On this page
As someone who works closely with companies adopting ZenML into their AI workflows, I’ve seen firsthand the diverse range of use cases for large language models (LLMs). While much of the buzz around LLMs focuses on real-time applications like chatbots, I’ve found that batch processing is often an unsung hero – especially when it comes to cost efficiency.
One tool that’s been particularly valuable in this regard is OpenAI’s Batch Prediction Service. Launched in April, it allows users to process large amounts of data using OpenAI’s powerful language models at a fraction of the usual cost. For many of the companies I work with, this has been a game-changer.
In this post, I’ll share some of the use cases where I’ve seen batch processing shine, explain how OpenAI’s Batch Prediction Service works, and show you how you can start leveraging it either using the OpenAI website or in your own ZenML workflows. If you’re looking to get the most out of your LLM-powered applications while keeping costs down, this is definitely a feature worth paying attention to.
50% cost reduction for batch requests
The core benefit is around cost: batch request cost half the normal rate. Any items submitted for batch processing will be made available to you within 24 hours. With this reduction, certain use cases become affordable, particularly now that some of the models have multi-modal capabilities. Perhaps you want to label lots of image data, or add captions to content; this might be cost-effective with this batch pricing but not at the full rate.
Aside from the cost benefits, you get significantly higher token limits if you’re sending in batch requests which again may make certain use cases feasible which weren’t with the standard limits. See the OpenAI docs for the specific details but this chart sums it up, with TPD and TPM being tokens per day and minute respectively:
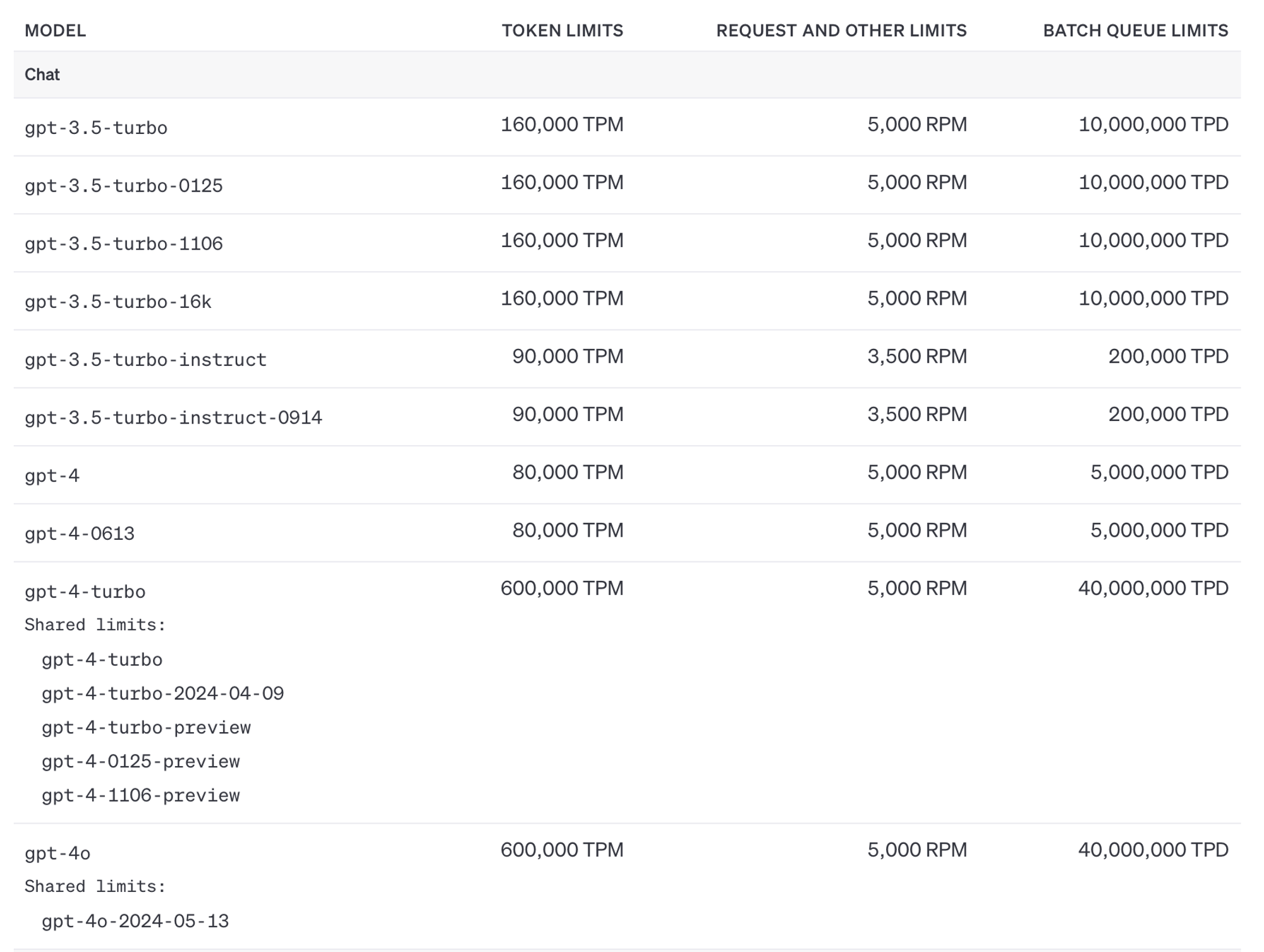
You should consider using the batch API for your use case includes some combination of the following:
- no real-time requirement (i.e. you’re fine waiting 24 hours to get your LLM call results back, though for smaller jobs you often get the processed jobs back much faster or even more or less immediately)
- a high-volume request for one of the multi-modal models (batch image processing for which you need an LLM, in other words; something like image captioning)
- a need for a larger, more powerful model like GPT-4 (which is slower to output, but much more expensive as well as more reliable / better performing on complex tasks)
With those 50% cost savings this might make the difference between a project or service that’s commercially viable and one that is just unaffordable.
How do I use the batch API?
Let’s discuss a real-world use case for batch processing with the OpenAI API. One interesting scenario could be a content creation platform that wants to generate summaries or metadata for a large number of articles. The platform might have a backlog of articles that need to be processed, or it may want to periodically generate summaries for newly added articles. Batch processing would be suitable in this case because the summary generation doesn’t need to happen in real-time as articles are added, but can be done efficiently on a large batch of accumulated content.
Here’s how it might work:
-
The platform collects articles over a certain period, say a day or a week.
-
At the end of each period, the collected articles are sent to the OpenAI API for summary generation using batch processing.
-
The API returns the generated summaries for each article.
-
The platform then stores the summaries along with the articles and uses them to improve features like search, previews, or recommendations.
This use case demonstrates how batch processing with the OpenAI API can help content platforms efficiently generate valuable metadata for a large number of articles, without the need for real-time processing. I’ll show you how to use the API to use the batch processing as well as the web UI.
Submission using the Python SDK / API
1. Prepare your data for submission
OpenAI require that you submit your data in the form of a JSONL file. The individual entries won’t necessarily be returned to you in order of submission so you can and should pass in a custom_id which will allow you to associate the original response with the inference that comes out. A sample of our data might look like this:
{"id": "batch_req_001", "custom_id": "article_1", "response": null, "error": null, "body": {"model": "gpt-3.5-turbo", "messages": [{"role": "system", "content": "You are a helpful assistant that summarizes articles."}, {"role": "user", "content": "Please summarize the following article:\n\nThe impact of climate change on global food production is becoming increasingly apparent. Rising temperatures, changing precipitation patterns, and more frequent extreme weather events are all affecting crop yields and food security around the world. Adaptation measures, such as developing drought-resistant crops and improving irrigation systems, will be crucial in mitigating the effects of climate change on agriculture. However, without significant reductions in greenhouse gas emissions, the long-term outlook for global food production remains uncertain."}]}}
{"id": "batch_req_002", "custom_id": "article_2", "response": null, "error": null, "body": {"model": "gpt-3.5-turbo", "messages": [{"role": "system", "content": "You are a helpful assistant that summarizes articles."}, {"role": "user", "content": "Please summarize the following article:\n\nArtificial intelligence (AI) is transforming industries across the board, from healthcare and finance to transportation and manufacturing. AI technologies, such as machine learning and natural language processing, are enabling businesses to automate processes, improve decision-making, and deliver more personalized products and services. As AI continues to advance, it is likely to have an even greater impact on the global economy, creating new opportunities and challenges for businesses and workers alike."}]}}
{"id": "batch_req_003", "custom_id": "article_3", "response": null, "error": null, "body": {"model": "gpt-3.5-turbo", "messages": [{"role": "system", "content": "You are a helpful assistant that summarizes articles."}, {"role": "user", "content": "Please summarize the following article:\n\nThe rise of remote work has been one of the most significant changes to the global workforce in recent years. Driven in part by the COVID-19 pandemic, more and more companies are embracing remote work as a way to reduce costs, improve employee satisfaction, and access a wider pool of talent. However, remote work also presents challenges, such as maintaining team cohesion and ensuring data security. As remote work becomes more prevalent, businesses will need to adapt their management practices and technologies to support a distributed workforce."}]}}
{"id": "batch_req_004", "custom_id": "article_4", "response": null, "error": null, "body": {"model": "gpt-3.5-turbo", "messages": [{"role": "system", "content": "You are a helpful assistant that summarizes articles."}, {"role": "user", "content": "Please summarize the following article:\n\nThe rapid growth of e-commerce has revolutionized the retail industry, providing consumers with unprecedented convenience and choice. Online marketplaces, such as Amazon and Alibaba, have become dominant players in the global economy, while traditional brick-and-mortar retailers have had to adapt to stay competitive. The rise of e-commerce has also had significant implications for supply chains, logistics, and consumer behavior. As e-commerce continues to evolve, it is likely to shape the future of retail in ways that are both exciting and unpredictable."}]}}
{"id": "batch_req_005", "custom_id": "article_5", "response": null, "error": null, "body": {"model": "gpt-3.5-turbo", "messages": [{"role": "system", "content": "You are a helpful assistant that summarizes articles."}, {"role": "user", "content": "Please summarize the following article:\n\nThe development of renewable energy technologies, such as solar, wind, and hydropower, is crucial for addressing the global challenge of climate change. Renewable energy sources offer a clean and sustainable alternative to fossil fuels, which are the primary driver of greenhouse gas emissions. Governments and businesses around the world are investing heavily in renewable energy, driven by a combination of environmental concerns, economic opportunities, and energy security considerations. As the costs of renewable energy continue to fall, it is becoming increasingly competitive with traditional energy sources, paving the way for a cleaner and more sustainable future."}]}}In a real-world use case we’d have hundreds or even thousands of these to pass in.
2. Send your data to OpenAI
You first have to upload your data to OpenAI’s servers before you can request the batch processing job. We can use their Files API to submit our data:
from openai import OpenAI
client = OpenAI()
batch_input_file = client.files.create(
file=open("batchinput.jsonl", "rb"),
purpose="batch"
)Note how we specify the purpose of the file upload as being for batch purposes.
3. Trigger the batch inference submission
Starting the job is easily accomplished with the Python SDK as well:
batch_input_file_id = batch_input_file.id
client.batches.create(
input_file_id=batch_input_file_id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={
"description": "nightly summarisation job"
}
)Don’t think that you can change the completion_window value, since at the moment OpenAI off only the 24h option.
4. Wait!
It’s possible that OpenAI might be done with the batch inference earlier than 24 hours from submission, but not guaranteed. If you want to check the status of your batch, you can query the API, for example here using curl:
curl https://api.openai.com/v1/batches/batch_abc123 \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \You should replace batch_abc123 with your specific batch id that you received back from OpenAI when you submitted the batch.
5. Download your data
When the processing is complete, your files will be downloadable using the OpenAI Files API:
from openai import OpenAI
client = OpenAI()
content = client.files.content("file-xyz123")You’ll need the output_file_id to download these successfully processed entries. If there were any that didn’t complete or where there was some kind of error, use the error_file_id to download full details of what went wrong.
Submission using the Web UI
You can accomplish everything above by using the OpenAI platform’s web UI. Let’s walk through the steps.
1. Upload your data
We already have a file, so we can just submit it directly. OpenAI will then validate that the file is in the right format and then directly schedule the batch predictions.
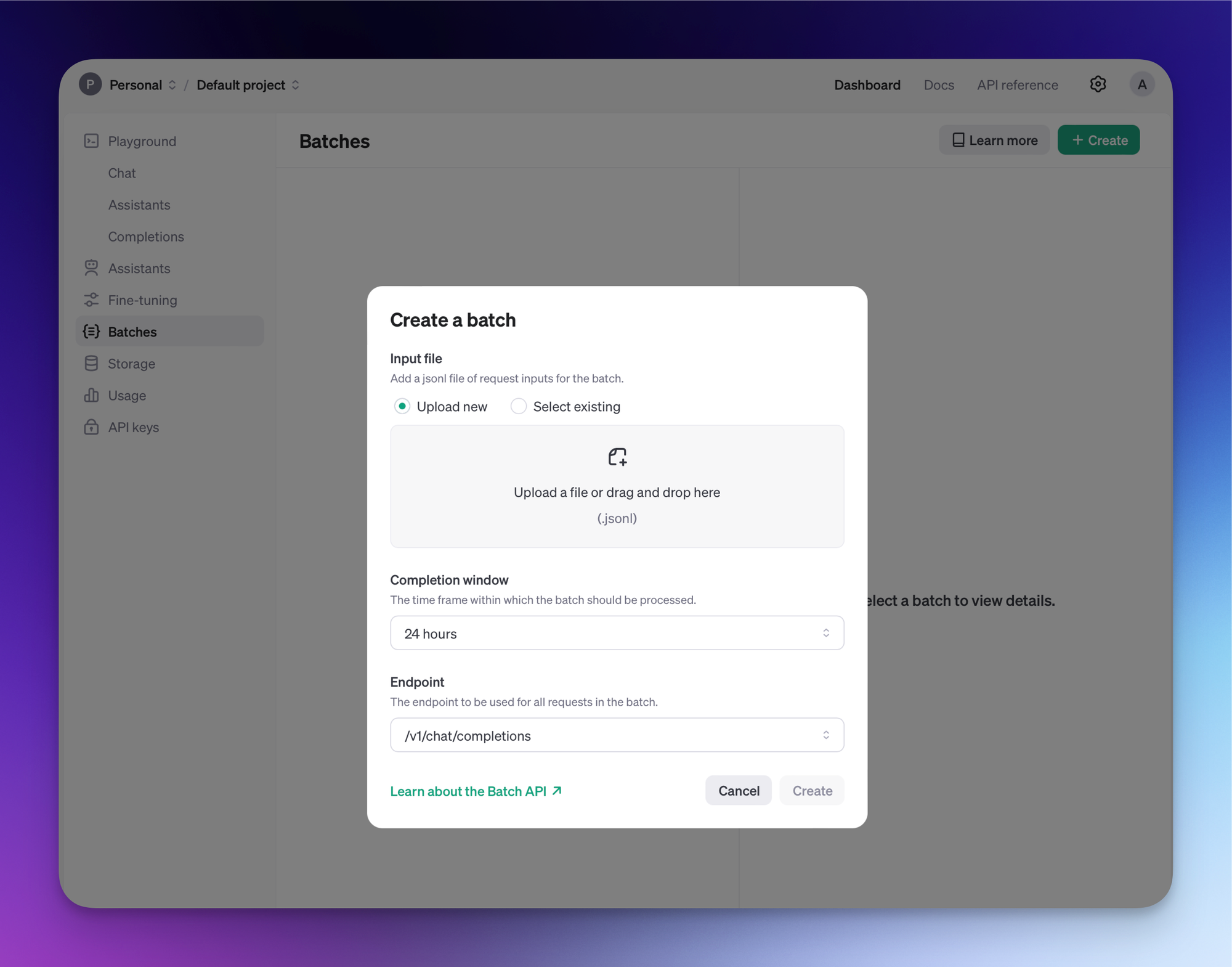
2. Download the predictions when ready
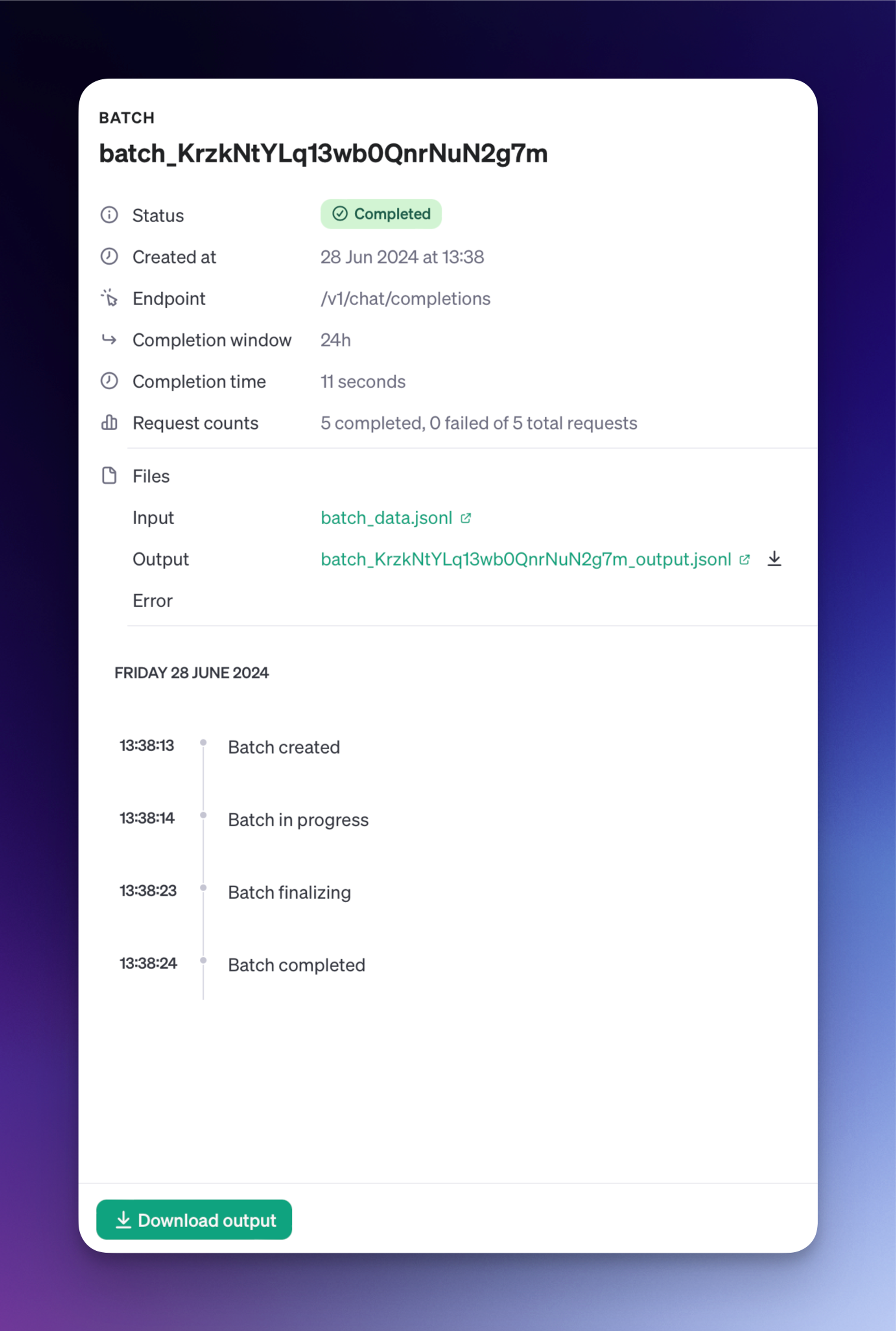
Depending on the size of the predictions, you will have to wait some time until they are ready. The five queries I submitted (see above for the actual prompts) were returned to me in 11 seconds actually, so this goes to show that you might receive your responses significantly faster than 24 hours.
You can download the data programatically as above, or you can just click the ‘Download output’ button. Our data is back and here’s one of the responses:
{
"id": "batch_req_uRFR2SlLNONnV3XNEB9u5hWA",
"custom_id": "article_1",
"response": {
"status_code": 200,
"request_id": "eace91e97e70f528f3e009036f584e4c",
"body": {
"id": "chatcmpl-9f4DicKRJuXYkIAGmoJEOH0OioqKP",
"object": "chat.completion",
"created": 1719574698,
"model": "gpt-3.5-turbo-0125",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The article discusses how climate change is affecting global food production through rising temperatures, changing precipitation patterns, and more frequent extreme weather events. It emphasizes the importance of adaptation measures like developing drought-resistant crops and improving irrigation systems to mitigate these effects. However, without substantial reductions in greenhouse gas emissions, the future of global food production is uncertain."
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 115,
"completion_tokens": 66,
"total_tokens": 181
},
"system_fingerprint": null
}
},
"error": null
}These ways of manually triggering batch predictions are all right for one-off prediction jobs or perhaps when you have something small you need processing, but when you start to have something that you need to perform repeatedly and at scale, you’ll probably want to add some kind of system or process around how you get the batch predictions. Next I’ll show you how you can run a pipeline in ZenML to submit your queries, schedule another pipeline to automatically fetch the results when they’re ready and then use those predictions in a subsequent pipeline.
Use ZenML to handle your batch predictions
You’ll want some kind of orchestration tool to handle repeatable workloads at scale. For orchestrators, ZenML integrates out of the box with twelve commonly-used tools like AWS Sagemaker and Google’s VertexAI so you can schedule your jobs to run in the cloud as part of your bigger machine learning workflows. (For the following code, there’s a prerequisite of having set up your Vertex orchestrator with a cloud artifact store and a cloud container registry, and then registering that all with ZenML as a stack. Check out our guide to doing that if you’re interested in getting started with GCP or AWS.) Here’s how you’d set that up:
1. Define the pipeline that submits the batch for processing
As above with the web UI, we load in a local file (see above for what this .jsonl file would look like), submit it to OpenAI and then schedule a batch processing job:
import tempfile
from openai import OpenAI
from zenml import pipeline, step, ExternalArtifact
from zenml.client import Client
from zenml.config import DockerSettings
docker_settings = DockerSettings(
requirements=[
"openai",
"google-cloud-scheduler",
]
)
@step
def submit_batch(json_batch: str) -> str:
zc = Client()
openai_key = zc.get_secret("openai").secret_values["api_key"]
client = OpenAI(api_key=openai_key)
# save the json_batch string to a temp file in .jsonl format
with tempfile.NamedTemporaryFile(
mode="w", suffix=".jsonl", delete=False
) as temp_file:
temp_file.write(json_batch)
temp_file_path = temp_file.name
batch_input_file = client.files.create(
file=open(temp_file_path, "rb"), purpose="batch"
)
batch_input_file_id = batch_input_file.id
batch = client.batches.create(
input_file_id=batch_input_file_id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"description": "nightly eval job"},
)
return batch.id
@pipeline(settings={"docker": docker_settings}, enable_cache=False)
def submit_batch_inference():
submit_batch(
ExternalArtifact(
value=open("/Users/strickvl/Desktop/batch_data.jsonl", "r").read()
)
)2. Define a step to check for the status of the processing
Now we need to define a step (and pipeline) that we can use to check if the job is ready.
from openai import OpenAI, NotFoundError
from zenml import pipeline, step
from zenml.client import Client
from zenml.config import DockerSettings
@step
def download_batch_inference() -> Optional[str]:
zc = Client()
openai_key = zc.get_secret("openai").secret_values["api_key"]
client = OpenAI(api_key=openai_key)
last_successful_run = zc.get_pipeline(
"submit_batch_inference"
).last_successful_run
batch_id = (
last_successful_run.steps["submit_batch"].outputs["output"].load()
)
try:
response = client.batches.retrieve(batch_id)
status = response.status
output_file_id = response.output_file_id
except NotFoundError as e:
logger.error(f"Batch {batch_id} not found: {e}")
return None
if status == "completed":
# pause the scheduled vertex run
scheduled_job = aiplatform.PipelineJobSchedule.list(
order_by='create_time desc',
filter='display_name:"batch_inference_loader"',
location="europe-west3",
)[0]
scheduled_job.pause()
return client.files.content(output_file_id).text
else:
return None
@pipeline(
settings={"docker": docker_settings},
enable_cache=False,
)
def batch_inference_loader():
download_batch_inference()We get our API key from the ZenML Secret Store, then get the last successful run of the pipeline defined in step 1. We can use this pipeline run to get the batch_id which OpenAI needs to look up our batch job. Then we either return the content of the job or None.
3. Schedule the pipeline to check the status and get notified when the job is complete
Notice how in the download_batch_inference step we included some code to look up the most recent scheduled job and pause it if we managed to successfully download the batch inference results. This is because when we run the pipeline we set it as a repeating pipeline on a schedule, in our case re-running the step every 45 minutes:
from zenml.config.schedule import Schedule
submit_batch_inference()
schedule = Schedule(cron_expression="*/2 * * * *")
batch_inference_loader.with_options(schedule=schedule)()So our pipeline keeps running in your cloud orchestrator of choice, every 45 minutes, until the data is ready. Of course you can configure the retry to happen at a less frequent pace and you could even consider connecting this up to one of our inbuilt Alerter components to get a message in your Slack or Discord if you wanted to receive a ping that this completed successfully.
Of course, all your runs and metadata are visible and inspectable via the ZenML dashboard:
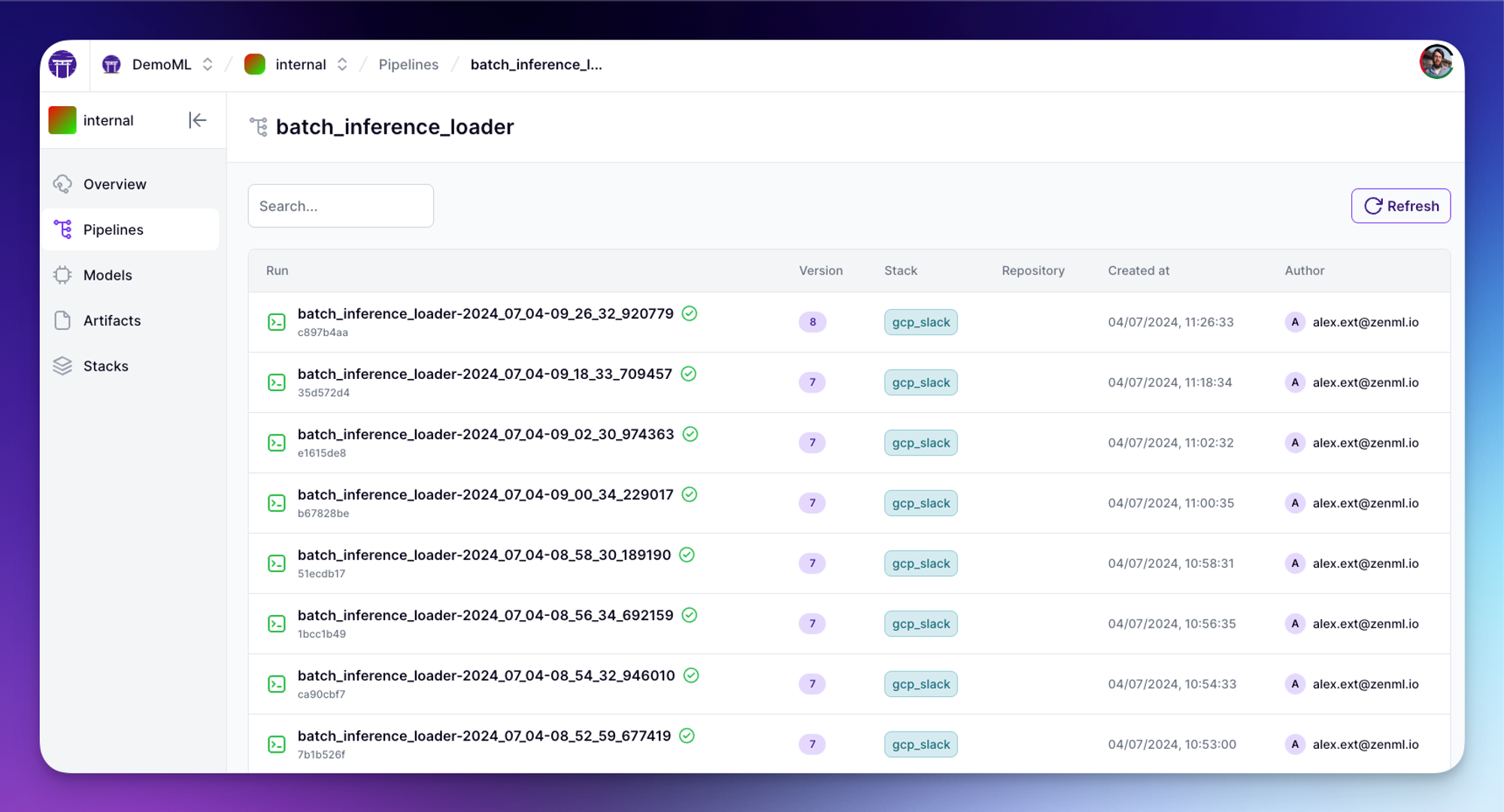
And to access the data you can just use the Python SDK to access the data, or alternatively just pass the output of this pipeline into another pipeline for processing for LLM finetuning or whatever your specific use case is!
👀 Gotcha Corner: Things to watch out for
As you’ve seen, the Batch API saves you a bunch of money and using ZenML to submit your inference jobs adds a lot of convenience. There are some caveats that you should bear in mind:
- Not All Models are Available for the Batch API: You’ll have to experiment a bit with this, since OpenAI’s documentation isn’t consistent. GPT-4o, for example, is listed as being supported in their main guide but their Batch API FAQ doesn’t include it. Of particular note is that the
text-moderation-...models are not currently supported. - Max Content Sizes: There are some limits with the amount of text that you can both submit in a single batch or in terms of how many examples you can submit. As of July 2024, a single batch may include up to 50,000 requests, and a batch input file can be up to 100 MB in size, but this may change.
- Max enqueued tokens per day: There are also some aggregate limits on how many tokens you can get processed per day, but as I noted above this is a separate limit / token count from the normal API limits so probably you won’t be hitting these limits.
- Zero data retention doesn’t apply: If you have zero data retention enabled for your organisation, note that zero data retention is not supported on the Batch API / endpoint. This is buried somewhere in the FAQ so if you care about this, make sure only to use the standard full-priced endpoints.
50% off for asynchronous use cases is a no-brainer
The 24-hour period stated in the OpenAI documentation is of course their stated maximum wait that you’d need for any batch jobs submitted, but in my experience for smaller jobs you often get the results almost immediately. If you can afford (time) to batch your inference up in this way, allowing for the possibility that it might take on the order of hours to get your results, you probably want to look into using the OpenAI Batch API.
At the risk of coming across as too enthusiastic about this OpenAI feature, if your use case fits the batch prediction model and you’re fine with an ‘out of the box’ cloud LLM provider then it’s a no-brainer to use the Batch API. Similarly, if you’re working with images and want to quickly annotate data using the latest models like gpt-4o for captioning or similar tasks, then it’s really going to make sense for you to use this API since images can be quite token-heavy and potentially your use case might be otherwise impossible without the cost savings.
It’s also not as if the OpenAI models are poor performers! For the most part they’re excellent general-purpose LLMs that you can use to solve many kinds of tasks and if it makes sense for you then I hope that this blog has given you some pointers on how it works and how you can use it with ZenML.
We run webinars about this and other topics relating to LLMs, machine learning and MLOps. Sign up to the ZenML newsletter to keep up-to-date with upcoming webinars and our latest updates!