

On this page
The AI landscape shifted in early 2025 when every major provider launched their own version of “deep research” capabilities. OpenAI’s Deep Research feature can now compile comprehensive reports for ChatGPT Pro users. Google’s Gemini Deep Research promises to save hours of work as your personal research assistant, and Perplexity’s offering brings structured research to the masses. Even Claude has its own multi-agent research pipeline for synthesising findings into detailed analyses.
These tools represent a notable development in AI capabilities. They’re not just answering questions anymore, they’re conducting research. They break down complex queries, formulate search strategies, gather evidence from multiple sources, cross-reference findings, and synthesise everything into comprehensive reports that would take human researchers hours to produce.
What you’ll learn in this post: This post explains how to build production-ready agentic workflows that combine strong research capabilities with observability, reproducibility, and cost control for enterprise deployments. We provide a technical walkthrough of our ZenML Deep Research pipeline, showing how to create AI systems that are agentic in capability and workflow-driven in execution. This approach delivers smart automation with transparency and control.
We address the core challenge for AI engineering teams: building systems along a spectrum of autonomy while maintaining order and avoiding the unpredictability of fully autonomous agents.
The Autonomy Spectrum: From Workflows to Agents
When we talk about GenAI systems, we’re really talking about different points along a continuum of autonomy. At one end, you have highly structured workflows. Think of them as sophisticated pipelines where LLMs handle specific, well-defined tasks within a larger orchestrated process. At the other end, you have fully autonomous agents that can plan, reason, and execute complex tasks with minimal human oversight. (See the classic “Building Effective Agents” blogpost from Anthropic if you haven’t already read it!)
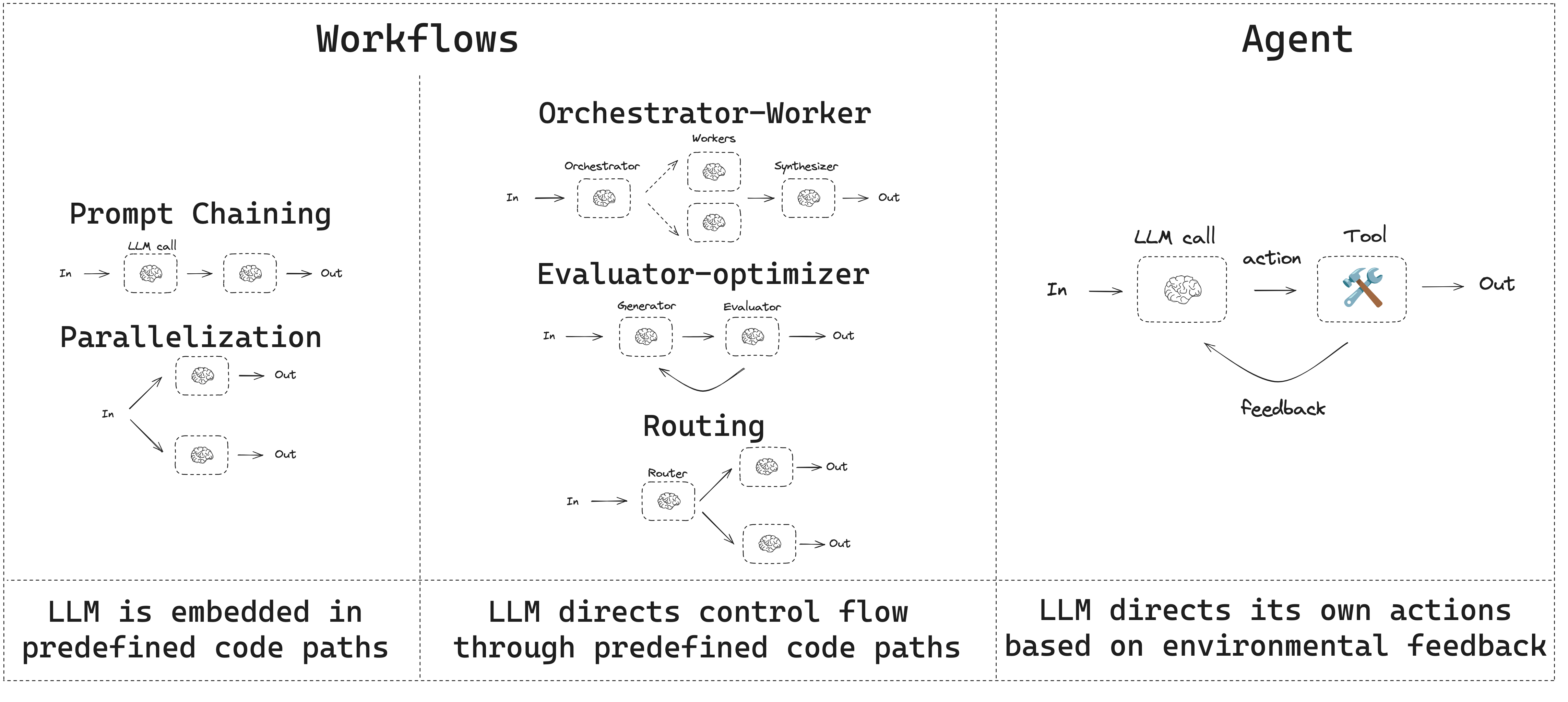
The more autonomous your system becomes, the more “agentic” it feels. Yet, there is a paradox: the more autonomy you add, the more entropy you introduce.
This isn’t just theoretical. It’s what we see in production deployments every day. Companies that rush toward full autonomy often find themselves dealing with unpredictable behaviour, compound errors, and systems that are impossible to debug when things go wrong. The most successful implementations tend to embrace what we might call “controlled autonomy”. These are systems that are intelligent and adaptive, but operate within clear boundaries and observable constraints.
The MLOps Evolution: Why Agentic Workflows Need Structure
At ZenML, we’ve been exploring this tension between autonomy and control, particularly in the context of complex research workflows. We wanted to understand the constraints around building an AI system that can conduct deep, thorough research while maintaining the observability, reproducibility, and reliability that production systems demand?
Our journey started when we came across the work of Aurimas Griciūnas, whose approach to structured research pipelines provided a solid foundation for experimentation. As we got more into the problem area, it became clear that most existing “agentic” solutions share some fundamental challenges:
Common Challenges in Agentic Workflows
- Lack of observability: You can't see why the system made specific decisions or where it might be going wrong
- Limited steerability: Once the agent starts working, you have minimal control over its direction or depth
- Poor reproducibility: Run the same query twice, get different results and research paths
- Cost unpredictability: No clear understanding of computational or API costs until after completion
- Debugging nightmares: When something goes wrong, tracing the failure through autonomous decision chains is nearly impossible
These aren’t just technical annoyances. They’re fundamental barriers to production deployment. Enterprise use cases require predictability, auditability, and cost control. They need systems that are reliable before they’re autonomous.
Our Approach: Smart Workflows, Not Agents with Constraints
Rather than building another autonomous research agent, we decided to create something different: a smart workflow that maintains human agency while amplifying research capabilities.
Our ZenML Deep Research pipeline is a system that conducts research through a structured, observable process. It breaks down complex queries into manageable sub-questions, searches multiple sources in parallel, synthesises findings across different perspectives, and even employs Anthropic’s Model Context Protocol (MCP) for enhanced tool usage. All of this happens while maintaining complete transparency about costs, decisions, and intermediate results.
The key insight? You don’t need full autonomy to achieve powerful research capabilities. You need thoughtful orchestration, clear boundaries, and systems designed for observability from the ground up.
What we built is a production-ready research pipeline that generates comprehensive, cited reports while giving users complete visibility into the research process, full control over cost and depth parameters, and the ability to steer the research direction at key decision points. It’s agentic in capability but workflow-driven in execution.
In the sections that follow, we’ll dive into the technical architecture, explore how we achieved full observability through integrated tooling like Langfuse as well as in-built ZenML features, and share the key lessons we learned about building reliable agentic workflows that actually work in production environments.
Deep Research Pipeline Code Walkthrough
The Deep Research pipeline integrates several core components into a unified workflow. Below, we outline each main part of the codebase and explain how they interact to deliver structured, reliable research automation.
Entry Point and Configuration (run.py)
The Deep Research pipeline starts from a run.py CLI entry point. This script uses ZenML to configure and run the pipeline. You can select preset modes (rapid, balanced, deep) to control the number of sub-questions and searches. CLI flags toggle features like caching, debug logging, or the web search provider (--search-provider accepts tavily, exa, or both). After parsing options, run.py builds the ZenML pipeline (parallelized_deep_research_pipeline) with the chosen configuration and parameters, then executes it with arguments such as the research query, maximum sub-questions, human approval requirement, and search backend.
run.py connects user input to the pipeline. It reads a YAML config for defaults, applies CLI overrides, configures logging, and invokes the ZenML pipeline to start the research process.
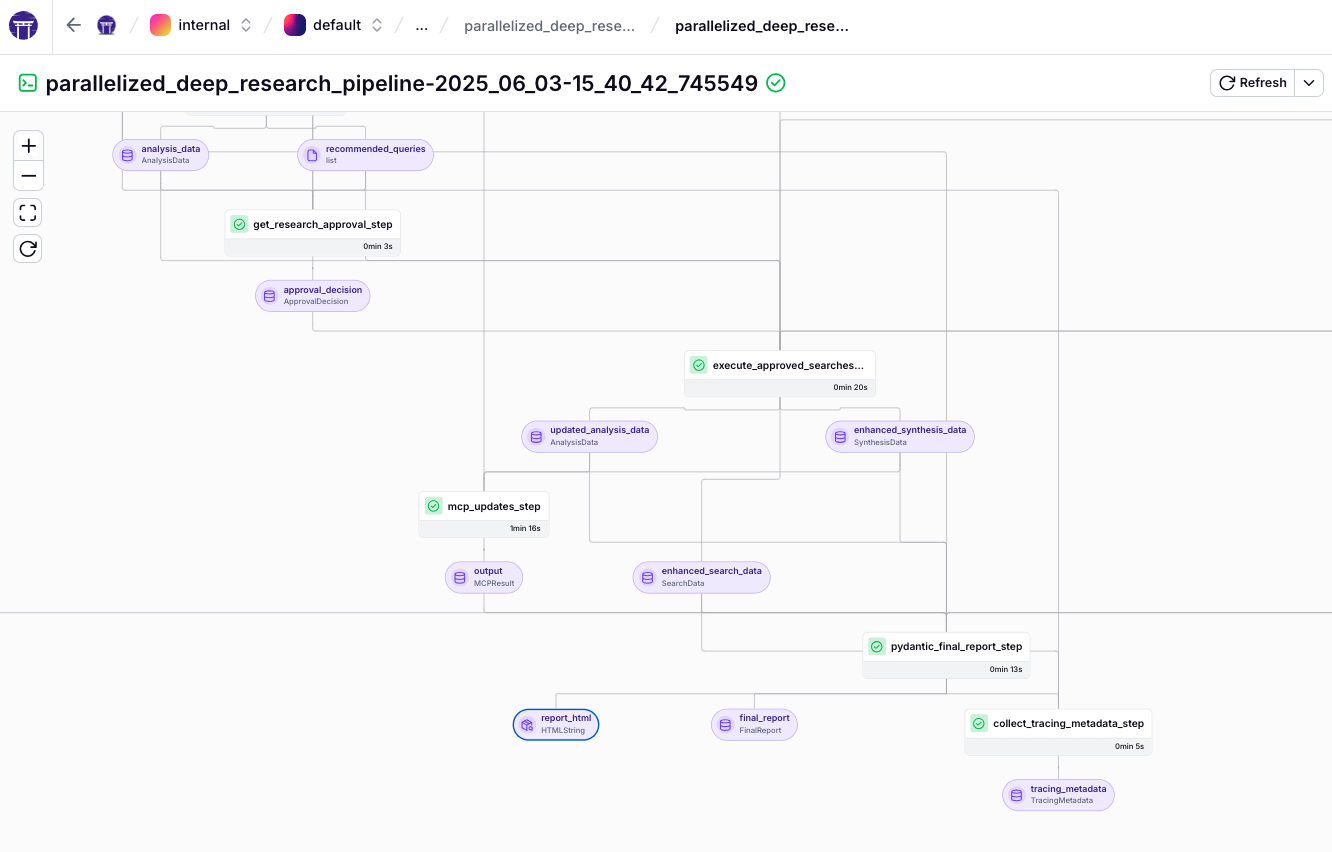
Parallel Research Pipeline Structure and Flow
The Deep Research pipeline uses ZenML’s pipeline and step decorators. It follows a fan-out/fan-in architecture to parallelize sub-question processing. The main stages are:
- Initialize Prompts: Loads all prompt templates (for search queries, synthesis, viewpoint analysis, etc.) and returns them. Each prompt is tracked as a versioned artifact for reproducibility.
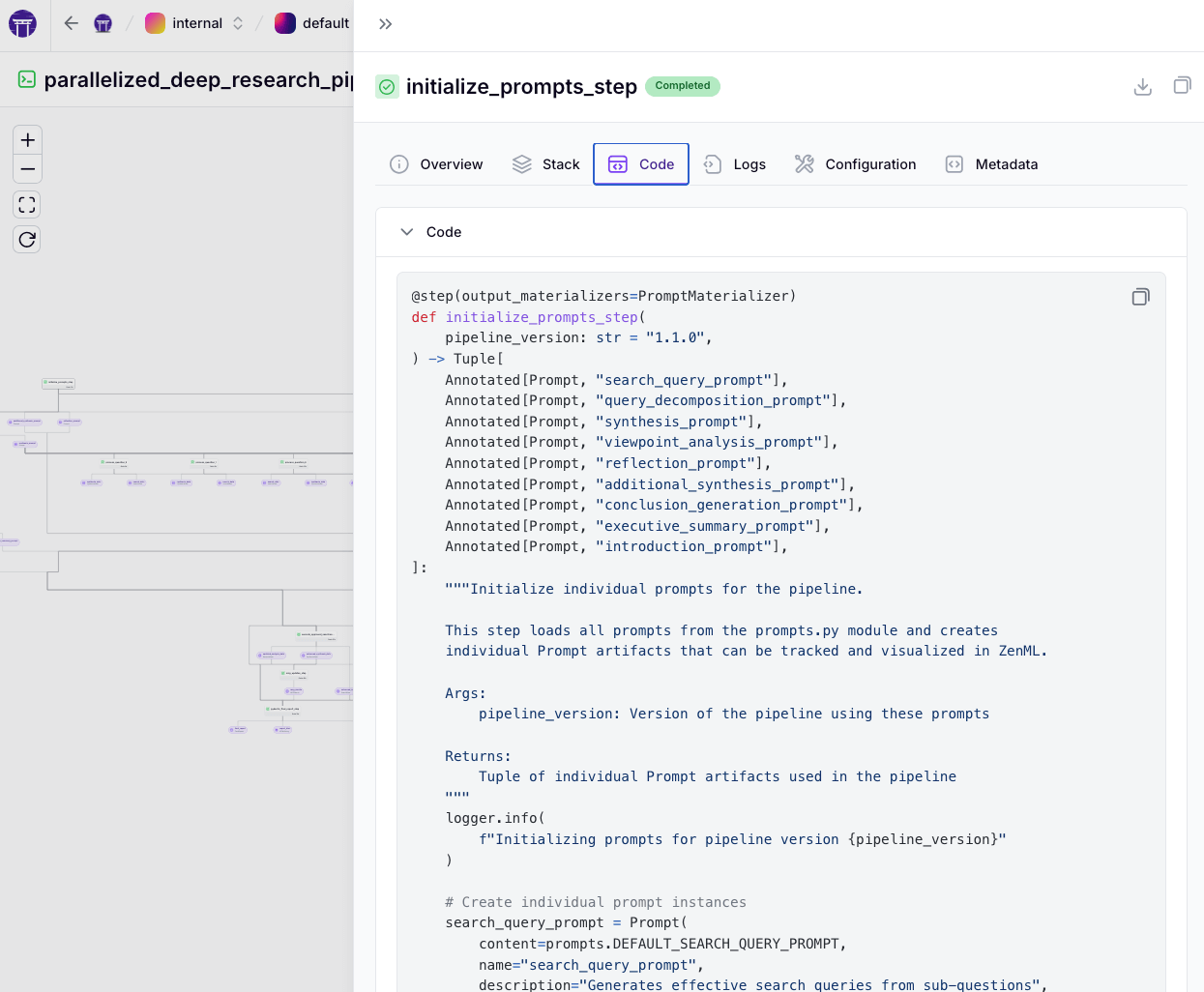
- Query Decomposition: An LLM analyzes the main research query to produce focused sub-questions. The
initial_query_decomposition_stepprompts the model to break down the topic, limited by a maximum number of sub-questions. The result is stored in aQueryContextobject with the main query and sub-questions. If the LLM fails, the step falls back to generic sub-questions. This step outlines the research into manageable pieces.
- Parallel Information Gathering: The pipeline spawns parallel steps for each sub-question. In a loop, it calls
process_sub_question_stepfor each sub-question index, all referencing the sameQueryContext. Each parallel step generates a search query (via LLM prompt), performs a web search, and synthesizes the information with another LLM call. These steps fan out after decomposition. Up to N sub-questions are processed in parallel (N is configurable, e.g., 5 for rapid mode, 15 for deep mode). Each sub-question produces SearchData (raw search results and cost info) and SynthesisData (LLM-generated answer/summary). - Merge Results: After the parallel search and synthesis steps, a merge step collates their outputs. The custom
merge_sub_question_results_stepwaits for allprocess_sub_question_*steps to finish and aggregates their results. This "fan-in" produces combinedSearchDataandSynthesisData, collecting all sub-answers and sources. - Cross-Viewpoint Analysis: The pipeline analyzes all synthesized sub-answers. The
cross_viewpoint_analysis_steptakes the merged synthesis output and uses an LLM to compare and analyze differences or commonalities from various perspectives. The prompt can ask for a cross-perspective critique or to identify gaps. The result is anAnalysisDataobject with insights such as agreements or contradictions between sub-answers. - Reflection Generation: The pipeline refines the research with the
generate_reflection_step. The LLM reflects on the current state, identifying gaps or areas needing more research. This step produces an updatedAnalysisData(including the AI's reflection) and a set of recommended follow-up queries for deeper research.
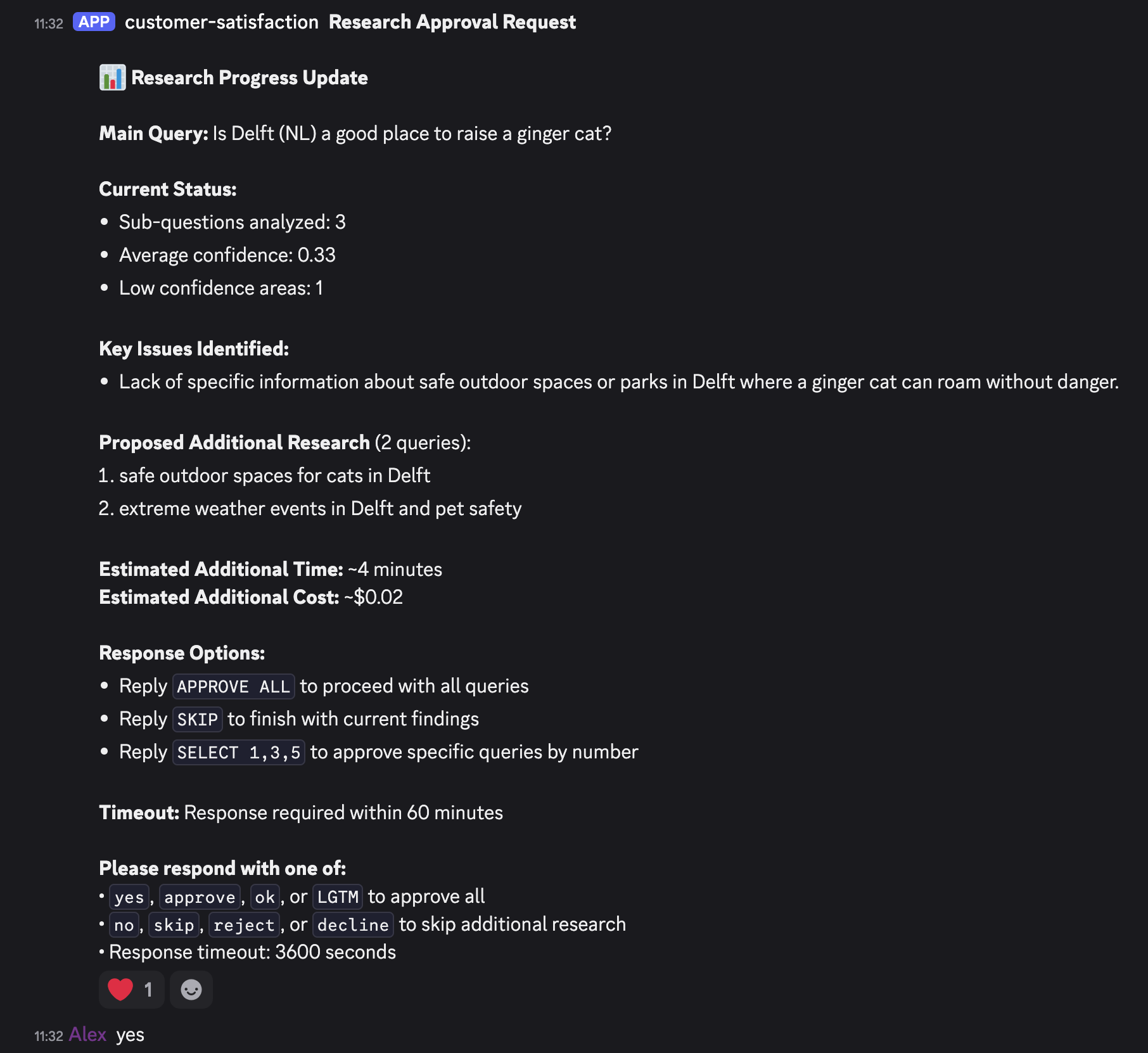
- Human Approval (Optional): If human-in-the-loop approval is required (
-require-approvalflag), the pipeline pauses for confirmation on recommended extra searches. Theget_research_approval_stepcan auto-approve or integrate with ZenML's alerters (e.g., Discord/Slack) to let a person decide which additional queries to pursue. This step outputs an approval decision indicating which queries, if any, are approved to execute.
- Execute Approved Searches: For approved follow-up queries, the
execute_approved_searches_stepperforms those searches and incorporates the results. This is a second round of information gathering, focused on identified gaps. It returns enhancedSearchData,SynthesisData, andAnalysisData, merging new information with previous results. If no additional searches are needed, this step passes through the original data. - MCP-Powered Agent Search: The pipeline includes an advanced research step using Anthropic's Model Context Protocol (MCP). The
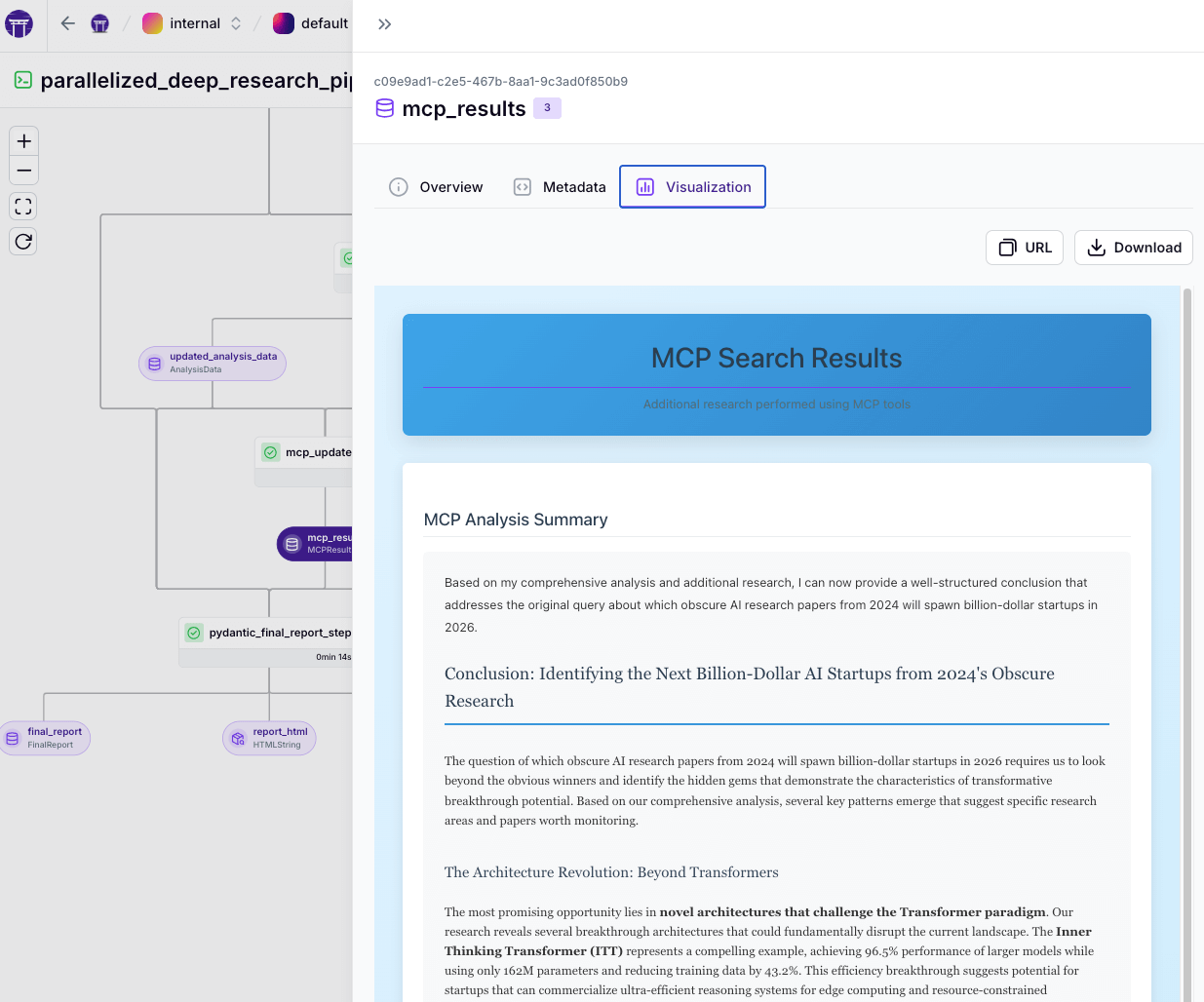
mcp_updates_stepinvokes an Anthropic Claude model with instructions to perform tool-assisted searches via the Exa API. Claude receives the current context (main query, synthesized answers, analysis) and can access Exa's research tools (e.g., research paper search, company data lookup, Wikipedia search) through the MCP interface. The model can iteratively call these tools to fetch targeted information and incorporate it into its final answer. The pipeline limits allowed tools (passed in theallowed_toolslist). The output is an MCPResult object with new findings, including both raw tool outputs and the model's final response. This step uses the Anthropic SDK directly, showing how the pipeline can integrate specialized LLM calls outside the standardlitellmwrapper. (We do this since this is a very new feature just added to the Anthropic API and it isn't as easily available throughlitellmyet.)
- Final Report Generation: The pipeline compiles a comprehensive final report. The
pydantic_final_report_stepuses a Pydantic model (FinalReport) to organize report sections (introduction, per-sub-question sections, conclusion, etc.). It feeds the accumulated data (query context, all synthesis/analysis info, and any MCP findings) into prompts or templates. For example, it might use a prompt to generate the introduction and another for the conclusion, calling the LLM for each section. These pieces are assembled into a structured HTML report with citations or source attributions (fromSearchData's stored URLs) and cross-references between sections. This step returns the completeFinalReportartifact, typically as an HTML string or object. - Collect Tracing Metadata: The final step,
collect_tracing_metadata_step, gathers observability data about the run. It collects metrics from the pipeline, focusing on LLM usage. This step queries the Langfuse observability backend (if enabled) to retrieve a trace of all LLM calls made during the run. It computes totals such as input/output tokens used, total LLM API cost, latency per call, and organizes these into aTracingMetadataobject. It also appends recorded search costs from SearchData so the final cost accounting includes both LLM and search API costs. This metadata supports monitoring and dashboard display. (See below for what this looks like inside the ZenML dashboard.)
The pipeline transforms an open-ended query into a thorough, multi-part research report. ZenML’s pipeline abstraction makes each step’s inputs and outputs explicit, and intermediate data (such as sub-questions and sub-answers) is stored as artifacts. The pipeline is parallelized at its core, reducing runtime by performing searches and analyses concurrently. The architecture balances automation with opportunities for human feedback, supporting scalable and controllable research.
LLM Observability with Langfuse
The pipeline provides full observability for all LLM interactions using Langfuse. Langfuse tracks prompts, responses, token counts, and (estimated) costs, supporting debugging and optimization of AI workflows. Integration is handled through the litellm library’s callback system. Setting litellm.callbacks = ["langfuse"] ensures every LLM call through litellm is logged to a Langfuse server. Each call includes metadata such as a trace name (the ZenML pipeline run ID), grouping all calls from a run under a single trace. Steps in the pipeline tag their LLM calls (for example, “structured_llm_output” for JSON output generation), allowing Langfuse to aggregate statistics by function.
At the end of a run, the collect_tracing_metadata_step retrieves aggregated metrics from Langfuse’s API using utility functions like get_trace_stats and get_prompt_type_statistics. This provides insights such as total tokens used (input and output), total LLM cost (in USD), cost breakdown by model, and breakdown by prompt type or pipeline step. For example, “information_synthesis” calls might consume 70% of the tokens, or query decomposition might be the most expensive step. The pipeline logs per-step token counts and costs, so you can see, for instance, that cross-viewpoint analysis used 500 tokens and cost $0.02, while final report generation used 1500 tokens.
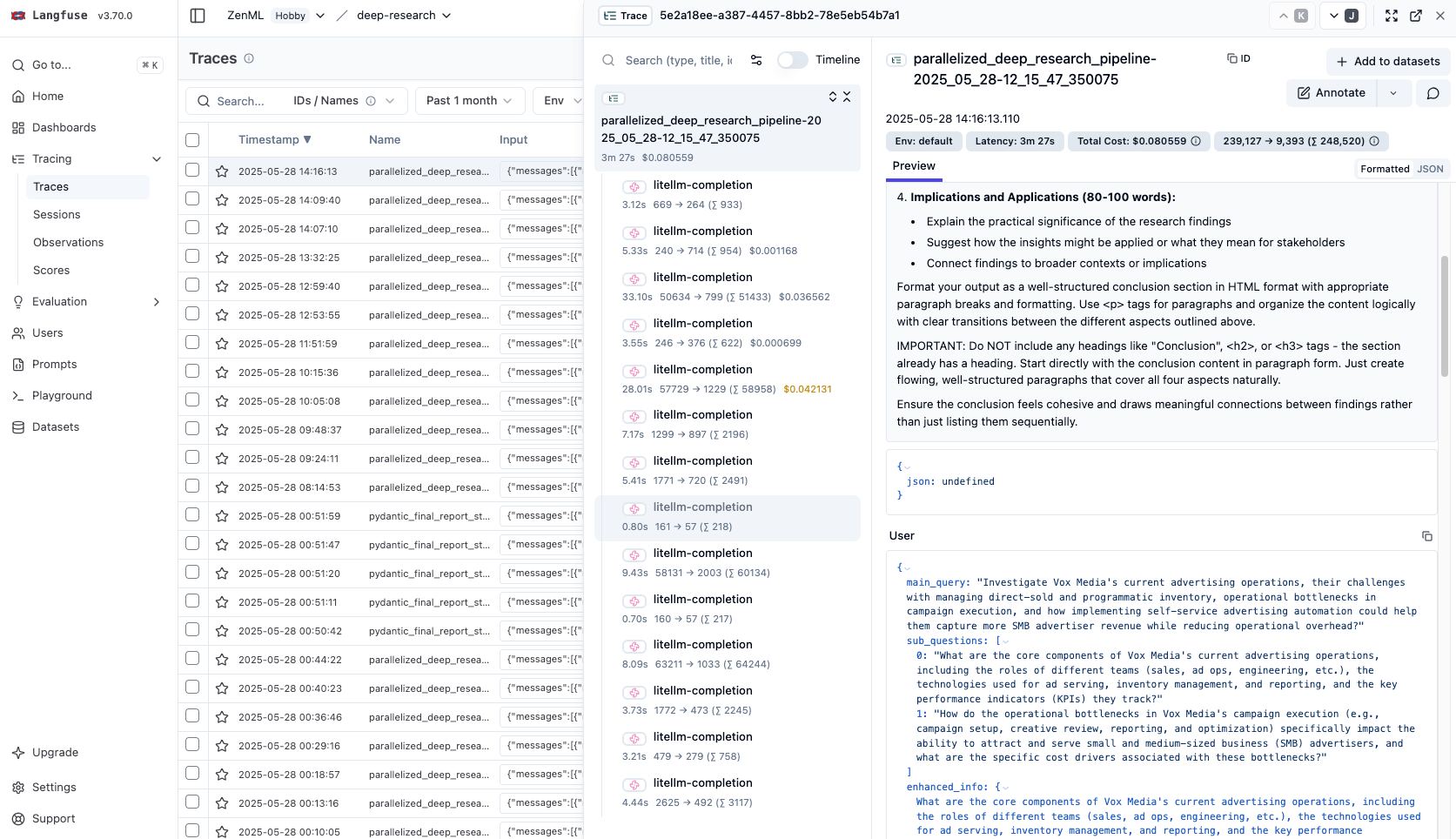
Langfuse provides a dashboard where each pipeline run appears as an interactive trace. You can inspect prompts and model responses, measure latencies, and verify the chain-of-thought. The Deep Research pipeline’s integration with Langfuse gives full visibility into the LLM reasoning process. All LLM usage is tracked and analyzed. This supports debugging (by inspecting the exact prompt used for any step) and cost management (by tracking model usage and costs). Each run yields both a research report and a detailed set of telemetry data about how the report was generated.
LiteLLM: A Lightweight LLM Proxy
The project uses LiteLLM, an OpenAI-compatible LLM proxy library, to interface with language models. LiteLLM provides a unified API (litellm.completion() etc.) that routes requests to different model providers with minimal code changes. In the Deep Research pipeline, all LLM calls except the Anthropic MCP step use this layer. Model names with prefixes select the provider: for example, “openrouter/google/gemini-2.0-flash-lite-001” uses the OpenRouter gateway for Google’s Gemini model, while “sambanova/DeepSeek-R1-Distill-Llama-70B” routes to a SambaNova-hosted model. This design allows the pipeline to switch between LLM backends (OpenAI, Anthropic, Meta, etc.) by changing configuration, without modifying the code that calls the LLM.
LiteLLM acts as an abstraction layer and HTTP client for LLM APIs. It is compatible with OpenAI’s API format, formats prompts, and handles chat completions. LiteLLM integrates with Langfuse out of the box, simplifying observability. Pipeline utility functions like run_llm_completion() and get_structured_llm_output() wrap litellm calls with project-specific logic (ensuring a provider prefix, adding metadata tags, cleaning outputs, etc.). When generating sub-questions or synthesizing information, the code calls litellm.completion() to get an assistant message, then extracts and cleans the content. Because LiteLLM provides a consistent interface regardless of the underlying model, these functions work with any supported model as long as the correct prefix is used.
LiteLLM enables the Deep Research pipeline to swap between LLM providers seamlessly while maintaining a consistent code path. It reduces log noise by setting less verbose logging levels for underlying HTTP libraries. This approach fits ZenML’s modularity philosophy: the research agent can use an OpenAI model or an open-source model without redesigning the pipeline.
MCP Integration: Anthropic’s Model Control Plane with Exa
The project integrates MCP (Model Control Plane) via Anthropic and Exa. Anthropic’s Model Context Protocol allows an AI model to interface with external tools or APIs during generation. In the Deep Research pipeline, MCP gives the Claude model the ability to perform high-level searches through the Exa API. Exa is a search platform with specialized endpoints, including semantic search. By configuring Claude with an MCP server pointing to Exa, the pipeline enables agentic behavior: Claude can call Exa’s search functions as it formulates its answer.
In mcp_updates_step, the code constructs a prompt with the user’s query, sub-questions and their synthesized answers, and any reflection metadata. It calls the Anthropic client’s beta.messages.create() with model="claude-sonnet-4-20250514" and an mcp_servers parameter for the Exa MCP endpoint. The request payload lists allowed tools (e.g., “research_paper_search”, “github_search”) to constrain the AI’s actions. Claude can dynamically issue tool calls to Exa (for example, performing a papers search to answer the query). The response from Anthropic includes both tool outputs and the model’s final answer. The code extracts any mcp_tool_result content for raw search results and the last text content for Claude’s completed answer.
This MCP-driven step enhances the pipeline’s research with an AI agent capable of open-ended exploration. Earlier steps use static web queries (Tavily/Exa with fixed prompts), while the MCP step lets the AI decide what to search for next. For example, on a “quantum computing advances” topic, Claude might use the research_paper_search tool to find recent academic publications and summarize them—something the initial web search might miss. The pipeline provides all current knowledge to Claude and asks it to dig deeper via tools if needed. The resulting MCPResult is passed into final report generation, so new insights from Claude are included in the report.
This integration demonstrates how the pipeline can incorporate new features. Anthropic’s MCP is leveraged as an optional step that augments research without affecting earlier logic. MCP integration turns the pipeline into a human-AI hybrid researcher: after conventional searches, it asks an AI agent (Claude + tools) for a second opinion and extra findings, increasing research thoroughness.
Web Search via Tavily and Exa
The pipeline uses two external search services to gather factual information: Tavily and Exa.
- Tavily is a web search API that provides advanced search capabilities. It returns result URLs, snippets, and full raw content of pages, which is essential for LLM input. Tavily is the default search provider. The code instantiates a
TavilyClientwith an API key and performs an "advanced" search for each query, requesting raw page content for up to N results (default 3, or as set by-num-results). If Tavily returns emptyraw_content, the pipeline retries or uses a different field (contentorinclude_answer=True) to get text. Tavily enables the pipeline to retrieve web page snippets or full articles for LLM synthesis. - Exa is a search API with neural (vector-based semantic search) and keyword-based search modes. Exa is used as an alternative to Tavily for initial searches and as the backend for MCP tool usage. When used directly (via
-search-provider exaorboth), the pipeline callsexa_search()using theExaPython client. Exa'ssearch_and_contentsmethod returns results with text content and optional highlights. Exa provides a cost estimate for each search query. The pipeline logs this cost and accumulates it in the SearchData. Exa can be tuned via asearch_modeparameter: "neural" for semantic search, "keyword" for traditional search, or "auto" to let it decide. The default is "auto".
The pipeline’s search strategy is configurable: use only Tavily, only Exa, or both. If both is selected, the unified_search function calls Tavily and Exa and merges the results by interleaving them, diversifying the information gathered. A compare_results option (in code) keeps results separate for analysis. By default in deep mode, the pipeline uses Tavily, but users can switch to Exa for semantic search.
In each process_sub_question_step, after generating the search query, the code calls search_and_extract_results(), which uses unified search with the specified provider and number of results. Raw results from Tavily/Exa are converted into a standard SearchResult Pydantic model (fields: url, title, content, snippet) so subsequent steps are agnostic to the search engine. The search_data.search_costs field may have multiple entries (e.g., “exa” and “tavily” costs if both were used).
Using Tavily and Exa together provides both breadth and depth. Tavily’s advanced search covers the topic broadly, while Exa’s neural search surfaces less obvious connections. Integrating both ensures the research agent retrieves a rich context before the LLM synthesizes answers. The LLM synthesizes and explains, while Tavily and Exa provide factual data.
All retrieved content is passed into LLM prompts for synthesis. For each sub-question, the prompt template might be: “Given the following sources [source texts] answer the sub-question…” The result is a SynthesizedInfo object with the model’s answer, key sources used, confidence level, and any identified information gaps. This structure clarifies which source contributed to each answer.
Custom Visualizations of Results and Artifacts
The project implements custom visualizations for different artifact types to make outputs and intermediate results easy to interpret. ZenML allows each artifact to have an associated visualization (HTML file or image). The Deep Research pipeline uses this to present research progress clearly:
- Query Context (Sub-questions) Visualization: The output of query decomposition is a
QueryContextobject with the main query and sub-questions. A customQueryContextMaterializergenerates an interactive mind-map style HTML view. The main query is at the center, sub-questions branch out, each numbered and styled, with a stats panel (number of sub-questions, query word count, etc.). If no sub-questions were generated, it displays a note.

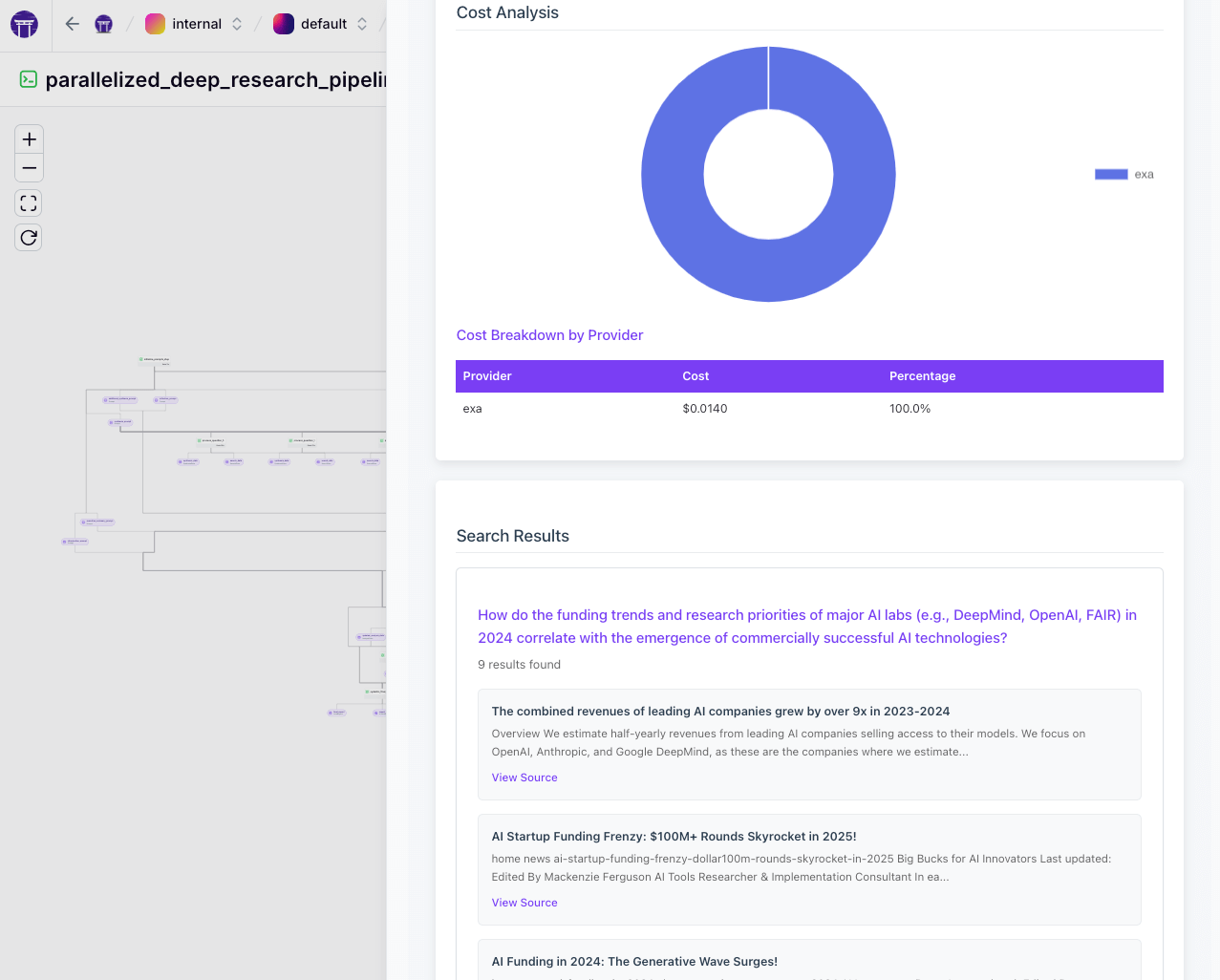
- Search Results Visualization: After parallel search steps, the merged SearchData artifact is visualized by
SearchDataMaterializer. This produces an HTML report with a cost breakdown chart and a list of results per sub-question. Chart.js renders a doughnut chart of search cost by provider (e.g., $0.05 on Exa vs $0 on Tavily). Each sub-question lists top result titles, content snippets, and direct links. If there are more than 5 results, it indicates "[...and X more results]" for brevity. This serves as a mini "search report" showing what was found and where.
- Synthesis & Analysis Visualization: The SynthesisData (answers for each sub-question) is visualized by
SynthesisDataMaterializeras an HTML page. Each answer appears in a card with the model's confidence level and key source references. Information gaps noted by the model are highlighted with a warning box. If the model suggested improvements, these are listed. If the execute_approved_searches step provided an enhanced answer, both original and enhanced answers are shown side by side, with an "Enhanced" badge. At the top, stats are summarized (number of answers, enhanced answers, average sources per answer, count of high-confidence answers). This shows answer quality and highlights weak spots.
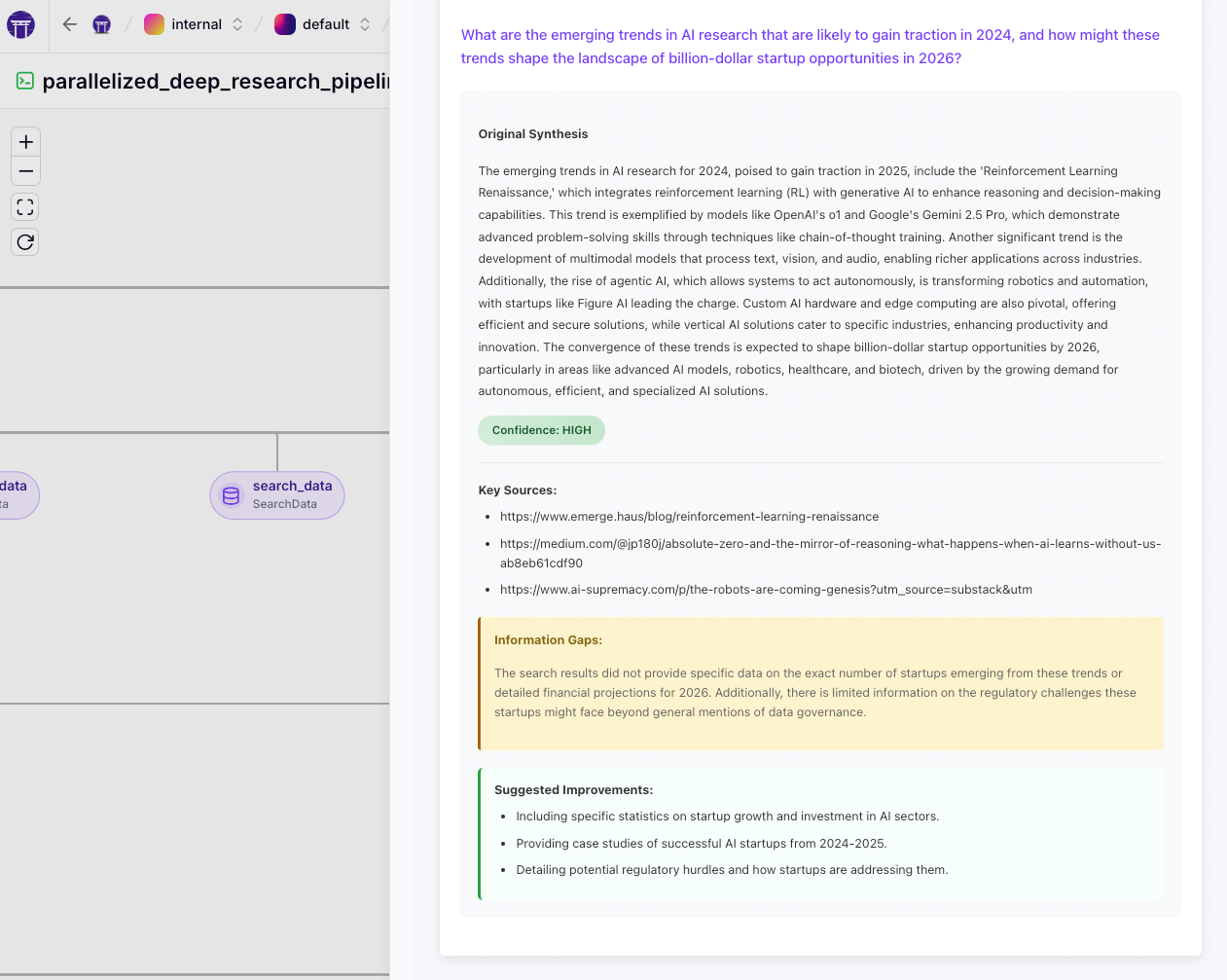
- Final Report: The final output is an HTML research report, saved by a
FinalReportMaterializer. The report uses a consistent stylesheet and includes sections for introduction, executive summary, each sub-question with its answer, cross-analysis commentary, conclusion, and possibly an appendix of sources. The materializer passes through the HTML content. In the ZenML dashboard or artifact store, this report can be opened directly.
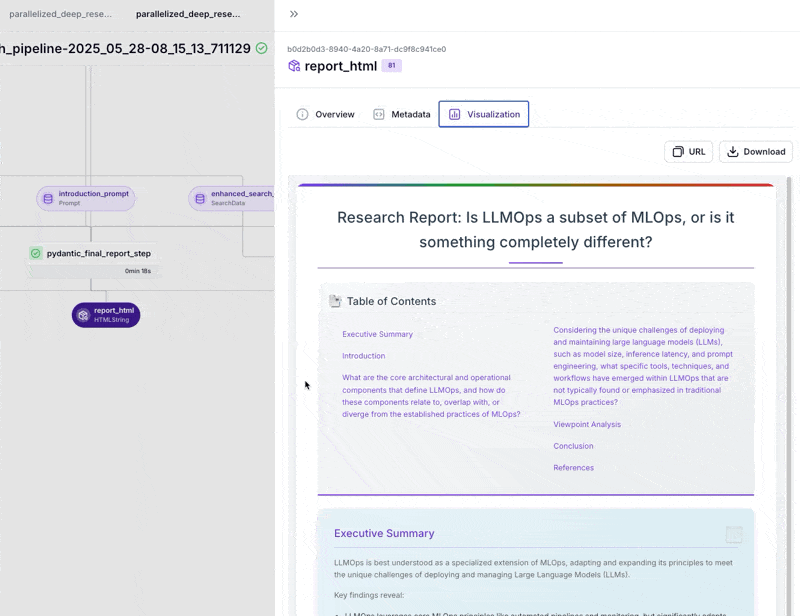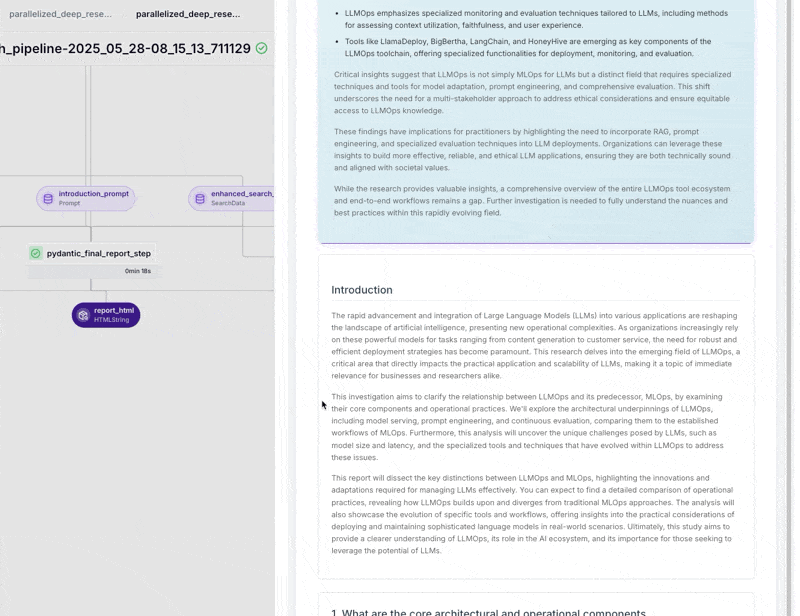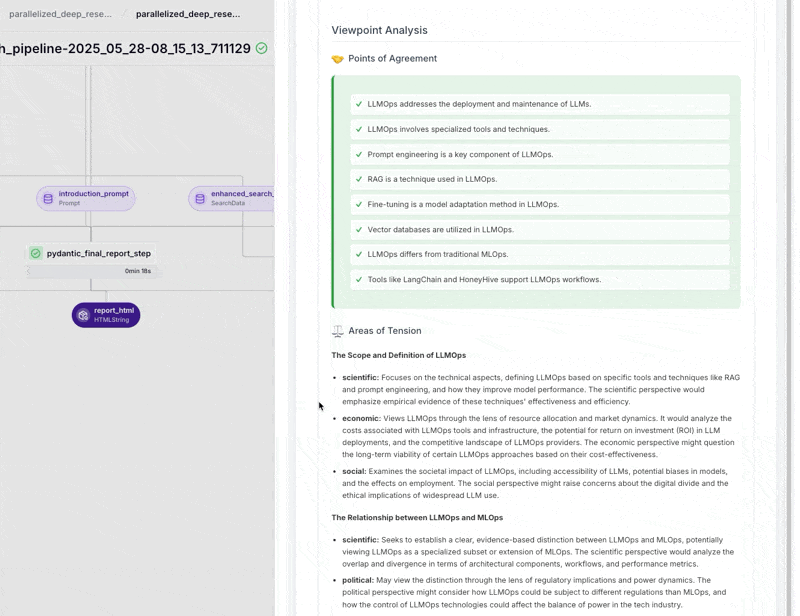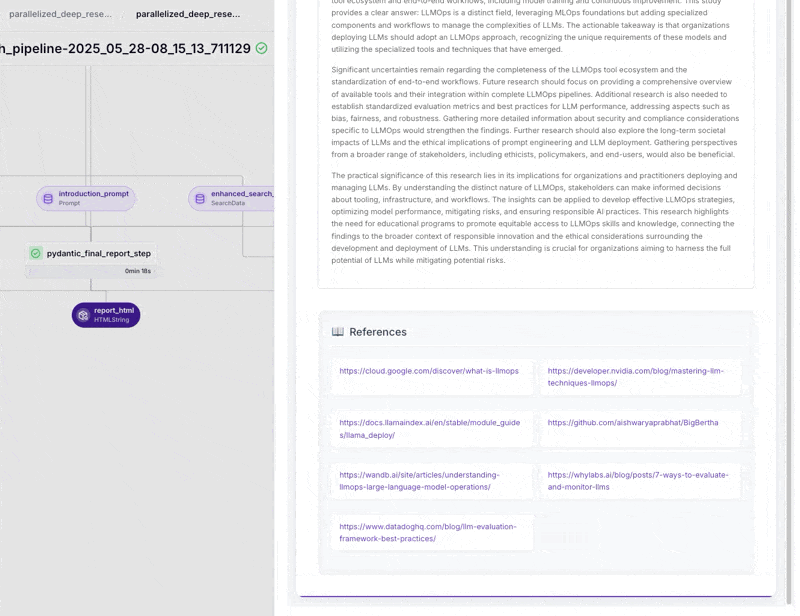
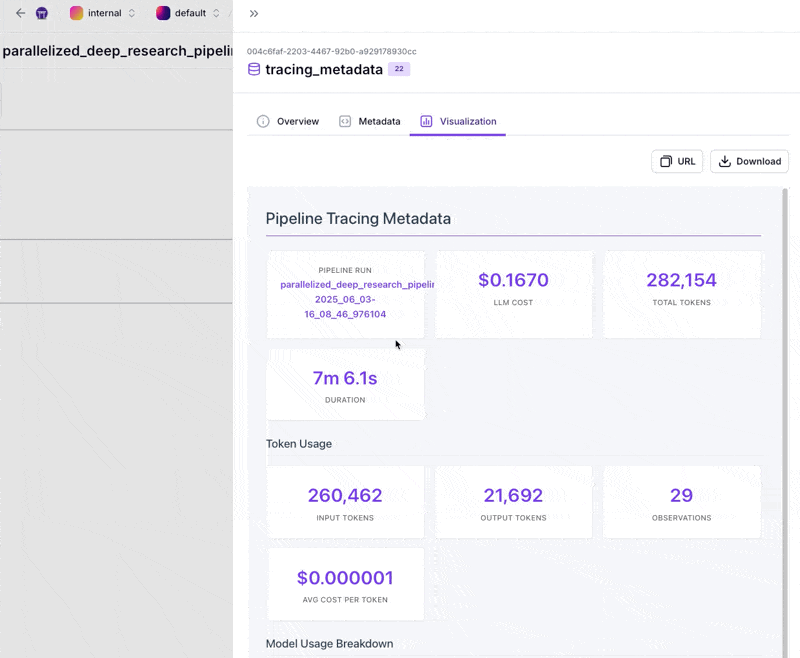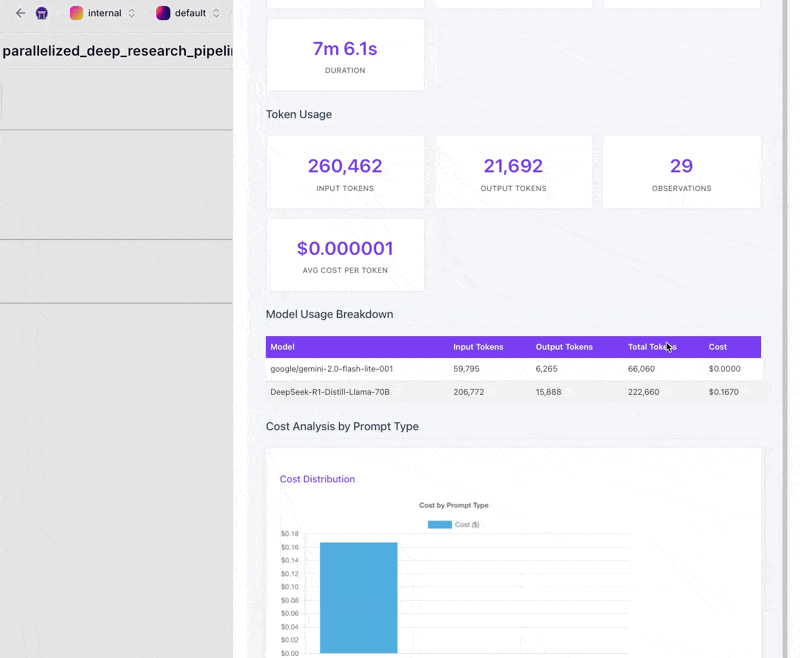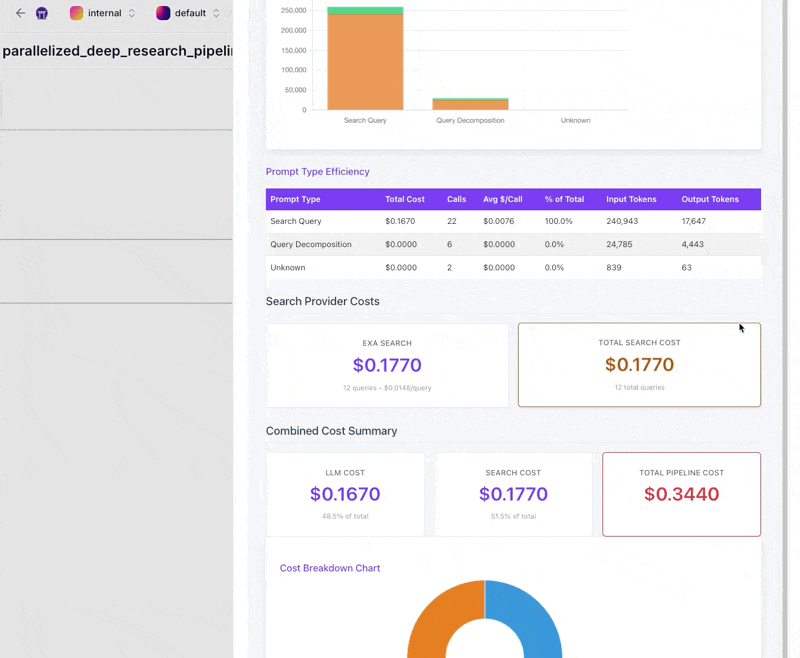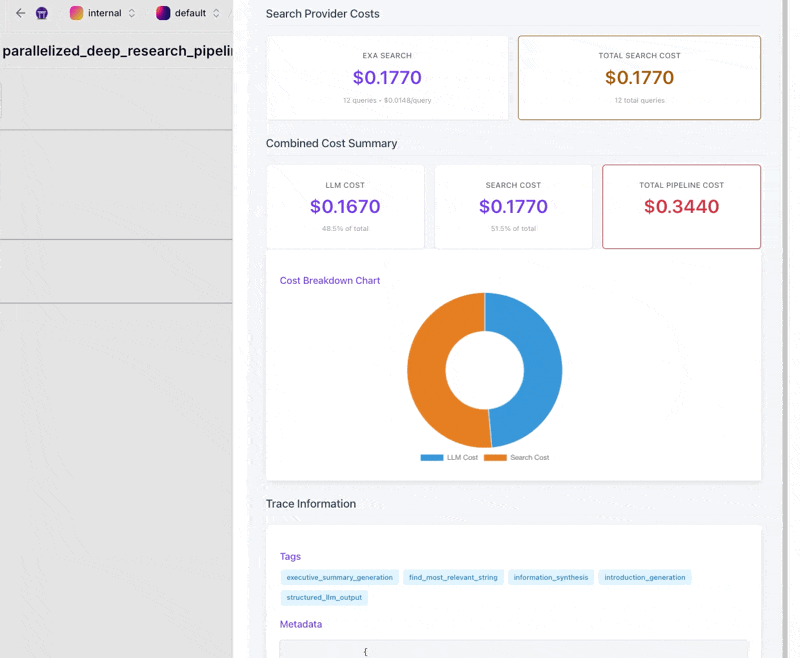
- Tracing Metadata Visualization: The telemetry from the tracing step is visualized by
TracingMetadataMaterializeras a cost and usage report. The visualization includes key metrics (total LLM cost, total tokens, pipeline duration) and detailed breakdowns. It tabulates each model's token and dollar contribution, shows prompt-level metrics (bar chart for cost per prompt type, stacked bar for token usage, table with total cost, number of calls, average cost per call, percent of total cost). If search costs are present, it adds them, including a stat for total search cost and a pie slice comparing LLM vs search spend. This helps identify performance bottlenecks or expensive steps.
All custom visualizations are rendered as HTML and saved as pipeline artifacts. In ZenML’s UI (or in a Jupyter environment), you can click on each artifact to see these outputs. These visuals turn the pipeline run into an interactive report of both results and process. You can inspect how the query was broken down, what was searched, what was answered, and the costs involved. This level of introspection clarifies how each answer was produced.
Conclusion and Future Work
ZenML’s Deep Research pipeline is an example of orchestrating a complex agentic workflow with modular steps. The pipeline’s architecture – from query decomposition to parallel searches, iterative refinement, an agentic MCP-powered search, and final report generation – showcases how to combine LLM reasoning with search engines and human oversight to produce credible, comprehensive results. Each component (Langfuse observability, LiteLLM integration for model flexibility, Exa and Tavily for data gathering, Anthropic MCP for tool use, and custom visualizations for transparency) plays a role in making the system production-ready and extensible.
In summary, the project is more than just a single script calling an API; it’s a full pipeline that structures an LLM-driven research process into clear stages with measurable outputs. The use of ZenML provides versioning, caching, and deployment options (one could run this pipeline on cloud infrastructure, scale out the parallel steps, etc.), making it suitable for real-world applications. Whether used as an AI research assistant or a template for similar LLM workflows, the workflow’s design demonstrates an effective orchestration of LLMs, search tools, and human feedback to achieve deep, explainable research results. The end result is a well-formatted HTML report answering the original query, and a set of logs and visual insights explaining how that answer was obtained – truly bridging the gap between MLOps and practical AI-driven research.
What makes ZenML particularly valuable here isn’t just the orchestration—it’s the systematic approach to complexity management. The artifact versioning means every intermediate result becomes inspectable and reproducible. The step-based architecture transforms what could be an opaque autonomous agent into a transparent, debuggable workflow. When something goes wrong, you’re not debugging a black box; you’re examining specific steps with concrete inputs and outputs. This observability extends from development through production, giving teams the confidence to deploy agentic workflows in enterprise environments where reliability matters more than novelty.
The real development work, however, lies ahead in vertical customization. Our current implementation works as a general-purpose research pipeline, but real enterprise production value emerges when you adapt it for specific domains. A financial research agent needs different prompts, specialized data sources like SEC filings, and domain-specific quality metrics. A medical research pipeline requires PubMed MCP or RAG integration, clinical trial databases, and evaluation frameworks that understand medical evidence hierarchies. Most critically, each domain needs custom evaluation approaches that reflect what constitutes good research in that specific context—financial materiality assessments differ fundamentally from clinical evidence evaluation, which differs from legal precedent analysis. The generic foundation becomes the starting point for these specialized implementations, but the evaluation layer is where domain expertise truly matters.
Looking forward, the most interesting applications will combine the controlled autonomy we’ve demonstrated with deeper domain expertise. The pipeline’s human-in-the-loop approval points could evolve into sophisticated quality gates where domain experts can steer research direction based on emerging findings. The MCP integration suggests a future where multiple specialized agents collaborate within structured workflows—not the chaotic multi-agent systems that often fail in production, but orchestrated intelligence where each component has clear responsibilities and observable behavior. This approach offers a path toward truly useful AI research assistants that enhance human expertise rather than attempting to replace it entirely.
Curious about implementing these concepts in your own projects? Check out the complete ZenML Deep Research pipeline on GitHub—it’s a great starting point for understanding how to build observable, production-ready agentic systems.


