On this page
Scaling MLOps: From Proof of Concept to Production in Retail Forecasting
In the fast-paced world of retail analytics, the journey from running a single proof-of-concept machine learning model to deploying dozens of production models is filled with interesting challenges. This post explores common hurdles organizations face when scaling their ML operations and offers practical solutions for building robust, scalable MLOps infrastructure.
The Challenge of Model Proliferation
As businesses grow and acquire more customers, the need for specialized ML models often grows exponentially. What starts as a simple forecasting model for one retail location can quickly evolve into a requirement for dozens or even hundreds of customer-specific models. This proliferation introduces several key challenges:
- Infrastructure Scaling: Moving from local development to production-grade infrastructure
- Model Management: Tracking and organizing multiple model versions across customers
- Deployment Workflows: Standardizing the process of moving models from development to production
- Resource Optimization: Balancing computational resources across multiple training pipelines
Building a Scalable MLOps Foundation
Standardized Pipeline Architecture
The key to handling multiple customer-specific models lies in creating a standardized, reusable pipeline architecture. Instead of building separate pipelines for each customer, focus on creating a single, configurable pipeline that can:
- Accept different customer data sources
- Handle varying data schemas and formats
- Produce customer-specific models
- Maintain isolation between different customer contexts
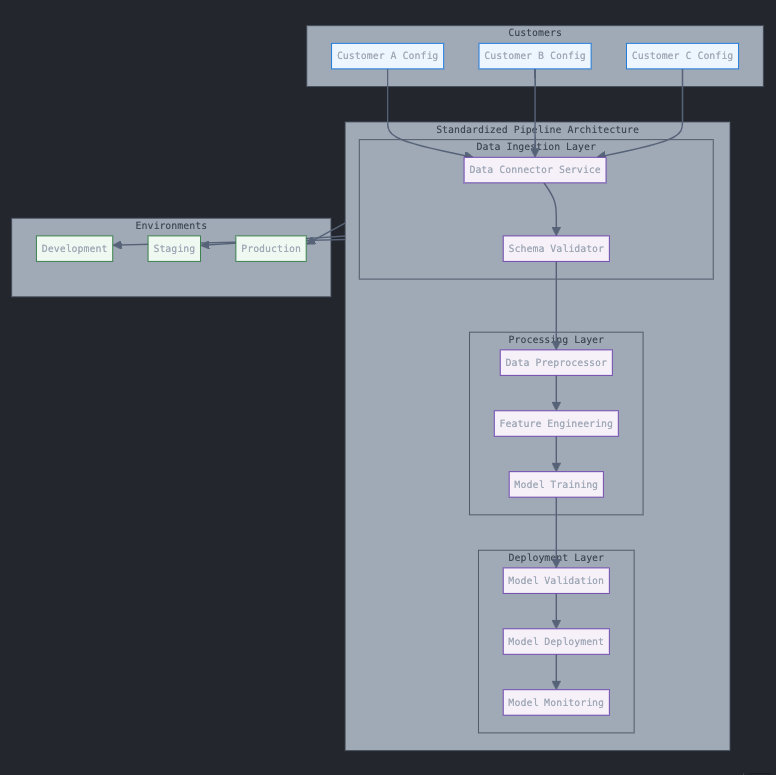
Environment Management Strategy
When scaling MLOps across different environments (development, staging, production), consider these best practices:
- Infrastructure Separation: Maintain distinct clusters for production and non-production workloads
- Configuration Management: Use environment-specific configurations while keeping pipeline code consistent
- Access Control: Implement proper RBAC and security measures across environments
- Artifact Management: Establish clear policies for model artifact promotion across environments
Advanced Model Management Considerations
As your model fleet grows, consider implementing these management strategies:
Version Control and Tagging
Implement a robust versioning system that includes:
- Semantic versioning for models
- Environment-specific tags (dev, staging, prod)
- Customer-specific identifiers
- Performance metadata
Automated Model Lifecycle
Create automated workflows for:
- Model training and validation
- A/B testing new versions
- Promotion between environments
- Performance monitoring
- Rollback procedures
Future-Proofing Your MLOps Stack
Organizations need to think ahead about:
- Scalability: Building infrastructure that can handle 10x current capacity
- Monitoring: Implementing comprehensive observability across all models
- Governance: Establishing clear policies for model deployment and updates
- Resource Management: Optimizing computing resources across multiple training jobs

Conclusion
Scaling MLOps from a single model to dozens of production models requires careful planning and robust infrastructure. The key is building standardized, repeatable processes while maintaining flexibility for customer-specific requirements. Focus on creating strong foundations in pipeline architecture, environment management, and model governance to support sustainable growth.
As the field continues to evolve, organizations must stay adaptable while maintaining operational excellence. The investment in proper MLOps infrastructure today will pay dividends as ML operations continue to scale tomorrow.


