On this page
Last updated: October 17, 2022.
ZenML is constantly extending its coverage to cover more and more areas of what is slowly but surely becoming the standard set of best practices and tooling that a mature MLOps framework has to provide, as detailed in a previous post. It should therefore come as no surprise that the ZenML team views data validation as a vital area of concern for MLOps, especially given the data-centric nature of ML development.
Great Expectations is the first ZenML Data Validator, a new category of libraries and frameworks that the 0.10.0 ZenML release adds to the ZenML ecosystem of integrations. Data Validators are MLOps tool stack components that allow you to define high data quality standards and practices and to apply them throughout the entire lifecycle of a ML project.
Some Introductory Terminology
Before we begin exploring the range of Great Expectations features and how they fit like puzzle pieces into the ZenML MLOps ecosystem, we should get some Great Expectations terminology out of the way. Feel free to skip ahead, if these terms are already familiar to you:
- Expectations can be thought of as declarative data validation rules. They are the core concept of the Great Expectations framework.
- Expectation Suites are collections of Expectations.
- A Validation Result is an object generated when data is validated against an Expectation or Expectation Suite.
- Data Docs are human readable documentation generated by Great Expectations detailing Expectations, Validation Results and other metadata information.
- The Data Context is the primary API entry point for Great Expectations. It wraps the Great Expectations deployment configuration and provides methods to manage all supporting components.
- Data Sources and Batch Requests are standard APIs used to access and interact with data.
Why Great Expectations?
Our decision was not random nor incidental. We chose Great Expectations to be the baseline for our ZenML Data Validator concept not just because it is a popular, best-in-class data quality framework (though for those it scored high on our criteria list), but also because we share a similar vision about the role of data validation in MLOps. On top of that, they are a natural fit from an engineering perspective, which made designing and implementing the Great Expectations ZenML integration a pleasurable experience.
Convinced already? If yes, you should fast-forward to the next section to dive into the integration itself or skip straight to the hands-on area to look at some code examples. Otherwise, keep reading below to get more insight into what makes Great Expectations and ZenML a great pair.
The Golden Path
ZenML and Great Expectations have compatible visions regarding the role of data validation and documentation in MLOps, the user experience and the general workflow of continuously validating the data that is circulated through ML pipelines. This is elegantly referred to as “the golden path” in a Great Expectations blog post entitled How does Great Expectations fit into MLOps.
Reproducible Data Validation
The reproducible nature of ZenML pipelines achieved through artifact versioning and metadata tracking is perfectly aligned with Great Expectations’ concept of Data Docs, a human readable view into the overall data quality state of a project. When combined, they can provide a complete historical record of the data used in a ML project and its quality characteristics at various points in time, making it extremely useful for the visibility and explainability of a project.
Keep Humans in the Loop
Not everything in MLOps can be automated, nor should it. ZenML features such as Experiment Trackers, Alerters, artifact Visualizers and the post-execution workflow features are designed with this very principle in mind. They give users an easily comprehensible view into the otherwise complex structure of the information collected and stored throughout the lifecycle of a ML project.
The Great Expectations “tests are docs and docs are tests” principle fits perfectly into that story and the rendered Data Docs are a great way of facilitating collaboration and interaction between the various roles that are part of the ML team.
Combined Extensibility
Great Expectation is a highly extensible framework. More than just another similarity between the ZenML and Great Expectations framework goals, this was vital to implementing a clean and elegant integration between the two frameworks and guarantees a maintainable relationship in the future.
Integration Tactics - How Did We Do It?
The ZenML integration leverages a few surprising similarities in how both Great Expectations and ZenML handle configuration and data to make data validation a continuous operation that is automated and tracked through ML pipelines.
🤯 The ZenML Artifact Store is a Great Expectations Store
The information managed by Great Expectations such as Expectation Suites, Validation Results and Data Docs need to be stored in some form of persistent storage. This can be your local filesystem or a cloud object storage service such as AWS S3, GCS or Azure Blob Storage. Great Expectations includes support for all of these types of object storage.
Perhaps the most rewarding aspect of the ZenML integration is how we coupled the Great Expectations Store and the ZenML Artifact Store concepts. When registered as a ZenML Data Validator stack component, Great Expectations is by default configured to store Expectation Suites, Validation Results, Data Docs and other artifacts in the ZenML Artifact Store:****
zenml integration install great_expectations
zenml data-validator register great_expectations --flavor=great_expectations
zenml stack register ge_stack -m default -o default -a default -dv great_expectations --setTo use this feature with your existing Great Expectations code, you only need to use the Data Context managed by ZenML instead of the default one provided by Great Expectations:
import great_expectations as ge
from zenml.integrations.great_expectations.data_validators import (
GreatExpectationsDataValidator
)
context = GreatExpectationsDataValidator.get_data_context()
# instead of:
# context = ge.get_context()
context.add_data_source(...)
context.add_checkpoint(...)
context.run_checkpoint(...)
context.build_data_docs(...)
...This has added advantages:
- all the artifacts produced by your project will be stored in the same place: Great Expectations artifacts and ZenML pipeline artifacts.
- you don’t need to worry about manually adjusting the Great Expectations deployment configuration if you don’t want to. It’s all done automatically for you. Of course, the ZenML integration gives you plenty of options, should you choose to migrate your existing Great Expectations configuration to ZenML, or to customize your configuration.
- Great Expectations transparently works with any and all present and future types of ZenML Artifact Store: local filesystem, AWS S3, GCS, Azure Blob Storage as well as any custom Artifact Store implementation.
- ZenML users can manage multiple Great Expectation deployment configurations and switch between them as easily as switching ZenML Stacks.
The example featured later in this article shows how straightforward it is to configure and switch between two different Great Expectations ZenML deployment scenarios, one using the local filesystem, the other using AWS S3.
The extensibility of Great Expectations was key to implementing this integration feature. ZenML extends the TupleStoreBackend base class and implements a new flavor of Great Expectations Store that redirects all calls to the Artifact Store API. In fact, storing Great Expectations metadata in the active ZenML Artifact Store can be done even without the ZenML Data Validator, by simply using the ZenML store backend in your Great Expectations configuration, e.g.:
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
module_name: zenml.integrations.great_expectations.ge_store_backend
class_name: ZenMLArtifactStoreBackend
prefix: great_expectations/expectations
validations_store:
class_name: ValidationsStore
store_backend:
module_name: zenml.integrations.great_expectations.ge_store_backend
class_name: ZenMLArtifactStoreBackend
prefix: great_expectations/validations
...Expectation Suites and Validation Results as Pipeline Artifacts
One of the key ZenML features is the ability to automatically version and store all the artifacts generated from its pipeline steps. This maintains a clear historical record of operations that facilitates model and data tracking and lineage.
We recognized the need to add Expectation Suites and Validation Results to this historical record as artifacts involved in the pipeline execution. As a result, the integration also includes ZenML Materializers(mechanisms for serializing and storing artifacts in persistent storage) for these data types, allowing ZenML users to use Expectation Suites and Validation Results as return values in their pipeline steps, as exemplified below:
import pandas as pd
from great_expectations.checkpoint.types.checkpoint_result import (
CheckpointResult,
)
from zenml.integrations.great_expectations.data_validators import (
GreatExpectationsDataValidator
)
from zenml.steps import BaseStepConfig, step
class DataValidatorConfig(BaseStepConfig):
expectation_suite_name: str
def data_validator(
dataset: pd.DataFrame,
config: DataValidatorConfig,
) -> CheckpointResult:
"""Example Great Expectations data validation step.
Args:
dataset: The dataset to run the expectation suite on.
config: The configuration for the step.
Returns:
The Great Expectations validation (checkpoint) result.
"""
context = GreatExpectationsDataValidator.get_data_context()
results = run_a_checkpoint_validation_check_on_runtime_data(
dataset = dataset,
expectation_suite_name=config.expectation_suite_name,
)
return resultsIt was relatively easy to serialize/deserialize Expectation Suites and Validation Results, given that the Great Expectations library is already well equipped to handle these operations for most of its objects. This is another testament to how flexible the Great Expectations library really is.
ZenML Visualizer for Great Expectations Data Docs
Another useful ZenML feature is the ability to visualize pipeline artifacts, either in a notebook environment or by opening generated HTML content in a browser.
The Great Expectations Data Docs concept fits perfectly with the ZenML Visualizer mechanism. A Great Expectations ZenML Visualizer is included in the integration to provide easy access to the Data Docs API, as showcased in the example included in this article.
Standard Great Expectations Data Profiling and Data Validation Pipeline Steps
Finally, it is customary to include some builtin pipeline steps with every ZenML integration, if possible. Great Expectations is no exception, as we included two standard steps that can be quickly plugged into any pipeline to perform the following operations powered by Great Expectations:
- data profiling - generating and returning an Expectation Suite from an input dataset.
- data validation - validating a dataset against an existing Expectation Suite and returning the results.
The builtin steps automatically configure temporary data sources and batch requests therefore simplifying the process of configuring Great Expectations even further.
👀 Time to Show You An Example Already!
If you reached this section, you’re probably eager to look at some code to get a feel of the Great Expectations ZenML integration. You are in the right place.
The example featured here consists of two stages. The first stage describes how to install ZenML and set up two different ZenML stack configurations, one local, the other using a cloud Artifact Store to store both Great Expectations and ZenML pipeline artifacts. The second stage defines a ZenML data validation pipeline with Great Expectations and shows how to run it on top of those stacks with similar results.
A similar, up-to-date version of this example can be accessed in the ZenML GitHub repository.
Setup ZenML
You can run the following to install ZenML on your machine (e.g. in a Python virtual environment) as well as the Great Expectations and scikit-learn integrations used in the example:
pip install zenml
zenml integration install great_expectations sklearn -yThe next subsections show how to configure two different ZenML Stacks, both featuring Great Expectations as a Data Validator, but with different Artifact Stores:
- a local artifact store that uses the local filesystem as a backend
- a cloud artifact store that uses a managed object storage service (AWS S3) as a backend.
The relevance of using two different stacks will become more obvious in the next stage. ZenML pipelines are portable, allowing the same pipeline to be executed on different stacks with literally no code changes required and this now also includes Great Expectations powered pipelines.
The Local Stack
The local ZenML stack leverages the compute and storage resources on your local machine. To register and activate a stack that includes a Great Expectations Data Validator and a local Artifact Store, run the following:
zenml data-validator register great_expectations_local \
--flavor=great_expectations
zenml stack register local_stack \
-m default \
-o default \
-a default \
-dv great_expectations_localWhen this stack is active, Great Expectations will use the local filesystem to store metadata information such as Expectation Suites, Validation Results and Data Docs.
The Cloud Storage Stack
This is a ZenML stack that includes an Artifact Store connected to a cloud object storage. This example uses AWS as a backend, but the ZenML documentation has similar instructions on how to configure a GCP or Azure Blob Storage powered Artifact Store.
For this stack, you will need an S3 bucket where our ML artifacts can later be stored. You can do so by following this AWS tutorial.
The path for your bucket should be in this format: s3://your-bucket.
To register a stack that includes a Great Expectations Data Validator and an AWS S3 Artifact Store, run the following:
zenml integration install s3 -y
zenml artifact-store register s3_store \
--flavor=s3 \
--path=s3://your-bucket
zenml data-validator register great_expectations_s3 \
--flavor=great_expectations
zenml stack register s3_stack \
-m default \
-o default \
-a s3_store \
-dv great_expectations_s3When this stack is active, Great Expectations will use the same storage backend as the Artifact Store (i.e. AWS S3) to store metadata information such as Expectation Suites, Validation Results and Data Docs. A local version of the Data Docs will also be rendered, to allow them to be visualized locally.
Run a ZenML Data Validation Pipeline
Now let’s see the Great Expectations Data Validator in action with a simple data validation pipeline example.
The following code defines two different pipelines, a profiling_pipeline that infers an Expectation Suite from a reference dataset and a validation_pipeline that uses the generated Expectation Suite to validate a second dataset. The generated Expectation Suite and the Validation Results returned from the validation pipeline are then both visualized:****
import pandas as pd
from sklearn import datasets
from zenml.integrations.constants import GREAT_EXPECTATIONS, SKLEARN
from zenml.integrations.great_expectations.steps import (
GreatExpectationsProfilerConfig,
GreatExpectationsProfilerStep,
GreatExpectationsValidatorConfig,
GreatExpectationsValidatorStep,
)
from zenml.integrations.great_expectations.visualizers import (
GreatExpectationsVisualizer,
)
from zenml.pipelines import pipeline
from zenml.repository import Repository
from zenml.steps import BaseStepConfig, Output, step
class DataLoaderConfig(BaseStepConfig):
reference_data: bool = True
@step
def importer(
config: DataLoaderConfig,
) -> Output(dataset=pd.DataFrame, condition=bool):
"""Load the breast cancer dataset.
This step is used to simulate loading data from two different sources.
If `reference_data` is set in the step configuration, a slice of the
data is returned as a reference dataset. Otherwise, a different slice
is returned as a test dataset to be validated.
"""
breast_cancer = datasets.load_breast_cancer()
df = pd.DataFrame(
data=breast_cancer.data, columns=breast_cancer.feature_names
)
df["class"] = breast_cancer.target
if config.reference_data:
dataset = df[100:]
else:
dataset = df[:100]
return dataset, config.reference_data
# instantiate a builtin Great Expectations data profiling step
ge_profiler_config = GreatExpectationsProfilerConfig(
expectation_suite_name="breast_cancer_suite",
data_asset_name="breast_cancer_ref_df",
)
ge_profiler_step = GreatExpectationsProfilerStep(config=ge_profiler_config)
# instantiate a builtin Great Expectations data validation step
ge_validator_config = GreatExpectationsValidatorConfig(
expectation_suite_name="breast_cancer_suite",
data_asset_name="breast_cancer_test_df",
)
ge_validator_step = GreatExpectationsValidatorStep(config=ge_validator_config)
@pipeline(
enable_cache=False, required_integrations=[SKLEARN, GREAT_EXPECTATIONS]
)
def profiling_pipeline(
importer, profiler
):
"""Data profiling pipeline for Great Expectations.
The pipeline imports a reference dataset from a source then uses the builtin
Great Expectations profiler step to generate an expectation suite (i.e.
validation rules) inferred from the schema and statistical properties of the
reference dataset.
Args:
importer: reference data importer step
profiler: data profiler step
"""
dataset, _ = importer()
profiler(dataset)
@pipeline(
enable_cache=False, required_integrations=[SKLEARN, GREAT_EXPECTATIONS]
)
def validation_pipeline(
importer, validator,
):
"""Data validation pipeline for Great Expectations.
The pipeline imports a test data from a source, then uses the builtin
Great Expectations data validation step to validate the dataset against
the expectation suite generated in the profiling pipeline.
Args:
importer: test data importer step
validator: dataset validation step
"""
dataset, condition = importer()
validator(dataset, condition)
def visualize_results(pipeline_name: str, step_name: str) -> None:
repo = Repository()
pipeline = repo.get_pipeline(pipeline_name)
last_run = pipeline.runs[-1]
step = last_run.get_step(name=step_name)
GreatExpectationsVisualizer().visualize(step)
if __name__ == "__main__":
profiling_pipeline(
importer=importer(config=DataLoaderConfig(reference_data=True)),
profiler=ge_profiler_step,
).run()
validation_pipeline(
importer=importer(config=DataLoaderConfig(reference_data=False)),
validator=ge_validator_step,
).run()
visualize_results("profiling_pipeline", "profiler")
visualize_results("validation_pipeline", "validator")In order to run this code, simply copy it into a file called run.py and run it with:
zenml stack set s3_stack
python run.pyYou can switch to the cloud storage stack and run the same code with no code changes. The difference is that the Great Expectation Data Context is now configured to store its state in the cloud:
zenml stack set s3_stack
python run.pyRegardless of which stack you are using to run the pipelines, you should see the ZenML visualizer kicking in and opening two Data Docs tabs in your browser, one pointing to the Expectation Suite generated in the profiling pipeline run, the other pointing to the validation results from the data validation pipeline run.
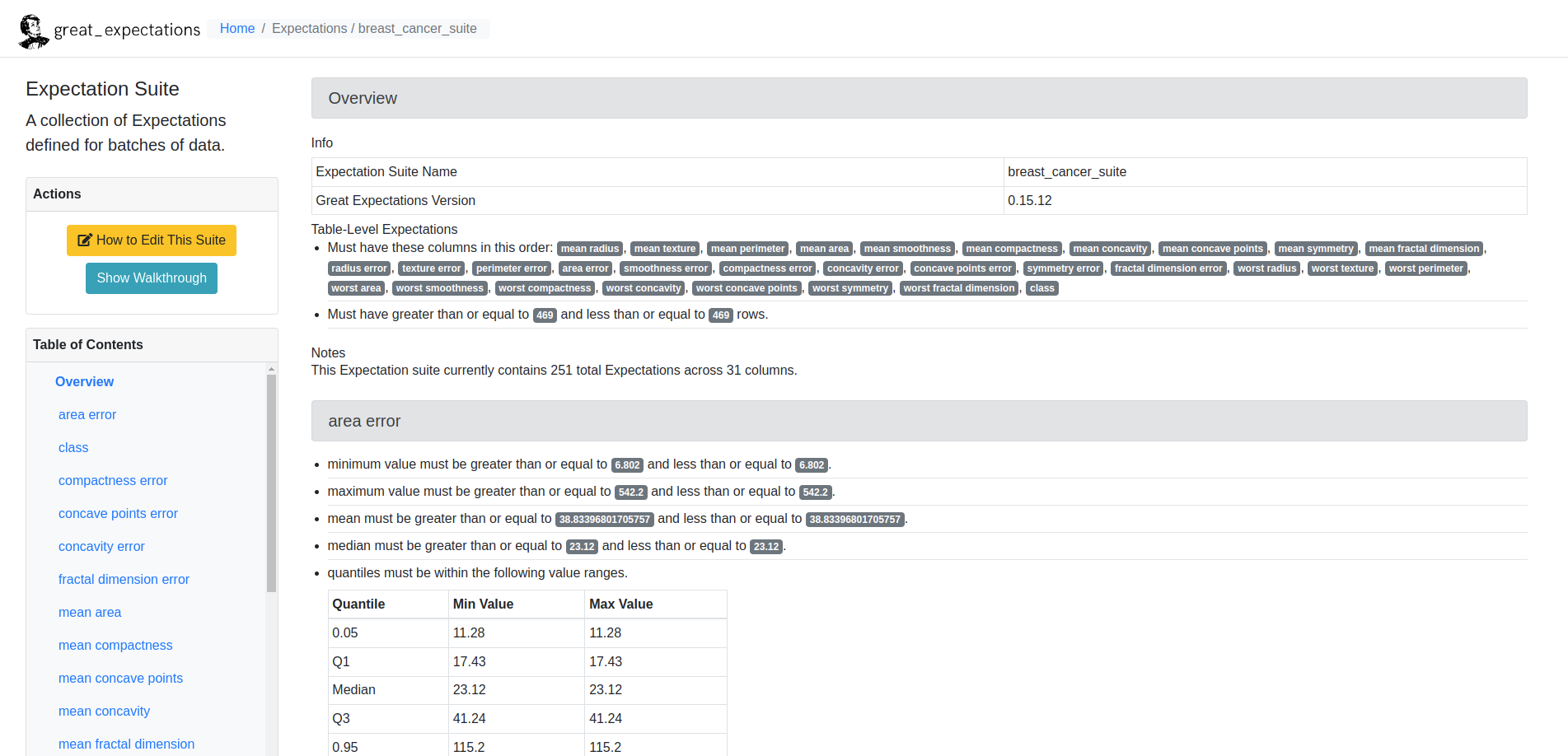
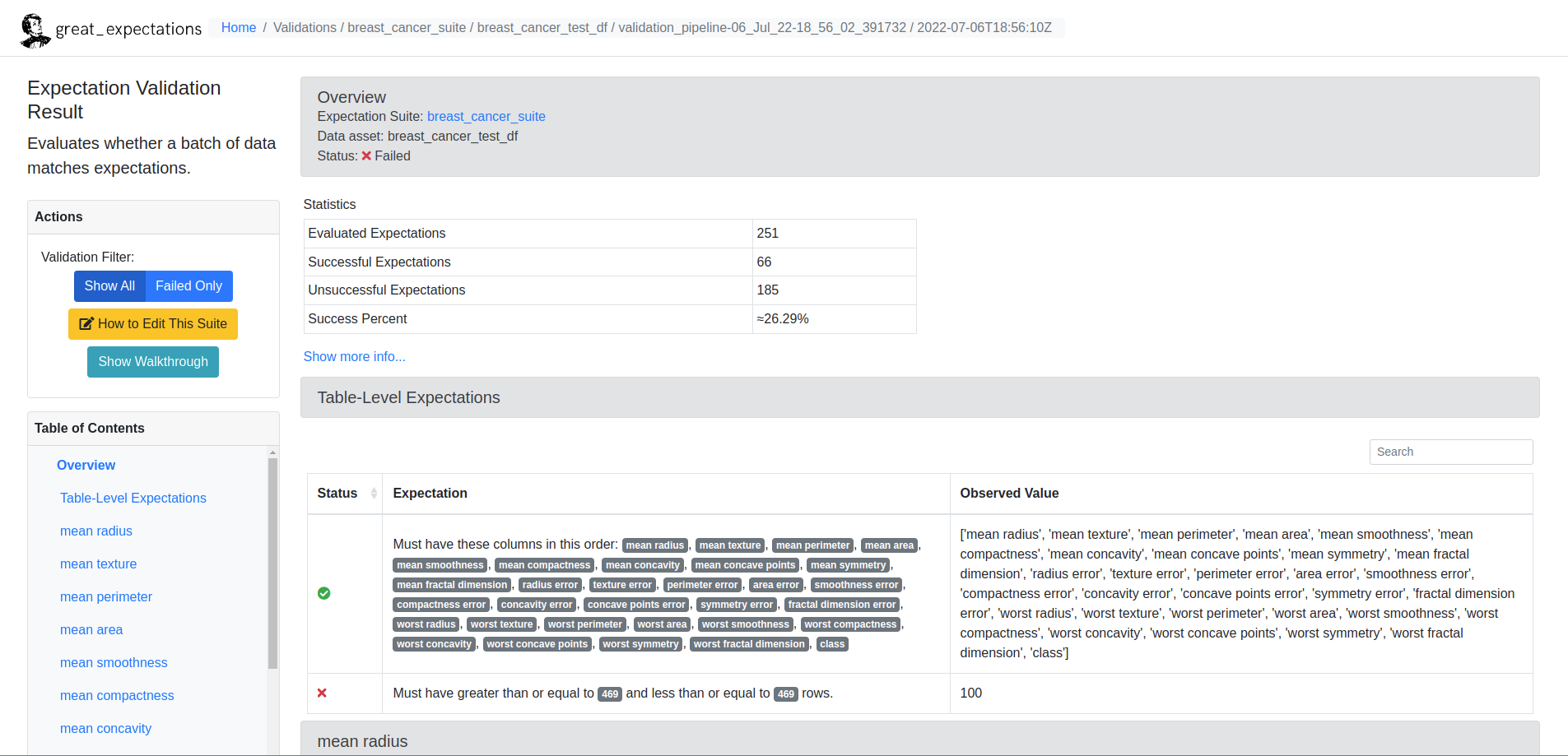
What Happened Here?
If you successfully installed ZenML and ran the example, you probably noticed that the Great Expectations validation result rendered in the Data Docs shows that the data validation has failed. This is to be expected with Expectation Suites automatically inferred from datasets, because these Expectations are intentionally over-fitted to the data in question.
The correct way to do this would probably be to run the profiling pipeline, then manually adjust the generated Expectation Suite, and then to run the validation pipeline as a final step. This re-validates the argument that data quality cannot be fully automated and there needs to be a high level of awareness and responsibility from ML project members regarding the characteristics of the data used by the project.
It’s a Wrap!
The Great Expectations ZenML integration makes it a breeze to enhance your ML pipelines with data validation logic and gives you direct and easy access to all of the well-designed benefits that come with the Great Expectations library, such as inferring validation rules from datasets and auto-generated Data Docs. Employing data validation early in your ML workflows helps to keep your project on track and to identify and even prevent problems before they negatively impact the performance of the models running in production.
🔥 Do you use data validation tools with your ML pipelines, or do you want to add one to your MLOps stack? At ZenML, we are looking for design partnerships and collaboration to develop the integrations and workflows around using data validation within the MLOps lifecycle. If you have a use case which requires data validation in your pipelines, please let us know what you’re building. Your feedback will help set the stage for the next generation of MLOps standards and best practices. The easiest way to contact us is via our Slack community which you can join here.
If you have any questions or feedback regarding the Great Expectations integration or the tutorial featured in this article, we encourage you to join our weekly community hour.
If you want to know more about ZenML or see more examples, check out our docs and examples.
Last updated: October 17, 2022.ZenML is constantly extending its coverage to cover more and more areas of what is slowly but surely becoming the standard set of best practices and tooling that a mature MLOps framework has to provide, as detailed in a previous post. It should therefore come as no surprise that the ZenML team views data validation as a vital area of concern for MLOps, especially given the data-centric nature of ML development.