

On this page
Kubeflow emerged as the standard for ML workflows on Kubernetes, promising a unified platform for the entire ML lifecycle. Yet despite widespread adoption, teams increasingly find themselves grappling with its steep learning curve, operational complexity, and architectural limitations that hinder rather than accelerate ML initiatives.
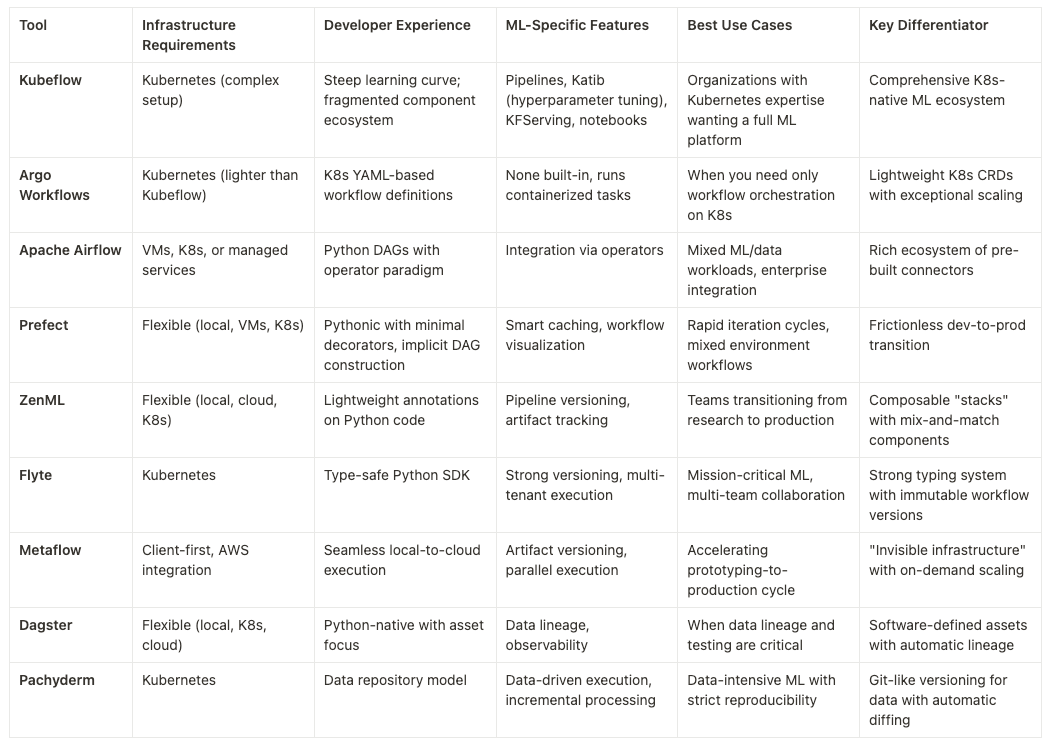
In this post, we’ll explore eight compelling alternatives to Kubeflow that address these pain points. But first, let’s understand why teams are seeking alternatives in the first place.
Understanding the Kubeflow Problem Space
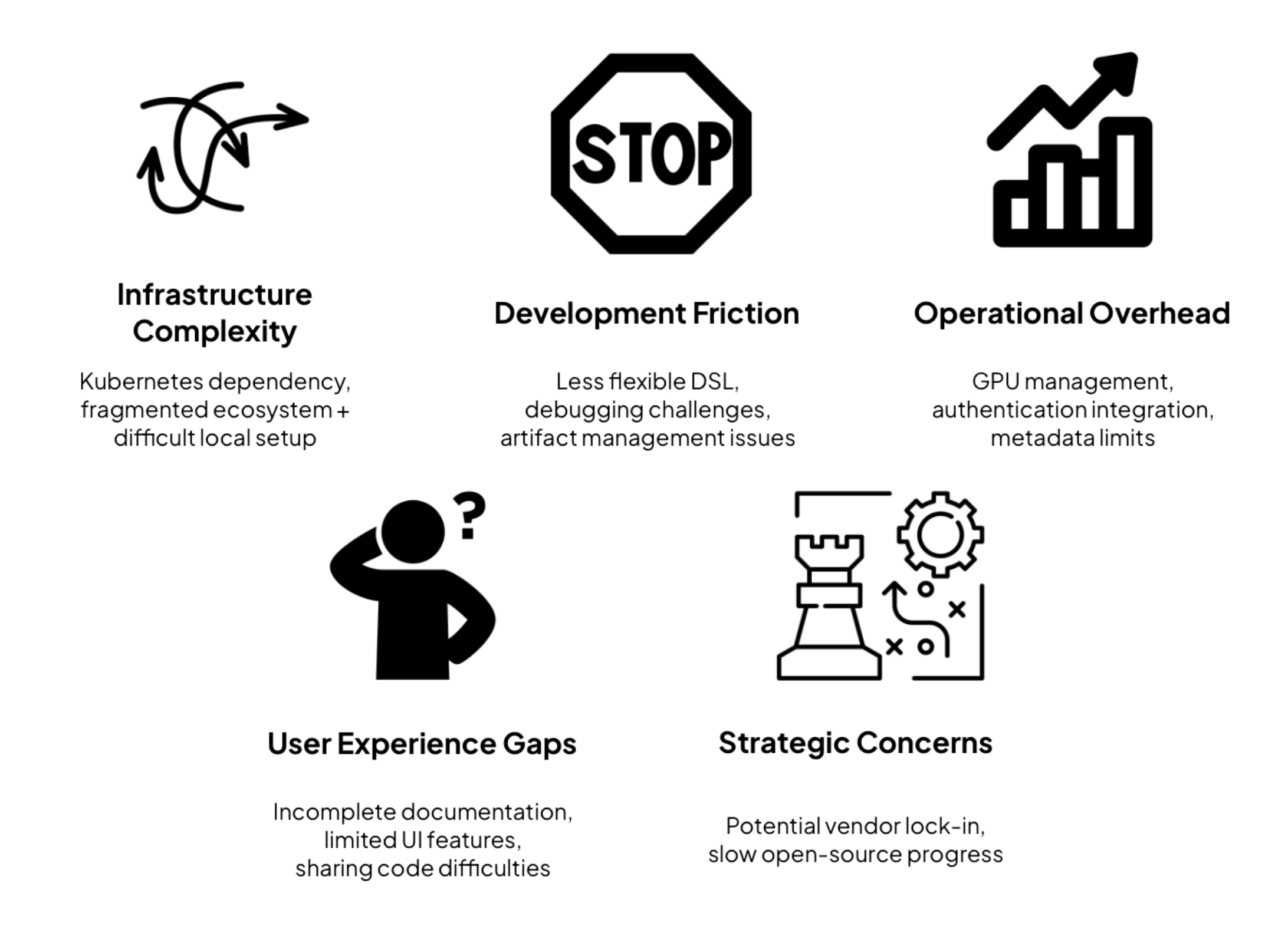
Kubeflow’s challenges manifest across several critical dimensions:
Infrastructure Complexity
The Kubernetes dependency creates an immediate barrier for ML teams without container orchestration expertise. The fragmented component ecosystem—Pipelines, Katib, KServe—forces teams to master multiple subsystems simultaneously, diverting focus from actual ML development. Local development environments are notoriously difficult to set up, creating a persistent disconnect between development and deployment.
Development Friction
The Kubeflow Pipelines DSL is criticized for being less flexible than raw Argo YAML while lacking Pythonic simplicity. Error messages are cryptic, debugging is cumbersome, and artifact management struggles with large datasets and complex versioning. These limitations push teams toward monolithic pipeline designs rather than modular, reusable components that would enable greater experimentation velocity.
Operational Overhead
GPU resource management—often the most expensive component of ML infrastructure—proves difficult to optimize, leading to either resource waste or execution bottlenecks. Authentication integration with enterprise SSO systems is complicated by Istio dependencies, while Kubernetes’ 256KB metadata limits for CRDs require manual workarounds.
User Experience Gaps
Documentation is scattered across component-specific docs and community forums. The UI lacks robust features for comparing pipeline runs or examining artifacts in detail. The absence of native support for sharing code between components forces teams into error-prone workarounds like duplication or complex package management.
Strategic Concerns
While marketed as cloud-agnostic, certain Kubeflow distributions (particularly vendor-specific ones) introduce platform dependencies that can lead to lock-in. Meanwhile, competing priorities between open-source contributors and commercial vendors sometimes slow critical fixes.
These challenges explain why teams are increasingly exploring alternative orchestration platforms. In the sections that follow, we’ll examine eight alternatives, evaluating how each addresses these pain points while introducing their own unique strengths and tradeoffs to help you make an informed choice that aligns with your team’s ML maturity and objectives.
Argo Workflows
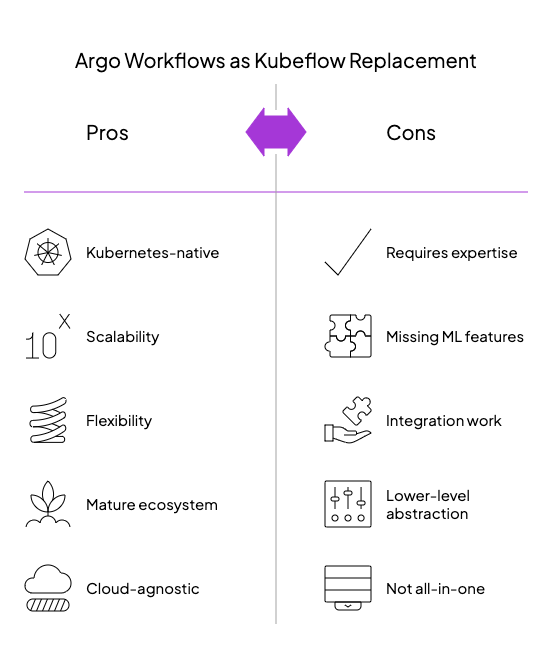
If Kubeflow’s complexity feels overwhelming but you still need robust workflow orchestration on Kubernetes, Argo Workflows offers a compelling alternative. As a Cloud Native Computing Foundation (CNCF) graduated project, Argo provides a streamlined approach to containerized task orchestration that appeals to teams with existing Kubernetes expertise.
Why Platform Engineers Choose Argo
Argo stands out for its lightweight, Kubernetes-native design. Unlike Kubeflow’s multi-component architecture,tw Argo installs as a simple Custom Resource Definition (CRD) with a controller—leveraging Kubernetes primitives rather than fighting against them. This approach yields several key advantages:
- Pure Kubernetes execution model: Each workflow step runs in its own pod, making resource allocation, monitoring, and debugging familiar to teams with K8s experience
- Minimalist state management: No heavy central database required—workflow state is stored as Kubernetes objects
- Exceptional scaling capabilities: Can effortlessly handle thousands of parallel pods for large-scale ML workloads
- Flexible integration options: Works with anything containerizable, making it adaptable to evolving ML toolchains
Technical Capabilities for ML Pipelines
While lacking built-in ML-specific abstractions, Argo excels at the orchestration patterns critical for ML workflows:
- Artifact passing: Seamlessly transfer data between steps using volumes or object storage
- GPU resource scheduling: Direct utilization of Kubernetes scheduler for hardware acceleration
- DAG-based workflows: Define complex pipelines with conditional execution and parallelism
- Step caching: Skip unchanged steps for faster iteration cycles
When Argo Outshines Kubeflow
Argo provides a compelling alternative when:
- You need only workflow orchestration: If you're looking exclusively for the pipeline component of Kubeflow without the surrounding ecosystem
- Kubernetes expertise is abundant: Your team already understands K8s concepts and wants direct access to its capabilities
- Scalability is paramount: The overhead of Kubeflow becomes a bottleneck for high-volume workflow execution
- Multi-purpose orchestration is valuable: You want one engine for both ML and non-ML workflows (ETL, CI/CD)
Practical Tradeoffs
While powerful, Argo’s lightweight approach comes with considerations:
- Less ML-specific tooling: No built-in experiment tracking or model registry integration
- More infrastructure exposure: Requires greater Kubernetes knowledge from data scientists
- Lower-level abstractions: More flexible but potentially more verbose pipeline definitions
Integration Ecosystem
Argo’s ubiquity in the cloud-native space means it integrates well with complementary tools:
- ML platforms: Often used as the execution engine for higher-level tools like Metaflow or ZenML
- Storage systems: Works with artifact stores (S3, MinIO) for model and dataset persistence
- CI/CD pipelines: Natural pairing with Argo CD for GitOps-driven ML deployment
For teams comfortable with Kubernetes seeking a streamlined, scalable orchestration solution without Kubeflow’s overhead, Argo Workflows represents a mature, battle-tested alternative that can grow alongside your ML platform needs.
Apache Airflow
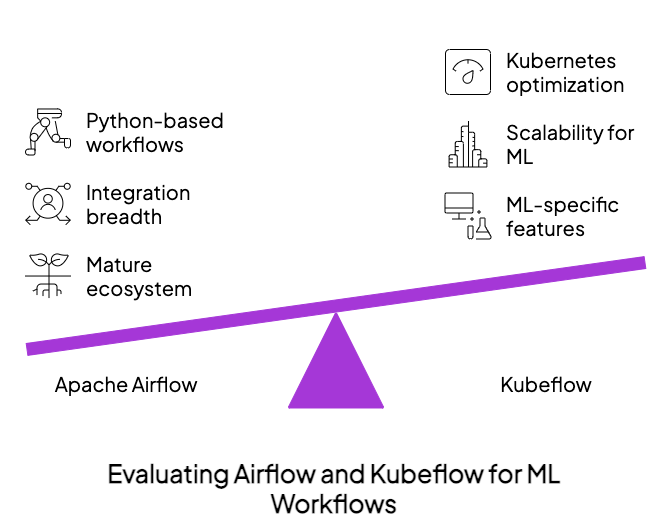
When ML platform teams need a proven orchestration solution with solid integration capabilities, Apache Airflow emerges as a pragmatic choice. Born at Airbnb in 2014 and now thriving as an Apache project, Airflow bridges traditional data pipelines with modern ML workflows through its Python-first approach.
Key Advantages Over Kubeflow
- Rich integration ecosystem: Hundreds of pre-built connectors for data sources, cloud services, and ML platforms
- Hybrid orchestration: Seamlessly connect on-prem systems, cloud services, and Kubernetes workloads
- Flexible deployment options: Run on VMs, Kubernetes, or use managed services (AWS MWAA, Google Cloud Composer)
- Lower adoption barrier: Familiar to both data and ML engineers with a gentler learning curve
Strategic Fit in the ML Stack
Unlike Kubeflow’s all-in-one approach, Airflow focuses exclusively on orchestration excellence, creating several key advantages:
- Simpler conceptual model: DAG-based workflows without Kubernetes complexity
- Incremental adoption: Can be introduced alongside existing infrastructure
- Cross-functional accessibility: Bridges the gap between data engineering and ML teams
Note that Airflow 3 is (at the time of writing) soon to be released and this will include some features that will be useful for ML and AI workflows.
Performance Considerations
Airflow’s centralized scheduler works well for regular retraining pipelines but may face bottlenecks with massive parallel experimentation. For containerized workloads, the KubernetesPodOperator provides isolation while maintaining Airflow’s orchestration benefits.
Practical Integration Strategy
For ML platform teams, Airflow often serves as the orchestration backbone connected to specialized ML tools:
- Use Airflow for scheduling, monitoring, and cross-system coordination
- Integrate with purpose-built ML components (MLflow, feature stores, model registries)
- Deploy the
KubernetesPodOperatorfor containerized training when needed
This pragmatic approach delivers much of what teams seek from Kubeflow without the associated complexity—making Airflow an enduring favorite for organizations prioritizing practical solutions over architectural purity.
If you want to use Airflow with ZenML, we support this out of the box. Read our documentation here and learn more about the comparison between the two options here.
Prefect
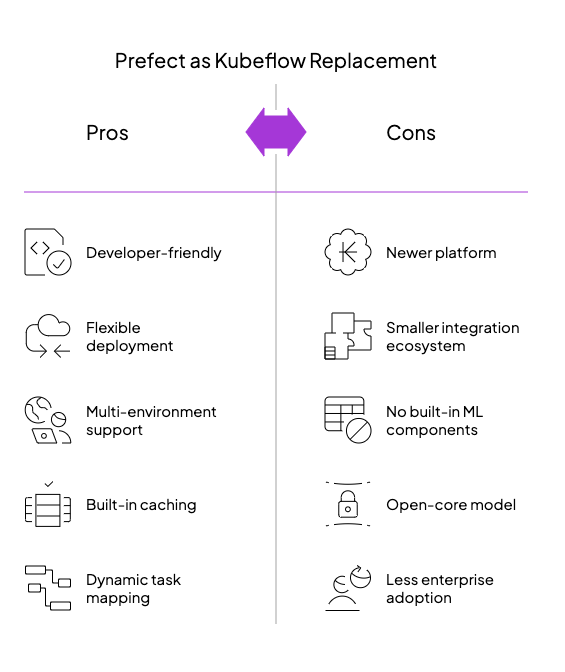
For ML engineers battling workflow complexities instead of focusing on models, Prefect offers a refreshingly Pythonic alternative to Kubeflow’s infrastructure-heavy approach. Launched in 2018 with a significant 2.0 rewrite in 2022 (followed by 3.0 in 2024), Prefect embodies its mission to “eradicate negative engineering” by eliminating friction between development and production.
Developer Experience That Respects ML Workflows
Prefect’s standout feature is its intuitive Python-native approach to pipeline definition, where ordinary functions become workflow components with simple decorators. This offers crucial advantages over Kubeflow Pipelines:
- Frictionless development-to-production transition: Same code runs locally and in production
- Implicit DAG construction: Dependencies determined by function calls, not explicit declarations
- Smart caching: Tasks cache results based on input hashing, accelerating iterative development
- Minimal ceremony: Pythonic syntax keeps focus on ML logic, not orchestration plumbing
Hybrid Execution Model for Infrastructure Flexibility
Unlike Kubeflow’s all-in Kubernetes approach, Prefect employs a hybrid architecture:
- Lightweight agents run in execution environments (Kubernetes, VMs, local machines)
- Centralized orchestration via Prefect Cloud (SaaS) or self-hosted Server
- Task isolation options including processes, containers, Kubernetes Jobs, and Dask clusters
This separation means ML teams can run workflows across heterogeneous environments without complex infrastructure coupling—ideal for organizations with mixed computing resources.
When Prefect Outshines Kubeflow
Prefect becomes particularly compelling when:
- Your team values rapid iteration: Development-to-production cycle is dramatically shorter
- Workflows span multiple environments: Combining on-prem data, cloud processing, and edge deployment
- Python is your primary language: ML engineers leverage existing skills without learning new DSLs
- Infrastructure flexibility matters: Orchestration remains decoupled from execution
Prefect’s “Python-first, not Python-only” philosophy creates a refreshing middle ground between Kubeflow’s infrastructure complexity and simple script-based approaches—making it increasingly popular for ML teams seeking workflow acceleration without sacrificing flexibility or control.
ZenML
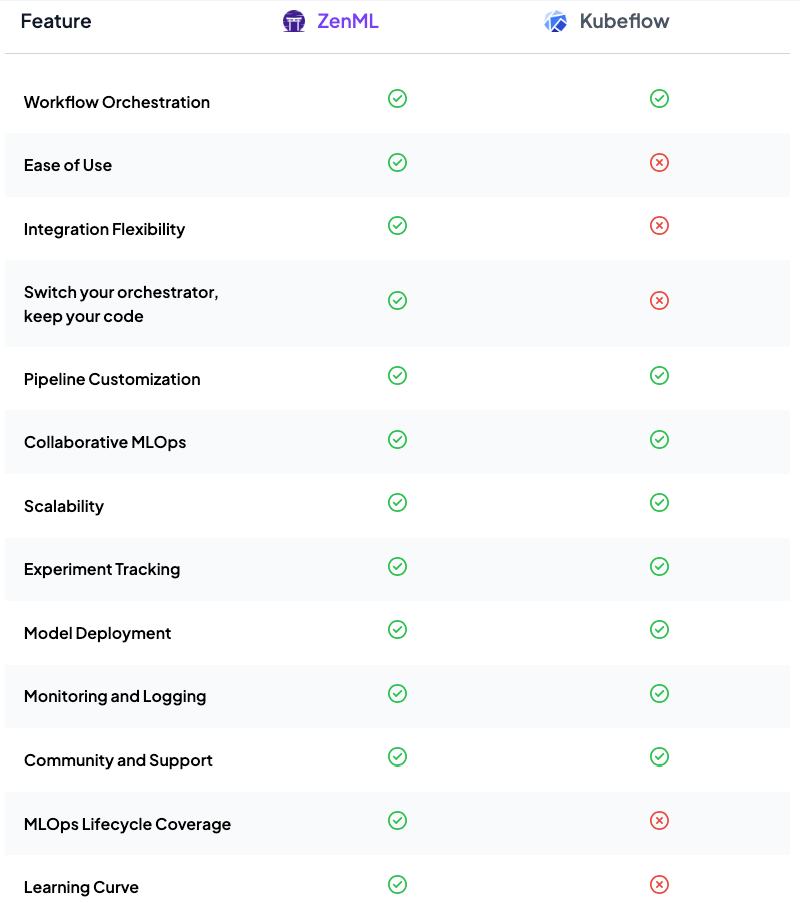
ZenML takes a fundamentally different approach to ML orchestration by prioritizing developer experience without sacrificing production readiness. Created specifically to address the friction between research prototypes and production systems, ZenML offers a lightweight yet powerful framework that integrates cleanly with existing ML infrastructure.
Simplified Pipeline Development With Production-Ready Outcomes
Unlike Kubeflow’s complex component architecture, ZenML focuses on transforming standard Python code into reproducible pipelines through minimal annotations. This approach enables ML practitioners to maintain their natural development workflow while gaining critical MLOps capabilities:
- Seamless code-to-pipeline transition: Transform research code into production pipelines with minimal modifications
- Infrastructure abstraction: Develop locally, deploy anywhere through configurable "stacks"
- Built-in lineage tracking: Automatically version artifacts, parameters, and execution metadata
- Native caching: Skip redundant computations through intelligent detection of unchanged inputs
This design philosophy eliminates much of the “negative engineering” that plagues ML productionization efforts, reducing the gap between prototype and production code.
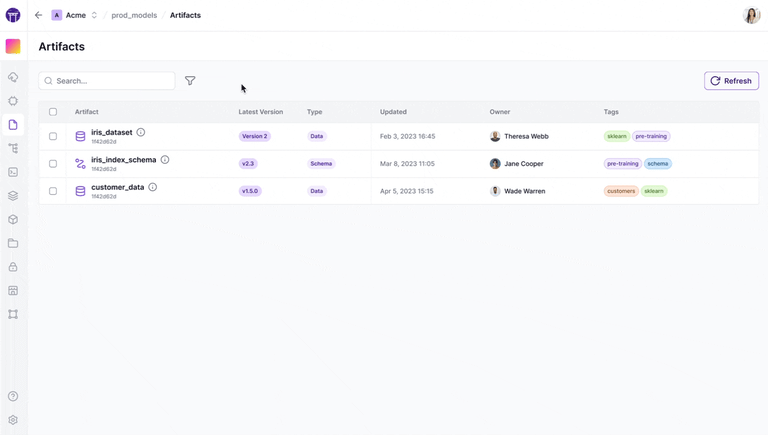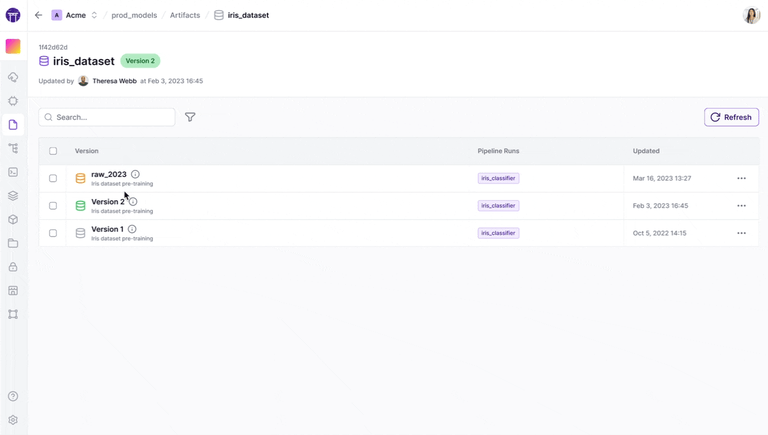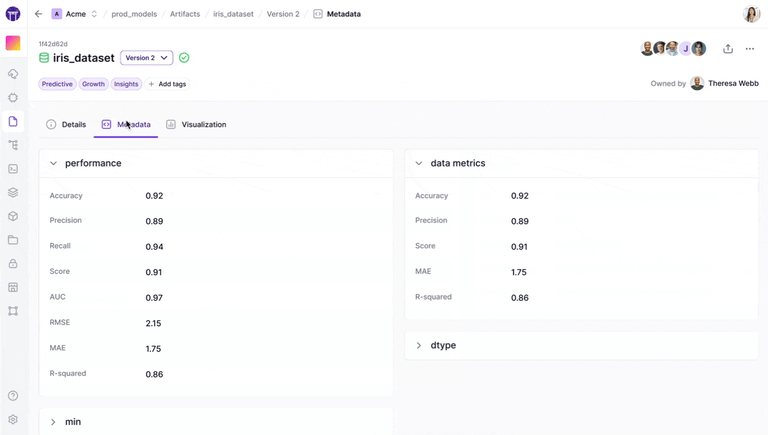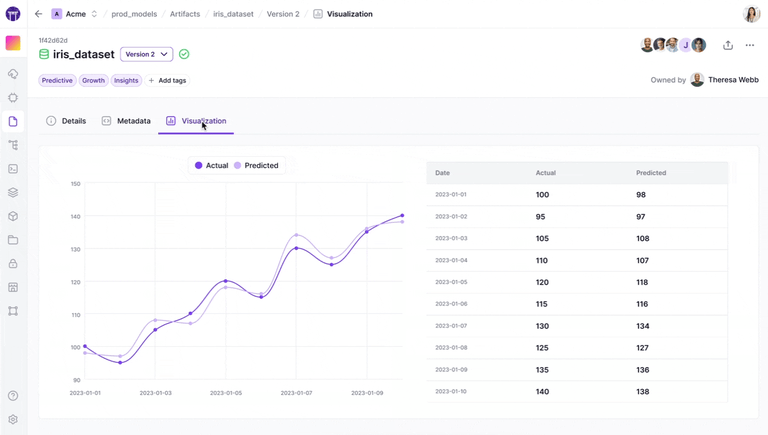
Comprehensive Metadata Tracking and Artifact Versioning
ZenML’s metadata system sits at the core of its value proposition, providing significantly more intuitive capabilities than Kubeflow’s:
- Automatic artifact versioning: Every artifact—be it data, models, or evaluations—is automatically tracked and versioned upon pipeline execution, ensuring reproducibility and traceability within your ML workflows.
- Rich metadata capture: ZenML automatically logs metadata for common data types like pandas DataFrames (shape, size) and allows custom metadata attachment to artifacts, steps, runs, and models.
- Human-readable naming: Custom naming capabilities for artifacts enhance discoverability and management across complex workflows.
- Integrated visualization: The dashboard provides convenient ways to visualize lineage through the DAG visualizer, making it easy to track how artifacts are created and how they relate to each other.
Unlike Kubeflow, where artifact and metadata management often requires additional components and configuration, ZenML builds these capabilities directly into its core functionality, making them immediately accessible to users.
The Model Control Plane: A Unified Model Management Approach
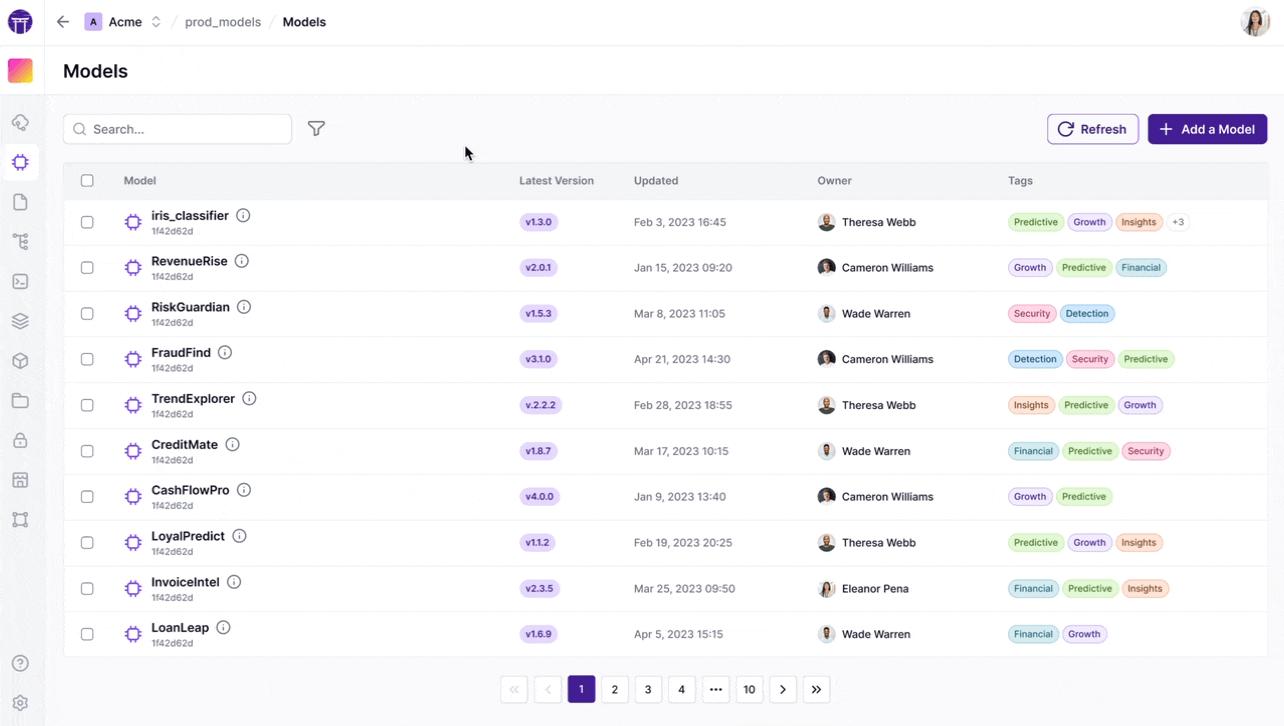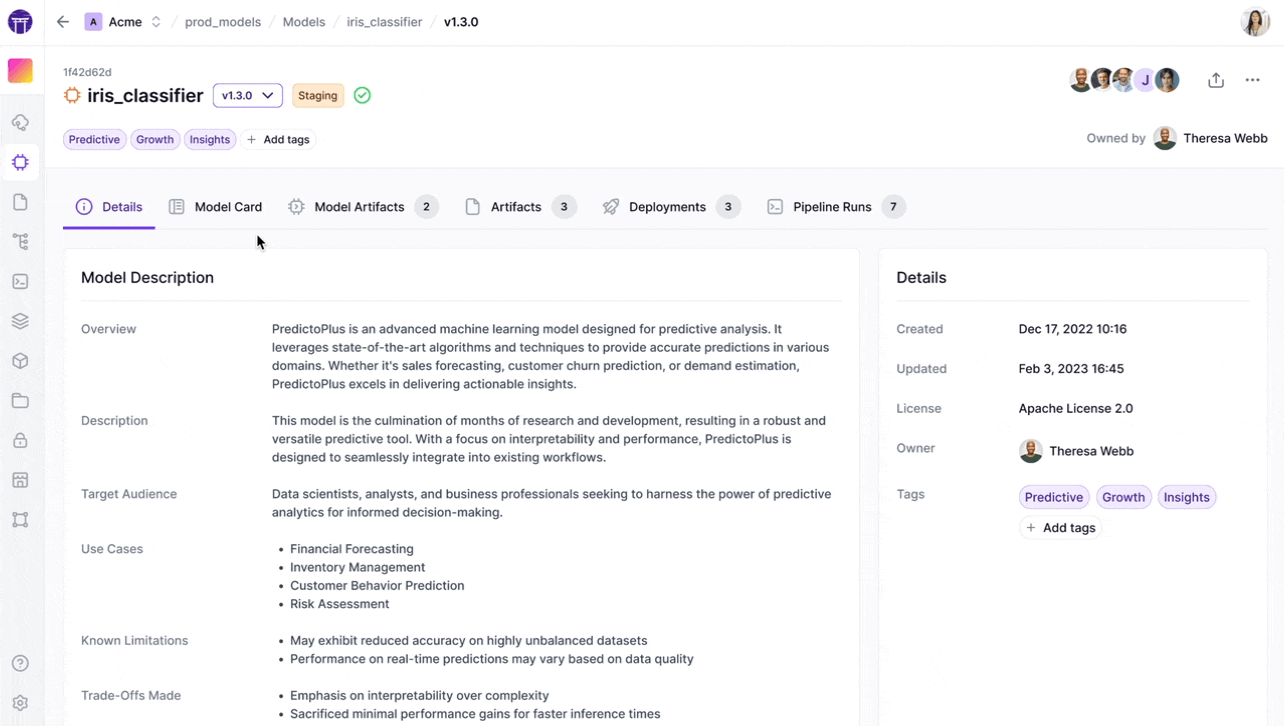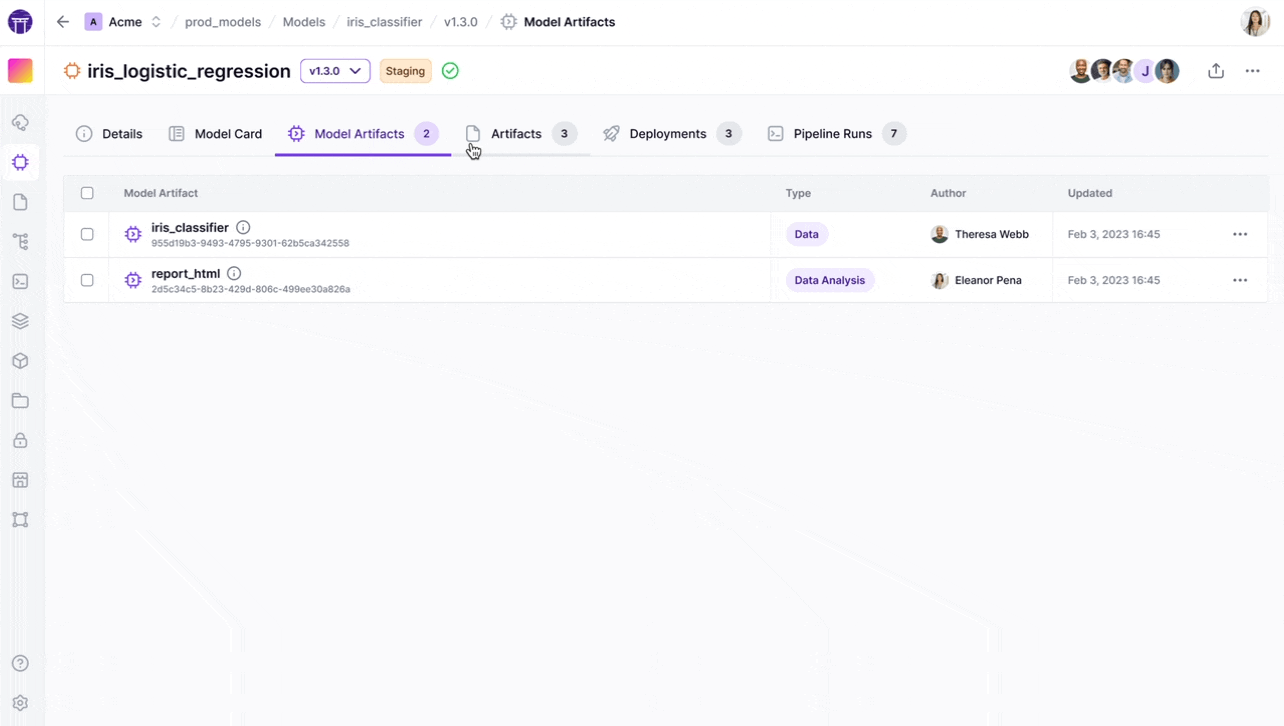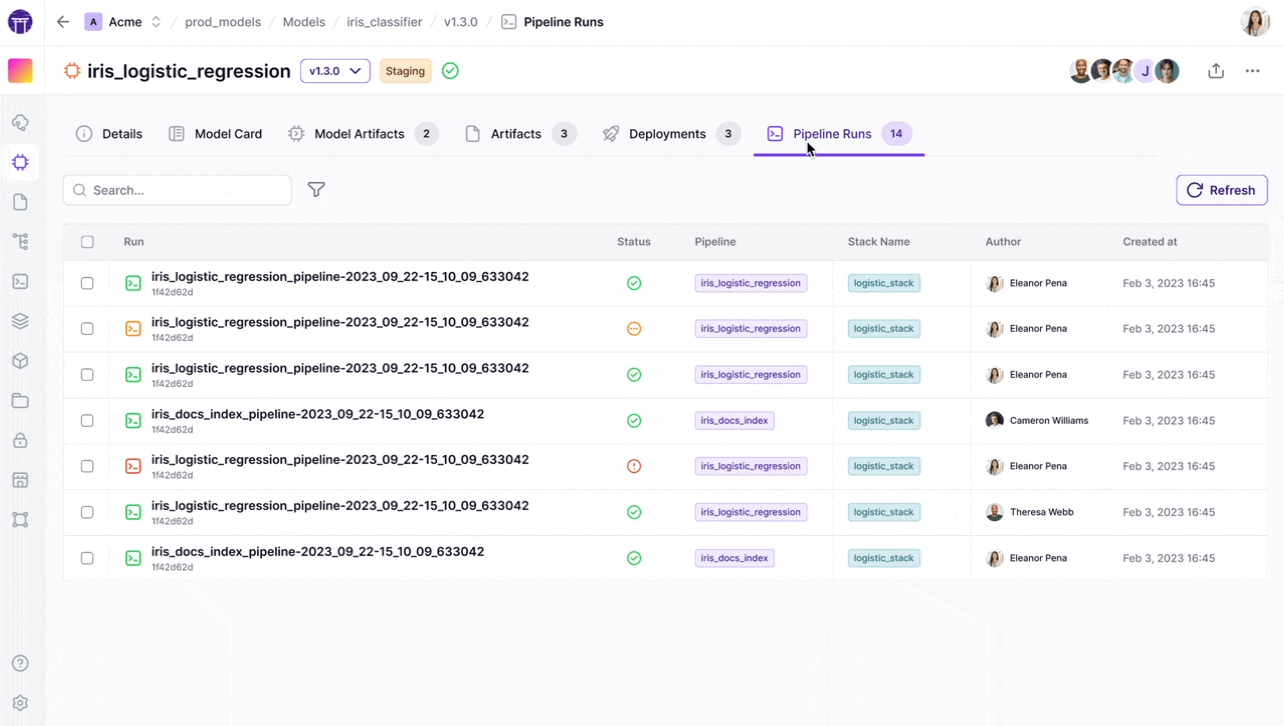
ZenML’s Model Control Plane represents a significant advancement over traditional orchestration systems like Kubeflow:
- Business-oriented model concept: A ZenML Model is an entity that groups pipelines, artifacts, metadata, and crucial business data into a unified entity—essentially encapsulating your ML product's business logic.
- Lifecycle management: Model versions track iterations of your training process with dashboard and API functionality supporting the full ML lifecycle, allowing versions to be associated with stages and promoted to production based on business rules.
- Artifact linking: The interface allows linking model versions with non-technical artifacts and data, including business data, datasets, or workflow stages.
- Central visibility: The Model Control Plane provides "one central glass plane view over all your models" where you can understand where models originated and track them from training to deployment across various infrastructures and tooling.
This holistic approach to model management addresses a key limitation of Kubeflow—while Kubeflow excels at pipeline orchestration, it lacks a unified model lifecycle management system that bridges technical and business concerns.
Composable Architecture for Customized ML Platforms
ZenML’s stack-based architecture provides a unique balance of standardization and flexibility:
- Mix-and-match components: Select the right tools for orchestration, artifact storage, and model deployment
- Multi-environment support: Run the same pipeline code locally, on Kubernetes, or with cloud services
- Progressive adoption: Start simple and incrementally enhance your stack as needs evolve
For teams transitioning away from Kubeflow, this composability offers a crucial advantage—you can adopt ZenML without abandoning working components of your existing stack, gradually migrating to a more streamlined workflow.
Practical Benefits for ML Teams
The framework delivers several concrete advantages over Kubeflow’s monolithic approach:
- Lower infrastructure overhead: No need to maintain a complex Kubernetes installation
- Reduced cognitive load: Python-native expressions instead of YAML or DSL configurations
- Incremental adoption: Start with a single pipeline and expand usage organically
- Future-proof integrations: Connect with specialist tools like MLflow, Weights & Biases, or BentoML through a consistent interface
- Enhanced reproducibility: By tracking lineage across environments and stacks, ZenML enables ML engineers to reproduce results and understand exactly how a model was created—crucial for ensuring reliability, especially when working in a team.
When ZenML Outperforms Kubeflow
ZenML provides a compelling alternative when:
- Development velocity matters: Rapid iteration cycles from research to production without pipeline rewrites
- Infrastructure flexibility is essential: Support for diverse execution environments without code changes
- Resource constraints exist: Need for MLOps capabilities without dedicated platform engineering teams
- Integration with specialized tools is required: Preference for best-of-breed components over all-in-one solutions
- Metadata tracking and model management are priorities: ZenML automatically tracks all ML metadata, providing complete lineage and reproducibility for ML workflows while enabling seamless collaboration among ML practitioners.
While ZenML may not match Kubeflow’s depth in areas like distributed training coordination or multi-tenant notebook management, it excels at streamlining the core ML workflow challenges that most organizations prioritize: reproducibility, deployment consistency, and operational simplicity.
For teams seeking to accelerate their ML delivery without the steep learning curve and maintenance overhead of Kubeflow, ZenML offers a pragmatic path forward—bringing structure and reliability to ML workflows without sacrificing developer productivity.
Flyte
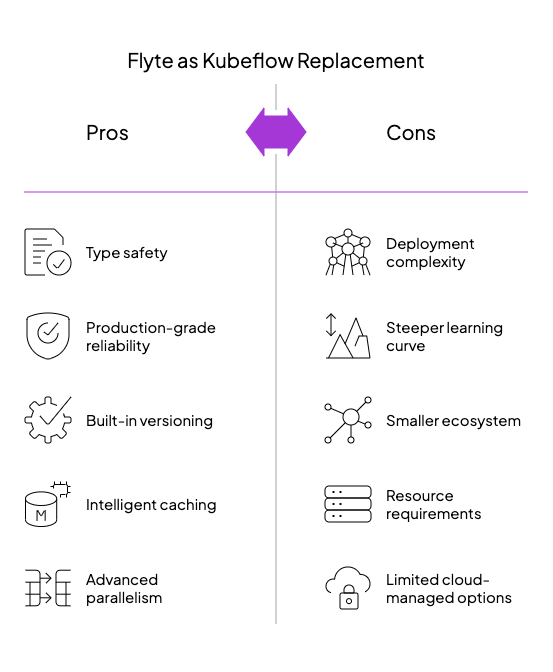
Born from Lyft’s need for reliable, scalable ML pipelines, Flyte has emerged as a compelling alternative to Kubeflow for organizations that require production-grade orchestration with strong reliability guarantees. Now a Linux Foundation AI & Data graduated project, Flyte brings software engineering principles to ML workflow management with a focus on reproducibility and robustness.
Type-Safe Workflows for Reliable ML Execution
Flyte differentiates itself from Kubeflow through its emphasis on software engineering rigor:
- Strong type system: Input/output validation prevents subtle pipeline errors
- Versioned workflows: Complete reproducibility through immutable execution histories
- Declarative specification: Clear separation between definition and execution
- Data-aware caching: Intelligent reuse of previously computed artifacts
These principles align particularly well with production ML systems where pipeline reliability is non-negotiable and errors can have significant downstream impacts.
Architecture Designed for Enterprise Scale
Unlike Kubeflow’s component-based approach, Flyte was architected from the ground up for multi-tenant, multi-team environments:
- Built-in multi-tenancy: Domain and project isolation without separate deployments
- Decentralized execution: Fault-tolerant workflow scheduling via Kubernetes CRDs
- Resource governance: Fine-grained control over compute allocation across teams
- Horizontal scalability: Proven at organizations like Lyft with 10,000+ workflows monthly
This architecture makes Flyte particularly well-suited for larger organizations that need to support multiple ML teams without creating infrastructure silos.
Practical Advantages for Production ML
For teams struggling with Kubeflow’s operational challenges, Flyte addresses several pain points:
- Reduced pipeline fragility: Container-based execution with explicit versioning eliminates "works on my machine" problems
- Simplified complex orchestration: Native support for dynamic workflows, map tasks, and conditional execution
- Unified data processing: Seamlessly incorporate Spark, Dask, and other data processing frameworks
- Developer-friendly interfaces: Python SDK with familiar syntax for ML practitioners
When Flyte Outshines Kubeflow
Flyte presents a compelling alternative when:
- Pipeline reliability is critical: Mission-critical deployments where failures are costly
- Multi-team collaboration is needed: Organizations requiring shared infrastructure without interference
- Complex data processing is involved: Workflows spanning both data engineering and ML training
- Engineering standards matter: Teams looking to bring software engineering best practices to ML
While Flyte requires Kubernetes expertise for deployment (similar to Kubeflow), its architectural consistency and reliability guarantees make it an increasingly popular choice for organizations that have outgrown simpler orchestration tools but found Kubeflow’s maintenance overhead challenging.
For ML platform teams seeking to build sustainable, production-grade infrastructure, Flyte offers a compelling balance of flexibility and engineering discipline that helps bridge the gap between ML innovation and operational excellence.
Metaflow
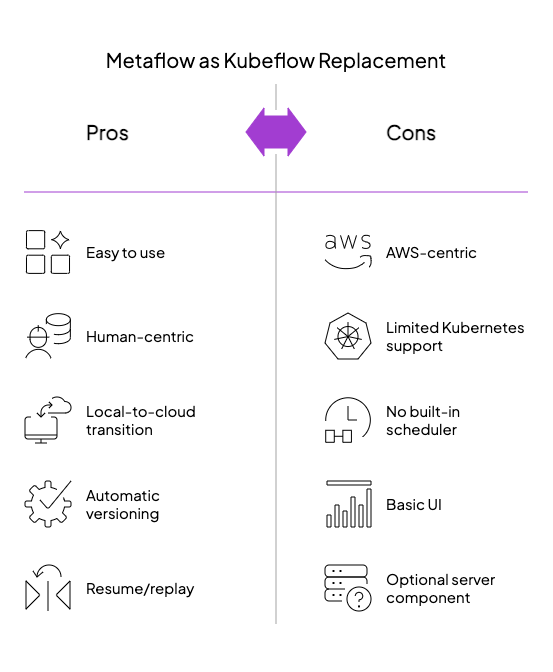
Developed at Netflix and now open-source, Metaflow tackles the ML orchestration challenge from a refreshingly different angle: focusing on data scientist productivity first, while seamlessly handling infrastructure scaling behind the scenes. This human-centric approach offers a compelling alternative to Kubeflow’s infrastructure-first paradigm.
Developer Experience as the North Star
Metaflow redefines what ML workflow tools should prioritize:
- Frictionless iteration: Move from notebook experimentation to production pipelines without changing code
- Invisible infrastructure: Cloud resources appear on-demand through simple Python decorators like
@batchor@kubernetes - Automatic data versioning: Every artifact in every run is tracked and versioned by default
- Resume and replay capability: Pick up workflows midway after failures or code changes
This design philosophy makes the gap between research and production nearly imperceptible—a stark contrast to Kubeflow’s explicit separation of these environments.
Architecture that Respects Development Workflows
Unlike Kubeflow’s cluster-centric model, Metaflow employs a unique client-first architecture:
- Client-side orchestration: Workflows are executed from your local machine, which delegates to cloud resources
- Seamless remote execution: Single decorator transforms a local step to run on powerful cloud instances
- Zero infrastructure setup: No persistent servers to maintain, only optional metadata services
- Implicit data flow: Artifacts move transparently between execution environments
This architecture eliminates the cognitive load of managing Kubernetes resources while still leveraging cloud-scale compute when needed.
Powerful ML Patterns with Minimal Complexity
Metaflow combines simplicity with sophisticated capabilities that ML workflows require:
- Parallel execution:
foreachsplits enable hyperparameter tuning and cross-validation without infrastructure knowledge - Step-level resource allocation: Independently scale compute for different workflow stages (preprocessing, training, evaluation)
- Artifact lineage: Track exactly which data produced which models across all executions
- Native cloud integration: Deep integration with AWS services like S3, Batch, and Step Functions
When Metaflow Outshines Kubeflow
Metaflow presents a compelling alternative to Kubeflow when:
- Speed of development is critical: Accelerating the prototype-to-production journey
- Data scientist autonomy matters: Reducing dependencies on platform teams
- AWS is your primary cloud: Leveraging Netflix's battle-tested AWS integration
- Simplicity trumps configurability: Trading some low-level control for dramatically improved productivity
While Metaflow may not match Kubeflow’s multi-team isolation or specialized ML components, it excels at streamlining the core ML workflow: iteratively developing, scaling, and deploying data science code without friction or complexity.
For organizations seeking to empower data scientists with infrastructure that adapts to their workflow—rather than forcing them to adapt to the infrastructure—Metaflow offers a pragmatic path that can dramatically accelerate ML delivery while maintaining production readiness.
Dagster
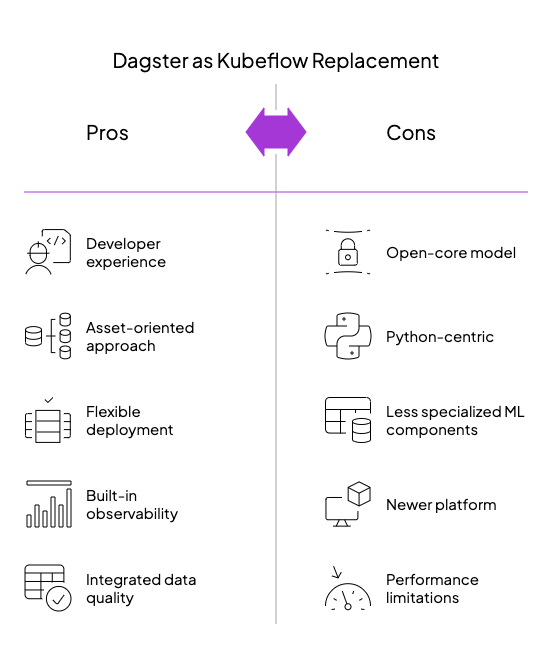
Dagster approaches the orchestration challenge from a fundamentally different perspective than Kubeflow, prioritizing data assets and developer experience over infrastructure primitives. Originally designed for data engineering but now widely adoptend for ML workflows, Dagster brings software engineering rigor to pipeline development while maintaining remarkable flexibility.
Asset-Centric Pipelines for ML Visibility
Unlike Kubeflow’s step-focused pipelines, Dagster centers its model around data assets:
- Software-defined assets: Model datasets, features, and ML models as versioned entities in your pipeline
- Automatic lineage tracking: Visualize exactly which data produced which models and downstream analytics
- Selective re-execution: Update only the affected downstream assets when source data changes
- Built-in data observability: Track data quality, formats, and schema evolution throughout the ML lifecycle
This asset-oriented approach provides critical context that Kubeflow’s task-centric model lacks—answering questions like “which data produced this model?” or “what downstream systems will be affected by this feature change?”
Developer Experience That Accelerates Iteration
Dagster eliminates the friction that plagues Kubeflow’s development workflow:
- Python-native pipeline definition: Define workflows with simple decorators on standard Python functions
- Local development to production parity: Run the same pipeline code in notebooks, locally, or in production
- Testing-friendly architecture: Unit test pipeline components without the orchestration machinery
- Immediate feedback loops: Iterate on pipeline components without rebuilding containers
For ML engineers tired of Kubeflow’s container-centric development process, Dagster’s approach means spending more time on models and less on infrastructure.
Flexible Architecture for Evolving ML Platforms
Unlike Kubeflow’s all-in Kubernetes approach, Dagster provides infrastructure flexibility:
- Gradual adoption path: Start locally, scale to production incrementally
- Multiple execution environments: Run on VMs, Kubernetes, or cloud services through a consistent interface
- Pluggable storage and execution: Use S3, GCS, or specialized ML artifact stores with the same pipeline code
- Integration-friendly design: Connect with specialized ML tools through a modular resource system
This adaptability makes Dagster particularly attractive for organizations with mixed infrastructure or those transitioning to cloud-native architectures without wanting to commit fully to Kubernetes.
When Dagster Outshines Kubeflow
Dagster presents a compelling alternative when:
- Data lineage is critical: Maintain visibility into data dependencies across the ML lifecycle
- Platform evolution is expected: Build a system that can adapt to changing infrastructure needs
- Cross-functional collaboration is required: Bridge the gap between data engineering and ML teams
While Dagster doesn’t include the full suite of ML-specific components that Kubeflow offers (notebook servers, distributed training operators, etc.), it excels at its core mission: orchestrating reliable, observable data and ML pipelines with minimal friction.
For teams that value software engineering principles, rapid iteration cycles, and holistic data visibility, Dagster represents a modern approach to ML orchestration that addresses many of Kubeflow’s pain points without sacrificing production readiness.
Pachyderm
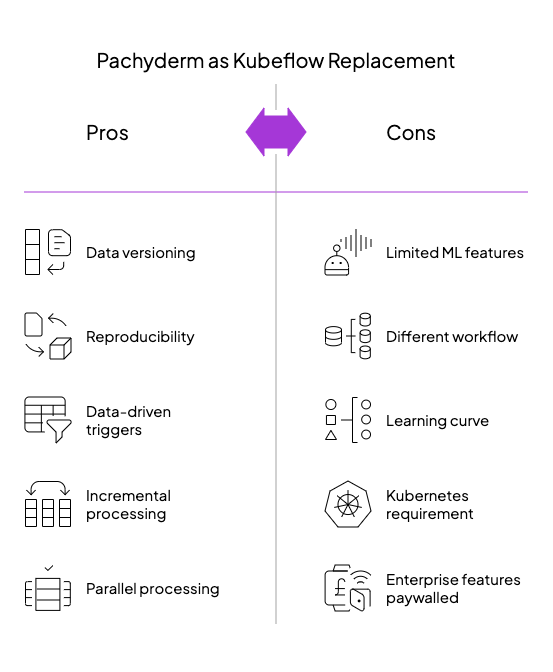
While most ML orchestration tools focus on workflow execution, Pachyderm addresses a fundamental challenge that Kubeflow often overlooks: rigorous versioning and lineage of datasets throughout the ML lifecycle. Often described as “Git for data,” Pachyderm brings software engineering principles to data management while providing powerful pipeline capabilities.
Data Versioning as the Foundation
Pachyderm establishes a new paradigm for ML workflows with its data-centric approach:
- Immutable data repositories: Commit, branch, and track changes to datasets just like code
- Automatic diffing: Identify and process only what's changed between versions
- Complete lineage tracking: Every output is linked to the exact data and code that produced it
- Data-triggered execution: Pipelines automatically run when their input data changes
This foundation addresses a critical gap in Kubeflow’s architecture, where data versioning is typically an afterthought implemented through external tools or manual processes.
Pipeline Architecture for Data-First Workflows
Unlike Kubeflow’s predefined step-based pipelines, Pachyderm structures execution around data transforms:
- Data repositories as interfaces: Pipelines subscribe to input repos and produce output repos
- Containerized processing: Each pipeline stage runs as a Docker container on Kubernetes
- Parallel data processing: Automatic sharding and distributed execution across worker pods
- Incremental computation: Only new or changed data flows through the pipeline
This architecture excels in scenarios where data preprocessing is as crucial as model training itself—particularly valuable for computer vision, genomics, and other data-intensive ML domains.
Practical Benefits for ML Governance
For organizations struggling with Kubeflow’s reproducibility limitations, Pachyderm provides several key advantages:
- Auditability: Trace any result back to the exact data and code that generated it
- Regulatory compliance: Meet strict data governance requirements in regulated industries
- Experiment comparability: Easily identify how data changes affected model performance
- Incremental processing efficiency: Dramatically reduce computation costs for large datasets
When Pachyderm Outshines Kubeflow
Pachyderm becomes particularly compelling when:
- Data reproducibility is non-negotiable: Regulated industries or high-stakes ML applications
- Datasets are large and evolving: Continuous data ingestion with efficient incremental processing
- Complex data transformations dominate: Pipelines with significant preprocessing before training
- Audit trails are required: Need to trace any result back to source data and transformations
While Pachyderm doesn’t match Kubeflow’s native experiment tracking or hyperparameter tuning capabilities, it provides something arguably more fundamental: absolute certainty about which data produced which results—a foundation upon which reliable ML systems must be built.
For organizations that find themselves manually tracking dataset versions or struggling to reproduce training runs in Kubeflow, Pachyderm offers a principled solution that brings the best practices of software versioning to the data that drives ML success.
Takeaways: which one should I use?
The best alternative to Kubeflow depends on your team’s needs and expertise. Each tool above has a niche where it outperforms Kubeflow’s broader but sometimes heavier approach:
- Argo Workflows is ideal if you want a fast, Kubernetes-native engine and you’re comfortable building ML pipelines with container scripts (great when Kubeflow is too monolithic and you just need agile pipeline orchestration).
- Apache Airflow fits if you need a tried-and-true orchestrator that can handle not only ML but also data engineering tasks, leveraging its rich integration ecosystem and large community (often chosen when an organization already uses Airflow and doesn’t want a separate Kubeflow system).
- Prefect appeals when a cloud-hybrid solution and Python-first interface matter – it provides an easier developer experience than Kubeflow with the option of a managed service, making it a good choice for smaller teams or multi-cloud workflows.
- ZenML shines in enabling rapid ML pipeline development with minimal ops. It’s a lightweight way to get many of Kubeflow’s benefits (and even use Kubeflow under the hood if needed) without steep learning curve – perfect for teams that value flexibility and integration with various MLOps tools. It’s also built for machine-learning workflows!
- Flyte is compelling for organizations that need a production-grade, highly scalable ML orchestration platform. It offers stronger guarantees around reproducibility and stability than Kubeflow, and is often favored when Kubeflow Pipelines prove fragile under scale or complexity.
- Metaflow provides a smooth developer experience, making it a good pick for data science teams who want to go from notebook to production quickly. It sacrifices some Kubernetes-centric features of Kubeflow for sheer simplicity and has a bit less flexibility in terms of which cloud platform you use.
- Dagster delivers a data-centric orchestration approach with built-in observability and testing capabilities, creating a unified experience across data engineering and ML workflows unlike Kubeflow's infrastructure-heavy paradigm. Teams choose it for its rich UI, integrated testing, and Pythonic design.
- Pachyderm stands out when data lineage and incremental data workflows are the priority. It can replace or augment Kubeflow in data-heavy pipelines to ensure full reproducibility of the entire data-to-model journey.
Finding Your Path Beyond Kubeflow
Each of these alternatives offers a unique approach to solving the orchestration challenges that Kubeflow addresses—often with less complexity and more flexibility. Your ideal solution depends on your team’s specific needs, technical background, and existing infrastructure.
For ML platform engineers evaluating alternatives, consider these key questions:
- How important is developer experience versus infrastructure control?
- Do you need data-centric or execution-centric orchestration?
- Is your organization fully committed to Kubernetes, or do you need flexibility?
- Are you building just ML pipelines, or a broader data platform?
While we’ve presented these alternatives objectively, we at ZenML believe that modern ML orchestration should prioritize simplicity, flexibility, and developer productivity—principles that guided our own platform’s design. If you’re ready to experience frictionless ML pipeline orchestration without sacrificing production-readiness, ZenML Cloud offers a managed solution that combines the best of these approaches with enterprise support and advanced collaboration features.
The journey beyond Kubeflow doesn’t have to be daunting. Whether you choose a lightweight Python framework, a robust data-centric system, or a more flexible orchestration layer, the key is finding the solution that removes infrastructure barriers rather than creating them—letting your team focus on what matters most: delivering valuable ML models to production.


