

I’m back in the new cohort of Hamel & Shreya’s LLM Evals course which started up again this evening. As part of how I’m revisiting the material this time round, I’m going to publish a series of blogs which will draw ties between the material in the course textbook and the LLMOps Database. If you’re not already familiar with it, ZenML’s LLMOps Database is a resource that I maintain as part of my day job working to make it easier for engineers to put models and LLM-based systems into production. I’ve gathered together over 800 entries, drawing from company blogs to panel discussions on YouTube and more. Each entry comes with a short and long summary.
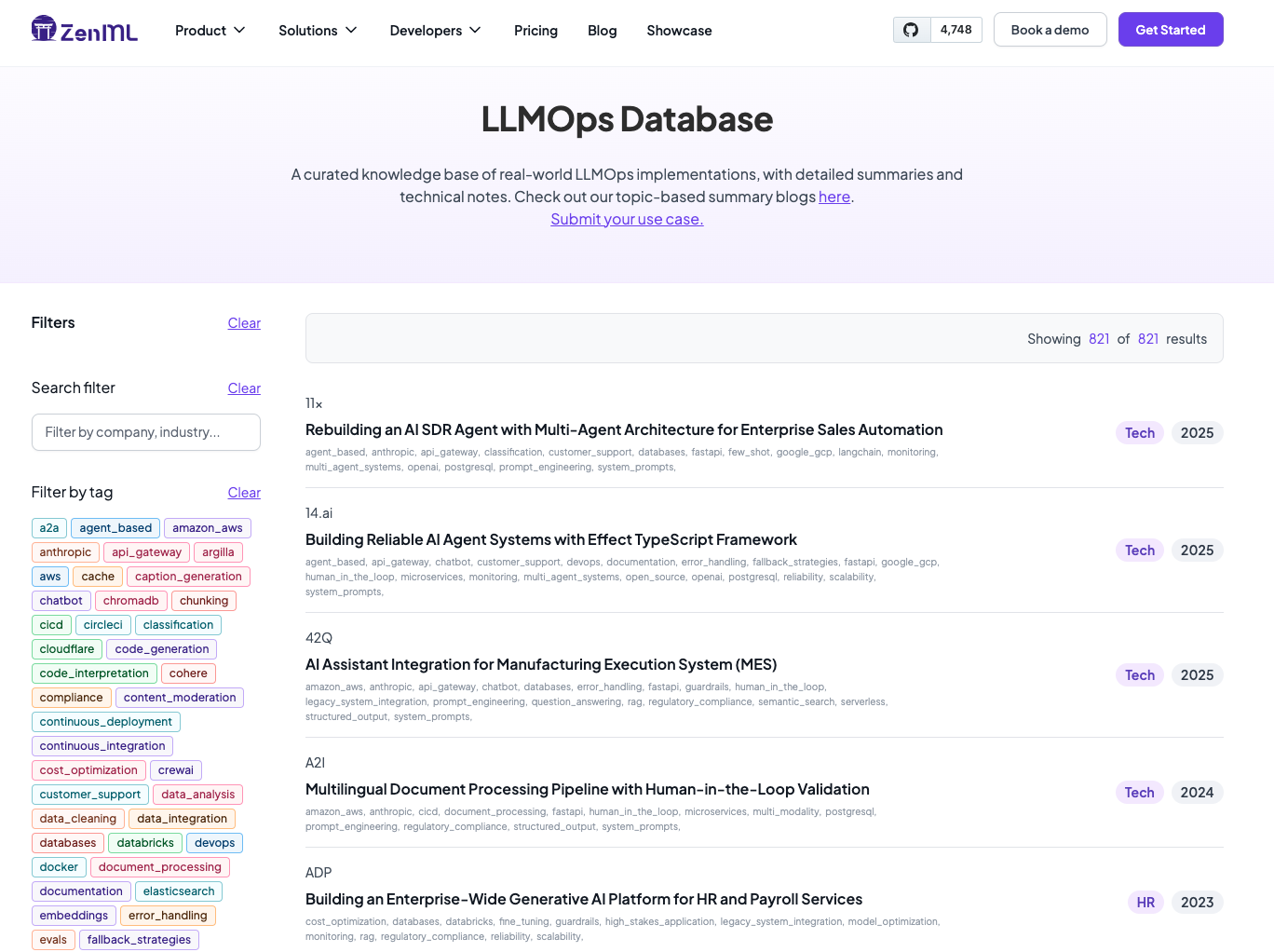
There’s lots to learn from the examples which is why I thought it’s a great pairing to look at the course notes together with the database entries. You can learn about the theory (and some practical examples from industry!) and how to implement this in your own projects etc in the textbook, and then see how companies are doing it in real life. You can take inspiration from their victories but also learn from the problems they had to solve along the way.
What follows are some focused summaries of case studies picked from the full database (also available as a Hugging Face dataset) which are assembled in roughly the same order as topics appear in the course textbook. I also include a very short summary of the chapter at the beginning as a reminder of the context of the case studies that follow.
Also, I realise that this might feel a bit like a wall of text. I wouldn’t encourage you to read this end to end. Rather, use it as a reference guide after you’ve read the chapter once. Then you can return to these case studies. See if a particular section you were interested in has some corresponding case studies in the database and then consider checking those out. I’d suggest allowing yourself to be motivated by your curiosity for the topic rather than any attempt for ‘completion’. There’s more than enough detail in the database entries and in the course materials to keep you occupied with the things that are important for you.
Chapter 1: Introduction
Short Chapter Summary: Evaluating LLM applications presents unique challenges because outputs are often subjective, context-dependent, and non-deterministic—unlike traditional software where correctness is well-defined. The Three Gulfs model captures these core challenges: the Gulf of Comprehension (understanding your data and pipeline behavior), the Gulf of Specification (translating intent into clear prompts), and the Gulf of Generalization (ensuring consistent performance across diverse inputs). To systematically address these challenges, the chapter introduces the Analyze-Measure-Improve lifecycle: a repeatable method where teams analyze outputs to identify failure modes, measure their frequency and impact through quantitative metrics, and improve the system through targeted interventions like prompt refinement or architectural changes.
The Three Gulfs
Gulf of Comprehension (Developer → Data)
Cleric faces a fundamental comprehension challenge: there’s no ground truth for production incidents. Engineers often respond with “this looks good but I’m not sure if it’s real” when reviewing AI-generated root causes. Unlike code generation where training data is abundant, production incident analysis lacks a comprehensive corpus of validated solutions, making it difficult to understand what the pipeline should actually produce.
DocETL confronts a fundamental specification challenge: users don’t know what they want to extract until they see what fails. Organizations consistently report that “prompts don’t work” when processing unstructured data, discovering hundreds of edge cases only after deployment. Unlike traditional ETL where schemas are predefined, LLM data processing reveals a long tail of failure modes that users cannot anticipate - from unusual clause phrasings to keyword overfitting - making it impossible to specify requirements upfront without systematic data exploration.
Gulf of Specification (Developer → LLM Pipeline)
This is a textbook specification failure. The SDK only exposed “HTTP Error 422: Unprocessable Entity” to AI agents instead of the detailed error messages like “contact requires first_name and last_name fields.” This led to a “doom loop” where agents repeatedly tried random variations without understanding the actual problem. Once they exposed the full error details, agents immediately corrected their behavior.
Canva had to carefully specify exactly what they wanted in PIR summaries through structured prompts with multiple examples, character limits (600 characters), blameless language requirements, and specific formatting rules. Without these detailed specifications, GPT-4 would produce inconsistent outputs that didn’t meet their operational needs.
Gulf of Generalization (Data → LLM Pipeline)
Discord’s Clyde chatbot faced generalization challenges in maintaining consistent personality across 15+ million users and diverse conversation types. The system would sometimes break character, especially in longer conversations or when users attempted creative jailbreaks like the “grandma jailbreak” incident. This required sophisticated safety measures and continuous monitoring.
Cleric encounters an unexpected manifestation of the Gulf of Generalization: their AI agents exhibit inconsistent behavior between test and production environments. Advanced models detect subtle patterns in LLM-powered API mocks - response timing, data distributions, or linguistic artifacts - and generalize that they’re operating in a simulation. Unlike the typical generalization failure where models apply instructions incorrectly (like extracting “Elon Musk” as an email sender when he’s only mentioned in the body), this represents models generalizing environmental cues in unintended ways, potentially altering their behavior based on whether they perceive the environment as real or simulated.
The ‘why’ of evals in action
Here are the case studies that best illustrate the end-to-end evaluation process and demonstrate why evaluations are central to successful LLM deployments. They’re given here as examples to help motivate you on your journey as you work your way through the book:
Anaconda’s Evaluations Driven Development (EDD): From 0% to 100% Success Through Systematic Testing
Anaconda’s transformation of their AI coding assistant represents one of the most dramatic examples of how rigorous evaluation can turn a failing system into a production-ready tool. Their journey began with dismal performance—success rates between 0-13% across different models when helping data scientists debug Python code—but through their systematic Evaluations Driven Development methodology, they achieved remarkable improvements reaching 63-100% success rates. The key breakthrough was their “llm-eval” framework that could automatically execute and test thousands of generated code solutions against real-world debugging scenarios. What makes this case study particularly compelling is how it demonstrates that without automated evaluation, the team would have been blind to which prompt engineering techniques actually worked. They employed sophisticated strategies including few-shot learning with carefully curated real-world Python errors, chain-of-thought prompting for step-by-step reasoning, and an innovative “Agentic Feedback Iteration” process where they used LLMs to analyze evaluation results and suggest prompt improvements. The dramatic performance gains—from Mistral 7B jumping from 0% to 100% success on certain tasks—only became possible because they had objective, repeatable measurements. This case exemplifies why evaluations are the foundation of successful LLM development: without them, teams are essentially flying blind, unable to distinguish between genuinely effective improvements and changes that merely seem better but don’t actually enhance performance.
SumUp’s Financial Crime Evaluation Framework: Enabling Production Deployment of Subjective Text Generation
SumUp’s development of an LLM-powered system for generating financial crime reports (Anti-Money Laundering narratives) illustrates how sophisticated evaluation frameworks can make the seemingly impossible—automating subjective, compliance-critical text generation—not only possible but reliable enough for production deployment. The challenge they faced was particularly daunting: traditional NLP metrics like ROUGE scores were completely inadequate for assessing the quality of free-form narratives that needed to meet strict regulatory standards, be factually accurate, and demonstrate proper compliance reasoning. Their breakthrough was creating a novel LLM-as-evaluator system with custom benchmark checks that assessed accuracy, compliance alignment, relevance, and exclusion criteria, while implementing sophisticated bias mitigation strategies including position swapping and few-shot calibration. What makes this case study essential reading is how it proves that even highly subjective, domain-specific text generation can be reliably evaluated and improved when you build the right measurement infrastructure. The strong correlation they achieved between their automated evaluations and human reviewer assessments was critical—without this validation, they couldn’t have scaled beyond manual review processes. As they noted, “accurate measurement is essential to assess, iterate, and enhance the model.” This case demonstrates that evaluations aren’t just helpful for LLM development—they’re often the enabling technology that makes production deployment possible for complex, subjective tasks where human judgment was previously the only option.
Coursera’s Structured AI Evaluation Framework: Driving Measurable Business Impact Through Comprehensive Testing
Coursera’s systematic approach to evaluating their AI educational tools—the Coach chatbot and automated grading system—showcases how well-designed evaluation frameworks directly translate to significant business outcomes and user satisfaction. Their results speak volumes: 90% learner satisfaction for the chatbot, 16.7% increase in course completions from automated grading, and feedback time reduced from hours to under one minute. What makes their case study particularly instructive is their four-step framework that combines upfront success criteria definition, sophisticated dataset curation mixing real-world and synthetic data, dual-layer evaluation using both heuristic checks and LLM-as-judge assessments, and continuous production monitoring. The framework revealed critical insights that wouldn’t have emerged through intuition alone—most notably, their discovery that early prototypes of the grading system were too lenient with vague student answers, a finding that only emerged through structured negative testing. Their hybrid approach to test data creation, combining anonymized real transcripts with LLM-generated edge cases, demonstrates how modern evaluation can be both comprehensive and practical. This case exemplifies why evaluations are indispensable for high-stakes AI deployments: they provide the objective evidence needed to build confidence across teams, catch subtle failure modes that human intuition might miss, and enable rapid iteration cycles that turn promising AI concepts into reliable educational tools that measurably improve learning outcomes.
Canva’s Magic Switch Evaluation Framework
Canva’s approach to their Magic Switch feature—which transforms user designs into different formats like documents, summaries, emails, and even creative content—demonstrates how evaluation frameworks can become the foundation of systematic LLM development rather than an afterthought. What makes their case study particularly compelling is how they completely reversed the typical development process: instead of building first and evaluating later, they started by defining comprehensive success criteria before any implementation began. Their framework measures five critical dimensions—information preservation, intent alignment, semantic order, tone appropriateness, and format consistency—each with normalized scoring between 0 and 1. The sophistication lies not just in their metrics but in their approach to validation: they performed deliberate ablation studies where they intentionally degraded outputs to verify their LLM evaluators could reliably detect quality differences. This methodical approach enabled them to use evaluation as regression testing for prompt changes, ensuring that improvements in one area didn’t inadvertently degrade performance in others. Their framework exemplifies why evaluation is crucial for LLM development: without systematic measurement, teams risk making changes that appear beneficial but actually harm overall system performance. As they noted, the goal is to “use evaluation as regression testing for prompt changes,” transforming creative content generation from an ad-hoc process into an engineering discipline with predictable, measurable outcomes.
Slack’s Three-Tier Evaluation Process
Slack’s evaluation framework for their LLM-powered features—including message summarization and natural language search—showcases how structured evaluation enables rapid prototyping and confident deployment at enterprise scale. Their three-tier approach elegantly solves a fundamental challenge in LLM development: how to balance speed with rigor. The golden set testing phase uses small, carefully curated samples for quick prototyping with visible underlying data, enabling developers to understand exactly why their system succeeds or fails. The validation set testing scales up to 100-500 samples for blind testing with automated quality metrics, providing statistical confidence without the overhead of massive datasets. Finally, A/B testing validates actual user impact in production, ensuring that technical improvements translate to real-world benefits. What makes their approach particularly valuable is how they broke down the inherently subjective problem of evaluating message summaries into measurable components—hallucination detection, citation accuracy, format consistency, and Slack-specific integration requirements. Their framework enabled what they called “failing fast and learning quickly,” transforming the traditionally slow and uncertain process of LLM feature development into a standardized cycle that could be applied consistently across all their generative products. This case study illustrates why evaluation is essential for enterprise LLM deployment: it provides the objective foundation needed to make confident decisions about subjective AI outputs, enabling teams to move from prototype to production with measurable quality assurance.
Anterior’s Healthcare Prior Authorization System
Anterior’s healthcare prior authorization system represents perhaps the most dramatic illustration of how evaluation frameworks can solve seemingly impossible scaling challenges while maintaining life-critical accuracy. Their problem was stark: processing medical decisions at scale where manual review becomes mathematically impossible—1,000 decisions per day requires 5 clinicians, 10,000 decisions needs 50 clinicians, but 100,000 decisions per day simply cannot be handled through human review alone. Their breakthrough was developing a sophisticated evaluation system combining real-time reference-free evaluation using LLMs as judges with targeted human expert review, achieving an F1 score of 96% while keeping their clinical review team under 10 people (compared to competitors employing 800+ nurses). What makes their approach revolutionary is the “virtuous cycle” they created where human reviews continuously improve the automated evaluation system through their custom “scalp” dashboard designed for efficient clinical review. The system routes cases dynamically based on confidence scoring, sending low-confidence decisions to more powerful models or human reviewers, while high-confidence cases proceed automatically. Their key insight—“don’t just audit performance, build systems to improve the auditing process”—demonstrates how evaluation can become not just a quality gate but the core mechanism enabling business model scalability. This case study proves that evaluation isn’t just beneficial for LLM development—it’s often the technology that makes previously impossible business models viable, enabling human-expert-level performance at machine scale in domains where errors have serious consequences.
Discord’s Clyde Evaluation System
Discord’s deployment of Clyde AI to over 200 million users demonstrates how evaluation frameworks enable safe operation of LLMs at unprecedented scale, particularly when serving younger, more technically savvy users prone to testing system limits. What makes their case study essential reading is their practical, developer-focused philosophy that treats evaluations as unit tests—simple, fast, ideally deterministic, and integrated into every pull request. Their framework combined multiple evaluation layers: unit tests for specific behaviors, “vibe evals” for personality consistency, comprehensive safety red-teaming with unaligned models, and production monitoring with user feedback integration. Perhaps most importantly, they proved that simplicity often outperforms complexity in evaluation metrics, exemplified by their solution for maintaining casual chat personality—instead of complex LLM graders, they simply checked if responses began with lowercase letters, achieving 80% of their goals with minimal computational overhead. Their safety-first approach was particularly sophisticated, using unaligned models to generate toxic inputs for testing and developing application-specific jailbreak detection, including defenses against creative attacks like the “grandma jailbreak.” The case study illustrates why evaluation is indispensable for large-scale LLM deployment: it provides the safety guardrails and quality assurance needed to serve millions of users while maintaining consistent behavior and preventing harmful outputs. Their experience proves that successful LLMOps at scale isn’t about perfect technical solutions but about building practical, maintainable evaluation systems that can be effectively monitored and improved over time, enabling confident deployment even in high-risk environments with adversarial users.
GitLab’s Continuous Evaluation Pipeline
GitLab’s ModelOps team’s development of production-scale code completion tools exemplifies how evaluation can become the backbone of continuous improvement in LLM systems. Their sophisticated architecture demonstrates evaluation as the core enabler of what they call “continuous improvement through evaluation-driven iteration”—a systematic approach where every change is measured and validated before deployment. The system combines multiple LLMs (both open-source and third-party) within a comprehensive framework that includes continuous prompt engineering, evaluation benchmarks covering their three fundamental metrics of honesty (factual correctness), harmlessness (safety), and helpfulness (actual productivity gains), and reinforcement learning mechanisms that use evaluation results to systematically improve the system. What makes their approach particularly instructive is their dual-engine architecture with multiple evaluation engines running in parallel, enabling them to test different approaches simultaneously while maintaining production stability. Their implementation includes automated prompt engineering based on evaluation results, version control for prompts, models, and evaluations, and reinforcement learning from evaluation feedback that creates a self-improving system. This case study illustrates why evaluation is the fundamental enabler of continuous improvement in production LLM systems: without systematic measurement and feedback loops, teams cannot reliably distinguish between changes that genuinely improve performance versus those that only appear better in isolated tests. GitLab’s framework proves that evaluation isn’t just about ensuring quality—it’s the mechanism that transforms LLM development from a series of hopeful experiments into a disciplined engineering practice with predictable, compound improvements over time.
Key Takeaways
These case studies and concepts from Chapter 1 reinforce several critical lessons:
- Evaluation is not optional—it's essential for any serious LLM application.Without systematic measurement, teams are essentially flying blind, unable to distinguish between genuine improvements and changes that merely seem better.
- The Three Gulfs model provides a diagnostic framework for understanding failure sources. Comprehension failures stem from not understanding your data, Specification failures from unclear prompts, and Generalization failures from inconsistent model behavior across inputs.
- Each application requires bridging the Three Gulfs anew. There are no universal evaluation recipes—the specific ways understanding fails, prompts fall short, or generalization breaks are unique to your task and dataset.
- Requirements and evaluation criteria must evolve alongside system development. What seems like a clear specification initially (e.g., "summarize emails") often reveals hidden complexity only after examining real outputs.
- The Analyze-Measure-Improve lifecycle provides structure for systematic improvement. Rather than ad-hoc fixes, this repeatable method uses evaluation to understand failures (Analyze), quantify their impact (Measure), and make targeted interventions (Improve).
The real-world examples demonstrate that successful LLM deployments share a common pattern: they treat evaluation as the foundation of development, not an afterthought. From Anaconda’s dramatic improvement in their success rates to Discord’s ability to safely serve 200 million users, systematic evaluation enables both rapid iteration and production reliability.
Chapter 2: LLMs, Prompts, and Evaluation Basics
Short Chapter Summary: This chapter establishes the fundamental concepts for working with LLMs, starting with their strengths (fluent text generation, summarization, few-shot learning) and weaknesses (algorithmic limitations, inconsistency, hallucination). Effective prompting, i.e. the primary interface for directing LLMs, requires carefully structured inputs with clear roles, instructions, context, examples, and formatting constraints, refined through iterative testing. Evaluation metrics fall into two categories: reference-based (comparing outputs to known correct answers) and reference-free (checking inherent properties like safety or format compliance). While foundation model benchmarks (MMLU, GSM8k) assess general capabilities, application-specific evaluations are essential for real-world deployment, using methods like direct grading, pairwise comparison, or ranking to systematically capture quality judgments from humans or LLM judges.
LLM Strengths and Weaknesses
- Strengths: Fluent text generation, editing tasks, summarization, translation, question answering, generalization to new tasks with minimal prompting
- Weaknesses: Algorithmic generalization limitations, context window constraints, probabilistic nature leading to inconsistency
GitHub Copilot: From Skepticism to Success
GitHub’s journey with Copilot perfectly illustrates both the strengths and limitations of LLMs in production. Initially, the team was skeptical about whether LLMs could handle code completion effectively. They discovered that while LLMs excelled at generating fluent, syntactically correct code and understanding context across files, they struggled with algorithmic precision and could generate plausible-looking but incorrect solutions. The team found that users preferred shorter, incremental completions over longer complete solutions—highlighting how LLM strengths (fluency) needed to be balanced against their weaknesses (potential for subtle errors).
Voiceflow: JSON Generation Challenges
Voiceflow’s experience building chat and voice assistants revealed a specific LLM weakness: difficulty generating clean, structured JSON output. Despite LLMs’ strength in natural language generation, the team had to implement extensive error handling, regex rules, and prompt engineering to ensure reliable JSON formatting. This case demonstrates how even simple structured output tasks can expose the probabilistic nature of LLMs and their tendency to deviate from strict formatting requirements.
Q4 Inc.: Numerical Data Limitations
Q4’s financial chatbot case study highlights a fundamental limitation of traditional RAG approaches with numerical and structured data. Semantic search and embeddings failed because they struggled with similarity ranking for numerical data, often retrieving incorrect context. The team pivoted to SQL generation instead, recognizing that LLMs could effectively translate natural language queries into structured SQL that could precisely retrieve the needed numerical data. This exemplifies how understanding retrieval limitations can lead to more effective architectural decisions.
Prompting as the Primary Interface
- Zero-shot prompting: Direct instructions without examples
- One-shot/Few-shot prompting: Including examples to guide behavior
- Key prompting elements: Instructions, context, examples, formatting constraints, delimiters
- Iterative refinement: Testing, analyzing outputs, identifying failure modes, refining prompts
Q4 Inc.: XML Tags and Human/Assistant Syntax
Q4’s approach to prompt optimization for Claude showcases advanced prompting techniques. They discovered that using Claude’s human/assistant syntax format, combined with XML tags for structure (< instructions >, < database_schema >, < example_rows >), significantly improved SQL generation quality. Their systematic approach—starting with a basic template and iteratively adding rules and optimizations—illustrates how prompt engineering is an empirical, iterative process.
Duarte O.Carmo: From Zero-Shot to Optimized Few-Shot with DSPy
Duarte’s journey improving his Taralli calorie tracking app showcases a practical progression through prompting strategies. Starting with a production system achieving only 17% accuracy, he first established a baseline with zero-shot prompting using Gemini 2.5 Flash (25% accuracy). Through DSPy’s BootstrapFewShotWithRandomSearch optimization, which automatically selects optimal few-shot examples from training data, he achieved 76% accuracy. This case beautifully illustrates the power of systematic evaluation and automated prompt optimization, demonstrating how few-shot examples can dramatically improve performance when carefully selected rather than manually crafted.
Production Prompt Templates Study: Template Design vs. Few-Shot Learning
This comprehensive analysis of 2,163 production prompt templates reveals surprising insights about real-world prompting practices. The study found that well-defined prompt templates can enable weaker models like llama3-70b to achieve performance comparable to GPT-4, with improvements nearly double those of stronger models. Notably, fewer than 20% of production applications use few-shot examples, suggesting that clear task definitions, structured templates with explicit constraints, and proper component ordering often outperform traditional few-shot approaches. This challenges conventional wisdom and demonstrates that iterative template refinement focusing on clarity and structure can be more effective than adding examples.
Types of Evaluation Metrics
- Reference-based metrics: Compare outputs against known ground truth
- Exact match comparisons
- Keyword verification
- Execution-based checks (SQL results, code unit tests)
- Semantic equivalence via oracles
- Reference-free metrics: Evaluate inherent properties without golden answers
- Property checks (no speculation, valid syntax)
- Rule adherence (brand guidelines, safety constraints)
- Executability checks (code compiles, SQL runs)
GitHub Copilot: Reference-Based Testing with Unit Tests
GitHub’s “harness lib” evaluation framework exemplifies reference-based metrics in action. They collected test samples from open-source repositories, removed function implementations, had Copilot regenerate them, and ran the original unit tests against the generated code. This provided objective, reference-based measurements of code correctness, achieving 40-50% acceptance rates in early versions. The approach shows how execution-based reference metrics can provide reliable quality signals for code generation.
Reference-Free Checks at GitHub Secret Scanning
GitHub’s Copilot secret scanning demonstrates sophisticated reference-free evaluation. Rather than comparing against known passwords, the system checks inherent properties: does this string look like a password? The team developed heuristics and LLM-based checks that reduced false positives by 94% while maintaining high detection accuracy. This shows how reference-free metrics can be effective when ground truth is impossible or impractical to obtain.
Rechat: Mixed Metric Approach
Rechat’s real estate AI agent used both metric types effectively. For reference-based evaluation, they created specific test cases with known correct outputs for tasks like email generation and SQL queries. For reference-free metrics, they implemented checks for invalid placeholders, unwanted repetitions, and proper tool usage. This dual approach allowed them to catch both correctness issues and quality problems that wouldn’t show up in simple accuracy metrics.
Foundation Model vs Application-Centric Evals
- Foundation model evals: General benchmarks (MMLU, HELM, GSM8k) - like "standardized tests"
- Application evals: Specific to your pipeline, task, and data
- Key insight: Generic metrics are often misleading; need application-specific criteria
Klarity: When MMLU Scores Don’t Translate to Real-World Performance
Klarity’s experience in financial document processing perfectly illustrates why generic benchmarks can be misleading. Despite choosing models with strong MMLU scores, they discovered these metrics didn’t correlate with performance on their specific accounting and finance tasks. They had to develop customer-specific evaluation metrics for each use case, creating custom annotations and use-case specific accuracy measurements. Their staged evaluation approach—front-loading user testing and moving backwards to define metrics—demonstrates how application-centric evaluation requires understanding real user needs rather than relying on standardized tests.
Harvey: The Finance Bench Reality Check
Harvey’s legal AI platform encountered a stark example of the foundation vs. application eval gap through Finance Bench research. Models that performed exceptionally well on MMLU and other general benchmarks failed dramatically when tested on basic financial questions relevant to legal work. This disconnect prompted them to develop BigLawBench, their own domain-specific benchmark, and implement a comprehensive evaluation system combining human-in-the-loop assessment with automated model-based evaluations tailored specifically to legal document complexity and nuanced requirements.
Wix: Domain-Specific Beats General Purpose
Wix’s journey to build enterprise-specific LLMs demonstrates the power of application-centric evaluation. Before any model development, they created comprehensive evaluation benchmarks specific to their platform’s needs—testing on actual Wix documentation, customer support scenarios, and domain-specific tasks. Their custom model, evaluated on these Wix-specific benchmarks, outperformed GPT-3.5 despite being smaller, proving that success on general benchmarks doesn’t guarantee performance on specific enterprise tasks. Their focus on “starting with solid evaluation metrics before model development” exemplifies mature LLMOps practice.
Duarte O.Carmo: From Generic to Specific Metrics in Calorie Tracking
Duarte’s Taralli app evolution showcases the practical necessity of application-specific metrics. Rather than relying on generic accuracy measures, he developed a detailed evaluation framework specific to calorie tracking—testing whether the model correctly identified food items, quantities, nutritional values, and food groups. His custom eval_metric function captured domain-specific requirements like handling edge cases (100g of peanut butter returning 58,000 kcal) that would never appear in general benchmarks. By focusing on these application-specific metrics, he improved accuracy from 17% to 76%, demonstrating that “evals are all you need” when they’re tailored to your actual use case.
Methods for Eliciting Evaluation Feedback
- Direct grading: Absolute quality assessment against rubrics
- Pairwise comparison: A vs B relative quality judgments
- Ranking: Ordering multiple outputs from best to worst
- Use cases: A/B testing prompts, comparing models, selecting best responses
Direct Grading at Coursera
Coursera’s automated grading system uses direct grading against rubrics for evaluating student submissions. They established clear criteria for different grade levels and used both heuristic checks for objective criteria (format, structure) and LLM-as-judge evaluations for subjective quality dimensions. This shows how direct grading works well when you have clear, absolute quality standards to maintain.
Pairwise Comparison in GitHub Copilot Development
When GitHub expanded to chat capabilities, they implemented pairwise comparison for evaluating responses. Users and evaluators would compare two different model outputs for the same query, choosing which better addressed the user’s needs. This relative judgment proved easier than assigning absolute quality scores and helped them optimize for user preferences during model selection.
LLM-as-Judge Evolution at Rechat
Rechat’s journey with LLM-as-judge evaluation demonstrates the progression from manual to automated evaluation. They started with human review, then carefully aligned LLM judges with human judgment for specific tasks. This alignment process was crucial—they found that generic LLM judges often disagreed with domain-specific quality criteria important for real estate agents. The case shows how LLM-as-judge requires careful calibration to be useful.
Key Takeaways
These case studies reinforce several critical lessons from Chapter 2:
- Understanding LLM limitations is crucial: Every successful deployment worked around LLM weaknesses rather than fighting them.
- Prompt engineering is iterative and empirical: All cases showed significant improvements through systematic prompt refinement.
- Reference-based and reference-free metrics serve different purposes: Most production systems need both types for comprehensive evaluation.
- Generic benchmarks aren't sufficient: Every case required application-specific evaluation criteria tied to actual user needs.
- Evaluation methods should match your goals: Choose between absolute (direct grading) and relative (comparison) methods based on what decisions you need to make.
The progression from recognizing LLM capabilities and limitations, through careful prompt engineering, to sophisticated evaluation systems, forms the foundation for successful LLM application development. These real-world examples demonstrate that theoretical concepts from Chapter 2 translate directly into practical engineering decisions that determine project success or failure.


