
Checkpoint Replay, Worker Shape, and Where Durable Execution Is Going
Armin Ronacher's Absurd and Kitaru arrived at the same answers on replay semantics, ephemeral compute, and an agent-legible runtime. Here's why that matters.

May 11, 2026
17 posts with this tag
Armin Ronacher's Absurd and Kitaru arrived at the same answers on replay semantics, ephemeral compute, and an agent-legible runtime. Here's why that matters.

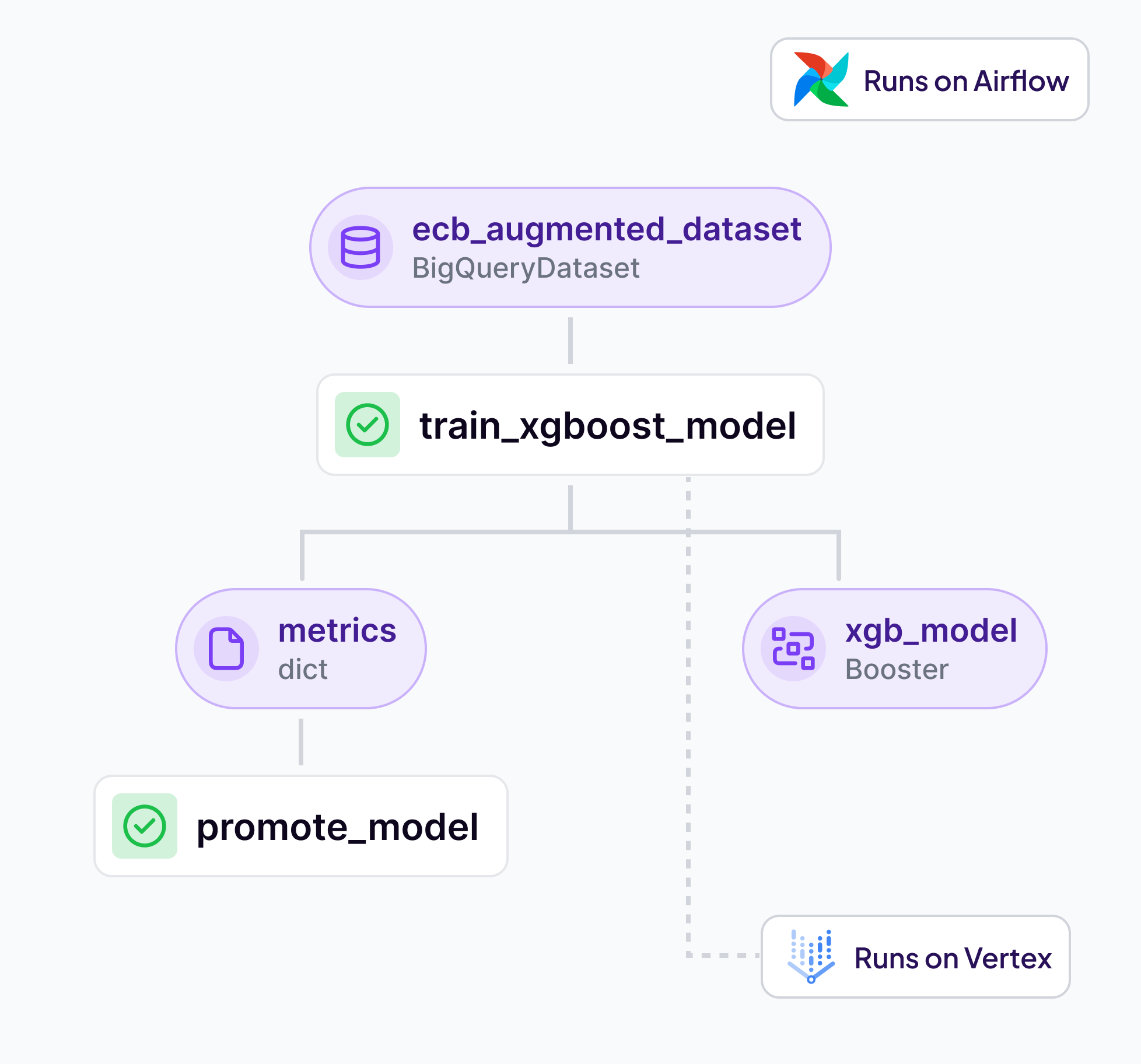
What people call the agent stack is really four layers: model, harness, runtime, platform. Conflating them costs durability. The runtime layer, and one split inside it, gets the least attention.

We break down GPU scheduling, fractional GPU allocation, gang scheduling, integrations, and pricing to help you pick the right tool for your AI infrastructure.

In this Run:ai vs ClearML comparison, we break down GPU orchestration, workload scheduling, resource policies, RBAC, integrations, and pricing to help you pick the right platform for your AI infrastructure.
Meet Kitaru — open source durable execution for Python agents, built by the ZenML team. Crash recovery, human-in-the-loop, and replay from any checkpoint.

Kitaru is live: open-source infrastructure platform for running Python agents in production.

We spent five years building ML pipeline infrastructure. Then agents showed up and we realized the next problem needed a new tool — not an extension of the old one.

Tracing shows you what went wrong. But what if you could go back, fix the input, and resume from where it failed — without re-running everything?

Every durable execution engine today forces your code to be deterministic. Kitaru takes a different approach — and it matters more than you think.

AI agents fail — they timeout, hit rate limits, crash on bad API responses. Without durable execution, every failure means starting over from scratch.

Durable execution engines were built for payment flows and order processing. AI agents need something different. Here's why.

An in-depth analysis of retail MLOps challenges, covering data complexity, edge computing, seasonality, and multi-cloud deployment, with real-world examples from major retailers like Wayfair and Starbucks, and practical solutions including ZenML's impact in reducing deployment time from 8.5 to 2 weeks at Adeo Leroy Merlin.

Discover how to optimize GPU utilization in Kubernetes environments by integrating NVIDIA's KAI Scheduler with ZenML pipelines, enabling fractional GPU allocation for improved resource efficiency and cost savings in machine learning workflows.

Discover how embeddings power modern search and recommendation systems with LLMs, using case studies from the LLMOps Database. From RAG systems to personalized recommendations, learn key strategies and best practices for building intelligent applications that truly understand user intent and deliver relevant results.
Discover why cognitive load is the hidden barrier to ML success and how infrastructure abstraction can revolutionize your data science team's productivity. This comprehensive guide explores the real costs of infrastructure complexity in MLOps, from security challenges to the pitfalls of home-grown solutions. Learn practical strategies for creating effective abstractions that let data scientists focus on what they do best – building better models – while maintaining robust security and control. Perfect for ML leaders and architects looking to scale their machine learning initiatives efficiently.

The combination of ZenML and Neptune can streamline machine learning workflows and provide unprecedented visibility into experiments. ZenML is an extensible framework for creating production-ready pipelines, while Neptune is a metadata store for MLOps. When combined, these tools offer a robust solution for managing the entire ML lifecycle, from experimentation to production. The combination of these tools can significantly accelerate the development process, especially when working with complex tasks like language model fine-tuning. This integration offers the ability to focus more on innovating and less on managing the intricacies of your ML pipelines.




