Last updated: November 21, 2022.
Last week’s blog on the places where data annotation plays a role in the MLOps lifecycle saw us receive lots of conversations and feedback from readers. It is clear that annotation must have a role in the story we tell about MLOps if a data-centric approach is known to bring value. Here at ZenML we’re really enthusiastic about how we can support the integration of these behaviors and practices as part of the wider machine learning lifecycle, so we cooked up something to support all of you who are interested in trying out some of these tools. But more on that a bit later!
We’ve been reviewing the space of annotation and labeling, and how it intersects with the lifecycle practices of machine learning in production. If MLOps is a booming space, then it seems data annotation is equally so, with new tools being released all the time. The big distinction seems to be that most of the innovation in annotation seems to happen behind closed doors; the open-source space is currently much less of a competitive arena. Indeed, this is probably the big choice you’ll have to make if you get to choose which annotation tool to use: integrate with a close-source platform that does a lot or choose a more flexible open-source option with fewer features.
The tradeoffs for both are often similar to the broader tools around choosing open-source for MLOps. (See Matt Squire’s blog on why open-source MLOps is awesome for a strong position on why you should go with open-source.) In broad strokes, open-source gives you flexibility and freedom albeit with the caveat that there might be some initial hurdles to get things set up and working in exactly the way you want. If you find a closed-source platform that fits completely with your situation and needs then that might be the way to go (at least initially). Eventually and inevitably, your needs will change and at that point you will likely feel the pain of being stuck in a box that doesn’t allow you the flexibility to reshape how the tool serves your needs. This is one of the clear and standout advantages of choosing the open-source route.
With all this in mind, I gathered together a list of all the open-source data labeling tools available currently. You can check out our awesome-open-data-annotation repository here.
The core selection criteria were as follows:
- The tool needs to have an open-source license.
- The tool needs to be actively maintained. (Someone’s hobby project from 5 years ago probably isn’t going to be of much use in a production environment in 2022.)
- The tool should be functional and fit for purpose.
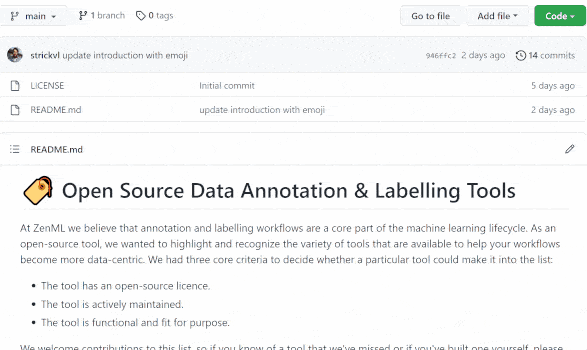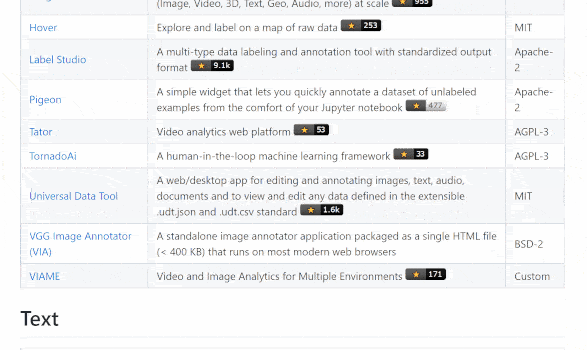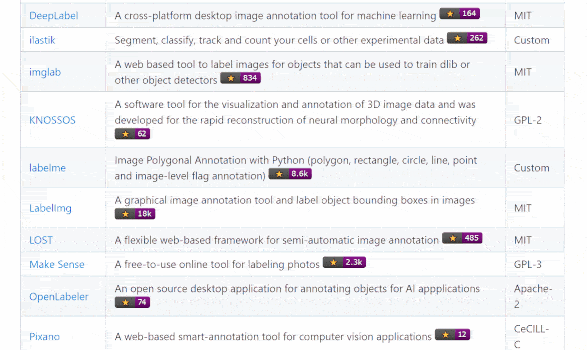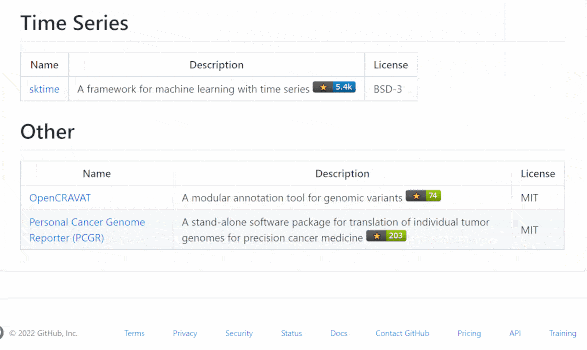
The repository showcases 48 tools with different specialisms, from text to images to cross-domain options. I was pleasantly surprised to find so many. Moreover, the selection include some that have been around for a few years and also others that are much newer. This shows that the space is still seen as one where it makes sense to invest in engineering robust solutions. As one example of this, we were excited to see companies like Recognai push forward in their development of the textual annotation tool Rubrix.
We welcome contributions to this repository. From suggestions for tools that we’ve missed to categories of annotation that we weren’t aware of, please feel free to send us your Pull Requests!
🔥 Do you use these tools or do you want to add one to your MLOps stack? At ZenML, we are looking for design partnerships and collaboration to develop the integrations and workflows around using annotation within the MLOps lifecycle. If you have a use case which requires data annotation in your pipelines, please let us know what you’re building and there are tools you feel like you couldn’t live without! The easiest way to contact us is via our Slack community which you can join here.
[*Cover photo by Darya Tryfanava on *Unsplash]