On this page
Modern machine learning engineering relies on pipelines to automate data preparation, model training, evaluation, and deployment.
However, selecting the right pipeline tool poses a significant challenge for ML engineers and data scientists, as many platforms overlap in functionality and promise to streamline workflow automation. This article compares Metaflow, Kubeflow, and ZenML – three popular ML pipeline frameworks – to help you understand their strengths and decide which is the best fit for your needs.
A quick note before we get started: Rather than positioning Metaflow, Kubeflow, and ZenML as direct competitors, we’ll explore how these platforms can complement each other in modern MLOps. In practice, many teams leverage combinations of these tools, using each platform’s strengths to mitigate the others’ weaknesses. With that context in mind, let’s dive into the key takeaways and detailed feature comparison.
Metaflow vs Kubeflow vs ZenML: Key Takeaways
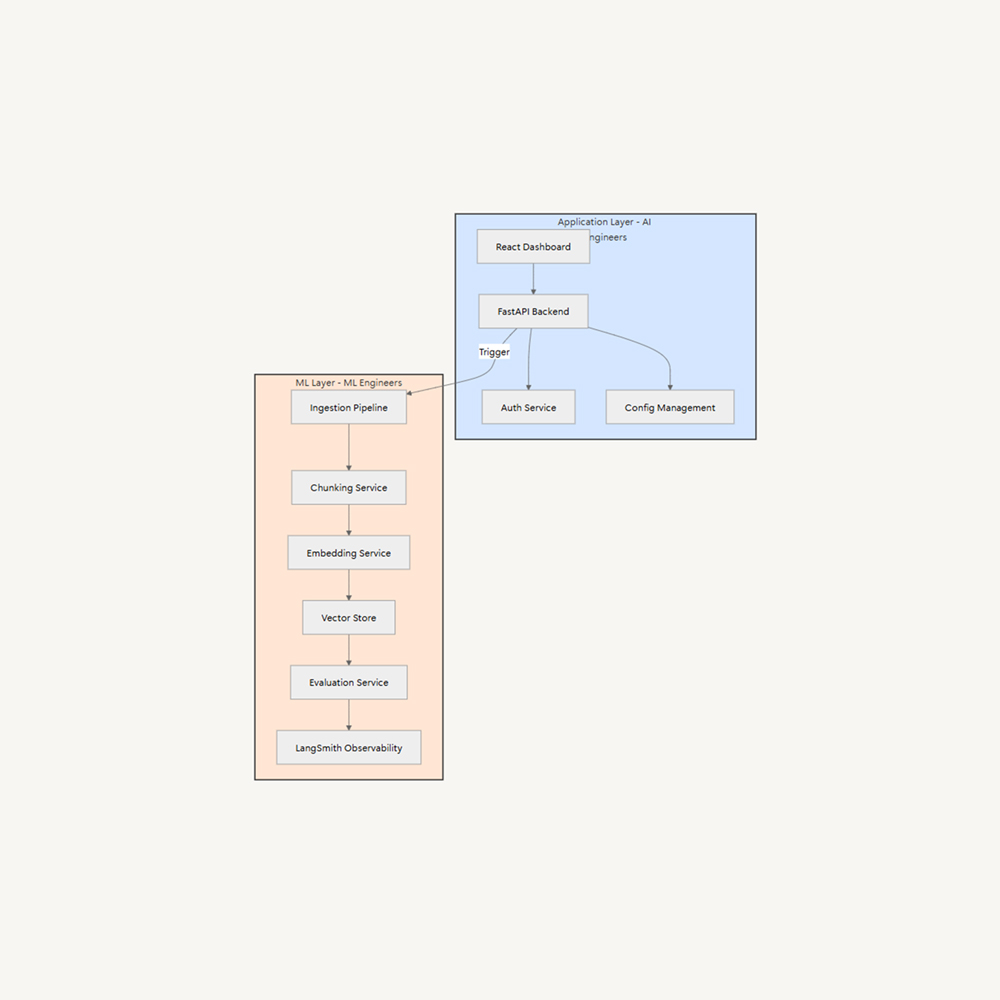
🧑💻 Metaflow: An open-source ML workflow framework originally developed at Netflix, focused on ease of use for data scientists. You define pipelines (flows) in plain Python and can develop and debug locally, then deploy to production without code changes.
🧑💻 Kubeflow: An open-source, Kubernetes-native platform for building and deploying portable, scalable ML workflows as containerized pipelines. Kubeflow Pipelines provides a rich user interface for managing experiments, pipeline runs, and recurring jobs, backed by a pipeline orchestration engine for scheduling multi-step workflows.
🧑💻 ZenML: An extensible, open-source MLOps framework for creating portable, production-ready ML pipelines. ZenML lets you write pipelines as simple Python functions decorated with @pipeline, composed of modular @step functions. The framework decouples pipeline code from infrastructure by abstracting components as a ‘stack,’ so you can run the same pipeline on different orchestrators or cloud platforms without changing your code.
Metaflow vs Kubeflow vs ZenML: Feature Comparison
Here’s a TL;DR of the features we compare for Metaflow, Kubeflow, and ZenML.
| Feature | Metaflow | Kubeflow | ZenML | Best For |
|---|---|---|---|---|
| Orchestration & Scheduling |
|
|
| 🏆 All three excel in different scenarios |
| Experiment Tracking & Versioning |
|
|
| 🏆 ZenML |
| Pipeline UI & Visualization |
|
|
| 🏆 Kubeflow & ZenML |
| Integration Capabilities |
|
|
| 🏆 ZenML |
| Pricing |
|
|
| Depends on scale & requirements |
| Best Use Cases |
|
|
| Choose based on your team’s needs |
Feature 1. Orchestration and Scheduling
Workflow orchestration is the process of coordinating the execution of various steps in an ML pipeline. A strong orchestrator handles task dependencies, parallelization, retries, scheduling of recurring runs, and resource management – all critical for production ML pipelines.
Metaflow
Metaflow’s core design centers on Python-based orchestration of flows. You define a pipeline as a FlowSpec class with Python @step methods, and Metaflow’s engine takes care of executing those steps in the correct order (based on your code’s self.next() dependencies).
By default, Metaflow runs steps locally or on AWS cloud infrastructure with minimal setup. For example, you can annotate steps with decorators like @resourcesor @batch to request CPU/GPU or launch on AWS Batch, and Metaflow will handle packaging the code and data for that execution.
When it comes to scheduling pipelines, Metaflow opts to integrate with external orchestrators rather than reinvent the wheel.
The platform provides built-in integrations to deploy your flows on AWS Step Functions, Argo Workflows, or Apache Airflow for production scheduling.
from metaflow import FlowSpec, Parameter, step
class ParameterFlow(FlowSpec):
alpha = Parameter('alpha',
help='Learning rate',
default=0.01)
@step
def start(self):
print('alpha is %f' % self.alpha)
self.next(self.end)
@step
def end(self):
print('alpha is still %f' % self.alpha)
if __name__ == '__main__':
ParameterFlow()In fact, you can take a Metaflow workflow and export it as a Step Functions state machine or an Airflow DAG automatically, using the same Python code you wrote for local execution.
In practice, Metaflow’s approach is developer-friendly: you can iterate on a flow locally with the metaflow run CLI, then deploy to production with one command (metaflow push) to a scheduler like Step Functions without rewriting any pipeline logic.
Basic time-based scheduling can be handled through these integrations or even via Metaflow’s built-in @schedule decorator for AWS Step Functions.
**📚 Also read: **Metaflow alternatives
Kubeflow
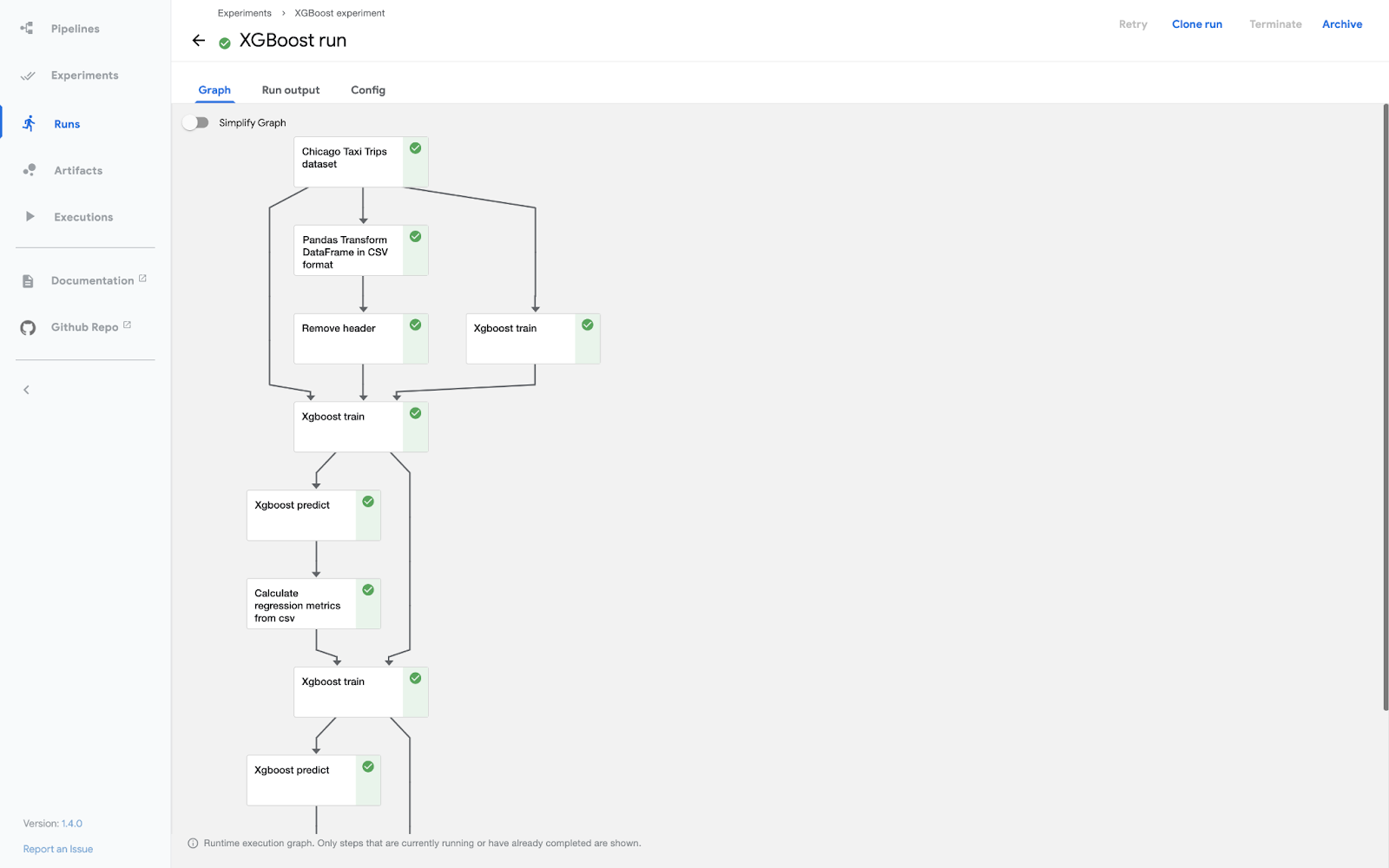
Kubeflow takes a more heavyweight but comprehensive approach to orchestration. Kubeflow Pipelines (KFP) is the component that orchestrates and schedules ML workflows on Kubernetes.
With Kubeflow, you describe your pipeline using the KFP Python SDK or TensorFlow Extended (TFX) DSL, which essentially involves writing Python functions and composing them into a directed acyclic graph (DAG) of tasks.
Under the hood, Kubeflow Pipelines will convert your pipeline into a Kubernetes workflow – by default on Kubeflow v1; this means an Argo Workflows YAML specification. Each pipeline step is packaged as a container (Docker image), and Argo executes these containers in the right order on the Kubernetes cluster.
Because it’s Kubernetes-native, Kubeflow can orchestrate at a massive scale, running many steps in parallel across a cluster, and it naturally handles containerized tasks.
For scheduling, Kubeflow Pipelines includes a built-in mechanism to schedule recurring pipeline runs via the Pipelines UI. You can configure Recurring Runs with a cron expression or periodic interval – for example, to retrain a model every day at 9 am.
The Kubeflow UI and API allow setting these triggers, and the system will automatically start new pipeline runs on schedule.
**📚 Also read: **Kubeflow vs MLflow
ZenML
ZenML takes a unique approach that we can call ‘meta-orchestration.’ Rather than being a full workflow orchestrator itself, ZenML acts as a layer above your choice of orchestrator.
When you run a ZenML pipeline, it delegates the execution of each pipeline step to an Orchestrator stack component that you configure.
ZenML comes with a local orchestrator, which just runs steps on your local machine in sequence or in parallel threads and supports a range of remote orchestrators through integrations.
The platform’s orchestrator abstraction handles packaging your code and sending it to the target orchestrator. For instance, ZenML will build a Docker image for your pipeline (if required by the orchestrator) and submit it to Kubeflow or Airflow for execution. This means you don’t have to write Argo YAML or Airflow DAG code – ZenML generates those for you all by itself.
Scheduling in ZenML is also implemented via the underlying orchestrators. ZenML provides a scheduling abstraction where you can attach a Schedule to a pipeline (with a cron expression or interval) using the SDK.
from zenml.config.schedule import Schedule
from zenml import pipeline
from datetime import datetime
@pipeline()
def my_pipeline(...):
...
# Use cron expressions
schedule = Schedule(cron_expression="5 14 * * 3")
# or alternatively use human-readable notations
schedule = Schedule(start_time=datetime.now(), interval_second=1800)
my_pipeline = my_pipeline.with_options(schedule=schedule)
my_pipeline()When you deploy that scheduled pipeline, ZenML will create the appropriate scheduled job in the orchestrator.
Bottom line: Metaflow offers straightforward orchestration with optional hooks into other schedulers. Kubeflow provides a Kubernetes-based orchestration powerhouse with built-in scheduling. ZenML gives you flexible orchestration by abstracting the backend, which is great for multi-environment workflows and leveraging existing orchestrators without writing new code.
Feature 2. Experiment Tracking and Versioning
In ML projects, experiment tracking and dataset/model versioning are crucial for reproducibility and collaboration. This feature encompasses how each tool keeps track of runs, parameters, metrics, artifacts, and model versions.
Metaflow
One of Metaflow’s standout features is its built-in versioning of data artifacts and code. Every time you run a Metaflow flow, it automatically tracks the code version and any data you produce or pass between steps.
In Metaflow, any object you assign to self (e.g., self.model = ...) in a step is persisted as an artifact, stored, and versioned by Metaflow.
from metaflow import FlowSpec, step, S3
import json
class S3DemoFlow(FlowSpec):
@step
def start(self):
with S3(run=self) as s3:
message = json.dumps({'message': 'hello world!'})
url = s3.put('example_object', message)
print("Message saved at", url)
self.next(self.end)
@step
def end(self):
with S3(run=self) as s3:
s3obj = s3.get('example_object')
print("Object found at", s3obj.url)
print("Message:", json.loads(s3obj.text))
if __name__ == '__main__':
S3DemoFlow()These artifacts are saved in Metaflow’s data store by default, a local directory, in production, typically Amazon S3. Each run of a flow gets a unique Run ID, and artifacts are organized under that run.
The upshot is that you can always refer back to a prior run and retrieve the exact data artifacts and even the code environment from that run, ensuring reproducibility.
For experiment tracking, Metaflow doesn’t have a fancy UI, but it provides a Client API to query past runs, parameters, and results. You can tag runs with custom labels to record things like ‘baseline’ or ‘production candidate’ and later filter or search runs by these tags.
**📚 Also read: **Metaflow vs MLflow
Kubeflow
Kubeflow approaches experiment tracking through the lens of its pipeline system and ancillary components.
In Kubeflow Pipelines, an ‘Experiment’ is essentially a namespace or grouping for pipeline runs. For example, you might have an experiment called ‘ResNet hyperparameter tuning’ under which multiple pipeline runs are executed.
The Kubeflow Pipelines UI lets you organize runs into these experiments for clarity. However, Kubeflow’s native tracking of metrics and parameters is somewhat limited.
When you want to record metrics from a pipeline step, you typically output them in a special way (think - writing to a file or stdout in a predefined format) so that the Kubeflow UI can pick them up and display them.
For artifact and lineage tracking, Kubeflow integrates with ML Metadata (MLMD) behind the scenes. You can record every pipeline run’s executions and artifacts in a metadata database.
What’s more, Kubeflow Pipelines UI even has a Lineage Graph view, where you can click on an artifact and see which step produced it and which subsequent steps consumed it.
Lastly, Kubeflow also provides ‘Katib’ for experiment tracking in the sense of hyperparameter tuning experiments. Katib will launch multiple trials - pipeline runs or training jobs, with different hyperparameters and track their metrics like objective values.
ZenML
ZenML was designed with experiment tracking in mind – in fact, it treats experiment tracking as a first-class concern in its stack.
# List all stacks
zenml stack list
# Register a new stack with minimal components
zenml stack register my-stack -a local-store -o local-orchestrator
# Register a stack with additional components
zenml stack register production-stack \
-artifact-store s3-store \
--orchestrator kubeflow \
--container-registry ecr-registry \
--experiment-tracker mlflow-trackerBy default, ZenML will track metadata for each pipeline run in its own SQLite database or a configured database. This includes pipeline run IDs, step statuses, parameters used, and artifacts produced.
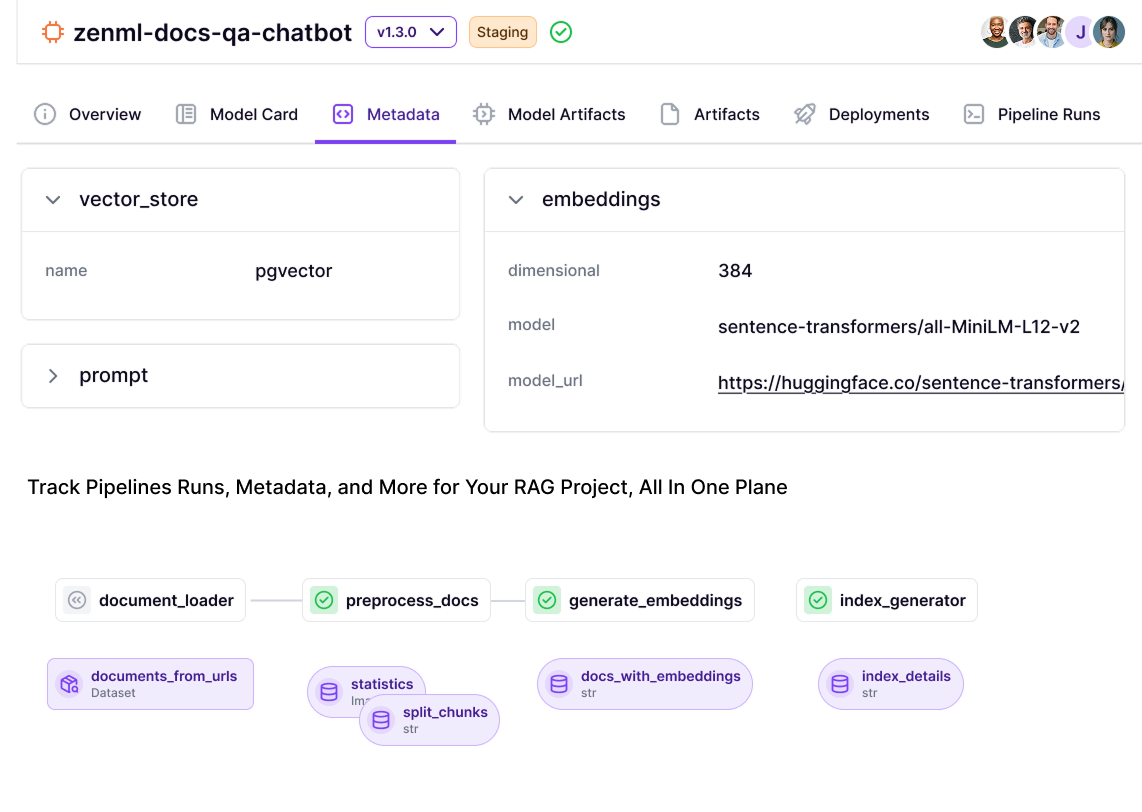
Every ZenML pipeline run can be viewed as an ‘experiment’ in ZenML’s terms. Our platform provides both programmatic and visual ways to leverage experimental information.
For artifact versioning, ZenML utilizes an Artifact Store – a local folder, S3 bucket, GCS bucket, etc. - to automatically save all step outputs.
Each pipeline run has its own artifact directory, containing artifacts for each step. Because ZenML knows the pipeline structure, it can maintain full data lineage: which artifact came from which step, and how it ties into the next step.
In the ZenML Dashboard (UI), you can actually inspect artifact lineage graphs, similar to Kubeflow, but often more interactive.
Where ZenML shines for experiment tracking is its integration with dedicated experiment tracker tools. In your ZenML stack, you can include an Experiment Tracker component like MLflow, Weights & Biases, Neptune, or Comet (more on integrations later).
Lastly, the new ZenML Dashboard also adds a lot for tracking. Through the dashboard, you can browse all pipeline runs, filter them, and see:
- Which code version was used
- Who ran it
- How long did it take
And more importantly, you can visualize artifacts and metrics directly.
Bottom line: Metaflow auto-versions everything for robust reproducibility but leaves advanced experiment analytics to you.
Kubeflow records metadata and can group runs, but often requires augmentation with external trackers for deep experiment analysis.
ZenML tracks everything end-to-end (artifacts, runs, metrics) and plays nicely with dedicated tracking tools, giving you a complete experiment management experience with minimal setup.
Feature 3. Pipeline UI and Visualizations
A user-friendly interface or visualization mechanism simplifies pipeline development and debugging. This feature looks at what each tool offers in terms of UI: pipeline graphs, run dashboards, artifact visualizations, and any special reporting capabilities.
Metaflow
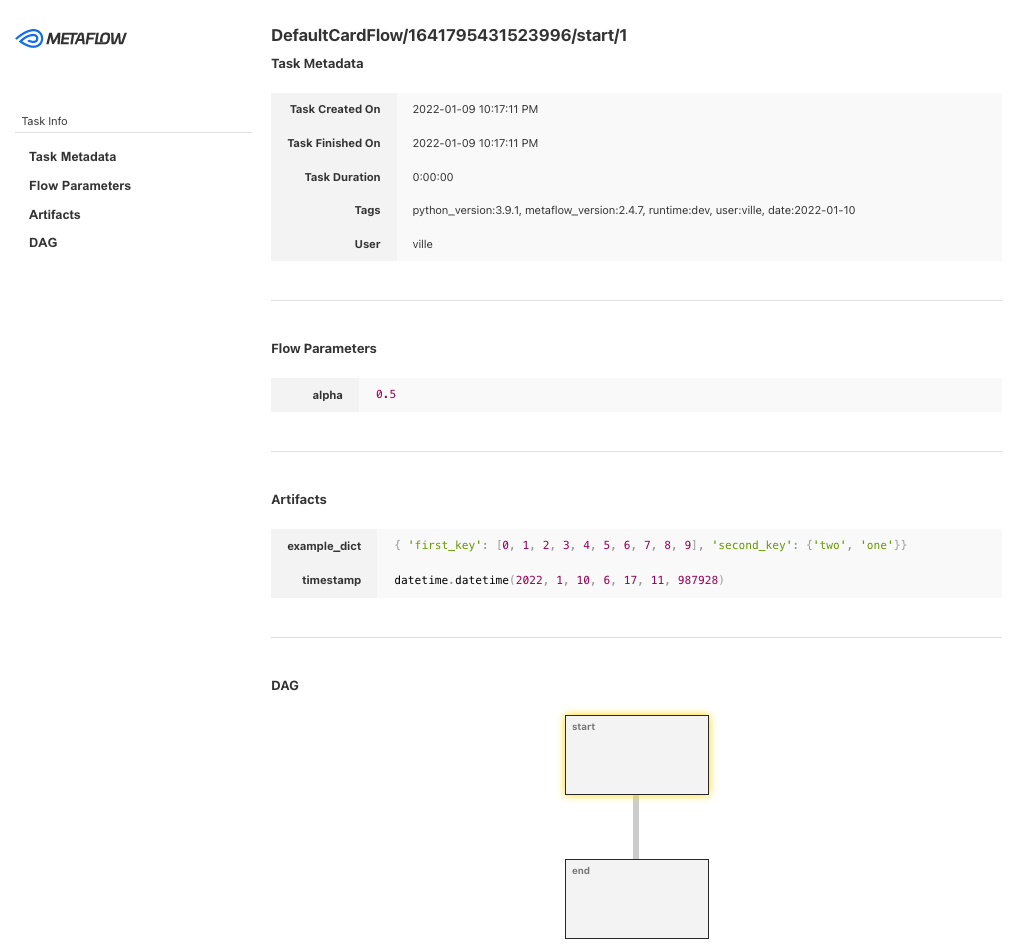
Metaflow famously has no traditional web UI for pipelines but instead provides an innovative feature called Cards for visualizing results.
A Metaflow Card is an HTML report that you can attach to any step in your flow. By using the @card decorator on a step or running a flow with the --with card option, Metaflow will capture that step’s artifacts and generate a default report in HTML.
The Default Card includes:
- Sections for task metadata
- Parameters used in the flow
- A list of artifacts produced by the step
- A simple visualization of the flow’s DAG around that step
While Metaflow doesn’t have a built-in GUI for general workflow management, Netflix has open-sourced an optional Metaflow UI service. This UI provides a dashboard for browsing runs, parameters, and logs, offering a visual overview of experiments.
Kubeflow
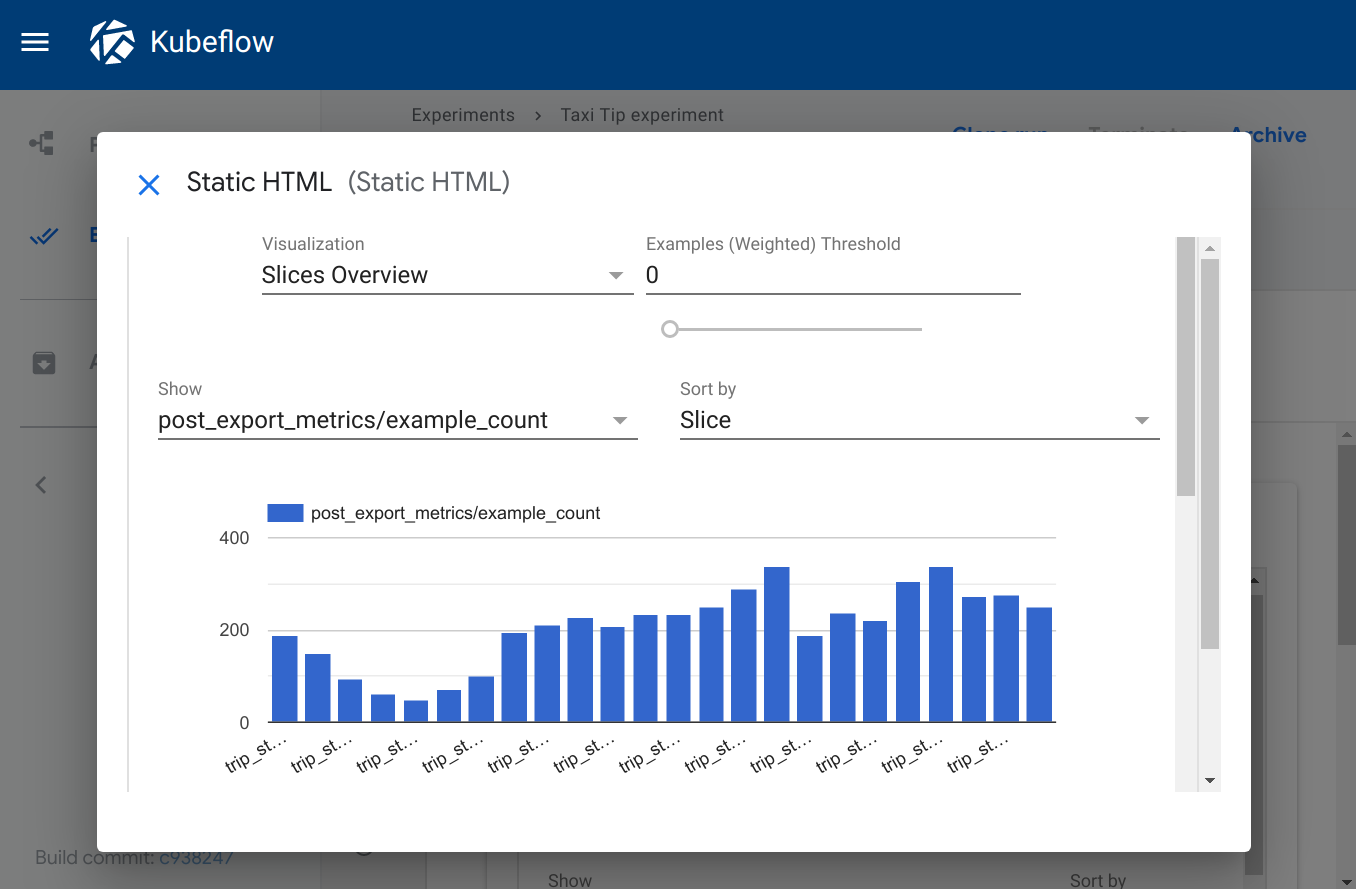
Kubeflow provides a fairly rich user interface for pipelines as part of its central dashboard.
When you access Kubeflow Pipelines UI, you can:
- View a list of Experiments
- List all pipeline runs along with statuses for each run
- See a detailed pipeline graph visualization
The pipeline graph shows each step as a node in the DAG, with arrows denoting dependencies. You can click on each node to inspect logs, inputs, and outputs for that step.
This graphical view is quite helpful in understanding and debugging pipeline runs – you can quickly spot if a step failed, see which steps ran in parallel, and more.
Kubeflow also has a dedicated Runs page where each run is listed with start time, duration, and outcome, and you can compare pipeline run configurations side by side.
For visualizing outputs, Kubeflow Pipelines has a feature for output artifacts visualization. If a step produces a certain type of output, for example, an ROC curve image or a table of results, you can use the Output Viewer mechanism. The SDK enables you to tag output files with metadata, allowing the UI to render them accordingly.
ZenML
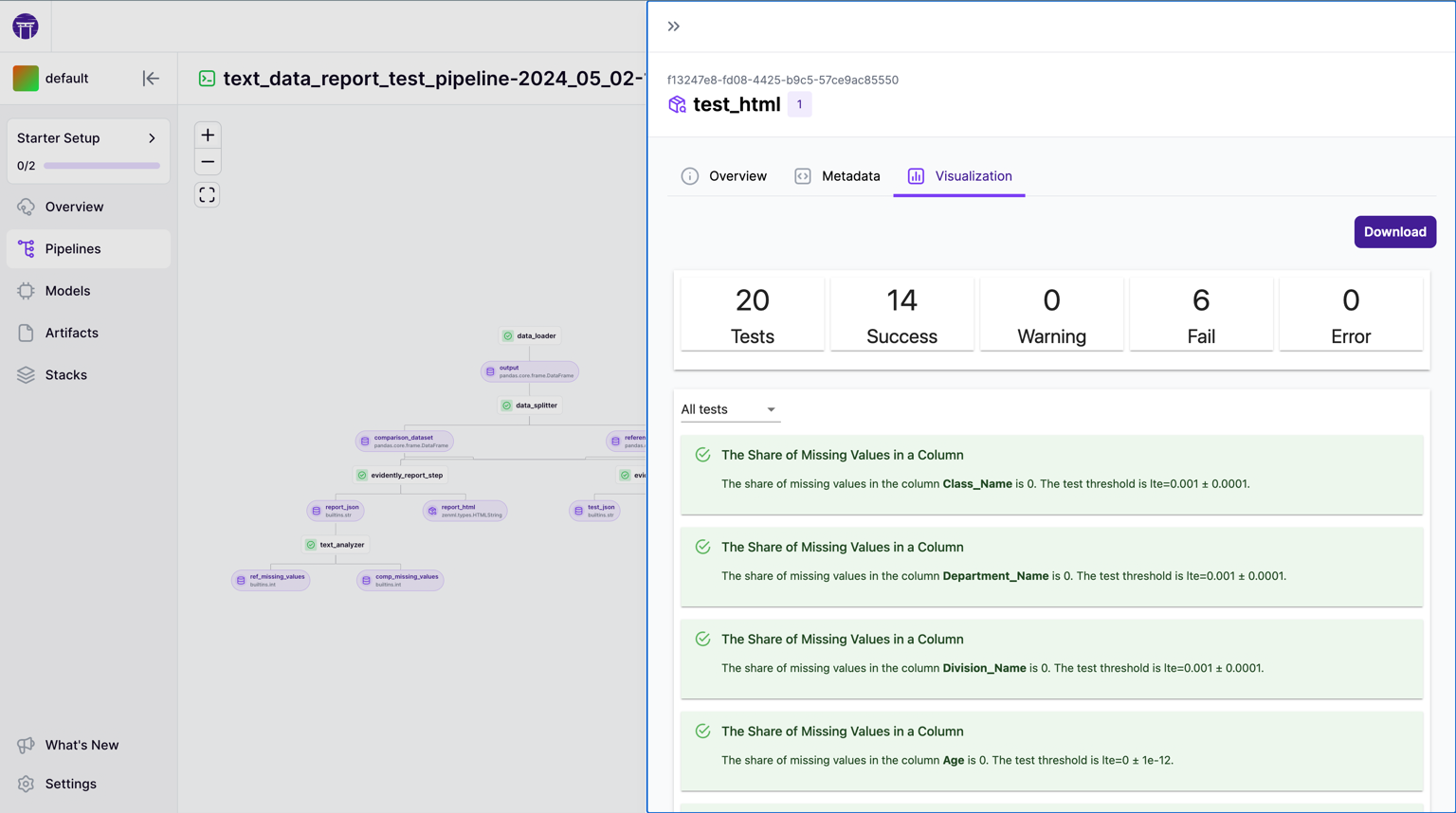
ZenML has recently introduced an official ZenML Dashboard to complement its CLI and Python APIs. The dashboard is a web interface that lets you perform many common tasks: visualize pipelines, monitor runs, inspect artifacts, manage stacks, and more.
It aims to give the kind of smooth experience you get from MLflow or other MLOps tools but is tailored to ZenML’s pipeline-centric paradigm.
In the ZenML Dashboard, one of the key features is Pipeline Visualization. Whenever you run a pipeline, the UI shows an interactive DAG of the pipeline’s steps.
This graph is similar in concept to Kubeflow’s: nodes for steps, arrows for dependencies. You can click on a step node to get more details like logs, status, and runtime.
Because ZenML pipelines are written in Python, this DAG is generated automatically without your efforts. The dashboard DAG views updates in real-time as the pipeline runs, showing which steps are running or completed.
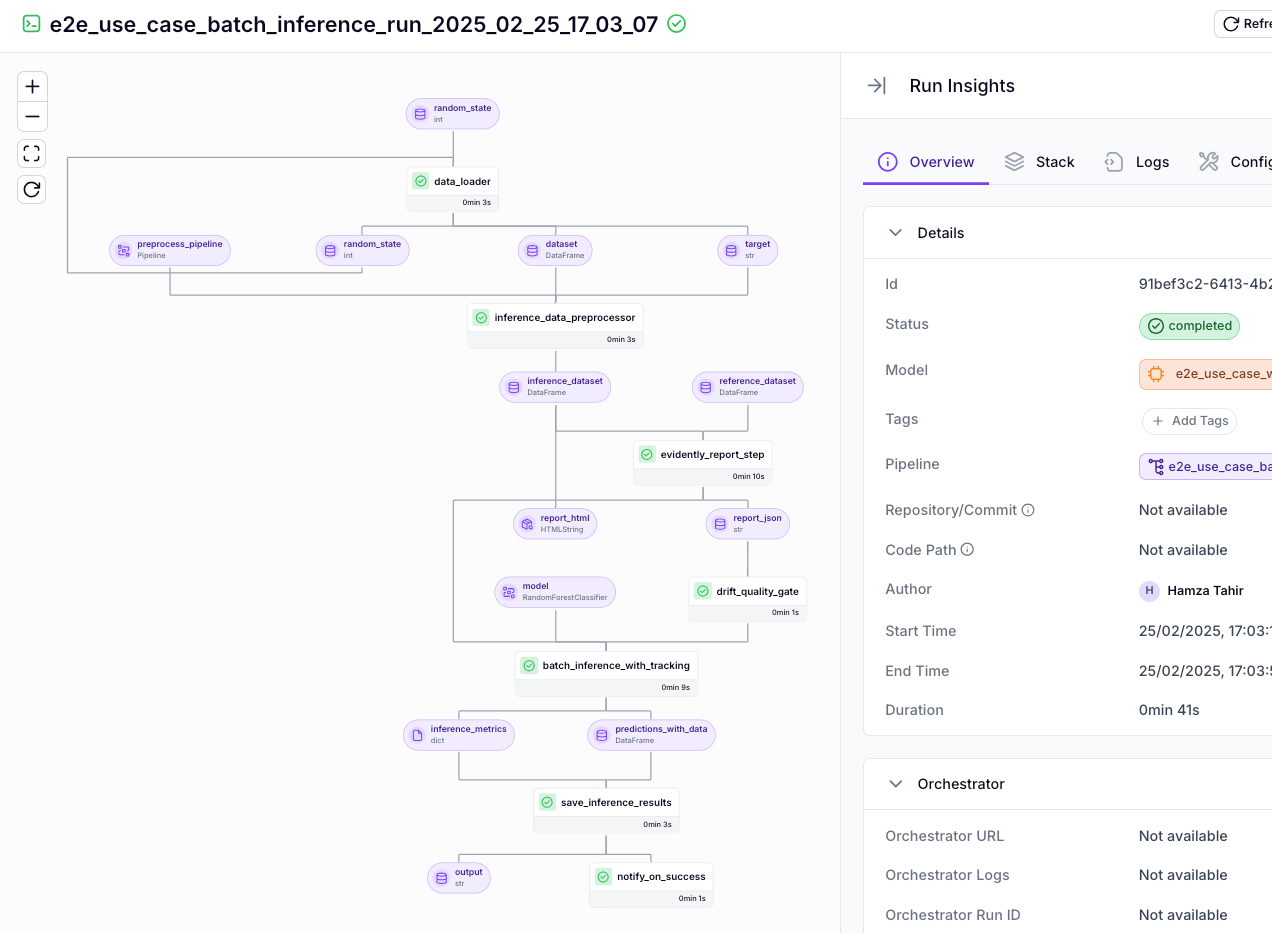
ZenML also provides a Pipeline Run History view in the dashboard. There, you can view all runs of a given pipeline, compare configurations, and filter by outcome or tags.
One of ZenML’s strongest UI features is Artifact Visualization. The dashboard has built-in support to visualize common artifact types automatically.
In addition to artifacts, ZenML’s UI displays logs for each step, allowing you to view the stdout/stderr of any step within the dashboard, as well as runtime metrics such as step execution time and caching information.
For teams using ZenML Pro, the dashboard offers advanced features like Experiment Comparison - select multiple runs and compare metrics side by side, and a Model Control Plane view that focuses on registered models and their deployments.
Bottom line: Metaflow is minimalistic – no always-on UI, but the Cards system provides on-demand visualization of results and debugging info.
Kubeflow offers a robust pipeline UI with DAG graphs, run management, and basic artifact viewers. It’s great for monitoring and debugging complex pipelines on Kubernetes in real-time.
ZenML provides a sleek dashboard that combines the best of both worlds: interactive pipeline graphs and detailed artifact/metadata views without requiring you to manage heavy infrastructure for the UI itself. It’s especially powerful when using ZenML’s own experiment tracking or integrations, as everything can be observed in one place.
Metaflow vs Kubeflow vs ZenML: Integration Capabilities
The ability of an MLOps platform to integrate seamlessly with existing workflows, tools, and cloud services is a critical factor in its adoption and long-term utility.
Metaflow

Metaflow integrates deeply with cloud infrastructure, reflecting its design for scalable, cloud-native ML workflows.
It was originally built with first-class support for AWS, enabling seamless execution on AWS Batch and leveraging AWS Step Functions.
Beyond AWS, Metaflow is designed to be cloud-agnostic, supporting deployment on Google Cloud (GKE + Cloud Storage) or Azure (AKS + Blob Storage) without requiring code changes.
It also allows for execution on any Kubernetes cluster or on-premises setup, providing flexibility in infrastructure choice.
On the tooling side, Metaflow provides connectors to several popular Python libraries, including TensorFlow, PyTorch, and Pandas.
This strong integration with core cloud services and common ML frameworks makes Metaflow a robust choice for teams operating within established cloud environments.
Kubeflow
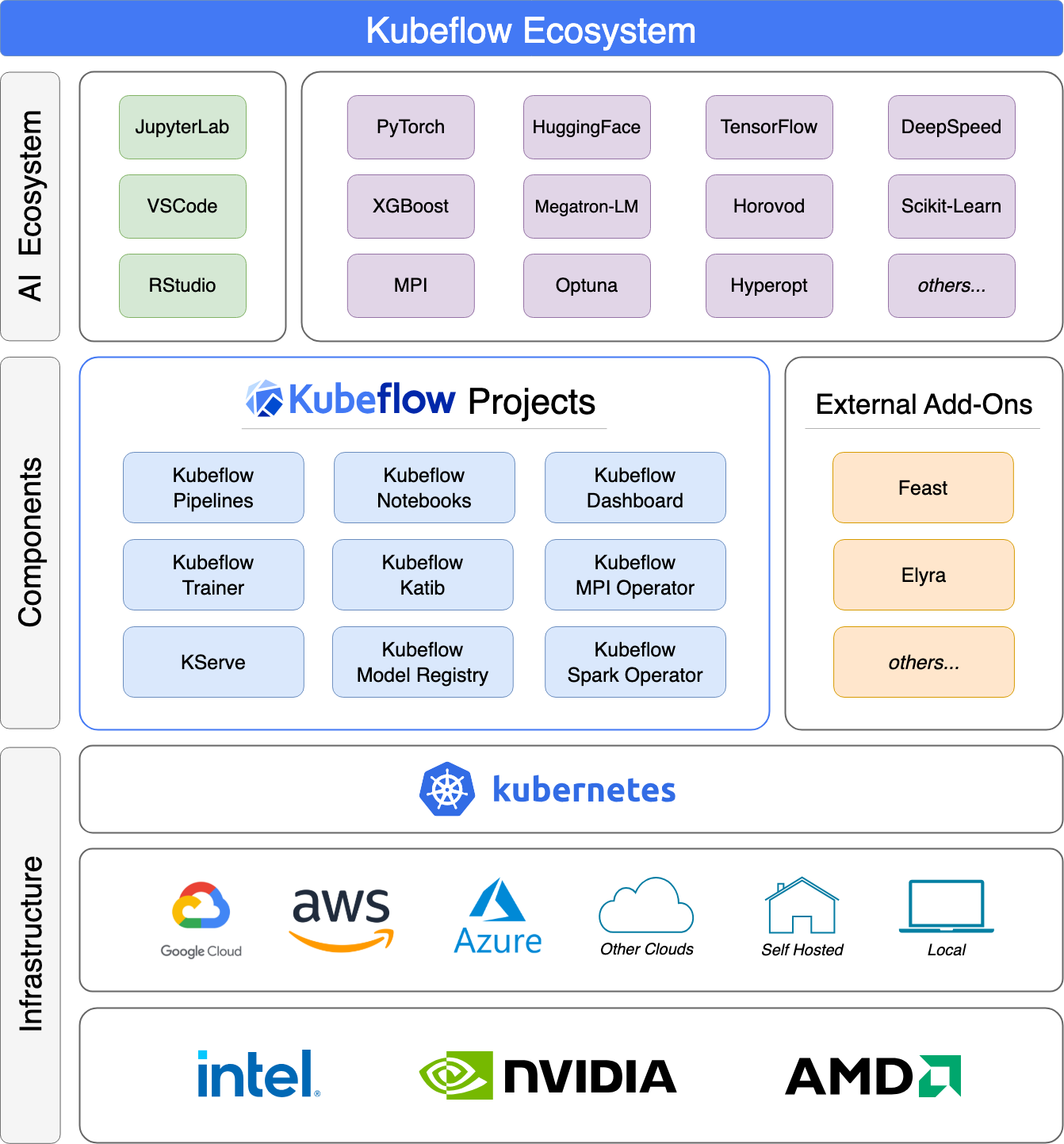
Kubeflow is a Kubernetes-native platform, so its integrations revolve around the cloud-native ecosystem. It’s essentially a collection of Kubernetes operators and components for ML.
Kubeflow Pipelines runs on Kubernetes using Argo or Tekton under the hood, meaning you’ll need a Kubernetes cluster and some DevOps proficiency.
In return, Kubeflow integrates tightly with other K8s tools for scalable ML workflows.
For example, it provides custom CRDs for distributed training: TFJob for TensorFlow and PyTorchJob for PyTorch, allowing you to run multi-worker training on a cluster.
ZenML
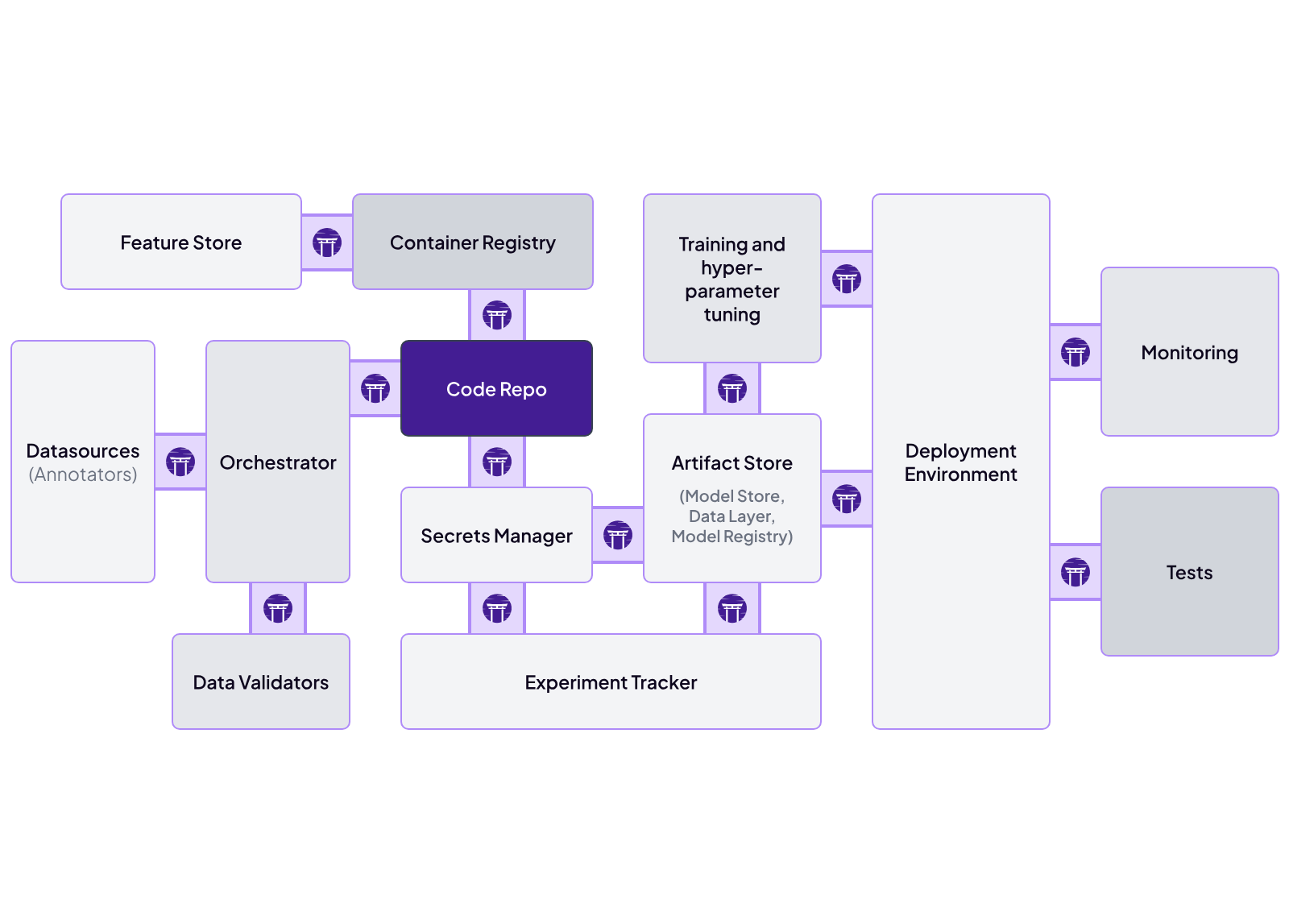
ZenML is fundamentally designed to be an integration-friendly MLOps framework. Its architecture is built around a pluggable ‘stack’ concept, where each part of the ML pipeline is an interchangeable component with multiple available flavors.
ZenML acts as a glue layer – it doesn’t reinvent the wheel for every MLOps feature but instead integrates with best-of-breed tools. You write your pipeline in ZenML using simple Python decorators, and you can execute it on various backends or with various plugins without changing your code.
ZenML can thus sit on top of existing infrastructure and tools, orchestrating across them.
Here are the tools ZenML integrates with across MLOPs:
- Artifact store: Amazon S3, Azure Blob Storage, Google Cloud Storage
- Cloud infrastructure: AWS, Google Cloud, Microsoft Azure
- Container registry: Azure, Elastic, GitHub
- Data validator: Deepchecks, Evidently, WhyLabs whylogs
- Experiment tracker: Comet, MLflow, Neptune
And many more.

Metaflow vs Kubeflow vs ZenML: Pricing
All three platforms are open source and free to use in their basic form. The total cost of adopting them, however, involves infrastructure and any managed services or enterprise add-ons you might choose.
Metaflow
Open Source: Metaflow’s core framework is completely free (Apache 2.0 license). You can install Metaflow and run it on your own infrastructure at no cost besides the cloud resources it consumes.
But the platform also has managed services.
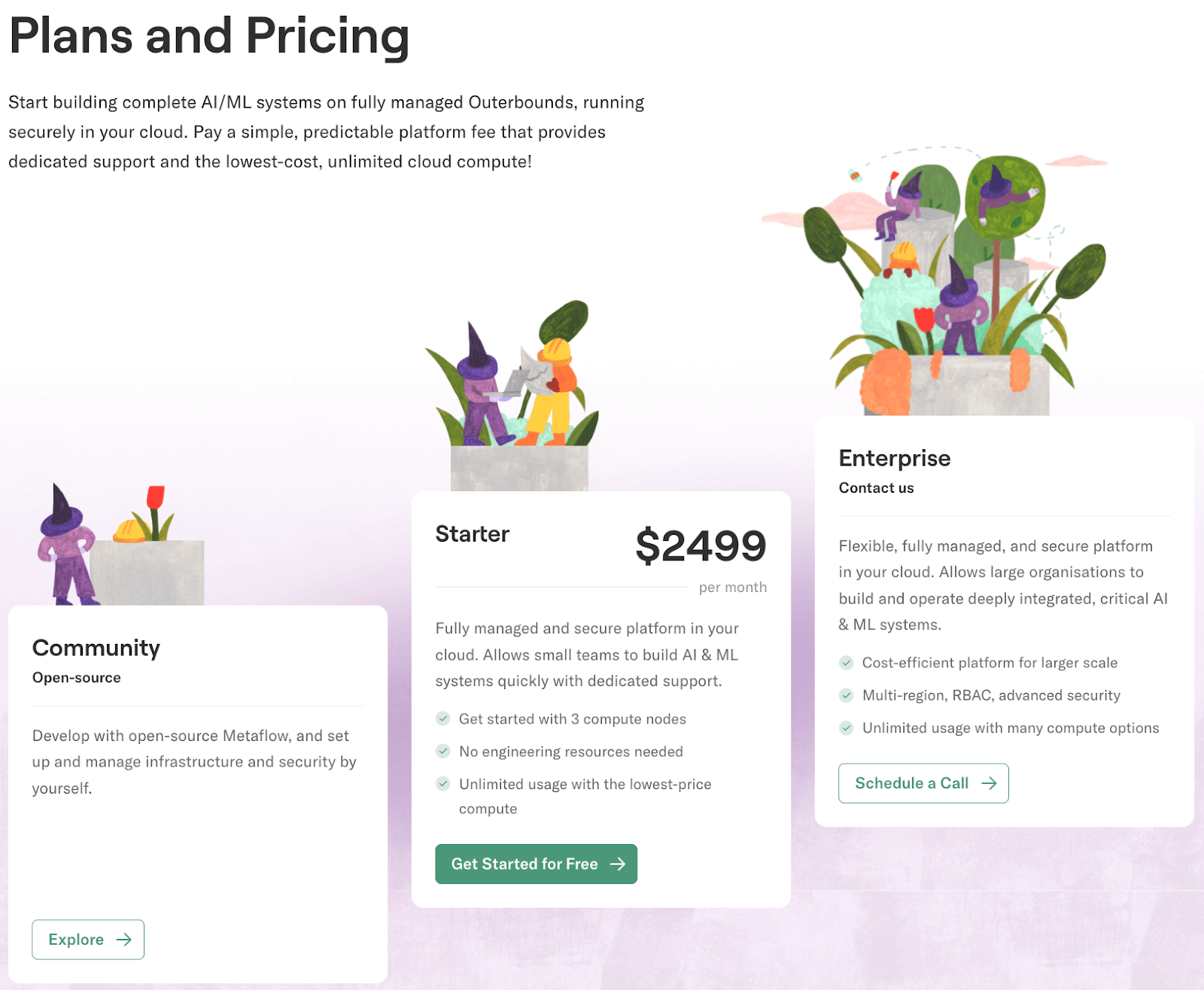
Managed Enterprise: The primary managed offering for Metaflow is provided by Outerbounds, the company founded by Metaflow’s creators. Outerbounds offers a hosted Metaflow service with additional features and support. The Starter plan is priced at $2,499 per month.
There is also an Enterprise plan with custom pricing for larger-scale deployments or advanced needs.
Additionally, Outerbounds can be purchased and deployed via major cloud marketplaces, including AWS, Google Cloud, and Azure - around $60k per year via AWS Marketplace, plus usage fees.
You can read more about Outerbound pricing in this guide: Outerbound Pricing Guide.
Kubeflow
Open Source: Kubeflow is an open-source project freely available to deploy on any Kubernetes cluster. There are no licensing fees – if you have a K8s cluster, you can install Kubeflow yourself.
The cost considerations for open-source Kubeflow are primarily infrastructure and maintenance. You’ll need to run and pay for the underlying Kubernetes nodes - VMs, storage, etc., which can be significant for large pipeline workloads or long-running services.
Managed Options:
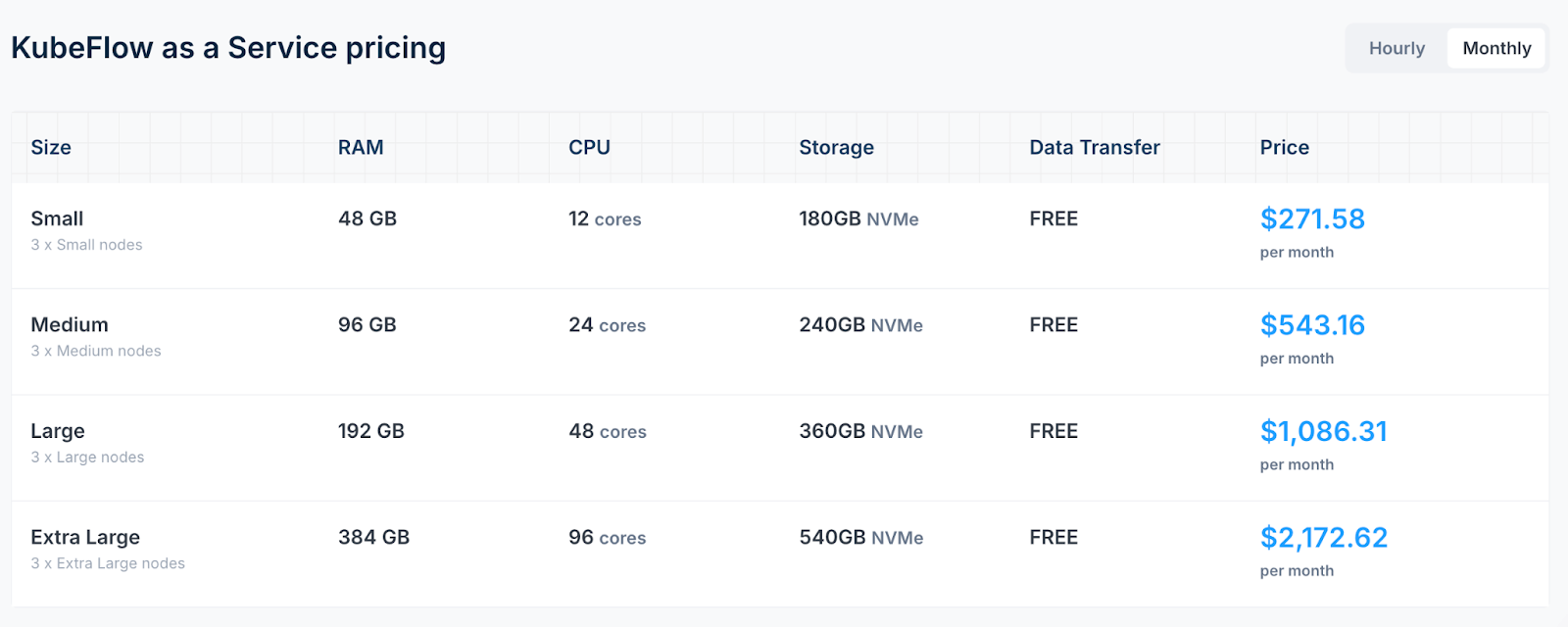
- Civo Kubeflow as a Service: Starts at $271.58 per month, providing a fully managed ML development environment with auto-scaling capabilities.
- Arrikto Kubeflow as a Service: Pricing begins at $2.06 per hour for active deployments and $0.20/hour when idle, offering a 7-day free trial.
- Canonical's Managed Kubeflow: Offers tailored solutions with a 99.9% uptime SLA, with pricing details available upon request.
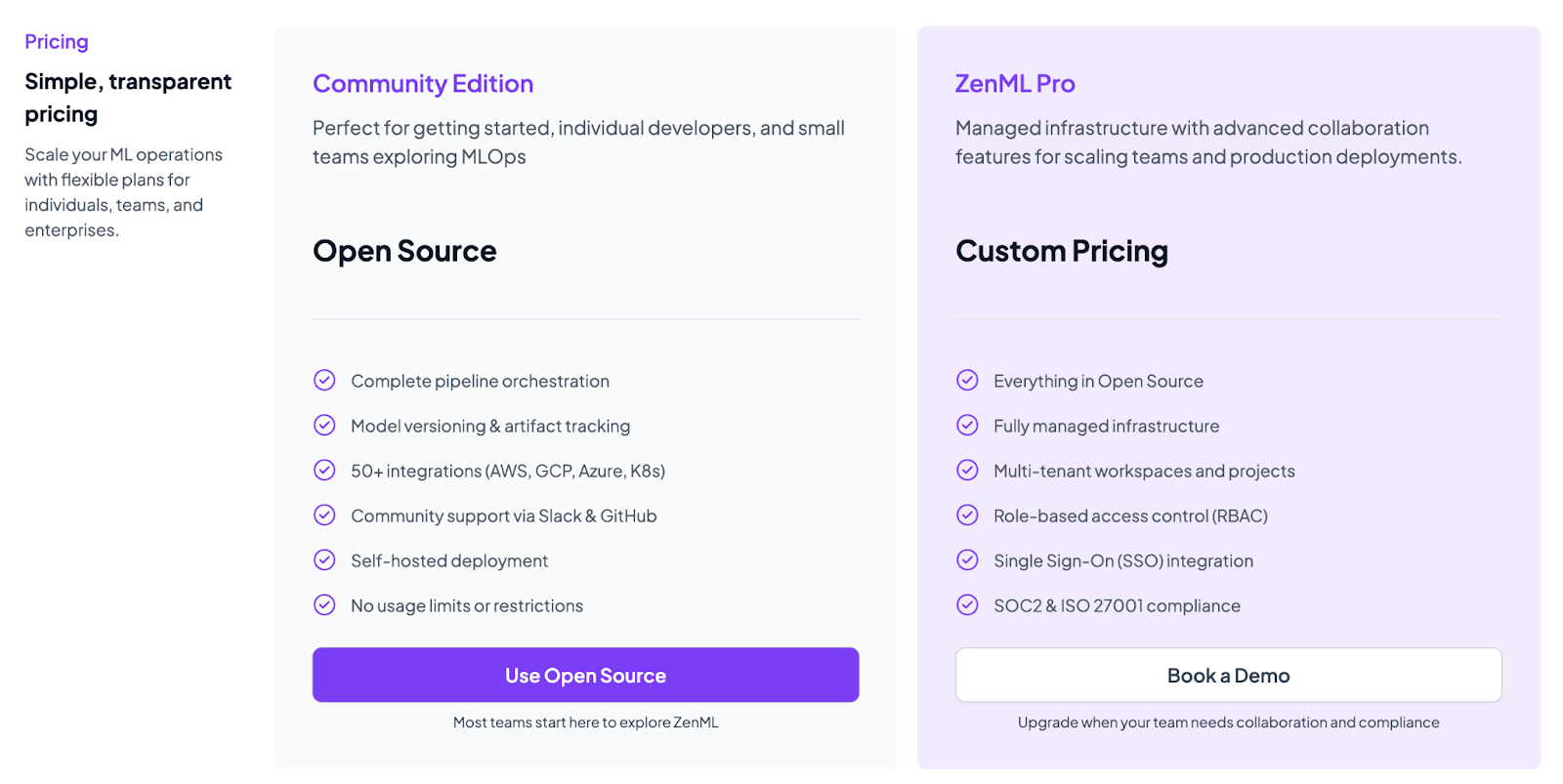
ZenML
ZenML’s pricing is pretty straightforward. We offer an open-source plan (community edition) available under an Apache 2.0 license. Anyone can pip-install ZenML and start building pipelines without paying for licenses.
We also offer ZenML Pro, which is a managed infrastructure with advanced collaboration features for scaling teams and production deployments. You can book a demo with us to learn more about the pricing.
Which ML Pipeline Tool Is Right for You?
Each of these pipeline tools has advantages in different scenarios, and your choice will depend on your team’s priorities across dimensions like integration needs, infrastructure preferences, and budget. Here’s a recap to help you decide:
- Choose Metaflow if you value a straightforward, code-centric approach to building pipelines and you’re operating in a cloud environment (especially AWS).
- Choose Kubeflow if your organization is deeply invested in Kubernetes and you need an end-to-end, cloud-native ML platform.
- Choose ZenML if you need a balanced and flexible solution that bridges experimentation and production with minimal friction.
ZenML is perfect for teams that want to start simple but maintain a path to scale out and integrate with many tools as their needs grow. Want to give ZenML a try? Sign up for our open-source plan, use it, and see if it meets all your needs.
When the time is right, book a demo call with us to learn how we can create a tailored plan for all your ML workflows.
📚 More comparison blogs worth reading: