On this page
Hello there! Today, we’re back to LLM land (Not too far from Lalaland). Not only do we have a new LoRA + Accelerate-powered finetuning pipeline for you, we’re also hosting a RAG themed webinar. Enough content to fill the entire month and satisfy your LLMOps curiosities. Let’s dive in..
Learnings from Building with LLMs
Back to LLMs for this edition: Over the past year, significant insights have emerged from building with large language models (LLMs) in production, and I wanted to synthesize my thoughts here:
Understanding fundamental prompting techniques is crucial, including n-shot prompts and in-context learning, which require a sufficient number of detailed examples to guide the LLMs effectively. Chain-of-Thought (CoT) prompting has shown to reduce hallucinations by helping models outline their reasoning before generating the final response. Structuring inputs and outputs to match the model’s training data format, such as using XML for Claude and JSON for GPT, also significantly improves performance. Additionally, decomposing complex prompts into multiple, simpler parts allows for more precise and manageable workflows.
When moving from development to production, regularly reviewing LLM inputs and outputs is essential to understand data distribution and detect anomalies or drift. As elsewhere in MLOps, it’s necessary to manage the differences between development and production data to maintain model accuracy. Structured outputs, such as JSON or YAML, ensure smoother downstream integration. Despite the allure of sophisticated models, exploring smaller, less resource-intensive models can often yield comparable or better results while optimizing for latency and cost. Design involvement early in the product development process is vital to ensure intuitive user experiences, particularly when incorporating Human-in-the-Loop (HITL) systems, which facilitate continuous improvement through user feedback.
Here are five good practices to consider when building with LLMs:
- Regular Data Review: Periodically check LLM inputs and outputs to maintain accuracy.
- Structured Outputs: Use machine-readable formats to ease integration with downstream systems. Use tools like Instructor or Outlines to coerce outputs into these formats.
- Model Pinning: Pin specific model versions to avoid unpredictable changes.
- Design Involvement: Engage design teams early for better user experience.
- Human-in-the-Loop Systems: Integrate feedback mechanisms to enhance data quality and model refinement.
A hands-on take on a lot of these core principles is explored in our LLMOps guide, which is nearly complete! Check it out today and reply to this email to share feedback!
Finetuning LLM Project
We have a new LLM template + project for the community! Andrei created this from scratch and finetuned Mistral in a distributed setting to make sure it works. All you need to do is follow the README instructions to finetune it on your data!
ZenML Product Corner
Fresh new docs
We’ve heard many times that old docs indexed by search engines and hard-to-search docs make the ZenML experience slightly tougher. We’ve taken your feedback into account and made the docs easier to understand and search through.
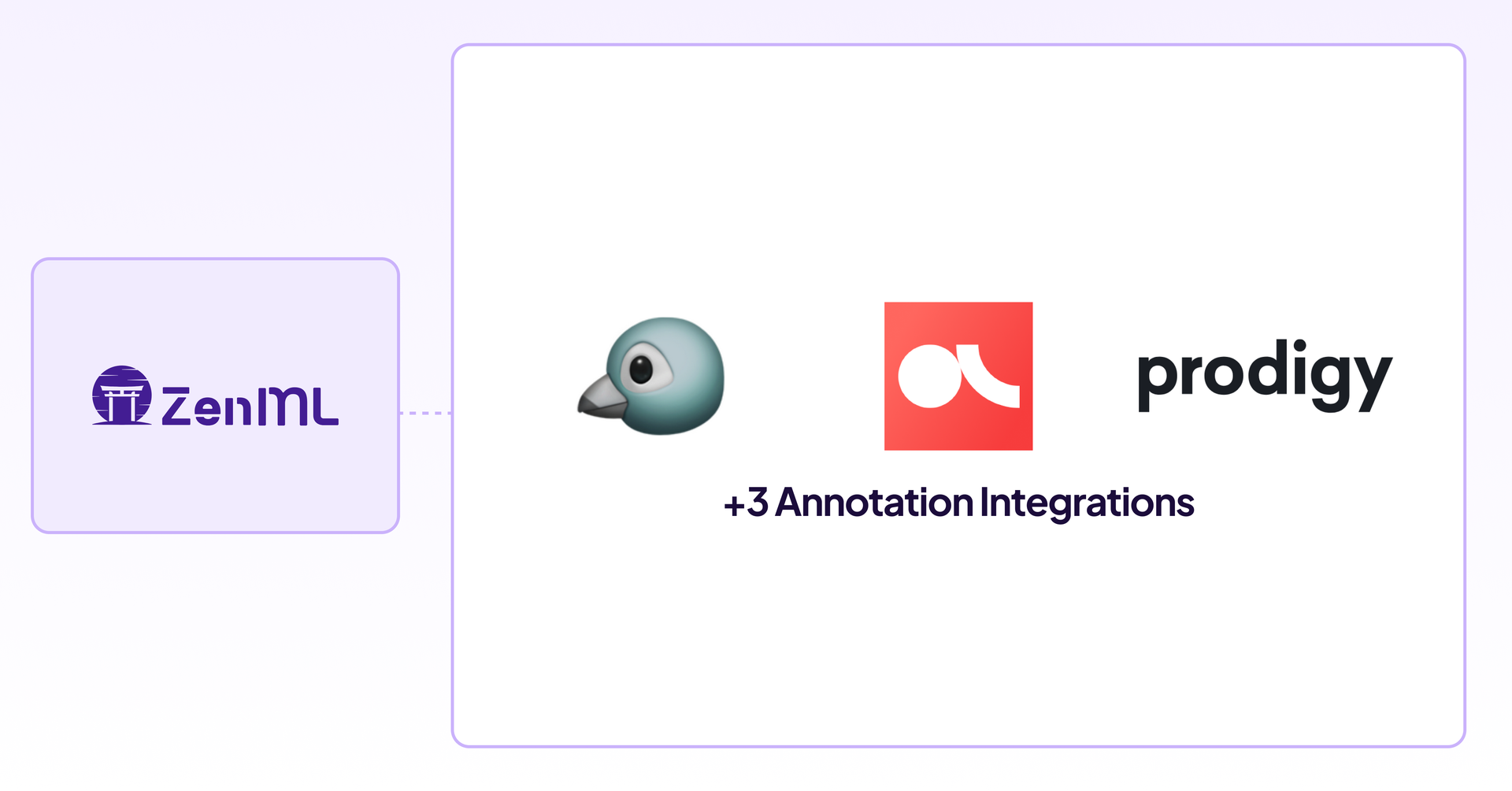
+3 New Annotator Integrations
Following the computer vision webinar, we realized we missed a few integrations in that space. The 0.58.0 release brings in three new integrations for the annotator stack component: Prodigy , Argilla, and Pigeon. Check it out by updating your ZenML!
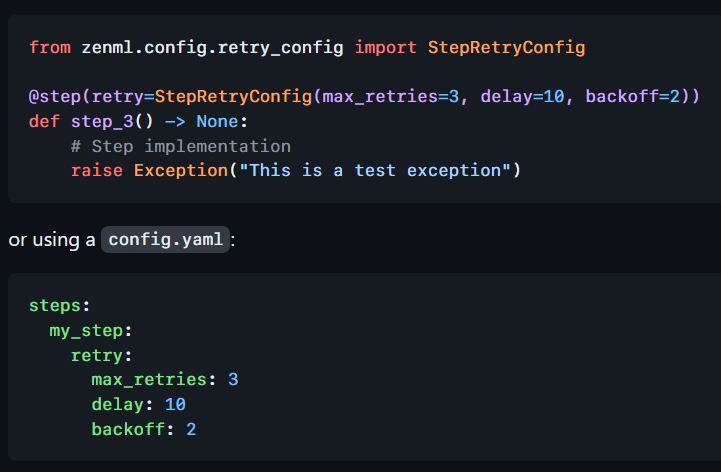
Retry configuration for Steps
The 0.58.0 release also includes new retry configuration for the steps. The following parameters can be set: StepRetryConfig(max_retries=3, delay=10, backoff=2)
Fresh from the community
Reusing pipelines across projects
New community member John W Oliver started a fantastic thread on how to share a data loading step in a pipeline between different projects. Michael replied with a clever solution using the log_artifact_metadata method.
The advantage of adopting ZenML
Julien Beaulieu started an insightful discussion on how a team who has a mature software engineer setup can leverage ZenML to adopt better MLOps practices and still keep the benefits of their legacy infrastructure
Register free for the LLM Webinar
An hour of a practical hands-on session about RAG pipelines

- The process of ingesting and preprocessing data for your RAG pipeline
- The critical role of embeddings in an RAG retrieval workflow
- How ZenML simplifies the tracking and management of RAG-associated artifacts
- Strategies for assessing the performance of your RAG pipelines
- The use of rerankers to enhance the overall retrieval process in your RAG pipeline
If you have any questions or need assistance, feel free to join our Slack community.
Happy Developing!
Hamza Tahir