

On this page
I built the same AI agent twice: once in Semantic Kernel, once in AutoGen. The experience felt different. SK pushed me toward explicit orchestration, plugins, and typed control. AutoGen lets a team of agents talk, argue, and cooperate.
In this Semantic Kernel vs AutoGen article, I draw on hands-on experience with both frameworks to explore their core concepts, features, integrations, and how they fit into an ML engineer’s toolkit.
By the end, you’ll understand the strengths of each, their ideal use cases, and how a tool like ZenML complements them in production.
Semantic Kernel vs AutoGen: Key Takeaways
🧑💻 Semantic Kernel: A plugin-based SDK for building AI agents across .NET, Python, and Java. Semantic Kernel is a model-agnostic SDK that empowers developers to build, orchestrate, and deploy AI agents and multi-agent systems. The framework treats AI models as orchestrators that call existing functions and APIs, making it ideal for integrating AI capabilities into established business processes.
🧑💻 AutoGen: A multi-agent conversation framework designed for orchestrating teams of AI agents that collaborate to solve complex tasks. It shines in scenarios that require dynamic, emergent workflows where the solution path is discovered through dialogue and interaction between multiple specialized agents.
Semantic Kernel vs AutoGen: Features Comparison
The table below summarizes key differences in how Semantic Kernel and AutoGen approach AI agents. After this, we dive deeper into four core feature areas: Agent Abstraction, Multi-Agent Patterns, Memory and RAG, and Human-in-the-Loop.
| Feature | Semantic Kernel | AutoGen |
|---|---|---|
| Agent Abstraction | SDK-first: The Kernel orchestrates Plugins (your code) and Functions (prompts). | Conversation-first: The ConversableAgent defines roles and manages dialogue. |
| Multi-Agent Patterns | Explicit, pre-built patterns like Sequential, Concurrent, and Group Chat. | Dynamic, conversation-driven patterns like GroupChat, Swarm, and GraphFlow. |
| Memory and RAG | Kernel Memory: A dedicated, multi-modal service for enterprise-grade RAG. | Memory Protocol: A flexible interface for conversational context, integrating with vector stores. |
| Human-in-the-Loop | Process orchestration with explicit approval gates for formal intervention. | A human acts as another agent (UserProxyAgent) participating in the conversation. |
Feature 1. Agent Abstraction
The fundamental building block of any agentic framework is its agent abstraction. This defines what an agent is and how you build it. Here, the philosophical split between Semantic Kernel and AutoGen becomes immediately clear.
Semantic Kernel
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
kernel = Kernel()
kernel.add_service(OpenAIChatCompletion(service_id="gpt-4o", ai_model_id="gpt-4o"))
from semantic_kernel.agents import ChatCompletionAgent
agent = ChatCompletionAgent(
service_id="gpt-4o",
kernel=kernel,
name="ResearchAgent",
instructions="Analyze market trends and summarize key insights."
)Semantic Kernel positions itself as a developer toolkit for AI, so its agent abstraction is tightly integrated with traditional programming.
Agents in SK are objects that can be invoked in your code and composed with tools via the SK plugin system and other AI functions.
The Agent Framework is an extension of the core Semantic Kernel SDK that provides base agent classes and patterns to incorporate ‘agentic’ behavior into applications. For example, SK provides agent base classes like ChatCompletionAgent and OpenAIAssistantAgent for different backends.
What’s more, you can create an agent, equip it with skills or tools (wrapping APIs, databases, etc.), and then let it autonomously handle tasks using those functions.
What I’ve found particularly effective about Semantic Kernel is how it bridges the gap between traditional software development and AI applications. Your existing functions become ‘plugins’ that the AI can intelligently invoke, making it easier to add AI capabilities to established systems without complete rewrites.
AutoGen
from autogen_agentchat.agents import AssistantAgent
from autogen_ext.models.openai import OpenAIChatCompletionClient
agent = AssistantAgent(
"researcher",
OpenAIChatCompletionClient(model="gpt-4o"),
description="An agent that researches market trends."
)AutoGen’s agent abstraction is layered to cater to both quick prototyping and advanced use cases. At the high level is AgentChat, which provides intuitive defaults for multi-agent interactions.
In AgentChat, you define agents by specifying their roles (prompts) and capabilities, and AutoGen handles the conversation loop among them.
For instance, you might create an AssistantAgent with a certain goal and a UserProxyAgent to represent a human user, then start a GroupChat – AutoGen will alternate messages between them according to the pattern logic.
This high-level API is very accessible: you don’t have to manage message passing or event loops; you just define agents and tasks.
For more advanced control, AutoGen’s core layer - autogen-core exposes an event-driven programming model. Here, an Agent is a more primitive concept that can send/receive messages and react to events.
You and your team can intercept events like message sends, tool invocations, etc., giving fine-grained control over the agent’s behavior. This is useful if you want to implement custom coordination logic not covered by the built-in patterns.
Feature 2. Multi-Agent Patterns
Once you have more than one agent, you need a way to orchestrate their interactions. Both frameworks provide patterns for this, but again, their approaches reflect their core philosophies of control versus conversation.
Semantic Kernel
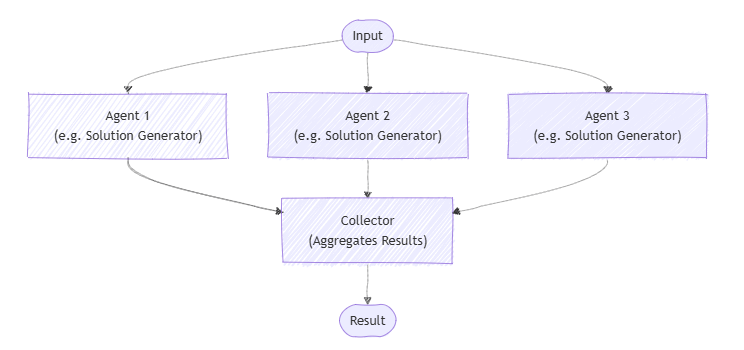
Because SK is rooted in explicit orchestration, it comes with well-defined multi-agent patterns baked into the framework. Recent versions of SK introduced an experimental Agent Orchestration API that supports several coordination patterns drawn from distributed computing analogies:
- Sequential: Pass output from one agent to the next, forming a pipeline.
- Concurrent: Broadcast a task to multiple agents and gather their independent results (useful for ensembling or parallel sub-tasks).
- Handoff: One agent can hand off control to another based on context or rules; for example, escalate to a specialized agent if a certain condition is met.
- Group Chat: Multiple agents converse together, usually with a designated coordinator or manager agent facilitating the discussion.
- Magentic: A pattern (inspired by an internal approach codenamed MagenticOne) which is essentially an advanced group chat for general multi-agent collaboration.
These patterns are available as classes in SK, for example, SequentialOrchestration, ConcurrentOrchestration, etc., so using them is straightforward: you instantiate the orchestration with your agents and then invoke it with a task.
AutoGen
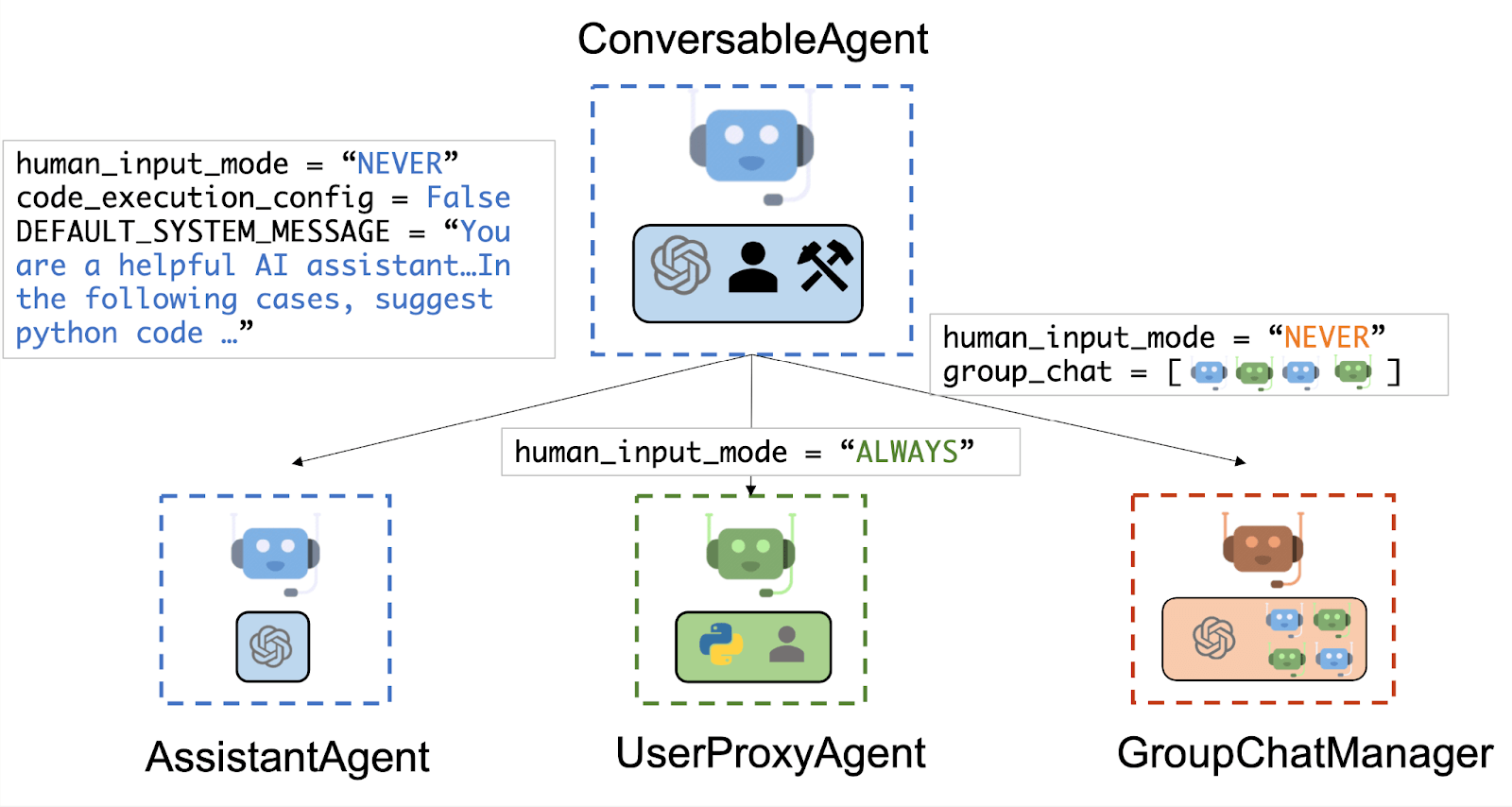
AutoGen approaches multi-agent orchestration through the concept of Teams and conversation patterns rather than static graphs. In AgentChat, a Team is essentially a group of agents plus a manager that defines how they interact. AutoGen ships with several team patterns:
- GroupChat: All agents are in a free-for-all chat, possibly with a simple round-robin or role-based turn-taking. This is analogous to an open discussion where each agent contributes in sequence or when called.
- Swarm: A pattern where one agent can delegate tasks to others dynamically, like a team lead spawning helper agents. The Swarm design mimics a scenario where agents decide among themselves who is best suited for a subtask and hand it off.
- GraphFlow: A more structured workflow where you define a directed graph of agent steps. This is AutoGen’s answer to explicit flows: you can precisely control the order and branching of agent interactions.
- Debate (multi-agent debate): A pattern where two or more agents argue or discuss opposing viewpoints, and perhaps a judge agent evaluates the outcome.
A key difference is that AutoGen’s multi-agent orchestration is less developer-scripted and more data-driven. You configure the roles and let the conversation play out.
Feature 3. Memory and RAG
An agent’s ability to access and remember information is critical. Retrieval-Augmented Generation (RAG) is the key technology here, and both frameworks provide robust solutions, but they are architected for different scales and purposes.
Semantic Kernel

Semantic Kernel’s solution for RAG is Kernel Memory, a powerful and comprehensive service designed for enterprise use cases. From my experience, it’s more than just a library; it’s a full-fledged data pipeline for RAG. It handles the entire ingestion process, including:
- Text Extraction: It can pull text from various document formats like PDF, Word, and PowerPoint.
- Data Processing: It automatically chunks the extracted text, generates embeddings, and stores them in a vector database.
- Retrieval: Agents can then query this knowledge base using a
TextSearchProviderto find relevant information to ground their responses.
Kernel Memory is built to create a persistent, large-scale, and often multi-modal knowledge source for an entire organization’s AI agents.
AutoGen

AutoGen approaches RAG from a more conversational and integrated perspective. It provides a flexible Memory protocol, which is an interface that you can connect to various backends, most commonly a vector store.
I have found it straightforward to implement RAG in AutoGen by connecting an agent to a vector database like ChromaDB using the ChromaDBVectorMemory extension. When a user asks a question, the Memory protocol queries the vector store for relevant chunks of text and injects them directly into the agent’s conversational context.
The focus here is on building a massive, external knowledge service and providing an agent or a team of agents with the specific, just-in-time information they need to effectively handle the current conversation.
Feature 4. Human-in-the-Loop
Human oversight remains crucial for reliable AI agent systems, and both frameworks provide different approaches to human intervention.
Semantic Kernel
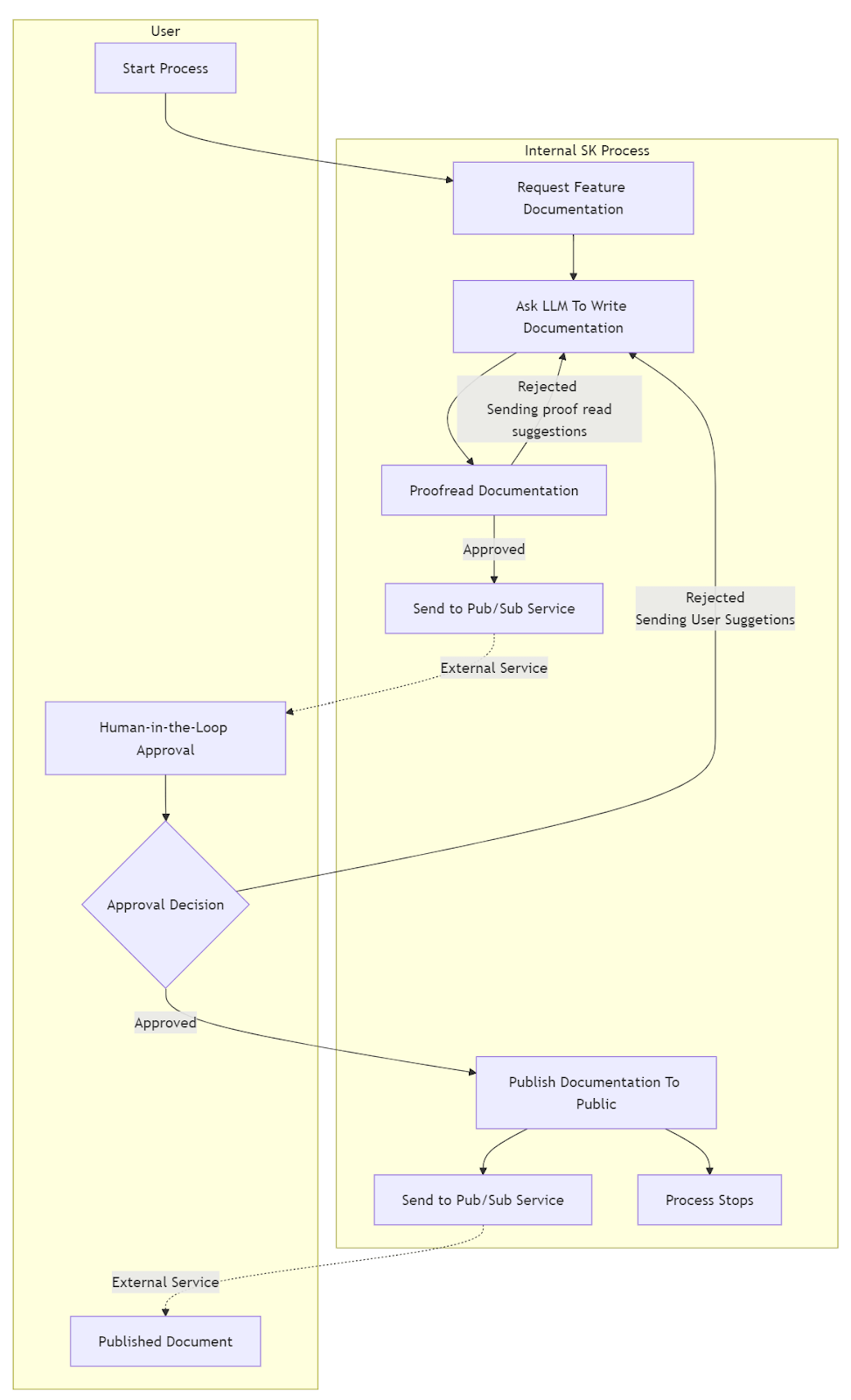
Human-in-the-Loop (HITL) in Semantic Kernel is best described as a formal process control mechanism. Using its Process Framework, you can design a workflow that explicitly pauses at a critical step.
For example, before an agent executes a sensitive action like deploying code or sending an email to a customer, the process can halt.
It can then use a ProxyStep to emit an event to an external system, notifying a human that their approval is required.
The entire process remains in an idle state until the human provides a response like approve or reject, at which point the workflow resumes. This is ideal for building auditable systems with formal approval gates.
AutoGen
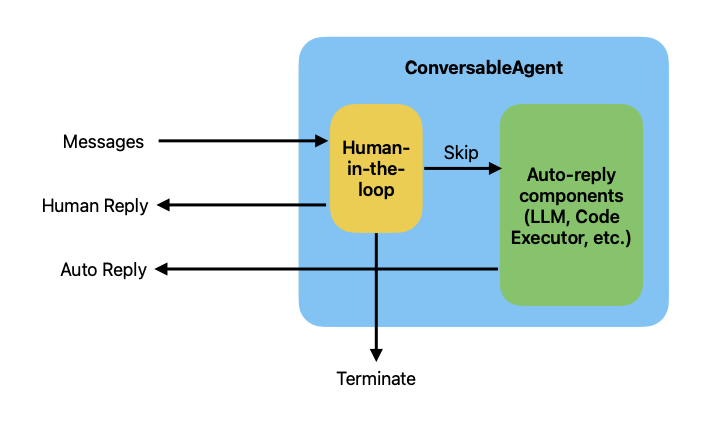
AutoGen’s approach to HITL is to treat the human as just another participant in the conversation. This is achieved through the UserProxyAgent. You can configure this agent with a human_input_mode parameter, which has three settings :
- ALWAYS: The
UserProxyAgentprompts the human for input at every turn. - TERMINATE: The agent only prompts for human input when the conversation is about to end or has reached a deadlock.
- NEVER: The agent runs fully autonomously.
With this model, the human isn’t interrupting a process; they are taking their turn to speak. This is perfect for interactive scenarios where the agent needs clarification, feedback, or guidance from the user to proceed.
Semantic Kernel vs. AutoGen: Integration Capabilities
Modern AI systems don’t live in isolation; they need to integrate with various models, data sources, and infrastructure. Both Semantic Kernel and AutoGen recognize this, but they integrate in different ways.
Semantic Kernel
Semantic Kernel provides a broad range of AI service integrations, reflecting its role as a general AI SDK.
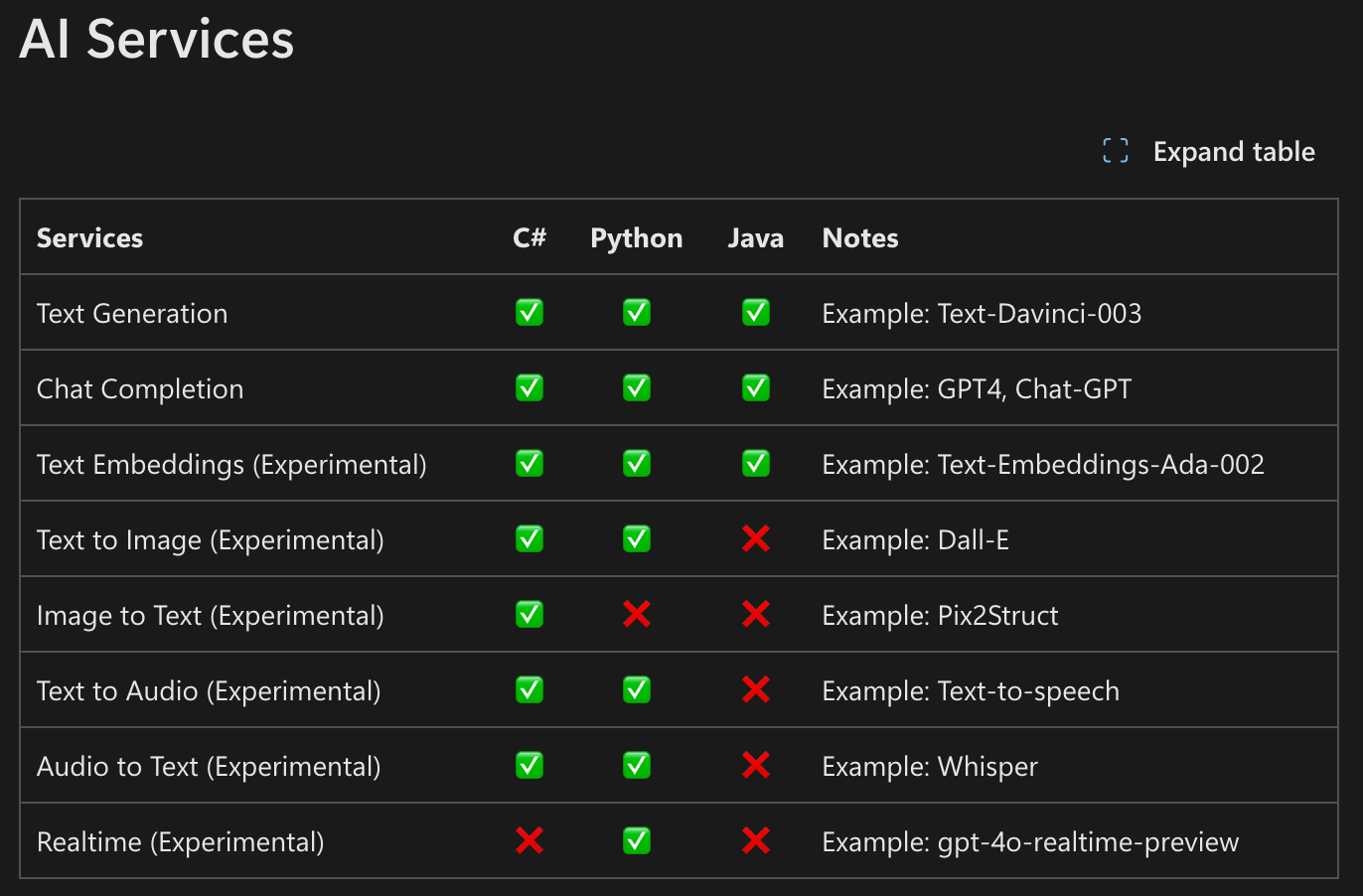
- LLM Providers: SK supports connectors for OpenAI (and Azure OpenAI), Hugging Face models, and other AI services. You can use either OpenAI’s GPT-5 API or an open-source model on HuggingFace just by configuring a different connector.
- Modalities: Although text is the primary domain, SK has experimental integration for vision and audio tasks too, like text-to-image with DALL-E, speech recognition with Whisper.
- Plugins for Microsoft Services: SK can integrate with other parts of the Microsoft ecosystem via its plugin system. For instance, there’s a Logic Apps plugin that lets an agent invoke workflows in Azure Logic Apps and an Azure Functions or Container Apps integration for executing code safely.
- Memory/Data: As discussed earlier, SK integrates with vector databases for memory. It can also connect to Azure Cognitive Search or other data retrievers as plugins. Essentially, if there’s a REST API or SDK for a service, you can wrap it as a Semantic Kernel plugin and thereby make it available to your agents.
One thing SK does not have is a proprietary UI or studio for agent design – it’s meant to be embedded in your applications or used via code.
AutoGen
AutoGen, while also a Microsoft project, is positioned as a more neutral, horizontal integration hub. Its ecosystem is broad and diverse, with integrations for many popular third-party tools and platforms. This includes:
- Other Agent Frameworks: Connectors for LlamaIndex, LangGraph, CrewAI, and more.
- Observability Tools: Integrations with platforms like AgentOps.
- Memory and Data: Support for numerous vector databases (Chroma, PGVector) and memory services (Zep, Mem0).
This approach makes AutoGen an excellent choice for building a flexible, best-of-breed MLOps stack where you can pick and choose the best tool for each part of your application.
Semantic Kernel vs AutoGen: Pricing
Both Semantic Kernel and AutoGen are open-source projects released under the permissive MIT license, which means the frameworks themselves are free to use. However, the ‘free’ license is only the beginning of the cost story.
The true Total Cost of Ownership (TCO) comes from the services and infrastructure required to run your agents in production.
These indirect costs include:
- LLM API Calls: This is often the most significant cost. Multi-agent systems, especially conversational ones built with AutoGen, will generate a large number of LLM calls in a single run, which can quickly become expensive.
- Cloud Compute: You will need to pay for the virtual machines or containers that host your agentic applications.
- Third-Party Services: If you integrate with managed services like a vector database, an observability platform, or other paid APIs, you will incur subscription fees for those tools.
👀 Note: It is also important to clarify a common point of confusion. There is a company called AutogenAI that offers an enterprise platform for proposal writing with a custom pricing model. This company is separate from Microsoft’s open-source AutoGen framework.
How ZenML Helps You Use Both These Platforms with Ease
After experimenting with both Semantic Kernel and AutoGen, you might wonder how to manage and deploy these agents in a production environment.
This is where ZenML comes into play. While Semantic Kernel and AutoGen excel at the ‘inner loop’ of development, i.e., creating and defining the agents and their behaviors, ZenML supports the ‘outer loop’ – the ongoing lifecycle, orchestration, and maintenance of those agents in production.
Here are the features ZenML offers that will help you manage your agentic AI in the most efficient way possible:
1. Pipeline Orchestration
ZenML is an MLOps + LLMOps framework that allows you to build pipelines, which can include steps for data preparation, model training, RAG indexing, agent execution, and evaluation.
You can easily embed an SK or AutoGen agent as a step in a ZenML pipeline, thereby integrating it with the rest of your workflow.
For example, you might have a pipeline that updates your vector database index (for RAG) and then runs an AutoGen agent to answer questions using that fresh index. ZenML will orchestrate these steps, schedule them, and ensure they run in the right order.
Here’s a basic step you can create in ZenML:
from zenml import step
@step
def load_data() -> dict:
training_data = [[1, 2], [3, 4], [5, 6]]
labels = [0, 1, 0]
return {'features': training_data, 'labels': labels}And here’s a code for the pipeline:
from zenml import pipeline
@pipeline
def simple_ml_pipeline():
dataset = load_data()
train_model(dataset)2. Reproducibility and Tracking
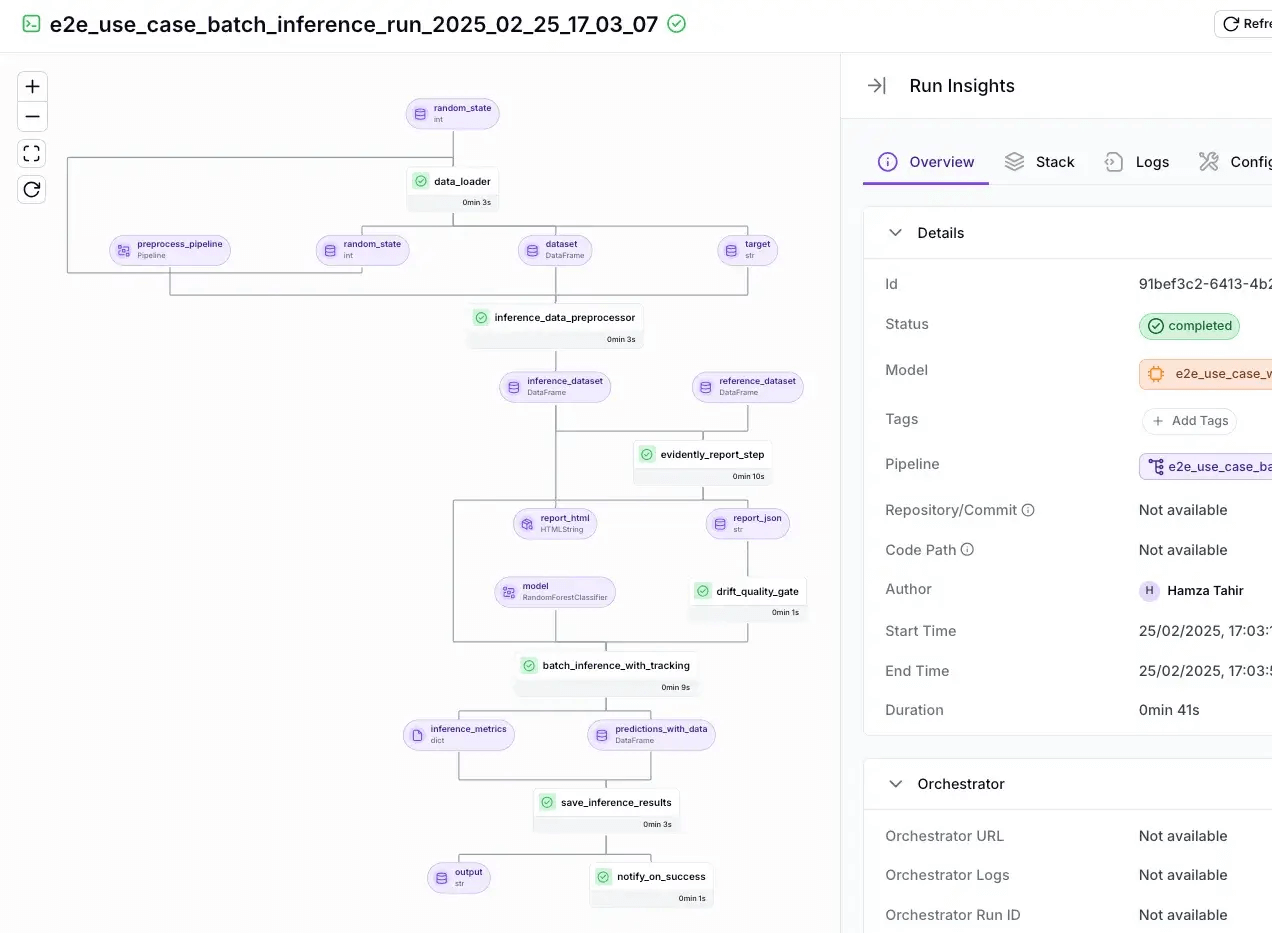
Because ZenML tracks artifacts and metadata for each pipeline run, it gives you visibility into how your agents are performing over time. You’ll know exactly which version of your Semantic Kernel agent was used in a given run, and you can compare outputs across versions.
This addresses a key pain point in agent development: things can be nondeterministic, so having robust logging and versioning via ZenML helps in understanding if an update to your agent or model made things better or worse.
3. Scaling and Deployment
When it’s time to deploy an agent-enabled application, ZenML can package your pipelines (which include the agent code) into production-friendly bundles.
It abstracts away the infrastructure details – whether you’re running on Kubernetes, Airflow, or a serverless setup, ZenML decouples the code from the environment.
This means you can develop your SK or AutoGen agent locally, then deploy it with ZenML on a cloud cluster without rewriting anything.
ZenML handles containerization, scheduling, and integration with cloud resources. The benefit is that you avoid the ‘it works on my machine’ syndrome for your AI agents; ZenML ensures it works in production too.
4. Monitoring and Feedback
In a production setting, you’d want to monitor your agents’ performance (accuracy of responses, latency, etc.) and perhaps retrain or tweak them based on real-world data.
ZenML provides a framework to automate feedback loops. For instance, you could log user-agent interactions, have an evaluation step that uses ZenML’s evaluation module or custom metrics to rate the agent’s responses, and then feed those insights into improving the agent or switching strategies.
This kind of end-to-end feedback loop is beyond the scope of Semantic Kernel or AutoGen themselves – they focus on the agent’s logic, while ZenML ties that logic into a continuous improvement process.
Ultimately, ZenML complements both SK and AutoGen. Think of SK/AutoGen as the engine that defines what the AI agent does, and ZenML as the vehicle that carries that engine through the journey of development to deployment and iteration.
In my experience, using ZenML with these frameworks gives the best of both worlds: you get powerful agent behaviors from SK or AutoGen, and you get the reliability, scalability, and reproducibility from ZenML to actually use those agents in a real product.
Which Agentic AI Framework Is Best For You?
Choosing between Semantic Kernel and AutoGen ultimately depends on your project’s needs and your team’s working style. Here are some guidelines to help you decide:
✅ Choose Semantic Kernel if your primary goal is to build reliable, auditable, and tightly integrated agent systems. It’s the superior choice when you need fine-grained control over each step of the workflow and want to leverage a strong architectural framework in a multi-language environment. If you’re working on enterprise software (especially in C# or Java) and require explicit orchestration patterns with predictable behavior, SK’s structured approach will serve you well.
✅ Choose AutoGen if your primary goal is rapid prototyping and exploring the emergent capabilities of multi-agent systems. AutoGen shines when you want to get an agent collaboration up and running quickly without designing the entire control flow yourself. It’s great for Python-centric teams who want to define agent roles and let them converse dynamically. If you’re experimenting with what multiple agents can do together – brainstorming, debating, solving complex tasks – AutoGen’s high-level API and flexible patterns will let you iterate fast.
✅ Use ZenML in any scenario where you need to take an agentic application from a proof-of-concept to a robust production system. Regardless of whether you built your agents with Semantic Kernel or AutoGen, ZenML will help you package, deploy, monitor, and evolve those agents in the real world.
ZenML’s upcoming platform brings every ML and LLM workflow - data preparation, training, RAG indexing, agent orchestration, and more - into one place for you to run, track, and improve. Type in your email ID below and join the early-access waitlist. Be the first to build on a single, unified stack for reliable AI. 👇


