On this page
MLflow has been and still is a solid starting point and the canonical experiment ledger inside many ML stacks. However, full-fledged production ML platforms demand governance, pipeline orchestration, CI/CD, observability, and enterprise security that MLflow leaves open-ended. Teams often retain MLflow at the core but surround it with opinionated, pipeline-centric layers or graduate to stacks where these capabilities are built in from day one.
In this article, we discuss the top 9 MLflow alternatives that take care of the drawbacks MLflow has and help you with modern ML operations.
TL;DR
- Why look for MLflow alternatives: As projects grow, MLflow’s limited support for enterprise security/governance, complex manual setup, and lack of support in pipeline orchestration and reproducibility become bottlenecks.
- Who might want to use these alternatives: These tools serve data science and MLOps teams hitting MLflow’s limits – e.g., needing multi-user collaboration, reproducible workflows across environments, or integrated deployment/monitoring.
- What we cover: A breakdown of nine MLflow alternatives across five categories. We’ll outline each tool’s key features, pros/cons, and pricing, helping you evaluate which alternative fits your needs.
Recently Updated (November 2025): This comprehensive MLflow alternatives guide has been refreshed with the latest market trends, including the explosive growth of AI agents and LLMOps platforms. The MLOps market has experienced dramatic expansion, growing from $1.58 billion in 2024 to a projected $19.55 billion by 2032. All tool comparisons and feature descriptions reflect current capabilities as of November 2025, with particular attention to how these platforms now support AI agent deployment and LLM operations alongside traditional ML workflows.
Why Would You Switch to an MLflow Alternative
Teams that outgrow MLflow gravitate toward frameworks that:
- Treat pipelines as first-class citizens (declarative DAGs, data & model lineage).
- Bundle experiment tracking with artifact versioning, not as a sidecar database but as an intrinsic layer.
- Offer managed or hybrid SaaS, offloading infrastructure toil while preserving open-source extensibility.
Here are the three major reasons why ML engineering teams switch from MLflow to its competitor.
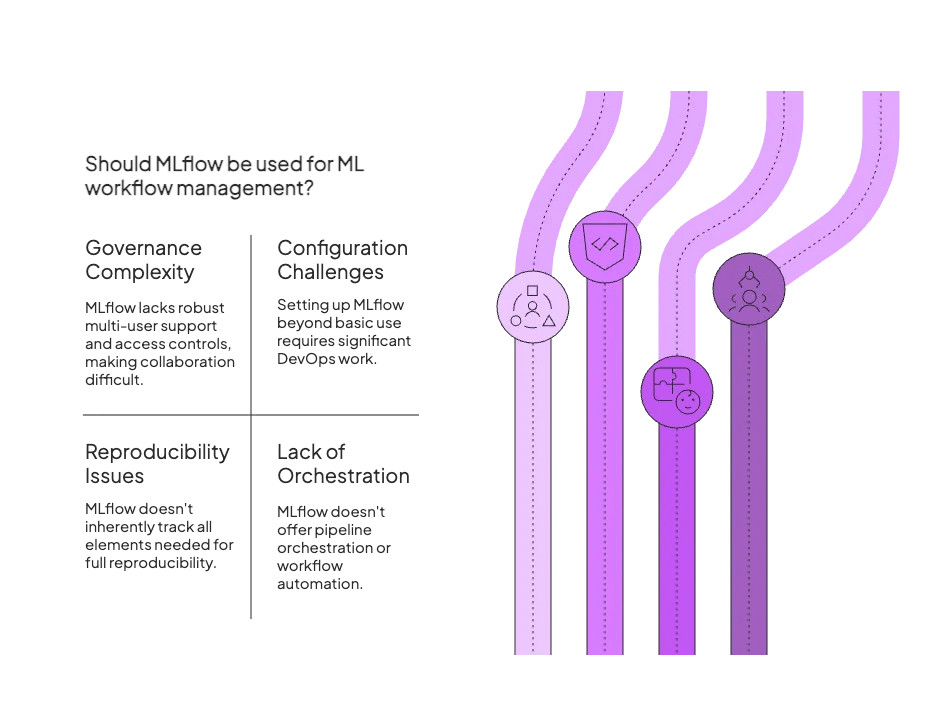
Reason 1. Governance Complexity and Access Control Limits
MLflow lacks robust multi-user support or role-based access controls (RBAC). Collaboration is hard when you can’t easily share experiments or collaborate on them because MLflow doesn’t provide user management and permissions.
“One of the biggest challenges is that anyone who has access to the UI can delete any experiment.” – Reddit User
Reason 2. Configuring Environments, Database, and Dependency Isolation is Hard
Running MLflow beyond the basic local use case requires substantial DevOps work. You need to set up a tracking server with a backing database, possibly a file or object store for artifacts, and handle authentication yourself.
There’s no built-in environment replication for experiments – you have to manage conda/virtualenv environments or Docker images manually for each run. In short, MLflow is not turnkey.
“Tracking experiments is great, but orchestrating multi-GPU fine-tuning jobs, data snapshots, and rollback plans is where production pain lives. A tracker alone won’t cut it.” – Senior MLOps Engineer, Enterprise AI Platform, USA.
Reason 3. Basic Reproducibility is Hard
While MLflow tracks parameters, metrics, and artifacts, it doesn’t inherently track all the pieces needed to fully reproduce an ML workflow. There’s no built-in pipeline concept to tie together data prep, model training, and evaluation steps.
Code versioning is rudimentary (you must remember to set source_dir or use Git tags manually). As a result, the addition of extra workings to the models is not automatic – if you forget to log something like a random seed or the training data version, MLflow won’t help.
Evaluation Criteria
After testing numerous MLflow alternatives across different team sizes and use cases, we identified three critical criteria to shortlist truly effective platforms.
1. Workflow Orchestration
MLflow’s most glaring limitation lies in its lack of native workflow orchestration capabilities. While it excels at experiment tracking and model management, it falls short of providing the pipeline creation, scheduling, and automation features that any decent MLOps platform must have.
True MLOps requires seamless orchestration of complex workflows, from data ingestion and preprocessing to model training, validation, and deployment. MLflow cannot natively handle dependencies between pipeline steps, conditional execution, or parallel processing.
This architectural gap forces ML teams to switch to an MLflow alternative.
2. Framework and Language Agnosticism
Through extensive hands-on testing, we discovered that the ideal MLflow alternative should genuinely support multiple ML frameworks, including TensorFlow, PyTorch, Scikit-learn, XGBoost, and emerging frameworks without forcing you into a specific ecosystem.
In our evaluation, we prioritized platforms that provide comprehensive REST APIs for integration with custom tools, legacy systems, and languages not directly supported.
3. Easy to Set Up and Use
Based on our real-world implementation experience, setup complexity should be minimal, with clear documentation, automated deployment scripts, and reasonable default configurations that work out of the box.
We evaluated the learning curve by:
- Measuring how quickly new team members can become productive across different platforms.
- Whether the platform required specialized knowledge (like Kubernetes expertise).
- The quality of available tutorials and examples.
What are the Best Alternatives to MLflow?
Some of the best MLflow competitors and alternatives are:
| Category | Alternatives | Key Features |
|---|---|---|
| 1. Best Overall | ZenML, ClearML | End-to-end MLOps platforms (tracking, orchestration, and deployment). |
| 2. Experiment Tracking | Weights & Biases, Neptune.ai | Experiment tracking with rich metadata and visualization. |
| 3. Model Serving & Deployments | BentoML, AWS SageMaker | Specialized model deployment and serving capabilities. |
| 4. Pipeline Orchestration | Kubeflow, Valohai | Workflow orchestration for ML pipelines at scale. |
| 5. Model Registry & Sharing | Azure ML | Central model registry for collaboration across teams. |
Category 1. Best Overall
If you want an end-to-end MLOps platform to cater to all your needs, ZenML and ClearML are among the best MLflow alternatives to try.
1. ZenML
ZenML takes a fundamentally different approach to ML orchestration compared to MLflow and traditional platforms. While MLflow excels at experiment tracking and model management, ZenML prioritizes developer experience and flexibility without sacrificing production readiness.
Feature 1. Easy to Deploy Pipelines with Production-Ready Outcomes
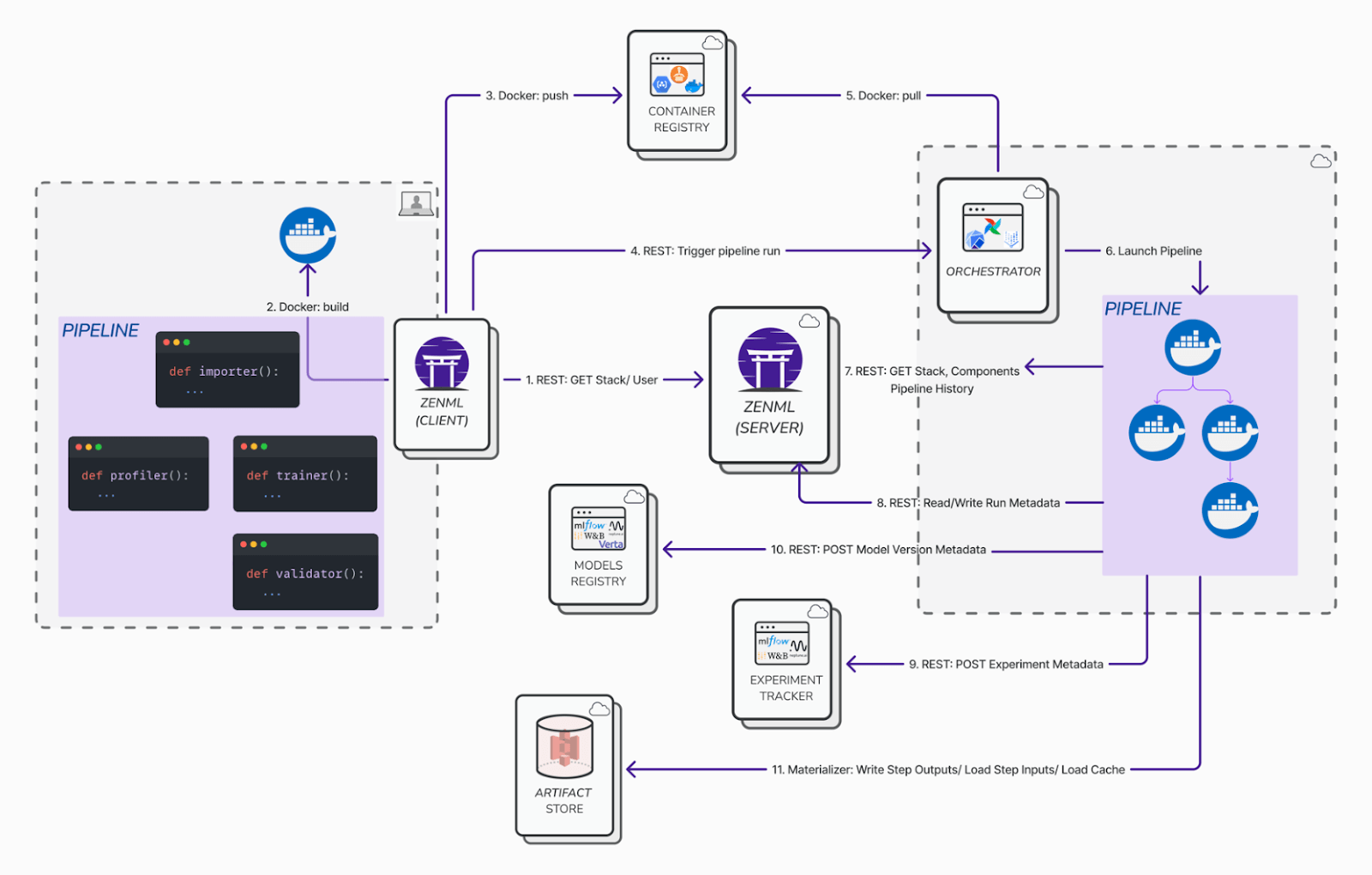
ZenML transforms standard Python code into reproducible pipelines with minimal annotations - something MLflow doesn’t offer natively. While MLflow focuses on tracking individual experiments, ZenML lets ML practitioners use familiar Pythonic workflows while automatically gaining critical MLOps capabilities like code-to-pipeline transition, infrastructure abstraction, native caching, and more.
Where MLflow requires external tools for pipeline orchestration, ZenML converts research code into production-ready pipelines with minimal modifications, avoiding extensive rewrites. Teams can develop locally and deploy anywhere through configurable ‘stacks’ - a concept that goes beyond MLflow’s tracking capabilities to include infrastructure management.
Feature 2. Comprehensive Metadata Tracking and Artifact Versioning
ZenML’s metadata system offers more automated capabilities than MLflow’s traditional tracking approach. While MLflow requires manual logging of artifacts and metadata, ZenML automatically tracks and versions each artifact produced by a pipeline step upon execution, guaranteeing reproducibility without extra effort.
ZenML’s metadata layer sits at the heart of every run, delivering more automation and structure than MLflow’s default tracking server.
- Automatic artifact versioning – every dataset, model, or metric emitted by a step is versioned and traceable out of the box.
- Rich metadata capture – data frames, models, and metrics are logged with shapes, schemas, and scores automatically.
- Human-readable naming – give runs and artifacts friendly names (e.g., ‘baseline_dataset_v1’) instead of opaque IDs, making lineage easy to follow.
👀 Note: The beauty of ZenML is its integration with ZenML. If you prefer using MLflow, ZenML integrates with your existing MLflow tracking server, so you don’t need to choose one over the other. Keep MLflow for experiment logs while ZenML adds pipeline orchestration and structured metadata on top to raise reproducibility.
Here’s how you can integrate MLflow with ZenML for experiment and metadata tracking, artifact versioning, and more.
# zenml integration install mlflow
# zenml experiment-tracker register mlflow_tracker -f mlflow ...
from zenml import pipeline, step
from zenml.integrations.mlflow.experiment_trackers import MLFlowExperimentTracker
from zenml.client import Client
@step(experiment_tracker="mlflow_tracker")
def train_model(X_train, y_train, X_test, y_test):
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
model = RandomForestClassifier()
model.fit(X_train, y_train)
# ZenML automatically logs parameters and the model
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
# Only need to log custom metrics
return model, {"accuracy": accuracy}
@pipeline
def ml_pipeline():
X, y = load_data()
X_train, X_test, y_train, y_test = preprocess_data(X, y)
model, metrics = train_model(X_train, y_train, X_test, y_test)
ml_pipeline()Feature 3. The Model Control Plane: A Unified Model Management Approach
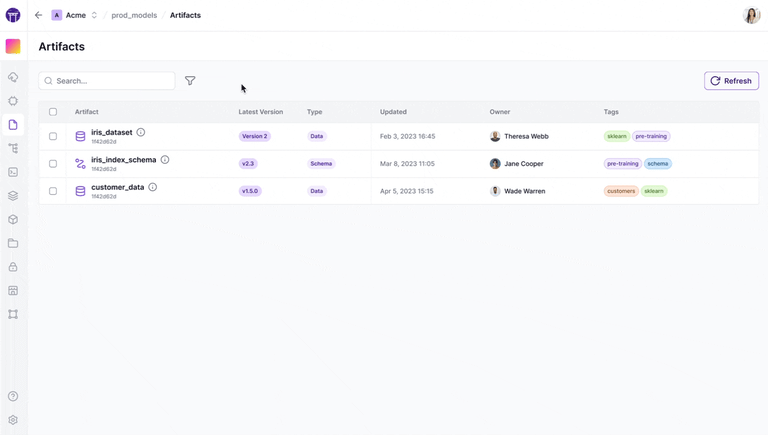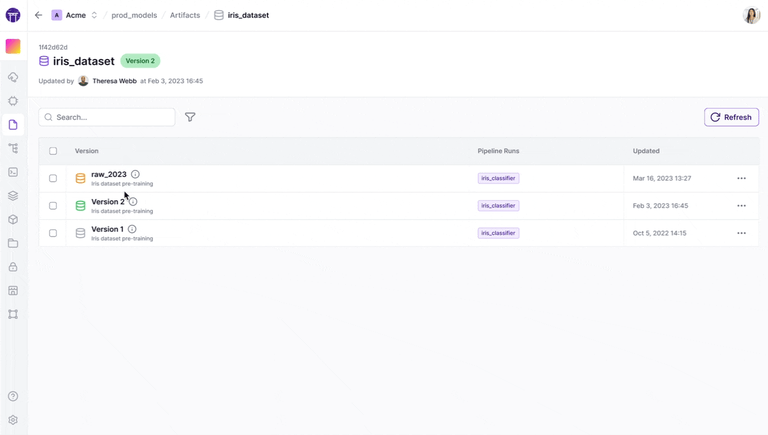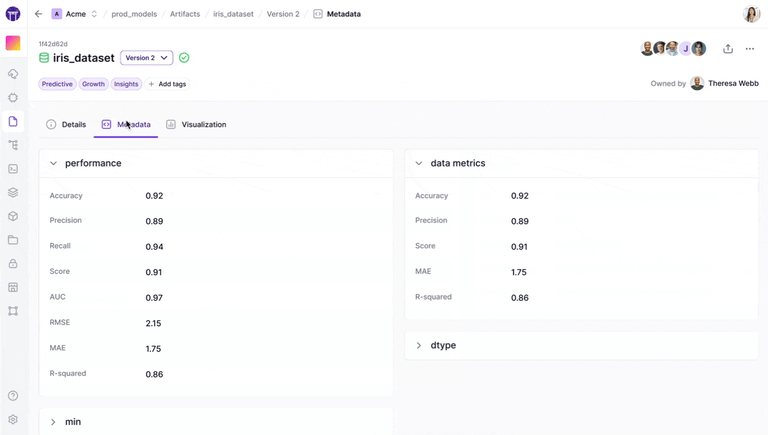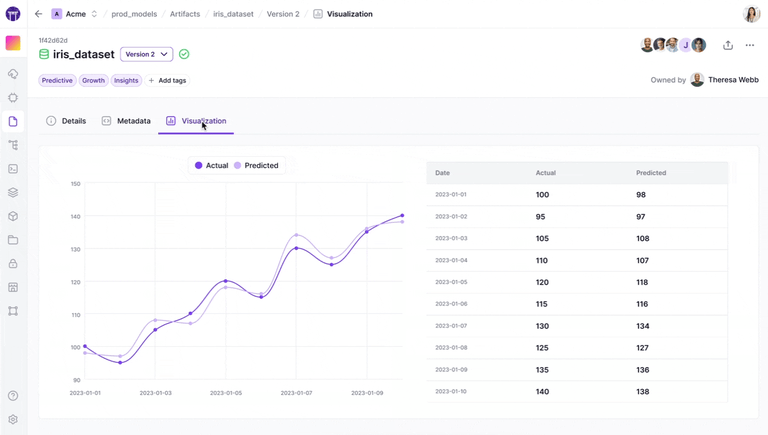
ZenML’s Model Control Plane represents a significant advancement over MLflow’s model registry approach.
Our platform groups relevant pipelines, artifacts, metadata, and business metrics for a given ML problem into a business-oriented model concept.
Each training run in ZenML produces a new Model Version, tracked automatically with lineage to the data and code that created it.
Feature 4. AI Agent and LLMOps Support
ZenML has evolved beyond traditional ML pipelines to become a comprehensive platform for operationalizing AI agents and LLM workflows. The framework provides native integration with popular agent frameworks like LangGraph and LlamaIndex, enabling teams to build reproducible agent pipelines with the same Pythonic approach used for traditional ML. ZenML’s artifact versioning automatically tracks prompt templates, retrieval chunks, and agent conversation histories, while the Model Control Plane extends to managing LLM fine-tuning runs and prompt optimization experiments. This positions ZenML as one of the few platforms bridging classical MLOps and the emerging LLMOps paradigm within a single, consistent framework.
How Does ZenML Compare with MLflow
Here are a few reasons to switch from MLflow to ZenML:
1. Built-in Pipeline Orchestration
ZenML provides native pipeline orchestration capabilities that transform your Python code into reproducible workflows without requiring external tools.
MLflow excels at experiment tracking and model registry but requires integration with separate orchestration platforms like Airflow, Kubeflow, or Prefect for pipeline management. This means additional setup complexity and maintaining multiple tools.
2. Automatic Metadata Capture vs. Manual Logging
ZenML automatically captures experiment metadata, artifacts, and lineage as part of its pipeline execution, reducing the amount of boilerplate code teams need to write.
Whereas, MLflow requires explicit logging statements throughout your code using mlflow.log_param(), mlflow.log_metric(), and similar functions. This manual approach increases the chance of missing important tracking information.
Pros and Cons
ZenML’s vendor-agnostic “stack” architecture enables easy migration between tools and cloud providers, reducing vendor lock-in risks. The platform is fully open-source with an Apache 2.0 license, promoting transparency and allowing unlimited customization to meet your specific needs.
However, our platform does not have a native Spark/Ray runner; you must wire these frameworks yourself.
📚 Learn more about ZenML: Documentation.
2. ClearML

ClearML is an end-to-end MLOps platform that, like MLflow, started with experiment tracking but has evolved into a full-suite solution covering everything from data management to model deployment.
Features
- Experiment ClearML provides an experiment manager similar to MLflow’s tracking UI, but with extra bells and whistles. Every training run is logged with parameters, metrics, source code snapshot, environment packages, and even the git diff of your code.
- Track large datasets through ClearML Data, which automatically logs data file hashes, versions, and metadata. This means your training data and preprocessing steps are version-controlled just like code.
- ClearML Deploy is the module that serves models in production. It supports deploying models as REST API endpoints (real-time serving) or batch jobs, with one-click deployment from the ClearML UI.
- Built-in hyperparameter optimization reduces training time and improves model accuracy without requiring code changes.
Pros and Cons
ClearML’s design is modular – you can adopt only the pieces you need (ex, just use it for experiment tracking initially) and gradually leverage more.
But, it has a steeper learning curve and setup time than a single-purpose tool. New users might find the documentation overwhelming, as it spans many components and use cases.
Category 2. For Experiment Tracking and Metadata
Weights & Biases and Nepture* excel at experiment tracking, model metadata management, and collaboration. We suggest you leverage these to replace or enhance MLflow’s tracking component with more advanced UIs and features.*
3. Weights & Biases
Weights & Biases (W&B) is a cloud-based experiment tracking platform that provides a slick UI to log and visualize everything about your ML experiments.
📚 Read more about how ZenML integrates with Weights and Biases for experiment tracking and visualization.
Weights & Biases Experiment Tracking and Metadata Features
The core of W&B allows you to track machine learning experiments with just a few lines of code. You initialize a run with wandb.init()** **in your training script, and then log metrics (loss, accuracy, etc.), parameters, and even arbitrary artifacts (datasets, model files) with simple API calls. These get streamed to the W&B cloud in real-time.
You can then review training progress in an interactive dashboard – plots update live as your model trains, and you can compare multiple runs on the same plot to see differences.
All the metadata is stored in the W&B cloud, making it easy to query past experiments and reproduce them.
You can track ML experiments with a few lines of code:
# Start a run.
#
# When this block exits, it waits for logged data to finish uploading.
# If an exception is raised, the run is marked failed.
with wandb.init(entity="", project="my-project-name") as run:
# Save mode inputs and hyperparameters.
run.config.learning_rate = 0.01
# Run your experiment code.
for epoch in range(num_epochs):
# Do some training...
# Log metrics over time to visualize model performance.
run.log({"loss": loss})
# Upload model outputs as artifacts.
run.log_artifact(model)Other Prominent Features
- Version and track datasets, models, and other assets throughout the ML lifecycle.
- Create shareable reports with interactive visualizations.
- Automated hyperparameter tuning with various optimization algorithms.
Pros and Cons
We liked how easy W&B is to use – instrumenting your code is often a copy-paste of 5 lines, and you immediately get an attractive UI for your experiments. It’s the best platform in this list when it comes to visualization capabilities.
Since the platform is primarily cloud-hosted, it’s normal to have concerns about sending sensitive experiment data to an external service.
Compared to MLflow, W&B can be expensive for larger teams once you exceed free limits.
📚 Learn more about W&B: Documentation.
4. Neptune
Neptune is designed to log any and all metadata from your ML experiments in a structured way, and it provides a powerful UI and API to query and analyze this metadata.
📚 Read more about how ZenML integrates with Neptune for powerful experiment tracking capabilities.
Neptune Experiment Tracking and Metadata
At its core, Neptune allows you to log, store, display, organize, compare, and query all your model-building metadata in one place. You integrate it by initializing a Neptune run (e.g., neptune.init() in Python) and logging various data: metrics, hyperparameters, model binary files, images, interactive charts, etc.
Neptune’s UI provides a table view of all runs with sortable columns (each parameter or metric can be a column) and a search query language to find experiments matching certain criteria (useful when you have thousands of runs). This is more advanced than MLflow’s filtering and even a bit beyond W&B’s filtering capabilities, giving you a database-like power over your experiment metadata.
Other Prominent Features
- Lets you structure your metadata as you like (it isn’t limited to predefined metrics/params).
- Teams can collaborate on Neptune by sharing projects. It has user management (especially in the enterprise self-hosted version) to control who can view/edit projects.
- Integrates with popular libraries and has a robust API/CLI.
Pros and Cons
Neptune.ai’s biggest pro is its flexibility in metadata handling. It can become the single source of truth for all experiment data, with a level of organization that scales to enterprise needs (searchable and queryable).
Neptune, being focused on tracking, means you’ll need complementary tools for other parts of the lifecycle (deployment, etc.). If you’re looking for a one-stop platform, Neptune isn’t it.
📚 Learn about Neptune - Documentation.
Category 3. For Model Serving and Deployments
BentoML and AWS Sagemaker* specialize in deploying machine learning models to production and serving predictions at scale – areas where MLflow’s own model serving (MLflow Models) may be insufficient or too hands-on.*
5. BentoML
BentoML is an open-source framework specifically focused on model serving. It helps you package trained models along with code and dependencies into a standardized ‘Bento’ format that can be deployed as API endpoints or batch jobs.
📚 ZenML integrates with BentoML for model deployment.
BentoML Model Serving and Deployments Feature
At the heart of BentoML is the concept of a Bento - a standardized bundle containing a model and all code, files, and environment needed to run it. You can think of it as a portable container for model inference.
Using BentoML’s Python API, you save a trained model (from PyTorch, TensorFlow, scikit-learn, etc.) as a Bento and define a service (a set of inference APIs). BentoML can then automatically generate a Docker image for this service, handling all the dependency packaging and environment setup for you.
This addresses one crucial pain point of MLflow: with MLflow, you can log a model, but deploying it in a consistent environment requires manually ensuring the same Python/R library versions. BentoML solves ‘dependency hell’ by capturing an exact environment via a simple config or Python decorator and containerizing it, ensuring reproducibility across platforms.
Other Prominent Features
- BentoML supports virtually any ML framework. It has adapters for Tensorflow, PyTorch, Scikit, XGBoost, HuggingFace Transformers, etc., so you can save models easily.
- The open-source BentoML can be self-hosted, but the team provides a hosted solution called Yatai (and the newer BentoCloud) that acts as a model serving platform.
- When you deploy via BentoML, it can integrate with logging and monitoring tools.
Pros and Cons
For model deployment, BentoML is one of the most straightforward yet powerful tools. It dramatically simplifies going from ‘model in a notebook’ to ‘running service’ – you don’t have to write Flask servers or deal with Docker build files manually.
BentoML specializes in serving, so you’ll still need something like MLflow or others for experiment tracking earlier in the pipeline.
📚 Learn about BentoML - Documentation.
6. AWS Sagemaker
Amazon SageMaker is a fully managed machine learning platform by AWS. It covers the entire ML lifecycle, but we specifically tested and liked its model deployment and serving, where it offers a rich set of capabilities.
📚 Streamline your machine learning workflows by running ZenML pipelines as Amazon SageMaker Pipelines, a serverless ML orchestrator from AWS.
SageMaker Model Serving and Deployments Feature
Sagemaker provides enterprise-grade model serving with automatic scaling and management capabilities. The platform offers real-time inference endpoints with low latency for immediate predictions, essential for applications requiring instant responses.
Batch transform capabilities enable efficient processing of large datasets, making it ideal for scenarios where you must process thousands or millions of records simultaneously.
Automatic scaling responds to traffic patterns and custom metrics, ensuring your models perform well under varying loads.
# Deploy the model to inference-component-based endpoint
falcon_predictor = falcon_model.deploy(
initial_instance_count = 1,
instance_type = "ml.p4d.24xlarge",
endpoint_type = EndpointType.INFERENCE_COMPONENT_BASED,
endpoint_name = "<endpoint_name>"
resources = resources,
)
# Deploy another model to the same inference-component-based endpoint
llama2_predictor = llama2_model.deploy( # resources already set inside llama2_model
endpoint_type = EndpointType.INFERENCE_COMPONENT_BASED,
endpoint_name = "<endpoint_name>" # same endpoint name as for falcon model
)
</endpoint_name></endpoint_name>Other Prominent Features
- Can spin up training jobs on distributed infrastructure and has built-in algorithms and hyperparameter tuning jobs.
- Includes a Pipeline feature that allows building end-to-end machine learning workflows for CI/CD of ML. This ties into model deployment: for example, you can automate retraining and deployment when new data comes in.
- Because it’s on AWS, you get AWS-level security options – VPC isolation for your model endpoints, IAM role-based access, data encryption at rest and in transit, etc.
Pros and Cons
SageMaker offers extreme convenience for deployment if you are okay with AWS services. With a few API calls or clicks, your model is a scalable endpoint – no need to manage servers, Docker, etc.
The biggest con is lock-in to AWS. Your workflow becomes tied to SageMaker and the AWS console/SDKs.
📚 Learn about Sagemaker - Documentation.
Category 4. For Pipeline Orchestration
Kubeflow and Valohai* focus on orchestrating complex ML workflows (pipelines) across steps and computing environments – a capability outside MLflow’s scope but critical for production ML.*
7. Kubeflow

Kubeflow is an open-source toolkit for running Machine Learning workloads on Kubernetes. It gained fame as the ‘machine learning toolkit for Kubernetes,’ which allows ML pipelines to be defined and executed at scale on cloud or on-prem clusters.
📚 ZenML integrates with Kubeflow to orchestrate pipelines.
Kubeflow Pipeline Orchestration Feature
Kubeflow Pipelines is a platform for building and deploying portable, scalable ML workflows using containers on Kubernetes.
Key features of Kubeflow Pipelines include:
- You can author pipelines in Python using the KFP SDK. This lets you write functions and annotate them to become pipeline steps (containers).
- The Kubeflow Pipelines UI shows a graph of the pipeline and the real-time status of each step. You can drill into the logs of each step’s container.
- The platform encourages writing reusable pipeline components. You can create a catalog of components (like data preprocessing, training an XGBoost model, and more) and reuse them in different pipelines.
Other Prominent Features
- Includes custom controllers to run distributed training on Kubernetes for TensorFlow, PyTorch, etc., managing all-reduce or parameter servers.
- Kubeflow has Katib, which is an HPO service. You can define a hyperparameter search, Bayesian, grid, random, etc., and it will launch multiple trial jobs on Kubernetes and find the optimal parameters.
Pros and Cons
Kubeflow’s main advantage is that it’s powerful and flexible. You’re leveraging the might of Kubernetes, which helps you run anything from small experiments to massive pipelines that use distributed computing.
Kubeflow is notoriously complex to deploy and manage. It demands Kubernetes expertise; setting up Kubeflow on a cluster can be non-trivial, and maintaining it is a serious ops effort.
📚 Learn more about Kubeflow: Documentation.
8. Valohai
Valohai is a lesser-known but powerful commercial MLOps platform focusing on automated pipeline orchestration and experiment tracking. It is a managed solution (closed-source) that aims to automate the entire ML workflow for companies, especially those who want to avoid building their own platform.
Valohai Pipeline Orchestration Feature
Valohai lets you define ML pipelines through YAML configuration (or via a UI) where you specify steps, their inputs/outputs, and dependencies. Each step can run in any Docker container environment you specify, and Valohai will orchestrate these steps on cloud VMs or Kubernetes (whichever you have connected).
A hallmark feature is what they call Smart Orchestration – Valohai automates the provisioning of resources and execution of pipelines with minimal input from you. With one click in the UI or one CLI command, you can launch thousands of experiments or a multi-step pipeline on any cloud provider.
Other Prominent Features
- Logs all metadata from runs and provides a dashboard to compare results, similar to Neptune or MLflow’s tracking UI.
- Integrate Valohai with anything since it’s just running Docker images. It plugs into Git (pulls the latest commit or a specific commit for each run, ensuring code versioning) and can connect to data sources (S3, Azure Blob, etc.).
Pros and Cons
Valohai can massively accelerate setup time for an MLOps pipeline. Instead of assembling and maintaining a stack of tools, you subscribe to Valohai and get an out-of-the-box platform.
The primary con is that Valohai is a proprietary paid platform, which means vendor lock-in and potentially high costs.
📚 Learn more about Valohai: Documentation.
Category 5. For Model Registry and Sharing
Azure ML* is one of the strongest ML Ops platforms in model registry and collaboration. MLflow’s Model Registry is basic; Azure offers more advanced model management and sharing capabilities.*
9. Azure ML
Azure ML is Microsoft’s cloud ML platform. Similar to SageMaker on AWS, it covers the end-to-end ML lifecycle on Azure. We highlight it here specifically for its Model Registry and model sharing features, which are particularly well-suited if you’re already in the Azure ecosystem.
📚 ZenML integrates with AzureML to leverage the robustness and scalability of Microsoft’s cloud-based orchestration service.
Azure ML Model Registry and Sharing Feature
Azure ML offers enterprise-grade model management capabilities with robust collaboration features for large organizations. The centralized model registry provides a single location to store, version, and manage models across multiple teams and projects.
Model lineage tracking captures the complete history of models, including data dependencies, training parameters, and performance metrics. Cross-workspace sharing capabilities enable teams to share models and pipelines across different workspaces and departments seamlessly.
Azure ML’s model registry can integrate with Azure’s CI/CD (Azure DevOps or GitHub Actions) so that when a new model is registered, it can trigger an automated deployment pipeline, enabling MLOps best practices like continuous delivery of models.
Other Prominent Features
- Provides experiment tracking - Azure ML Experiments, a suite for ML pipelines, AutoML, etc.
- Microsoft pushes the integration of Azure ML with Azure DevOps and GitHub.
- Azure ML Studio allows role-based access so multiple users can collaborate on a workspace.
Pros and Cons
The model registry is especially useful for large teams as it provides a single source of truth for models and prevents siloed model management.
While the registry itself doesn’t have a direct cost, using Azure ML services (like compute for training or deployment) will incur Azure cloud costs.
📚 Learn about Azure ML: Documentation.
MLOps and AI Agents: The Landscape in Late 2025
The MLOps ecosystem has undergone a fundamental transformation throughout 2025, driven by what industry experts are calling “the year of the AI agent.” Traditional experiment tracking platforms like MLflow are being rapidly augmented or replaced by tools that support the full lifecycle of agentic AI systems.
The Rise of LLMOps: Organizations are increasingly moving beyond traditional MLOps to embrace LLMOps (Large Language Model Operations), which addresses unique challenges like prompt engineering, hallucination prevention, and context management. According to recent enterprise surveys, 99% of developers building AI applications are now exploring or actively developing AI agents, creating unprecedented demand for platforms that can orchestrate these complex workflows.
Market Explosion: The global MLOps market has experienced explosive growth, expanding from $1.58 billion in 2024 to a projected value between $19.55 billion and $89.18 billion by 2032, depending on market definitions. This represents a compound annual growth rate (CAGR) of 35-45%, reflecting the rapid enterprise adoption of AI-native applications. North America continues to dominate with approximately 41% market share, though Asia-Pacific is emerging as the fastest-growing region.
Production Agent Deployment: Real-world agent systems in production look quite different from research demos. Successful implementations tend to be narrow, single-domain specialists operating under human supervision rather than fully autonomous systems. Retrieval-Augmented Generation (RAG) has become the default pattern for production LLM applications, spawning specialized orchestration tools as core MLOps components. Companies are finding that evaluation infrastructure and human-in-the-loop golden datasets are more critical than ever for maintaining quality in agent deployments.
These shifts mean that when evaluating MLflow alternatives in 2025, teams must consider not just experiment tracking and model deployment, but also capabilities for managing LLM fine-tuning, prompt versioning, agent orchestration, and the unique monitoring requirements of generative AI systems.
Common Questions About MLflow Alternatives in 2025
What’s the difference between MLOps and LLMOps, and do I need different tools? LLMOps extends traditional MLOps to handle the unique complexities of large language models and AI agents, including prompt engineering, context window management, and hallucination detection. While platforms like MLflow can track LLM experiments, specialized LLMOps-ready alternatives like ZenML, W&B, and Azure ML now offer native support for prompt versioning, LLM-specific metrics, and agent workflow orchestration. Most organizations in 2025 benefit from platforms that handle both traditional ML and LLM workloads within a unified framework.
How much does it cost to move from MLflow to a commercial alternative? Costs vary significantly by platform. Open-source alternatives like ZenML and ClearML offer free self-hosted options with optional paid enterprise features. Cloud-native solutions like AWS SageMaker and Azure ML charge based on compute usage (typically $0.10-$13.83 per hour for training instances) with no platform fees. SaaS platforms like Weights & Biases and Neptune offer tiered pricing starting around $50-200 per user per month for teams, while enterprise deployments can run several thousand dollars monthly. Many teams find that the operational efficiency gains and reduced infrastructure management costs offset the platform fees within 3-6 months.
**Can I use multiple MLflow alternatives together, or do I need to choose one?**Modern MLOps architecture is increasingly modular. Many successful teams combine tools - for example, using ZenML for pipeline orchestration while integrating MLflow for experiment tracking, or coupling Kubeflow with W&B for visualization. The key is selecting platforms with strong integration capabilities. ZenML explicitly supports this approach through its stack architecture, allowing you to compose best-of-breed tools. However, for smaller teams, all-in-one platforms like ClearML or Azure ML can reduce integration complexity.
Which MLflow alternative is best for deploying AI agents in production? For AI agent deployment in 2025, consider platforms with strong LLMOps capabilities and agent orchestration support. ZenML offers flexible integration with agent frameworks like LangGraph and LlamaIndex while providing pipeline orchestration. AWS SageMaker and Google Vertex AI have introduced native agent builders (Bedrock Agents and Vertex AI Agent Builder) with managed infrastructure. For teams building custom agents, platforms that support prompt versioning, human-in-the-loop evaluation, and RAG pipeline orchestration—like ZenML with W&B integration or ClearML—provide the most comprehensive solution.
Quick Selection Guide: Which MLflow Alternative for Your Use Case?
- Building AI Agents or LLM Applications: ZenML (for flexible orchestration with agent frameworks), AWS Bedrock (for managed agent infrastructure), or Google Vertex AI Agent Builder (for rapid prototyping)
- Need Strong Experiment Tracking & Visualization: Weights & Biases (best-in-class UI and collaboration), Neptune (advanced querying), or ClearML (all-in-one with good tracking)
- Production Model Serving at Scale: BentoML (specialized for packaging and serving), AWS SageMaker (auto-scaling endpoints), or Seldon Core (Kubernetes-native serving)
- Pipeline Orchestration for Complex Workflows: ZenML (Python-native with flexible integrations), Kubeflow (Kubernetes power users), or Valohai (managed automation)
- Enterprise with Azure Investment: Azure ML (tight Microsoft integration, comprehensive RBAC)
- Startup or Small Team: Open-source MLflow (free, well-documented baseline), ZenML (free tier with easy scaling), or ClearML (all-in-one open source)
- Regulated Industry (Healthcare, Finance): Azure ML or AWS SageMaker (enterprise compliance built-in), ZenML with on-premise deployment (for data sovereignty)
- Multi-Cloud or Avoiding Vendor Lock-in: ZenML (cloud-agnostic stack architecture) or open-source ClearML (deploy anywhere)
Which is the Best MLflow Alternative for You?
All the wide range of platforms mentioned above are excellent alternatives to MLflow and effectively address its drawbacks.
From open-source toolkits like ZenML and Kubeflow that give you flexibility and control, to managed platforms like SageMaker and Azure ML that offer convenience, to specialized solutions like BentoML for model serving or Valohai for automated pipelines – there is no one-size-fits-all.
The ‘best’ alternative depends on your team’s priorities: Do you need a complete open-source stack or a managed service? Are you optimizing for ease of use or for customizability?
Ready to move beyond MLflow’s limitations? Book a personalized demo with ZenML to know how we can help you and your MLOps team