
On this page
Last updated: October 17, 2022.
Around 87% of machine learning projects do not survive to make it to production. There is a disconnect between machine learning being done in Jupyter notebooks on local machines and actually being served to end-users to provide some actual value.
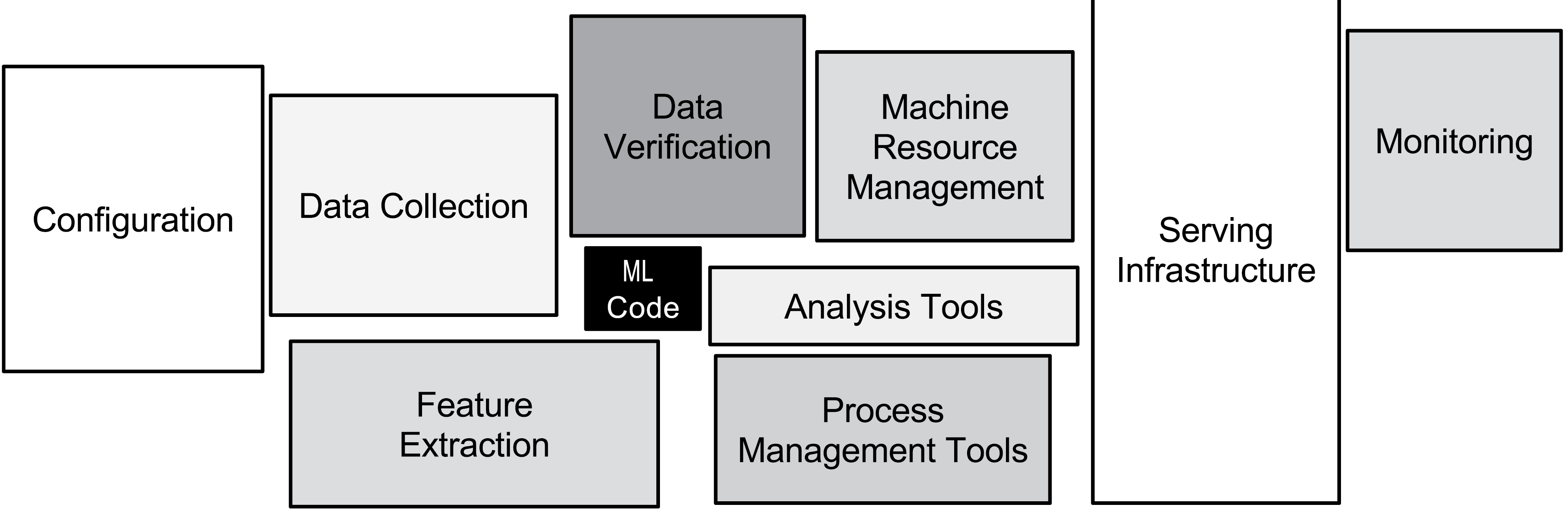
 Source: Hidden Technical Debt in Machine Learning Systems (Sculley et al.)
The oft-quoted Hidden Technical Debt paper, whose diagram can be seen here, has been in circulation since 2017, yet still, deep learning in production has a ways to go to catch up to the quality standards attained by more conventional software development. Here is one take on what is broken:
Data is not treated as a first-class citizen
In traditional software development, code is (rightly-so) **a first-class citizen. In ML development, there is a further need for data to be a first-class citizen as well. Therefore, data has to be treated with the same care that most developers give to the code they write.
Right now in most organizations, data is spread everywhere and inaccessible. This is not just about raw data either-even if an organization spends a lot of money into centralizing their data into lakes, critical data is spread across the organization in colabs, notebooks, scripts and pre-processed flat files. This causes, amongst other things:
- Wasted compute on redundant transformations of data
- No transparency and accountability of what data trains what models
- Inability to transfer important training phase to the serving phase (see below)
Different requirements in training and serving
Teams often find it surprising when a well-trained model starts to give spurious results in the real world. The transition from training a model to serving it is far from trivial.
For examples, there is a skew in training and production data, that needs to be taken into account. Secondly, one has to be very careful in making sure that production data goes through the same preprocessing steps in production as in training. Lastly, while training involves running experiments and quickly iterating, serving has even further requirements on the application level, e.g. inference time and costs at scale. All these need to be taken into account to avoid unnecessary surprises when the transition from training to serving happens.
No gold standard yet for ML Ops
Applying DevOps principles for ML development (or MLOps) is all the rage right now. However, there is yet no gold standard for it. The field in its infancy needs to tackle:
- Resources (compute, GPU etc) are scattered and not being used efficiently across teams
- No proper CI/CD pipelines
- No proper monitoring in production (change in data quality etc.)
- Scaling is hard - in training and in serving
- Machine learning compute works in spikes, so systems need to be equipped to deal with that
Collaboration is hard
In conventional software development, we use workflows that integrate tickets and version control to make collaboration as seamless and transparent as possible. Unfortunately, ML development still lags behind on this front. This is largely due to the fact that ML developers tend to create silos which include glue-code scripts, preprocessed data pickles, and jupyter notebooks. While all these are useful for research and experimentation, they do not translate well into a robust, long-running, production environment.
In short, in the ML world, there is largely:
- Non-transparency coupled with individual experimentation
- Notebook Hell with glue-code scripts
- No versioning, in data, code or configuration
Conclusion
Most of the problems highlighted above can be solved by proper attention being paid to machine learning development in production, from the first training onwards. The field is catching up, slowly but surely, but it is inevitable that machine learning will catch up with traditional software engineering quickly. Will we see new, even improving, and exciting ML products in our lives at that point? Let’s hope so!
Our attempt to solve these problems is ZenML, an extensible, open-source MLOps framework. We recently launched and are now looking for practitioners to solve their problems in production use-cases! So, head over to GitHub, and don’t forget to leave us a star if you like what you see!


