On this page
Welcome to the ZenML newsletter!
Hello there! This is Hamza, co-founder of ZenML. The fact that you are receiving this newsletter is either because you signed up directly or created an account on ZenML Cloud. Either way, I’m happy to see you, and hope you’re having a lovely day!
We started this newsletter because the MLOps & LLMOps world is crazy right now, and we wanted a place to share with the ZenML community our thoughts as we navigate it. Personally, I really enjoy how Tristan Handy (founder of dbt Labs) approaches newsletters. They are more like essays on his team’s current thought process, and I find them fascinating reads. We’ll try to keep these equally personal, and shed some light on the ZenML perspective in the space.
I took a look at the people who’ve signed up for the newsletter so far, and it’s a very diverse mix - From students to ZenML customers to ML practitioners who I’m sure are just curious. I hope we can strike a balance between high-level strategic topics vs hands-on tutorials and guides that might help people who want to get their hand’s dirty.
If you have any feedback at any time, please us me know by hitting the reply button. As this is the first ever newsletter, I expect there is a lot of learnings to be had over the next months.
The evolution of RAG in Production
For a long time, I was not sure what a good entrypoint story for ZenML into LLMOps would be. However, the more I look into production LLM use-cases, specifically Retrieval-Augmented Generation systems, the more it dawned on me that these dynamic systems are not dissimilar to the typical MLOps projects where ZenML fits in rather smoothly.
In fact, there seems to an even greater need for automation and putting together disparate infrastructure components. Starting from a basic RAG use-case, you can add reranking, finetune embeddings (this is getting easier), and even finetune the LLM. This recent paper showcases the journey well. Here is my take:
- The set-up of an LLMOps system involves four steps. The first step is stablishing an indexing pipeline to automate data updating from proprietary sources is the crucial first step to creating an effective LLMOps system.
- Increasing the sophistication of the setup, a reranking model is added to the system. This model helps score and reorganize documents according to their relevance to a given query. Training this model over time can lead to improved accuracy.
- Fine-tuning embeddings on the system can significantly improve retrieval rates, further enhancing the overall effectiveness of the setup. This process, however, is more complex and requires the generation of synthetic data.
- The final step involves further fine-tuning or pretraining the large language model. This step is technically complex but can yield results that are specific to your domain or data, enhancing the quality and relevance of the system's output.
ZenML is well positioned to be the tool that connects the disparate LLMOps components together, and automates these pipeline end to end, regardless of which tool you are using. I’m super excited to see how ZenML can condense this journey and make it easier for people to get started putting to together. More details in the accompanying blog.
Read the full RAG evolution blog here
Join the conversation
Finetuning opensource LLMs using MLOps pipelines
Refine your ML strategies with our latest insights into fine-tuning open-source LLMs using MLOps pipelines.Join the LinkedIn conversation here.
12 Key Pain Points in RAG Implementation & Their Solutions
The complexities and solutions for deploying Retrieval-Augmented Generation (RAG) systems in production
Discover more in the detailed discussion and join the conversation here.
ZenML Product Corner
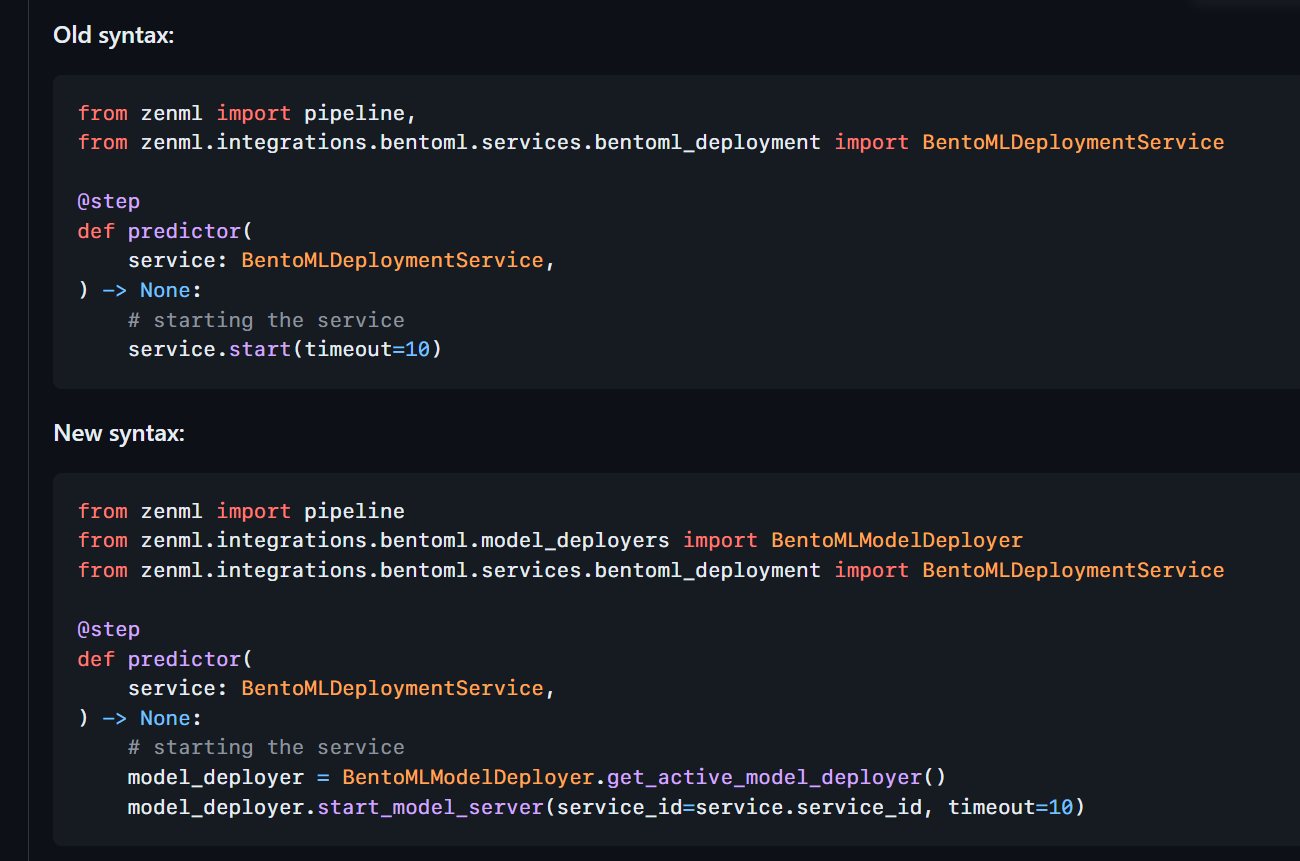
HuggingFace Deployer + Services Update
With 0.56.2, we released amazing features including a community-contributed HuggingFace Deployer and a more robust way of dealing with Services (e.g. model deployments)
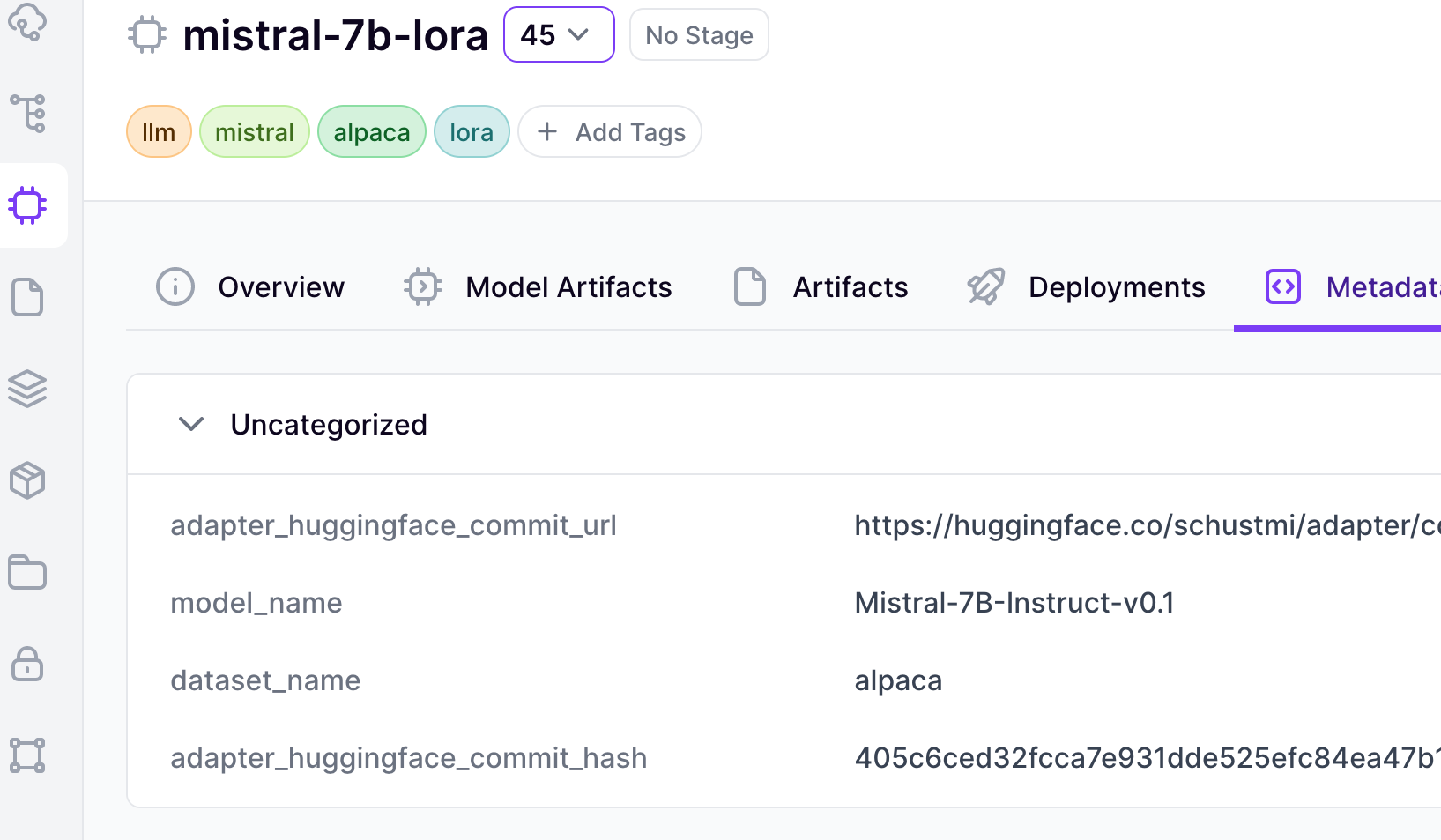
A brand-new LLM finetuning template
The new LLM finetuning template contains a collection of ZenML steps, pipelines and other artifacts and useful resources that can serve as a solid starting point for finetuning open-source LLMs using ZenML.
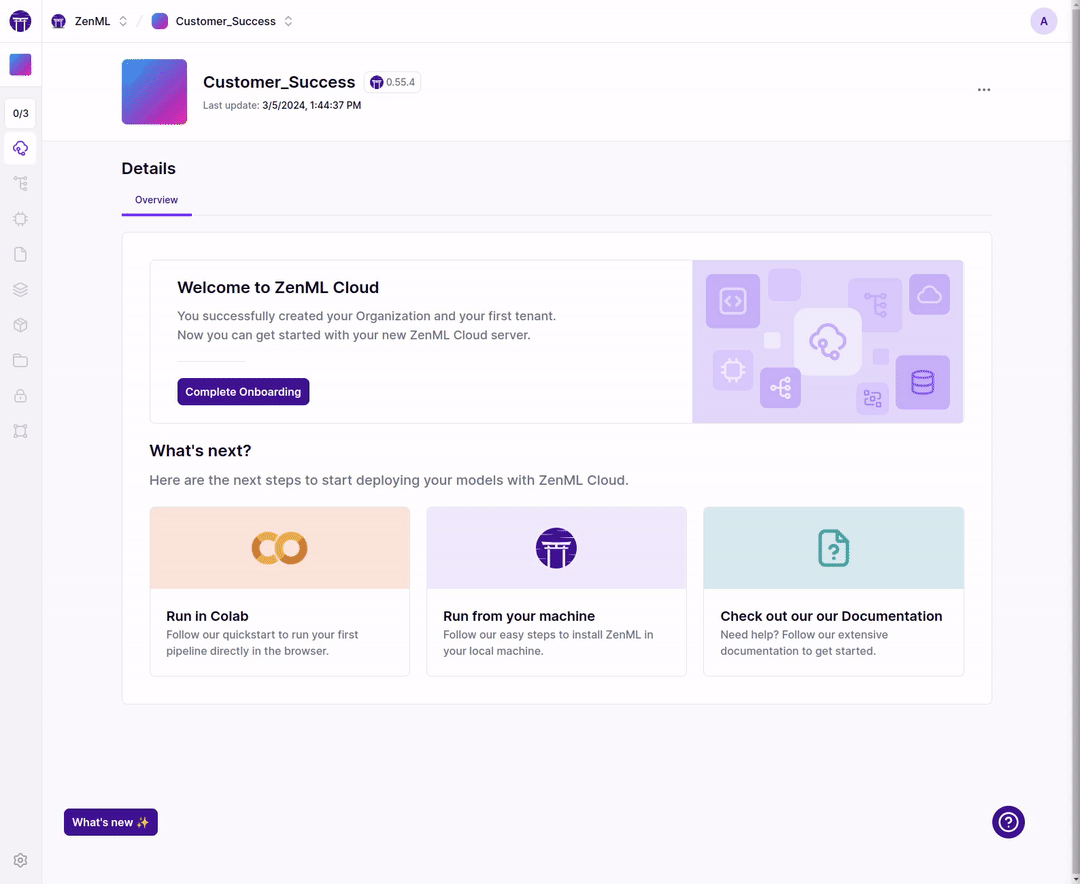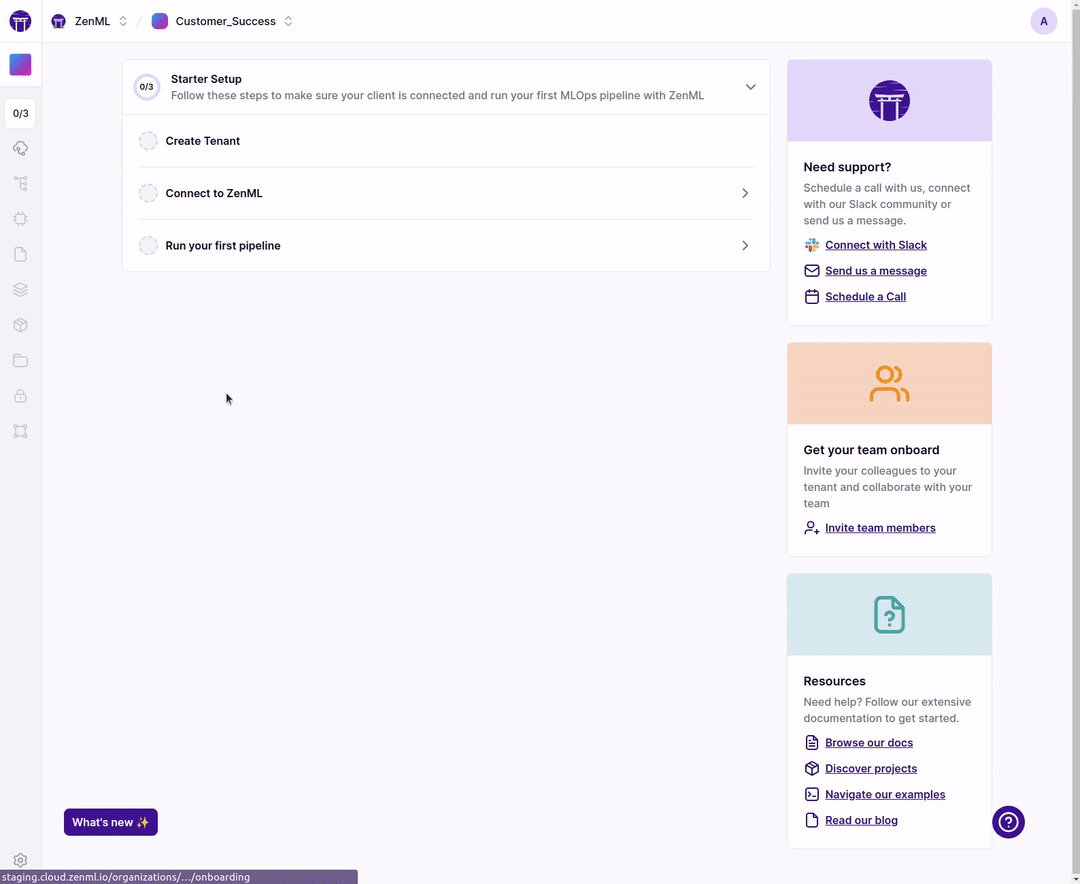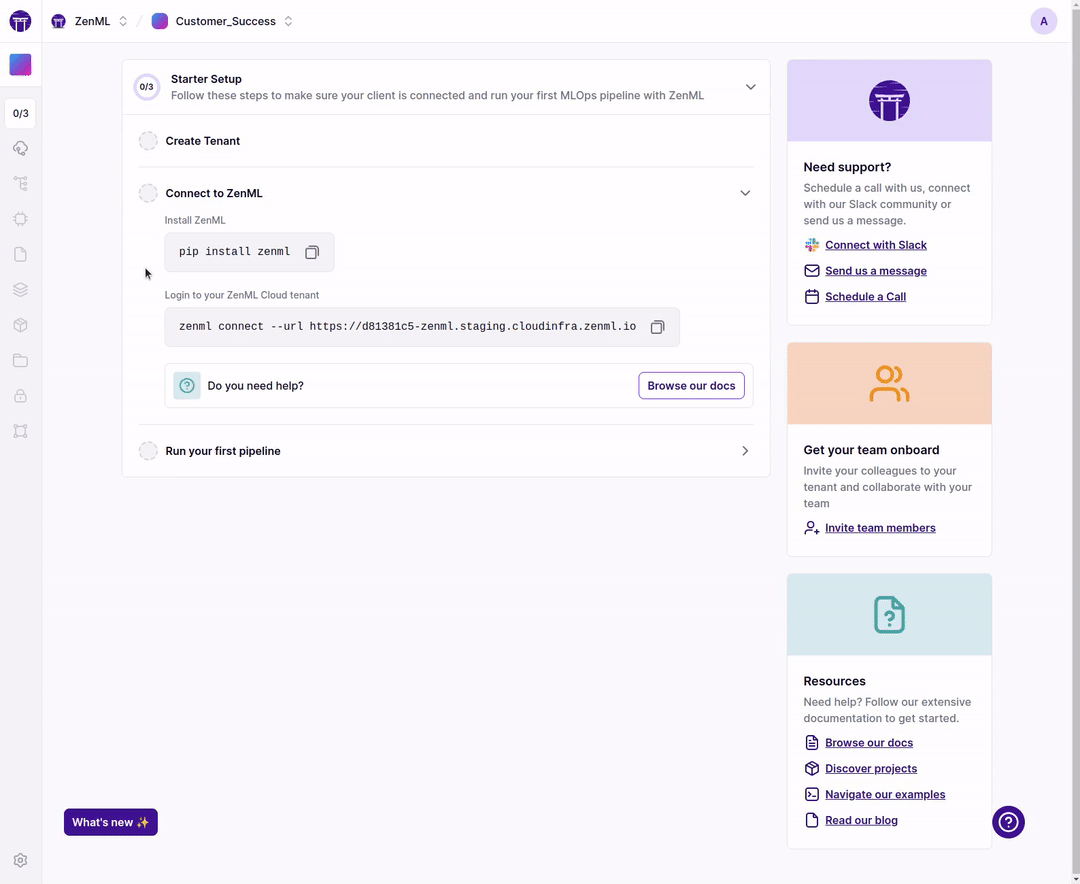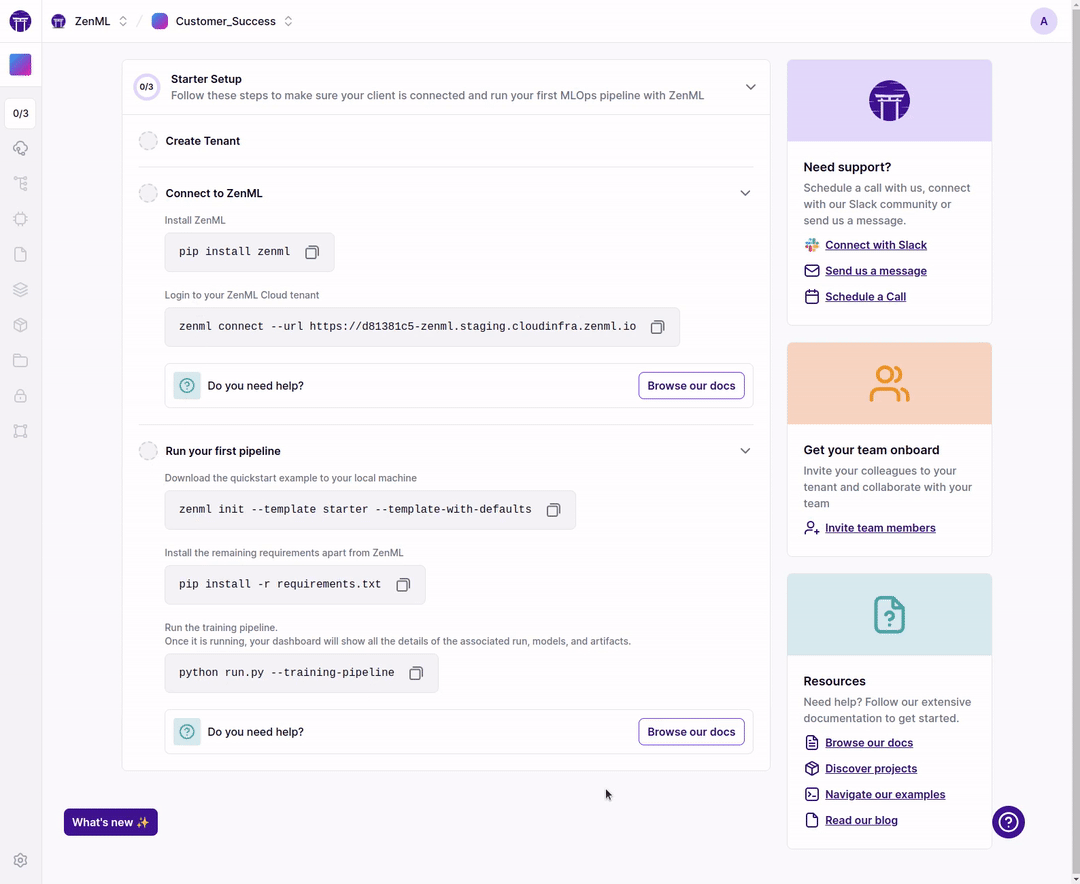
New cloud onboarding for a faster start!
When you deploy your tenant you now get a simple onboarding flow that gets you started in no time.
Fresh from the community
New #generative-ai channel
Get ready to learn and discuss generative AI use cases (from LLMs to video and image generation and beyond).
Contributors Spotlight
We had three awesome contributions by @dudeperf3ct, @moesio-f,and @christianversloot in the 0.56.0 release!
If you have any questions or need assistance, feel free to join our Slack community.
Happy Developing!
Hamza Tahir