On this page
Last updated: October 17, 2022.
“Spend more time with your data.” As a data scientist or ML practitioner, you’ll probably have heard this advice more times than you can count. Familiarity with the data breeds understanding of the problem domain which in turn leads to better models and solutions. But how do you do this in practice? The very fact that we need to be reminded of this suggests at least some lack of clarity.
One way to become intimately familiar with your data is to get involved in labeling the data. This approach has recently gained popularity following the emergence of the data-centric AI movement. In this blog, I will explain the benefits of being more closely involved in annotation and labeling of your data. I will also talk through the moments in your overall workflows where you’re likely to think about doing annotation and how it benefits you in each case.
Why you might want to label your own data
I imagine that in a few years we’ll see the push for ‘data-centric AI’ as a correction to how things are routinely done rather than an entirely separate approach or discipline. Indeed, if you speak to any researcher from the world of the humanities or social sciences they will all affirm the importance of being familiar with the raw materials of what you’re working with.
I’ve learned and relearned this countless times in own career and can attest to the benefits that come from immersion into the sources and materials that make up your problem domain or context. You’ll very rarely find you don’t benefit from familiarity with this data. (You still want to be smart about exactly how much of your time you spend doing this, but I’ll put that to one side for now.)
Familiarity with your data helps spot and solve your problems faster. For instance, spending a few hours labeling image data will give you some heuristic, however brief, as to the kinds of things contained in your images, what formats or sizes your images take, and so on. If your model training process throws an error out of nowhere, your knowledge of the input data will likely be useful in coming up with a hypothesis as to what happened.
Familiarity with your data is also a great way to keep your process nimble and focused. There’s no need to go full AutoML, trying out every hyperparameter or pre-trained model under the sun if you have a sense of the boundaries or edges of your data space.
Perhaps most importantly, the wide availability of some pretty great starting points in the form of pre-trained models (e.g. in the computer vision and NLP domains) mean that you don’t actually need much data to get started. Making an initial set of annotations allows you to get going with the work of getting a baseline started and iterating on your solution.
When and where to do your labeling
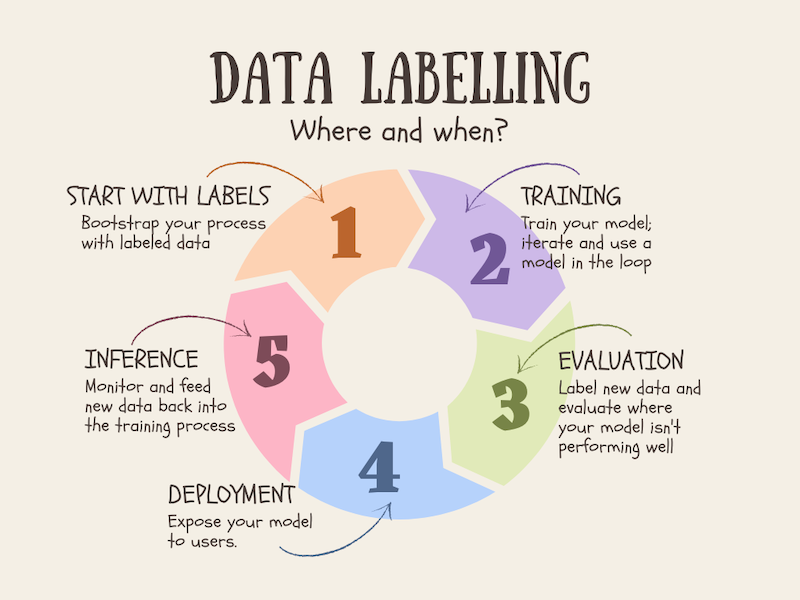
Labeling isn’t a static practice but rather something you probably will want to be doing throughout. There are some places where it makes a lot of sense to plan to do some labeling:
- At the start: You might be starting out without any data, or with a ton of data but no clear sense of which parts of it are useful to your particular problem. It’s not uncommon to have a lot of data, but to be lacking accurate labels for that data. So you can start and get great value from bootstrapping your model: label some data, train your model, use your model to suggest labels allowing you to speed up your labeling, iterating on and on in this way. Labeling data early on in the process also helps clarify and condense down your specific rules and standards. For example, you might realize that you need to have specific definitions for certain concepts so that your labeling efforts are consistent across your team.
- As new data comes in: New data will likely continue to come in, and you might want to check in with the labeling process at regular intervals to expose yourself to this new data. (You’ll probably also want to have some kind of automation around detecting data or concept drift, but for certain kinds of unstructured data you probably can never completely abandon the instant feedback of actual contact with the raw data.)
- Samples generated for inference: Your model will be making predictions on real-world data being passed in. If you store and label this data, you’ll gain a valuable set of data which you can use to compare your labels with what the model was prediction, another possible way to flag drifts of various kinds. This data can then (subject to privacy / user consent) be used in retraining or fine-tuning your model.
- Other ad hoc interventions: You will probably have some kind of process to identify bad labels, or to find the kinds of examples that your model finds really difficult to make correct predictions. For these, and for areas where you have clear class imbalances, you might want to do ad hoc annotation to supplement the raw materials your model has to learn from.
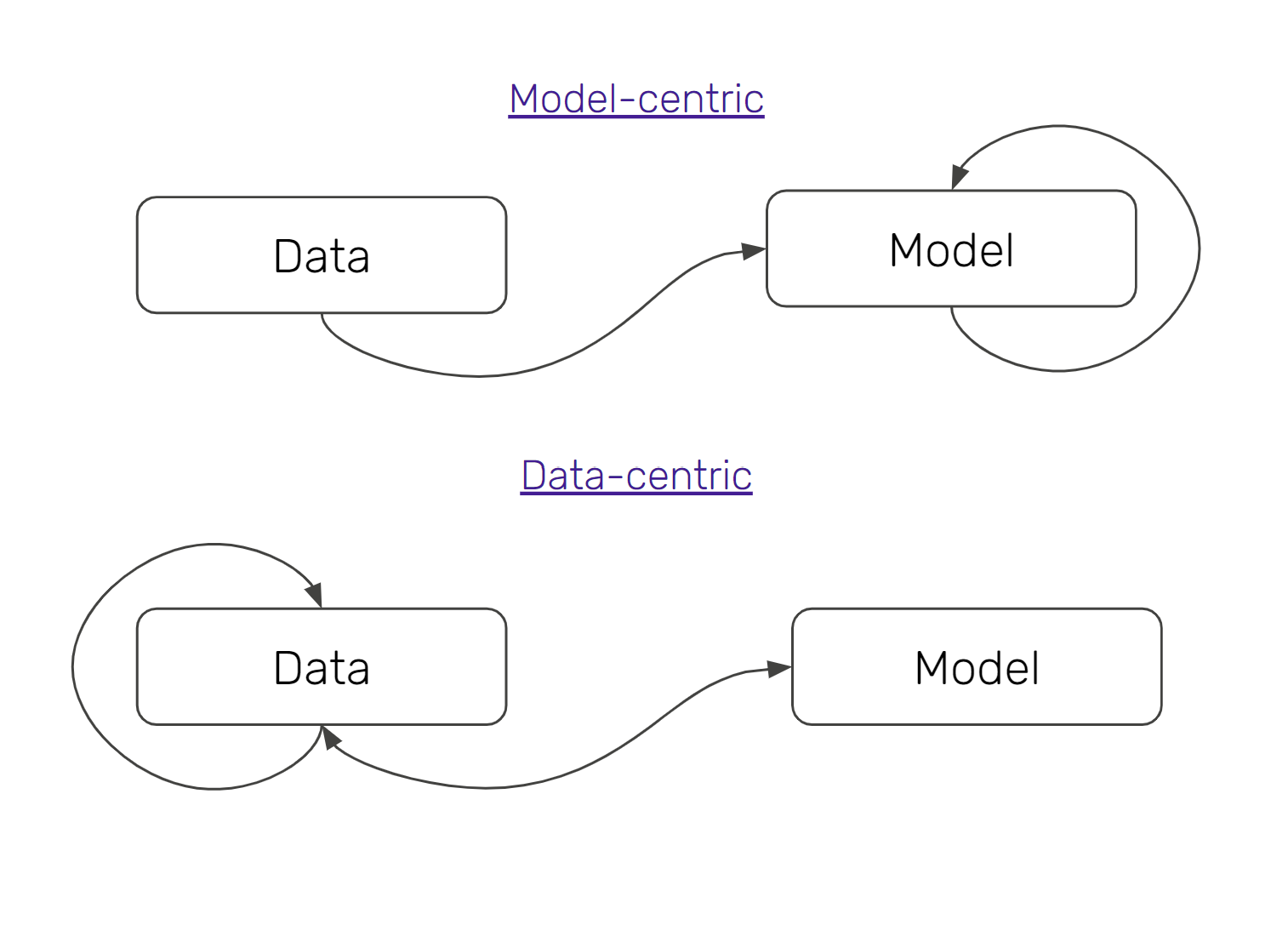
The Promise of Data-centric AI
The shift and refocus towards data quality is more of a course correction than it is a fundamental rethink of how machine learning models get trained. Nevertheless, it does shift the emphasis and allocation of time to different parts of the ML training pipeline.
You will probably never regret spending time with your data, exposed to all the tiny idiosyncrasies and edge cases. After all, your model goes through some version of this itself as it works to fit a function to the precise use case you’ve set up. Knowing how to incorporate data labeling as part of your data-centric approach will pay dividends in increasing the speed at which you can iterate and boost the extent to which you feel intuition around the raw materials of your problem.
At ZenML, we’re starting work to incorporate data labeling and annotation tools into our framework so that you can gain all the benefits described above as a core part of your workflow. If you have a use case which requires data annotation in your pipelines, please let us know what you’re building and there are tools you feel like you couldn’t live without! The easiest way to contact us is via our Slack community which you can join here.
[*Cover photo by Alina Grubnyak on *Unsplash]