

On this page
Efficiently utilizing GPU resources in Kubernetes environments has always been challenging. When running machine learning workloads, we often face the “all-or-nothing” problem with GPU allocation: a pod requesting GPU resources gets assigned an entire physical GPU, even when the workload only needs a fraction of its power. NVIDIA’s KAI Scheduler (formerly CHI Scheduler) solves this problem by enabling fractional GPU allocation, allowing multiple workloads to share the same physical GPU. This blog post demonstrates how to leverage KAI Scheduler with ZenML to optimize your GPU resources and reduce costs.
TL;DR If you already have a GPU‑enabled GKE cluster, jump straight to the “Run the ZenML test pipeline” section and watch your fractional‑GPU pods spin up under KAI Scheduler.
Why should you care about KAI Scheduler?
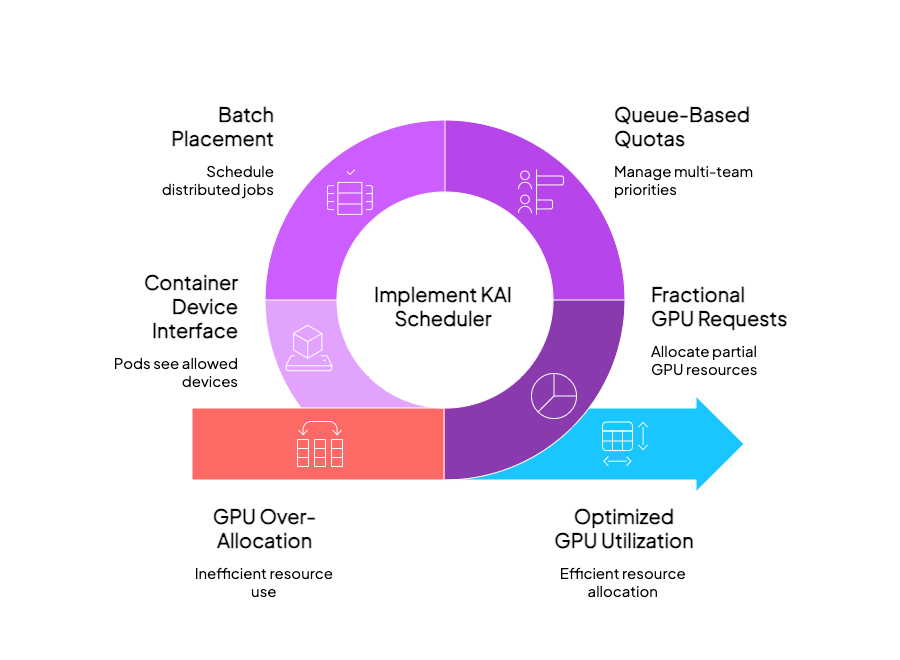
Kubernetes has a blind spot: once a container asks for one GPU, the scheduler hands over the entire card—even if your workload needs only a sliver of its memory or compute. NVIDIA’s KAI Scheduler (open‑sourced by Run:ai in March 2025) closes that gap by adding AI‑centric primitives on top of the default scheduler:
- Fractional GPU requests (
gpu-memoryorgpu-fractionannotations) - Queue‑based quotas & priorities for multi‑team governance
- Batch placement & gang scheduling for distributed jobs
- CDI (Container Device Interface) so pods see exactly the devices they're allowed to use
In short, KAI lets you squeeze more jobs into the same silicon without rewriting your ML code. That is a game‑changer for cost‑constrained teams running LLM serving, RL training loops, or mixed production + research clusters.
For ZenML users, this means you can run more concurrent pipelines on the same GPU infrastructure, significantly improving resource utilization and reducing costs. Fractional GPU allocation is particularly valuable when your pipelines have modest GPU memory requirements but still benefit from acceleration.
Installing KAI Scheduler on a GKE cluster
The official KAI Scheduler documentation gloss over two pain points:
- GPU drivers – you still need either Google's driver‑installer DaemonSet (COS) or the full NVIDIA GPU Operator.
- GPU sharing flags – GPU sharing and CDI are off by default in the Helm chart.
Below is a condensed, battle‑tested recipe adapted from Zhiming Shen’s excellent Exostellar blog post (as well as the working README in our kai-k8s-zenml repository).
Prerequisites
# Cloud tooling
brew install google-cloud-sdk terraform helm kubectl
# Make sure you are pointing at the right GCP project
export PROJECT_ID="my-gpu-project"
gcloud config set project $PROJECT_ID- A GKE cluster ≥ 1.32 with at least one GPU node pool (T4, L4, or H100—anything supported by the GPU Operator).
kubectlcontext pointing at the cluster.
Set up GPU drivers (GPU Operator flavour)
# Create a namespace + quota so the operator can deploy daemonsets safely
kubectl apply -f <https: raw.githubusercontent.com="" nvidia="" gpu-operator="" v25.3.0="" deployments="" gke="" namespace-with-quota.yaml="">
# Install the operator **without** the bundled driver (GKE already supplies the kernel‑matched driver)
helm repo add nvidia <https: helm.ngc.nvidia.com="" nvidia=""> && helm repo update
helm install gpu-operator nvidia/gpu-operator \\
--namespace gpu-operator --create-namespace \\
--version v25.3.0 \\
--set driver.enabled=false \\
--set cdi.enabled=true --set cdi.default=true
</https:></https:>Verify:
kubectl get pods -n gpu-operatorAll pods except nvidia‑cuda‑validator should be Running (the validator finishes as Completed).
Install KAI Scheduler with GPU sharing enabled
helm repo add nvidia-k8s <https: helm.ngc.nvidia.com="" nvidia="" k8s=""> && helm repo update
helm upgrade --install kai-scheduler nvidia-k8s/kai-scheduler \\
--namespace kai-scheduler --create-namespace \\
--set "global.registry=nvcr.io/nvidia/k8s" \\
--set "global.gpuSharing=true" \\
--set binder.additionalArgs[0]="--cdi-enabled=true"
</https:>Check:
kubectl get pods -n kai-schedulerYou should see binder, scheduler, and podgrouper Running.
Create resource queues
cat <<'EOF' | kubectl apply -f -
apiVersion: scheduling.run.ai/v2
kind: Queue
metadata:
name: default
spec:
resources:
cpu: {quota: -1, limit: -1, overQuotaWeight: 1}
gpu: {quota: -1, limit: -1, overQuotaWeight: 1}
memory:{quota: -1, limit: -1, overQuotaWeight: 1}
---
apiVersion: scheduling.run.ai/v2
kind: Queue
metadata:
name: test
spec:
parentQueue: default
resources:
cpu: {quota: -1, limit: -1, overQuotaWeight: 1}
gpu: {quota: -1, limit: -1, overQuotaWeight: 1}
memory:{quota: -1, limit: -1, overQuotaWeight: 1}
EOFSanity check fractional GPUs
At this point, you can deploy a test workload to verify that KAI Scheduler is correctly handling fractional GPU requests. For example, you could deploy a TinyLlama vLLM container and confirm you can pack two pods onto a single T4 by setting annotations.gpu-memory: "5120".
Heads‑up: KAI does not enforce isolation; vLLM will happily grab the entire card unless you pass —gpu-memory-utilization. When using frameworks like PyTorch, consider configuring PYTORCH_CUDA_ALLOC_CONF environment variables to achieve proper memory allocation limits.
Running a ZenML pipeline under KAI Scheduler
With the infrastructure ready, we can now configure ZenML to work with KAI Scheduler. The key is to tell ZenML’s Kubernetes orchestrator to:
- Use
kai-schedulerinstead of the default one. - Label the pod with the target queue.
- Add the right GPU‑sharing annotation (either fraction or MiB).
The run.py in our repository already does that; here’s the minimal snippet:
from kubernetes.client.models import V1Toleration
from zenml.integrations.kubernetes.flavors.kubernetes_orchestrator_flavor import (
KubernetesOrchestratorSettings,
)
kubernetes_settings = KubernetesOrchestratorSettings(
pod_settings={
"scheduler_name": "kai-scheduler",
"labels": {"runai/queue": "test"},
"annotations": {"gpu-fraction": "0.5"}, # or "gpu-memory": "5120"
"tolerations": [V1Toleration(key="nvidia.com/gpu", operator="Exists", effect="NoSchedule")],
"node_selector": {"cloud.google.com/gke-accelerator": "nvidia-tesla-t4"},
}
)Wrap your usual ZenML steps with @step(settings={"orchestrator": kubernetes_settings}) and kick off the pipeline:
python run.pyYou should see log lines like Found GPU via KAI Scheduler environment and two pods sharing the same physical GPU.
Real-world example: Running PyTorch on fractional GPUs
Our repository includes a complete PyTorch example that demonstrates:
- Automatic GPU detection with multiple discovery methods
- PyTorch model training on the Iris dataset using fractional GPUs
- Proper node tolerations and environment setup
Optional: one‑command stack registration via Terraform
If you prefer infrastructure-as-code, the terraform/ module in our repository will:
- Create (or re‑use) a GCS bucket and Artifact Registry
- Register a ZenML stack that embeds the KAI‑aware orchestrator
- Output helper commands such as
kubectl get-credentialsand queue creation
cd terraform
cp terraform.tfvars.example terraform.tfvars # edit as needed
terraform init && terraform applyThe Terraform configuration also creates appropriate service accounts with the necessary permissions, sets up proper IAM bindings, and configures the KAI Scheduler settings automatically.
Key takeaways and best practices
Working with KAI Scheduler and ZenML, we’ve identified several important considerations:
- Proper memory allocation: While KAI Scheduler enables fractional GPU allocation, it doesn't enforce memory limits. You should configure your ML frameworks appropriately:
- For PyTorch: Set
PYTORCH_CUDA_ALLOC_CONFenvironment variables - For TensorFlow: Use
tf.config.experimental.set_memory_growthandtf.config.set_logical_device_configuration - For vLLM: Pass the
-gpu-memory-utilizationparameter
- For PyTorch: Set
- Scheduler configuration: Always enable GPU sharing and CDI with the Helm chart options we've provided above.
- Queue management: For multi-team environments, create appropriate queue hierarchies with resource quotas.
- Pod requirements: Always set both the scheduler name and queue label for your pods.
For monitoring GPU utilization, consider using NVIDIA DCGM Exporter with Prometheus to track actual memory usage across pods.
Maximising GPU Efficiency with KAI and ZenML
The NVIDIA KAI Scheduler offers a powerful way to maximize GPU utilization in Kubernetes environments, particularly valuable for teams running ZenML pipelines with varying GPU requirements. By enabling fractional GPU allocation, you can run more concurrent workloads, improve resource efficiency, and reduce costs - all while using familiar ZenML patterns.
Our kai-k8s-zenml repository provides a complete working example that you can adapt to your own environment. The combination of ZenML’s orchestration capabilities with KAI Scheduler’s GPU management creates a powerful platform for ML workloads.
For teams running ZenML in production environments, this approach is particularly valuable. If you’re interested in exploring more advanced orchestration features, check out ZenML Pro, which offers enhanced monitoring, collaboration, and governance capabilities that complement the resource optimization provided by KAI Scheduler.
Through this integration, we’ve demonstrated how ZenML continues to embrace cutting-edge technologies that optimize machine learning workflows. Whether you’re running a small development cluster or managing large-scale production ML systems, the combination of ZenML and KAI Scheduler offers a compelling solution for maximizing GPU utilization and streamlining your machine learning operations.


