

On this page
Whether you’re orchestrating AI agents that call OpenAI’s API or serving your own scikit-learn models, you face the same production challenges: keeping resources warm, tracking every prediction, and rolling back bad deploys. Pipelines solve this for both—one abstraction that handles your LLM-powered agents AND your classical ML models, with warm state, observability, and instant rollbacks built in. Here’s why we doubled down on pipelines, and how Pipeline Deployments make this practical.
The usual objection: “Why not just wrap my model in FastAPI and call it a day?” Fair question. FastAPI is excellent. But as AI systems grow from single-model inference to multi-step orchestration, tool integration, and stateful agent flows, you need more than a web framework. You need lineage tracking across invocations, immutable deployment snapshots, instant rollbacks, and unified observability—all while maintaining sub-second latency.
ZenML’s new Pipeline Deployments deliver exactly this. They transform any pipeline—whether it’s classical ML inference or complex agent orchestration—into a persistent HTTP service with warm state, reducing cold start latency by 10–100x. Every request is still a traceable pipeline run, but now executing at web-scale speeds.
Let’s explore why pipelines are the right abstraction for this new world of real-time AI, and how Pipeline Deployments make it practical.
Why pipelines?
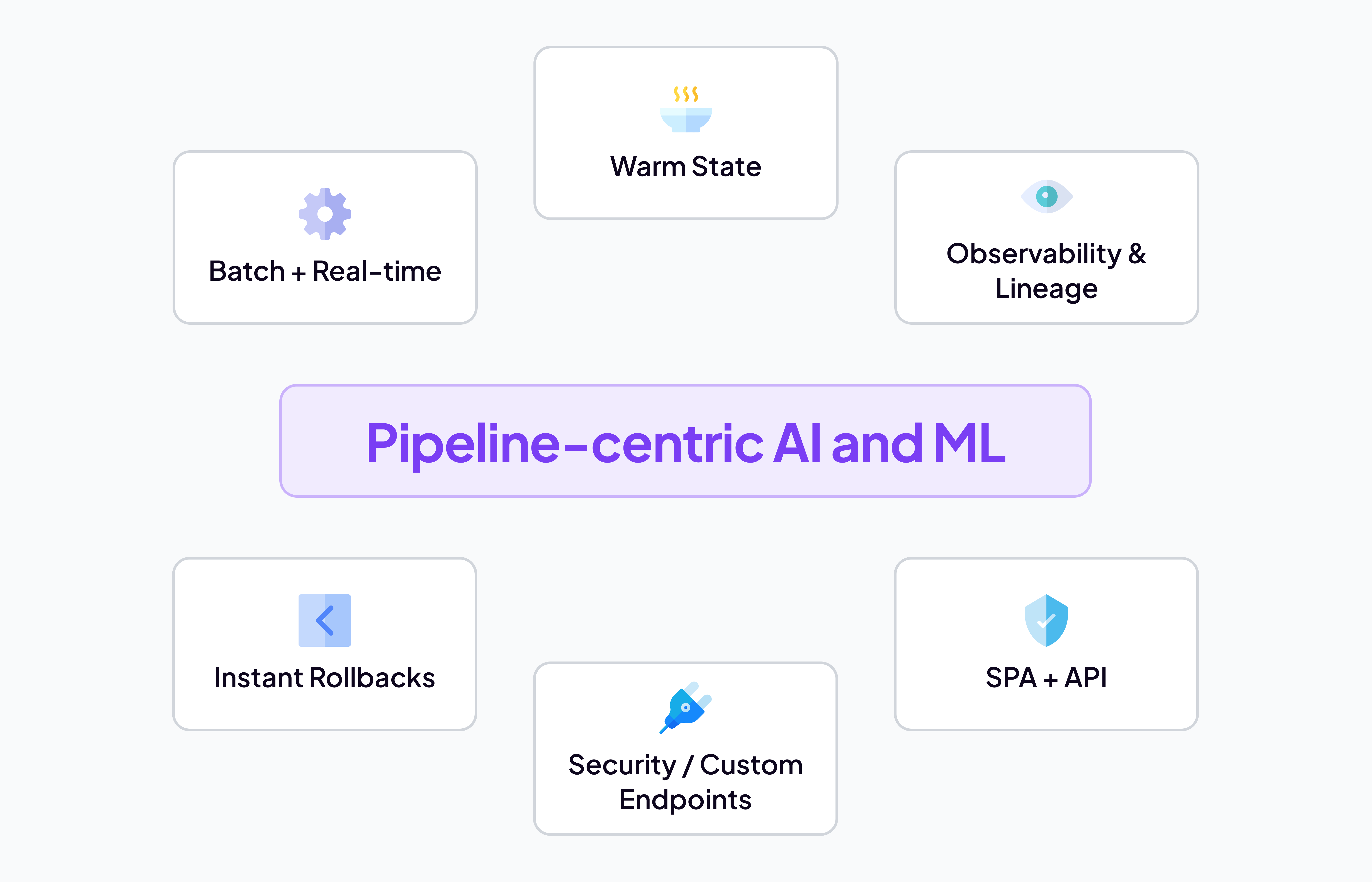
Pipelines aren’t just for batch jobs anymore. Here’s what you get when you use them as your application boundary for real-time AI:
- Unify batch + real-time on one abstraction — No drift between training code and serving code. The same pipeline that trains offline can serve online.
- Warm state and cold start control — Models, tools, and vector stores loaded once and kept in memory. No more 30-second cold starts on every request.
- Observability and lineage per invocation — Every request is a traceable pipeline run. Debug production issues with the same tools you use in development.
- Instant rollbacks via snapshots — Deploy an immutable bundle; roll back to any previous snapshot in seconds.
- Security, CORS, custom endpoints and middleware — Full control of your HTTP surface without rebuilding infrastructure.
- Serve a SPA next to your API — Ship complete AI applications with frontend and backend from one deployment.
Pipelines evolved from where they were mostly represented by cron scripts to where orchestrators took over and now we have real-time agents. There’s a lot of history that covers this shift since the early 2000s, but for now, the takeaway: the real-time workloads of 2025 need a persistent, callable pipeline, not one-off batch jobs.
Introducing Pipeline Deployments
The shift from batch to real-time pipelines isn’t just a matter of speed — it demands new architectural primitives. To meet these needs, we’re introducing pipeline deployments, a new way to run pipelines as persistent, real-time services. Instead of executing once and tearing down, these deployments stay warm, ready to respond instantly to requests.
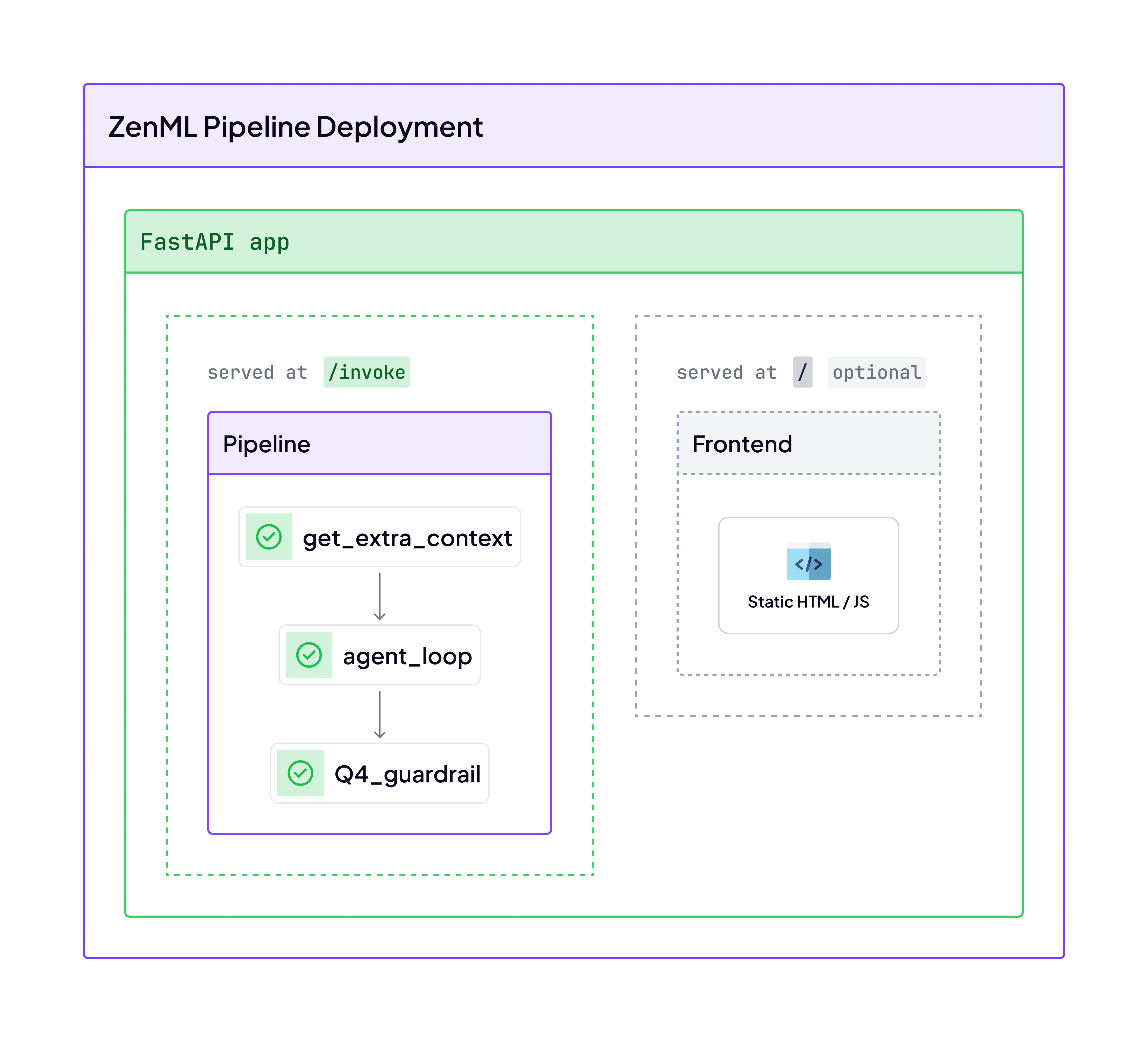
Let’s look at a simple example — a ZenML pipeline that uses an LLM to fetch and analyze the weather for a given city (defined in a run.py file):
from zenml import pipeline
# steps are defined separately
@pipeline
def weather_agent(city: str = "London") -> str:
weather_data = get_weather(city=city)
result = analyze_weather_with_llm(weather_data=weather_data, city=city)
return result
weather_agent()Deploy with a single command:“
zenml pipeline deploy run.weather_agent --name my_weather_agentThen invoke it via curl:
curl -X POST \
-H "Content-Type: application/json" \
-d '{"parameters":{"city":"Paris"}}'Each HTTP request creates a pipeline run, giving you full lineage and observability. Pipeline Deployments turn your pipeline into a long-running HTTP service that keeps resources warm—cutting cold starts from 30 seconds to milliseconds.
The built-in local deployer works out of the box. For cloud deployments, see our Deployer documentation. Targeting AWS or GCP is just a matter of registering a different deployer as part of your stack:
| Flavor | Integration | Notes |
|---|---|---|
local | Built-in | Runs locally in a process |
docker | Built-in | Local Docker containers for testing |
gcp | GCP | Serverless on Cloud Run |
aws | AWS | Serverless on App Runner; requires ECR registry, IAM roles for access/instance |
Advanced feature: With the on_init and on_cleanup hooks, you can prepare and tear down components when the deployment starts or stops — ensuring heavy resources (like models, vector stores, or tool registries) are loaded only once and reused efficiently.
Every request to that endpoint is still a ZenML run under the hood — meaning you retain full lineage, metadata, and observability. You can inspect inputs, outputs, and execution logs just like any other pipeline execution. This continuity is key: even in a real-time setup, you don’t lose the rigor and traceability that make pipelines reliable in production.
At the same time, not every request needs the full artifact tracking overhead. For latency-sensitive use cases, you can configure deployments to selectively disable or downsample artifact storage — keeping performance snappy while maintaining visibility where it matters.
Common pushbacks, answered
”I can just use FastAPI”
You keep FastAPI—that’s exactly what runs under the hood. But you also get lineage tracking, deployment snapshots, warm state management, and a dashboard. Plus, DeploymentSettings lets you bring your own endpoints, middleware, and security configurations. You’re not replacing FastAPI; you’re getting FastAPI with production-grade ML/AI infrastructure built in.
”Isn’t ZenML heavy?”
The local deployer ships by default—zero additional setup. You choose per pipeline whether to run batch or serve real-time. For latency-sensitive workloads, you can throttle or disable artifact persistence. The overhead is a minimal amount on top of your actual model inference time.
”Do I still need Seldon/BentoML/specialized serving?”
For single model serving with extreme performance constraints (sub-10ms inference), specialized model servers can help. But for multi-step logic, tool orchestration, and agents—where you’re composing models with business logic—pipeline deployments eliminate the glue code and give you a unified abstraction.
”What about LangGraph/CrewAI/Autogen?”
Keep them! These frameworks excel at defining agent logic and tool interactions. Wrap their graphs in a ZenML pipeline to get deployment lifecycle management, observability, instant rollbacks, and an HTTP surface. Here’s the pattern:
from zenml import pipeline, step
@step
def process_the_input(input: str) -> str:
# Your preprocessing logic here
processed_input = do_something_here(input)
return processed_input
@step
def my_langgraph_logic(input: str) -> str:
# Your LangGraph/CrewAI/Autogen logic here
result = graph.run(input)
return result
@pipeline
def my_langgraph_agent(input: str) -> str:
processed_input = process_the_input(input)
result = my_langgraph_logic(processed_input)
return resultYou get the best of both worlds: specialized agent frameworks for logic, ZenML for production deployment. (For code examples of how to use ZenML together with popular agent frameworks, check out our agent_framework_integrations folder on Github.)
Abstracted, but Fully Customizable
Under the hood, ZenML deployments are long-running FastAPI applications. Because of this, a common pushback I hear is:
“If ZenML deploys a FastAPI app for me, do I lose control of the application itself?”
Not at all. In fact, this is where the flexibility of the new deployer really shines. Under the hood, every deployment spins up a fully standard FastAPI server — and you can customize it however you like.
Through the new DeploymentSettings API, you can inject your own CORS rules, add middleware, define custom routes, or adjust security headers. Want to add authentication? Plug in your own OAuth middleware. Need extra endpoints for metrics or health checks? Define them directly in your pipeline configuration.
Here’s a glimpse of what that looks like:
from zenml.config import DeploymentSettings
deployment_settings = DeploymentSettings(
cors=True,
invoke_url_path="/predict",
health_url_path="/healthz",
app_title="Customer Churn Prediction Service",
)That’s it — your deployed pipeline now exposes clean, configurable endpoints under a FastAPI app you can fully extend.
Because it’s a real FastAPI server, you can go a step further: serve not just your pipeline logic, but also a frontendalongside it. This unlocks something powerful — full, interactive AI applications shipped straight from your pipelines.
In our Weather Agent example, the index.html file defines a minimal chat UI that connects to the pipeline’s /invoke endpoint. You can include this in your deployment by referencing it directly in the DeploymentSettings:
from zenml.config import DeploymentSettings
deployment_settings = DeploymentSettings(
dashboard_files_path="frontend/", # Contains index.html and assets
invoke_url_path="/invoke",
app_title="Weather Agent",
)When deployed, ZenML automatically serves your frontend and backend from the same FastAPI app.
Open the deployment URL, and you’ll see a fully functional web interface — inference in real time with your deployed pipeline.
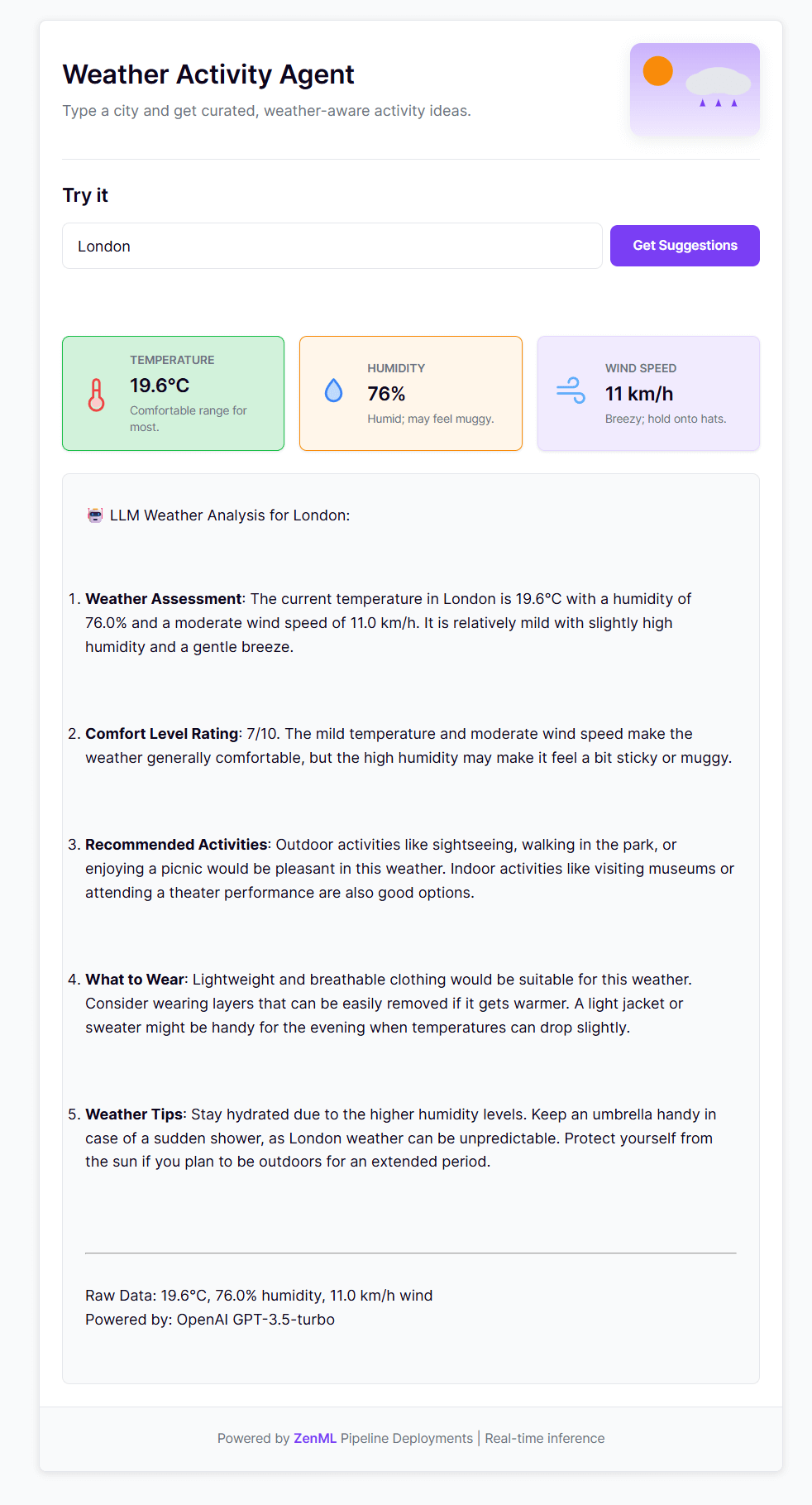
It’s a small detail with huge implications: you can now go from pipeline to production-grade AI app — backend, API, and live frontend — all with a single deployment command.
Beyond Agents: Classical ML Gets the Same Upgrade
This isn’t just an LLM story. The same deployment model turns classical ML pipelines into low-latency, production-ready services—with versioning, lineage, and instant rollbacks baked in.
Instead of a simple cached function, our deploying_ml_model example (a customer churn predictor) demonstrates the full MLOps lifecycle: a batch pipeline for training and a separate, persistent pipeline for real-time inference.
Step 1: The Batch Training Pipeline
First, a training pipeline runs as a batch job. It generates data, trains a scikit-learn model, and—most importantly—tags the model artifact as “production” using ArtifactConfig. This signals which model version our inference service should use.
# From examples/deploying_ml_model/steps/train.py
from sklearn.pipeline import Pipeline
from zenml import ArtifactConfig, step, pipeline
@step
def train_churn_model(
features: pd.DataFrame, target: pd.Series
) -> Annotated[Pipeline, ArtifactConfig(name="churn-model", tags=["production"])]:
pipeline = Pipeline(
[
("scaler", StandardScaler()),
("classifier", RandomForestClassifier()),
]
)
pipeline.fit(features, target)
# Model is automatically versioned and tagged "production"
return pipeline
# From examples/deploying_ml_model/pipelines/training_pipeline.py
@pipeline
def churn_training_pipeline(num_samples: int = 1000):
features, target = generate_churn_data(num_samples=num_samples)
train_churn_model(features=features, target=target)Step 2: The Deployed Inference Pipeline
Second, a separate inference pipeline is deployed as a persistent service. This pipeline uses two key ZenML features to achieve a warm state and high performance:
on_initHook: A function (init_model) runs once when the service starts. It connects to ZenML, finds the latest "production" model, and loads it into memory.- Pipeline State: The inference step (
predict_churn) accesses this pre-loaded model directly from thestep_context.pipeline_state, completely avoiding model-loading latency on every request.
It also uses DeploymentSettings to serve an interactive web UI from the frontend/ directory, turning your ML pipeline into a full-stack application.
# From examples/deploying_ml_model/pipelines/hooks.py
from zenml.client import Client
def init_model() -> Pipeline:
"""Load the latest 'production' model *once* at startup."""
client = Client()
model_artifact = client.get_artifact_version("churn-model")
model = model_artifact.load()
return model # This model is now kept warm in the pipeline's state
# From examples/deploying_ml_model/steps/inference.py
@step
def predict_churn(
customer_features: dict,
) -> Annotated[Dict[str, Any], "prediction"]:
# Access the warm model from the pipeline's state (no loading!)
model = get_step_context().pipeline_state
features_df = pd.DataFrame([customer_features])
churn_probability = float(model.predict_proba(features_df)[0, 1])
return {
"churn_probability": round(churn_probability, 3),
"model_status": "success",
}
# From examples/deploying_ml_model/pipelines/inference_pipeline.py
@pipeline(
enable_cache=False,
on_init=init_model, # Load the model at startup
settings={
"deployment": DeploymentSettings(
app_title="Customer Churn Prediction Service",
dashboard_files_path="frontend", # Serve the web UI!
),
},
)
def churn_inference_pipeline(
customer_features: Dict[str, float]
) -> Dict[str, Any]:
return predict_churn(customer_features=customer_features)Deploying this robust, two-part system is just two commands:
# 1. Train the model first to create the "production" artifact
python run.py --train
# 2. Deploy the inference pipeline as a persistent service
zenml pipeline deploy pipelines.churn_inference_pipeline.churn_inference_pipeline \
--name churn-serviceNow, every curl request to the /invoke endpoint (or interaction with the web UI) gets a prediction from your scikit-learn model. You get the best of both worlds: a model trained in a reproducible batch pipeline, served with a warm state, full lineage tracking, and even a custom UI.
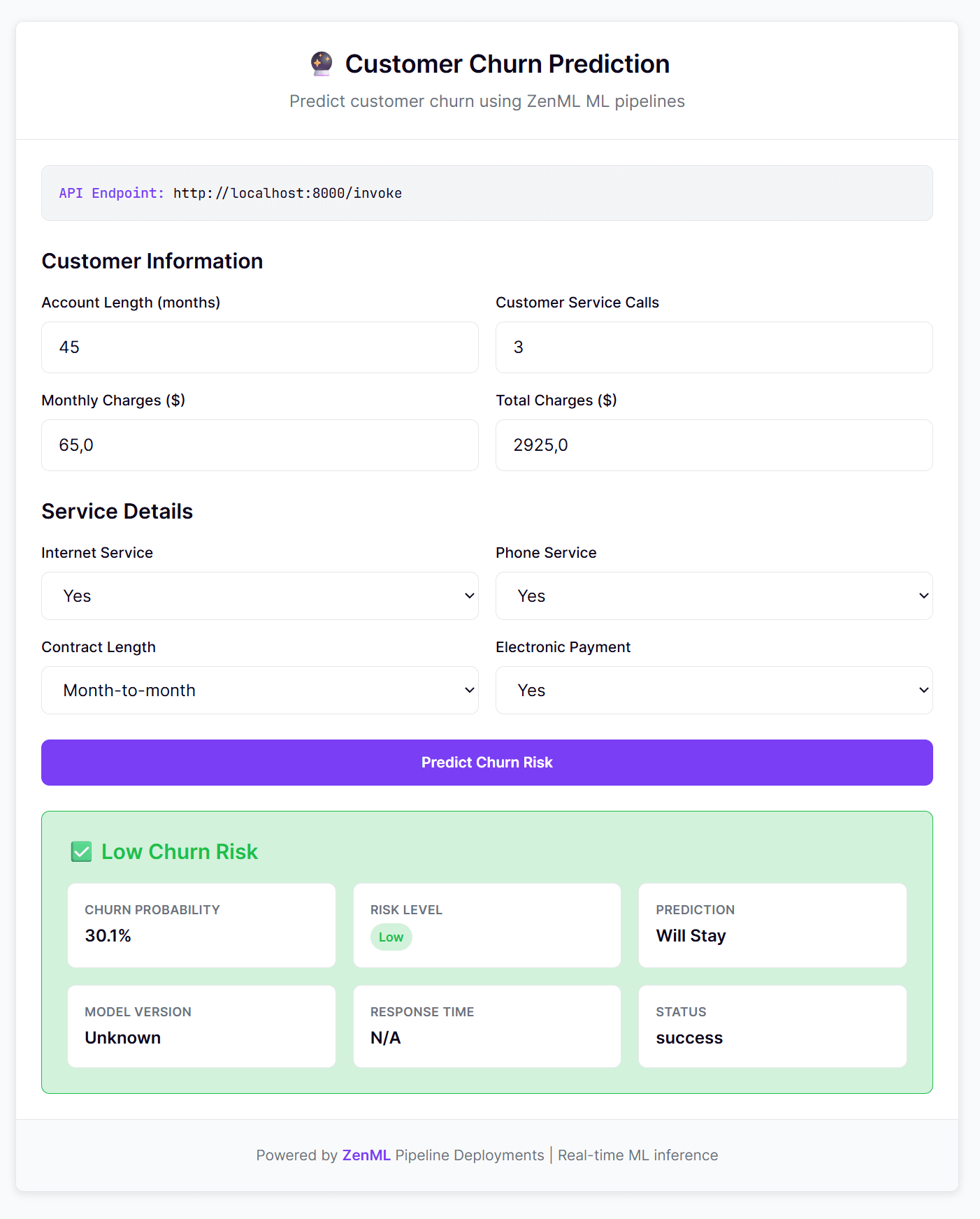
Try it in the Dashboard
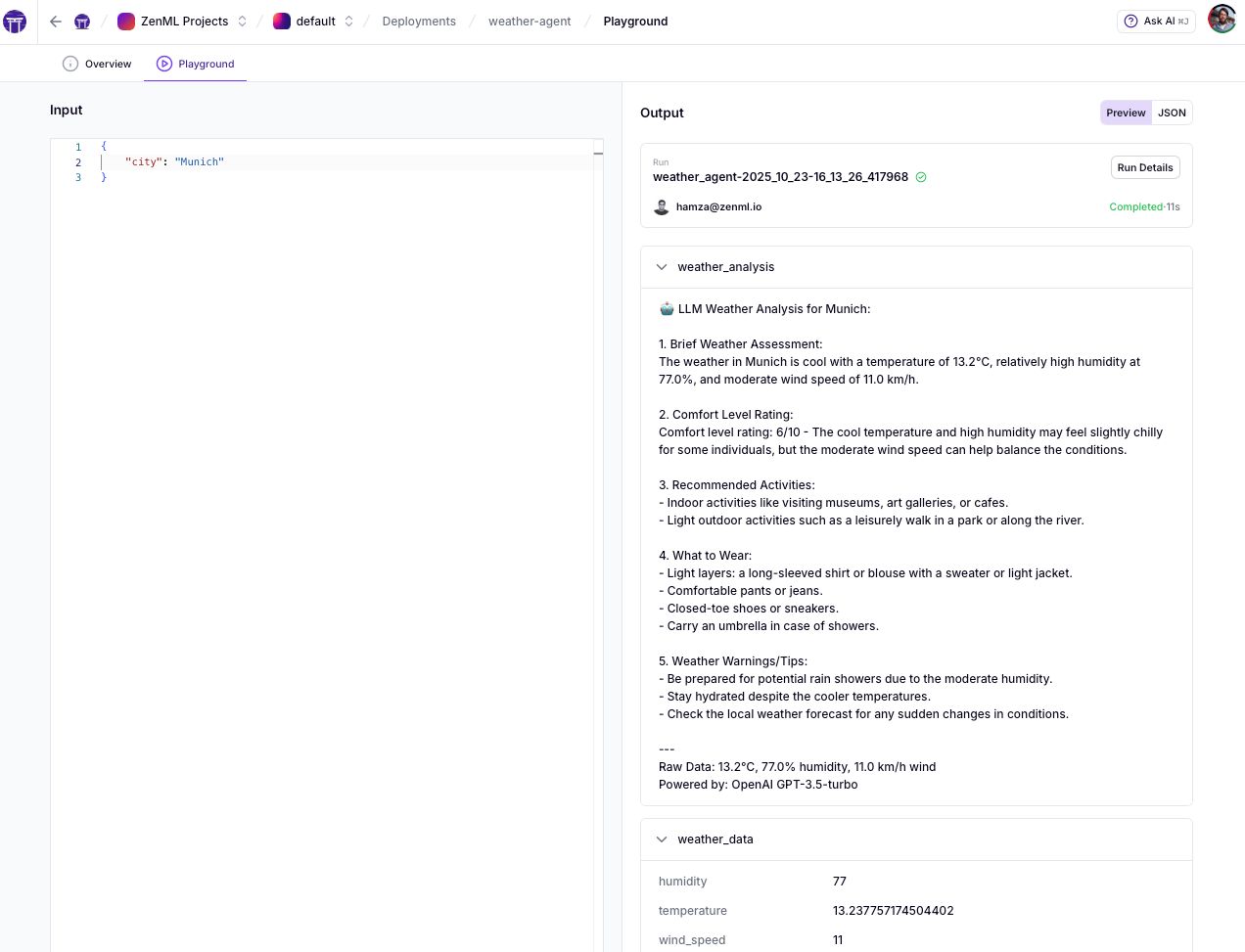
Once deployed, use the ZenML dashboard’s Playground to test your deployment:
- Paste your JSON payload
- Click Invoke to test the endpoint
- Get instant response, latency metrics, and a ready-to-use cURL command
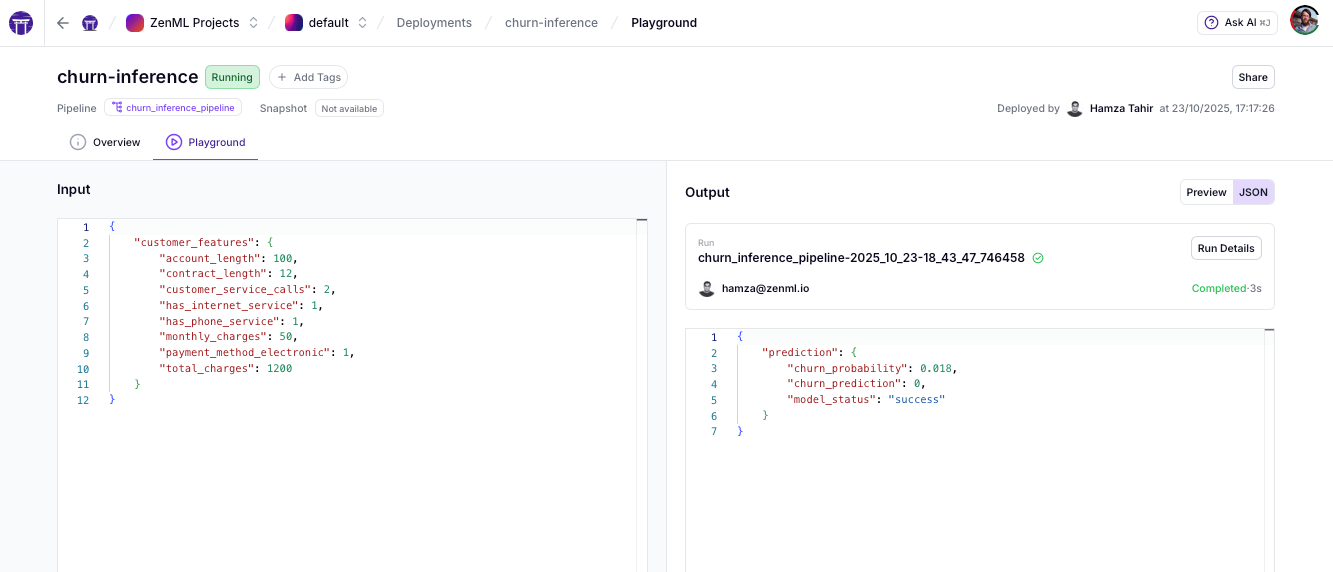
That’s the pattern: whether for agents or classical ML, pipelines become your application boundary—with real-time endpoints, full lineage, and instant rollbacks.
Deprecation Note: Earlier ZenML versions (<0.90.0) included a “Model Deployer” for single-model serving. As pipelines evolved to handle multi-step workflows and agents, we’ve replaced it with the general Deployer—one primitive for any pipeline, whether classical ML or agentic. For migration details, see our deprecation guide.
Where Pipeline Deployments Fit In
It’s worth noting how this new paradigm fits into the broader ecosystem of AI tools.
ZenML deployments don’t replace streaming systems like Kafka or Flink—they complement them. Use streaming to keep features and state fresh in the background; use deployments for the interactive layer where users, agents, or services need instant, request–response results.
Already using LangGraph, CrewAI, or Autogen? Great—keep them. Those frameworks define how your agent logic runs; ZenML defines where it runs, with lifecycle, observability, lineage, and rollback. Increasingly, we expect agent graphs to be wrapped in ZenML pipelines and served via deployments.
Learn more and get started
We’ve shown why pipelines are the right abstraction for real-time AI—unifying batch and streaming, managing state, providing observability, and enabling instant rollbacks. Pipeline Deployments make this practical: your familiar ZenML pipeline becomes a production-ready HTTP service with a single command.
Whether you’re serving classical ML models or building complex agents with LangGraph and CrewAI, you get the same benefits: immutable deployments, warm state management, and full lineage tracking at web-scale speeds. The infrastructure adapts to your use case, not the other way around.
In the coming weeks, we’re doubling down on making deployments faster, leaner, and more observable:
- Scalability & robustness: harden the FastAPI deployer for high concurrency and spikes; reduce overhead so the cost is near zero.
- Fine-grained persistence controls: choose exactly which artifacts (if any) are stored per invocation to balance latency, cost, and traceability.
- Richer observability: first-class logs, metrics, and time-series graphs of invocations; clearer request/response tracing right in the dashboard.
- More integrations: deeper built-in integrations to observability tools like Langfuse, Braintrust, Langsmith and more.
Big picture: ZenML remains a platform for both worlds—batch pipelines and real-time services. Whether you’re shipping classical ML inference or agentic systems, you can build with pipelines, deploy with confidence, and keep full lineage and control.
Ready to try it? Start with the quickstart below, explore our examples, or join the upcoming webinar for a deep dive into real-time AI pipelines.
Get Started Today
🧭 Docs: Pipeline Deployments Guide
💬 Examples: Weather Agent | Churn Service
⚡ Quickstart (LLM Agent)
# Install ZenML
pip install "zenml[server]>=0.90.1"
# Clone the repo and navigate to the example
git clone https://github.com/zenml-io/zenml.git
cd examples/weather_agent
pip install -r requirements.txt
# OpenAI API key for enhanced recommendations
export OPENAI_API_KEY="your-key"
# Initialize ZenML and deploy the agent
zenml init
zenml pipeline deploy run.weather_agent --name weather-agent-service⚡ Quickstart (Classical ML)
# (Assuming ZenML is installed and you are in the cloned zenml repo)
cd examples/deploying_ml_model
pip install -r requirements.txt
# Initialize ZenML
zenml init
# 1. Run the training pipeline to create the "production" model
python run.py --train
# 2. Deploy the inference pipeline as a service
zenml pipeline deploy pipelines.churn_inference_pipeline.churn_inference_pipeline \
--name churn-service
# Open http://localhost:8080 (or your deployment URL) to see the UI!We’re also going to be presenting the details behind this new feature in a webinar on ….. and you can click here to sign up to attend the webinar (🎬 Webinar: Real-time AI Pipelines Deep Dive).
Join our Slack community to share what you build!


