

On this page
In today’s enterprise landscape, Kubernetes has become table stakes for production ML workloads, with 96% of global enterprises running some production workload on K8s according to the latest CNCF survey.
Given this widespread adoption, it’s natural for ML teams within enterprises to leverage this robust infrastructure for their specific needs. Many have embraced Kubernetes for a range of applications, from batch feature computation to real-time inference, benefiting from its scalability, resilience, and automation capabilities. This alignment not only streamlines ML operations but also fosters a culture of experimentation and agility, enabling organizations to navigate the complexities of the digital age effectively.
However, using Kubernetes for machine learning brings its own pain points. Organizations find themselves in this curious middle ground where they need Kubernetes’ power but struggle with its complexity. They often maintain a hybrid approach – using managed services like Vertex AI Pipelines for some workloads while running custom Kubernetes clusters (maybe using platforms like Airflow or Kubeflow) for others. This is especially true when:
- Multi-cloud flexibility is non-negotiable
- GPU utilization and cost need granular control
- Regulatory requirements demand on-premises deployment

The arrival of LLMs has only amplified these issues. Training and deploying large language models demands specialized infrastructure setups—from GPU/TPU super-computers and high-bandwidth interconnects to optimized parallel-training frameworks—careful attention to data governance to ensure lineage, privacy, and compliance throughout the model lifecycle, and new approaches to monitoring/observability (LLMOps) that track output quality, cost, latency, bias, and safety in real time — all while preserving the agility ML teams need to iterate quickly by automating prompt-engineering workflows and shortening experiment cycles.
As one ML infrastructure lead at a leading fintech recently noted: “Our biggest challenge right now is managing infrastructure at scale. We’ve got an 8×H100 server and no good way to split it across jobs.” This sentiment echoes across industries where expensive GPU resources sit idle while teams wrestle with Kubernetes concepts far removed from their core expertise in data science.
The K8s MLOps Challenge: Why It Gets Messy Fast
| Kubernetes MLOps Pain Point | Business Impact |
|---|---|
| Cluster Complexity & Skill Gaps | Data scientists spend critical time debugging YAML instead of analyzing data, slowing innovation cycles. |
| Inefficient GPU Resource Allocation | Over 50% of training time wasted; $50K+ annual waste per team in idle H100 GPU time. |
| Multi-Tenant Governance & Security | 67% of organizations delay production releases due to K8s security concerns, amplified in regulated industries. |
| Data Gravity & Pipeline Orchestration | Large datasets and complex pipelines create bottlenecks when moving between storage systems. |
| Tool Fragmentation | Disconnected tools (notebooks → Airflow → Docker → Helm) create technical debt and deployment friction. |
| Missing Cost Visibility | Organizations can't track which teams consume expensive GPU resources, making budgeting impossible. |
ML practitioners often face the following difficulties when working with Kubernetes:
Cluster Complexity & Skill Gaps
The Kubernetes learning curve remains steep, particularly for those whose primary focus is model development rather than infrastructure. While DevOps teams might understand concepts like pods, deployments, and StatefulSets, ML practitioners often find themselves entangled in YAML files and configuration headaches. Data scientists excel at building models, not writing YAML manifests or debugging pod scheduling issues. This skill gap translates directly to reduced productivity and innovation.
As aptly summarized in Chips Huyen’s blog: “I became a data scientist because I wanted to spend more time with data, not with spinning up AWS instances, writing Dockerfiles, scheduling/scaling clusters, or debugging YAML configuration files.”
This disconnect creates friction in the ML lifecycle, slowing down experimentation and delaying the deployment of models that could deliver business value.
GPU Resource Allocation Is Inefficient
Perhaps no challenge is more pressing than efficient GPU allocation. Prior to recent innovations, Kubernetes demanded whole-GPU requests, often resulting in significant waste of expensive compute resources. For organizations with H100 clusters costing millions in capital expenditure, suboptimal GPU utilization translates directly to wasted investment.
Studies from Google, Microsoft, and IBM have shown that more than half of model training time is wasted because of waiting for data, creating GPU idle time, and inefficient resource utilization.A 2020 Datadog container report found that almost half of the containers used less than a third of their requested CPU and memory, suggesting widespread resource overprovisioning. In regulated industries like defense or finance, this resource inefficiency can amount to over $50,000 per year in idle GPU time for each model team. For companies developing computer vision pipelines for drones or real-time fraud detection systems, such inefficiency is simply untenable.
Multi-Tenant Governance & Security
Organizations developing ML models across multiple teams face additional complexity around governance. How do you ensure that the fraud detection team and the marketing personalization team can both access GPU resources without stepping on each other’s toes? How do you implement role-based access control (RBAC) at the pipeline level?
According to Red Hat’s 2024 security report, 67% of organizations have delayed production releases due to Kubernetes security and compliance concerns. In highly regulated environments like defense technology development or financial services, these concerns can bring model deployment to a standstill. For financial institutions, these concerns are amplified by regulatory scrutiny from bodies like the FCA and EBA.
Data Gravity & Pipeline Orchestration
The challenges extend to data management as well. ML pipelines often require access to large datasets that may reside in various storage systems. According to Kubermatic’s 2024 analysis, integrating AI/ML with Kubernetes presents several significant challenges including “complex setup and management, resource allocation and optimization, security and compliance, and continuous monitoring and maintenance of models”. This complexity is amplified when dealing with the “data gravity” problem—where massive datasets can’t be easily moved.
A survey from DataScienTest indicates that data scientists “must diligently monitor various metrics and the databases they use” and “need to manage access and credentials to data warehouses”. For financial institutions, these challenges manifest in configuring persistent volume claims, managing secrets securely, and establishing proper network policies—all while adhering to strict regulatory requirements.
Tool Fragmentation Creates Maintenance Nightmares
Without a unified approach, organizations often accrue technical debt through fragmented tooling. The typical journey looks something like this:
- Develop in Jupyter notebooks
- Schedule with Airflow cron jobs
- Containerize with custom Dockerfiles
- Deploy with manually crafted Helm charts
Each transition introduces complexity, increases the chance of errors, and widens the gap between development and production environments. As one ML lead put it: “We started with Airflow, then custom scripts, now looking at MLflow… It’s hard to keep track.”
Each transition introduces complexity, increases the chance of errors, and widens the gap between development and production environments. According to a Towards Data Science analysis, ML teams often need to “wrap our atomic steps around a configuration file that organizes the fragmented activities in a structured workflow” just to maintain basic process consistency.
This fragmentation creates real business challenges. As Productboard’s ML team observed when implementing their MLOps practices, “Data handover” between steps becomes a significant issue when trying to pass datasets between tasks. Even basic operations like transferring training data between preprocessing and model training steps require complicated workarounds.
Cost Visibility Is Often Missing
Organizations struggle with GPU cost observability in Kubernetes. According to Kubecost’s analysis released in October 2024, it’s critical for teams to track “GPUs which have not been requested at all and the wasted cost associated” with them. This lack of visibility becomes particularly problematic when multiple teams share expensive GPU resources.
A recent study by Finout highlighted that “Kubernetes doesn’t offer built-in cost observability” for tracking resources, leaving organizations blind to which pods or namespaces are consuming their GPU budget. Rafay’s platform documentation explains that “Monitoring how effectively GPUs are used in relation to their cost helps to ensure a good return on investment” – yet most organizations lack this capability.
As Komodor’s CTO noted in August 2024, “Kubernetes environments are highly dynamic, with containers being created, scaled, and terminated frequently. This constant change makes it challenging to keep track of resource usage and associated costs.” The result is that Kubernetes promised infinite scale, but for ML engineers, it often delivers infinite YAML, GPU dead-zones, and compliance headaches instead.
Modern Solutions: How ZenML Tames Kubernetes for ML Teams
ZenML addresses the complexities of Kubernetes for ML by providing an abstraction layer that makes enterprise-grade infrastructure accessible to ML practitioners while maintaining the power and flexibility that infrastructure teams require. Let’s dive into how ZenML transforms the Kubernetes experience for ML teams.
Service Connectors: Beyond Data Access
ZenML’s service connectors eliminate the complexity of managing connections across environments, but they go far beyond simple data access. These connectors provide a centralized, secure way to manage access to various resources—including Kubernetes clusters—across your organization.
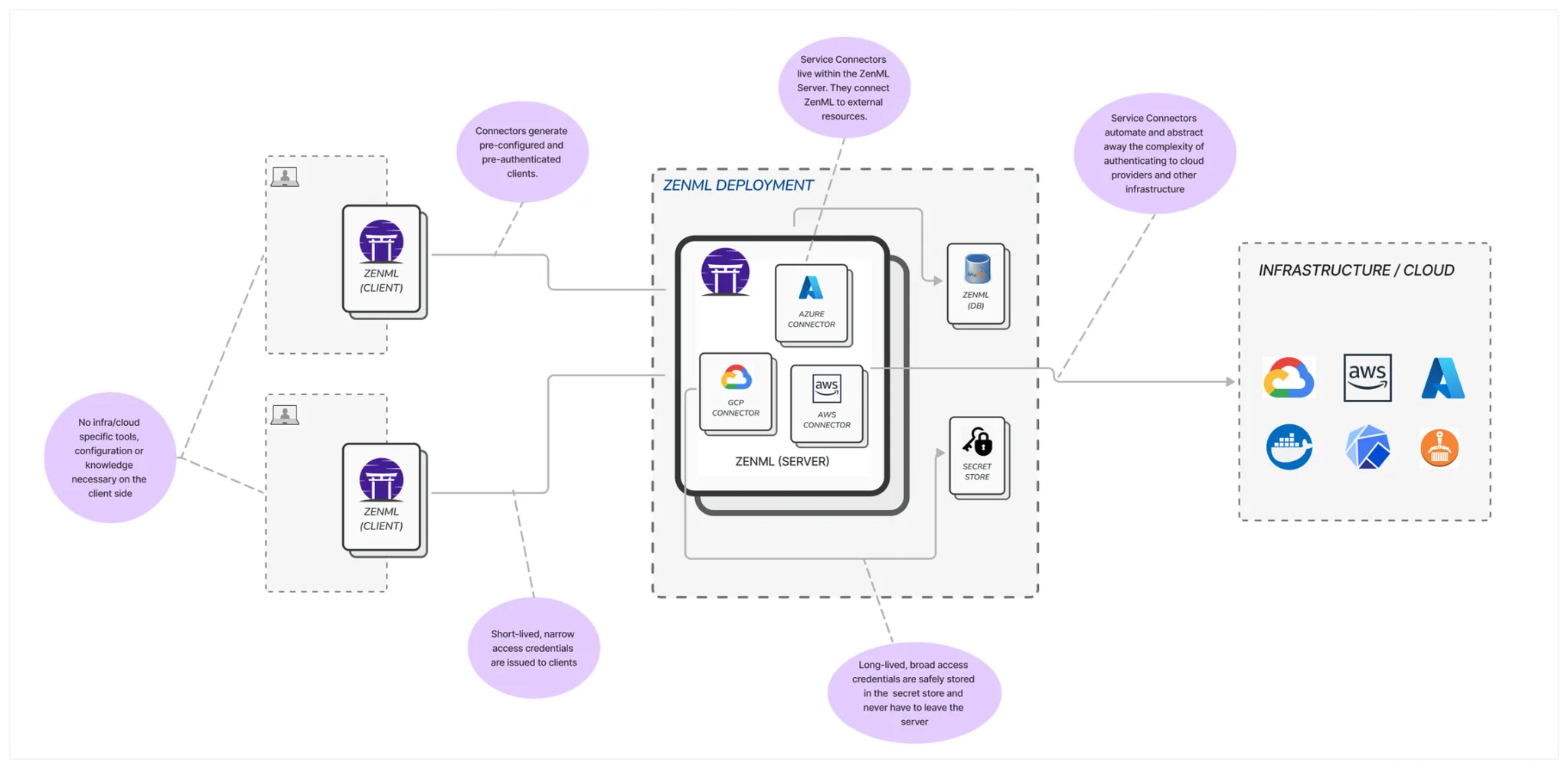
Service connectors serve as a bridge between your ML teams and infrastructure, allowing MLOps administrators to:
- Define connection profiles once and reuse them across pipelines
- Centrally manage authentication to cloud services, databases, and Kubernetes clusters
- Implement proper security controls with automatic credential rotation
- Enable controlled access to production resources without sharing sensitive credentials
For organizations with multiple teams and strict compliance requirements, service connectors create a secure boundary that allows data scientists to access the resources they need without compromising security policies. Infrastructure teams can define which Kubernetes namespaces or clusters are accessible to specific teams, all managed through ZenML’s unified interface.
To learn more about service connectors and the background to them, read our blog “How to Simplify Authentication in Machine Learning Pipelines (Without Compromising Security)”.
Modular Stacks: Infrastructure Governance Made Simple
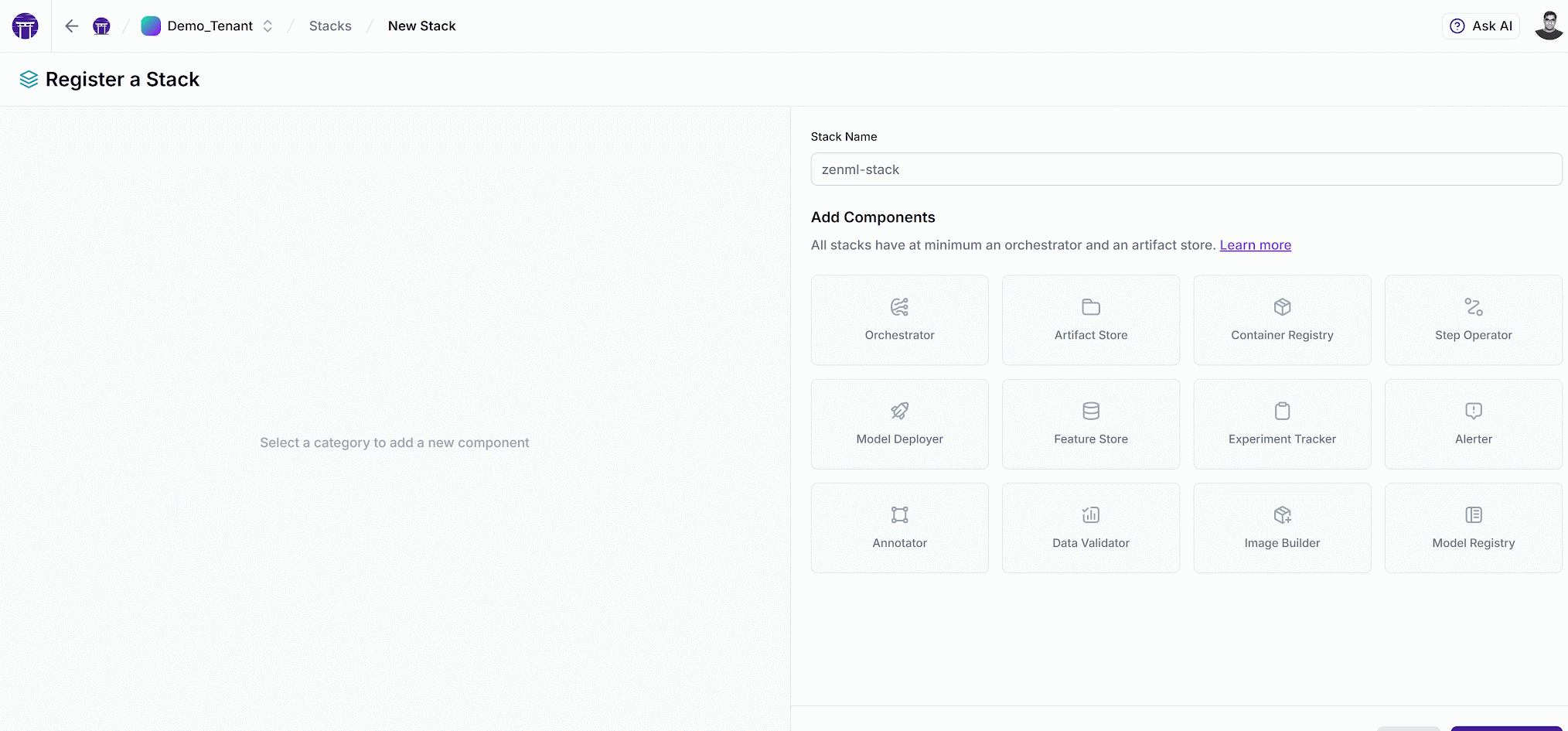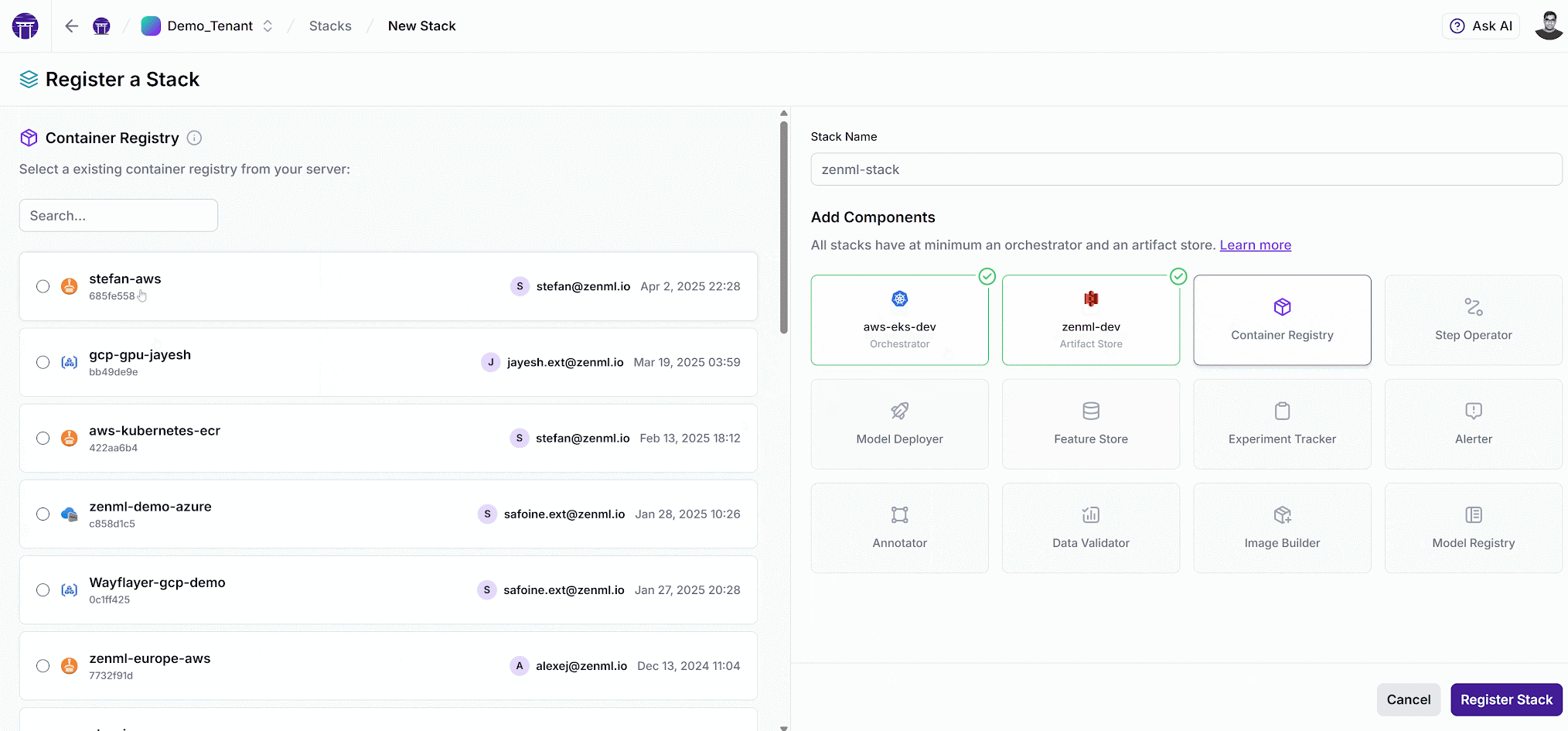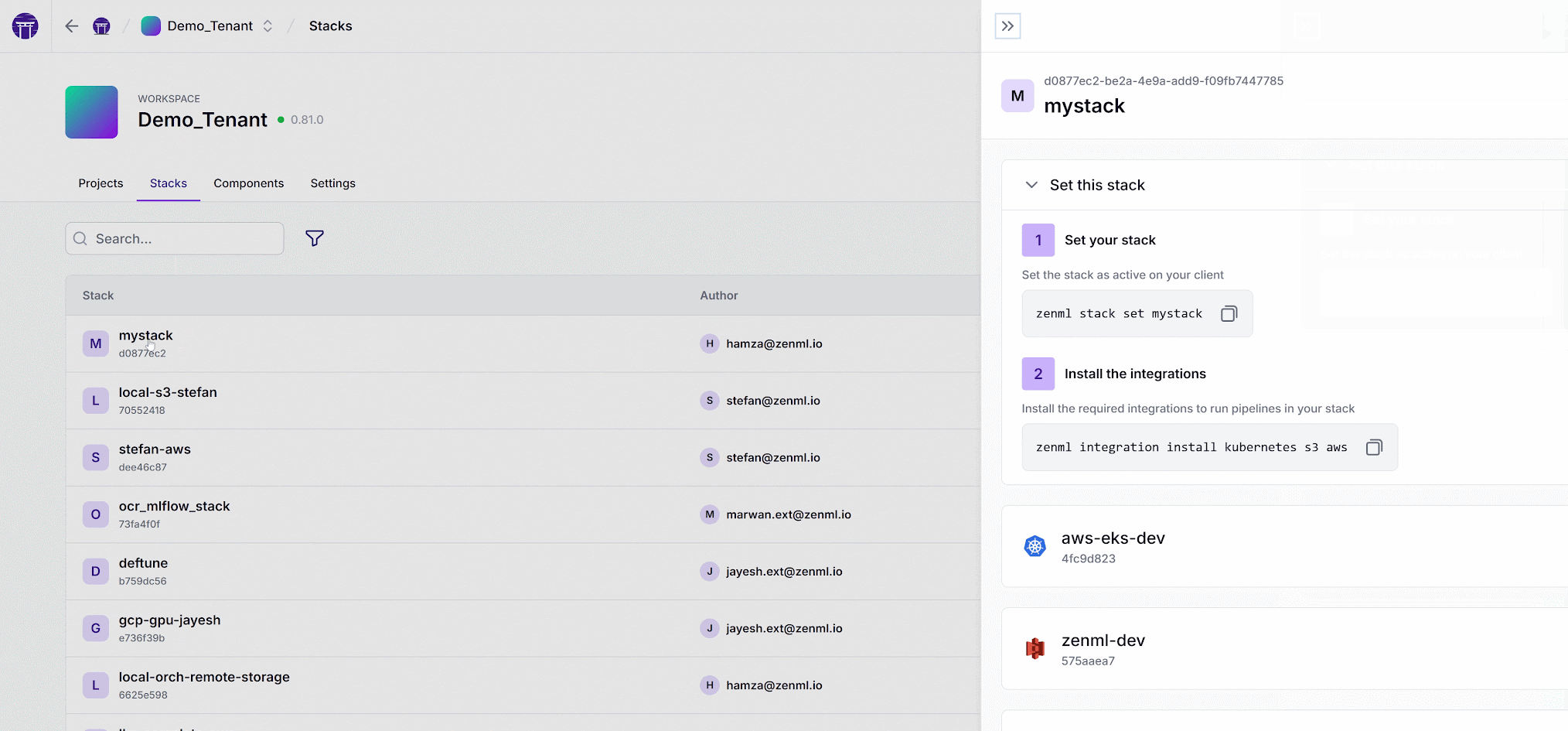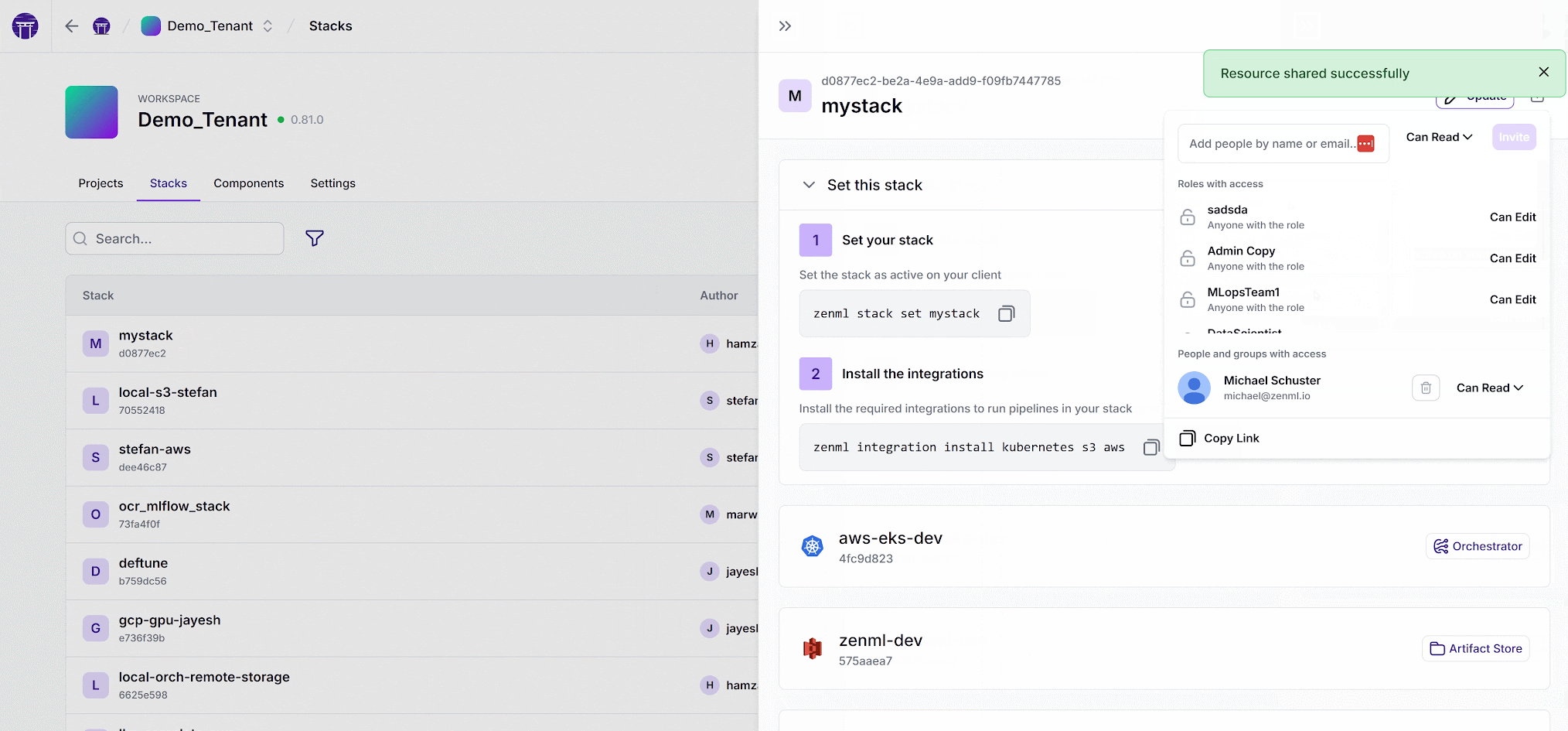
Connect disparate infrastructure stack components and share them securely with a few clicks
ZenML stacks significantly improve how ML infrastructure is managed at scale. Rather than forcing every data scientist to become a Kubernetes expert, stacks provide a composable, declarative way to define your ML infrastructure.
With ZenML Pro, administrators can create pre-approved stacks for different scenarios:
- Development stacks with limited resources for experimentation
- Production stacks with stricter governance for deployed models
- High-performance stacks with GPU access for training
- Compliance-focused stacks with additional audit capabilities
The ZenML Terraform provider makes infrastructure-as-code straightforward, allowing teams to define, version, and deploy their ML infrastructure alongside their application code. This approach bridges the gap between DevOps and ML teams:
# Example Terraform code to provision ZenML stacks
resource "zenml_stack" "production_stack" {
name = "production-gpu-stack"
description = "GPU-enabled stack for production workloads"
orchestrator_id = zenml_orchestrator.kubernetes_orchestrator.id
artifact_store_id = zenml_artifact_store.cloud_artifact_store.id
container_registry_id = zenml_container_registry.company_registry.id
}Organizations can implement robust access control, limiting which teams can use specific stacks based on their role and requirements. This governance layer ensures that production resources remain secure while enabling innovation across the organization.
Fractional GPUs: Maximizing Expensive Resources
The integration between ZenML and NVIDIA’s KAI Scheduler represents a way for ML teams building on Kubernetes to get the most out of their infrastructure. Traditional Kubernetes scheduling forces whole-GPU allocation, but real-world ML workloads rarely require 100% of a high-end GPU’s resources.
KAI Scheduler enables:
- Fractional GPU allocation: Request exactly the GPU memory needed (e.g., 8GB on a 40GB A100)
- Multi-tenant GPU sharing: Run multiple workloads on the same physical GPU with proper isolation
- Fair-share scheduling: Ensure all teams get equitable access to GPU resources
- Hierarchical queues: Create priority tiers for different workload types
- Gang scheduling: Coordinate distributed training jobs to start simultaneously
For financial institutions and other enterprises with substantial investments in GPU infrastructure, this capability alone can yield millions in savings by increasing utilization rates from typical 20-30% to 80%+ through intelligent resource sharing.
ZenML’s implementation abstracts away the complexity, allowing data scientists to simply specify their requirements while the platform handles all the intricate Kubernetes configurations to make it happen.
📢 See a working example of how to use fractional GPUs with ZenML on Kubernetes on GitHub
Beautiful UI for Data and Artifact Tracking
Beyond simplifying infrastructure, ZenML provides a comprehensive UI for tracking experiments, datasets, and model artifacts. This visual layer transforms how teams interact with their ML systems:
- Pipeline visualization: See the structure and execution of complex workflows
- Data lineage tracking: Understand how data flows through your system
- Experiment comparison: Easily compare model performance across runs
- Artifact inspection: Examine model assets and metrics without writing code
- Run history: Track all executions with their inputs, outputs, and parameters
The UI serves as a central hub for collaboration, allowing teams to share insights, troubleshoot issues, and make informed decisions. For regulated industries, this visualization layer also supports compliance efforts by making model development transparent and auditable.
Heterogeneous Compute Environments: The Best Tool for Each Job
ZenML’s architecture was designed from the ground up to support heterogeneous compute environments. Your pipelines aren’t limited to just Kubernetes—they can leverage the right compute environment for each specific task:
- Run preprocessing on Kubernetes for scalable data transformation
- Execute training on specialized GPU clusters for performance
- Deploy model serving on cloud-managed services like Vertex AI or SageMaker
- Schedule batch inference on Apache Spark for large-scale processing
- Utilize local execution for quick development iterations
This flexibility is particularly valuable for complex workflows that span multiple environments. A single pipeline can seamlessly orchestrate steps across on-premises Kubernetes clusters, cloud-managed services, and specialized AI infrastructure without changing your code.
The abstraction layer that ZenML provides means your teams can focus on what matters—building great models—while the platform handles the complexity of coordinating across these environments.
Example: Multi-Team GPU Access with ZenML for Financial Use-Case
Let’s explore a hypothetical scenario illustrating how a financial institution could implement ZenML to address ML infrastructure challenges across multiple departments.
The Challenge
Consider a financial institution with three distinct ML teams, each having different requirements:
- Fraud Detection Team: Needs reliable, high-priority access to GPU resources for real-time fraud prediction models
- Investment Research Team: Requires flexible GPU access for experimental quantitative models
- Customer Analytics Team: Runs periodic batch training jobs for customer segmentation and recommendation models
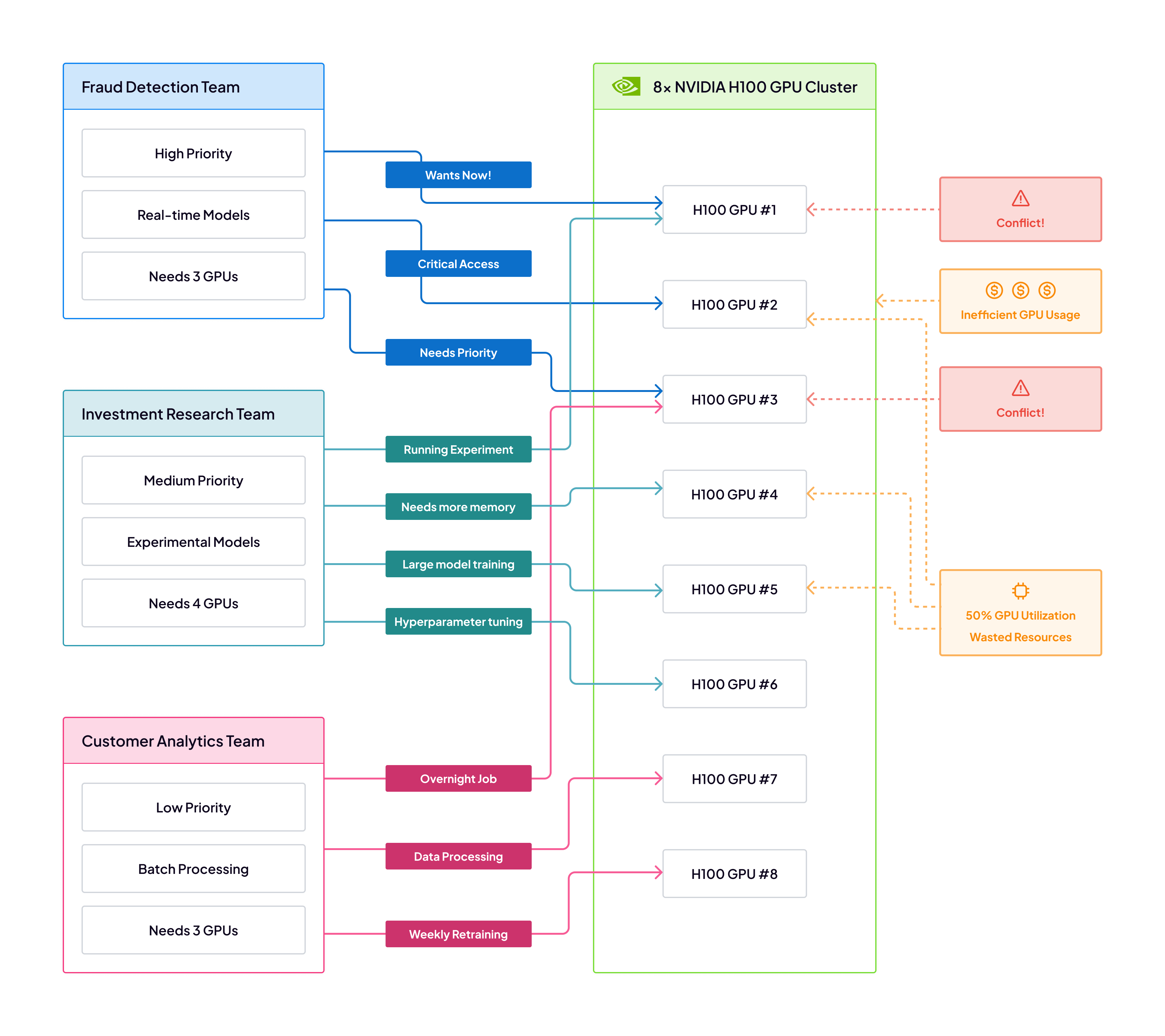
In this scenario, these teams would compete for resources on a shared GPU cluster, potentially leading to conflicts, inefficient resource utilization, and frustration. Critical fraud models might be delayed by experimental research jobs, while expensive GPU hardware could sit idle outside of business hours.
A Potential Solution Architecture
The institution could implement a ZenML solution with three distinct stacks sharing a single Kubernetes cluster enhanced with the KAI Scheduler:
- High-Priority Production Stack:
- Reserved GPU resources with highest queue priority
- Strict governance and approval workflows
- Automated testing and deployment pipelines
- Used by the Fraud Detection team for mission-critical models
- Research and Development Stack:
- Flexible GPU allocation with fair-share scheduling
- Jupyter integration for interactive development
- Experiment tracking and comparison capabilities
- Used by the Investment Research team for model exploration
- Batch Processing Stack:
- Scheduled execution during off-peak hours
- Larger GPU resource allocation during nights and weekends
- Pipeline-level caching to optimize repeated runs
- Used by the Customer Analytics team for periodic retraining
With this, the entire ML process across the enterprise becomes cleaner and more efficient:

The Benefits
With this type of architecture, an organization might expect to see benefits such as:
- Cost Optimization: Fractional GPU sharing and intelligent scheduling reduce infrastructure costs by 30-50% through improved resource utilization.
- Regulatory Compliance: End-to-end lineage tracking and immutable pipeline versions satisfy model risk management requirements in frameworks like SR 11-7.
- Enterprise Security: Strict isolation between teams and role-based access control protect sensitive financial data while enabling multi-tenancy.
- Accelerated Delivery: Pre-configured stacks and automated orchestration let data scientists focus on models instead of infrastructure, significantly reducing time-to-market.
- Environmental Flexibility: A consistent layer works across on-premises clusters, cloud resources, and specialized hardware, simplifying operations in complex hybrid environments.
Most importantly, data scientists can focus on model development rather than infrastructure management, accessing ML resources through a consistent interface regardless of whether they’re working on experimental models or production systems.
For examples of how to implement similar patterns, visit our GitHub repository where we provide sample code and configuration
Infrastructure That Gets Out of the Way
The most valuable ML infrastructure is the kind you don’t notice - it just works, allowing data scientists and ML engineers to focus on building models that drive business value rather than battling YAML and resource constraints.
By combining ZenML’s orchestration capabilities with Kubernetes advanced GPU scheduling, organizations gain the best of both worlds: the flexibility and power of modern infrastructure with the simplicity and accessibility that ML teams need.
For institutions dealing with the dual pressures of innovation and regulation, this approach doesn’t just solve technical problems - it creates a competitive advantage through faster, more reliable AI deployment.
Want to learn more about how ZenML can help your organization scale MLOps on Kubernetes? Reach out for a personalized demo to get started today.


