On this page
ML engineers often struggle to decide which MLOps tool best fits their needs, especially when choosing between MLflow, Weights & Biases, and ZenML.
When you first think about it, comparing these three platforms might seem unusual, as all three have different primary focuses:
- MLflow is primarily an open-source experiment tracking and model management tool
- W&B is a cloud-based experiment tracking and visualization platform
- ZenML is an extensible pipeline orchestrator that can integrate with both and has built-in artifact and model versioning capabilities.
We’ve not written this comparison to compare and conclude which one out of these three is the best MLOps platform. Instead, we educate you about how to leverage these platforms in tandem to increase efficiency.
In this MLflow vs Weights & Biases vs ZenML article, we compare the features, integrations, and pricing, and learn about how ZenML can be used with MLflow and W&B to run ML pipelines in the most efficient way.
MLflow vs Weights & Biases vs ZenML: Feature Comparison
A TL;DR for the feature comparison:
| Capabilities | Best-suited |
|---|---|
| Experiment tracking |
|
| Model registry and Artifact versioning |
|
| Pipeline orchestration |
|
| Collaboration and visualization |
|
If you want to learn about how we came to the conclusions above, read ahead.
In this section, we compare MLflow, W&B, and ZenML across four key features:
- Experiment Tracking
- Model Registry & Artifact Versioning
- Pipeline Orchestration
- Collaboration & Visualization.
For each feature, we highlight how the three tools differ.
Feature 1. Experiment Tracking
MLflow
MLflow excels at experiment tracking. The platform’s tracking component provides an API and UI to log parameters, code versions, metrics, and output files from your ML code and then visualize results.
You can use MLflow Tracking in virtually any environment (as a script, in a notebook, on-prem or cloud) to record experiment runs. If pointed at a shared tracking server, multiple users can log and compare their runs in one place – teams can use MLflow to compare results from different users and runs.
MLflow’s strength lies in its simplicity and language-agnostic design – it works with Python, R, Java, or REST APIs, which means it can integrate with nearly any project.
It also supports auto-logging for popular libraries like TensorFlow and PyTorch, automatically capturing metrics and parameters during the model training process. This lowers the manual effort required to track experiments.
Weights & Biases
Weights & Biases was built specifically for experiment tracking and visualization. It offers one of the most polished tracking experiences. The platform lets you initialize a run in your training script wandb.init(...)** **and then log metrics, hyperparameters, and artifacts to the W&B cloud.
W&B’s experiment tracking automatically records nearly everything needed to reproduce and analyze experiments – for example, it saves the code version, all hyperparameter values, system metrics, model checkpoints, and even sample predictions from each run. All this information is synced to a centralized dashboard in real time.
A major benefit of W&B is that it’s hosted: there’s no need to set up your own server, and you get a web UI without any installation. This makes it extremely convenient for you and your team to start tracking experiments in minutes.
ZenML
ZenML approaches experiment tracking a bit differently. Out-of-the-box, it doesn’t replace dedicated experiment tracking tools; instead, it integrates with them. The platform is a framework to create pipelines, and it allows you to use ‘experiment tracker’ plugins (flavors) like MLflow or W&B within your ZenML pipeline runs.
In practice, this means you can log all your metrics and artifacts from each pipeline step to an external tracker while ZenML orchestrates the pipeline execution.
For example, you might have ZenML orchestrate a training pipeline and configure an MLflow experiment tracker in your stack, resulting in every pipeline run also creating an MLflow experiment run with all the parameters and metrics logged.
This gives you the benefits of MLflow tracking combined with ZenML’s pipeline management.
📚 Read more about how ZenML seamlessly tracks and visualizes ZenML pipeline experiments with MLflow: ZenML + MLflow integration.
📚 Read more about how you can supercharge your ZenML pipelines with Weights & Biases experiment tracking and visualization: ZenML + W&B integration.
**Bottom line: **Weights & Biases has a polished interactive dashboard that lets you track experiments efficiently. MLflow also has functionalities like auto-logging that helps you with tracking experiments. ZenML focuses on pipeline control and lets you plug in either MLflow or W&B for each run, giving you a choice while keeping your workflow coherent.
Feature 2. Model Registry and Artifact Versioning
MLflow
MLflow comes with a built-in Model Registry component, which serves as a central hub to manage the lifecycle of machine learning models.
Model Registry provides a centralized model store with a set of APIs and UI for managing model versions, stages, annotations, and lineage.
Using this concept, each model you log can be registered under a name, and new versions of that model are tracked automatically. What’s more, you can assign stages like ‘Staging’ or ‘Production’ to different versions, add notes or descriptions, and even trigger webhooks on stage changes.
Here’s a way to add a model to the registry with MLflow
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
from mlflow.models import infer_signature
with mlflow.start_run() as run:
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
params = {"max_depth": 2, "random_state": 42}
model = RandomForestRegressor(**params)
model.fit(X_train, y_train)
# Infer the model signature
y_pred = model.predict(X_test)
signature = infer_signature(X_test, y_pred)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_metrics({"mse": mean_squared_error(y_test, y_pred)})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="sklearn-model",
signature=signature,
registered_model_name="sk-learn-random-forest-reg-model",
)Artifacts like datasets, trained model files, etc., are also handled by MLflow whenever you log them in a run. Each run can save arbitrary artifact files (like a model .pkl, a CSV of results, images, etc.), which MLflow stores on a configured backend (local disk, S3, etc.).
Weights & Biases
Weights & Biases approaches dataset and model versioning through its Artifacts system. In W&B, an artifact is a versioned data item – typically a dataset, model file, or any file output of a run. W&B Artifacts provides a lightweight way to version and track datasets and models across your projects.
Every time you log a model (or any file) as a W&B artifact, W&B creates a versioned record of it. For example, you might log model.h5 as an artifact in run 1, and later in run 2 log another model.h5 – W&B will store both as separate versions under the artifact name ‘model.’
import wandb
run = wandb.init(project="artifacts-example", job_type="add-dataset")
artifact = wandb.Artifact(name="example_artifact", type="dataset")
artifact.add_file(local_path="./dataset.h5", name="training_dataset")
artifact.save()
# Logs the artifact version "my_data" as a dataset with data from dataset.h5On top of artifacts, W&B provides a Model Registry UI, which builds on artifact versioning. The W&B Model Registry gives teams a centralized repository to govern the model lifecycle, similar in goal to MLflow’s registry.
ZenML
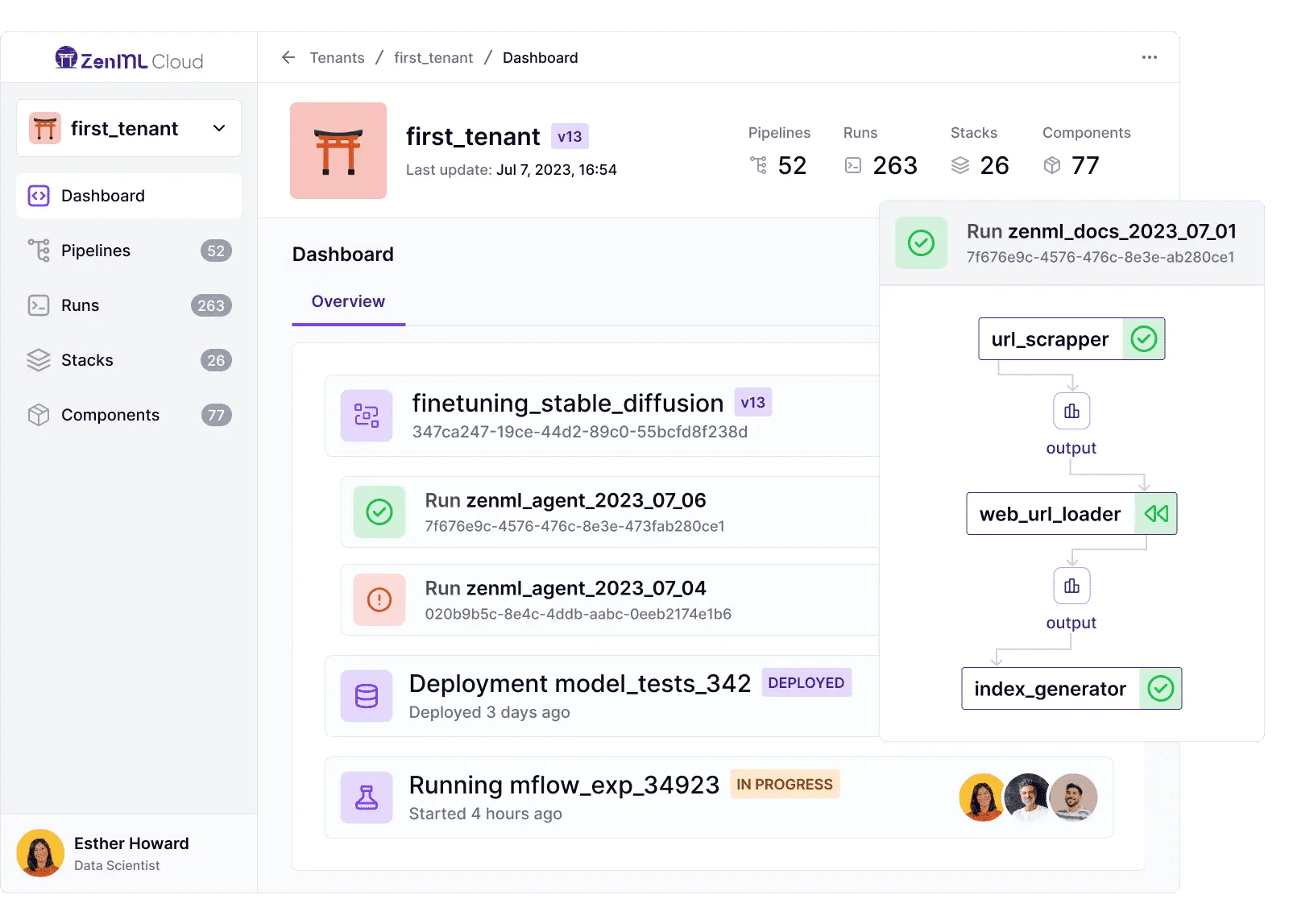
ZenML’s approach to model registry and artifacts is tightly connected to its pipeline and integration philosophy. In a ZenML pipeline, every step can produce outputs (artifacts) which ZenML stores in an artifact store (for example, a folder on a local disk, an S3 bucket, GCS, etc., depending on your stack configuration).
ZenML, therefore, inherently versions artifacts by pipeline runs – each pipeline run will have its own artifact directory or path, often timestamped or uniquely identified. ZenML’s metadata store keeps track of these artifact URLs and their lineage through the pipeline.
You get the Model Registry/Management feature with ZenML’s paid plans. The benefit ZenML brings to artifact and model management is the end-to-end lineage, because ZenML orchestrates the entire pipeline, it knows how a model was produced (which data, which code, which parameters), and where it was deployed.
You can create artifacts with ZenML with a few lines of code:
from zenml import pipeline, step
import pandas as pd
@step
def create_data() -> pd.DataFrame:
"""Creates a dataframe that becomes an artifact."""
return pd.DataFrame({
"feature_1": [1, 2, 3],
"feature_2": [4, 5, 6],
"target": [10, 20, 30]
})**Bottom line: **MLflow and Weights & Biases stand on par for model registry and artifact versioning, each giving full lineage and stage control. ZenML has a different take on how to do model registry and artifact versioning. It uses a more pipeline-oriented way - something that’s not comparable with the other two platforms.
Feature 3. Pipeline Orchestration
MLflow
When it comes to orchestrating multi-step pipelines like:
data preprocessing step > training step > evaluation > deployment
MLflow is not designed as a pipeline orchestrator. It’s a tracking solution and model management tool, and doesn’t have a built-in engine to define and schedule workflows that chain multiple components.
If you need to run a sequence of steps automatically, you would typically use MLflow alongside an external orchestrator like ZenML, Apache Airflow, Kedro, Prefect, or Kubeflow Pipelines.
Weights & Biases
Weights & Biases is also not a pipeline orchestration tool. It focuses on experiment tracking and related utilities like hyperparameter sweeps. You typically run your training code, and W&B logs the results; W&B does not have a feature that chains processes together with dependencies in a directed acyclic graph as a general pipeline.
That said, W&B does offer a couple of adjacent features: W&B Sweeps is a module for orchestrating hyperparameter search experiments. With Sweeps, W&B can launch multiple runs (with different hyperparameters) and manage them, either on your local machine or by interfacing with a cloud compute backend. This is a form of orchestration, but it’s specifically for parallelizing experiments (grid search, Bayesian optimization, etc.), not for sequential pipelines where each step’s output feeds the next.
Another feature is W&B Launch, which helps deploy training jobs to different environments, like sending this training to a Kubernetes cluster or SageMaker.
ZenML
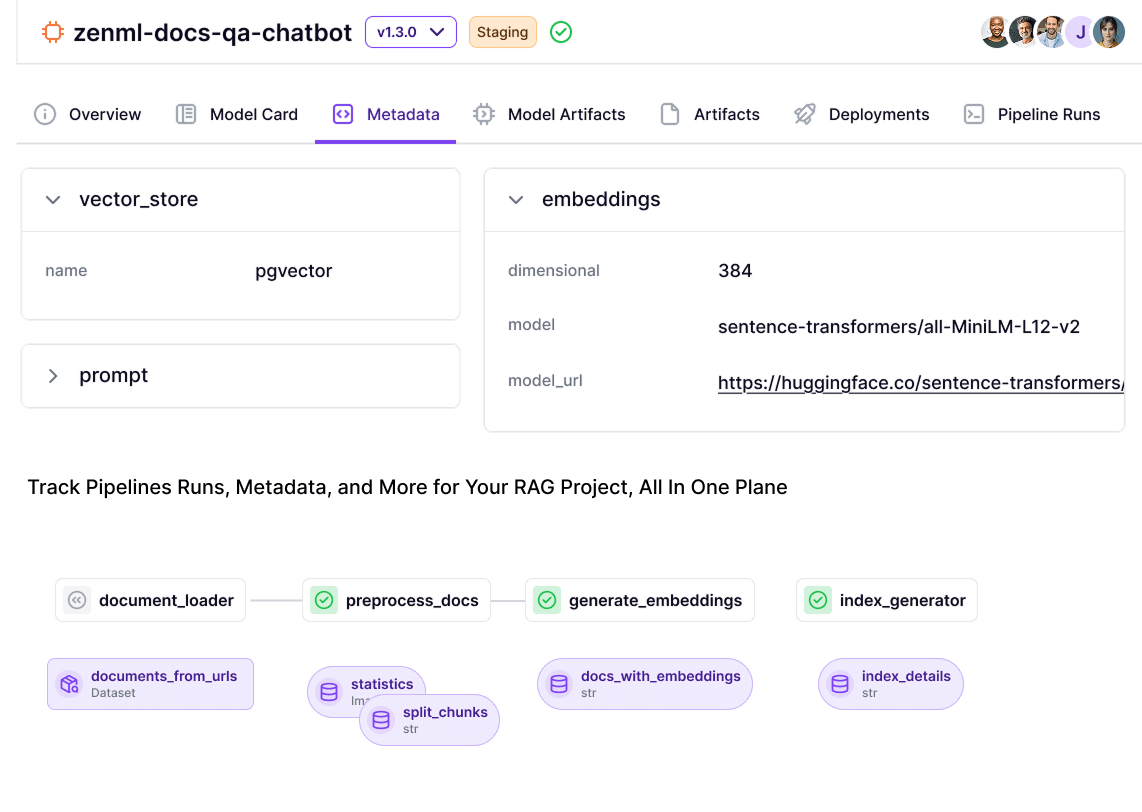
ZenML’s core purpose is pipeline orchestration with ML-specific conveniences. It takes a pipeline-centric approach to MLOps: you define steps as Python functions or classes and compose them into a pipeline, then ZenML handles running those steps in the correct order on the execution backend of your choice.
The key benefit is that you can develop your pipeline locally. For instance, run everything sequentially on your laptop for testing, and later run the same pipeline on a different orchestrator, like on a Kubernetes cluster or Airflow, without changing your pipeline code.
ZenML can plug into multiple orchestrators through its integration system – for example, it has integrations for Airflow, Kubeflow, Vertex AI, etc. – and even a simple local orchestrator for development.
Because ZenML was built to make pipelines first-class, it has features like:
- Caching of steps, so if data hasn’t changed, you don’t re-run a step
- Artifact passing, outputs of one step, can be automatically passed to the next step
- Configuration management
Bottom line: For pipeline orchestration and workflow automation, ZenML provides a unified and extensible approach. Neither MLflow nor W&B aim to do this, so ZenML fills that gap. If you have complex pipelines or want to productionize your ML code with scheduled runs, retries, and use of cloud services, ZenML is a strong choice to simplify that process.
# zenml integration install kubeflow
# zenml orchestrator register kf_orchestrator -f kubeflow ...
# zenml stack update my_stack -o kf_orchestrator
from zenml import pipeline, step
@step
def preprocess_data(data_path: str) -> str:
# Preprocessing logic here
return processed_data
@step
def train_model(data: str):
# Model training logic here
return model
@pipeline
def my_pipeline(data_path: str):
processed_data = preprocess_data(data_path)
model = train_model(processed_data)
# Run the pipeline
my_pipeline(data_path="path/to/data")Feature 4. Collaboration and Visualization
MLflow
Collaboration in MLflow’s open-source offering is mostly achieved by sharing the tracking server among team members. If a team sets up an MLflow Tracking Server with a backing store like SQL and a file store or S3 for artifacts, everyone can log to the same server and see each other’s runs on the MLflow UI. In this sense, MLflow supports collaboration by providing a centralized experiment database. However, MLflow’s UI is relatively basic compared to W&B.
Another aspect is permissions and sharing. MLflow (open source) doesn’t have user accounts or authentication features; it’s usually deployed within a secure environment or with a simple authentication proxy if needed. So everyone with access to the server sees the same projects and experiments.
Weights & Biases
Collaboration is a core strength of Weights & Biases. Because W&B is a hosted platform by default, all your experiment results are available on a web interface that can be shared with team members.
You can organize runs into projects, and each project can be private to your team or public if you want it to be. With W&B Teams, multiple users can be part of an organization and share projects automatically.
One standout feature of W&B is Reports. The feature lets you take plots from your runs and arrange them with text into a report (think of it like a shareable research paper or dashboard) and then send that to others.
This is great for collaboration because it turns raw experiment data into a narrative. Team members can collaboratively build reports or annotate findings.
W&B also offers alerts and notifications, which help when collaborating – for instance, sending a Slack message to the team when a run finishes or when a metric is achieved.
From a visualization perspective, W&B provides powerful tools: custom charts, parallel coordinates plots for hyperparameters, embedding projector for viewing high-dimensional data, confusion matrices, and more.
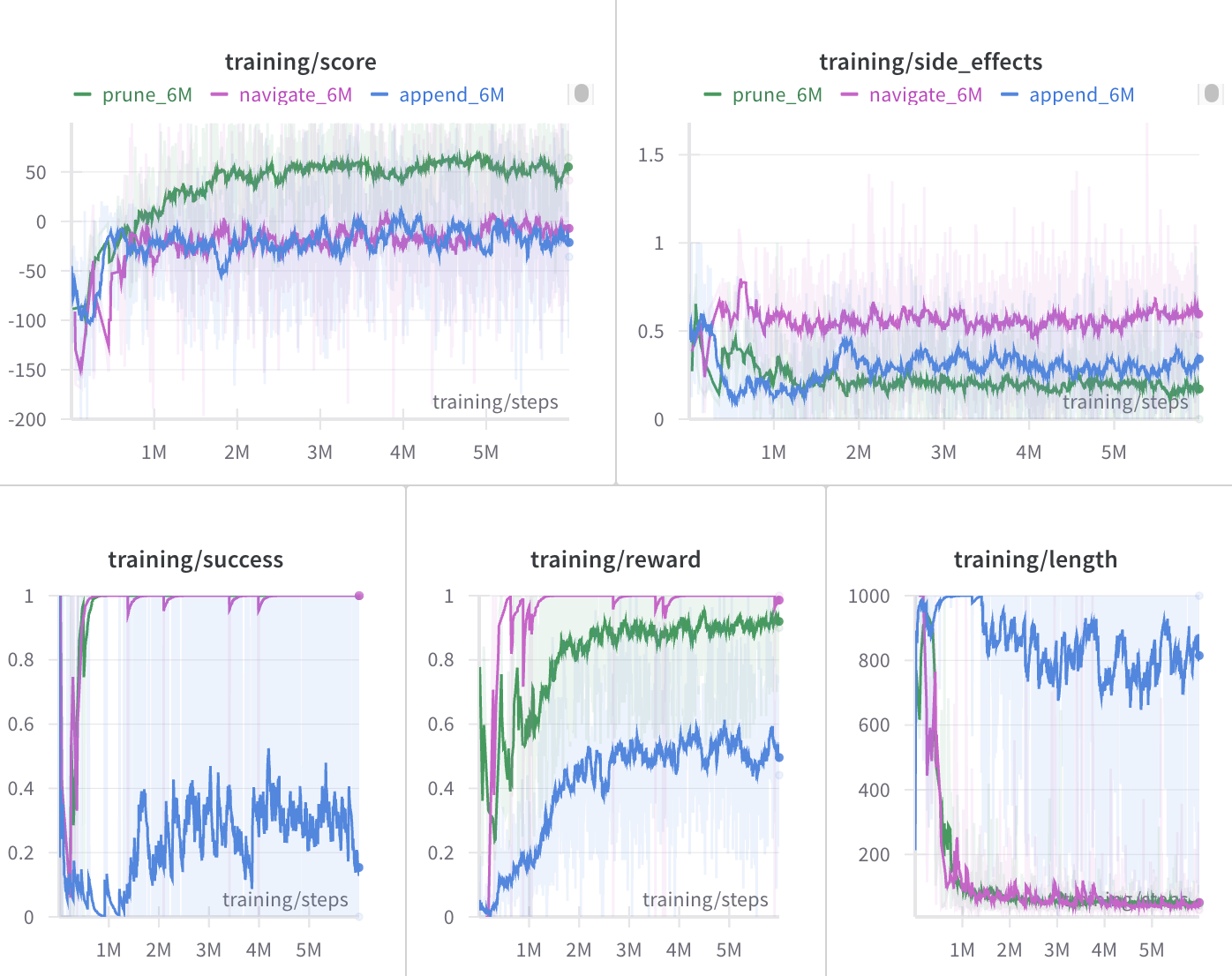
ZenML
ZenML approaches collaboration from the angle of reproducibility and integration. By using ZenML, team members codify their ML pipelines in a standardized way.
This means any team member can run the same pipeline and expect the same results (assuming access to the same data and infrastructure), which is a huge plus for collaboration between research and production teams.
Additionally, ZenML’s numerous integrations - 50+ plugins for various tools foster a sort of collaboration across tools. For example, one person might prefer using MLflow for experiment tracking while another prefers W&B. In a ZenML-driven project, you could actually accommodate both by switching out the experiment tracker integration, while the rest of the pipeline remains consistent.
When it comes to visualization, ZenML provides built-in capabilities to visualize artifacts, helping you gain insights into your data, model performance, and pipeline execution.
ZenML Pro significantly enhances collaboration through comprehensive Role-Based Access Control (RBAC) with detailed permissions across organizations, workspaces, and projects.
Teams can implement sophisticated access patterns like Organization Admins overseeing all resources, Workspace Developers managing specific projects, and Stack Admins handling infrastructure.
The system supports resource ownership models, cross-workspace sharing, and team-based permission management, enabling secure collaboration scenarios from research-to-production handoffs to multi-region development while maintaining compliance and audit trails.
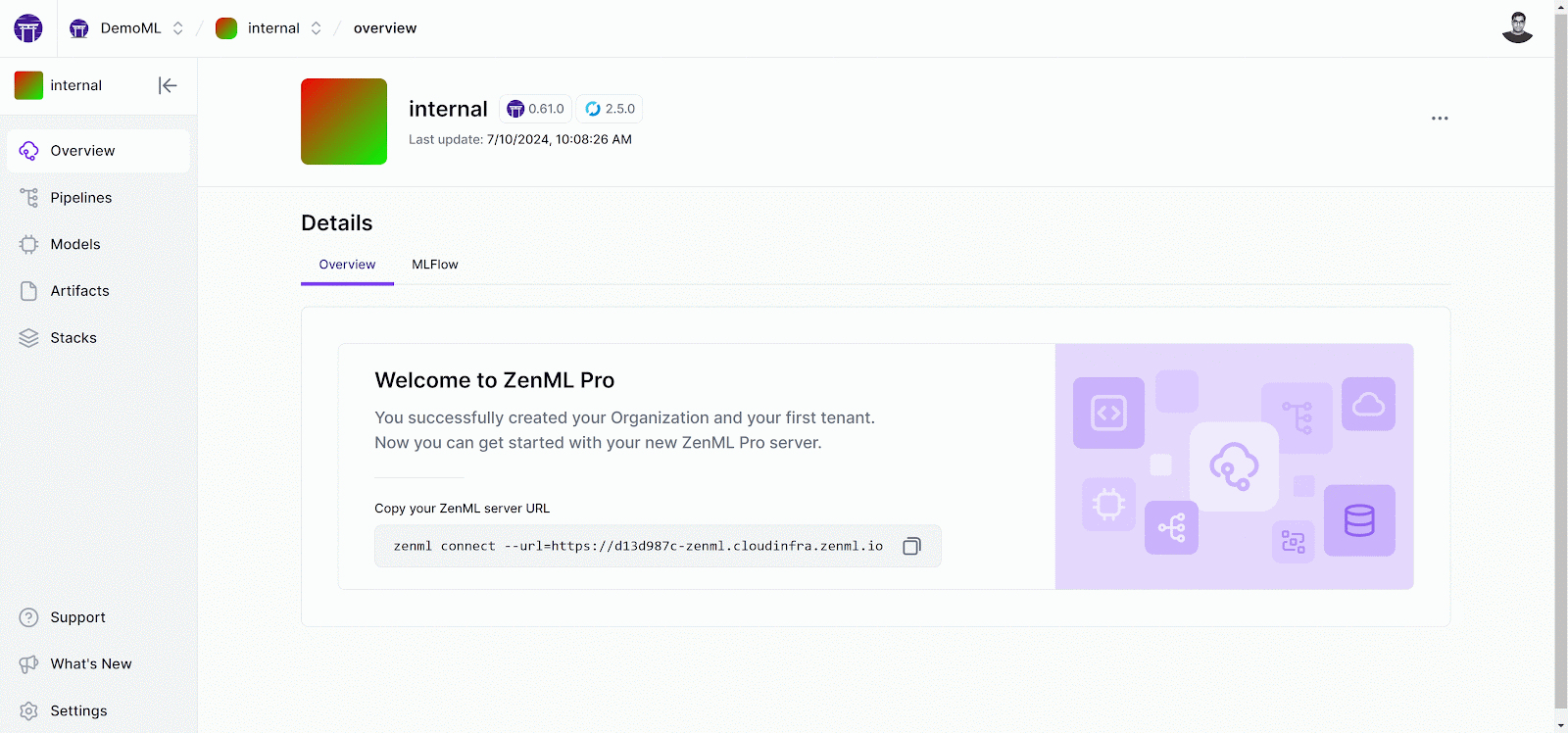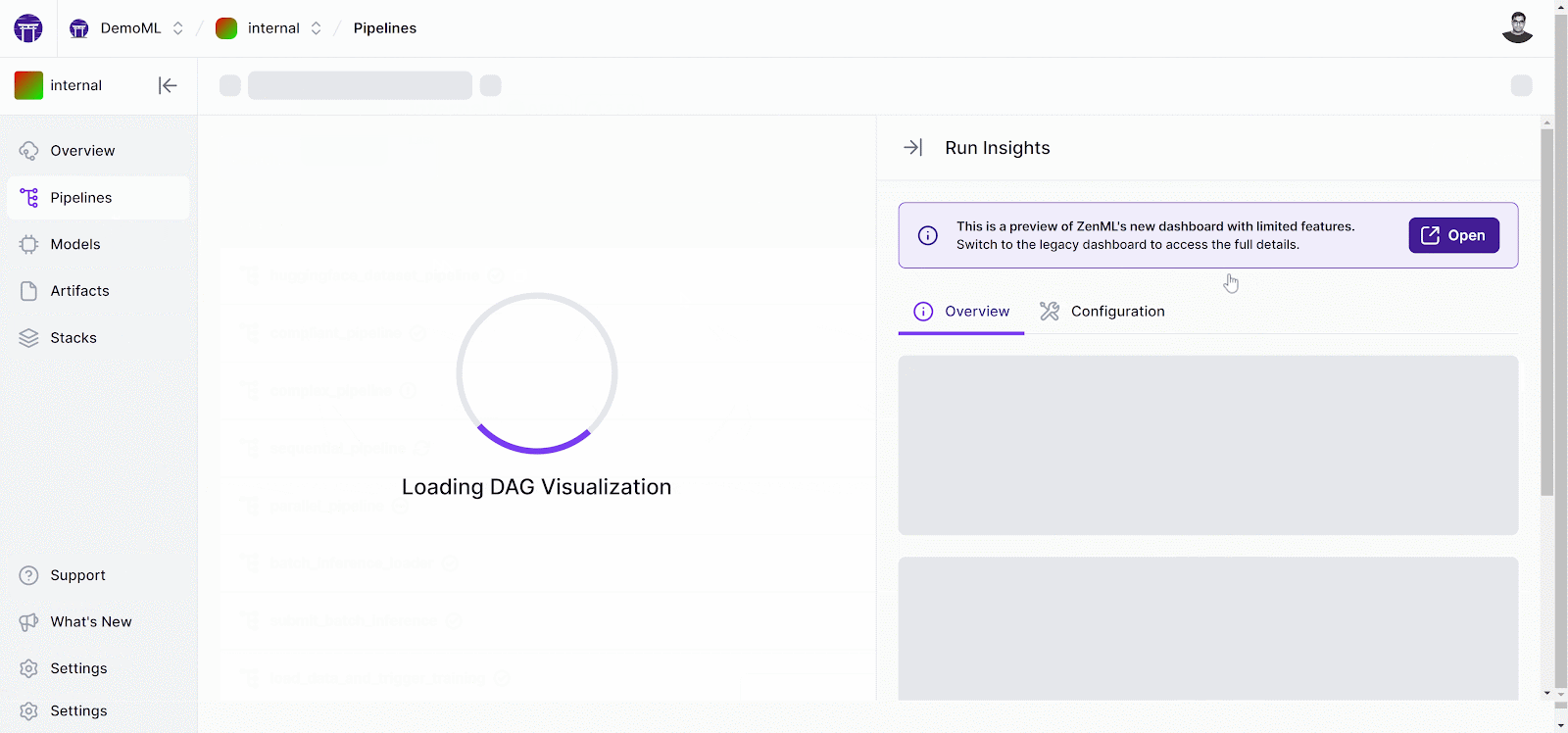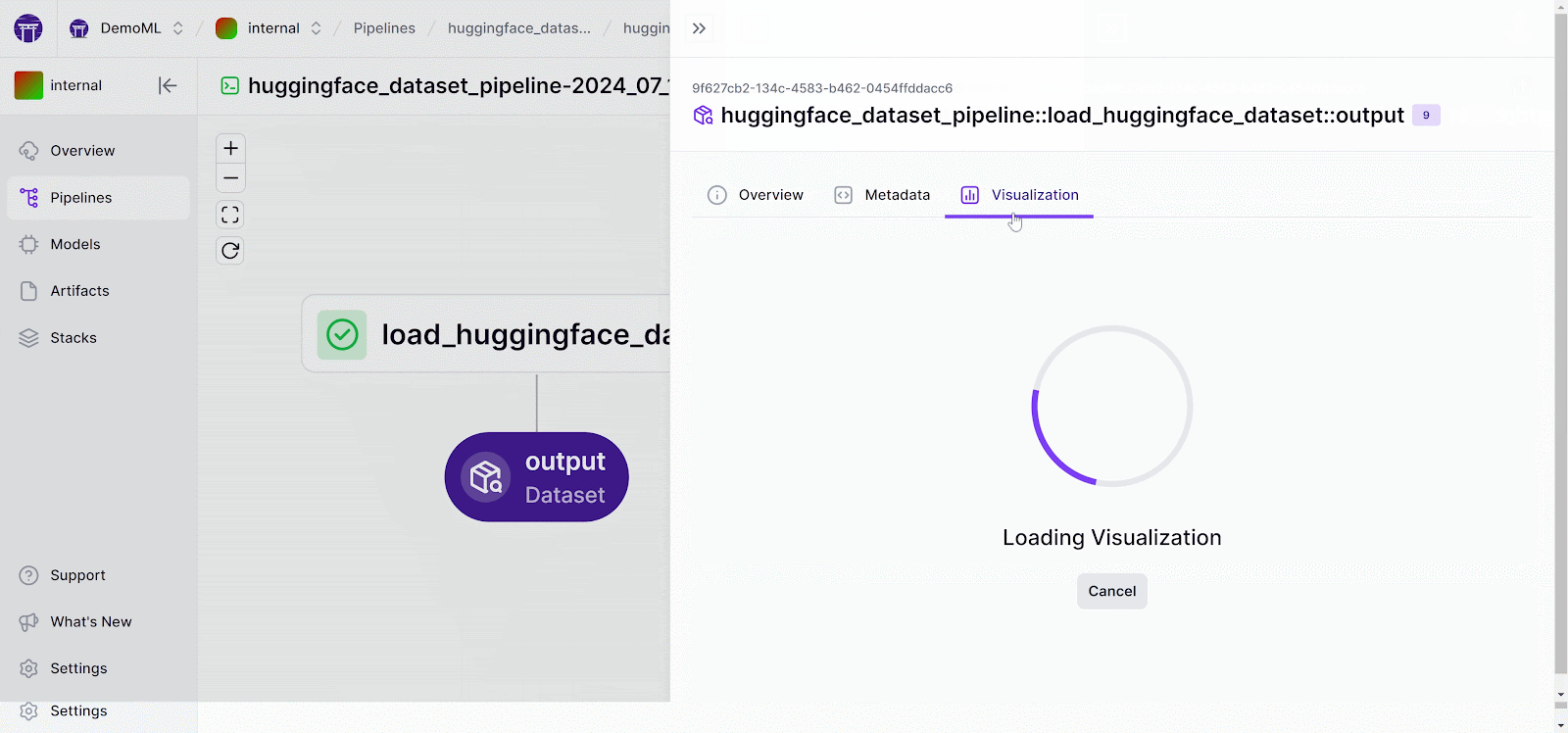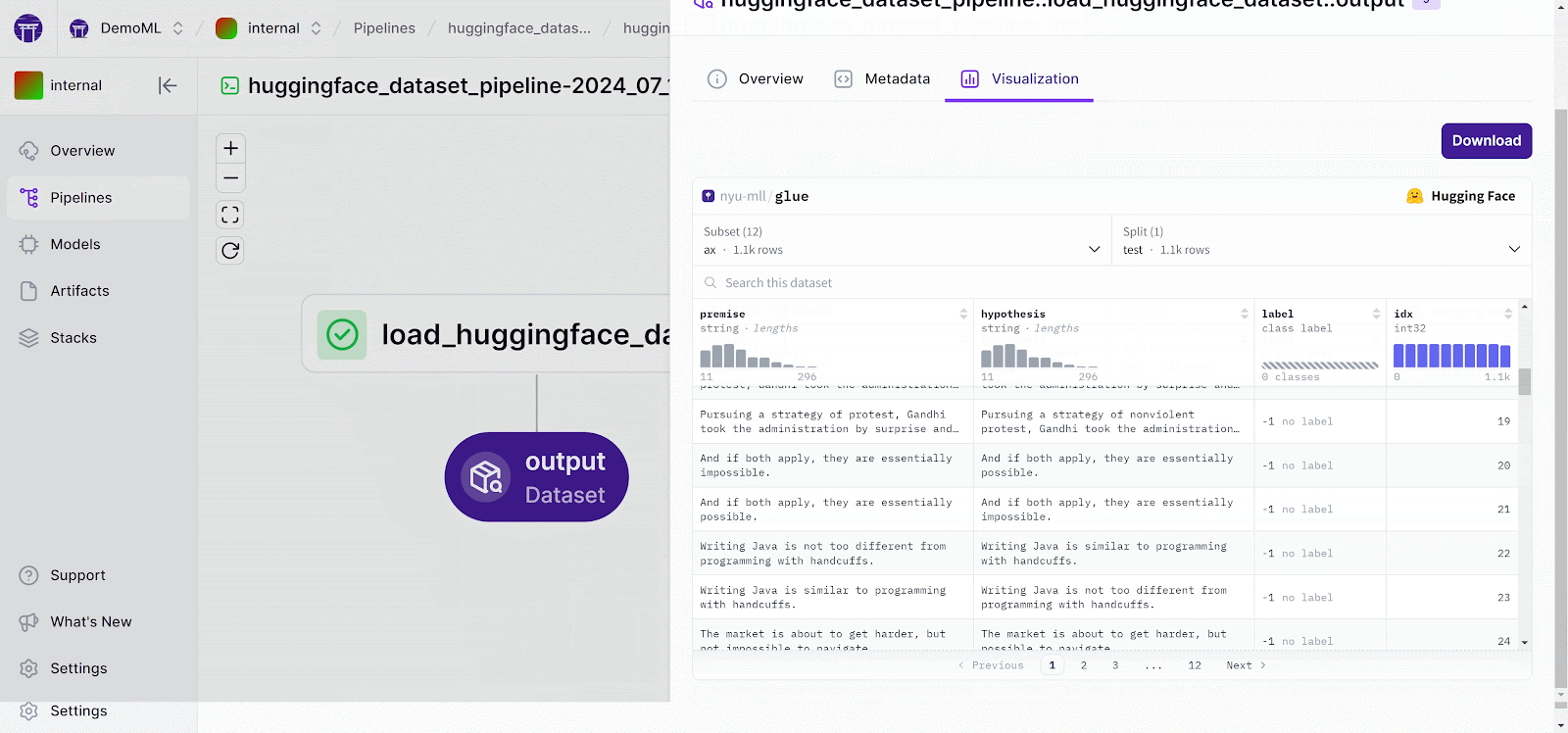
Bottom line: W&B leads with shared web projects and deep visual reports. MLflow offers a simple shared server for basic teamwork. ZenML delivers efficient collaboration by standardizing pipelines, letting teams swap in either tracker, and adding artifact visuals that keep research and production aligned.
MLflow vs Weights & Biases vs ZenML: Integration Capabilities
MLflow

MLflow is designed to be library-agnostic and works with any ML code via its APIs. It supports Python, R, Java, and REST interfaces, which means you can use MLflow tracking in most environments with minimal fuss.
MLflow also provides auto-logging integrations for many popular frameworks:
- TensorFlow
- Keras
- PyTorch
- XGBoost
- LightGBM
- Scikit-learn and more.
So that it can automatically capture parameters and metrics without much code modification.
On the model deployment side, MLflow integrates with cloud services and container tools: for example, you can deploy an MLflow model to AWS SageMaker or Azure ML, or package it into a Docker container using MLflow’s command-line interface.
Weights & Biases
W&B provides SDKs for Python and also has clients for other languages - there’s a lightweight client for JavaScript, for example, for logging from web apps.
W&B has a long list of integrations for ML frameworks and environments – these include direct integrations with:
- TensorBoard
- Keras
- PyTorch Lightning
- Hugging Face Transformers
- Scikit-learn
- XGBoost
- Non-ML things like Roblox for reinforcement learning logging
W&B integrates with cloud compute providers: for instance, it has plugins to easily use W&B on AWS SageMaker jobs or Google Colab.
One notable integration is with Jupyter notebooks – W&B can automatically save your notebook and its requirements for each run, aiding reproducibility.
ZenML
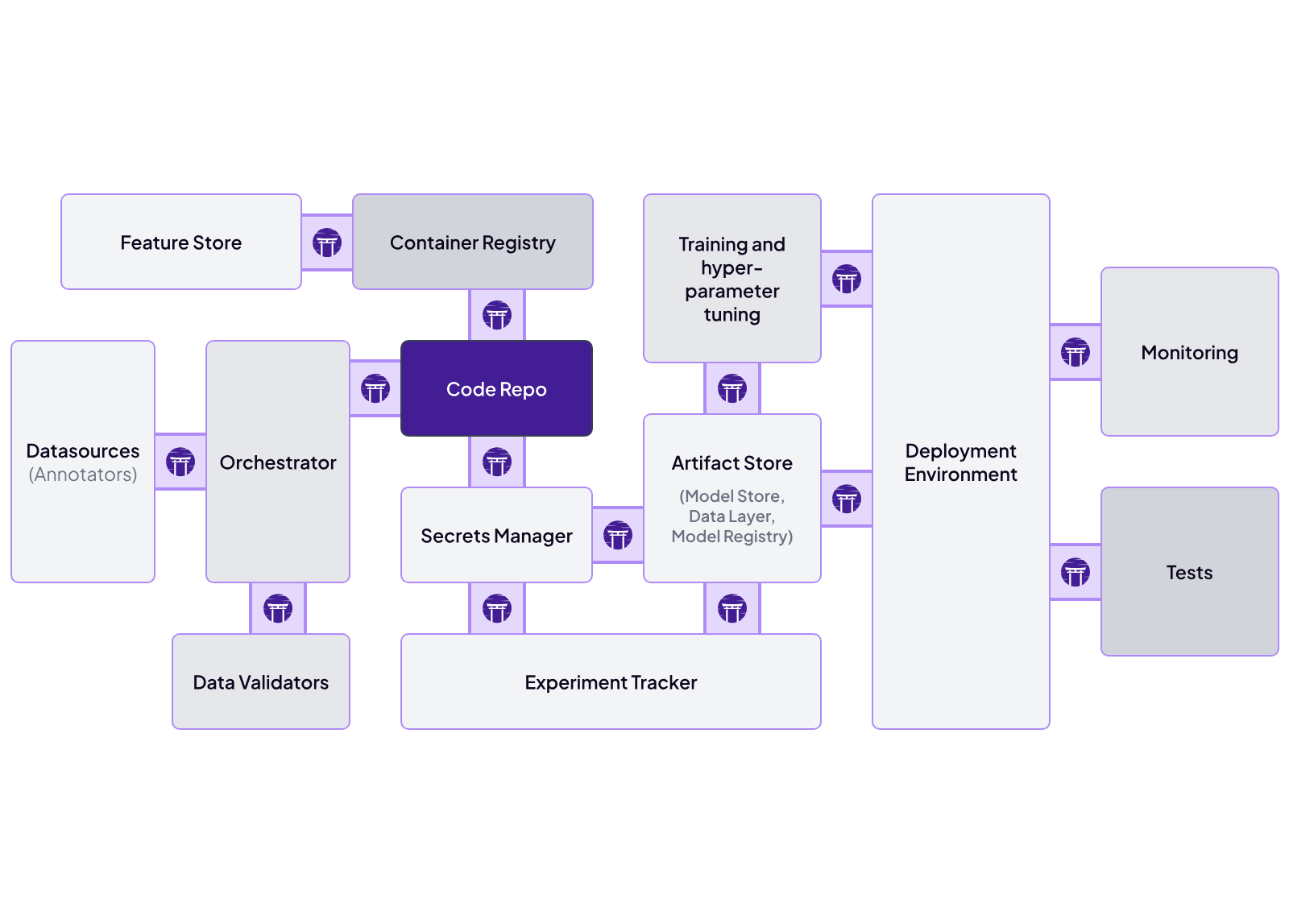
ZenML is all about integrations – it provides a unified interface to over 50 different MLOps tools and frameworks across the pipeline stack.
ZenML has a concept of ‘stack components’ for things like orchestrators, experiment trackers, data artifact stores, model registries, feature stores, model deployers, and more. Each of these components can have different flavors (for example, an orchestrator could be Airflow, Kubeflow, local, etc.).
ZenML’s MLflow integration enables teams to use MLflow for both experiment tracking and model registry within ZenML pipelines. The integration automatically handles MLflow run creation and management, linking each ZenML pipeline step to the corresponding MLflow runs.
The W&B integration allows teams to use Weights & Biases’ sophisticated tracking and visualization capabilities within ZenML workflows. ZenML automatically creates W&B runs for pipeline steps configured with the W&B experiment tracker, enabling real-time monitoring and rich visualizations.
Beyond MLflow and W&B, ZenML’s integration architecture supports over 50+ tools across different MLOps categories. The platform’s pluggable stack system includes:
- Multiple orchestrators: Airflow, Kubeflow, Google Cloud Composer, Tekton
- Experiment trackers: Neptune, TensorBoard, Comet
- Model registries: AWS SageMaker Model Registry, Google Vertex AI Model Registry
- Artifact Store: Amazon S3, Azure Blob Storage, Google Cloud Storage
And many more.

MLflow vs Weights & Biases vs ZenML: Pricing
MLflow
MLflow is completely open-source and free for self-deployment on any infrastructure, giving teams full control over their experiment tracking and model registry without licensing costs.
Managed MLflow services include:
- Databricks MLflow: Fully integrated MLflow experience within Databricks, with pricing based on Databricks compute units and storage consumption rather than separate MLflow fees.
- AWS SageMaker MLflow: Managed MLflow tracking server starting at $0.642/hour for ml.t3.medium instances, plus separate charges for artifact storage in S3.
- Azure Machine Learning with MLflow: Built-in MLflow integration with pricing based on Azure ML compute instances and storage usage.
- Nebius Managed MLflow: Dedicated MLflow clusters starting at approximately $0.36/hour for 6 vCPUs and 24 GiB RAM configurations.

Weights & Biases
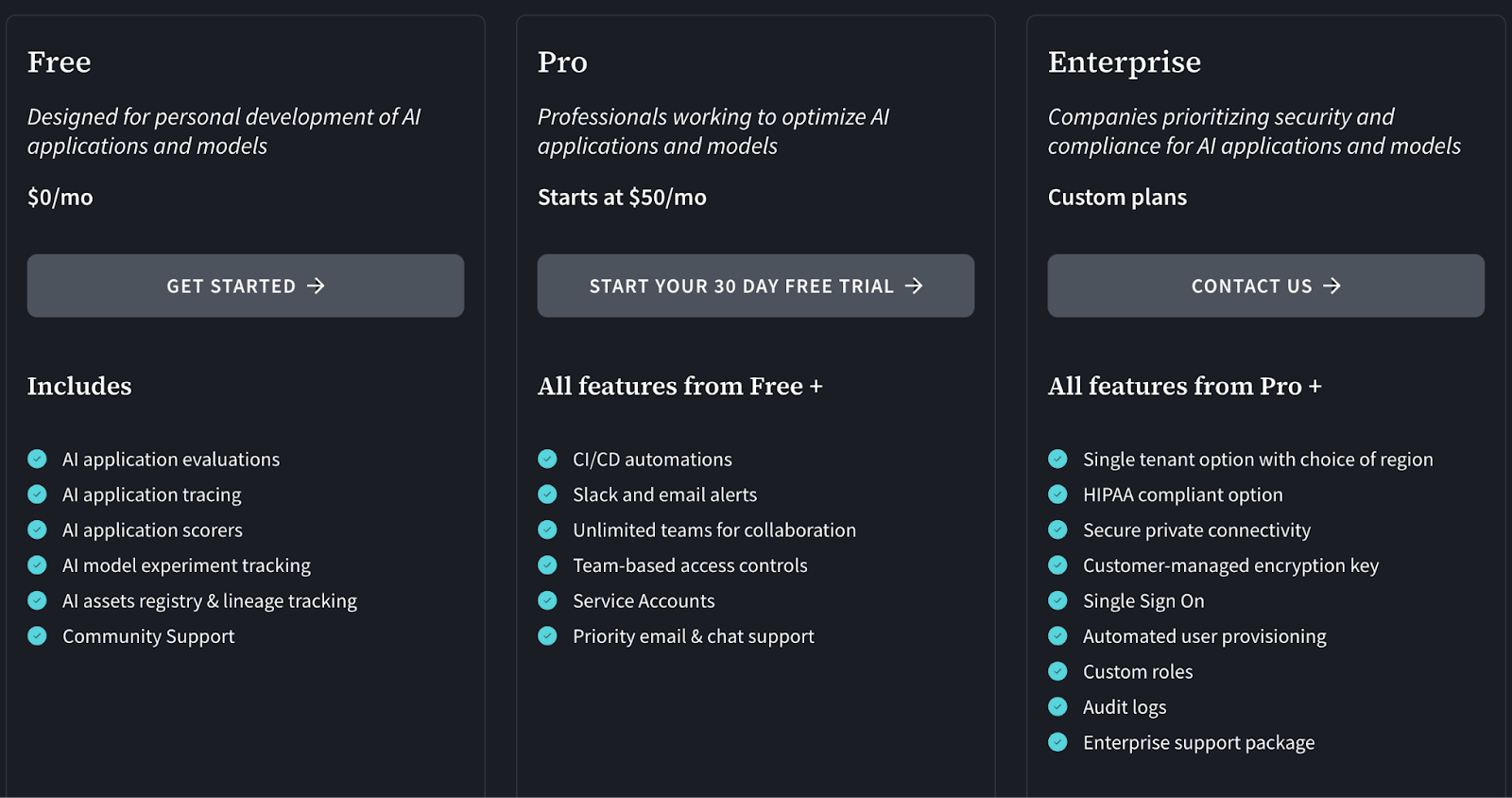
W&B offers a free plan designed for the personal development of AI applications and models and has multiple paid plans to choose from:
- Pro: Starts at $50 per month
- Enterprise: Custom pricing
The above plans are for cloud-hosted platforms. W&B also offers privately-hosted plans that cost $0 per month for 1 user seat and basic features. To get a more advanced plan, contact W&B for its Advanced Enterprise plan and pricing.
ZenML
ZenML has a simple and pretty straightforward pricing compared to MLflow and W&B. The platform offers an open source version, ideal for individuals and small projects. Apart from the open source plan, ZenML has two paid plans to choose from:
- Basic: $25 per month
- Scale: Custom pricing
With its Basic paid plan, you get a 14-day free trial.
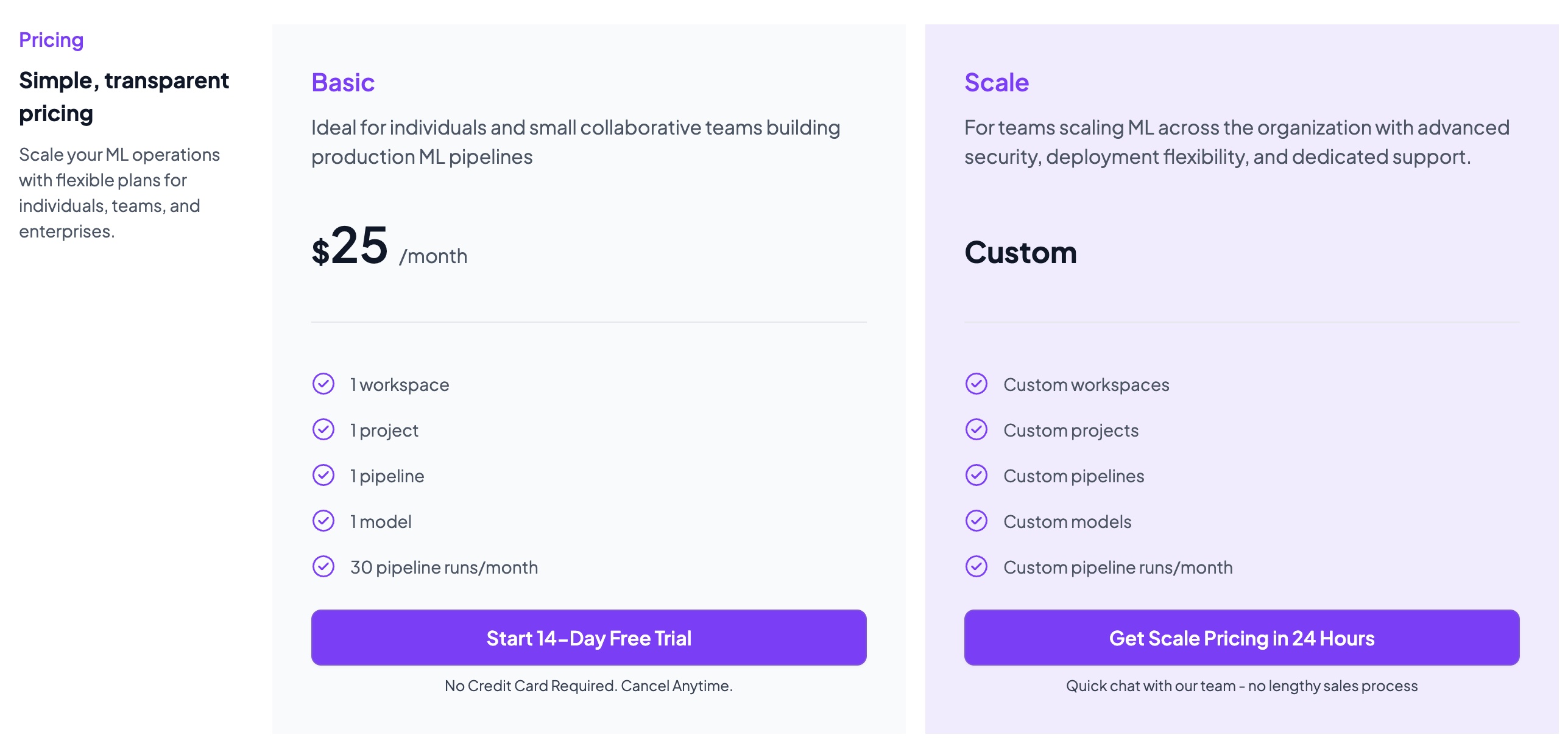
The Scale plan is a custom solution that has limits and features depending on your needs. You can book a demo with us and get all the details in less than 24 hours.

Which MLOps Platform Is Best For You?
Choosing among MLflow, Weights & Biases, and ZenML depends on your specific needs and use cases. Each platform shines in different scenarios, and in many cases, you might actually use them together. Here’s some guidance:
✅ Choose MLflow if you need an open-source, flexible experiment tracking and model management solution that you can self-host.
✅ Choose Weights & Biases if your priority is a superb user experience for experiment tracking and you want powerful visualization and collaboration features.
✅ Choose ZenML if you need a pipeline-centric MLOps framework that can tie all your tools together and take you from experimentation to production seamlessly.

So instead of just leveraging any one of them, why not leverage all of them via ZenML? Book a personalized demo with our (ZenML’s) founder and get to know how to use all three platforms in tandem.