On this page
Imagine you’re responsible for a credit scoring system that evaluates thousands of loan applications daily. Your models directly impact people’s financial opportunities. They determine who gets approved for loans, mortgages, and credit cards, and under what terms. When working properly, these algorithms can increase financial inclusion by making consistent, data-driven decisions. When flawed, they risk perpetuating or amplifying existing biases—as Goldman Sachs discovered when a single viral tweet exposed a 20× gender gap in Apple Card credit limits, triggering multi-year regulatory scrutiny.
Under the EU AI Act, these systems fall under the category of “high-risk AI” (Annex III), which triggers strict requirements for documentation, fairness, oversight, and risk management. The SCHUFA ruling in late 2023 tightened these requirements further. For financial institutions, this introduces a new compliance landscape that fundamentally changes how credit scoring models are built, deployed, and maintained.
This post walks through a demo project using ZenML to automate most EU AI Act compliance requirements.
For a deep dive into the EU AI Act itself and its February 2025 updates, check out Alex’s overview post. This blog focuses on the practical implementation of those requirements.
The Compliance Challenge in Banking
Banks have always needed to justify their models, but the AI Act raises the bar. It’s no longer sufficient to demonstrate that your model works. You must prove how it works, why it works, and ensure it works fairly, securely, and accountably.
The documentation requirements are extensive: system descriptions, technical specs, development processes, risk procedures, validation results, and monitoring plans. This must stay current across model lifecycles and remain audit-ready. With weekly retrains and hundreds of production models, manual compliance becomes unmanageable
Non-compliance carries serious consequences: fines up to €35 million or 7% of global turnover, not to mention the potential reputational damage. Yet only 14% of financial organizations still track models in spreadsheets.
What’s needed is infrastructure that makes compliance a natural outcome of good engineering, not a separate and burdensome process. The EU AI Act essentially codifies ML best practices:
- Article 9: Comprehensive risk management system
- Article 10: Data governance and quality controls
- Article 11: Detailed technical documentation (Annex IV)
- Article 12: Automatic recording and event logging
- Article 14: Effective human oversight measures
- Article 15: Accuracy, robustness, and cybersecurity
- Article 17: Post-market monitoring and feedback
- Article 18: Incident reporting mechanisms
I built a credit-scoring pipeline satisfying every requirement without spreadsheets or manual processes. What made the process dramatically easier was leveraging ZenML’s lineage tracking, versioning, artifact management, and automatic logging, turning compliance into a natural byproduct of a well-designed ML pipeline.
Architecture for Compliance: Three-Pipeline Design
The credit-scoring workflow is split into three ZenML pipelines:
- Feature Engineering: Ingests raw loan-application data, profiles quality with WhyLogs, applies cleaning and encoding steps, and stores versioned feature sets for downstream use.
- Model Training: Trains and tunes a
LightGBMClassifier, logs hyperparameters, evaluates performance across demographic groups, and bundles the model with full lineage. - Deployment & Monitoring: Adds an approval gate, packages the model with its compliance artifacts (including Annex IV), and deploys it as a FastAPI service on Modal.
Let’s dive into each pipeline to see how they address specific EU AI Act compliance requirements.
Feature Engineering Pipeline: Data Governance in Action
The first pipeline lays the groundwork for EU AI Act compliance by focusing on data governance. Articles 10 emphasizes strong data quality controls, while Article 12 requires meticulous record-keeping for all data processing activities.
@pipeline(name=FEATURE_ENGINEERING_PIPELINE_NAME)
def feature_engineering(
dataset_path: str = "src/data/credit_scoring.csv",
test_size: float = 0.2,
normalize: bool = True,
target: str = "TARGET",
random_state: int = 42,
sample_fraction: Optional[float] = None,
sensitive_attributes: List[str] = None,
):
"""End-to-end feature engineering pipeline with data governance controls."""
# Load data with provenance tracking (Art. 10)
df, whylogs_data_profile = ingest(
dataset_path=dataset_path,
sample_fraction=sample_fraction,
target=target,
sensitive_attributes=sensitive_attributes,
)
# Split dataset with documented rationale (Art. 10)
train_df, test_df = data_splitter(
df=df,
test_size=test_size,
target=target,
random_state=random_state,
)
# Preprocess with transformation tracking (Art. 10)
train_df_processed, test_df_processed, preprocess_pipeline = data_preprocessor(
train_df=train_df,
test_df=test_df,
normalize=normalize,
target=target,
)
return whylogs_data_profile,train_df_processed, test_df_processed, preprocess_pipelineThe pipeline incorporates several essential compliance features:
- Data Provenance with SHA-256 Hashing: Ensures the exact data used for training is traceable and tamper-proof.
- WhyLogs Profiling: Captures comprehensive quality metrics like data drift and anomalies.
- Preprocessing Transparency: Each transformation is logged, enabling full visibility into how data is prepared.
- Sensitive Attribute Identification: Flags protected demographic features for fairness assessments.
By wrapping these steps in ZenML’s pipeline framework, we gain automatic lineage tracking, artifact versioning, and metadata persistence, which are all essential for meeting the record-keeping requirements of Article 12.
Training Pipeline: Performance with Accountability
The second pipeline handles model training, evaluation, and risk assessment, directly addressing Articles 9 (Risk Management), 11 (Technical Documentation), and 15 (Accuracy) of the EU AI Act.
@pipeline(name=TRAINING_PIPELINE_NAME)
def training(
train_df: Any = None,
test_df: Any = None,
target: str = "TARGET",
hyperparameters: Optional[Dict[str, Any]] = None,
protected_attributes: Optional[List[str]] = None,
approval_thresholds: Optional[Dict[str, float]] = None,
risk_register_path: str = "docs/risk/risk_register.xlsx",
model_path: str = "models/model.pkl",
):
"""Training pipeline with integrated evaluation and risk assessment."""
# Train model with documented hyperparameters (Art. 11)
model = train_model(
train_df=train_df,
test_df=test_df,
target=target,
hyperparameters=hyperparameters,
)
# Evaluate with fairness metrics (Art. 15)
evaluation_results, fairness_metrics = evaluate_model(
model=model,
test_df=test_df,
target=target,
protected_attributes=protected_attributes,
approval_thresholds=approval_thresholds,
)
# Conduct risk assessment (Art. 9)
risk_scores = risk_assessment(
evaluation_results=evaluation_results,
fairness_metrics=fairness_metrics,
risk_register_path=risk_register_path,
)
return model, evaluation_results, risk_scoresThe key compliance features here include:
- Hyperparameter documentation for reproducibility (satisfying Article 11's technical documentation requirements)
- Performance metrics across demographic groups (providing the transparency needed for Article 15 compliance)
- Risk scoring with mitigation tracking (providing the structured risk management required by Article 9)
The evaluate_model step automatically calculates fairness metrics across protected attributes and generates alerts when potential bias is detected, which addresses the fairness requirements of Article 15.
Deployment Pipeline: Human Oversight and Documentation
The third pipeline manages model approval, deployment, and monitoring, addressing Articles 14, 17, and 18 of the EU AI Act. This pipeline demonstrates how meaningful human oversight can be integrated into automated deployment workflows.
@pipeline(name=DEPLOYMENT_PIPELINE_NAME)
def deployment(
model: Annotated[Any, MODEL_NAME] = None,
preprocess_pipeline: Annotated[Any, PREPROCESS_PIPELINE_NAME] = None,
evaluation_results: Annotated[Any, EVALUATION_RESULTS_NAME] = None,
risk_scores: Annotated[Any, RISK_SCORES_NAME] = None,
environment: str = MODAL_ENVIRONMENT,
):
"""Deployment pipeline with human oversight and monitoring."""
# Human approval gate (Art. 14)
approved, approval_record = approve_deployment(
evaluation_results=evaluation_results,
risk_scores=risk_scores,
approval_thresholds=DEFAULT_APPROVAL_THRESHOLDS,
)
# Deploy with versioning (Art. 16)
if not approved:
return None
deployment_info = modal_deployment(
model=model,
preprocess_pipeline=preprocess_pipeline,
environment=environment,
)
# Generate SBOM for security tracking (Art. 15)
sbom = generate_sbom(model=model, preprocess_pipeline=preprocess_pipeline)
# Setup monitoring (Art. 17)
monitoring_plan = post_market_monitoring(
model=model,
evaluation_results=evaluation_results,
deployment_info=deployment_info,
)
# Generate technical documentation (Art. 11)
documentation_path = generate_annex_iv_documentation(
evaluation_results=evaluation_results,
risk_scores=risk_scores,
deployment_info=deployment_info,
sbom=sbom,
monitoring_plan=monitoring_plan,
approval_record=approval_record,
)
return documentation_pathThe key compliance features include:
- Human approval gate with documented rationale via the
approve_deploymentstep (important for Article 14) - Software Bill of Materials generation
- Post-market monitoring configuration
- Annex IV documentation generation
The human oversight implementation is particularly important. The approve_deployment step requires explicit review and sign-off before models can be deployed, creating an auditable record of human oversight. When the system detects issues requiring review, it sends structured Slack notifications using ZenML’s Slack alerter integration with this assessment:

This wasn’t a false positive. Our model exhibited severe disparate impact (0.161 ratio) across age groups, meaning it was systematically discriminating against certain age demographics. The Slack alert enabled immediate visibility into this critical bias issue, ensuring it didn’t get lost in terminal logs or overlooked during deployment cycles.
The EU AI Act’s requirements allowed me to discover a critical fairness issue that demanded immediate remediation, which could’ve gone undetected without full compliance monitoring. It shows how compliance infrastructure becomes a quality assurance mechanism that protects both institutions and the people they serve.
The Documentation Engine: Automating Annex IV
Automating comprehensive technical documentation turned out to be one of the most technically challenging aspects of compliance. The EU AI Act’s Annex IV requirements are extensive and specific, demanding everything from general system descriptions to detailed post-market monitoring plans.

These requirements become manageable when you understand how existing MLOps infrastructure can address them. Rather than building compliance systems from scratch, ZenML’s native capabilities handle most requirements through features you’re likely already using for good ML engineering practices.
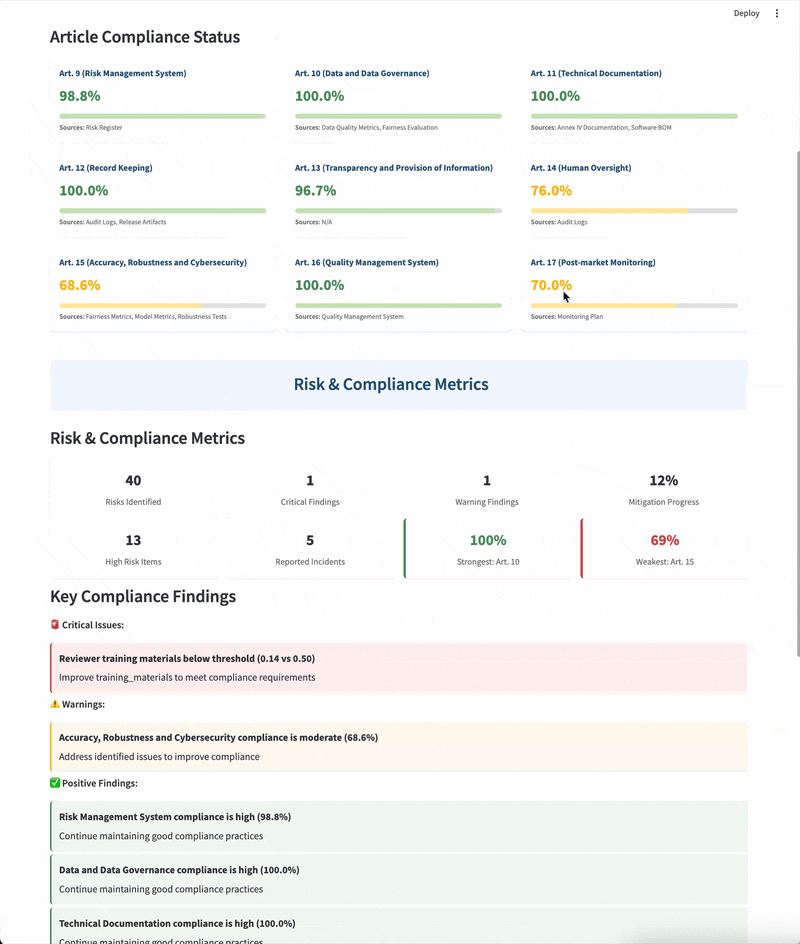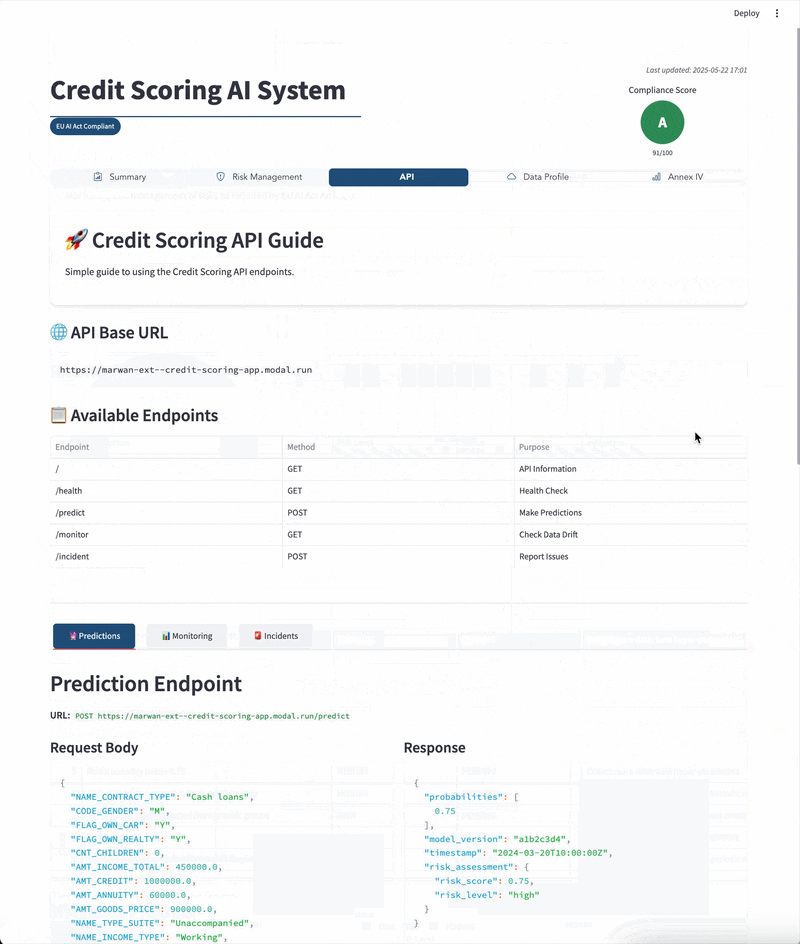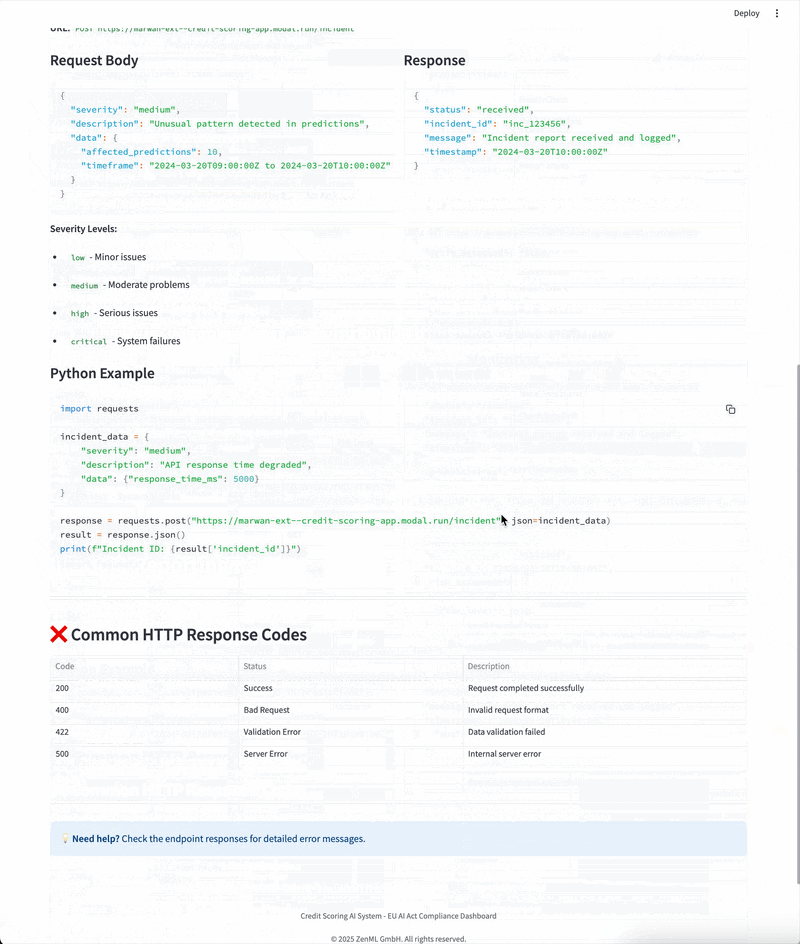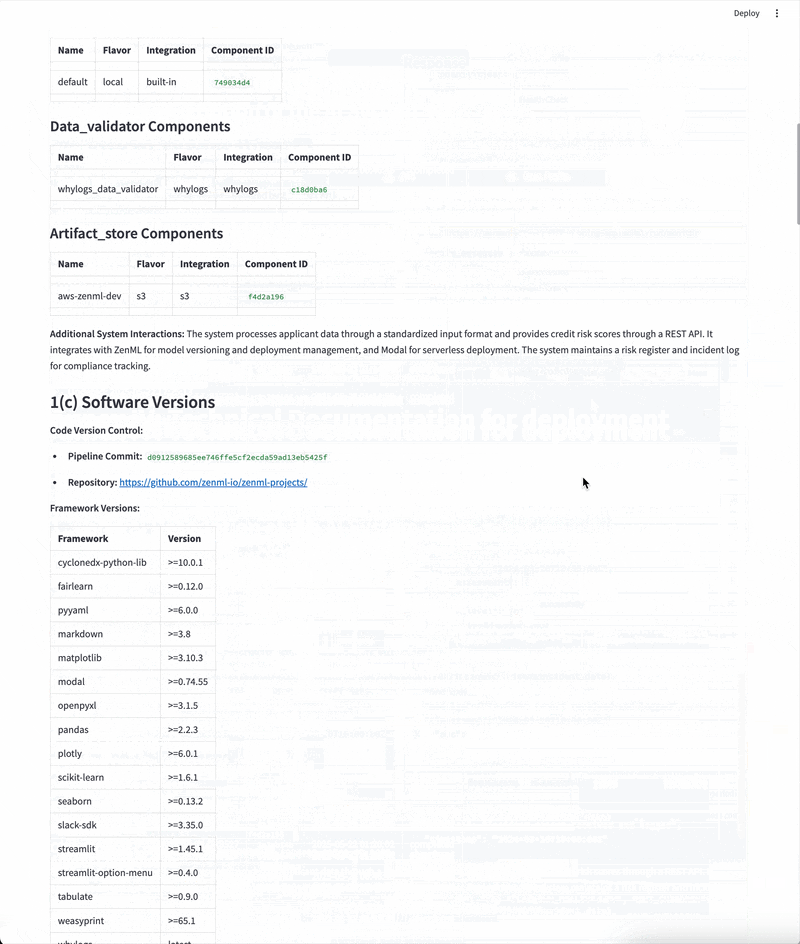
| Article | Key Requirements | ZenML Implementation |
|---|---|---|
| Art. 9 Risk Management | Risk assessment, mitigation measures | Step output tracking, metadata logging |
| Art. 10 Data Governance | Data quality, representativeness | Artifact lineage, dataset versioning |
| Art. 11 Documentation | Complete system documentation | Pipeline run history, step metadata |
| Art. 12 Record-keeping | Automated event logging | Run history tracking, artifact storage |
| Art. 14 Human Oversight | Human review capabilities | Approval steps, model workflows |
| Art. 15 Accuracy | Performance metrics, robustness | Metrics tracking, evaluation artifacts |
| Art. 17 Post-market Monitoring | Deployed model monitoring | Artifact versioning, pipeline triggers |
| Art. 18 Incident Notification | Incident reporting mechanisms | Step outcomes tracking, failure monitoring |
The generate_annex_iv_documentation step transforms scattered pipeline metadata into structured compliance packages. Rather than maintaining separate compliance documentation, the system leverages ZenML’s automatic metadata capture and artifact store to generate complete technical documentation bundles.
Each documentation package includes multiple artifacts that address specific compliance requirements:
| Artifact | Content Source | EU AI Act Coverage |
|---|---|---|
| annex_iv.md | ZenML metadata + Jinja templates | Art. 11 (Technical Documentation) |
| model_card.md | Performance metrics + fairness analysis | Art. 13 (Transparency) |
| evaluation_results.yaml | Model evaluation step outputs | Art. 15 (Accuracy) |
| risk_scores.yaml | Risk assessment step results | Art. 9 (Risk Management) |
| git_info.md | Repository commit information | Art. 12 (Record-keeping) |
| sbom.json | Requirements.txt parsing | Art. 15 (Cybersecurity) |
| log_metadata.json | Pipeline execution logs | Art. 12 (Record-keeping) |
| README.md | Generated artifact index | Cross-article compliance mapping |
This automated approach eliminates the inconsistency and incompleteness that plague manual documentation processes. The system ensures documentation accurately reflects actual implementation since it’s generated directly from the same metadata that drives model training and deployment.
Benefits Beyond Compliance
While regulatory compliance is often perceived as a cost center, my experience implementing the EU AI Act requirements revealed several unexpected business benefits that extend far beyond regulatory checkbox exercises.
The documentation and validation requirements forced me to implement more rigorous testing protocols, resulting in models with better performance and reliability. Explicit fairness assessments led to more equitable predictions across demographic groups. Comprehensive validation procedures identified edge cases that might otherwise have been missed. Structured risk assessment practices helped prioritize model improvements based on actual impact and likelihood.
The Competitive Advantage of Compliance-Ready Infrastructure
The EU AI Act represents more than a regulatory burden. It’s an opportunity to build better AI systems. Organizations that approach compliance as an infrastructure challenge rather than a documentation exercise will discover that regulatory requirements become competitive advantages.
ZenML’s pipeline-based approach demonstrates how compliance can be embedded directly into development workflows, creating systems that are simultaneously more reliable, more transparent, and more trustworthy. As the AI Act’s implementation timeline advances, the organizations that build these capabilities now will be positioned to innovate confidently within the regulatory framework.
Although this project focused on the financial sector, similar approaches apply to other high-stakes domains like the energy sector, where regulators like Ofgem are rolling out new AI oversight guidelines.
Try It Yourself
You can explore the CreditScorer project and experiment with it by following these steps:
- Clone the project.
- Follow the setup and installation instructions detailed in the project's
READMEfile. - Run pipelines or launch the demo compliance dashboard:
streamlit run_dashboard.pyThe included Streamlit app provides an interactive UI that provides real-time visibility into EU AI Act compliance status, a summary of current risk levels and compliance metrics, and a generated Annex IV documentation with export options.