
Ensure Data Quality and Consistency in Your ML Pipelines with Great Expectations and ZenML
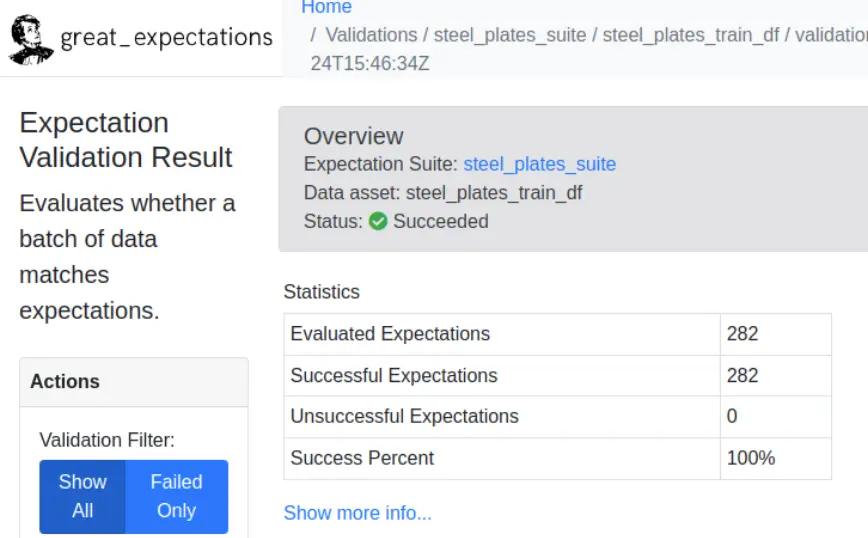
Integrate Great Expectations with ZenML to seamlessly incorporate data profiling, testing, and documentation into your ML workflows. This powerful combination allows you to maintain high data quality standards, improve communication, and enhance observability throughout your ML pipeline.
from zenml.integrations.great_expectations.steps.ge_validator import (
great_expectations_validator_step,
)
ge_validator_step = great_expectations_validator_step.with_options(
parameters={
"expectations_list": [
GreatExpectationExpectationConfig(
expectation_name="expect_column_values_to_be_between",
expectation_args={
"column": "X_Minimum",
"min_value": 0,
"max_value": 2000
},
),
],
"data_asset_name": "steel_plates_train_df",
}
)
@pipeline(enable_cache=False, settings={"docker": docker_settings})
def validation_pipeline():
imported_data = importer()
train, test = splitter(imported_data)
ge_validator_step(train)
validation_pipeline()Expand your ML pipelines with more than 50 ZenML Integrations