On this page
Hey ZenML community! 👋
From our recent mini-roadshow in France—ADEO Dev Summit in Lille and our MLOps Paris meetup (130+ attendees, waitlisted)—teams are moving past agent hype toward production-ready agentic systems.
We’re seeing MLOps patterns re-emerge for agentic workflows: pipeline orchestration, monitoring, deployment strategies, artifact management. The teams succeeding in production aren’t rebuilding from scratch—they’re adapting existing MLOps practices.
Agentic workflows are MLOps evolution, not revolution. MCP (Anthropic’s Model Context Protocol) handles model-context integration while deterministic workflow patterns keep reasoning systems reliable. Same engineering discipline that made traditional ML robust, applied to agents.
This month: performance improvements, production agentic workflow examples from ZenML, and our take on industry direction (intelligent orchestration over unchecked autonomy).
⚡ 200x Performance Boost: Engineering Discipline Meets Real-World Scale
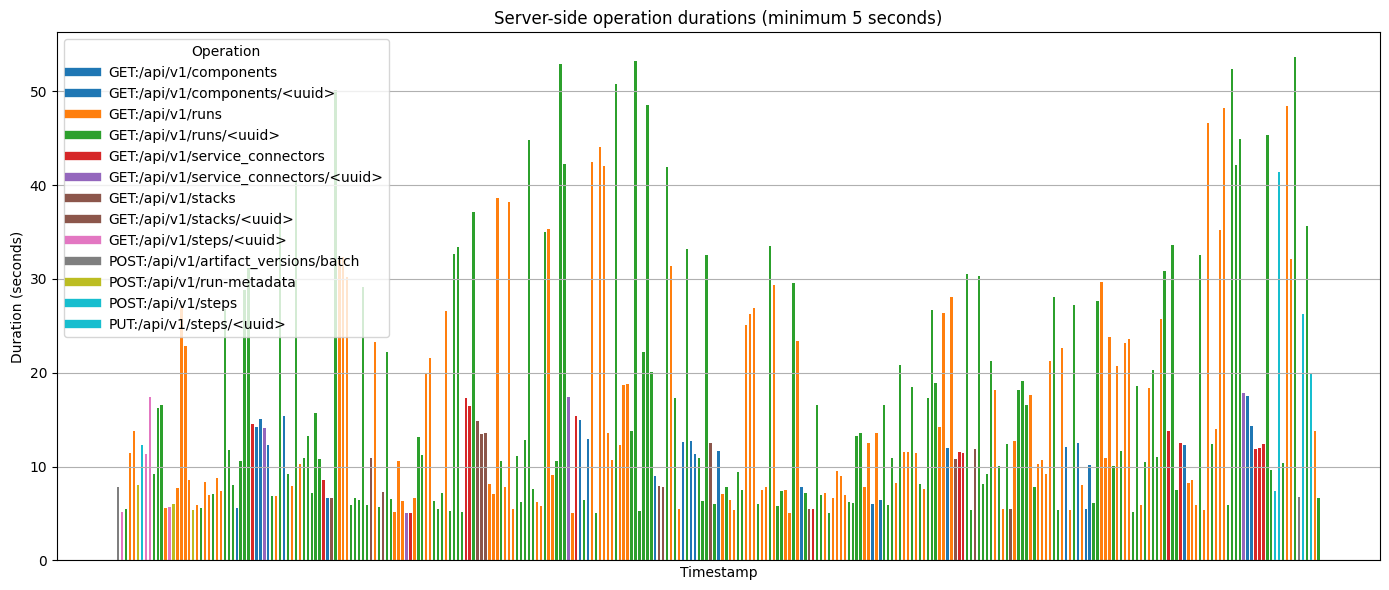
As ZenML adoption has grown, enterprise adoption brought scale challenges we didn’t anticipate: multi-thousand-run experiments, massive artifact stores, high-concurrency dashboard usage. Every performance bottleneck became visible under real production loads.
We rewrote ZenML’s performance-critical paths for 0.83.0, targeting three core areas that were breaking under enterprise workloads. Database queries were performing unnecessary joins and N+1 operations that scaled poorly. FastAPI endpoints weren’t optimized for production concurrency patterns—fine for dev environments, catastrophic at scale. Memory management assumed small datasets and lightweight operations, not the massive artifacts and complex pipelines our enterprise users were running.
Results: Dashboard loads dropped from 30+ seconds to under 2 seconds. Pipeline queries that previously timed out now return instantly. Artifact retrieval that used to block entire workflows now happens in the background. Overall system throughput improved 200x across the board.
(We’re still hitting Python GIL limitations on CPU-bound operations, but that’s our next architectural challenge)
This wasn’t just optimization—it was rebuilding core systems around actual usage patterns from teams running ML operations at production scale. The performance gains unlock workflow complexity that simply wasn’t feasible before.
Check out the full technical deep-dive on scaling ZenML 200x with FastAPI and database optimizations.
🧑💻 Codespaces: Because Reading Docs Shouldn’t Be Your First ZenML Experience
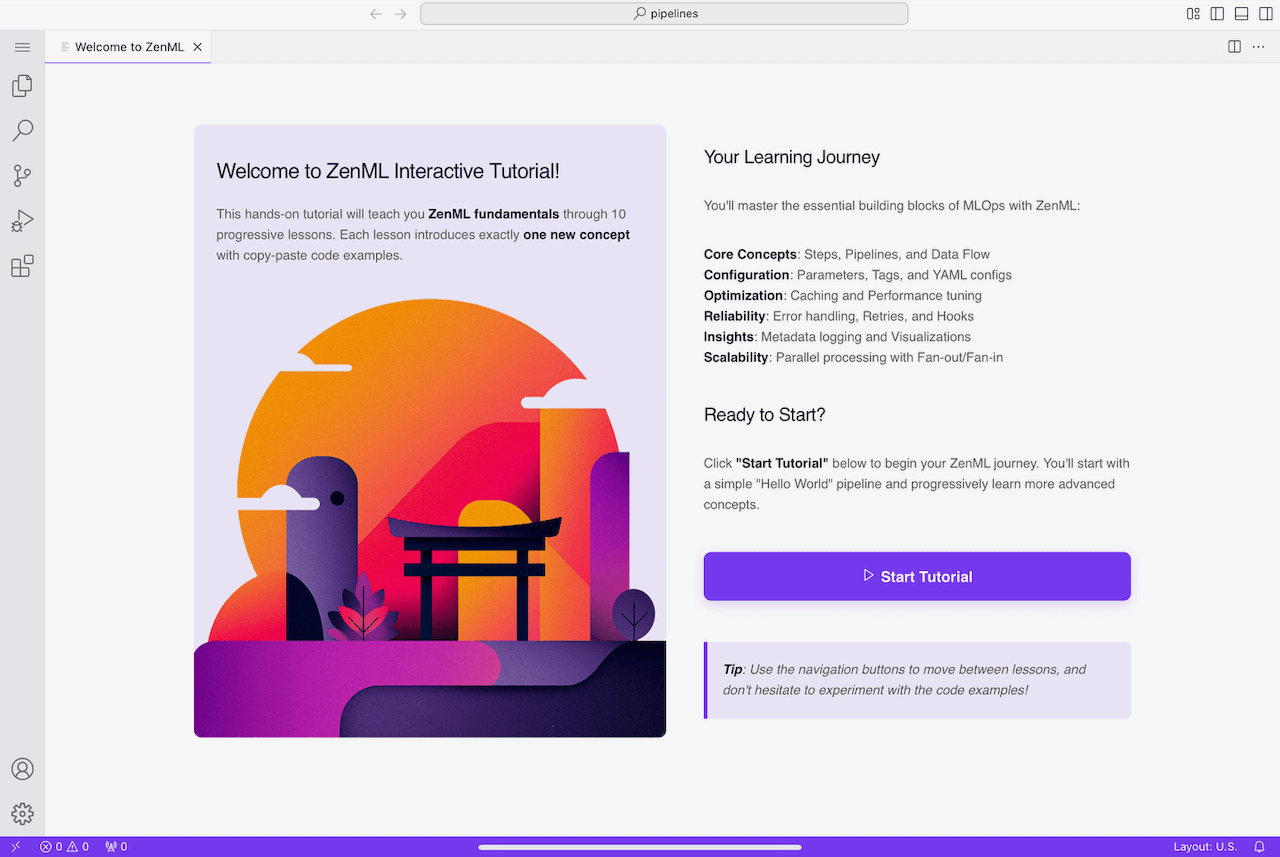
Nobody learns MLOps from docs—you learn by running pipelines and debugging when they break. But the “I want to try ZenML” to “first pipeline running” journey has always involved too much setup friction.
ZenML Codespaces eliminates that entirely. Sign up and get a fully configured VS Code instance running in the cloud (hosted on Modal), preloaded with interactive tutorials. No local environment setup, no dependency hell.
It’s a guided experience: click through code with inline explanations, run actual pipelines without installing anything. Environment spins up in seconds, lasts 6 hours—enough time to explore without commitment.
Existing Pro users can access this through the “Codespaces” tab in your workspace. Think sandbox for experimenting with new patterns or onboarding team members without the usual environment setup.
This previews our broader direction: disposable environments for any ZenML project. Trying a new ML workflow should be as easy as clicking a link—no Docker, no virtual environments, no “works on my machine” issues.
We’re interested in use cases beyond onboarding. Hit us up in Slack or email with feedback—especially weird use cases we didn’t anticipate.
🇫🇷 Paris Insights: Why Agentic Workflows Are Just MLOps in Disguise

My keynote “Evolving MLOps: Foundations for Agentic Workflows” from our Paris event is now live on YouTube.
Core thesis: Most AI projects aren’t making it to production, and successful teams aren’t replacing MLOps—they’re adapting it. Same foundational challenges from traditional ML are appearing in agentic systems, just with reasoning layers added.
Key insight: “Production use cases work way better with deterministic LLM-powered workflows than with autonomous reasoning systems.” Workflows are essentially “agents with less agency”—more autonomy means more entropy, which enterprise use cases can’t tolerate.
I demonstrated this with a live comparison: a fully autonomous research agent (impressive, unpredictable) versus its structured “deep research” pipeline built with ZenML. Same results, but with versioned prompts, cost controls, restart capability, and full observability. All the MLOps discipline we’ve spent years building.
Strong audience reaction—teams are realizing that reliable agentic systems come from better orchestration patterns, not more autonomy.
Closing advice: “Start simple before you go full autonomous. Never go full autonomous.” The future isn’t replacing MLOps with something new—it’s evolving what already works.
🔍 Deep Research Project: The Paris Demo, Now Open Source
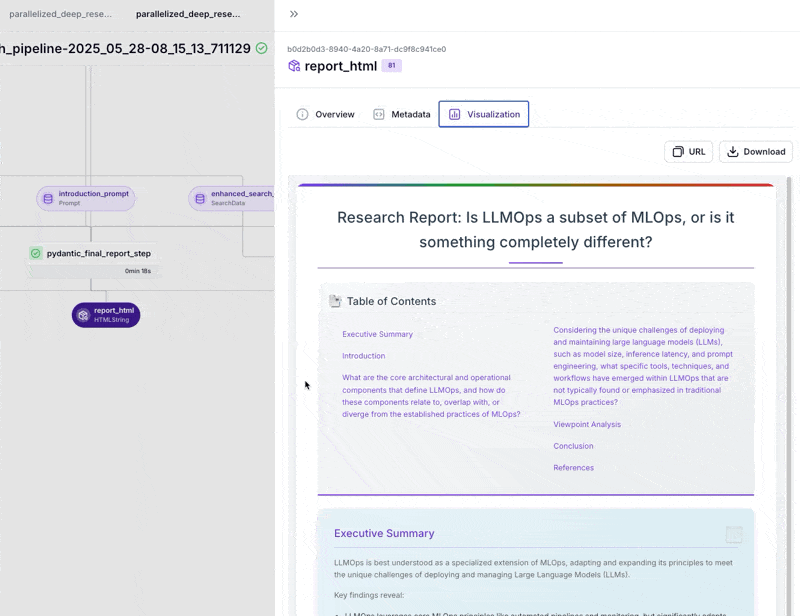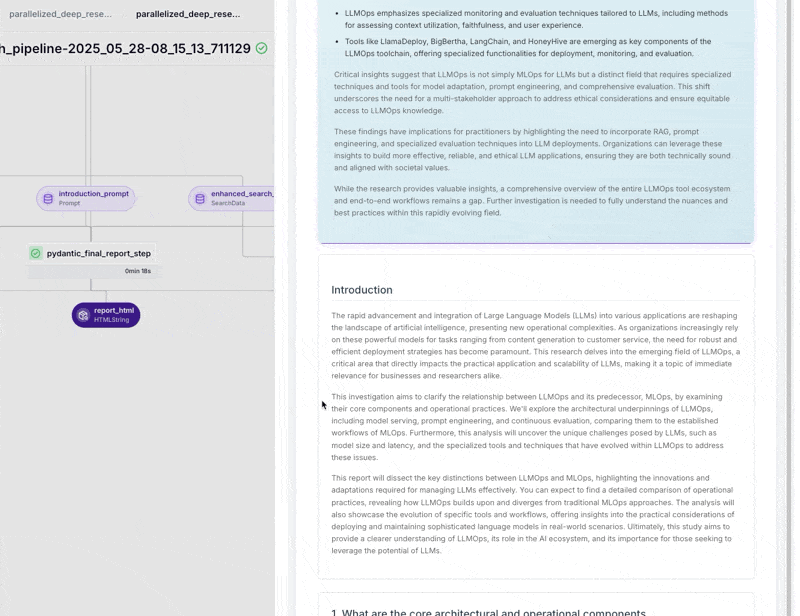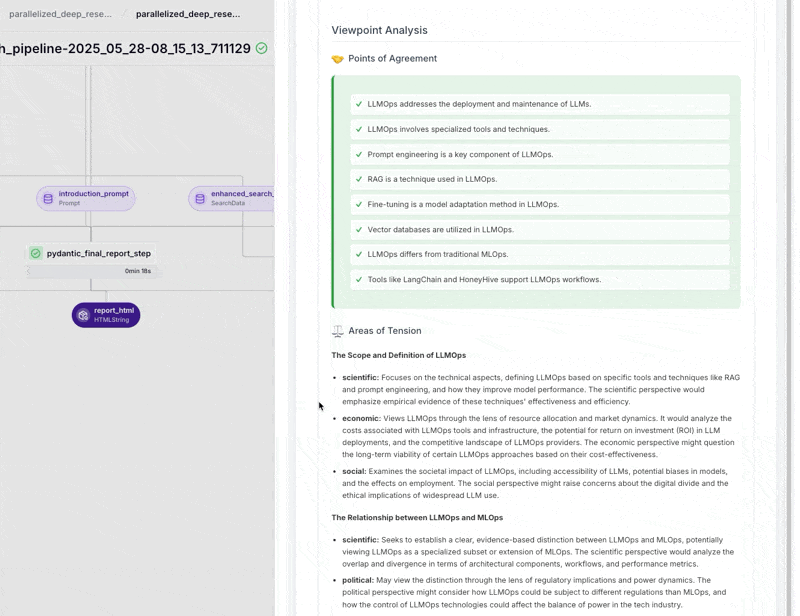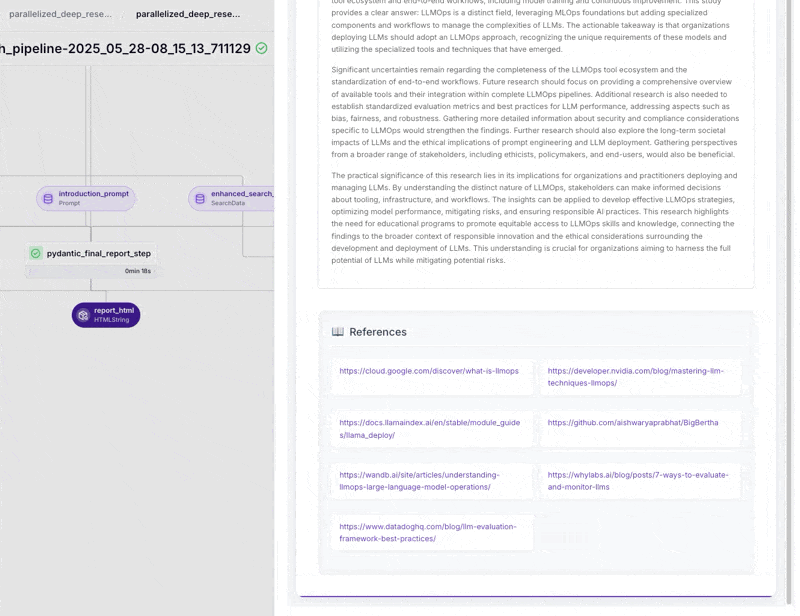
The research workflow we showcased in Paris—the one with complete cost, observability, and reproducibility control versus black-box autonomous agents—is now fully open source as the ZenML Deep Research Agent.
Alex refined it into a production-ready pipeline that demonstrates our “workflows over autonomy” philosophy. Architecture is modular: query decomposition, parallel information gathering, cross-viewpoint analysis, iterative reflection, and report generation. Each step is tracked, versioned, and restartable from any point.
MCP integration was the breakthrough. We connected to Anthropic’s Model Context Protocol with Exa search capabilities, so the system intelligently chooses search types—academic papers, company research, competitor analysis—based on research gaps it identifies.
Cost tracking proved essential. You can see exactly what each research mode costs (rapid, balanced, deep) and optimize accordingly. No surprise API bills from overzealous agents.
This validates the Paris thesis: agentic systems work best when built on solid MLOps foundations. The “intelligent” decisions happen within well-defined pipeline steps you can observe, debug, and improve. The code is available now for teams who want structured research workflows without sacrificing control.
🏛️ AI Act Compliance: When Regulation Actually Makes You Better
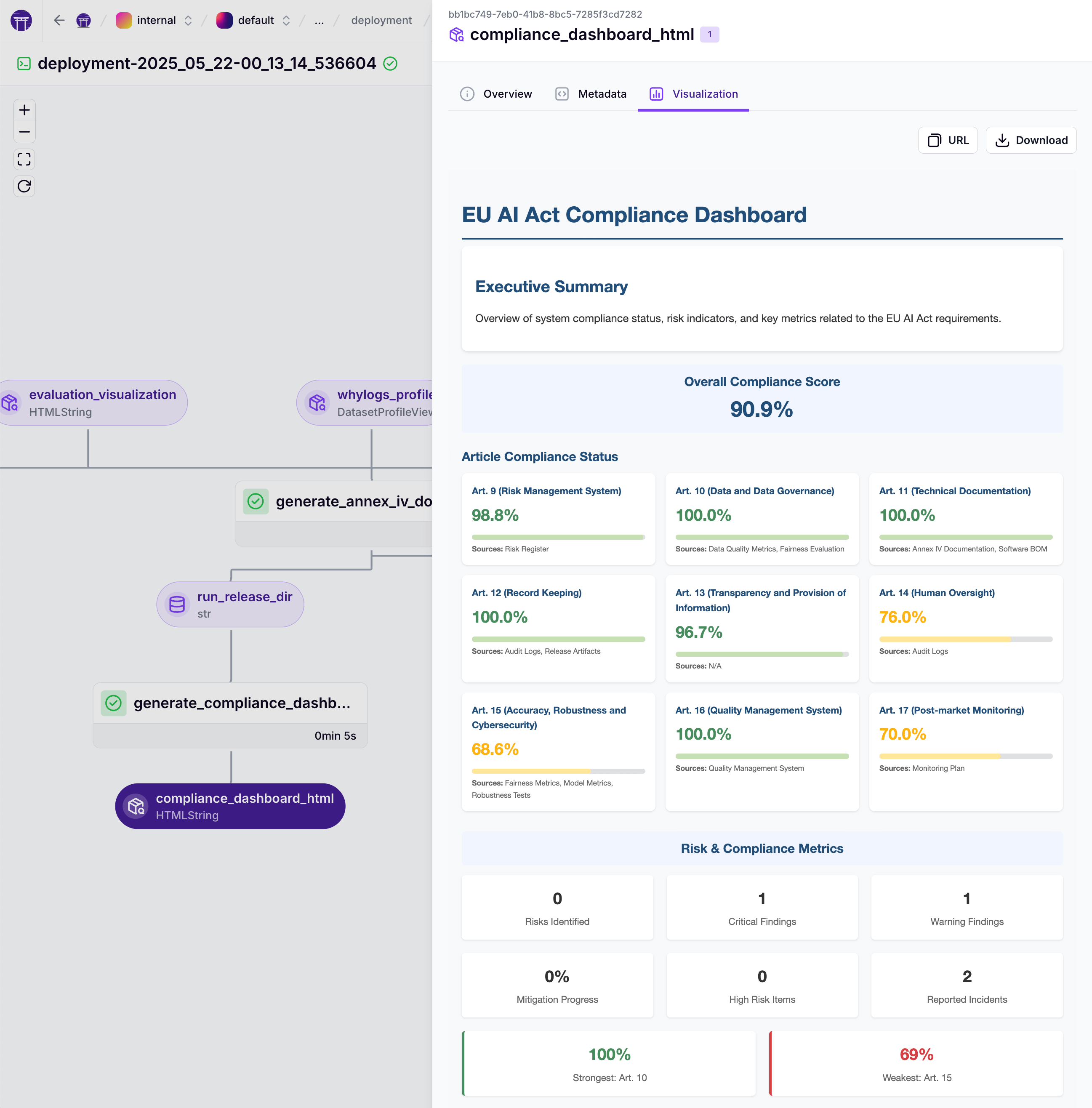
Hot take: EU AI Act compliance isn’t bureaucratic overhead—it’s MLOps best practices with legal enforcement.
We proved this with our credit scoring pipeline project, which automatically satisfies every major AI Act requirement without spreadsheets or manual documentation. The overlap between regulatory demands and good ML engineering is massive.
Comprehensive risk management, data governance, technical documentation, automatic logging, human oversight—these aren’t regulatory burdens, they’re fundamentals of reliable ML systems. The AI Act codifies what we should have been doing anyway.
Our three-pipeline architecture demonstrates this: feature engineering with automatic data provenance, model training with fairness assessments, deployment with human approval gates. Each step generates compliance artifacts as a byproduct of good engineering.
This becomes a competitive advantage. Organizations building these capabilities now won’t just avoid €35 million fines—they’ll build more reliable, trustworthy AI systems that outperform competitors still stuck in “move fast and break things” mode.
AI Act takes effect for high-risk systems next year. You can treat it as an opportunity or scramble to retrofit compliance onto brittle systems.
Check out the full technical deep-dive and try the project yourself.
Rant’s Corner: Stop Fighting the Tools, Start Experimenting

The coding agent discourse has become exhausting. Half the timeline thinks these tools will replace developers next week. The other half dunks on them for generating buggy boilerplate. Even our team opinions range from “game-changer” to “glorified autocomplete.”
These tools are wildly different. Claude Code running GitHub Actions isn’t the same as Cursor’s agentic mode. Codex’s task platform isn’t comparable to Jules’ free tier. Treating them as one monolithic “AI coding” category misses critical nuance.
We got into software engineering because we like tools and experimentation. Why are we suddenly afraid to try these? Free and low-volume versions barely scratch the surface of full-featured implementations.
Lower expectations, stay curious. Don’t expect architectural brilliance from AI that’s never seen your legacy codebase. Don’t dismiss tools because they can’t rewrite your entire system.
Use them for what they’re actually good at: tedious documentation updates, boilerplate generation, quick bug fixes, and exploratory prototyping. Claude Code for those GitHub Actions you’ve been avoiding. Jules for data transformation scripts. Cursor for speeding up test writing.
Productivity gains come from automating grunt work that burns out engineers, not replacing human judgment. Stop debating whether they’re “real AI” and figure out which tasks you’d rather delegate to a very capable, very fast intern.
The future isn’t about choosing sides—it’s about choosing the right tool for the right job.
🎯 Why You Don’t Need an Agent (But You Might Need a Workflow)

I’m giving a talk tonight at our Munich event called “Why You Don’t Need an Agent,” and the title captures something that’s been bugging me for months. 75% of AI projects fail to reach production, and I think the obsession with “agents” is part of the problem.
The hype tells you that you need multi-agent, mostly autonomous systems, and that it’s all pretty easy. But there’s actually a spectrum, and you probably want to be on the more defined, less autonomous side of that spectrum to increase reliability and because it’s much easier to work with.
The distinction between agents and workflows is more gradient than binary. What people call “agents” are often just workflows with varying degrees of autonomy. Prompt chaining? That’s a workflow. Tool-calling loops? Still a workflow. Even complex research systems are fundamentally orchestrated DAGs with LLMs making routing decisions.
The more agency you add, the harder everything gets. Hallucinations compound, communication overhead explodes, and state management becomes a nightmare. The teams succeeding in production aren’t building sophisticated autonomous systems—they’re building reliable orchestration that keeps AI capabilities on rails.
My practical framework is simple: start with basic tool-calling behind an MCP server. If complexity grows, build workflows that chain prompts and LLMs. Add scoped agentic loops only where the value clearly exceeds the unpredictability. And never start without proper evaluation processes.
Alex’s recent analysis on structured workflows reinforces this from the architecture side—component-driven design beats monolithic “vibes-based” systems every time.
The workflow mindset gives you everything you actually need: reproducibility, modularity, versioning, and the ability to debug when things inevitably go wrong.
Take a look at my talk’s slides if you’re interested!
🌍 Join Us in Munich (Tonight!) & We’re Hiring
If you’re in Munich tomorrow night, swing by our “Agents In Production” event. Marc from Langfuse is talking about current best practices from hundreds of teams, plus lightning talks from enterprises actually running AI agents in production. The kind of no-BS technical conversation that cuts through the hype. Grab a spot here.
We’re also growing the team with open positions for a Senior Software Engineer and Senior Frontend Engineer. If you’re interested in working on infrastructure that makes AI more reliable, we’d love to hear from you.
The week in France crystallized something: we’re at an inflection point where agentic workflows are becoming real production workloads. The teams succeeding aren’t building the most sophisticated autonomous systems—they’re applying solid engineering discipline to make AI capabilities actually reliable.
The infrastructure we’re building today determines which organizations can deploy AI at scale versus which ones stay stuck in pilot mode. That’s the opportunity we’re all working toward.
If you’re tackling similar challenges, I’d love to hear about your experiences. Hit reply or find us in the usual places.
Until next time,
Hamza (Co-founder, ZenML)