

On this page
The choice of Vector database for RAG pipelines can make or break your agent’s core paradigm.
A well-chosen vector store recalls relevant documents with low query latency, and a poor choice can slow down responses and cause agents to hallucinate or fail.
However, finding the correct vector database for your RAG pipeline is not a simple task. You have to test each system’s semantic accuracy, query throughput, and metadata filtering under realistic loads.
But don’t worry, we’ve done the testing, so you don’t have to.
For this article, we evaluated and tested the 10 best vector databases for RAG pipelines, assessing them under various parameters and comparing their strengths and weaknesses in real-world agentic AI workflows.
TL;DR for Top Vector Databases for RAG Pipelines
- Pinecone: A fully-managed cloud vector DB. Known for enterprise-grade reliability and scalability.
- Turbopuffer: An S3-based serverless vector + text search engine. Cost-effective with built-in hybrid search even on low tiers.
- Redis (RediSearch): In-memory vector search via Redis Stack. Ultra-low-latency queries and flexible schema.5
- Weaviate: An open-source graph-based vector store. Features a GraphQL API and a modular design.
- Qdrant: An open-source Rust vector database. Excels at real-time embedding search with rich JSON-based payload filtering.
- Milvus (Zilliz Cloud): Open-source, GPU-accelerated vector DB. Optimized for massive scale and high-throughput serving.
- Vespa: A full-featured search platform with vector support. Designed for billion-scale deployments.
- pgvector (PostgreSQL): A Postgres extension for vector columns. Brings HNSW/IVF indexing to PostgreSQL’s relational engine.
- Elasticsearch: A proven distributed search engine. Combines Elasticsearch’s mature text querying and filtering with vector fields.
- MongoDB (Atlas Vector Search): A document database with built-in vector search. Supports hybrid full-text and embedding search, as well as rich JSON filtering.
Our Evaluation Criteria to Pick the Top Vector Databases for RAG Pipelines
When comparing vector databases for RAG, our evaluation focused on three core pillars that matter most in a RAG pipeline.
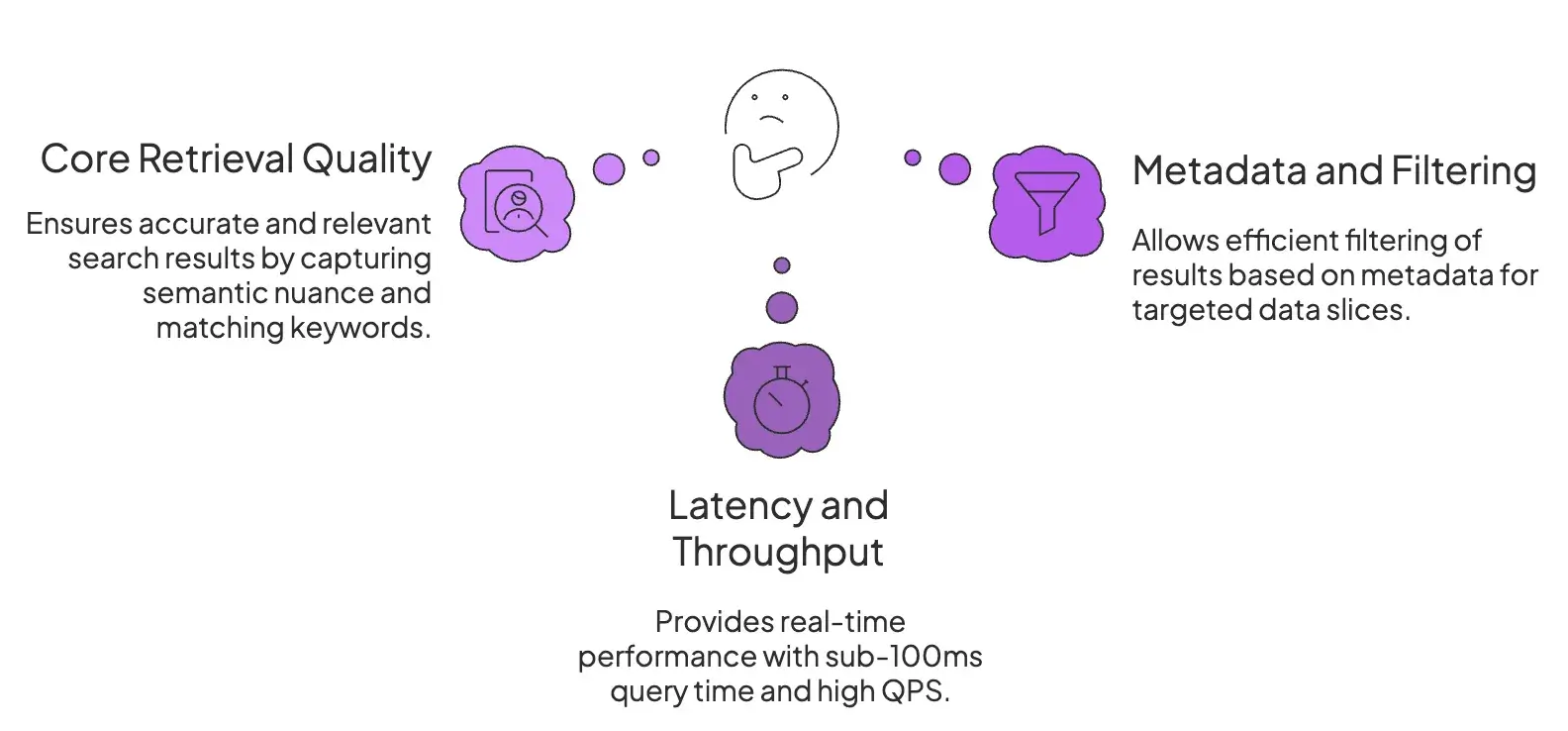
1. Core Retrieval Quality
Retrieval quality is about finding the most relevant context for a query.
Early systems struggled when a query for ‘Apple’ returned documents about the fruit instead of the company. One of our first evaluation criteria was to determine how accurately the system surfaces the right embeddings for a query.
For that, we looked for tools that support:
- Proven Approximate Nearest Neighbor (ANN) algorithms like HNSW and IVF.
- Tuning options that affect recall and relevance.
- Hybrid search capabilities that combine dense vector (semantic) search with sparse vector (lexical) search, like BM25.
Essentially, we evaluated whether the RAG tool can capture semantic nuance while still matching the exact keywords and acronyms that are often critical for relevance.
2. Latency and Throughput
Latency refers to the time elapsed between when a query is received and the output is provided.
Real-time or interactive RAG apps like AI agents and chatbots demand sub-100ms query times, even under high QPS (queries per second) and with datasets scaling to billions of vectors.
We also considered operational factors like ease of deployment, language SDKs, community support, and data persistence for all tools.
3. Metadata and Filtering
Raw vector search is rarely sufficient for production applications. Filtering is crucial for restricting RAG to relevant data slices, like date, customer ID, document source, or security permissions.
We evaluated tools for:
- Does it allow you to pre-filter or post-filter results?
- Does it support Boolean filters and faceted queries?
- Is it able to apply these metadata filters efficiently without hammering performance?
What are the Best Vector Databases for RAG Pipelines?
Here is a quick summary of the 10 best vector databases we tested for building RAG pipelines:
| Tool | Best For | Key RAG Features | Pricing Model |
|---|---|---|---|
| Pinecone | Teams that want a fully managed, serverless database for rapid development. | - Serverless architecture - Hybrid search and real-time indexing - Advanced metadata filtering | Free tier, plans start at a $50/month minimum. |
| Turbopuffer | RAG at a massive scale, where cost-efficiency is the top priority. | - Object-storage architecture - Combined vector and full-text search - High write throughput | Plans start at $64/month. |
| Redis | Applications needing ultra-low latency retrieval for real-time RAG. | - In-memory performance - Flexible indexing (HNSW/FLAT) - Hybrid queries, multi-purpose datastore | Open-source; cloud plans start at $5/month. |
| Weaviate | Developers looking for an AI-native, open-source database with built-in vectorization. | - Integrated vectorization modules - Advanced hybrid search - Multimodal capabilities | Open-source; serverless cloud plans start at $25/month. |
| Qdrant | RAG systems require high performance with complex metadata filtering. | - Advanced pre-filtering - Rust-based performance - Vector compression | Open-source and a free cloud tier; Plans start at $0.014/month. |
| Milvus | Enterprise-grade RAG deployments are needed with high scalability. | - Distributed architecture - Diverse index support and enterprise features (multi-tenancy, RBAC) | Open-source, with managed cloud plans including a free tier and dedicated options. |
| Vespa | Sophisticated RAG applications where custom, machine-learned ranking is critical. | - Unified search and ranking engine - Native tensor support - Real-time performance at scale | Open-source, with usage-based cloud pricing based on allocated resources. |
| pgvector | Teams already using PostgreSQL who want to add RAG capabilities simply. | - Integration with PostgreSQL - Leverages SQL and ACID compliance - HNSW/IVFFlat indexing | Free open-source extension; costs are for PostgreSQL hosting. |
| Elasticsearch | Enterprise RAG systems that require best-in-class hybrid search. | - Mature hybrid search (BM25 + vector) - Distributed scalability - Rich filtering and aggregations | Free and open tier, with cloud plans starting at $95/month. |
| MongoDB | Developers in the MongoDB ecosystem building RAG on a flexible document model. | - Integrated into the core database - Hybrid search with MQL - Scalable via Search Nodes. | Free tier, with usage-based pricing for Atlas clusters. |
1. Pinecone

Pinecone is a fully managed, cloud-native vector database designed for ease of use and massive scale. Its serverless architecture makes it a popular choice for RAG applications, as it abstracts away scaling constraints and infrastructure management, and allows developers to focus on building.
Features
- Use optimized ANN indexes (e.g., HNSW, IVFPQ) for low latency and fast similarity search over dense embeddings.
- You can attach arbitrary key-value metadata to each vector and use boolean filters in queries. Pinecone also supports namespaces within an index for multi-tenant isolation or sharding.
- Supports real-time indexing of vectors, allowing RAG applications to access the freshest data without delays or re-indexing batches.
- Apply rich metadata filtering during the ANN search to retrieve only vectors that match the specified criteria, with minimal impact on latency.
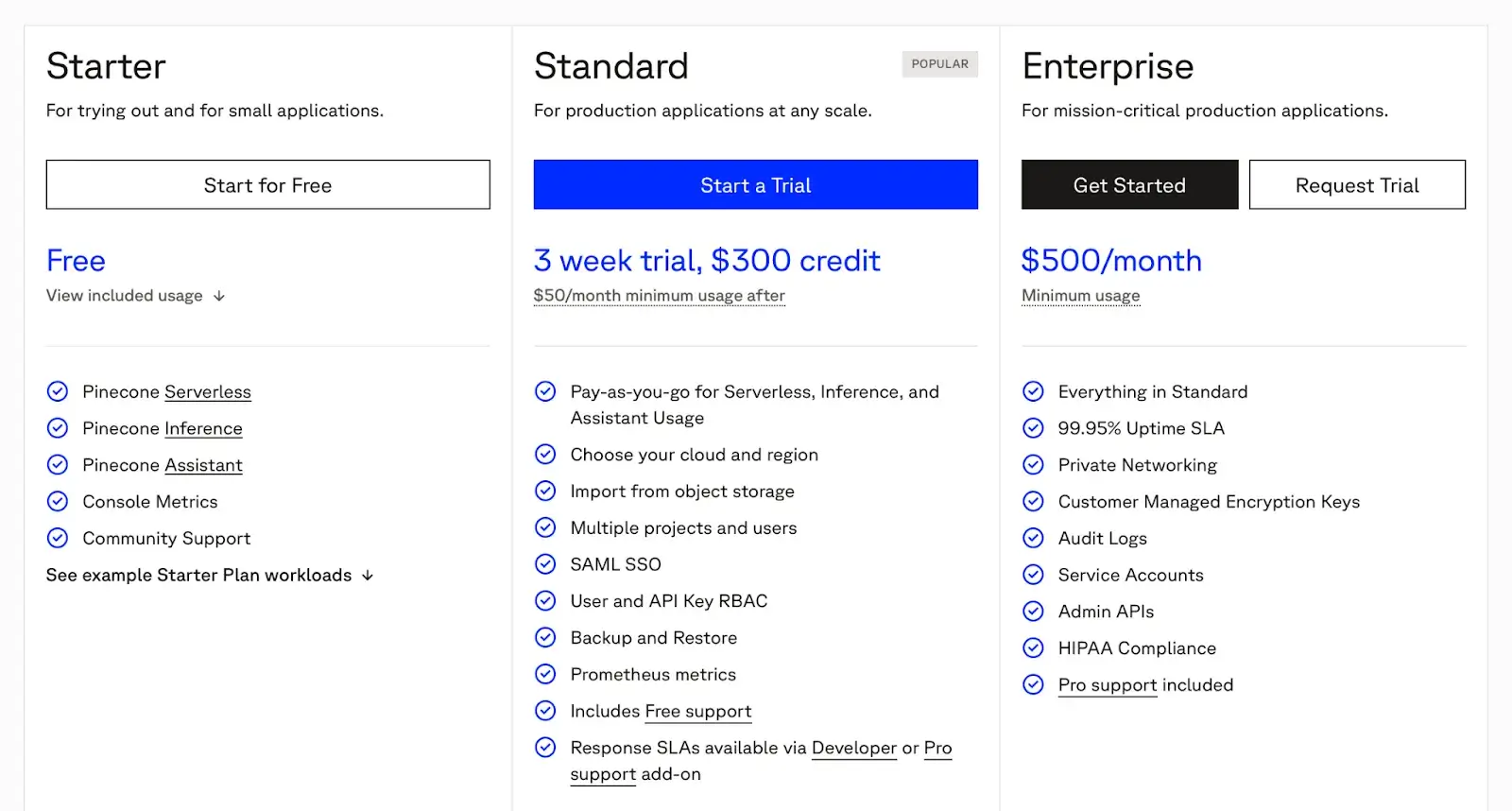
Pricing
Pinecone offers a usage-based pricing model with a free ‘Starter’ tier. The Starter plan (no credit card required) includes up to 2GB of storage, 2 million write units, and 1 million read units. Beyond free usage, it has two paid plans:
- Standard: $50 per month minimum spend
- Enterprise: $500 per month minimum spend
Pros and Cons
The major pro is Pinecone’s simplicity and fully managed, serverless nature, which offloads infrastructure concerns for RAG developers. Its real-time indexing and powerful filtering are built for production. Pinecone also handles large workloads with strong SLA support.
However, Pinecone is a closed-source SaaS. If you need on-premises or more control, Pinecone may not be the right fit. Additionally, scaling beyond the free tier can become costly compared to open-source alternatives.
2. Turbopuffer
Turbopuffer is a serverless vector and full-text search engine built on object storage. It is designed for extreme cost-effectiveness and scalability, making it an intriguing option for RAG pipelines at a massive scale.
Features
- Supports both dense vector similarity and BM25 keyword indexes, allowing RAG applications to combine semantic and lexical relevance in one system.
- Access to storage solutions like S3/Blob makes it cheaper to store large volumes of vector data compared to memory or SSD-based solutions.
- Features a pre-warming function that pre-fetches and caches data in memory, allowing even cold-start requests to be fast.
- Turbopuffer scales to millions of namespaces, enabling natural data partitioning for multi-tenant RAG applications where each tenant's data is isolated for performance and security.
Pricing
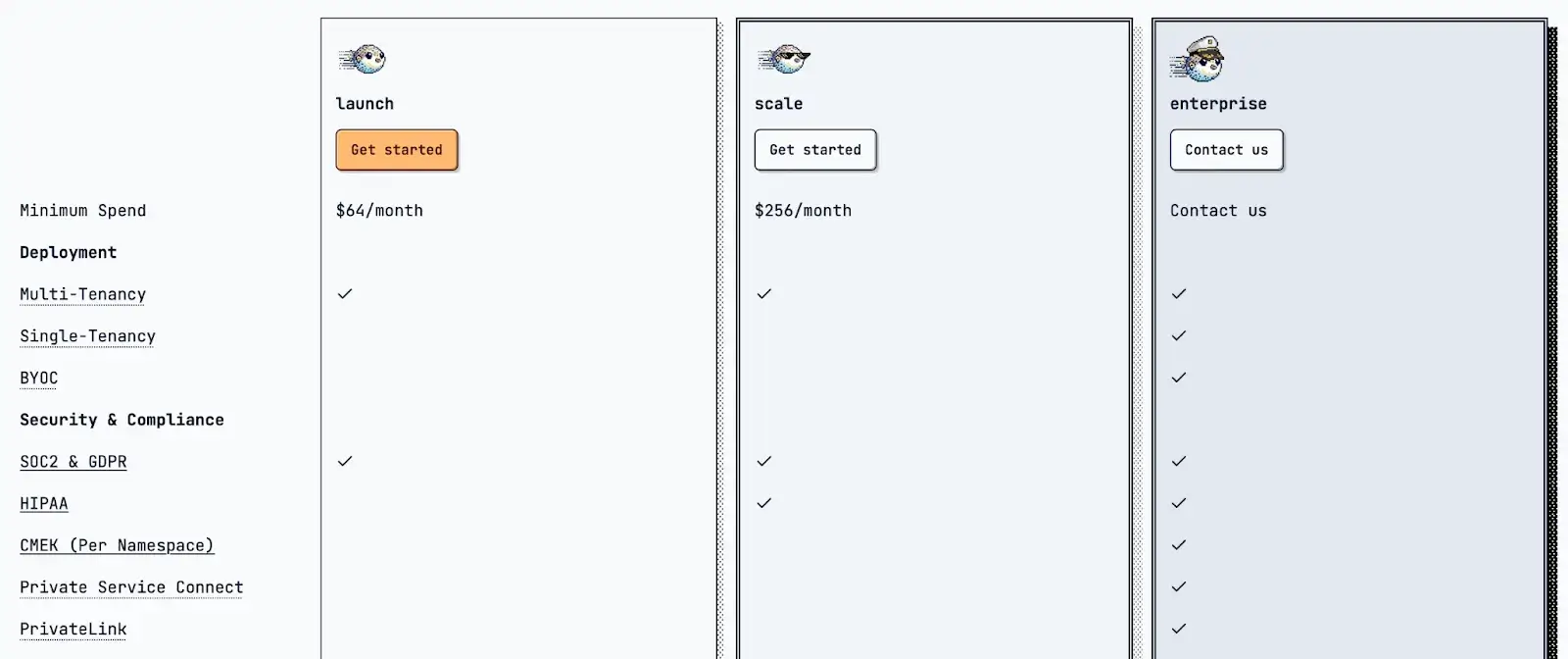
Turbopuffer offers plan-based pricing with a minimum monthly spend. It has three plans:
- Launch: $64 per month
- Scale: $256 per month
- Enterprise: Custom pricing
👀 Note: Within these tiers, usage costs are based on storage, writes, and queries.
Pros and Cons
Turbopuffer stands out for price-performance. A disruptive cost model for large-scale RAG deployment. The enterprise readiness, like SOC2 and GDPR compliance, and community support, comes standard.
The main downside is the trade-off in latency; cold queries and writes have higher latency (p50 > 200ms), which may not be suitable for all real-time RAG use cases. Also, the $64 minimum spend can catch small projects off guard. It is not open-source, so you rely on Turbopuffer’s cloud.
3. Redis
Redis is a well-known data store that offers vector search as a natural extension of its in-memory engine. Its exceptional speed makes it a strong candidate for low-latency RAG applications, especially for teams already using Redis in their stack.
Features
- Being in-memory, vector queries and filters execute with ultra-low latency in the single-digit milliseconds.
- Supports multiple vector search algorithms, including FLAT for exact nearest neighbor search and HNSW for approximate nearest neighbor (ANN) search.
- Beyond vector search, Redis can serve as a semantic cache or an LLM session manager within the same RAG pipeline.
- Perform hybrid searches that combine text queries with vector similarity filtering on numeric, geographic, tag, and text fields. You can embed Boolean logic (AND/OR) around vector queries for complex filters.
Pricing
Redis is open-source, so the core vector search capability is free to use on your own hardware. For managed service, Redis offers three pricing plans:
- Flex: $0.007 per hour
- Essentials: $0.007 per hour
- Pro: $0.274 per hour
👀 Note: Pricing is primarily based on memory (RAM) and can scale up significantly for larger datasets.
Pros and Cons
Redis’s biggest pro is its raw speed, delivering sub-millisecond latency that is hard to beat. Its multi-model nature means you can manage your embeddings alongside other app data in one system.
The primary con is its in-memory nature, which makes it expensive for storing large vector datasets. The RAM requirement grows with data size. Moreover, scaling Redis often requires sharding, which you may need to design yourself.
4. Weaviate

Weaviate is an open-source, AI-native vector database built with a graph-like class schema. The design helps you scale and provide more flexibility in RAG workflows. It offers a rich feature set, including built-in vectorization modules and advanced search capabilities.
Features
- Every query goes through a GraphQL-like schema. You can do nested queries, filter on any property, and include vector-based search in the same query.
- Built-in Vectorization Modules automatically vectorize text and image data at import time through integrations with models from OpenAI, Cohere, HuggingFace, and others.
- Supports hybrid queries that merge keyword (BM25) search with vector similarity in a single API call.
- You can run Weaviate in single- or multi-node clusters, either self-hosted or in Weaviate Cloud Service. It uses HNSW internally by default for vector indexing.
Pricing
Weaviate itself is open-source (BSD-3), so you can self-host it for free. The Weaviate Cloud Service has a free trial and three paid plans:
- Serverless Cloud: $25 per month
- Enterprise Cloud: $2.64 per AIU (AI Unit)
- BYO Cloud: Custom pricing

Pros and Cons
Weaviate is very flexible and developer-friendly for RAG. Its core value is its AI-native design, particularly the built-in vectorization modules and its powerful hybrid search. Multi-modality is a first-class citizen: you can index images, text, and other content seamlessly.
However, defining the schema correctly is critical. Performance can lag behind some bare-metal solutions at a very large scale. Also, while it has built-in vectorizers, the module costs can add up.
5. Qdrant
Qdrant is an open-source vector search engine written in Rust. It’s purpose-built for RAG applications where speed and memory safety are paramount.
Features
- Filter vectors using JSON payload fields such as range, equality, list, and geospatial to ensure high performance even with complex metadata filters.
- Built-in quantization to compress vectors, significantly reducing memory usage and cost while maintaining high search performance.
- Leverage CPU or GPU for vector queries and use HNSW indexing for fast k-NN searches on large datasets.
- Support storing multiple vectors per document (e.g., for title and body) and can handle sparse vectors for hybrid search.
- Use its Recommendation API for multi-vector retrieval to influence results or blend recommendations.
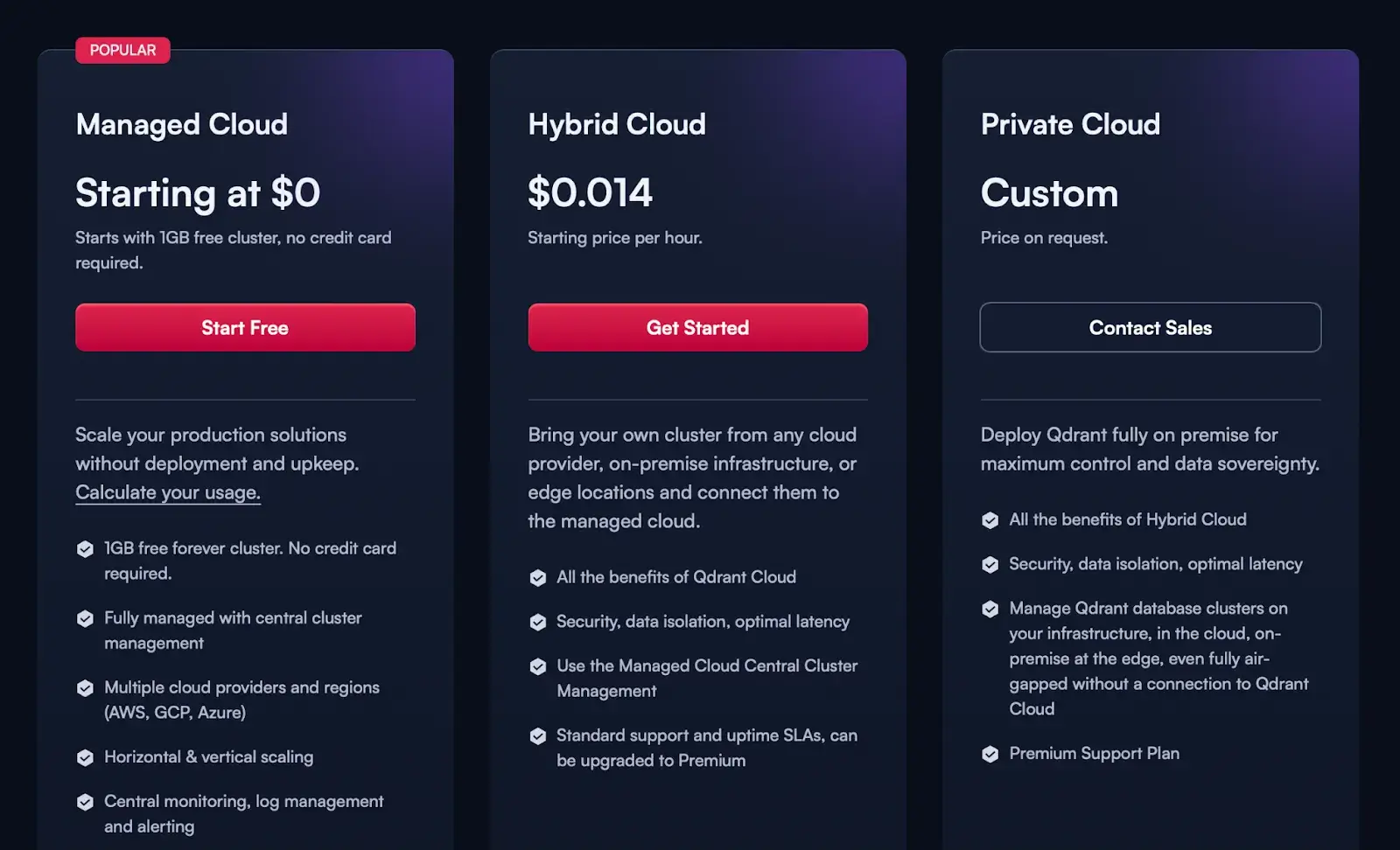
Pricing
Qdrant itself is open-source. The Qdrant Cloud service offers a free 1GB cluster. Beyond free usage, managed clusters are usage-based:
- Hybrid Cloud: $0.014
- Private Cloud: Custom pricing
Pros and Cons
Qdrant’s open-source nature and flexible deployment are strong advantages. Many teams find their Rust core is efficient and simple to get running via Docker. An ideal choice for complex RAG applications that need to slice and dice data.
However, it doesn’t natively do hybrid keyword search or have built-in vectorizers. By default, Qdrant is vector-only; you’d have to manage full-text search separately. Also, clustering (sharding) is relatively new in Qdrant and not as battle-tested as older DBs.
6. Milvus
Milvus is a highly scalable, open-source vector database. Built with a cloud-native, distributed architecture that separates compute and storage, Milvus can scale to handle billions or even trillions of vectors.
It’s a graduate project of the LF AI & Data Foundation, making it a popular choice for enterprise-grade RAG systems.
Features
- Supports HNSW, IVF, PQ, CAGRA index types and similarity metrics (L2, IP, Cosine). You can choose the best index for trade-offs between recall and speed.
- Use up to 10 vector fields per collection with support for a wide range of data types, including sparse vectors for full-text search.
- Allows scalar and string filtering on fields with wildcards (prefix/infix/suffix) on metadata, which is useful for text-based filters.
Pricing
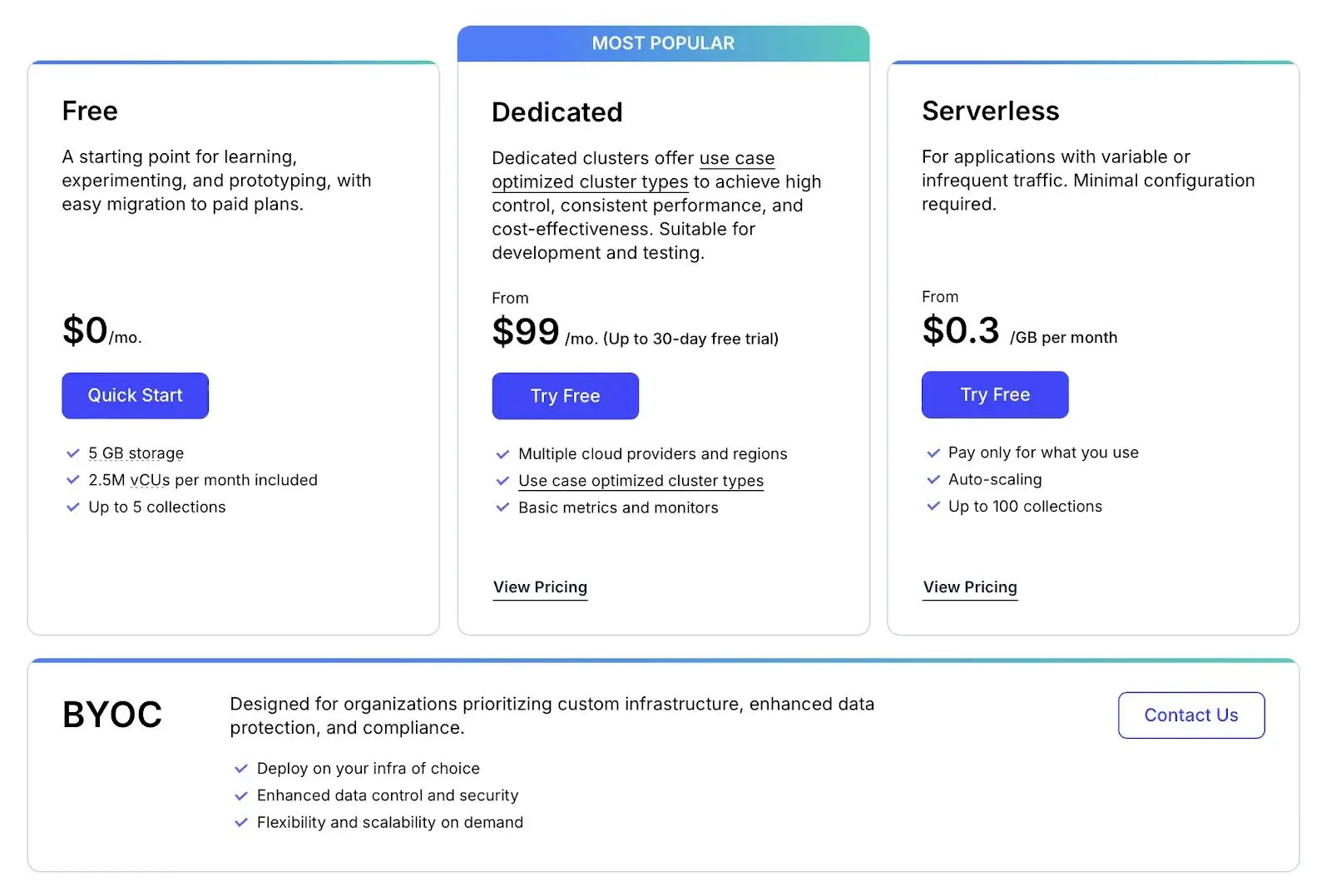
Milvus itself is open-source. Zilliz offers Milvus as a managed service. The free tier includes 5GB of storage (~1 million vectors). Beyond that, you can choose from three paid plans:
- Dedicated: $99 per month
- Serverless: $0.30 per GB per month
- BYOC: Custom pricing
Pros and Cons
Milvus’s support for GPU indexing means you can achieve very high QPS on massive datasets. The multiple index options let you tune for recall or speed. The open-source community is large and active.
On the contrary, Milvus can be complex to operate. Its clustering and resource settings require careful tuning, or you rely on the cloud product. Also, Milvus’s built-in text filtering is not as intuitive as a SQL-like query language; you must define proper field indexes and use expressions.
7. Vespa

Vespa is a powerful open-source engine for big data and AI. It functions as both a fully-featured search engine and a vector database. It’s designed for real-time applications that combine vector search, lexical search, and machine-learned ranking at scale.
Features
- Supports native tensor operations that allow implementing more complex retrieval and ranking models, like multi-vector representations, directly within the database.
- Supports nested conditions, OR/AND chains, and faceted filters on any field. This makes multi-condition RAG queries straightforward.
- Vespa can run neural models at query time. It can apply re-rankers or embed models on the fly, which is unique among vector stores.
- Vespa has client libraries for Python, Java, etc., and you query with a JSON-based query language (similar to Elasticsearch DSL).
Pricing
Vespa itself is open-source (Apache 2.0) and can be self-deployed at no software cost. They also offer Vespa Cloud, a managed service with usage-based pricing based on allocated resources (vCPU, memory, disk) per hour, with different tiers for support and features.

Pros and Cons
Vespa’s core advantage is search quality and scale. It will handle queries with dozens of conditions and millions of documents efficiently. Hybrid search and advanced ranking mean you can tightly control relevance.
However, running a Vespa cluster is more involved than a simple vector store. You must define a detailed schema and understand its query language. The managed cloud is based on raw resource pricing, which is hard to estimate. And because it’s a general search engine, it may be overkill if all you need is a simple vector KNN.
8. pgvector (postgres)
pgvector is an extension for PostgreSQL that adds vector similarity search to the classic SQL database. If your application already uses Postgres, you can keep everything in one database (data + vectors). You get full SQL querying power on the same data that backs your app.
Features
- Add a vector column type to Postgres. You insert embeddings as float arrays. pgvector implements HNSW and IVF indexes on these columns to accelerate similarity search.
- Join vector tables with relational tables and apply filters in the same SQL query to combine semantic and structured retrieval for RAG.
- Query nearest neighbors with standard SQL syntax and combine vector scores in broader SELECT statements.
- Use the MIT-licensed extension on Postgres or compatible services like AWS Aurora and Supabase without requiring special hardware.
Pricing
pgvector is a free, open-source extension. Costs are associated with hosting the PostgreSQL database itself, which is available on all major cloud providers (like AWS RDS and Google Cloud SQL) with pay-as-you-go pricing.
Pros and Cons
The biggest pro is one-stop storage: your embeddings live alongside your application data. No need to sync between systems. You can leverage SQL, foreign keys, and complex filters naturally.
On the contrary, Postgres isn’t designed for massive vector workloads. Large embedding tables can slow down other DB operations. pgvector’s performance, while decent, lags behind specialized vector engines on high-dimensional data.
9. Elasticsearch
Elasticsearch (by Elastic) is a mature distributed search engine. Traditionally used for text, logs, and metrics, Elasticsearch can also store and search embeddings via its dense vector datatype.
Features
- Combine traditional BM25 keyword search with rich vector queries and refine results with ELSER neural re-ranking.
- Filter results on any field, including numeric ranges, geospatial, term, and aggregation queries, using the Query DSL to complement vector search.
- Scale horizontally by sharding indexes across nodes, and ensure production readiness with built-in replication and automated recovery.
- Integrate with a mature ecosystem including Kibana, Elastic APM, SIEM, and numerous connectors to manage, visualize, and ship data alongside vector search.
- Support cosine, dot-product, and L2 on dense vectors, using Lucene’s approximate k-NN for fast similarity.
Pricing
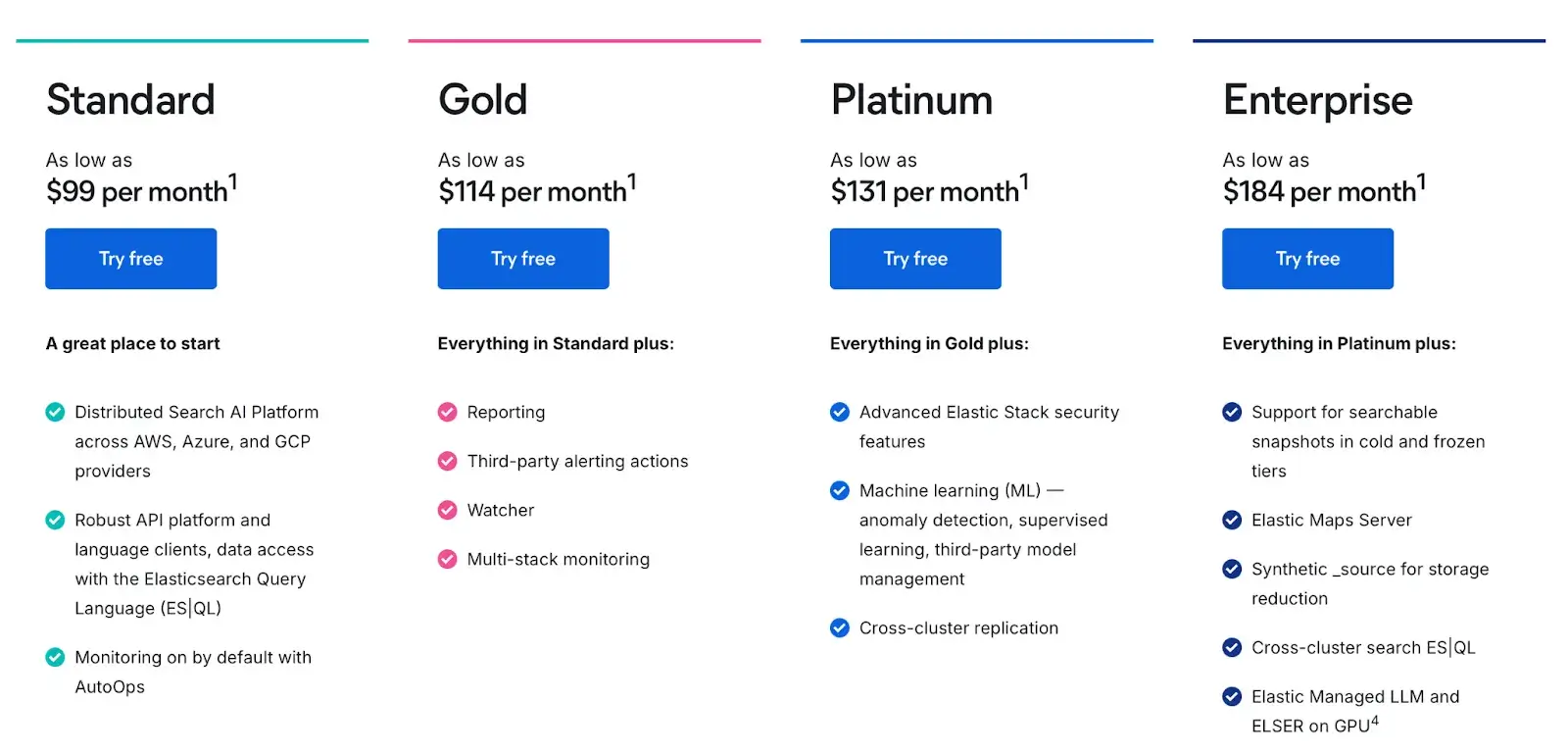
Elasticsearch is open-source, but the managed service is popular. On the Elastic Cloud Hosted plan, you have three paid tiers:
- Standard: $99 per month
- Gold: $114 per month
- Platinum: $131 per month
- Enterprise: $184 per month
Pros and Cons
Elasticsearch’s core strength for RAG is its mature and powerful hybrid search capability. If your organization already uses ES, adding vector search is straightforward; no new platform to learn. The recent Elasticsearch ML integrations, like semantic search, LLM-based ranking, and others, make it a natural choice for AI search.
However, it can be complex to manage and tune, and its resource consumption, especially memory, can be higher than that of some purpose-built vector databases. Historically, adding vectors to ES has had limitations, like slower indexing. Elastic tried to improve it with the e5 model (ELSER), but it can still be heavier than a specialized vector engine.
10. MongoDB
MongoDB, a leading document database, has integrated vector search directly into its platform with Atlas Vector Search. You store your data as usual in MongoDB collections and define a vector search index on a field containing embeddings. This allows developers to build RAG applications on a flexible document model, storing vectors alongside their application data.
Features
- Store embeddings alongside application data in MongoDB, add vector search to existing Atlas apps without migrations, and query with $vectorSearch while filtering by any document field as you would with find().
- Combine full-text predicates and vector similarity in a single pipeline by applying match and other filters first, then running vectorSearch on the narrowed subset for hybrid relevance.
- Process nearest neighbors with the aggregation pipeline to group, join, and project results, enriching RAG logic within one server-side query.
- Scale transparently through Atlas sharding and global distribution so vector search capacity grows with the underlying cluster.
- Use Atlas Vector Search at no additional charge, pay only for the cluster, and prototype on the free M0 tier with small size limits.
Pricing
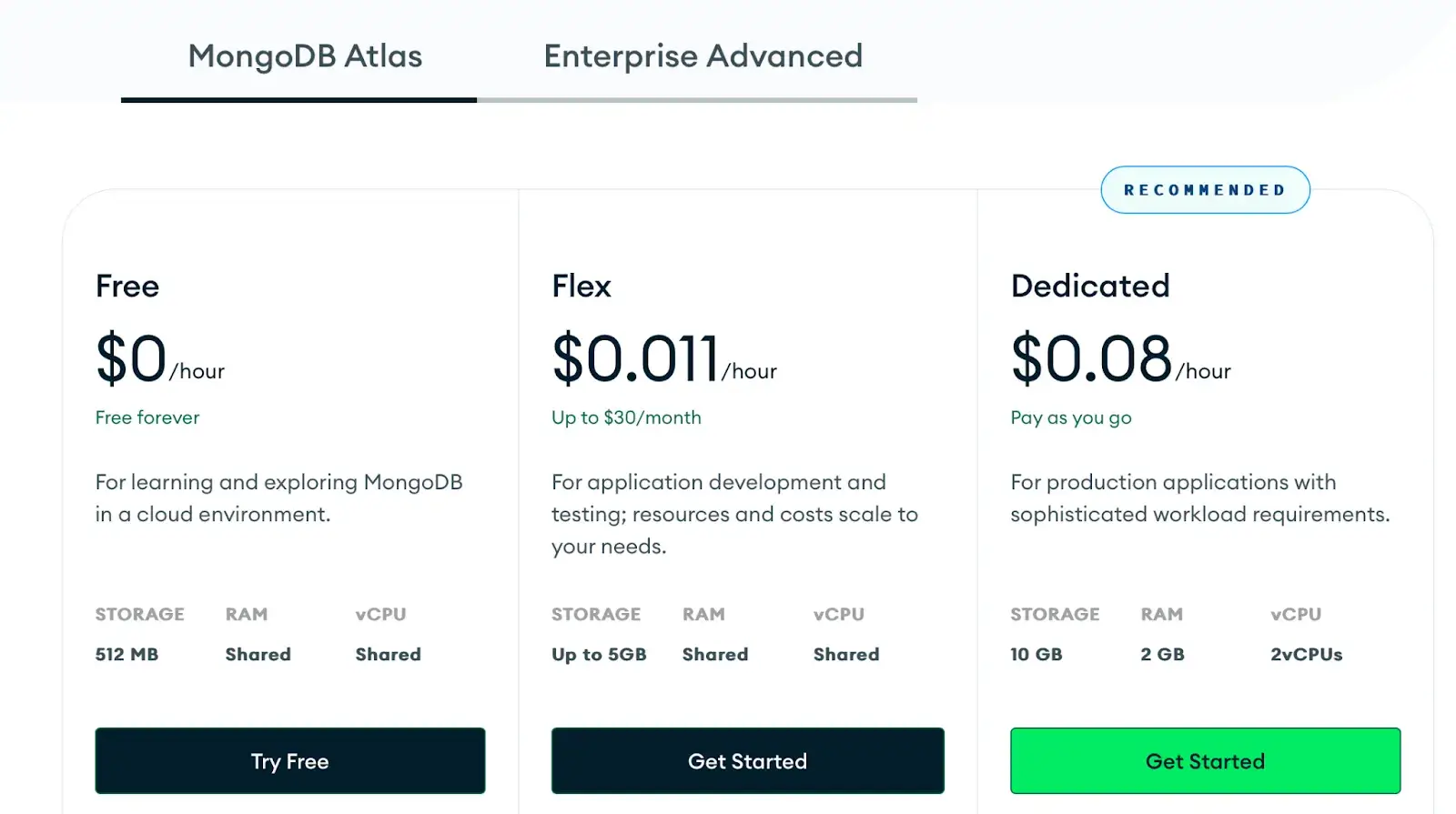
Vector Search in Atlas has no separate fee. It’s included on all cluster tiers. You only pay for the normal MongoDB cluster cost, which is as follows:
- Free (Up to 512 MB storage, shared RAM, and vCPU)
- Flex: Up to $30 per month ($0.11 per hour)
- Dedicated: Pay as you go ($0.08 per hour)
Pros and Cons
If your application already uses MongoDB, vector search just fits without moving data. Its flexible document model and rich query language are also major benefits.. Also, the zero additional cost for the vector feature is a big advantage for smaller projects or prototypes.
As a more recent addition, its large-scale vector workloads are improving but may lag dedicated systems. The feature set is still evolving; some advanced KNN tuning or index types aren’t exposed to users. Also, self-hosted MongoDB does not include vector search, which might be a bottleneck for some users.
Which Vector Database for RAG Pipelines is the Best in Business?
Choosing the right vector database depends on your priorities. What do you prioritize: latency, scalability, cost efficiency, or ecosystem fit? Each of the databases we tested brings its own strengths and trade-offs to the table. The good news is that you don’t have to lock yourself into just one choice.
That’s where ZenML comes in. ZenML is not a vector database; it’s the orchestration layer for your entire RAG and agent pipeline. With ZenML, you can plug in any vector database you prefer, whether Pinecone, Weaviate, Qdrant, Milvus, or even Postgres with pgvector, and focus on building reliable, fine-tuned production-ready pipelines.
The database you choose matters, but what matters more is how well it integrates into your overall workflow. ZenML ensures that, regardless of which vector DB you use today or switch to tomorrow, it integrates smoothly into your RAG pipelines and scales with your agile AI applications.
Bottom line: It doesn’t matter what vector database you use; it works with ZenML.
Wrapping Up: Our Top Vector Database Picks
Among all the options we tested, a few consistently stood out for different reasons.
Pinecone remains the go-to choice for teams that want a fully managed, serverless database with real-time indexing and enterprise reliability. If you value ease of use and don’t want to worry about infrastructure, Pinecone delivers a production-ready experience straight out of the box.
For teams looking for an open-source solution with strong performance and advanced metadata filtering, Qdrant is hard to beat. It brings the speed of Rust together with flexible deployment, making it ideal for complex RAG pipelines.
Another favorite is Weaviate, an AI-native database with built-in vectorization and multimodal support, which is particularly appealing for developers who want to experiment with hybrid and multimodal search in one system.
And if your workload demands extreme scale and GPU acceleration, Milvus is a proven enterprise option capable of handling billions of vectors with ease.
If you’re interested in taking your AI agent projects to the next level, consider joining the ZenML waitlist. We’re building out first-class support for agentic frameworks (like LangGraph, CrewAI, and more) inside ZenML, and we’d love early feedback from users pushing the boundaries of what AI agents can do. With ZenML, you can seamlessly integrate whichever agent framework you choose into robust, production-grade workflows. Join our waitlist to get started.👇


