options are more framework-neutral. The platform can package models along with their environment (using MLflow models export) and then deploy them using MLflow’s model serving tool or to various platforms.
For instance, MLflow can deploy models to AWS SageMaker or Azure ML, or host a local REST API using the MLflow server command. It also integrates with Docker for containerizing models.
However, MLflow’s native serving is basic (suitable for testing or lightweight loads) compared to Kubeflow’s production-grade serving on Kubernetes.
Many companies use MLflow’s model registry in combination with a separate serving infrastructure: for example, register a model in MLflow, then manually deploy it to a cloud service or via Kubernetes.
ZenML
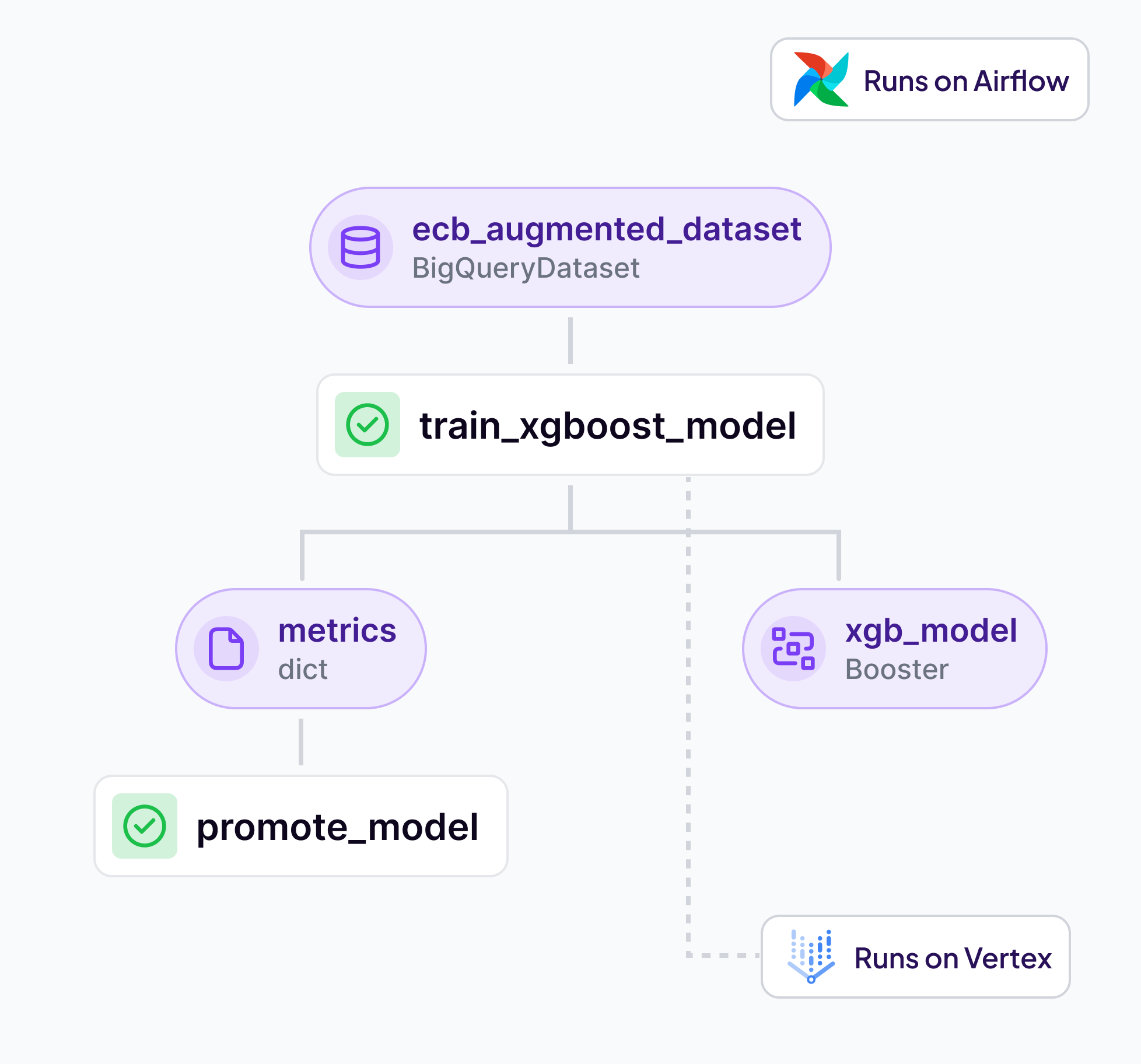
ZenML approaches model deployment by integrating specialized serving frameworks into its pipeline system.
The platform supports batch inference natively, which allows you to schedule pipelines that load specific artifact versions to produce offline predictions with ease.
For real-time model inference, ZenML leverages a flexible integration framework called Model Deployers. Through this approach, ZenML connects your pipelines to specialized serving tools such as MLflow, Seldon Core, and BentoML, delegating heavy lifting and scaling of real-time deployments to these dedicated platforms.
A practical example is the recent OncoClear project, where ZenML pipelines train and deploy a scikit-learn model as a FastAPI application.
This end-to-end flow demonstrates how easily ZenML can handle production-grade deployments, providing model serving and monitoring capabilities while preserving full visibility and control within a unified MLOps pipeline.
Learn more about ZenML’s Model Deployers here.
Bottom line: Kubeflow provides an all-in-one solution if you are already in the K8s ecosystem – you can train and serve on the same platform. In short, Kubeflow is ideal if you need to deploy models at scale on Kubernetes (with capabilities like autoscaling and multi-model serving).
MLflow offers flexibility in deploying machine learning models to different environments, but doesn’t handle large-scale serving itself (you’d integrate it with cloud services or custom serving stacks).
ZenML functions more as an integration layer that can leverage both platforms, along with others.
Kubeflow vs MLflow vs ZenML: Integration Capabilities
Integration capabilities define how easily your MLOps platform fits into existing workflows and tools.
Kubeflow, MLflow, and ZenML each offer distinct strengths in this area, from Kubernetes-native compatibility and versatile APIs to extensive pluggable components that enable seamless integration into machine learning environments.
Kubeflow
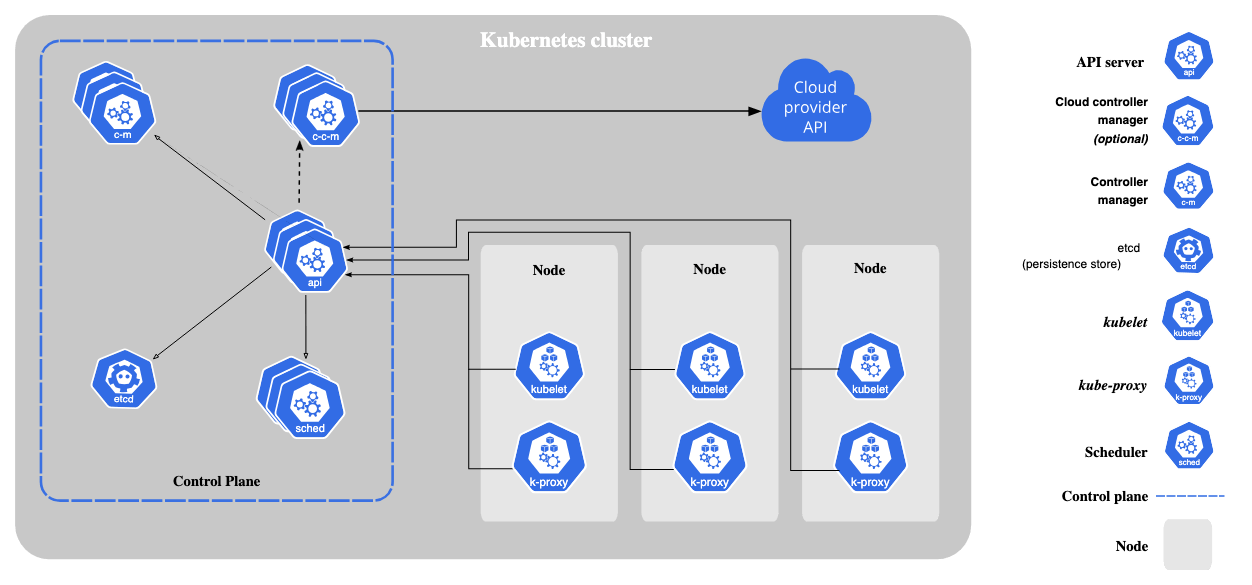
Kubeflow integrates deeply with the Kubernetes ecosystem. This is a big plus if you already use Kubernetes for infrastructure. Kubeflow is cloud-agnostic in the sense that if Kubernetes is there, Kubeflow can run – and it’s officially compatible with AWS, GCP, and Azure (there are deployment scripts for each).
In terms of ML tools integration, Kubeflow includes support for TensorFlow (via TFJob operator) and PyTorch (via PyTorchJob) for distributed training jobs, and it supports other frameworks through containers (you can containerize any code to run in a pipeline).
For data and storage, Kubeflow pipelines can interface with data on cloud storage (e.g., S3, GCS) or databases by mounting volumes or through pipeline steps, though you have to set that up via Kubernetes secrets or volumes.
Integration sum up:
- Kubernetes: Core infrastructure for deployment and scaling.
- ML Frameworks: TensorFlow, PyTorch, XGBoost.
- Notebooks: Jupyter, RStudio, VS Code.
However, outside of the Kubernetes world, Kubeflow’s integration is limited – it’s not a single Python library you can use in any environment; it expects a Kubernetes cluster.
So while it’s excellent for integrating various components within a cloud-native infrastructure (CI/CD pipelines, storage, GPU scheduling, etc.), it’s not designed to plug into non-K8s workflow tools.
MLflow

MLflow integrates seamlessly with a wide range of ML tools and environments, as it supports Python, Java, R, and REST APIs.
The platform integrates with popular ML frameworks, providing auto-logging capabilities for TensorFlow, PyTorch, scikit-learn, XGBoost, and other libraries. These integrations automatically capture relevant metrics and parameters without requiring manual logging, as they offer tailored APIs, auto-logging, and a user-friendly UI for traditional ML libraries.
For deployment, MLflow integrates with serving platforms and cloud services, which enables model deployment across different environments. The platform supports packaging models as Docker containers, making them deployable to various container orchestration platforms, as you can build Docker images for their models, suitable for deployment to cloud platforms.
Integration sum up:
- API Support: Python, Java, R, and REST APIs.
- ML Frameworks: Native integration with TensorFlow, PyTorch, scikit-learn, XGBoost, and others with auto-logging capabilities.
- Storage Options: Flexible backends including local filesystems, SQL databases (like PostgreSQL), and cloud storage solutions.
- Deployment Methods:
- REST API endpoints for model serving
- Docker containerization for portable deployment
- Integration with various container orchestration platforms
- Cloud Platforms: AWS SageMaker, Azure ML, and Databricks with specialized deployment workflows.
📚 Relevant read: MLflow alternatives
ZenML
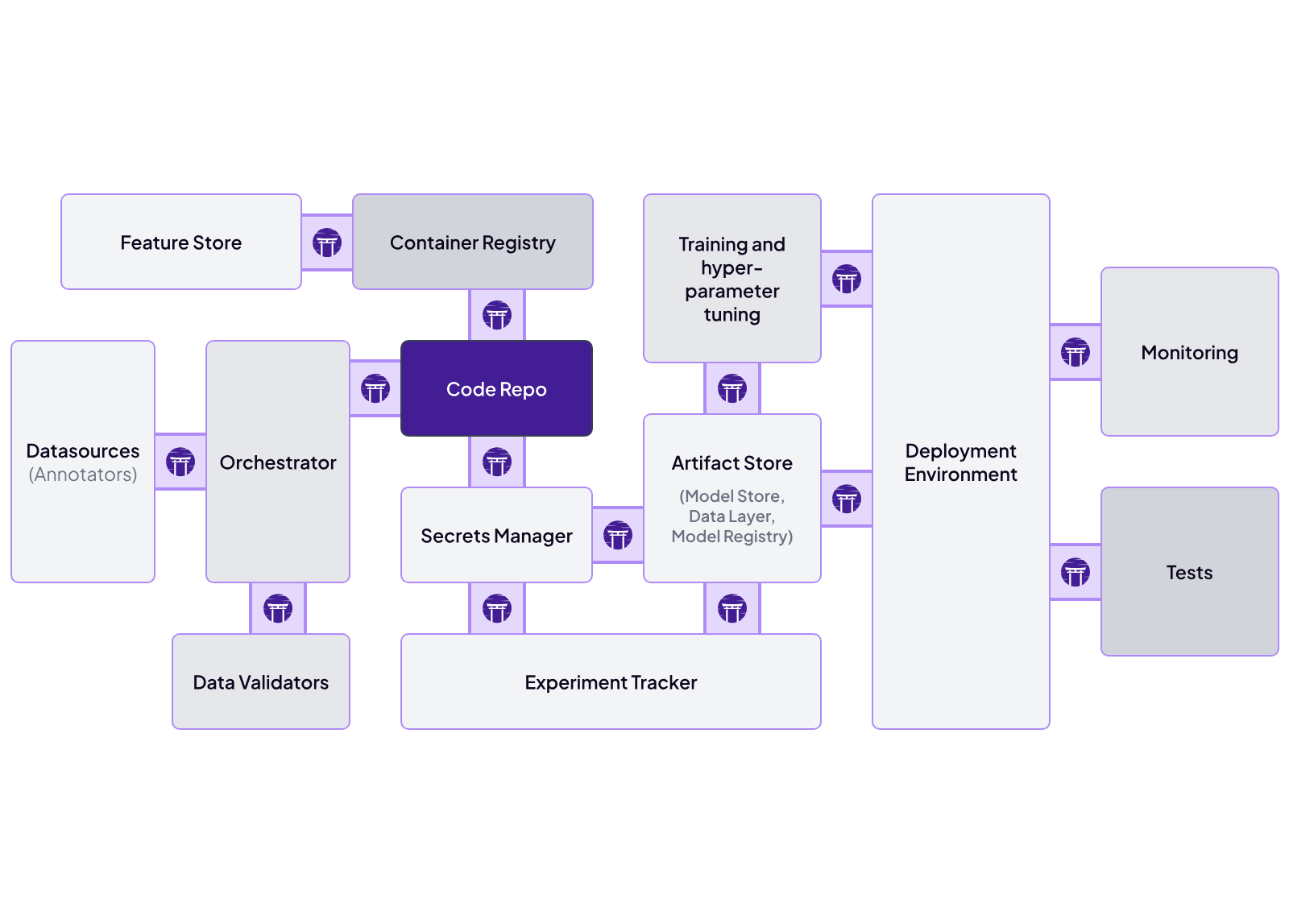
ZenML is designed to be an integration-friendly MLOps framework.
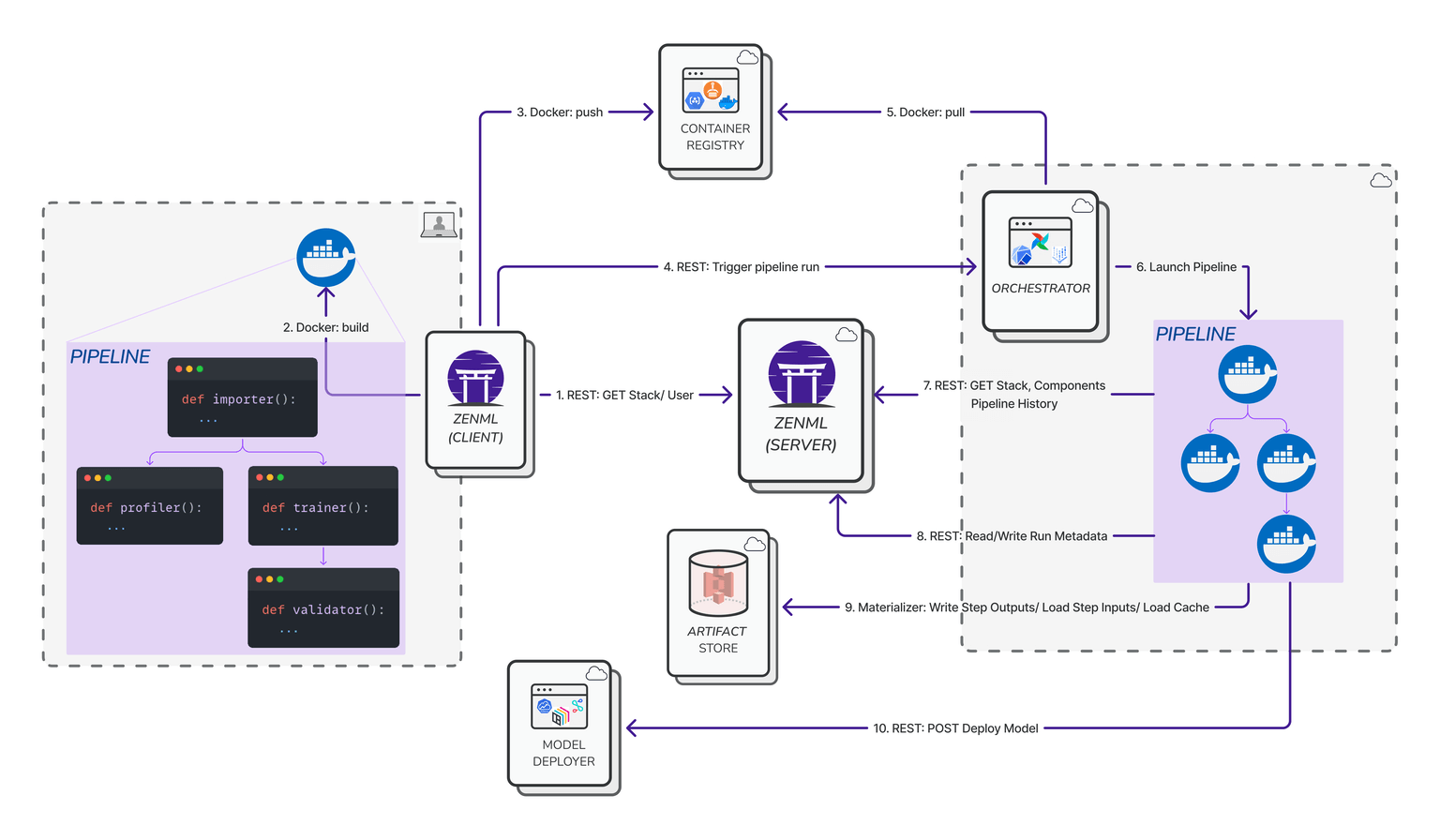
The platform’s built around a pluggable ‘stack’ architecture . Every major part of the MLOps lifecycle is abstracted as a stack component, and each component has multiple ‘flavors’ that integrate popular open‑source or cloud services.
For example, ZenML integrates with Kubeflow as an orchestrator out of the box: you can develop a ZenML pipeline locally and then run it on a Kubernetes cluster via Kubeflow without changing your code.
Similarly, ZenML already integrates with experiment trackers like MLflow – you can configure a ZenML pipeline to use MLflow for logging, and ZenML will automatically record all your metrics and parameters to an MLflow server.
Beyond Kubeflow and MLflow, ZenML provides over 50 integration plugins for data sources, feature stores, model deployment tools, cloud services, and more. This means you can mix and match components: for instance, use an Airflow orchestrator, MLflow tracking, Seldon Core for model deployment, and AWS S3 for artifact storage – all coordinated through ZenML.

ZenML now integrates with Anthropic’s Model Context Protocol (MCP), turning your pipeline metadata into conversational insights. Query your runs, analyze pipeline performance, and trigger deployments through natural language via Claude Desktop or Cursor.
Kubeflow vs MLflow vs ZenML: Pricing
All three platforms offer an open-source version of the tool that’s completely free. But when you need a hosted option, you have to opt for a managed service, which these platforms have. Let’s discuss what these services cost.
Kubeflow
Kubeflow is freely available for deployment on any Kubernetes cluster.
It also has managed services with:
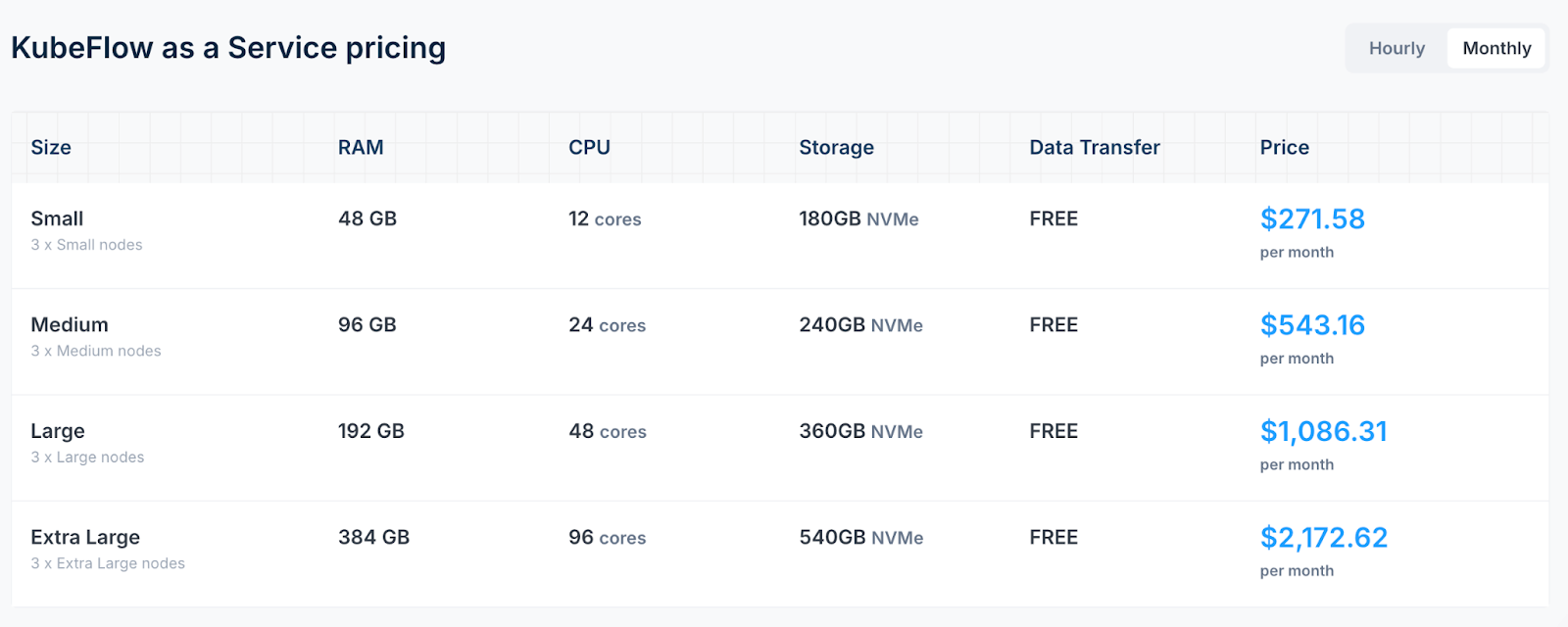
- Civo Kubeflow as a Service: Starts at $271.58 per month, providing a fully managed ML development environment with auto-scaling capabilities.
- Arrikto Kubeflow as a Service: Pricing begins at $2.06 per hour for active deployments and $0.20/hour when idle, offering a 7-day free trial.
- Canonical's Managed Kubeflow: Offers tailored solutions with a 99.9% uptime SLA, with pricing details available upon request.
MLflow
Like Kubeflow, MLflow also offers an open-source version that can be self-hosted on various infrastructures.
Managed services:
- Databricks Managed MLflow: Integrated within the Databricks platform, pricing varies based on compute and storage usage.
- Amazon SageMaker with MLflow: Offers a fully managed MLflow experience, with costs based on the size and uptime of the tracking server (e.g., $0.642/hour for a small instance) and storage usage.
- Nebius Managed MLflow: Charges approximately $0.36/hour for a cluster with 6 vCPUs and 24 GiB RAM.

ZenML
ZenML is free to use under an open-source license, which allows you and your team to self-host and manage MLOps pipelines independently.
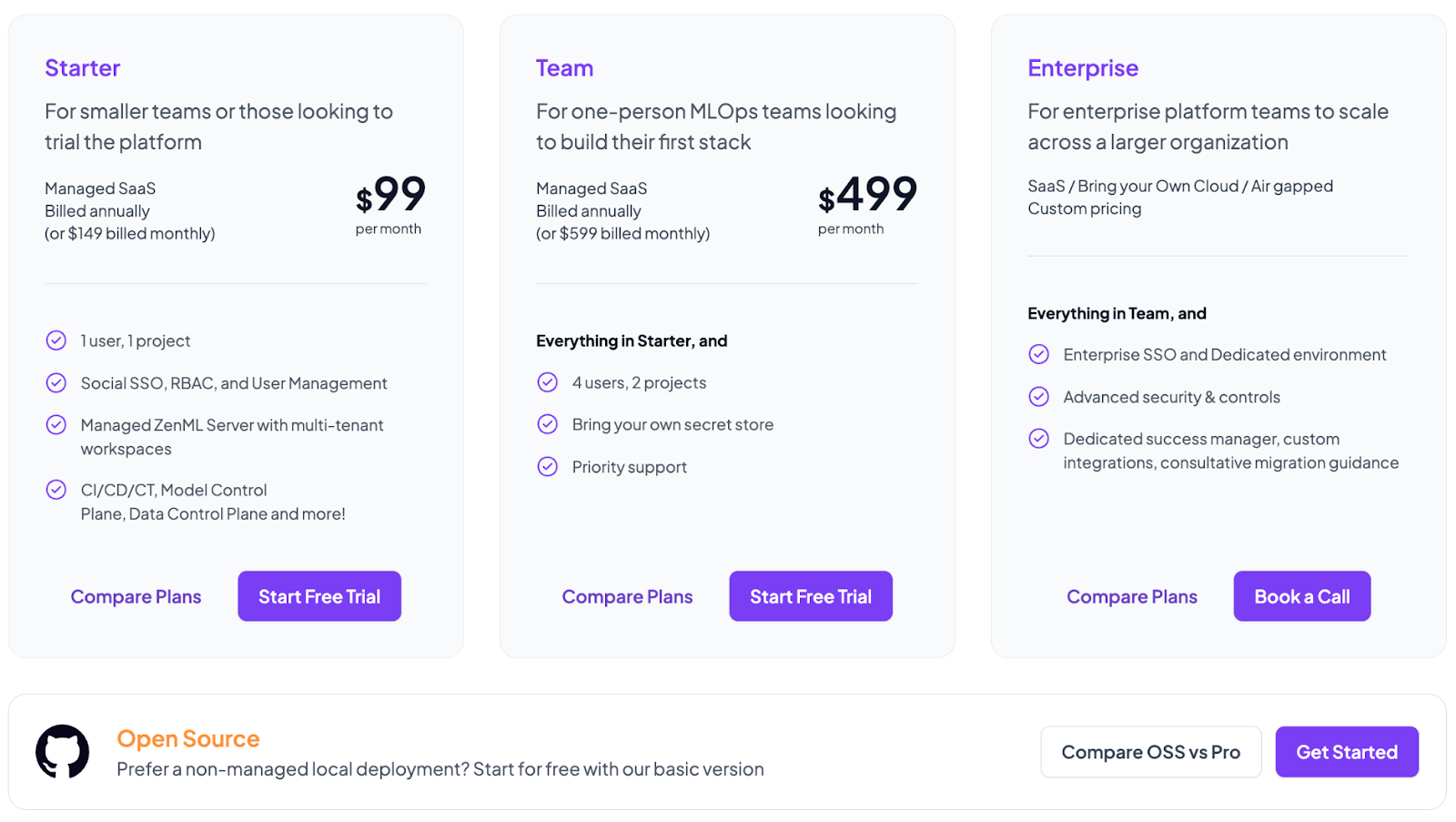
Apart from the free version, the managed platform offers three paid versions:
- Starter: $99 per month
- Team: $499 per month
- Enterprise: Custom pricing
Note: Every paid plan comes with a 14-day free trial; no credit card required.
The Shift to LLMOps in 2026
The MLOps landscape has evolved significantly in 2025, with both Kubeflow and MLflow expanding their capabilities to address the unique challenges of Large Language Models and AI agents.
Kubeflow’s LLMOps Evolution
Kubeflow 1.11, released in December 2025, pushed the platform further into LLM territory. The update ships with KServe 0.15.2 featuring vLLM v0.8.1+ support (reasoning models, tool calling, Llama 4, Qwen 3), a brand new Model Catalog for governed model discovery, and KEDA event-driven autoscaling. Trainer v2.2 now natively supports JAX, XGBoost, and Flux workloads. The platform now includes hyperparameter optimization specifically designed for LLM fine-tuning through Katib, enabling teams to efficiently tune foundation models at scale. Trainer has evolved since 2.0; Trainer v2.2 now includes native support for JAX and XGBoost runtimes, Flux for HPC workloads, and deeper observability into training jobs with progress tracking and metrics reporting. Security improvements, like rootless containers and enhanced CISO compatibility, address the governance requirements that enterprises face when deploying AI agents in production.
KServe’s vLLM runtime was upgraded to v0.8.1+ with support for reasoning models, tool calling, embeddings, reranking, and models like Llama 4 and Qwen 3. If you’re serving LLMs on Kubernetes, this is the real deal.
MLflow 3: Built for the GenAI Era
MLflow 3 launched in June 2025 and has evolved fast. The current stable release is MLflow 3.10.1 (March 2026), which now includes multi-workspace support, cost tracking for traces, a GenAI Overview dashboard with pre-built charts, and MemAlign, a new evaluation algorithm that learns from human feedback patterns. The platform now treats prompts and AI agents as first-class citizens alongside traditional models. Key features include comprehensive tracing powered by OpenTelemetry for debugging complex agent workflows, a LoggedModel entity that tracks entire GenAI application versions (not just model artifacts), and native support for popular frameworks like LangChain, LlamaIndex, and AutoGen. MLflow 3.5 added Claude Code SDK tracing support and flexible prompt optimization APIs, making it the go-to platform for teams building conversational AI and agent-based systems. MLflow now tracks token usage and cost per trace. When you’re running hundreds of agent calls a day, knowing what each one costs is important.
ZenML: Bridging Traditional ML and LLMOps
ZenML continues to excel as an integration layer that connects both platforms while adding its own capabilities. The platform’s pipeline-first approach now seamlessly handles both traditional ML workflows and modern LLMOps patterns, including RAG pipelines and multi-agent systems. ZenML’s Model Control Plane provides unified governance across traditional models and GenAI applications, addressing the critical need for audit trails in AI systems.
The Rise of AgentOps
Industry analysts identify 2025 as “the year of agentic AI,” with organizations moving beyond simple chatbots to autonomous AI agents that can reason, plan, and take actions. This evolution introduces new operational challenges: monitoring agent behavior, debugging multi-step reasoning chains, and ensuring safe autonomous operation. Both Kubeflow and MLflow are adapting their platforms to support these “AgentOps” requirements, with enhanced observability, safety controls, and tool orchestration capabilities.
Common Questions About Kubeflow vs MLflow
Which platform is better for LLM and GenAI projects in 2025? MLflow 3 has emerged as the leader for LLM operations, with native support for prompt engineering, agent tracing, and GenAI evaluation. However, if you need to fine-tune large models at scale on Kubernetes with GPU optimization, Kubeflow 1.10’s enhanced training operators and hyperparameter tuning for LLMs make it the stronger choice for compute-intensive GenAI workflows.
Can I use both Kubeflow and MLflow together? Absolutely. Many organizations use MLflow for experiment tracking and model registry while leveraging Kubeflow for pipeline orchestration and production deployment. ZenML makes this integration seamless by supporting both as pluggable stack components, allowing you to use MLflow’s tracking UI with Kubeflow’s scalable infrastructure.
Which platform has lower deployment time? Organizations using Kubeflow report 32% lower model deployment time once pipelines stabilize, according to 2024 research. However, MLflow enables 40% faster experimentation cycles due to its lightweight setup. The choice depends on whether you prioritize production deployment speed or rapid experimentation.
What about AI governance and compliance? Both platforms have significantly improved their governance features in 2025. MLflow 3 offers model lineage tracking, audit trails, and LLM-as-a-Judge evaluation for quality assurance. Kubeflow 1.10 enhanced security with rootless containers, CISO-compatible configurations, and comprehensive logging. For regulated industries, these governance features are now essential rather than optional.
Which platform is more cost-effective for startups? MLflow is typically more cost-effective for startups due to minimal infrastructure requirements—you can run it with a simple pip install. Managed MLflow services from providers like Databricks and AWS start around $0.36-0.64 per hour. Kubeflow requires a Kubernetes cluster, making it more expensive initially, though managed services like Civo’s Kubeflow-as-a-Service start at $271.58/month with auto-scaling that can reduce costs for variable workloads.
Which MLOps Platform Is Best For You?
If you’re deeply embedded in Kubernetes and need enterprise-scale orchestration and serving, you should use Kubeflow. Its native Kubernetes integration provides robust scalability, ideal for organizations already committed to K8s infrastructures.
For ML teams focused mainly on experiment tracking, model versioning, and ease-of-use, MLflow is a great MLOps solution. Its intuitive interface and flexible API integrations make it the go-to for quickly bringing experiments into organized, collaborative workflows.
However, if your team seeks a balanced solution that offers flexible yet powerful orchestration, extensive integrations, and easy-to-manage deployments, ZenML is the one for you.
ZenML uniquely bridges experimentation and production, which allows ML engineers and data scientists to switch seamlessly between local and cloud-based workflows without steep infrastructure learning curves.
Quick Decision Framework:
- Choose Kubeflow when you have: Existing Kubernetes infrastructure, need for GPU orchestration at scale, 10+ models in production, DevOps expertise, or requirements for distributed training and large-scale LLM fine-tuning
- Choose MLflow when you prioritize: Rapid experimentation cycles, lightweight infrastructure, ease of onboarding for data scientists, GenAI application development with agents and RAG, or multi-framework flexibility
- Choose ZenML when you need: Flexibility to switch between orchestrators, pipeline-centric development workflows, integration with both Kubeflow and MLflow, simplified production deployment without Kubernetes complexity, or unified governance across traditional ML and LLMOps
Book your personalized demo with us today. The demo gets you a 1on1 session with ZenML’s founder. Book a call and know how ZenML uniquely bridges experimentation and production, which allows ML engineers and data scientists to switch seamlessly between local and cloud-based workflows without steep infrastructure learning curves.