

On this page
In the last year or so, the agentic AI space has leaped from building simple chatbots to intricate, multi-step systems. The jump in sophistication has made many look for frameworks that can manage intricate logic, interact with external tools, and maintain context over long periods.
Both Haystack and LlamaIndex help you build agentic AI workflows. However, they differ in primitives, architecture, and focus.
In this article, we compare Haystack and LlamaIndex across features, integration capabilities, pricing, and ideal use cases to help you find the ideal tool for your next agentic workflow.
Haystack vs LlamaIndex: Key Takeaways
🧑💻 Haystack: An AI orchestration framework for building customizable, production-ready LLM applications. It uses a modular, pipeline-based architecture where components like models, vector databases, and file converters are connected to create explicit, graph-based workflows.
🧑💻 LlamaIndex: A RAG-first toolkit designed to build LLM-powered applications and agents over your data. The new AgentWorkflow favors a code-first style for grounded retrieval and data indexing for your LLM app. Although young, it’s evolving fast and is perfect for tight control over data and context, though it lacks pipeline-level serialization.
Haystack vs LlamaIndex: Framework Maturity and Lineage
The table below compares the framework maturity of Haystack vs LlamaIndex:
| Metric | Haystack | LlamaIndex |
|---|---|---|
| First Public Release | v1.0 – Dec 2021 | v0.0.1 – Nov 2022 |
| GitHub Stars | 22,700 | 44,300 |
| Forks | 2,400 | 6,400 |
| Commits | 4,300 | 7,100 |
| PyPI downloads (last 30 days) | 363,000 | 5 million |
Haystack was released nearly a year before LlamaIndex’s debut in November 2022.
Despite that, LlamaIndex has seen explosive growth in community engagement. It boasts nearly double the GitHub stars and forks of Haystack, indicating a larger popularity and highly active developer following.
If we compare framework maturity in the real world, LlamaIndex has over ten times the number of PyPI downloads in the last month compared to Haystack (~5 million vs. ~394k). The numbers signal a higher adoption rate across projects.
Haystack vs LlamaIndex: Features Comparison
| Features | Haystack | LlamaIndex |
|---|---|---|
| Agent Primitive and Loop Execution | Agents are defined as a pipeline with support for branching and parallel tools via pipeline nodes and edges. | Programmatic, event-driven AgentWorkflow where steps conditionally return events to create flexible branches and loops. |
| Serialization | Serializes the entire pipeline structure (components, connections) to YAML for versioning and collaboration. | Serializes the workflow state via a Context object for persistence and durability context retention; no YAML export feature. |
| Retrieval as an Agent Tool (RAG) | Native RAG support. Wraps any component, including a full RAG pipeline, as a ComponentTool for modular use by an agent. | Integrates data retrieval via QueryEngineTool and RetrieverTool. |
| Human-in-the-Loop | Supports human approval steps via special tools or pipeline pauses. | Native HITL support through its event-based system allows asynchronous pausing until a human provides input. |
Feature 1. Agent Primitive and Loop Execution
The core of any agentic framework is shaped by its orchestration model. That is, how it defines, executes, and controls the task flow. Haystack and LlamaIndex follow two different paradigms: a graph-based system vs a programmatic, event-driven one.
Haystack
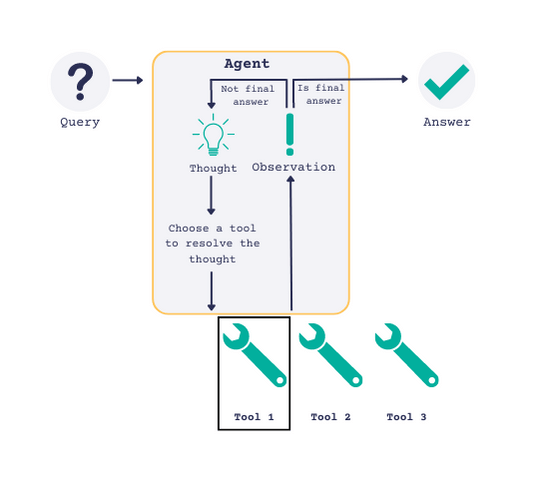
Haystack’s orchestration is built around the Pipeline, a one-pass multigraph system where components are nodes and their connections are edges. We can say the design is highly modular yet static because components are already declared, so the workflow’s structure is explicitly defined.
A Haystack Agent is a specialized component that operates within this pipeline. The agent loops through a reasoning cycle: it queries LLM, decides on tool usage, invokes tools, and continues the loop until the goal is accomplished.
You can assemble agents with a chat generator and a list of tools, like searching the web, performing calculations, and so on. In fact, you can include an Agent inside a larger Haystack Pipeline, alongside other nodes.
For complex graphs with multiple agents, Haystack provides specific components:
ConditionalRouterto direct the data flow down different branches based on runtime conditions.BranchJoinerto merge the outputs of multiple branches back into a single path. It can take the output from a downstream component and route it back to an earlier one in the pipeline.
Overall, Haystack’s component-based method makes the control flow visible, structured, and debuggable. The trade-off is a bit more upfront design compared to entirely code-driven loops.
LlamaIndex
LlamaIndex approaches agents in a more code-centric way. Instead of drawing static pipelines, you typically write Python code that defines the agent’s behavior.
At the core is the AgentWorkflow, an event-driven orchestration system for async steps. A ‘step’ is a Python function decorated with @workflow.step that processes an incoming event and returns a new one.
You can branch, loop, or pause for human input on events, which suits interactive apps and fine-grained approvals. You can plug in query engines over your own data for grounded responses.
Basically, a LlamaIndex agent is ‘LLM + loop + tools assembled programmatically.’
The upside is flexibility and speed for prototyping. You get direct control over logic, data access, and tool use without a fixed pipeline schema. The trade-off is more responsibility for guardrails like step limits, termination, and error handling, since there is no built-in pipeline serialization. (We talk about this next)
Bottom line: Both Haystack and LlamaIndex follow different approaches for loop execution.
Haystack’s pipeline-based model is analogous to infrastructure-as-code, where the structure is the primary artifact. It’s often easier to version, monitor, and maintain in an enterprise setting.
LlamaIndex’s event-driven model resembles modern asynchronous programming paradigms. The control logic is the primary artifact and gives you more precise control over the agentic workflow.
Feature 2. Serialization
Serialization is the cornerstone of MLOps and production-grade workflows. Haystack and LlamaIndex approach this with fundamentally different objectives.
Haystack
Haystack supports exporting a pipeline configuration to YAML and loading it back later. In practice, this means you can design an agent or workflow in Python, dump it to a YAML file, and then reuse or share it later, even in another environment with compatible components.
From a practical perspective, using serialization is straightforward. For example, after constructing a Pipeline object in code, you can do:
yaml_str = pipeline.dumps()
with open("agent_pipeline.yml", "w") as f:
f.write(yaml_str)The YAML will save the workflow structure with all components, their types, parameters, and connections. To reconstruct, you simply call Pipeline.loads(yaml_string) and get the same Pipeline object back
Serialization is unique to Haystack and a cornerstone of MLOps and production-grade workflows. It allows you to:
- Version control pipeline architectures are directly in Git.
- Collaborate on and share complex pipelines easily.
- Modify pipeline configurations in YAML without writing new Python code.
- Deploy pipelines in a standardized, repeatable manner, which is perfect for Kubernetes-native environments.
If you need to frequently deploy and update agent workflows or share them between teams, Haystack’s serialization is a big advantage.
LlamaIndex
LlamaIndex (and most similar agent frameworks) do not offer pipeline serialization. There is no one-click export of an agent’s logic to a file. Since LlamaIndex workflows are defined in code, the ‘source of truth’ is your Python code itself.
However, LlamaIndex developer docs suggest a way around it. LlamaIndex has a mechanism for serializing the workflow’s state. This is handled through a special Context object, which comes with a Store property that can be used to store and load data, including chat history, intermediate results, and other variables.
w = MyWorkflow()
handler = w.run()
context = handler.ctx
# Save the context to a database
db.save("id", context.to_dict())
#
# Restart the Python process...
#
w = MyWorkflow()
# Load the context from the database
context = Context.from_dict(w, db.load("id"))
# Pass the context containing the state to the workflow
result = await w.run(ctx=context)LlamaIndex’s state serialization allows building durable and persistent agents. It enables:
- Long-running conversations that can survive process restarts or failures.
- Asynchronous tasks, where a human might take hours or days to respond.
- Stateful agents that maintain memory and context across different sessions.
Bottom line: Ultimately, the two frameworks have different goals.
Haystack focuses on structural persistence.
LlamaIndex focuses on state persistence. The choice depends on whether the priority is the reproducibility of the architecture or the continuity of the agent’s experience.
Feature 3. Retrieval as an Agent Tool (RAG)
Retrieval-Augmented Generation is a core capability for modern agents, allowing them to ground their responses in factual data from external documents.
Both Haystack and LlamaIndex are very strong in Retrieval-Augmented Generation, but their usage in agents differs slightly.
Haystack
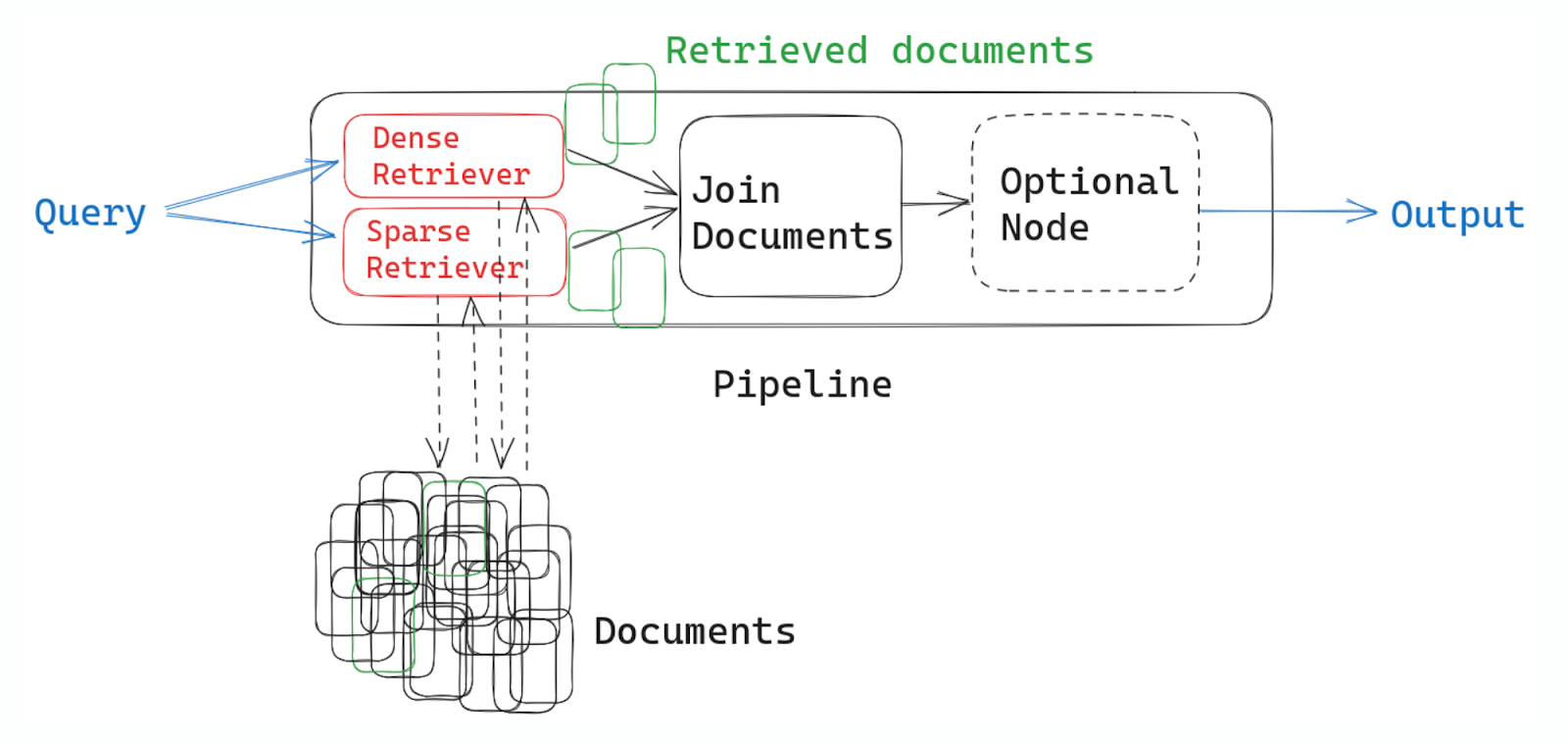
Haystack builds on its roots in retrieval and QA, so RAG fits naturally into its agent design. Its modular architecture allows any component or even an entire sub-pipeline to be wrapped as a Tool with the ComponentTool class for any agent to use.
For example, you might have a ‘document_search’ tool that internally uses a DenseRetriever and returns top documents.
Similarly, you can add multiple retrieval tools, like one for product databases and another for wikis. Frankly, it’s a nice way to inject guaranteed retrieval behavior and reduce hallucinations, while still letting the agent handle the overall conversation or multi-step task.
LlamaIndex
LlamaIndex’s framework design was literally built for RAG. So retrieval is a core part of any agent you build with it.
It offers specific tool classes for retrieval purposes:
- The
QueryEngineTool, which handles both retrieval and synthesis - The
RetrieverTool, which is directly plugged in as a tool that the agent can intelligently select and use
In multi-document scenarios, you can equip a top-level agent with multiple QueryEngine tools, each connected to a different document set or data source. The agent can then act as a router, analyzing a user’s query and dispatching it to the correct specialized document agent.
Because LlamaIndex has a RAG-first nature and native query engines, it supports keyword search, embedding search, hierarchical retrieval, and other sophisticated retrieval logic without you implementing it from scratch.
It’s particularly well-suited if your agent’s primary job is to answer questions or take actions based on proprietary data.
Bottom line: The distinction lies in how RAG is conceptualized.
Haystack treats RAG as a powerful, composable module that can be plugged into an agent.
LlamaIndex treats RAG as a native capability of its agents.
If your agentic workflow uses RAG alongside many other non-RAG tools, Haystack’s modularity is intuitive. If the primary purpose is to reason over a custom data set, LlamaIndex’s specialized and data-native approach is exceptionally powerful.
Feature 4. Human-in-the-Loop
We understand if you don’t want your agents to be completely autonomous. For many critical tasks, agents cannot operate with full autonomy, and human oversight is necessary.
Both Haystack and LlamaIndex acknowledge this and provide robust mechanisms for implementing Human-in-the-Loop (HITL) workflows.
Haystack
In Haystack, the pattern is to add a special tool, like an AskHumanTool or human_in_loop_tool, directly inside an agent workflow.
When invoked, it places a human checkpoint at the spot and signals the agent to pause, wait for external input, and then resume the reasoning loop.
In practice, this can be as simple as posting a question to Slack and resuming once a reply comes back.
Put simply; the human is one of many resources the agent can choose to consult if stuck. This makes Haystack well-suited for workflows like approvals or clarifications, where a human should confirm or guide the next step.
LlamaIndex
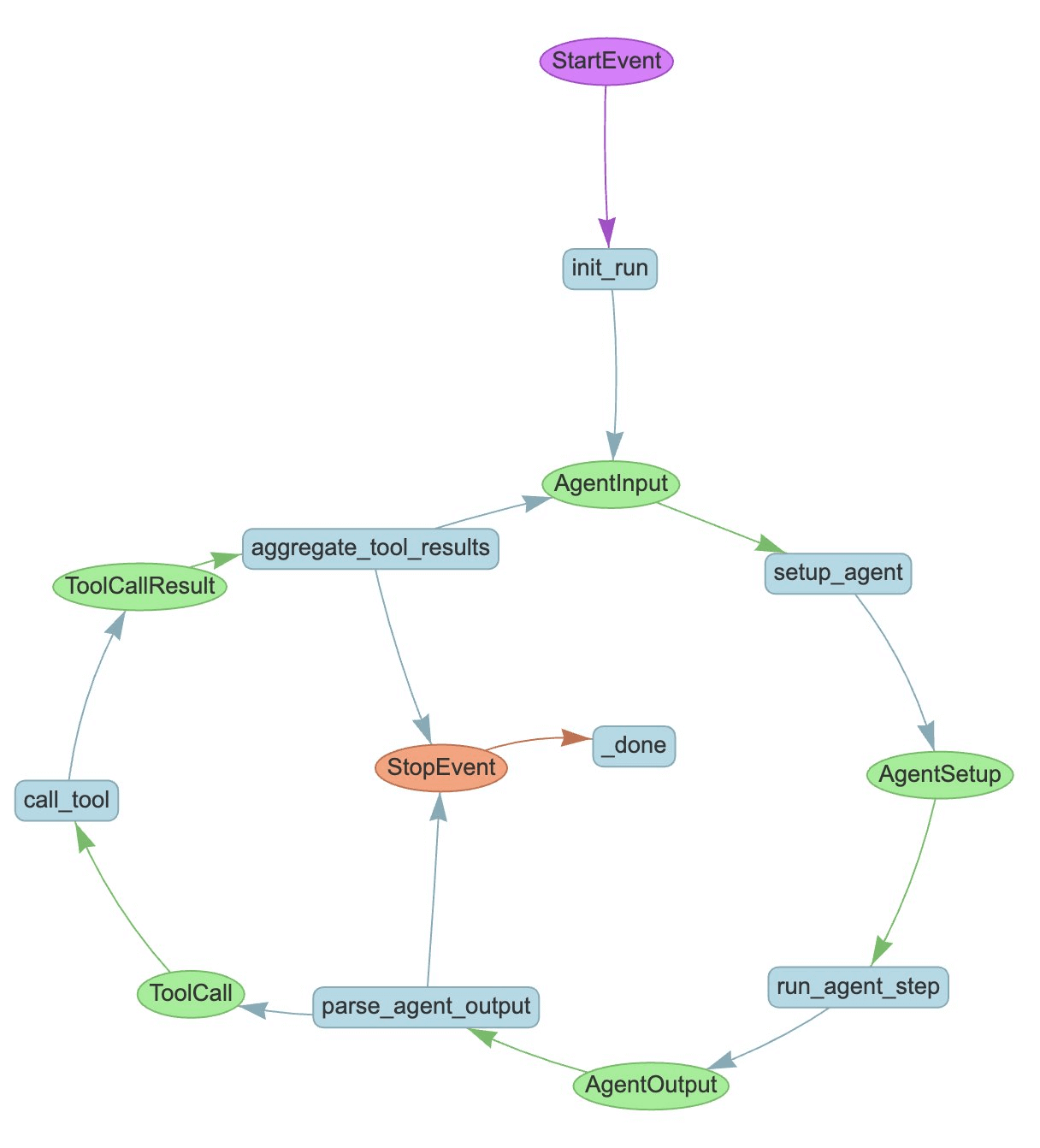
Unlike HayStack, LlanaIndex implements HITL as a native feature of its event-driven workflow system and not as a tool.
You can simply place an InputRequiredEvent to integrate HITL within a LlamaIndex workflow.
When an agent workflow reaches that node, it pauses and won’t continue until a matching HumanResponseEvent is received, making the process feel natural inside a chat or app interface.
The agent doesn’t block the system while waiting. Instead, it yields control, lets your UI handle the user prompt, and resumes once the response is delivered.
The pattern does require some event-handling code, but it allows you to naturally blend human judgment directly into the agent loop.
Haystack vs LlamaIndex: Integration Capabilities
The ability of both Haystack and LlamaIndex to connect with various LLMs, vector databases, and other tools is a big plus.
Haystack
Haystack’s integrations focus on providing stable, enterprise-grade connectors, including:
- Model Providers: OpenAI, Cohere, Anthropic, Mistral, Hugging Face, Google Vertex AI.
- Document Stores: Elasticsearch, OpenSearch, Chroma, Qdrant, Weaviate, Pinecone, Neo4j.
- Monitoring Tools: Arize Phoenix, Opik, DeepEval.
In short, Haystack’s integration strength lies in enterprise environments – it can slot into your infrastructure whether you use AWS, GCP, on-prem, etc. It’s a full-stack approach: from data ingestion to model serving, Haystack tries to cover the needs.
Moreover, the haystack-core-integrations repository serves as a central hub for community contributions, ensuring a consistent standard of quality.
LlamaIndex
LlamaIndex’s integrations focus on data connectivity and flexibility. It has a vast, community-driven ecosystem and some 300 integrations centered around ‘LlamaHub’, including:
- Data Loaders: Hundreds of connectors for sources like Notion, Slack, Google Drive, Discord, and APIs.
- Vector Stores: Integrations with all major providers.
- LLMs: Support for a wide range of models and providers.
- Agent Tools: A growing library of pre-built tools for agents.
Bottom line: If your agent needs to pull from 10 different databases and APIs, the LlamaHub connectors will save you a ton of time. On the flip side, if you need a plug-and-play production deployment with minimal coding around it, LlamaIndex by itself will need some scaffolding (which is where ZenML or similar can help, as we’ll discuss).
Haystack vs LlamaIndex: Pricing
Both frameworks are open-source and free for self-hosted use. However, both also offer managed commercial platforms with distinct pricing models.
Haystack
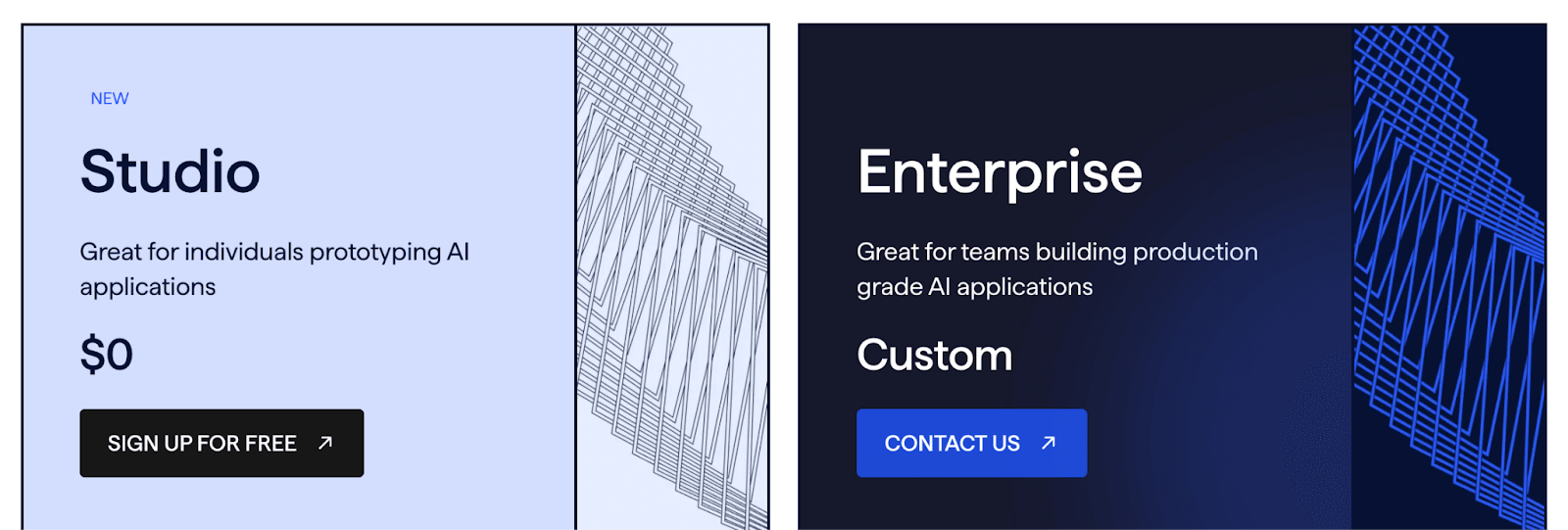
The Haystack framework is open-source and free. Deepset also offers a commercial ‘deepset AI Platform,’ which includes a free ‘Studio’ tier for prototyping and custom-priced Enterprise plans.
LlamaIndex
The open-source LlamaIndex library is MIT-licensed and free to use. You can pip install llama-index and build with it locally or on your own servers without paying anything (aside from costs of the underlying LLM API calls and infrastructure).
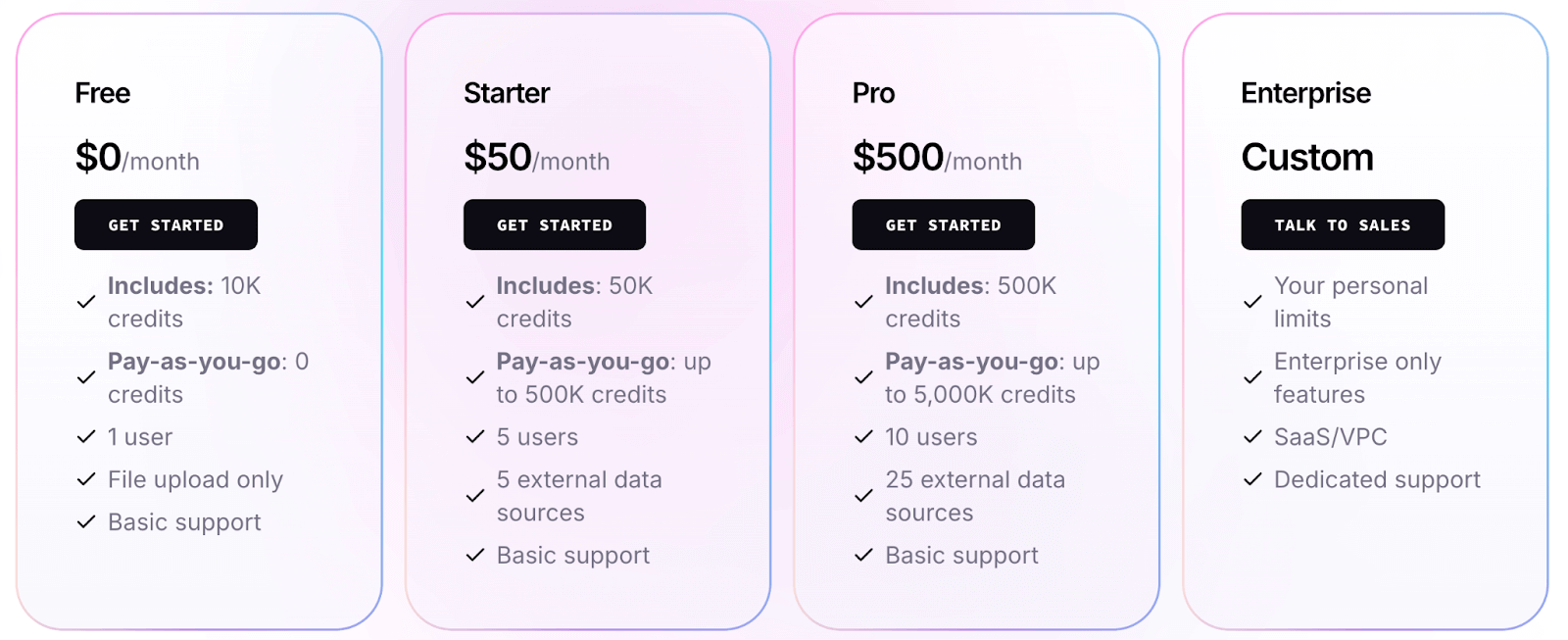
LlamaIndex also provides a hosted platform, which offers more and better features. Their pricing (as of 2025) is credit-based:
- Free tier: $0, includes 10k credits (sufficient to try out with smaller workloads).
- Starter plan: $50 per month, includes 50k credits.
- Pro plan: $500 per month, includes 500k credits.
- Enterprise plan: Custom pricing
How ZenML Manages the Outer Loop when Deploying Agentic AI Workflows
Haystack and LlamaIndex are powerful frameworks for the ‘inner loop’ of development: defining, writing, and iterating on agentic behavior.
However, they do not address the challenges of the ‘outer loop,’ which covers the entire lifecycle of productionizing, deploying, monitoring, and continually improving these agents over time. This is where a dedicated MLOps and LLMOps framework like ZenML becomes essential.
ZenML acts as the unifying outer loop that governs the production lifecycle of your agents, regardless of whether they are built with Haystack, LlamaIndex, or any other tool.
1. Pipeline Orchestration
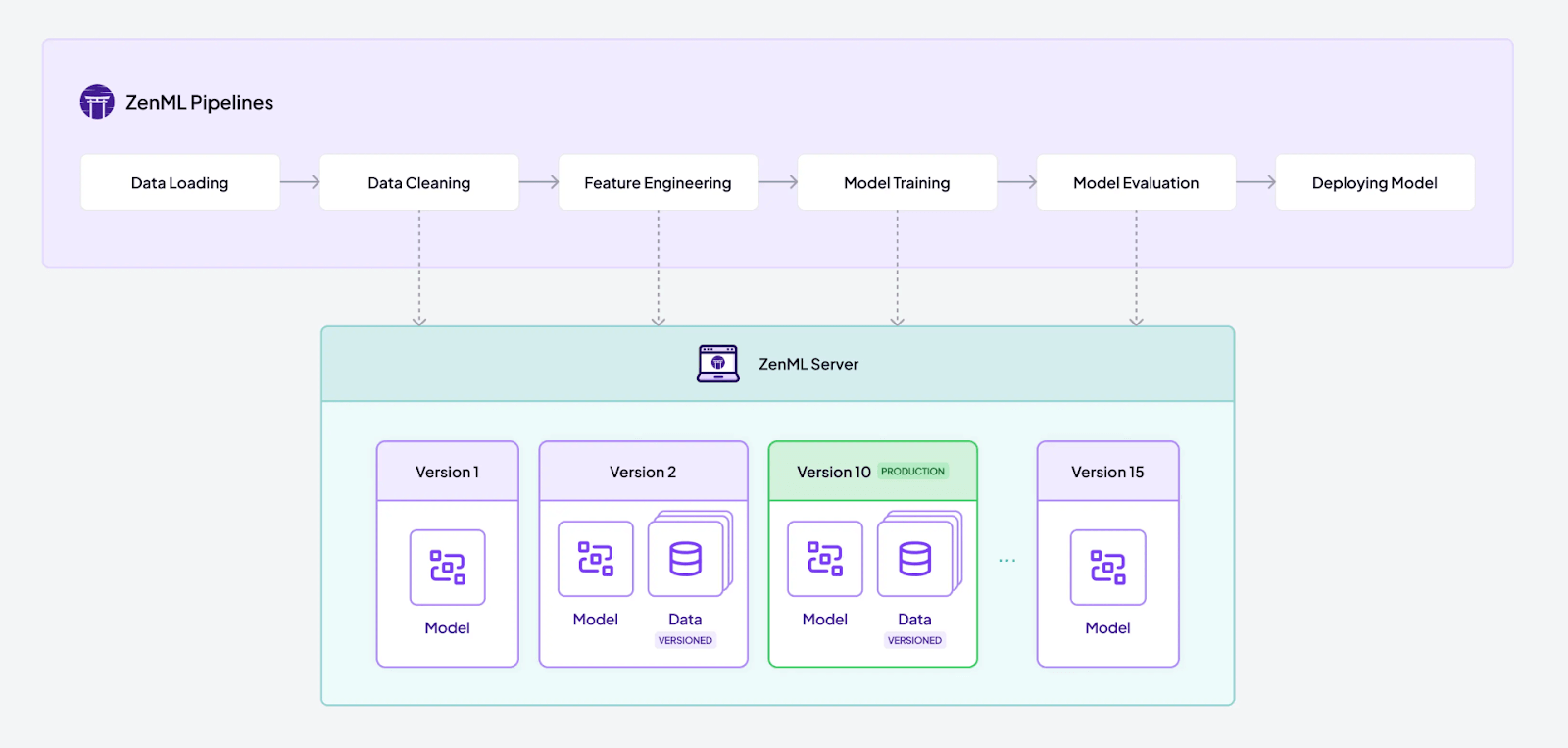
A ZenML pipeline can wrap an entire agentic workflow. Steps in the pipeline can handle data preparation for RAG, execute Haystack and LlamaIndex agents, evaluate results, and collect feedback on outputs.
ZenML will orchestrate these with any orchestrator (Airflow, Kubernetes, etc.) behind the scenes. This means even if your agent needs to run on a schedule or as part of a larger process (e.g., nightly report generation with an agent), ZenML can handle it.
2. Reproducibility and Versioning
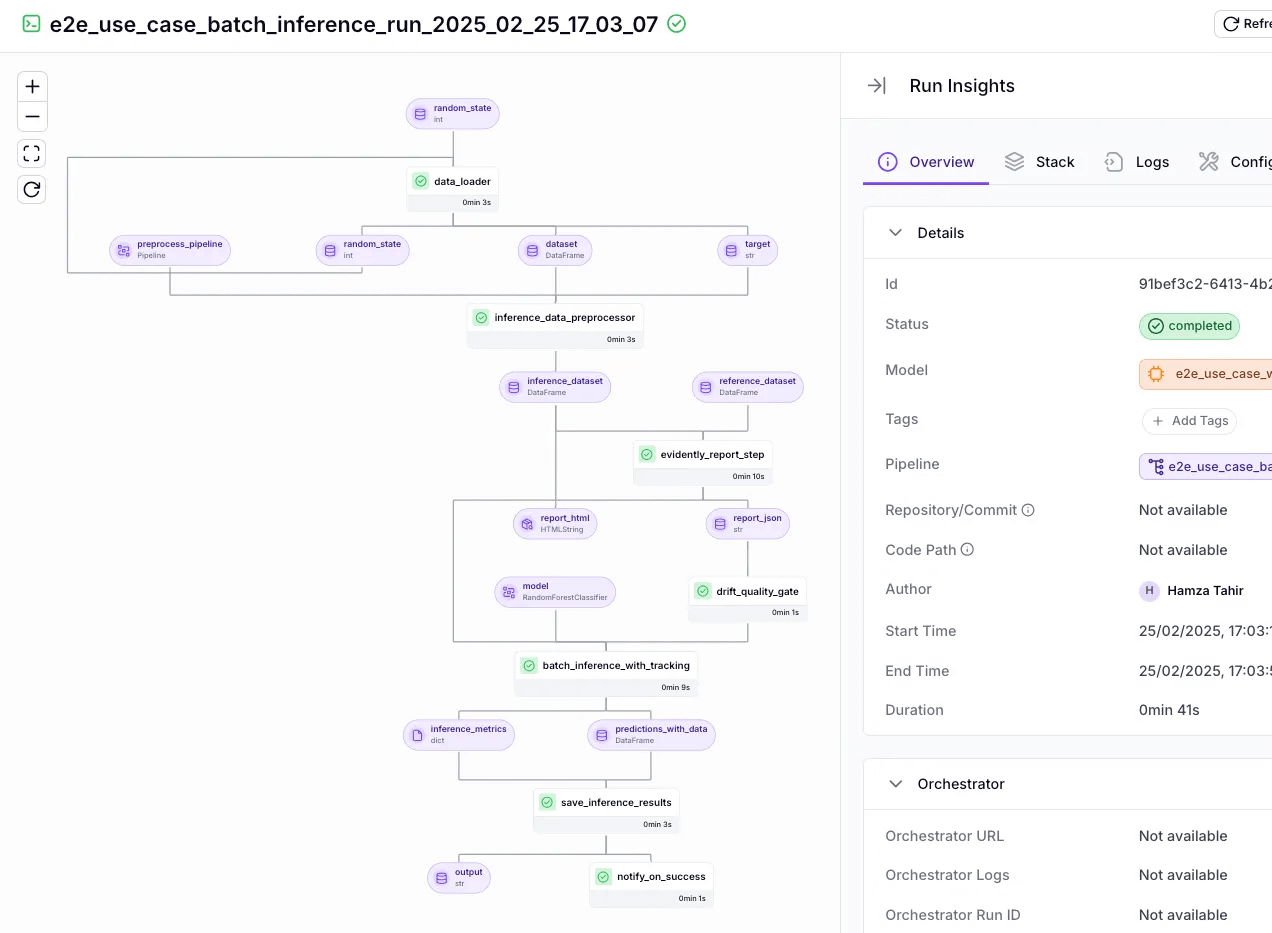
ZenML automatically version-controls your pipeline configurations, data artifacts, and even models.
If you tweak your LlamaIndex agent prompt or Haystack pipeline, ZenML can version those changes. The async is crucial for agents because their behavior can change with minor prompts or tool adjustments – ZenML helps you keep track of what changed and when.
Moreover, ZenML dashboards visualize the lineage of all artifacts, giving your team a complete picture of how your systems are behaving and making it possible to debug failures systematically.
3. End-to-End Deployment
Neither Haystack nor LlamaIndex by themselves provides a full deployment story. With ZenML, you can deploy your agent workflow to various environments consistently.
For instance, using ZenML’s containerization, you can move your agent from local dev to a cloud deployment without rewriting code – ZenML handles the packaging.
ZenML also interfaces with model serving tools, so if your agent or any sub-component needs to be served as an API, ZenML can wrap it up.
4. Quality Checks and Evaluation
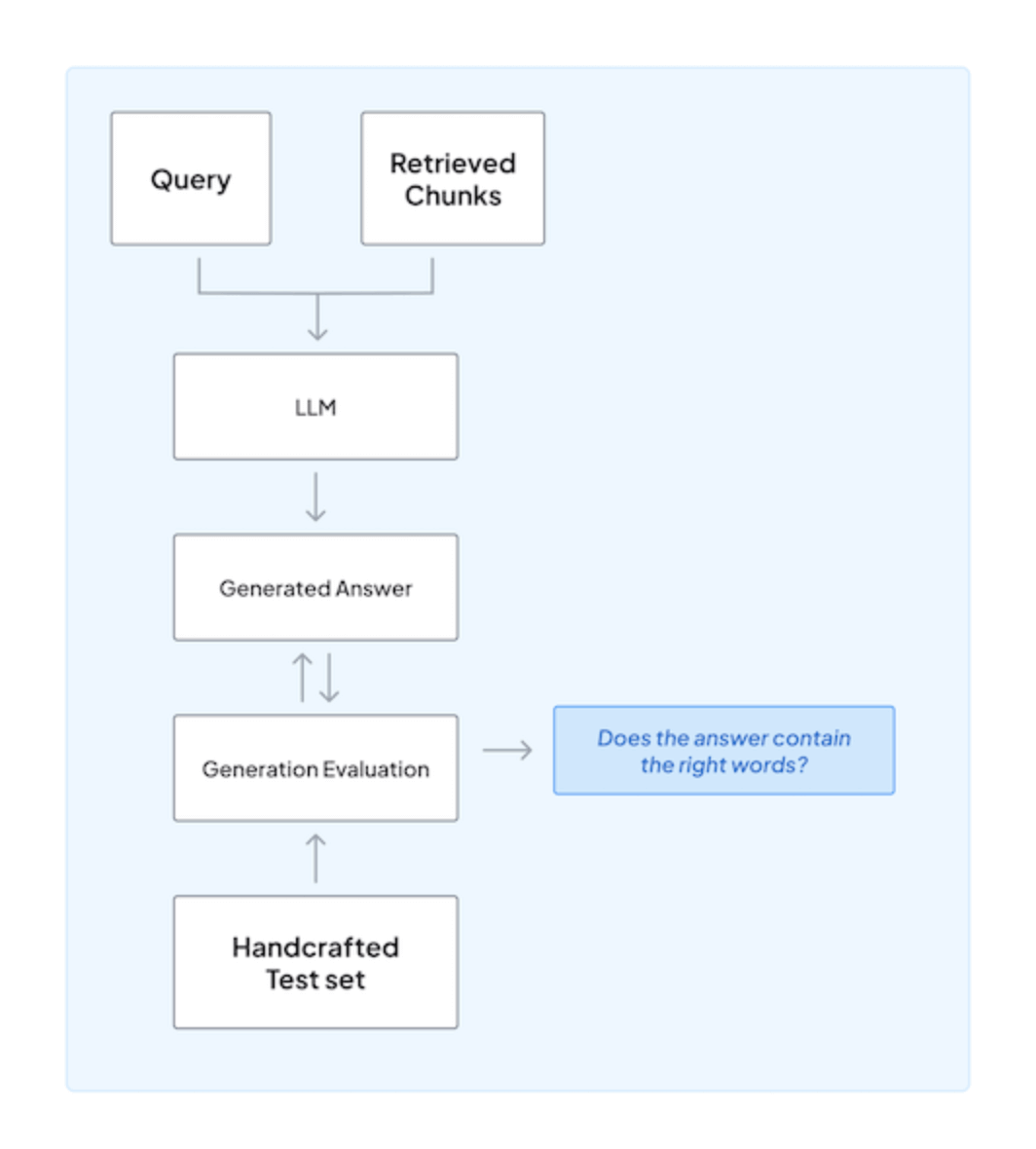
A ZenML pipeline can include steps that automatically run evaluations after each agent execution, flagging bad runs and enabling continuous quality monitoring in production.
ZenML integrates with experiment trackers to let you test different prompts, tools, or parameters with logged runs. You can compare runs to see which prompt gave better results.
👀 Note: At ZenML, we have built several such integrations with tools like LangChain, LlamaIndex, CrewAI, and more. We are actively shipping new integrations that you can find on this GitHub page: ZenML Agent Workflow Integrations.
📚 Other comparison articles to read:
Which One’s Better at Building Agentic AI Workflows?
The choice between Haystack and LlamaIndex depends entirely on your project’s goals and your requirements for control versus flexibility.
✅ Choose Haystack if your primary goal is to build highly reliable, production-grade search and RAG systems that are easy to visualize, version control, and debug.
✅ Choose LlamaIndex if your primary goal is to connect an LLM to diverse and complex private data sources, especially for advanced RAG.
✅ Use ZenML when you are ready to move any agentic application from a research notebook to a robust production system. It works as a control center to manage your agents’ entire development cycle, regardless of the framework used to build them.
If you’re interested in taking your AI agent projects to the next level, consider joining the ZenML waitlist. We’re building out first-class support for agentic frameworks (like LangChain, LlamaIndex, and more) inside ZenML, and we’d love early feedback from users pushing the boundaries of what AI agents can do. With ZenML, you can seamlessly integrate whichever agent framework you choose into robust, production-grade workflows. Join our waitlist to get started.👇


