

On this page
Unlike traditional software with deterministic logic, LLMs behave in an unpredictable way. Their failures are often silent, subjective, and difficult to pin down.
How do you prove a model’s response is ‘better’ than it was yesterday? How do you guard against hallucinations? In this market, you just can’t ‘build and deploy on guesswork.’
To build truly robust AI products, you need specialized tools designed to evaluate and test your LLM. This guide cuts through the noise. It provides a clear, engineer-focused analysis of the best LLM evaluation tools on the market today.
Factors to Consider when Selecting the Best LLM Evaluation Tools to Use
The best tool is not the one with the longest feature list. It’s the one that aligns with your project’s requirements across four key areas: metric coverage, RAG-specific capabilities, security testing, and reproducibility.
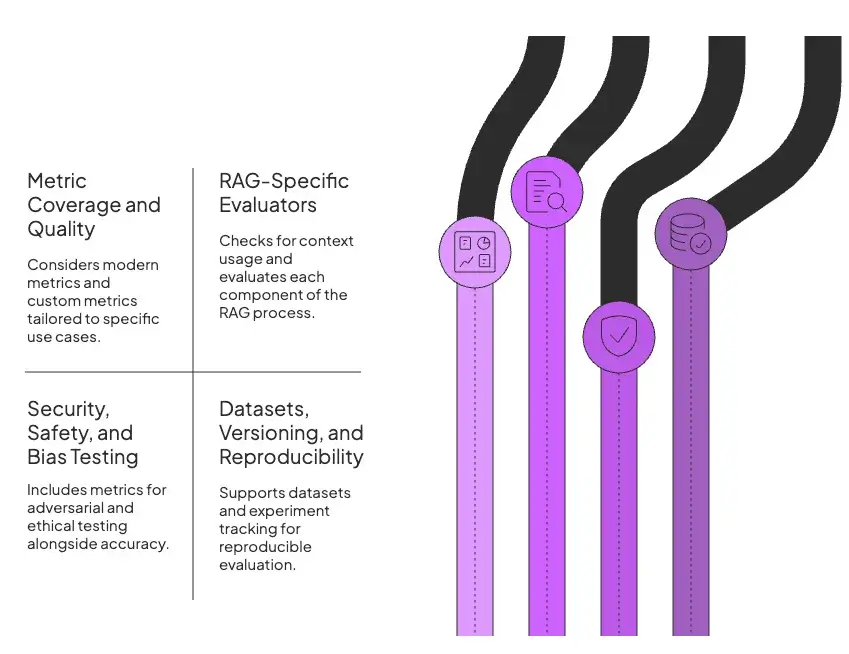
1. Metric Coverage and Quality
First and foremost, consider the tool’s metric coverage.
While most frameworks offer classic metrics like BLEU, these can be misleading as they often low-ball valid responses for simply using different wording.
To counter this, modern tools now utilize ‘learned metrics’ like BERTScore and LLM-as-a-judge to more effectively evaluate qualities such as coherence, relevance, and correctness in a human-like manner.
Ultimately, no single metric is sufficient. And so, your ideal LLM evaluation tools should also allow for custom metrics tailored to your specific use cases.
2. RAG-Specific Evaluators
When selecting a tool, check if it offers RAG-specific evaluators or the ability to incorporate custom checks for context usage. This is essential if your LLM works with external knowledge or tools.
Evaluating a RAG pipeline requires a specific set of metrics that assess each component of the process. The most critical are:
- Context Precision and Recall: Measures the quality of the retrieval step. Did the system retrieve relevant documents (recall) without retrieving irrelevant ones (precision)?
- Faithfulness: Assesses the generation step. Is the answer generated only from the provided context, without hallucinations?
- Answer Relevance: Checks if the generated answer actually addresses the user's original query.
If you are building RAG systems or other context-grounded LLM apps, ensure the tool supports these unique evaluation needs.
Note: Not all LLM evaluators handle this well, so specialized tools like RAGAS or TruLens excel in this area.
3. Security, Safety, and Bias Testing
LLMs are prone to unwanted behaviors, from leaking private data to generating biased or harmful content. This can be prompt-initiated or an internal mistake.
However, the best evaluation frameworks must include metrics for adversarial and ethical testing alongside accuracy.
Beyond adversarial attacks, look for tools that also test for bias and fairness with metrics for toxicity, bias, or hate speech in outputs.
4. Datasets, Versioning, and Reproducibility
Finally, consider the tool’s support for datasets and experiment tracking, which is crucial for reproducible evaluation. A single evaluation run is not very useful if you can’t repeat it later or trace which model/prompt version was tested.
The top LLM eval tools provide features like versioned evaluation datasets, logging of model and prompt versions, and integration with experiment trackers.
What are the Best LLM Evaluation Tools
| Tool | Best For | Key Evaluation Features | Pricing |
|---|---|---|---|
| ZenML | Teams needing a unified MLOps + LLMOps foundation | - Provides recipes and stack integration - Artifact tracking and reproducibility - ZenML pipelines are the perfect fit for evals | Free (open-source) + paid |
| RAGAS | Evaluate retrieval and generation in RAG systems | - Context Precision and Recall - Faithfulness metric and custom evaluators - Integration with LangChain | Free (open-source) |
| Trulens | Agentic workflows and RAG systems | - Trace instrumentation - Feedback functions (groundedness, relevance) - Leaderboard & debugging UI | Free (open-source) |
| LangSmith | LLM apps built using LangChain | - Trace logging - LLM-as-judge evaluation - Human feedback queue - Prompt and dataset versioning | Free; Plan starts at $39 per month |
| DeepEval | Unit testing LLM outputs in a CI/CD workflow | - 30+ ready-made eval metrics - Red-teaming attacks - Unit-test style assertions | Free; Paid plans start at $19.99 per month |
| W&B Weave | Deep experiment comparison and visualization | - Full trace logging - Built-in scorers - Run comparisons via visuals | Free; Paid plans start at $60 per month |
| Humanloop | Collaborative LLMOps and evaluation | - Offline/online evals - Human-in-the-loop scoring - Prompt experimentation and real-time monitoring | Free and Enterprise |
| OpenAI Evals | Standardized benchmarking and custom evaluations | - Flexible eval harness - LLM-as-judge patterns - Registry of community evals | Free (Pay-per-use) |
| MLflow | Teams already using MLflow for experiment tracking | - mlflow.evaluate API- Versioned eval dataset - Tracking metrics and artifacts | Free; Paid cloud options available |
1. ZenML
ZenML is more than just an MLOps + LLMOps platform; it’s a unified framework for evaluating, orchestrating, and scaling LLM systems. With built-in support for model evaluation, experiment tracking, and RAG-specific metrics, ZenML helps teams close the outer loop around their AI workflows, from data ingestion to post-deployment testing.
Features
- Unified LLMOps and Evaluation Framework: ZenML integrates evaluation directly into its pipeline architecture, allowing teams to run and compare LLM performance across datasets, prompts, and model versions, all within one reproducible workflow.
- RAG evaluation patterns and integrations: Rather than ‘built-in metrics,’ ZenML provides recipes and stack integrations to evaluate retrieval and generation, so you can compute things like context precision/recall, faithfulness, and answer relevance using the tools you choose, while ZenML handles pipelines, runs, and artifact lineage.
- Artifact Tracking and Reproducibility: Every evaluation run is versioned. You can trace which model, prompt, dataset, and evaluation logic produced which metrics, ensuring perfect auditability and experiment reproducibility.
- Integrations with LLM Ecosystem: ZenML supports integrations with LangChain, LangSmith, Weights & Biases, MLflow, and Hugging Face, making it easy to plug evaluation into existing AI workflows.
Pricing
We are upgrading our platform to bring every ML and LLM workflow into one place for you to run, track, and improve. Think of processes like data preparation, training, RAG indexing, agent orchestration, and more, all in one place.
Pros and Cons
ZenML offers pipeline-first visibility with an interactive DAG, run history, artifact lineage, and step logs, making debugging simple. It integrates cleanly with experiment trackers and supports autologging.
But remember, ZenML is not a specialized LLM observability or a one-click QA solution – it’s a framework.
2. RAGAS

RAGAS is an open-source Python framework purpose-built for the nuanced tasks of evaluating RAG pipelines. It specializes in metrics for context-grounded QA and generative models, providing a programmatic toolkit to score how well an LLM uses retrieved context.
Features
- Provides specialized RAG metrics like Context Precision, Context Recall, Faithfulness, and Response Relevance.
- Uses both classic BLEU and ROUGE metrics, as well as LLM-powered evaluators for deeper analysis.
- Creates evaluation datasets and synthetic test cases to probe your model in the absence of a labeled benchmark.
- Built to plug into popular LLM pipelines. It works with LangChain and even integrates with observability platforms and vector databases.
Pricing
RAGAS is a fully open-source framework and is free to use. A critical consideration, however, is that its primary evaluation metrics rely on making API calls to powerful LLMs like GPT-4. The maintainers offer community support on Discord and conduct office hours for users, but all features are available in the open-source package.
Pros and Cons
RAG evaluation is core to RAGAS, making it a major advantage over other tools. Its metrics provide deep, component-level insights. Being open source, it’s highly extensible, and you can even write custom metrics in RAGAS if needed.
As a relatively new project, RAGAS is still evolving. Some users report that certain metrics can be brittle and lead to odd scores. The library is code-centric and lacks a rich UI, so you’ll be working in Python.
3. Trulens

Trulens is an open-source library, originally from TruEra and now supported by Snowflake. It helps evaluate and trace AI agent behavior using feedback functions. Trulens is especially popular for agentic workflows and retrieval-augmented generation, where understanding why the model produced an answer is as important as the answer itself.
Features
- Built-in feedback functions to measure key qualities like Groundedness (faithfulness), Context Relevance, and Answer Relevance.
- Supports OpenTelemetry traces to capture each step and provide a detailed reasoning trace for every run.
- Compare different versions of your app side by side on various metrics and visualize experiment results using a metrics leaderboard.
- Although Python-first, TruLens comes with a lightweight dashboard that allows you to view traces and feedback scores in a web UI, filterable by metric.
Pricing
Trulens is completely free and open source. Originally developed by TruEra and now open-sourced (with Snowflake overseeing development), it has no licensing cost. You can pip install trulens and use all features locally or on your own infrastructure.
Pros and Cons
The major pro is Trulens’s rare combination of evaluation and tracing. Its local dashboard and detailed tracing make it easy to quickly identify and understand failures. Another pro is the community and backing; being open source under a major company’s wing (Snowflake) gives some confidence in its longevity and improvement pace.
Its primary focus, however, is on local development and experimentation. For production-level concerns like scheduled runs or scalable orchestration, you may need to plug those traces into a larger MLOps framework.
4. LangSmith
LangSmith is the official observability and evaluation platform by the LangChain team. Although it’s deeply integrated with the LangChain ecosystem, it’s framework-agnostic and helps debug, test, monitor, and evaluate any LLM application, whether or not you built it with LangChain.
Features
- Captures detailed traces of every application run and allows you to run evaluations directly on these traces.
- Robust version control enables you to save datasets of test queries and regression tests to identify when a change degrades performance.
- Supports various evaluators, including LLM-as-a-judge, gold-standard comparisons, programmatic checks, and pairwise comparisons.
- The built-in 'Annotation Queue' enables subject-matter experts to easily review, score, and correct model outputs.
- Offers a Prompt Playground and Canvas for experimenting with prompts and models, while allowing collaborators to propose tweaks and review evaluations in real-time from a single UI.
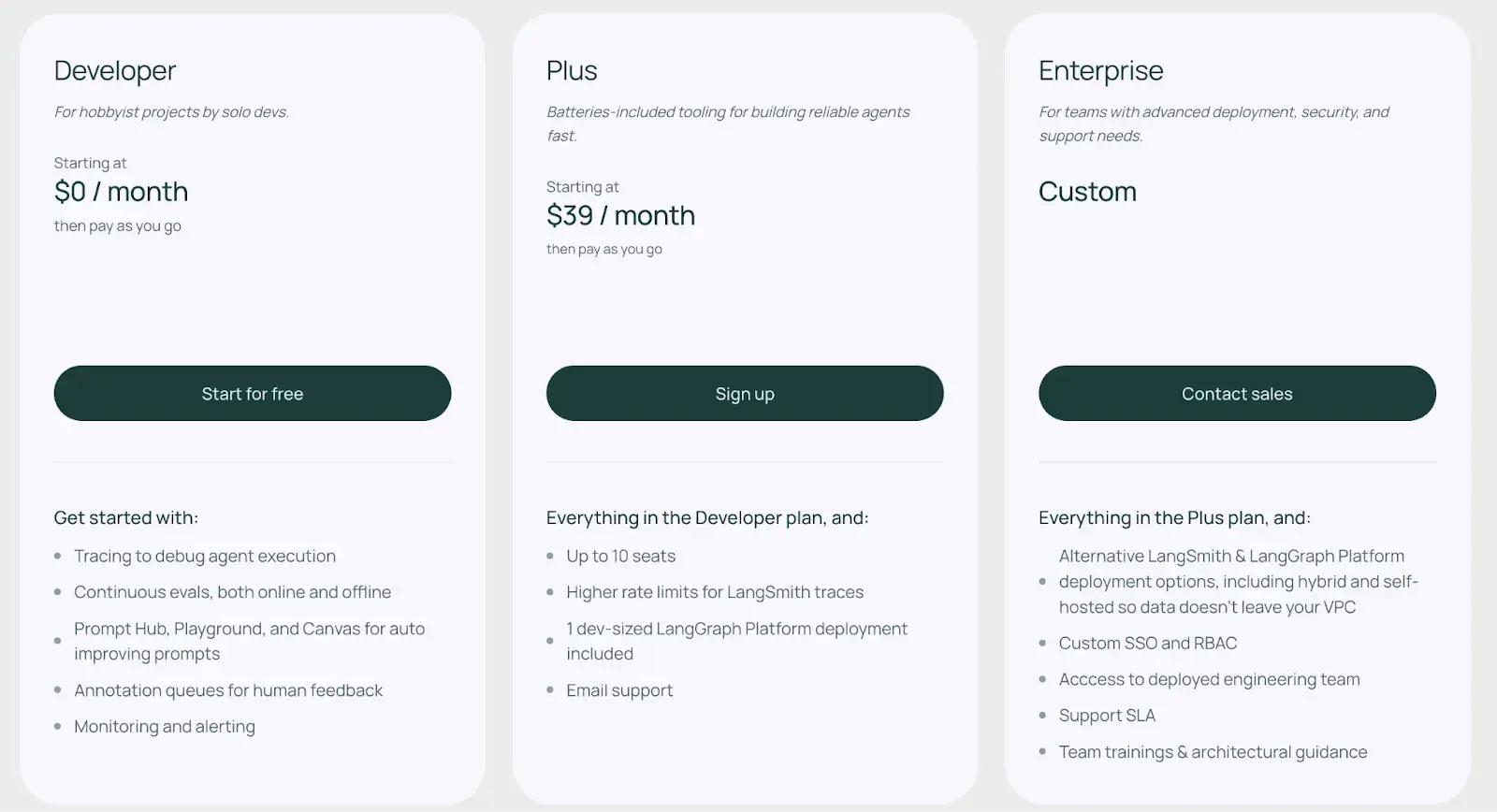
Pricing
LangSmith offers a generous free ‘Developer’ plan for individuals and hobbyist projects. And two premium plans:
- Plus: $39 per month
- Enterprise: Custom pricing
Pros and Cons
LangSmith’s greatest strength is its polished, all-in-one user experience. For anyone using LangChain, integration is almost seamless. Particularly strong is the way it handles evaluation datasets and regression testing: it allows you to easily convert real user interactions into test sets for automated reruns.
However, its proprietary SaaS nature may not suit teams needing full data control. If you’re not a LangChain user, you might find some features less directly applicable. Additionally, logging every call can lead to significant costs for high-traffic applications as they scale.
5. DeepEval
Confident AI by DeepEval is an open-source Python evaluation framework that brings the familiar unit testing paradigm to the world of LLMs. It is designed to be lightweight, developer-centric, and easy to integrate into a CI/CD pipeline, functioning much like Pytest but for AI models.
Features
- Features over 14 pre-built RAG metrics, including truthfulness and hallucination checks, answer relevance, answer contextual recall, agentic metrics, toxicity detection, and bias detection.
- Provides a class-based structure for defining evaluation test cases in standard Python files and uses a simple
assert_testfunction to evaluate them against a list of metrics. - Test an entire LLM system or individual intermediate components, or both, in one run.
- Built-in red-teaming module allows stress-testing your LLM’s guardrails automatically against over 40 types of attacks and bad inputs.
Pricing
DeepEval core library is open-source and free to use. It integrates with an optional companion cloud platform, Confident AI, which offers a free tier for individuals, along with paid plans:
- Starter: $19.99 per user per month
- Premium: $79.99 per user per month
- Enterprise: Custom pricing

Pros and Cons
DeepEval’s biggest advantage is its developer-friendly, code-first approach, which integrates with existing software practices. Its comprehensive, open-source framework covers everything from simple metrics to complex LLM-as-judge scoring, ensuring both flexibility and transparency.
As a rapidly evolving project, its documentation and stability can sometimes lag, requiring users to keep up with frequent updates. While the core library is free, unlocking its full capabilities requires the associated Confident AI cloud service.
6. Weights & Biases Weave

W&B Weave is a new offering from Weights & Biases that’s built atop the popular W&B experiment tracking platform. It tightly integrates LLM evaluation into the experimentation workflow, enabling rigorous tracking, visualization, and comparison of prompts, models, and application logic.
Features
- Automatically traces and logs LLM calls and application logic, capturing outputs, latency, and token usage, all by adding a single-line code snippet to your LLM app.
- Evaluate outputs using built-in RAG eval scorers like LLM-as-a-judge, hallucination detection frameworks, and custom evaluation templates.
- Leverage W&B's powerful UI to visualize evaluation results in interactive dashboards with powerful tools for filtering, searching, and aggregation.
- Since it’s built on W&B’s platform, Weave facilitates team collaboration with shareable reports and fine-grained access controls.
Pricing
Weights & Biases offers a free tier for individual developers and two premium plans:
- Pro: $60 per month
- Enterprise: Custom pricing

Pros and Cons
For teams already using W&B for traditional machine learning, Weave is a natural and powerful extension for their LLM projects. The one-line instrumentation philosophy is a pro; you don’t have to restructure your app to start logging and evaluating.
The main downside is that W&B is a comprehensive and heavy-duty platform. The cost can add up quickly for larger teams or high-volume usage, and it may be overkill for teams needing a more lightweight solution.
7. Humanloop
Humanloop’s philosophy is to involve both developers and non-developers in the loop, hence the name. It’s an enterprise-grade platform designed to build, evaluate, and deploy LLM applications with a strong emphasis on collaboration and rapid iteration.
Features
- Supports a hybrid evaluation approach that allows for automated testing with code-based and AI-based evaluators, both online and offline.
- Provides first-class support for dataset versioning and metadata, so you always know which test cases were used.
- Integration into CI/CD allows you to automatically run your evals whenever the model or prompt updates, catching regressions early.
- Offers a collaborative workspace for your team to create, maintain, and experiment with multiple prompt versions.
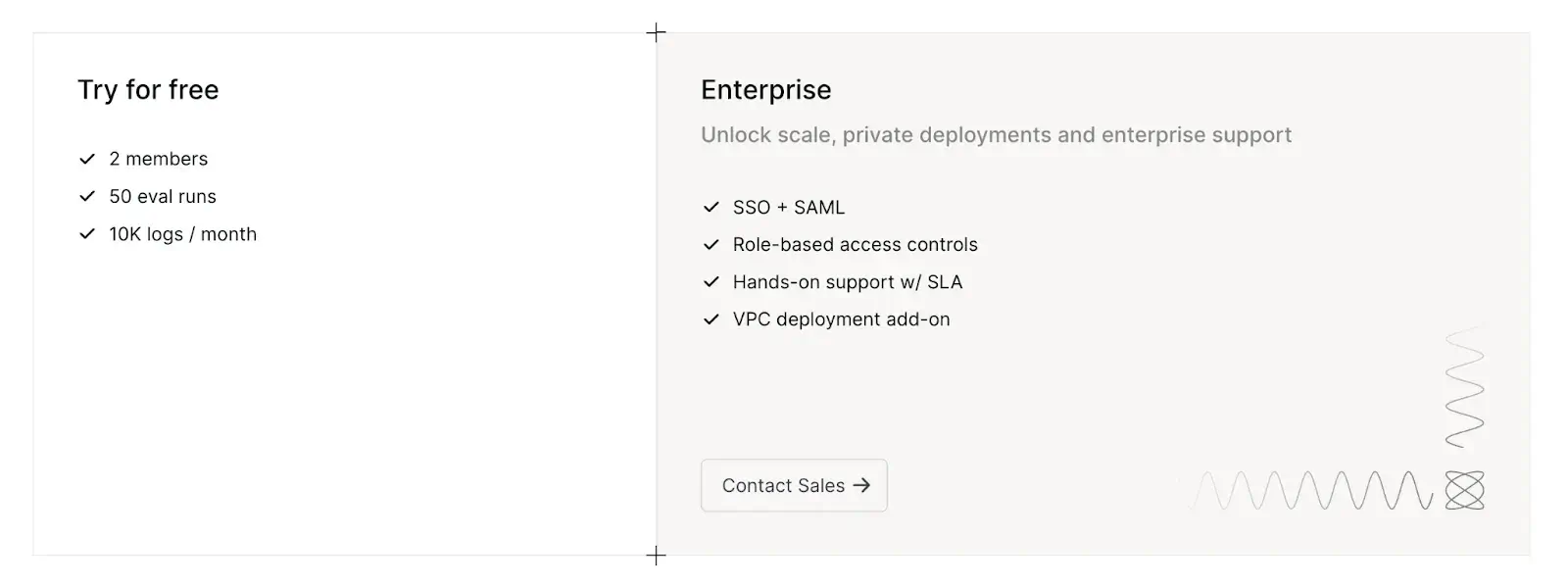
Pricing
Humanloop offers a free plan for 2 members, 50 evaluations, and 10k logged interactions per month. Then it jumps straightaway to enterprise pricing.
Pros and Cons
Humanloop’s focus on collaboration is a pro: both engineers and non-engineers can use the web interface to contribute, which is great for cross-functional teams building AI products.
The support for CI/CD integration stands out. Also, being enterprise-focused, Humanloop offers features like role-based access control, data privacy options, and SLAs that big companies need.
For small-scale or open-source aficionados, Humanloop might feel heavy. It’s a proprietary platform, so you won’t have code-level control or the option to self-host. The free tier is limited, and the entry price is a huge leap from free to enterprise.
8. OpenAI Evals
OpenAI Evals is an evaluation framework open-sourced by OpenAI. Its primary purpose is to provide a standardized way to evaluate LLMs’ performance, particularly OpenAI’s models, on a wide range of tasks.
Features
- Support for advanced eval techniques like LLM-as-a-judge and multi-turn evaluations, and also lets you write custom eval logic in Python.
- Has an extensive registry of pre-built evaluations for various capabilities like math word problems, trivia QA, coding challenges, and more.
- Unsurprisingly, the framework works seamlessly with OpenAI’s API to evaluate runs.
- Use ‘Completion Function Protocol’ to evaluate multi-model calls involving prompt chains or tool-using agents.
Pricing
The Evals framework itself is open-source and free to use. However, running an evaluation requires making API calls to an LLM, which incurs standard token-based usage costs from OpenAI.
Pros and Cons
OpenAI Evals provides a standardized way to evaluate that many in the community have rallied around. A significant advantage is the library of existing evaluations on well-known benchmarks. It’s also highly configurable, and evaluations are almost always transparent and reproducible.
The flip side of its flexibility is that OpenAI Evals is not the most user-friendly for non-coders. Other than the minimal OpenAI dashboard integration, there’s no slick UI. You’re mostly working with Python scripts or config files.
9. MLflow
MLflow is a widely adopted open-source platform for managing the end-to-end machine learning lifecycle. Its capabilities extend to LLM evaluation, allowing teams to integrate testing into the broader MLOps context.
Features
- Offers built-in LLM evaluation metrics, including classic reference-based metrics and mode-based metrics, like LLM-as-a-judge, toxicity detection, completeness, and more.
- All evaluation results are automatically logged to MLflow’s tracking server. Each run will have metrics, and you can also log the per-example results as an artifact.
- Use MLflow’s visually rich UI to compare evaluation metrics side-by-side, over time, or across experiments.
Pricing
MLflow is an open-source and completely free platform for self-hosting. You can install it and run the tracking server locally or on your own servers at no cost.
Many companies also get MLflow as part of Databricks, so if you’re on Databricks, the LLM eval features may be available in that environment too.
Pros and Cons
The biggest pro for MLflow is integration and familiarity. Many ML teams already use MLflow for tracking experiments, and extending it to LLM eval means less context switching.
While powerful, MLflow’s LLM evaluation features are still relatively basic compared to specialized frameworks. It lacks dedicated RAG metrics, human feedback workflows, and built-in dashboards tailored for prompt or response analysis, requiring custom setup for deeper evaluation use cases.
Which LLM Evaluation Tool is the Right Choice for You?
Selecting the right LLM evaluation tool is critical to building trustworthy AI systems. The right framework ensures every model update, prompt tweak, or retriever change is measurable, repeatable, and explainable.
After analyzing the top options, three tools stand out for most teams:
✅ ZenML: Best overall for teams that want a unified, reproducible, and production-grade LLMOps framework that combines evaluation, tracking, and orchestration in one place. It’s the only platform that truly closes the outer loop for LLM evaluation.
✅ RAGAS: Ideal for developers focused solely on retrieval-augmented generation. Its specialized metrics for context precision and faithfulness make it a great choice for RAG researchers and engineers.
✅ LangSmith: Perfect for teams building with LangChain and looking for a polished, visual UI for debugging, dataset versioning, and human-in-the-loop review.
ZenML offers the most complete foundation for LLM evaluation at scale, from testing small prototypes to managing production-grade pipelines.
If you’re interested in taking your AI agent projects to the next level, consider joining the ZenML waitlist. We’re building our first-class support for agentic frameworks (like LangGraph, CrewAI, and more) inside ZenML, and we’d love early feedback from users pushing the boundaries of what AI agents can do. With ZenML, you can seamlessly integrate whichever agent framework you choose into robust, production-grade workflows. Join our waitlist to get started.👇


