

On this page
Databricks grew into the default lakehouse for data engineering, analytics, and AI, with more than 10,000 organizations building pipelines on its unified stack.
However, for many operations-focused data teams and ML platform leads, the platform is not beginner-friendly, is expensive if not used carefully, and lacks adequate documentation and release notes for its new features.
In this post, we will explore 10 Databricks alternatives designed to address the aforementioned pain points.
Before diving in, let’s understand why data teams need a Databricks alternative.
TL;DR
- Why Look for Alternatives: Databricks’s steep learning curve (especially for those new to Spark and SQL), frequent but poorly documented updates, and high costs at scale prompt many teams to seek alternatives.
- Who Should Care: MLOps engineers, data science leads, and decision-makers who need a more accessible, cost-efficient, or flexible platform for big data and machine learning workflows.
- What to Expect: The 10 alternatives below offer various strengths – from easier ML orchestration with ZenML to fully managed SQL analytics with Snowflake – so you can choose the one that best suits your team’s skills, infrastructure (cloud or on-premises), and use case.
Recently Updated (November 2025): This guide has been refreshed with the latest platform updates, including new features from ZenML, Snowflake’s expanded AI capabilities, and updated pricing considerations for AWS and Azure services. All code examples and integration details reflect current best practices.
The Need For Databricks Alternatives
There are several reasons why you might need an alternative to Databricks:
- Not beginner-friendly software
- Poor documentation and release notes
- Lack of excellent customer support
Here are the two main reasons worth discussing.
Reason 1. Overwhelming For Beginners
If you’re a beginner with no experience in SQL and Spark, you will have a hard time wrapping your head around Databricks.
Nowadays, many tools work as well as Databricks, where you can simply drag and drop commands rather than writing SQL queries.

Reason 2. New Updates Take Time to Understand
Databricks frequently updates its platform, which is great, but it often fails to update its documentation as frequently as needed.

What’s more, the release notes also don’t do a great job of explaining new updates comprehensively. Additionally, the upgrades often fail to install due to bugs.
Evaluation Criteria
We evaluated all Databricks alternatives against a set of criteria. These factors helped us determine which platform is the best for your needs.
1. Ease of Use and Learning Curve
How accessible is the platform for new engineers or data scientists? A solution that is easier to learn, with an intuitive UI or familiar APIs, can save time if your team is not already experienced with Spark.
2. Integration and Flexibility
We tested how well the alternative integrates with our existing tech stack and workflows.
Does it lock us into a specific cloud or ecosystem, or is it vendor-neutral?
If avoiding vendor lock-in or using certain cloud services (AWS, GCP, Azure) is important, this influenced our choice.
3. Scalability and Performance
Test the platform to verify that it can handle large data volumes and meet performance requirements.
Some alternatives excel at large-scale data warehousing, while others excel at real-time streaming, and so on. We then matched the tool’s strengths to our use case (e.g., large SQL analytics vs. flexible ML experimentation).
With these criteria in mind, let’s compare the top 10 Databricks alternatives and see how they stack up.
What are the Best Databricks Alternatives and Competitors?
Some of the best alternatives to Databricks are:
| Top Databricks Alternatives | Features | Best For |
|---|---|---|
| ZenML |
| ML teams needing production-ready orchestration without vendor lock-in |
| Microsoft Azure |
| Enterprises already invested in the Microsoft ecosystem |
| Snowflake |
| Data warehousing and BI teams prioritizing SQL workloads |
| Amazon Redshift |
| AWS-native data warehousing and analytics |
| Apache Spark |
| Teams wanting full control over distributed computing without vendor costs |
| Google BigQuery |
| Serverless SQL analytics on massive datasets with minimal ops |
| Amazon EMR |
| AWS teams needing flexible big data processing with Spark, Hadoop, or Presto |
| Cloudera |
| Hybrid cloud deployments with strict governance and compliance requirements |
| Google Cloud Dataproc |
| Cost-conscious GCP teams running Spark and Hadoop workloads |
| Oracle Database |
| Enterprise SQL analytics with high availability and security requirements |
Quick Selection Guide by Use Case:
- Rapid ML prototyping → production: ZenML lets you develop locally and deploy to any cloud
- Heavy SQL analytics with minimal ops: Snowflake or BigQuery
- Real-time streaming at scale: Apache Spark on EMR or Dataproc
- Hybrid cloud with strict governance: Cloudera
- AWS-native data warehousing: Redshift with AQUA
1. ZenML

ZenML takes a fundamentally different approach to ML orchestration compared to Databricks, prioritizing developer experience and flexibility without sacrificing production readiness.
While Databricks is a unified analytics platform built around Apache Spark (excellent for large-scale data processing), ZenML was created to bridge the gap between research prototypes and production systems with a lightweight, extensible framework that integrates cleanly with existing ML infrastructure.
Feature 1. Simplified Pipeline Development with Production-Ready Outcomes
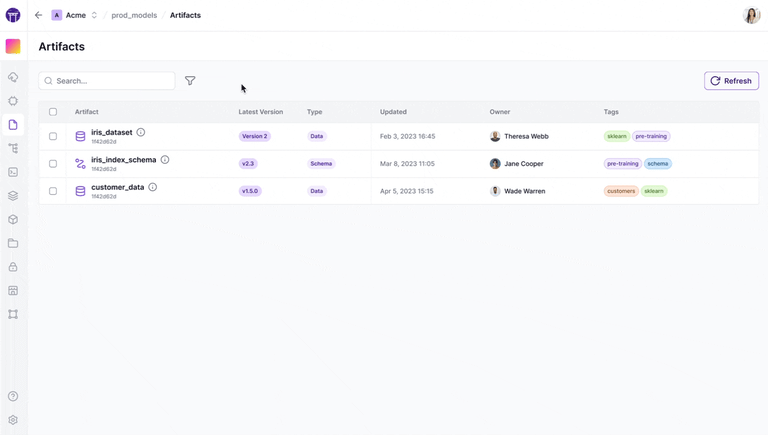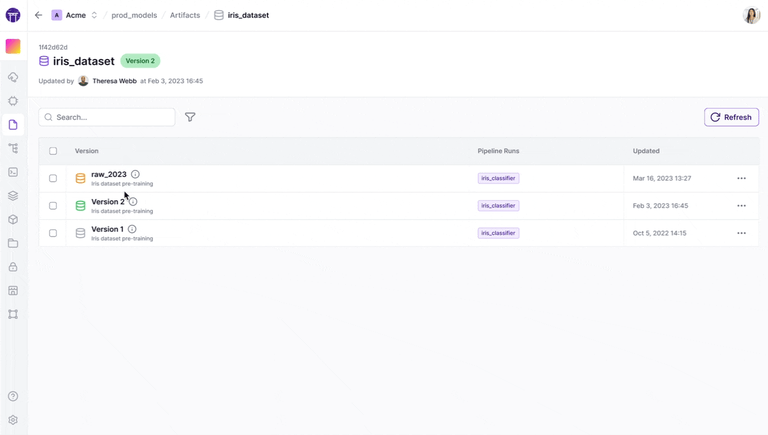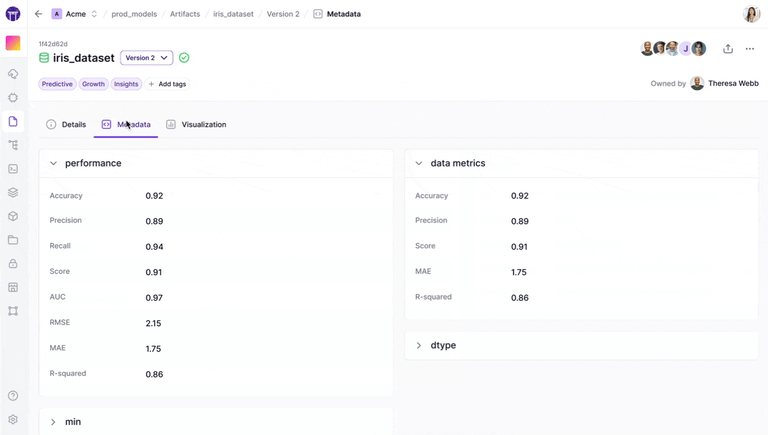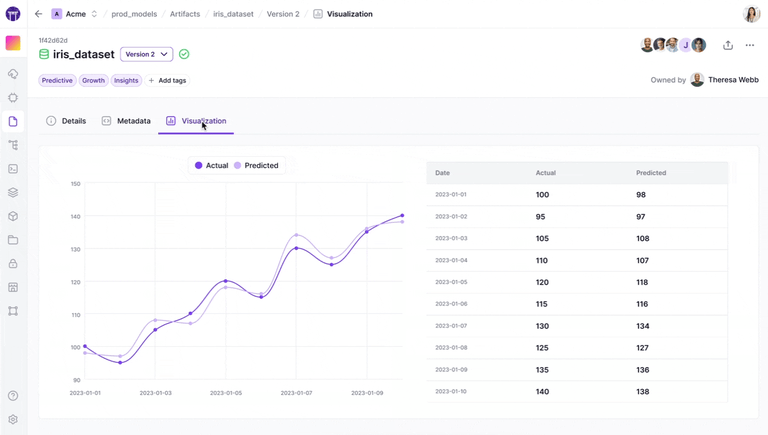
Unlike Databricks’ approach, which often involves Spark-specific pipelines or managing code in notebooks, ZenML focuses on transforming standard Python code into reproducible pipelines with minimal annotations.
This lets ML practitioners use familiar Pythonic workflows while automatically gaining critical MLOps capabilities like:
- Seamless code-to-pipeline transition: Convert research code into production-ready pipelines with minimal modifications, avoiding extensive rewrites.
- Infrastructure abstraction: Develop locally and deploy anywhere through configurable “stacks.”
- Native caching: ZenML intelligently caches pipeline results, skipping redundant computations when inputs haven’t changed.
This design philosophy eliminates much of the “negative engineering” that plagues ML productionization efforts, reducing the gap between prototype and production code.
Here’s how the code for a ZenML pipeline looks vs. that of a Spark notebook 👇🏻
─── ZenML (2025) ─────────
from zenml import step, pipeline
@step
def ingest() -> pd.DataFrame: ... # plain Python function
@step
def train(data: pd.DataFrame) -> Any: ... # idem
@pipeline
def training_pipeline(ingest, train): # DAG described as Python call-graph
return train(ingest())
if __name__ == "__main__":
training_pipeline()
# ─── Databricks Notebook (Spark-style) ─────────
# COMMAND ----------
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import RandomForestRegressor
from pyspark.ml import Pipeline
spark = SparkSession.builder.getOrCreate()
df = spark.read.format("delta").load("/mnt/train")
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
rf = RandomForestRegressor(labelCol="label")
pipeline = Pipeline(stages=[assembler, rf]) # build Spark ML pipeline
model = pipeline.fit(df) # distributed cluster run
display(model.transform(df)) # notebook-style output</pre><h3>Feature 2. Comprehensive Metadata Tracking and Artifact Versioning</h3><p>ZenML’s metadata system sits at the core of its value proposition, offering more automated and intuitive capabilities than Databricks’ typical MLflow-based tracking.</p><p>Key features of ZenML’s metadata and artifact management include:</p><ul><li><a href="https://docs.zenml.io/user-guides/starter-guide/manage-artifacts"><strong>Automatic artifact versioning</strong></a>: Each artifact produced by a pipeline step – whether a dataset, a model, or an evaluation report – is automatically tracked and versioned upon execution. This guarantees reproducibility and traceability across your ML workflows without extra effort.</li><li><a href="https://docs.zenml.io/how-to/model-management-metrics/track-metrics-metadatahttps:/docs.zenml.io/how-to/model-management-metrics/track-metrics-metadata"><strong>Rich metadata capture</strong></a>: ZenML automatically logs detailed metadata about inputs and outputs. For example, when you pass a pandas DataFrame, ZenML records its shape and schema; for models, it can log performance metrics.</li><li><a href="https://docs.zenml.io/user-guides/starter-guide/manage-artifacts#giving-names-to-your-artifacts"><strong>Human-readable naming</strong></a>: Instead of opaque IDs, ZenML lets you assign human-friendly names to pipeline runs and artifacts. This makes it easier to identify artifacts (e.g., “baseline_dataset_v1”) and manage them in complex projects.</li></ul><h3>Feature 3. The Model Control Plane: A Unified Model Management Approach</h3><p><a href="https://docs.zenml.io/how-to/model-management-metrics/model-control-plane">ZenML’s Model Control Plane</a> represents a significant advancement over Databricks’ model management approach.</p><p>Databricks provides an MLflow <a href="https://docs.zenml.io/stacks/model-registries">Model Registry</a> (and now Unity Catalog for models) to version models, but ZenML goes further by unifying pipeline lineage, artifacts, and business context into a single model-centric framework.</p><p>With ZenML’s Model Control Plane:</p><ul><li><strong>Business-oriented model concept:</strong> A ZenML Model is a first-class entity that groups the relevant pipelines, artifacts, metadata, and business metrics for a given ML problem.</li><li><strong>Lifecycle management:</strong> Models in ZenML have versioning and stage management built in. Each training run can produce a new Model Version, tracked automatically with lineage to the data and code that created it.</li><li><strong>Artifact linking:</strong> The Model Control Plane allows linking each model version to not only its technical artifacts (weights, metrics) but also to relevant non-technical context.</li></ul><h3>How Does ZenML Compare to Databricks?</h3><p>Here are a few reasons to switch from Databricks to ZenML:</p><p><strong>1. Vendor‑Agnostic “Stack” Architecture</strong></p><p>A ZenML stack is simply a pluggable bundle of components: orchestrator, experiment‑tracker, model‑deployer, and more that you can register, swap, or extend at will.</p><p>Because every stack component is defined by a lightweight “flavor” interface, teams create custom plugins or add new clouds without forking the core codebase.</p><p>Databricks, by contrast, centralizes orchestration within its own workspace; externalizing parts of the workflow typically means leaving the platform or incurring additional costs for connectors.</p><p><strong>2. Local‑First Development → Remote Execution</strong></p><p>ZenML encourages an inner loop where pipelines run on a laptop first, then re‑run unchanged on Kubeflow, Vertex AI, SageMaker, or GitHub Actions once you are ready for scale.</p><p>Databricks jobs always start on a cloud cluster; even with serverless, you still provision a Spark runtime, which can slow small, experimental iterations.</p><h3>Pros and Cons</h3><p>ZenML enables easy migration between tools and cloud providers, reducing dependency on a single vendor.</p><p>Being fully open-source (Apache 2.0 license), ZenML promotes transparency, has an active community, and can be customized to meet your specific needs.</p><p>However, our platform does not have a native Spark/Ray runner; you must wire these frameworks yourself.</p><h3>2. Microsoft Azure</h3><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:2048px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="2048px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/032b0fe5/681c1a95ad8d443c623b6f79_microsoft_azure_homepage.png" loading="lazy" alt="microsoft-azure-homepage" width="auto" height="auto" /></figure><p><a href="https://azure.microsoft.com/en-gb/">Microsoft Azure</a> is a cloud computing platform that offers services like computing, analytics, storage, and networking.</p><p>The platform is widely known for its Microsoft integrations and offers a flexible, scalable environment for businesses of all sizes.</p><h3>Features</h3><ul><li>Azure Synapse Analytics is a strong alternative for Databricks’ unified data analytics capabilities. The former combines big data and data warehousing into a single platform, which is ideal if you’re focused on SQL-based processing and business intelligence workflows rather than Spark-heavy data pipelines.</li><li>Azure Stream Analytics capabilities come with a fully managed service for real-time analytics. It handles streaming data from IoT devices, logs, and apps, making it a solid choice for operational use cases that require instant insights without managing clusters.</li><li>Azure Machine Learning Studio covers the end-to-end machine learning lifecycle. It enables experimentation, model training, deployment, and monitoring, best for teams looking for a scalable, low-code solution built into the Azure ecosystem.</li></ul><h3>Pros and Cons</h3><p><a href="https://learn.microsoft.com/en-us/azure/?product=popular">Azure</a> is easy to navigate and well-categorized into apps and services like databases, analytics, computing, security, and more. It offers strong scalability and performance for big data and analytics workloads.</p><p>While Azure’s analytics offerings are solid, it lacks the innovation edge to catch up with AWS.</p><h3>3. Snowflake</h3><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:2048px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="2048px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/e6a996a0/681c1aa5c82b51806b4671e5_snowflake_hompage.png" loading="lazy" alt="snowflake-homepage" width="auto" height="auto" /></figure><p><a href="https://www.snowflake.com/en/">Snowflake</a> is a single, fully managed platform that powers the AI Data Cloud. It’s known for its data warehousing capabilities that let you store, process, and explore large datasets.</p><h3>Features</h3><ul><li>Offers a decoupled storage and computing architecture that allows you to scale resources independently for better cost-efficiency across data workloads.</li><li>It natively supports querying semi-structured formats, like JSON and XML, using standard SQL. This feature makes it a solid alternative to Databricks’ Spark SQL engine, especially for teams that prefer a fully managed, SQL-centric workflow over writing Spark jobs.</li><li>With features like time travel and zero-copy cloning, <a href="https://docs.snowflake.com/">Snowflake</a> enables rapid testing, data versioning, and safe experimentation.</li><li>Snowflake automatically handles compute resource scaling based on user demand for reliable performance, even during high concurrency.</li></ul><h3>Pros and Cons</h3><p>Snowflake lets you restore and edit older data versions and comes with the ability to manage massive datasets, straightforward queries, and fast performance.</p><p>However, the platform primarily focuses on structured and semi-structured data, lacking robust native support for unstructured data types.</p><h3>4. Amazon Redshift</h3><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:2048px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="2048px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/eb0748d1/681c1ab60e3a373c5980d79b_amazon_redshift_homepage.png" loading="lazy" alt="amazon-redshift-homepage" width="auto" height="auto" /></figure><p><a href="https://docs.aws.amazon.com/redshift/">Amazon Redshift</a> is a fully managed, petabyte-scale data warehouse service within the AWS ecosystem.</p><p>It's designed for high-performance analytics on structured and semi-structured data, offering deep integration with AWS services, making it a go-to choice for businesses heavily invested in AWS.</p><h3>Features</h3><ul><li>Has a columnar storage format and a Massively Parallel Processing (MPP) engine. It works well for high-performance analytics on large datasets and is the right fit if you prefer SQL over Spark-based workloads.</li><li>The AQUA (Advanced Query Accelerator) feature brings compute to the storage layer. This setup delivers faster data processing compared to traditional architectures that separate compute and storage.</li><li>Redshift integrates with Amazon SageMaker, allowing teams to run machine learning models directly from SQL queries. This helps replicate predictive analytics workflows typically built in Databricks.</li><li>The platform supports native ingestion and querying of semi-structured formats like JSON and Parquet. With this, you can explore diverse data types without needing complex transformation pipelines.</li></ul><h3>Pros and Cons</h3><p>Redshift integrates well with other AWS services, which makes it easy to implement and scale. The tool’s architecture allows for easy scaling to accommodate growing data volumes and user concurrency.</p><p>One negative aspect we observed with Redshift is that it can be expensive to process on a large scale, particularly with increasing amounts of data.</p><h3>5. Apache Spark</h3><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:2048px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="2048px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/1b334e8c/681c1ac5a5fbfc9bd42efcd4_apache_spark_homepage.png" loading="lazy" alt="apache-spark-homepage" width="auto" height="auto" /></figure><p><a href="https://spark.apache.org/">Apache Spark</a> is an open-source, distributed computing system designed for large-scale data processing.</p><p>It provides a unified engine capable of handling batch processing, real-time streaming, machine learning, and graph analytics.</p><h3>Features</h3><ul><li>By processing data in memory, <a href="https://spark.apache.org/docs/latest/index.html">Spark</a> significantly reduces the time required for data retrieval and computation, resulting in faster analytics compared to traditional disk-based processing systems.</li><li>It supports APIs in Java, Scala, Python, and R. Developers can build applications in the language they know best, which helps teams collaborate more efficiently across different stacks.</li><li>Includes built-in libraries such as MLlib for machine learning, GraphX for graph processing, and Spark Streaming for real-time data processing. These built-in tools cover most analytical use cases without needing third-party add-ons.</li><li>Designed to scale from a single server to thousands of machines, Spark can handle petabyte-scale data, making it suitable for both small-scale applications and large enterprise solutions.</li></ul><h3>Pros and Cons</h3><p>With Apache Spark, you can handle large volumes of data, making it horizontally scalable. What’s more, its fault tolerance through data replication and support for batch streaming makes data processing faster.</p><p>However, the platform lacks built-in support for event time processing.</p><h3>6. Google BigQuery</h3><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:2048px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="2048px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/cd82fddd/681c1ad68120b20c6a28a287_google_bigquery_homepage.png" loading="lazy" alt="google-bigquery-homepage" width="auto" height="auto" /></figure><p><a href="https://cloud.google.com/bigquery?hl=en">Google BigQuery</a> is a fully managed, serverless data warehouse that enables scalable analysis over petabyte-scale data.</p><p>Its architecture decouples storage and compute, allowing for flexible resource allocation.</p><h3>Features</h3><ul><li><a href="https://cloud.google.com/bigquery/docs">Google BigQuery</a> removes the need for manual infrastructure setup. It automatically provisions and scales resources based on workload demands.</li><li>You can build and run machine learning models using standard SQL inside BigQuery. This feature supports predictive analytics without moving data into separate ML environments.</li><li>Supports real-time data ingestion, allowing teams to analyze fresh data as it arrives, making it ideal for operational dashboards and streaming use cases that would otherwise require Databricks Structured Streaming.</li><li>It allows cross-source querying across Cloud Storage, Google Drive, and external databases. Teams can analyze distributed data without replicating or transferring it to a central warehouse.</li></ul><h3>Pros and Cons</h3><p>BigQuery makes working with large datasets easy and offers several user-friendly learning tutorials, as well as a reliable community to help solve all your problems.</p><p>However, remember that if not careful, complex queries for large datasets can add up, resulting in a significant increase in pricing.</p><h3>7. Amazon EMR</h3><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:2048px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="2048px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/efe24f39/681c1ae210c33b0fe77897b4_amazon_emr_homepage.png" loading="lazy" alt="amazon-emr-homepage" width="auto" height="auto" /></figure><p><a href="https://aws.amazon.com/emr/">Amazon EMR</a> (Elastic MapReduce) is a cloud-native big data platform that simplifies running large-scale data processing frameworks like Apache Spark and Hadoop.</p><p>It provides a managed environment to process vast amounts of data quickly and cost-effectively.</p><h3>Features</h3><ul><li>Supports multiple open-source engines such as Apache Spark, Hadoop, Hive, and Presto. This flexibility allows teams to choose the right tool for their specific data processing needs, unlike Databricks, which primarily centers on Spark.</li><li>EMR clusters can scale compute power up or down depending on demand. This elasticity helps teams manage large workloads without overprovisioning resources.</li><li>Teams can customize EMR cluster configurations to match application-specific requirements, making it an appealing tool for engineers who want deeper tuning than what Databricks’ managed environment allows.</li><li>Auto Scaling and Spot Instance support reduces compute costs, especially for long-running or batch workloads.</li></ul><h3>Pros and Cons</h3><p><a href="https://docs.aws.amazon.com/emr/">Amazon EMR</a> makes it easy for you to launch and clone an EMR cluster. The platform seamlessly connects to S3, Glue, and Lake Formation for data storage, cataloging, and governance.</p><p>But one issue we ran into - booting up takes more time compared to other competitors in the space.</p><h3>8. Cloudera</h3><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:2048px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="2048px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/728a6e50/681c1af4ad8d443c623b97d2_cloudera_homepage.png" loading="lazy" alt="cloudera-homepage" width="auto" height="auto" /></figure><p><a href="https://www.cloudera.com/">Cloudera</a> is a hybrid data platform that provides enterprise-grade tools for data engineering, machine learning, and analytics across on-premises and cloud environments.</p><p>It offers a unified platform to manage the entire data lifecycle.</p><h3>Features</h3><ul><li>Supports deployment across public cloud, private cloud, and on-premise environments, giving you more control over data residency and infrastructure.</li><li>Combines ingestion, storage, processing, and analytics into a single integrated platform. Teams can build complex data workflows without relying on separate services for ETL, data warehousing, or business intelligence.</li><li>The platform features include data governance, lineage tracking, and regulatory compliance, which are particularly useful in highly regulated industries.</li><li>Provides tools for developing and deploying machine learning models using open-source frameworks. It supports building end-to-end ML workflows similar to what Databricks offers with MLflow and collaborative notebooks.</li></ul><h3>Pros and Cons</h3><p><a href="https://docs.cloudera.com/">Cloudera</a>'s Hadoop distribution enhances enterprise Hadoop with built-in security, scalability, and management tools, and it has a large and active community of users and developers.</p><p>But the learning curve for the tool is quite steep. You need expertise to manage on-prem HDFS clusters and optimize performance.</p><h3>9. Google Cloud Dataproc</h3><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:1906px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="1906px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/f73080bb/681c1b03fef7813522a4e476_google_cloud_dataproc_homepage.png" loading="lazy" alt="google-cloud-dataproc-homepage" width="auto" height="auto" /></figure><p><a href="https://cloud.google.com/dataproc?hl=en">Google Cloud Dataproc</a> is a fast, easy-to-use, fully managed cloud-based data platform running Apache Spark and Hadoop clusters. It simplifies setting up, managing, and scaling big data environments.</p><h3>Features</h3><ul><li>Lets you and your team spin up fully managed Spark and Hadoop clusters in minutes. It supports automated scaling and simplifies configuration, offering a faster setup experience than manually configuring Spark on Databricks.</li><li>The platform includes flexible pricing options like per-second billing and support for preemptible VMs, making it a cost-effective alternative for batch or fault-tolerant workloads.</li><li>Integrates deeply with BigQuery, Google Cloud Storage, and Google’s AI services, which you can leverage to build end-to-end analytics and ML pipelines within the Google Cloud ecosystem.</li><li>Lets you customize clusters by adding libraries, packages, or environment-level settings during provisioning.</li></ul><h3>Pros and Cons</h3><p><a href="https://cloud.google.com/dataproc/docs">Dataproc</a> comes with a fully managed service for running Spark, Hadoop, and related ecosystems. The software lets you fine-tune cluster size, machine types, and autoscale for specific workloads.</p><p>While Dataproc simplifies a lot, it’s still essentially Hadoop/Spark under the hood. You might need Spark/Hadoop tuning knowledge to optimize jobs.</p><h3>10. Oracle Database</h3><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:2048px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="2048px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/a1f15e47/681c1b13a5fbfc9bd42f33ae_oracle_database_homepage.png" loading="lazy" alt="oracle-database-homepage" width="auto" height="auto" /></figure><p><a href="https://www.oracle.com/database/">Oracle Database</a> is a relational database management system known for its powerful performance, high availability, and enterprise-grade security.</p><p>The advanced analytics capabilities of the platform cater to complex, large-scale SQL-based workloads.</p><h3>Features</h3><ul><li>Supports advanced SQL-based analytics, including predictive modeling, time-series analysis, and real-time insights, which serves as a strong alternative to Spark SQL for teams that prefer traditional RDBMS performance and structure.</li><li>With Oracle Autonomous Database, infrastructure management, patching, and optimization are fully automated. This setup reduces the operational overhead typically associated with managing Spark environments in Databricks.</li><li>Enables deployment across public cloud, private cloud, and on-premises environments. It’s a great fit for teams that need tight control over infrastructure.</li><li>The platform delivers high-speed performance and scales effectively for OLAP and transactional workloads, making it well-suited for teams handling large datasets in business-critical environments.</li></ul><h3>Pros and Cons</h3><p><a href="https://docs.oracle.com/en/database/">Oracle Database</a> offers enterprise-grade tools like RMAN for backups, Data Guard for replication, and ASM/RAC for shared storage. It supports pluggable databases (PDBs) for server consolidation, easing upgrades and migrations in cloud environments.</p><p>But managing the infrastructure for deploying microservices or large-scale applications can be daunting, especially when scaling applications to meet real-time demand.</p><h3><strong>Choosing the Right Alternative in Late 2025</strong></h3><p>The landscape of data platforms has evolved significantly throughout 2025. Teams are increasingly prioritizing vendor-agnostic solutions that prevent lock-in, especially as cloud costs continue to rise. We've seen a marked shift toward platforms that support local development with remote execution, reducing the expensive trial-and-error cycles that plague Spark-based workflows. </p><p>For teams building production ML systems, the ability to integrate with existing infrastructure—rather than replacing it wholesale—has become the primary decision factor. This is why frameworks like ZenML that work <em>with</em> your current tools (whether that's Snowflake, BigQuery, or custom infrastructure) are gaining traction over monolithic platforms.</p><h2>Which is the Best Databricks Alternative for You?</h2><p>All the platforms mentioned above are excellent alternatives to Databricks and effectively address its drawbacks.</p><p>Unfortunately, Databricks isn’t user-friendly, can become expensive as you scale, and doesn’t do a great job of documenting new features, which are the main reasons people opt for an alternative.</p><p>But how do you determine which Databricks alternative is best for you?</p><p>Well, there’s no better way than signing up for free trials and judging products for yourself.</p><p>While we have presented these alternatives objectively, we at ZenML believe that modern ML orchestration should prioritize simplicity, flexibility, and developer productivity, principles that guided the design of our own platform.</p><p>No matter if you're an ops-heavy data engineer or an ML lead looking for a solution that helps you build optimized ML pipeline orchestration without sacrificing production-readiness, we can help. </p><p><a href="https://www.zenml.io/book-your-demo">Schedule a demo</a> with us today to get a 1on1 session with ZenML's Founder and know how the tool can help you and your MLOps team to up your game in no time.</p><figure class="w-richtext-figure-type-image w-richtext-align-fullwidth" style="max-width:2602px" data-rt-type="image" data-rt-align="fullwidth" data-rt-max-width="2602px"><img src="https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/55428de0/684576e834000d9981f3b957_zenml-book-a-demo.png" loading="lazy" alt="Schedule a demo with ZenML" width="auto" height="auto" /><figcaption>Schedule a demo with ZenML</figcaption></figure><p>We offer a managed solution that combines the best of these approaches with enterprise support and advanced collaboration features.</p><p><strong>📚 Related reading:</strong></p><ul><li><a href="https://www.zenml.io/blog/mlflow-alternatives"><strong>MLflow Alternatives</strong></a><strong>:</strong> Discover the best MLflow alternatives designed to improve all your ML operations.</li><li><a href="https://www.zenml.io/blog/metaflow-alternatives"><strong>Metaflow Alternatives</strong></a><strong>: </strong>8 Metaflow alternatives that takes care of Metaflow drawbacks like no native window support, CLI-only operations, and more.</li></ul><h2>Common Questions About Databricks Alternatives</h2><p><strong>Is Databricks still worth it in 2025?</strong> Databricks remains powerful for teams with deep Spark expertise and heavy big data processing needs. However, many ML teams find that lighter-weight orchestration tools like ZenML, combined with managed compute from cloud providers, deliver better developer experience and lower costs for typical ML workflows.</p><p><strong>What's the most cost-effective alternative to Databricks?</strong> Cost depends heavily on your workload. For SQL analytics, Snowflake or BigQuery often prove cheaper. For ML orchestration, open-source frameworks like ZenML with your existing cloud infrastructure typically cost 50-70% less than Databricks Unity Catalog setups.</p><p><strong>Can I migrate from Databricks without rewriting everything?</strong> Yes. Tools like ZenML let you keep your Python code largely intact while changing the underlying orchestration. The key is choosing a vendor-agnostic framework that doesn't lock you into specific APIs or data formats.</p>

