

On this page
Let’s face it. Installing MCP servers and getting them to run isn’t always easy. You’re often left managing some custom Python or Node.js environment, installing packages whenever they update and updating the server itself manually whenever you notice that a new release is out.
You also have to manually edit the ~/.claude/claude_desktop_config.json file (or perhaps a custom version of that file that lives in a bespoke directory closer to your project). We’re probably optimistically talking 10-15 minutes of setup even before you make your first query.
Luckily, now we have DXT. DXT (‘desktop extension’) files are zip files containing the code and libraries needed to run an MCP server, plus metadata containing version information and tool descriptions and so on. This standard and the capabilities to use DXT files were released by Anthropic last week and already Cursor, IntelliJ AI Assistant, and VS Code Chat are all reported to be working on DXT loaders.
Here’s how easy it is to install the ZenML MCP Server in Claude Desktop with our DXT file:
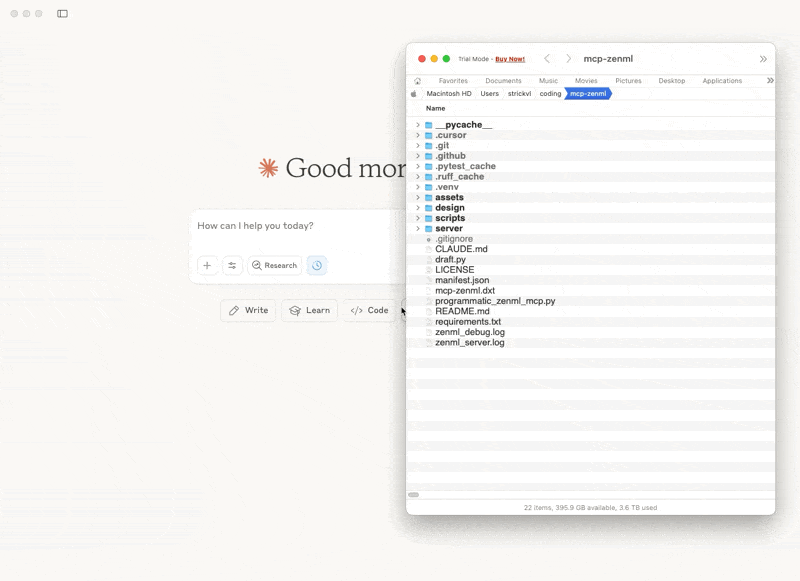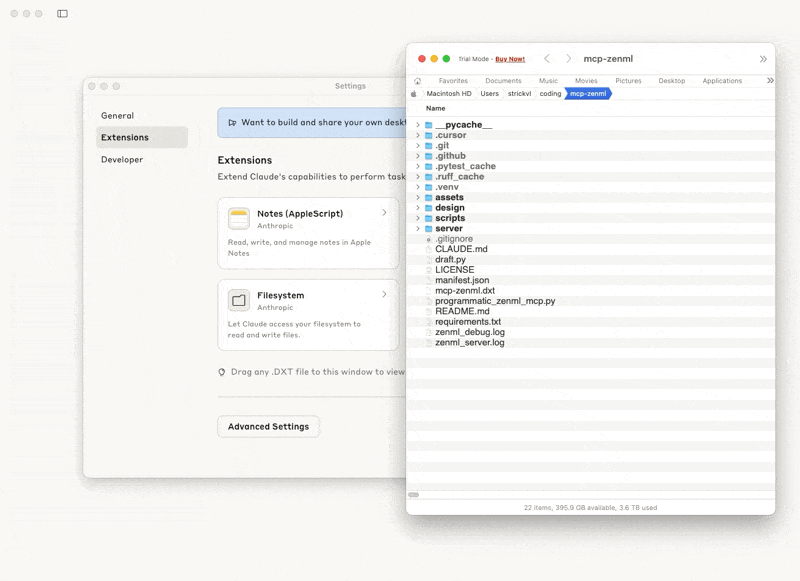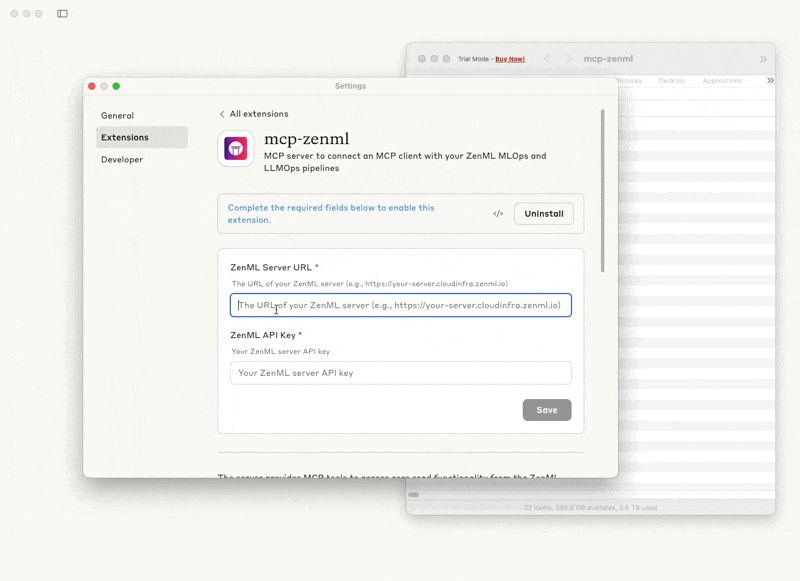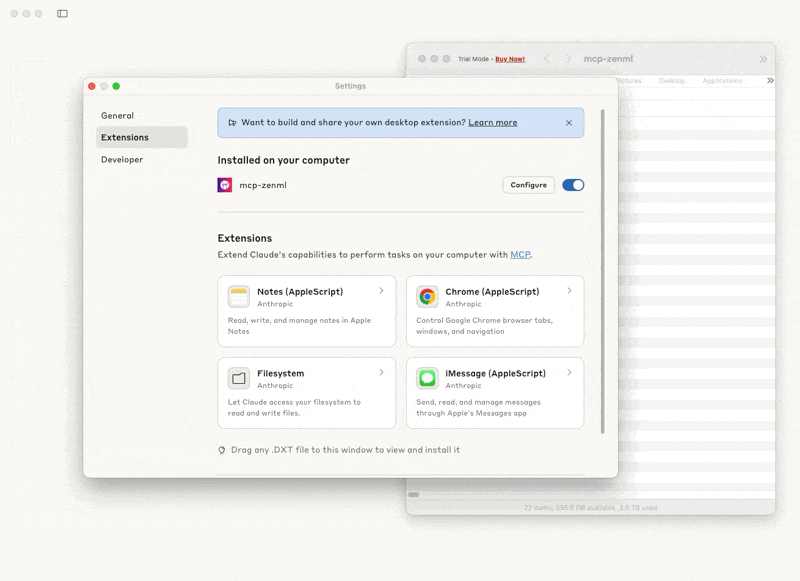
You download the DXT file, you drag and drop it onto the ‘Settings’ pane, click ‘Install’ and it’s then clear which extra values you need to provide to get it up and running. From download to first query we’re now talking something like 30 seconds instead of 15 minutes.
Why This Matters: MLOps Teams Need Better Discovery
You might be asking why we’re even talking about MCP servers at ZenML. “Aren’t MCP servers for agents to use for their tool calls? What has this got to do with ZenML?”
Think of your typical ML team’s workflow like an archaeological dig site where every experiment, pipeline run, and model training session leaves behind artifacts scattered across different tools and dashboards. Your experiment tracking lives in MLflow, your pipeline orchestration in Vertex AI (also tracked in ZenML), your model registry somewhere else, and your compute metrics in yet another system. When someone in your daily standup mentions “that new experiment showing promising results,” you’re left playing detective across multiple interfaces just to understand what they’re talking about. Instead of this archaeological expedition through disconnected tools, you can now simply ask your ZenML MCP server: “What experiments did Sarah run yesterday with the new transformer architecture?” and get an immediate, contextual answer.
The real power emerges in those everyday scenarios that eat up significant chunks of your team’s time. When yesterday’s training pipeline inexplicably took three times longer than usual, instead of manually cross-referencing logs, metrics, and resource usage across multiple dashboards, you can ask: “Why did yesterday’s training pipeline take 3x longer than usual?” When you need to make sense of a week’s worth of fine-tuning experiments, rather than exporting CSVs and building comparison charts, you simply query: “Compare the validation metrics across all BERT fine-tuning runs this week.” And for team coordination, instead of Slack messages asking “who’s been working on what,” you can discover: “Which team members have run experiments with our new dataset?” These conversational interactions transform MLOps from a treasure hunt across disparate tools into a natural dialogue with your infrastructure.
Understanding DXT: ZIP Files with Superpowers
At its core, DXT isn’t just another package format—it’s a deployment abstraction that eliminates the friction between “I want to try this MCP server” and “I’m actually using this MCP server.” While traditional MCP server installation requires juggling Node.js versions, Python virtual environments, port configurations, and manual JSON editing, DXT packages everything into a single zip file with a manifest.json that declaratively describes not just what the server does, but how it should be executed, what permissions it needs, and what configuration options should be presented to users. The manifest spec supports sophisticated features like variable substitution (${__dirname}, ${user_config.api_key}), platform-specific overrides, and explicit user configuration schemas that automatically generate UI forms—transforming the typical “edit this JSON file and figure out the right paths” experience into a guided installation flow.
The technical cherry-on-top lies in the explicit permission model and self-contained nature. Rather than MCP servers having implicit access to your entire system, DXT extensions declare exactly what they need through structured user_config fields—directory pickers for filesystem access, secure string inputs for API keys, boolean toggles for operational modes—and the manifest’s compatibility object ensures extensions only run where they’re actually supported. The format supports Python servers with bundled virtual environments, Node.js servers with complete node_modules trees, and pre-compiled binaries, all with automatic dependency resolution and no external runtime management. Updates happen transparently through manifest update URLs, and the entire package remains portable across macOS, Windows, and Linux without platform-specific installation procedures.
The ecosystem momentum is building rapidly: Cursor, IntelliJ AI Assistant, and VS Code Chat are all implementing DXT loaders, and there’s discussion about integrating DXT support directly into uv run as a built-in subcommand. This isn’t just about Claude Desktop convenience—it’s about establishing a universal standard for distributing AI tool integrations that works across the entire landscape of AI-powered development environments. The format’s simplicity (it’s just a zip file with a JSON manifest) combined with what it enables (supporting complex configuration, security boundaries, and cross-platform deployment) positions it as the natural evolution from today’s fragmented “clone this repo and run these commands” approach to something approaching the ease of browser extension installation.
Using ZenML MCP Programmatically
Our launch blog showcased a few examples of prompts and how you might use something like Claude Desktop or Cursor to help debug pipelines.
Since those early days, MCP has gone mainstream and you can now find frameworks and APIs allowing you to use it programatically with ease. The big model providers like Anthropic and OpenAI offer easy ways to connect remote MCP servers, but for local servers you can use mcp-use, for example.
Here’s a simple example getting showcasing how you might get some general improvement suggestions for a recent pipeline run:
import asyncio
import os
from langchain_openai import ChatOpenAI
from mcp_use import MCPAgent, MCPClient
from rich import print
async def main():
config = {
"mcpServers": {
"zenml": {
"command": "/usr/local/bin/uv",
"args": [
"run",
"/path/to/mcp-zenml/server/zenml_server.py",
],
"env": {
"ZENML_STORE_URL": os.getenv("ZENML_STORE_URL"),
"ZENML_STORE_API_KEY": os.getenv("ZENML_STORE_API_KEY"),
},
},
}
}
client = MCPClient.from_dict(config)
llm = ChatOpenAI(
openai_api_key=os.getenv("GROK_OPENROUTER_API_KEY"),
openai_api_base=os.getenv("OPENROUTER_BASE_URL"),
model_name="x-ai/grok-4",
)
agent = MCPAgent(llm=llm, client=client, max_steps=30)
result = await agent.run(
(
"Any problems in my recent 'distill_finetuning' pipeline runs and suggestions on "
"bigger-picture fixes we might want to make to handle them? You can check out the implementation perhaps "
"or the code or the returned artifacts (esp HTMLStrings) if anything needs more of a deep dive. i.e. please see how we're doing in our model distillation attempts"
"Please go ahead and use tools to investigate directly without asking for followup questions."
),
)
print(f"\nResult: {result}")
if __name__ == "__main__":
asyncio.run(main())I used the new Grok4 model via OpenRouter to put it through its paces.
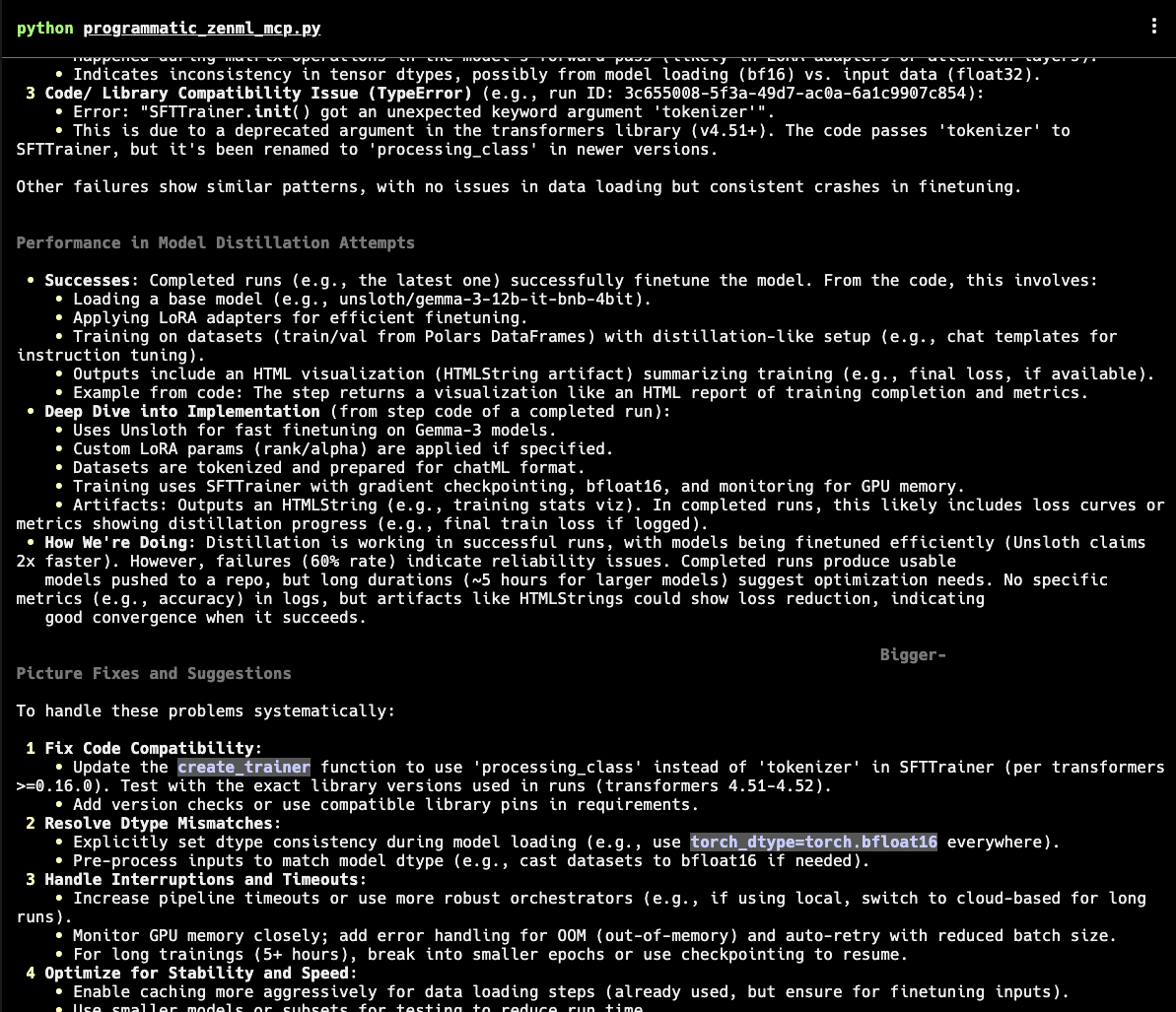
The suggestions for improvement (for a DeepSeek distillation project we’re working on) are almost all on point and include one or two points I hadn’t at all thought to consider. If you have real eagle eyes you’ll notice that the new DXT implementation isn’t used in how our MCP server gets set up with mcp-use , but that’s mainly because we’re so early in getting our implementation out. At time of writing only Cursor Desktop supports the new format, but mcp-use has an open issue and others are busy with their implementation so it’s only a matter of weeks I expect.
(If you’re really curious, you can view the full output for Grok4 and compare it to the same for OpenAI’s o3. The only thing I’d add to the outputs is that o3 was significantly faster than Grok4.)
It’s not hard to think into the future beyond this somewhat toy use case to how you might use the ZenML MCP Server to help optimise your pipelines, to alert you with suggested improvements or to debug systematic or intermittent failures.
The Tool Explosion Challenge and MCP’s Broader Success Story
MCP’s rapid adoption is creating a scale problem that wasn’t immediately obvious in early implementations. Personal development environments like Claude Desktop typically use 5-10 focused tools, but business automation agents are already pushing toward 50+ specialized tools spanning CRM systems, infrastructure monitoring, experiment tracking, and compliance reporting. This creates bigger questions about tool organization and selection that the MCP specification doesn’t address.
The core challenge is cognitive rather than technical. When an AI assistant has access to dozens of tools, how does it determine which ones to use for a given query? Current implementations rely on tool descriptions and basic heuristics, but this approach doesn’t scale well. We’re likely heading toward a stratified ecosystem where different contexts require different tool management approaches—personal productivity environments favor deep integration with few tools, while enterprise scenarios need sophisticated orchestration layers for dynamic tool selection based on context and permissions.
MCP succeeded where many previous standardization efforts failed because of three key factors. First, Anthropic released it as an open specification rather than maintaining it as a proprietary feature, creating immediate space for competitors to adopt without ceding strategic advantage. Second, the standard focused narrowly on structured communication between AI systems and external tools, leaving implementation details to individual developers. Third, it addressed a genuine pain point that every AI application developer was experiencing independently, creating natural network effects.
ZenML’s approach reflects a broader strategic bet that MLOps infrastructure’s future lies in tools that work seamlessly within existing ecosystems rather than demanding wholesale platform migrations. The companies that succeed will be those that reduce integration friction while maintaining the specialized capabilities that make their tools valuable.
Getting Started Today
For ZenML users, the fastest path to trying conversational MLOps is downloading the mcp-zenml.dxt file from the repository root. The installation process takes roughly 30 seconds: drag the file into Claude Desktop’s Settings menu, add your ZenML server URL and API key, and you’re ready to start querying your infrastructure.
Once installed, try these example queries to get familiar with the capabilities:
- "What pipeline runs failed in the last week?"
- "Show me the artifacts from my most recent training pipeline"
- "Which team members have been running experiments with the new dataset?"
- "What's the status of my current pipeline runs?"
- "Can you show me the logs from that failing step?"
For MCP server developers, our DXT implementation demonstrates how to package a Python-based MCP server with all dependencies included. The key lessons from our implementation are straightforward: follow Anthropic’s launch post instructions and design your configuration schema to minimize user input requirements while maintaining security. The DXT format itself is remarkably simple—it’s just a zip file with a manifest, but the tooling around it makes packaging and distribution significantly more accessible than traditional approaches.
For the curious, you can explore the programmatic MCP connector approach using libraries like mcp-use to integrate ZenML queries into your own applications. The server exposes all its capabilities through standard MCP tools, making it straightforward to build custom workflows on top. The repository includes comprehensive examples of both the DXT packaging process and direct MCP server usage for developers who want to understand the underlying mechanics.
The intersection of MCP and MLOps is still developing, and the patterns that emerge will depend heavily on how practitioners actually use these tools in their daily workflows. We want to hear from you about what tools would make your MLOps workflow smoother, how many tools feels manageable versus overwhelming for your use case, and what standards you’d like to see standardized next across the ecosystem.
The most valuable feedback comes from real usage scenarios—whether you’re debugging a failing pipeline through conversational queries, using MCP to generate pipeline reports, or building custom integrations on top of the ZenML server. Join the conversation in our Slack community, contribute to GitHub issues, or share your MCP + ZenML stories with the broader community.


