On this page
Every planning cycle, valuable time is wasted on the same circular debate:
- "Let's move everything to Databricks, one throat to choke."
- "We're already on GKE—just run Kubeflow and call it a day."
- "Why not Vertex AI? It's managed, less yak‑shaving."
Meanwhile, real projects stall, PoCs fork into snowflake repositories, and your engineering team rewrites infrastructure code instead of delivering value. Here’s the uncomfortable truth: your organization will inevitably use multiple ML platforms anyway. Acquisitions bring new tech stacks, compliance requirements demand specific deployments, and evolving business needs shift infrastructure priorities.
The question isn’t “which platform should we standardize on?” but “how do we make our ML pipelines portable across whatever platforms we’ll need to use?”
The platform landscape — more diverse than you think
| Platform Type | Examples | Typical sweet‑spot | Inevitable Challenges |
|---|---|---|---|
| K8s-backed Platforms | GKE, EKS, AKS, OpenShift | Cloud-native microservices, teams fluent in Kubernetes | Infra maintenance overhead, YAML complexity, cross-region deployment |
| SaaS Data Platforms | Databricks, Snowflake, Dataiku | Unified data workflows, SQL/notebook-centric teams, rapid prototyping | License costs, vendor lock-in, limited customization, compliance constraints |
| Open-source Orchestrators | Kubeflow, Airflow, MLflow, Flyte | Full control, on-prem requirements, regulated industries | Integration complexity, maintenance burden, expertise requirements |
| Cloud ML Services | Vertex AI, SageMaker, Azure ML | Managed infrastructure, integration with respective cloud ecosystems | Cloud-specific patterns, egress costs, limited portability |
| Edge/Hybrid Solutions | Azure IoT Edge, AWS Greengrass, TensorRT | Edge deployment, offline capability, hardware optimization | Divergent deployment patterns, synchronization complexity |
Reality check: Analyst research consistently shows that most companies no longer bet on a single ML stack:
- 71% of enterprise AI teams rely on two or more ML platforms, according to Omdia's "Selecting an Enterprise MLOps Platform" report (2021).
- IDC's Cloud Pulse survey (Q3 2024) found 79% of organizations already run workloads across multiple cloud providers, further confirming the multi-platform trend across infrastructure layers.
This isn’t a failure of standardization—it reflects the reality that different tools excel at different stages of the ML lifecycle (e.g., a SaaS platform for feature engineering paired with a Kubernetes orchestrator for model serving).
Why multi-platform is inevitable, not optional
The multi-platform reality isn’t a planning failure—it’s a response to business needs. Your data science team prefers interactive notebooks. Your production engineers optimize for reliability and scalability. Compliance requires certain workloads remain on-premise. An acquisition brings Azure-based systems into your GCP environment. A strategic partner insists on their Snowflake-based data share.
Instead of fighting this reality with endless standardization debates, smart teams focus on creating a portable abstraction layer that allows them to:
- Write ML pipeline code once
- Deploy it anywhere the business requires
- Maintain consistent lineage and governance across platforms
- Adapt quickly when infrastructure needs change
Real-World Example: DENSO Corporation
DENSO, one of the world’s largest automotive suppliers, faced serious challenges building their connected car platform. They needed to support ML workloads across vehicle edge computers (with limited connectivity) and cloud platforms. Their solution? A unified Kubernetes architecture that spans from vehicle edge to multiple managed Kubernetes services (GKE, EKS, AKS). As a Tier-1 supplier working with multiple vendors, DENSO recognized that “trying to have the same portability between vehicle edge and cloud platform” was essential—maintaining two separate systems wasn’t viable as they scaled to thousands of vehicles.
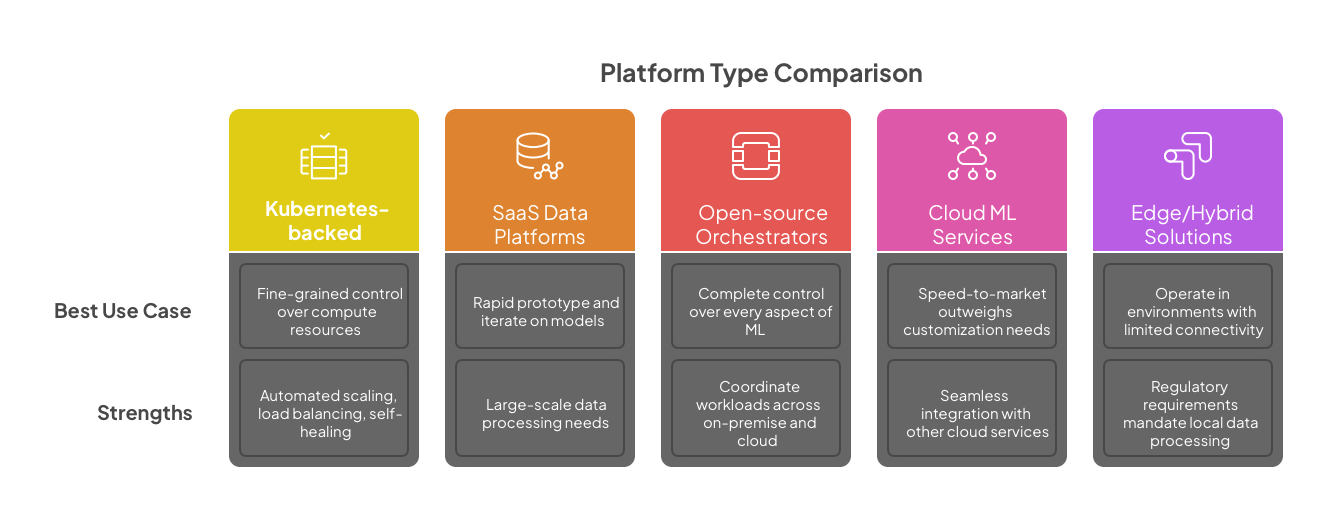
When each platform type excels
Each platform category serves a specific set of needs in the ML lifecycle, which is precisely why organizations inevitably end up using multiple platforms. Understanding these strengths helps teams make informed decisions about where to deploy specific workloads—while maintaining portable pipeline code that can move between platforms.
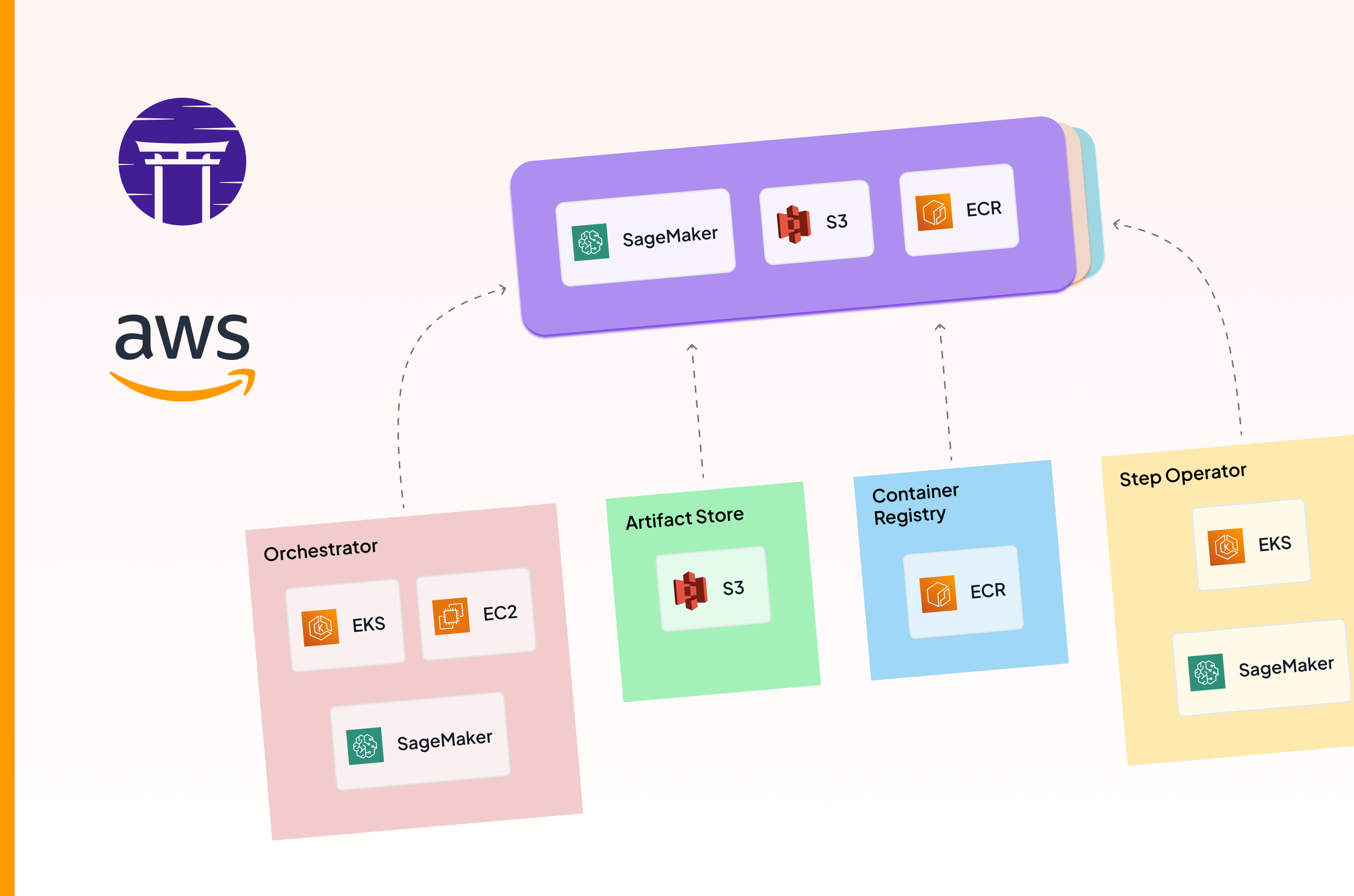
Kubernetes-backed Platforms shine when…
Kubernetes-based platforms like GKE, EKS, and AKS deliver exceptional value when your organization needs fine-grained control over compute resources and infrastructure. Their containerized approach makes them ideal for teams that have already invested in cloud-native architectures and need to run inference at scale alongside other microservices.
These platforms excel at workloads that benefit from automated scaling, load balancing, and self-healing capabilities. When your production engineers need to integrate ML systems with existing DevOps practices—including GitOps deployment, canary releases, and robust observability—Kubernetes platforms provide battle-tested solutions.
SaaS Data Platforms excel when…
Data-centric SaaS platforms like Databricks and Snowflake become indispensable when your data scientists need to rapidly prototype and iterate on models without managing infrastructure. Their notebook-centric environments combine code, visualizations, and collaboration in ways that accelerate experimentation.
These platforms particularly shine for organizations with large-scale data processing needs, where the integrated processing engines (like Spark) and optimized storage formats provide significant performance advantages. When your teams need to seamlessly transition from interactive exploration to scheduled production jobs without changing their environment, these platforms offer compelling workflow continuity.
Open-source Orchestrators thrive when…
Open-source orchestration frameworks like Kubeflow, Airflow, and MLflow become essential when your organization requires complete control over every aspect of the ML lifecycle. They’re the platform of choice for regulated industries with strict compliance requirements, air-gapped environments, or teams with unique workflow patterns that commercial platforms don’t accommodate.
These orchestrators excel in hybrid scenarios where you need to coordinate workloads across on-premise and cloud environments under a unified control plane. When you need to avoid vendor lock-in while maintaining the flexibility to customize every component of your ML system, open-source orchestrators provide the necessary foundation.
Cloud ML Services deliver when…
Cloud-native ML services like Vertex AI, SageMaker, and Azure ML provide exceptional value when speed-to-market outweighs customization needs. Their fully-managed infrastructure eliminates operational overhead, allowing teams to focus exclusively on model development rather than platform maintenance.
These services particularly shine when you need seamless integration with other services in the same cloud ecosystem. When your organization values automated MLOps capabilities like model monitoring, versioning, and deployment without building these systems from scratch, cloud ML services offer pre-built solutions that accelerate development cycles.
Edge/Hybrid Solutions become critical when…
Edge computing platforms become indispensable when your models need to operate in environments with limited connectivity, strict latency requirements, or specialized hardware. They excel at bringing ML capabilities to remote locations, IoT devices, and scenarios where sending data to the cloud isn’t practical.
These solutions shine when regulatory requirements mandate local data processing, or when real-time inference is needed for time-sensitive applications. When your organization needs to distribute intelligence across a network of devices while maintaining central management, edge platforms provide the necessary architecture.
…and when each reveals its limitations
The multi-platform reality becomes most apparent when you encounter the inherent limitations of each platform type. These constraints aren’t design flaws—they’re natural trade-offs that emerge from each platform’s architectural choices and priorities.

Kubernetes-backed Platforms falter when…
The flexibility of Kubernetes comes at a cost of complexity. Organizations frequently underestimate the operational burden of maintaining these platforms, especially as they scale. The infamous “YAML sprawl” can quickly overwhelm teams without dedicated platform engineers, while multi-region deployments introduce challenging problems around secret management, networking, and observability.
Cross-environment consistency becomes particularly challenging, as subtle differences between cloud provider implementations can lead to mysterious runtime behaviors. And while Kubernetes excels at orchestrating containers, it provides no inherent data processing capabilities—requiring teams to bolt on additional components for ML-specific needs.
SaaS Data Platforms stumble when…
The convenience of SaaS platforms often collides with harsh economic realities as scale increases. What starts as an affordable solution can quickly transform into budget-breaking expenses as workloads grow. The notorious “pay-as-you-go becomes pay-as-you-gasp” phenomenon has derailed many ML initiatives that failed to accurately forecast costs.
These platforms also impose significant limitations for sensitive workloads, with compliance requirements sometimes forcing organizations to maintain parallel infrastructure for regulated data. The vendor lock-in concerns are real, as deep integration with proprietary APIs and storage formats can make migration painfully expensive.
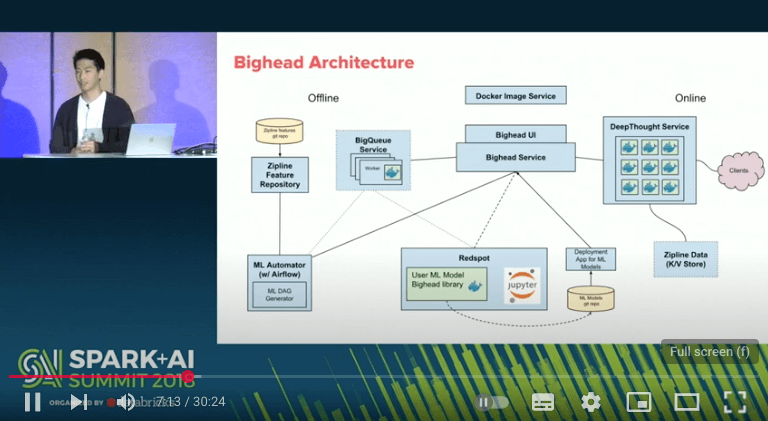
Real-World Example: Airbnb’s ML Architecture
Airbnb’s machine learning infrastructure highlights this multi-platform challenge. With ML needs spanning search ranking, pricing recommendations, and fraud detection, Airbnb required a solution that worked across diverse infrastructure. Rather than standardizing on a single platform, Airbnb developed Bighead—a unified ML platform that allows data scientists to develop in notebook environments but deploy to various infrastructure backends. This approach recognized that different ML workloads had different requirements, and forcing everything into a single platform would compromise either development speed or production efficiency.
Learn about Airbnb’s Bighead →
Open-source Orchestrators struggle when…
The freedom of open-source comes with substantial maintenance overhead. Organizations consistently underestimate the resources required to keep these platforms operational, especially through major version upgrades. The “community documentation gap” means teams often find themselves alone when troubleshooting obscure issues in complex deployments.
Integration challenges multiply when connecting these orchestrators to enterprise systems, and the lack of commercial support means your team becomes responsible for security patches and compatibility issues. The flexibility that makes these platforms attractive also means more decisions, more components to maintain, and more potential failure points.
Cloud ML Services disappoint when…
The convenience of cloud ML services evaporates when organizations need to work across multiple cloud providers or incorporate on-premise workloads. The proprietary nature of these services creates significant friction for multi-cloud strategies, while data transfer costs between regions or providers can quickly escalate into budget concerns.
These services also impose architectural constraints that may conflict with existing systems, forcing uncomfortable compromises or parallel implementations. When customization needs evolve beyond what the service offers, organizations find themselves hitting frustrating capability ceilings that require either complex workarounds or painful migrations.
Edge/Hybrid Solutions falter when…
The distributed nature of edge deployments introduces significant complexity in model management, versioning, and synchronization. Organizations frequently underestimate the operational challenges of maintaining consistent ML capabilities across heterogeneous devices with varying capabilities and connectivity patterns.
The resource constraints of edge environments force difficult compromises in model size and capability, while the diversity of deployment targets creates painful fragmentation in operational processes. When business needs require rapid model updates across the entire device fleet, edge architectures can introduce frustrating delays and inconsistencies.
The inevitable multi-platform journey
What emerges from this landscape isn’t a recommendation to choose the “best” platform—it’s a recognition that each platform type serves different aspects of the ML lifecycle. The real challenges arise when organizations attempt to standardize on a single platform, only to discover that changing requirements, acquisitions, or new business initiatives invariably lead to multi-platform environments.
Regional data regulations might force specific workloads into European data centers while others remain in US clouds. An acquisition brings Azure-based ML systems into your GCP-centric architecture. Your edge devices require specialized deployment pipelines that don’t match your cloud patterns. A critical partner insists on data exchange through their Snowflake instance.
Real-World Example: DoorDash’s Multi-Platform ML Architecture
DoorDash’s ML infrastructure perfectly illustrates the multi-platform reality. They use Apache Airflow for scheduling training jobs, AWS S3 for model storage, and Kubernetes for deploying their prediction service (“Sibyl”). Their feature store leverages Redis for caching, while their model serving layer supports both shadow predictions and A/B testing. Rather than forcing all these components into a single platform, DoorDash created a unified abstraction layer that allows different services to use the appropriate infrastructure while maintaining consistent lineage. This approach has allowed them to scale their ML operations while keeping their data scientists focused on business impact rather than infrastructure integration.
Explore DoorDash’s ML architecture →
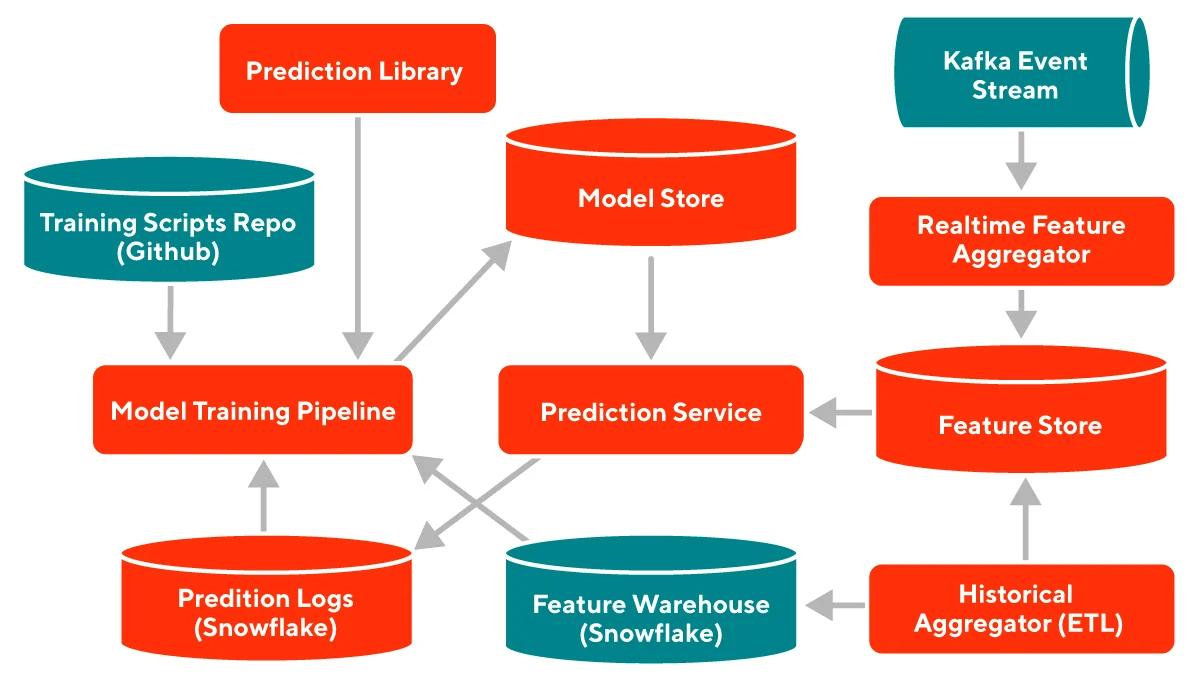
These scenarios aren’t exceptions—they’re the rule. The question isn’t whether you’ll operate in a multi-platform world, but how effectively you’ll navigate it.
The Solution: Decouple What Your Pipeline Does from Where It Runs
After examining the inevitable multi-platform reality, the solution becomes clear: stop tying your ML code to specific platforms. The organizations in our examples all embraced a similar principle—separating what their pipelines do from where they run.
Think of ML pipelines like shipping containers: standardized boxes that travel seamlessly via truck, rail, or cargo ship. The logistics layer changes, but the container—with all its contents—remains intact.
This decoupling approach delivers key benefits:
- Declarative pipeline definitions describe what your workflow does—not how the infrastructure provisions resources
- Pluggable orchestration backends allow the same pipeline to run on GKE today, Databricks tomorrow, and Kubeflow next month without changing code
- Centralized artifact tracking maintains consistent lineage across platforms, ensuring governance and reproducibility
When Kubernetes becomes too complex, shift components to a managed service. When SaaS costs explode at scale, migrate compute-intensive portions to your infrastructure. When compliance requires on-premises processing, route only those components to your private cloud.
Enter ZenML
ZenML gives you a standard abstraction: a Python SDK where you define pipelines once, swap an orchestrator or stack, and rerun on any of the orchestrators we support (or write your own custom one!).
# !zenml stack set kubeflow (swap to "databricks" or "gke" later)
@step
def trainer(data: pd.DataFrame) -> Model:
…
@pipeline
def forecast_pipeline():
df = ingest()
model = trainer(df)
deploy(model)No step code changes. Switching from Databricks dev cluster to GKE prod is a single CLI call:
zenml orchestrator register gke_prod --flavor=kubernetes ...
zenml stack register gke --orchestrator gke_prod --artifact_store gcs_bucket
python run.py --stack=gkeCommon objections to portable pipelines
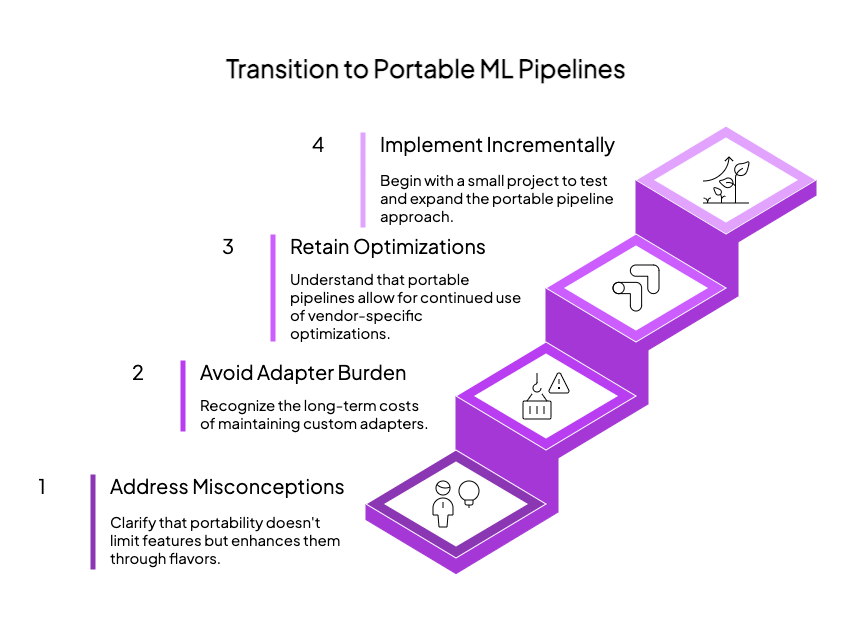
When organizations first consider a portable approach to ML pipelines, several concerns typically arise. Let’s address the most common ones:
“Portability means least-common-denominator features.”
This is a misconception. Modern abstraction layers like ZenML expose advanced platform-specific capabilities through pluggable components called flavors. You can still use Spark on Databricks, TPUs on Vertex AI, and GPUs on your on-premise clusters—all while maintaining the same core pipeline structure.
The key difference is that these platform-specific optimizations become configuration choices rather than code dependencies. When you need to leverage the unique capabilities of a specific platform, you simply configure the appropriate flavor without embedding platform-specific code throughout your pipeline.
“We can write adapters ourselves.”
Many teams start down this path, creating thin adapter layers that translate between their code and various platforms. This approach seems straightforward initially but becomes a significant maintenance burden as your ML systems mature.
The true cost emerges when you need enterprise-grade features like CI/CD integration, intelligent caching, artifact lineage, secrets management, monitoring dashboards, and multi-tenant isolation. Each of these capabilities must be implemented and maintained for every platform you support. This “glue code tax” compounds over time, draining resources that should be focused on model innovation.
“We’ll lose vendor optimizations we’ve worked hard to implement.”
Portable pipelines don’t require abandoning the specialized capabilities you’ve developed. Instead, they provide a framework where these optimizations can be cleanly separated from core pipeline logic.
For example, you can build your pipeline once but still access Databricks’ Delta Lake optimizations or Vertex AI’s hyperparameter tuning via step-specific integrations. The difference is that these integrations become modular components that can be swapped out rather than foundational dependencies that lock you in.
“This sounds complex to implement in our existing workflow.”
Transitioning to portable pipelines doesn’t require a “big bang” rewrite of your existing systems. The most successful organizations start with a single pipeline or team, prove the concept, and gradually expand. The decoupling approach can be applied incrementally, starting with new projects while existing systems continue to operate normally.
Cost lens — the hidden ROI of pipeline portability
While technical benefits of portable pipelines are compelling, the financial impact often drives executive decision-making. Our analysis of organizations that have adopted portable pipeline architectures reveals significant ROI across multiple dimensions:
| Cost category | Locked single‑vendor approach | Portable pipeline approach |
|---|---|---|
| Re‑platforming after M&A | 4–6 engineer-months of rewriting pipelines and fixing broken integrations | Configuration change + infrastructure provisioning = days of work |
| Edge roll‑out of computer vision models | Maintaining separate codebases for cloud and edge deployments | Same pipeline code deployed via KServe to both environments |
| Experiment → production lead‑time | 6–10 weeks of reengineering notebook code for production | 1–3 weeks from prototype to production (based on retail customer data) |
| Knowledge transfer during talent transitions | New team members spend weeks deciphering undocumented platform-specific implementations | Standardized patterns enable productive work after minimal onboarding |
| Platform evaluation costs | High-friction proof-of-concepts requiring significant rework for each potential platform | Run the same pipelines on multiple platforms to directly compare performance and cost |
The most dramatic ROI comes from avoiding forced re-platforming projects. When the business landscape changes (through acquisition, new compliance requirements, or cost-cutting mandates), portable pipelines transform what would have been months-long rewrites into configuration updates that can be completed in days.
Even a single avoided replatforming project can save hundreds of engineering hours and prevent significant disruption to your ML delivery pipeline—creating both direct cost savings and indirect business value through reduced time-to-market for model improvements.
Future-Proof Your ML Pipelines
Infrastructure changes are inevitable. Your ML platforms will evolve faster than your models. New vendors will emerge, compliance requirements will shift, and acquisitions will introduce new technology stacks. What remains constant is the business need to deliver ML value quickly and reliably.
Stop rewriting your pipelines every time your infrastructure changes. Define your ML workflows once, deploy them anywhere, and focus your precious engineering resources on solving business problems rather than reengineering infrastructure code.
Ready to make your ML pipelines platform-agnostic?
Try ZenML today:
- Install our open-source framework and run the quickstart examples
- Clone our multi-platform demo repository to see real-world examples
- Read our documentation to learn about integrations with your existing tools
Want expert guidance?
- Schedule a personalized demo with our team or startyour POC with our team to port over one of your existing pipelines!
- Join our Slack community to connect with other organizations solving similar challenges
The real question isn’t whether you’ll need to use multiple ML platforms—it’s whether you’ll be prepared when it happens. Start building platform-agnostic pipelines today, and transform infrastructure changes from painful migrations into simple configuration updates.