
On this page
Machine Learning Operations (MLOps) and Large Language Model Operations (LLMOps) often appear side by side in discussions about AI infrastructure, but they’re not the same.
Both aim to bring order, automation, and reliability to how machine learning or AI models are built and deployed. Yet, the workflows behind them differ significantly because the models they manage behave very differently.
As organizations adopt generative AI, understanding how MLOps and LLMOps differ and where they overlap has become critical.
In this article, we explore both frameworks in depth: what they do, where they diverge, and how you can use them together to power your next AI system.
MLOps vs LLMOps: The Short Answer
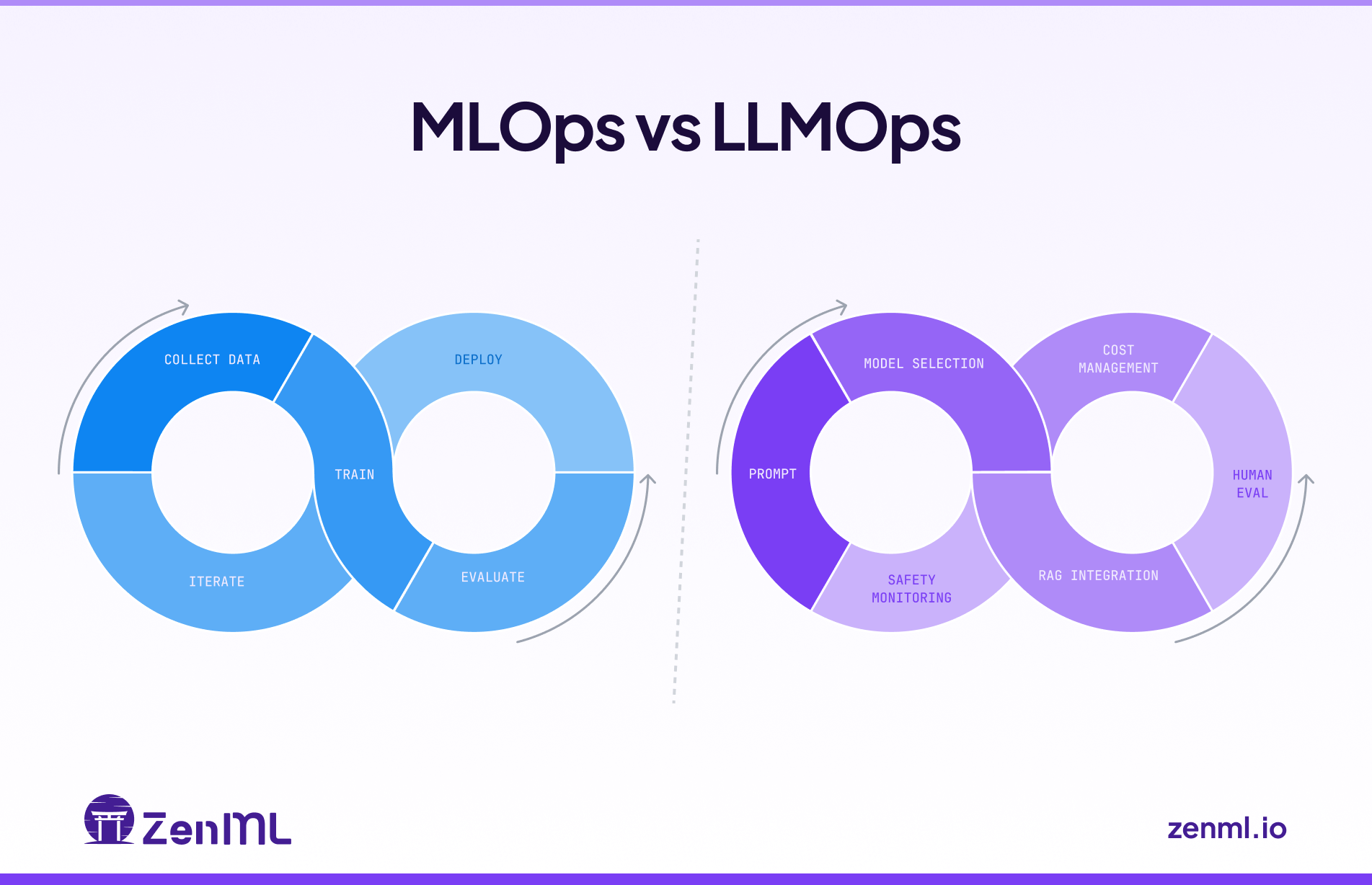
- MLOps stands for Machine Learning Operations. It’s the process of managing the end-to-end machine learning lifecycle, from development to deployment and maintenance. MLOps manages the end-to-end lifecycle for ML across structured and unstructured data (tabular, images, audio, text).
- LLMOps stands for Large Language Model Operations. It extends MLOps principles to LLMs and generative AI, adding capabilities like prompt management, fine-tuning, and model monitoring for LLM-powered apps. For example, managing an OpenAI-based customer service chatbot or text summarizer.
In the long shot, both processes are born from a spectrum: DevOps gave rise to MLOps. LLMOps extends MLOps for LLMs. But that’s where differentiating between them gets tricky and interesting at the same time.
What is MLOps?
Machine Learning Operations (MLOps) involves a set of practices that help you automate and manage machine learning workflows and deployments.
It standardizes how data scientists and engineers deploy ML models from experimentation to production. Think of MLOps as an assembly line with different tools and components that automate tasks like data versioning, training pipelines, and model retraining.
MLOps ensures that machine learning systems don’t break once they leave Jupyter notebooks. It’s most useful for creating ML models that learn patterns from structured data and need continuous retraining and monitoring over time.
Think of Spotify’s recommendation engine or Amazon’s buy next suggestions; they are all trained on ML models.
Speaking of which, MLOps should be used when your project involves:
- Predictive Analytics: Forecasting sales, predicting stock prices, etc..
- Classification: Spam detection, image recognition, or sentiment analysis.
- Recommendation Engines: Suggesting movies on Netflix or products on Amazon
What is LLMOps?
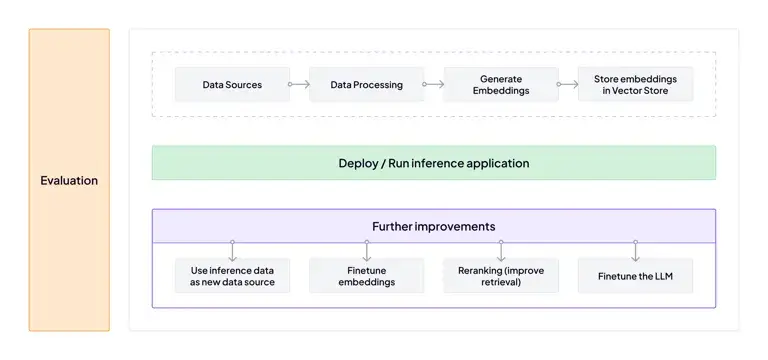
ZenML simplifies the development and deployment of LLM-powered MLOps pipelines.
Large Language Model Operations (LLMOps) is the next evolution of MLOps built for the lifecycle management of LLM-powered applications, like chatbots or retrieval-augmented generation (RAG) systems.
It inherits and extends MLOps principles to large language models. But with a slight twist. LLMOps treat prompts, embeddings, vector databases, and agent tools as first-class citizens.
While MLOps feed on structured datasets, LLMOps work with unstructured text.
- Their behavior is shaped by prompts.
- The development cycle is also much faster.
- Unlike MLOps' lengthy retraining periods, you iterate quickly on prompts, update RAG documents, and refine guardrails to steer the model's behavior.
For instance, a company deploying an OpenAI-powered support bot needs LLMOps to handle prompt versioning, monitor latency, and prevent hallucinations in responses.
Evaluation in LLMOps is also more complex than MLOps. It often requires human judges or other LLMs to assess quality and check for hallucinations.
Long answer short, you should use LLMOps when your application involves:
- Generative AI: Building chatbots, virtual assistants, or content creation tools.
- Complex Problem-Solving: Using LLM agents to perform multi-step tasks.
- Semantic Search: Creating search systems that understand the meaning behind queries, not just keywords.
MLOps vs LLMOps: Major Differences?
By now, we know the subtle difference between MLOps and LLMOps. Now let’s get into the details. While LLMOps inherits its traits from MLOps, their operational workflows have some stark differences.
| Category | MLOps | LLMOps |
|---|---|---|
| Data and Artifacts | Tracks datasets, features, and model binaries for reproducibility. | Tracks prompts, embeddings, vector indexes, and guardrails as core artifacts. |
| Build Loop | Slower cycle: collect, train, evaluate, deploy, and retrain on new data. | Fast, iterative cycle: tweak prompts, RAG, and guardrails; minimal retraining. |
| Testing and Evaluation | Uses fixed datasets and metrics like accuracy or F1 score. | Uses golden prompts, human or LLM judges, and groundedness checks. |
| Deployment and Monitoring | Deploys models behind APIs, monitors drift and latency. | Orchestrates RAG, tools, and safety layers; tracks hallucination and cost. |
| Cost Model | Training dominates cost; inference is cheap. | Inference dominates cost; pay per token and vector operation. |
1. Data and Artifacts
Artifacts are any files or digital assets that are inputs to, outputs of, or intermediate results produced during an ML or LLM lifecycle process.
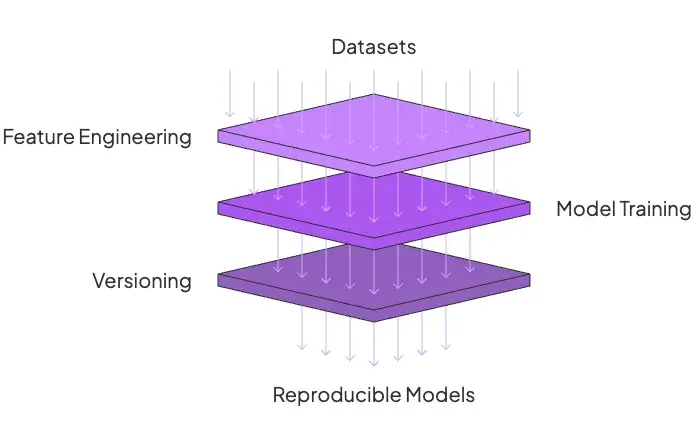
MLOps
In MLOps, the most important artifacts are the datasets, features engineered from them, and the final trained model binary. The core focus is on versioning these components alongside code to ensure reproducibility.
Tools like model registries and data version control keep track of which data was used to train which model, and what feature definitions were applied.
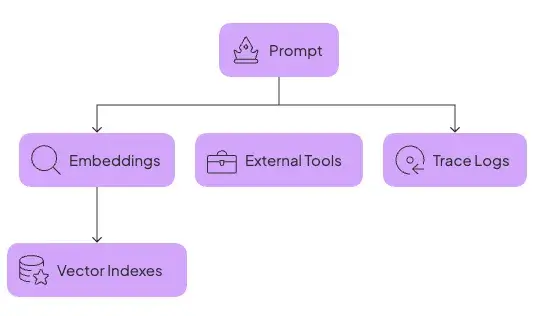
LLMOps
LLMOps, on the other hand, deals with a new set of artifacts. The prompt is king. It’s treated as a first-class artifact that’s versioned and tested just like code. But beyond that, you’re tracking a whole ecosystem:
- Embeddings for semantic search
- Vector indexes that store them
- External tools and policies for agents
- Trace logs to debug the LLM's reasoning process
Bottom line: In MLOps vs LLMOps, things like prompts, retrieval databases, and guardrail configurations become ‘first-class citizens’ in LLMOps, whereas MLOps is primarily centered on data and model artifacts.
2. Build Loop
LLMOps builds upon the foundations of MLOps. But the ‘build loop’ or iterative development cycle is revised for the unique characteristics of LLMs.
MLOps
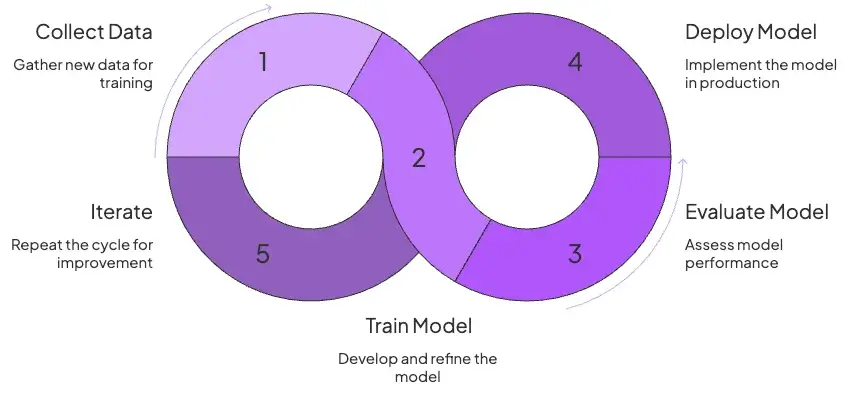
The classic MLOps lifecycle centers on an offline training loop. You collect data, train a model, evaluate it, and deploy. This cycle repeats periodically as new data arrives or model improvements are discovered.
The iteration cadence is often slower. Much of your effort goes into feature engineering and improving the training process.
LLMOps
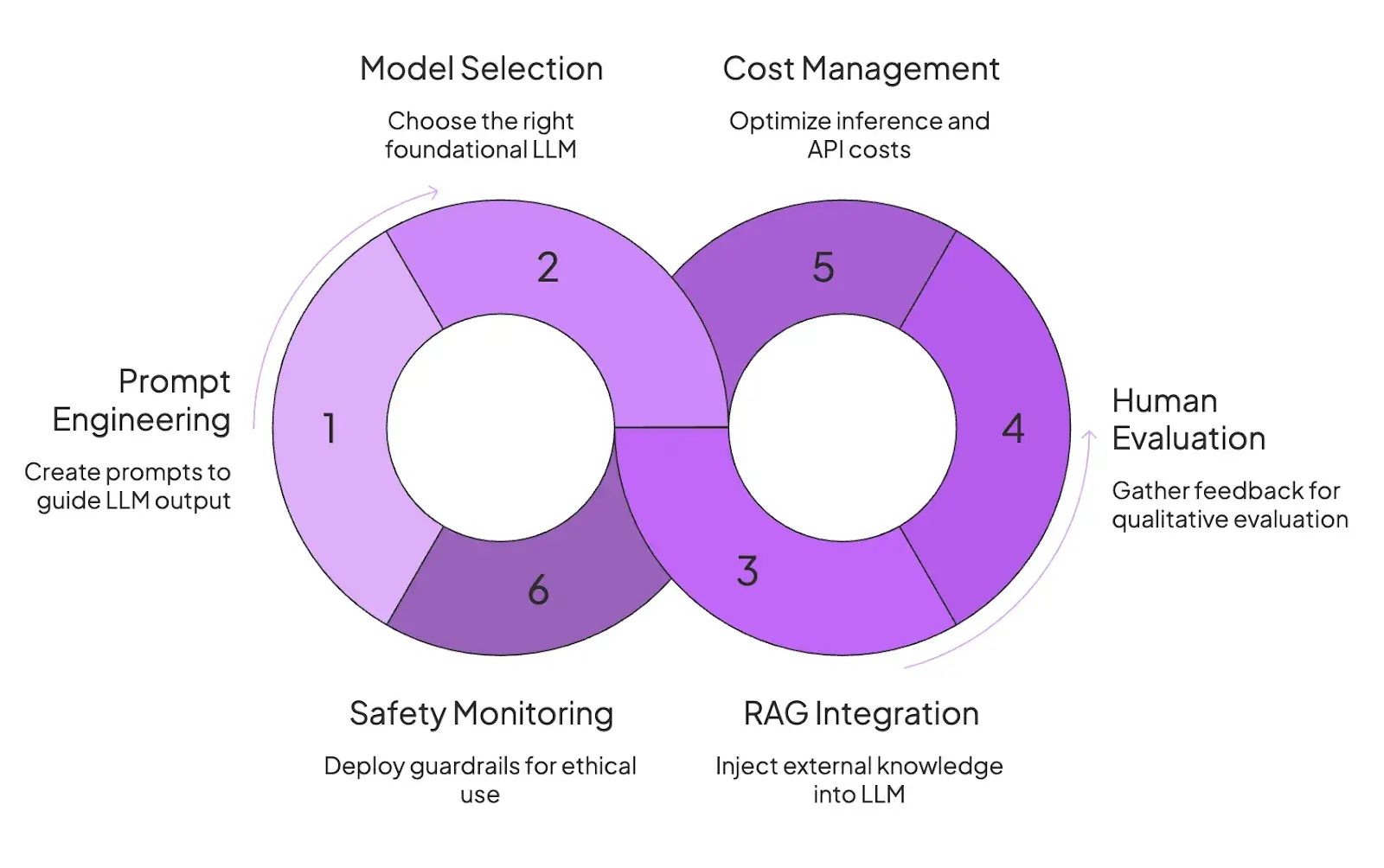
The LLMOps build loop is far more dynamic and faster. You’re not usually training a model from scratch. Instead, you start with a pre-trained foundation model. So the ‘training’ phase is minimal or skipped at best.
But the process introduces new elements to fit in the nature of LLMs, such as:
- Prompt Engineering: Create prompts and design context windows to guide the LLM's output.
- Model Selection: Choose the right foundational LLM (e.g., GPT, Llama, Claude).
- Retrieval Augmented Generation (RAG): Inject external knowledge into the LLM during inference, reducing the need for model retraining with every new information.
- Human-in-the-Loop Evaluation: Due to the subjectivity large language models bring, human feedback and qualitative evaluation are core to LLMOps.
- Cost Management: Focusing on efficient inference, managing API costs, and optimizing for latency and throughput.
- Safety Monitoring: Deploy guardrails to prevent harmful or undesirable outputs from the LLM and monitor for ethical use.
At first, it seems overwhelming. But LLMOps offer dynamic iteration cycles. You can iterate on prompts, update the RAG corpus, add new tools, or adjust guardrails. The best part is, you can do it in tandem to observe outputs and not on a fixed schedule like MLOps.
Full model retraining is an option. But it’s treated as a last resort due to its cost and complexity. Most developers will only undertake retraining when there is a clear ROI or an error that prompting and RAG can’t solve.
Bottom line: MLOps heavily relies on curated training data, while LLMOps emphasizes prompt engineering and context design.
MLOps is more work, with more steps, and more model retraining. LLMOps, on the other hand, gives a head start with pre-trained models, configurable through prompts and RAG.
3. Testing and Evaluation
MLOps and LLMOps carry different testing and evaluation sets. MLOps uses quantitative metrics, while LLMOps heavily incorporates qualitative and human-centric evaluation.
MLOps
MLOps evaluation focuses on the accuracy and performance of predictive models. You rely on static holdout datasets and quantitative metrics like accuracy, precision, recall, F1 score, and RMSE to evaluate model performance.
Testing is often automated, deterministic, and done against a defined dataset. If the model meets the benchmark, let’s say 95% accuracy on output to the known correct answer, it’s considered good to go.
Continuous integration (CI) in MLOps might include unit tests for data pipeline code and maybe some checks on model performance against a validation set, but not much beyond that.
LLMOps
The LLMOps evaluation technique is subjective and complex. Otherwise, how else do you measure if a paragraph is safe, relevant, and accurate?
The core evaluation starts with LLMOps teams curating a set of prompt-response pairs. Also coined as the ‘Golden Dataset.’ You run these pairs and compare outputs from different prompt versions.
LLMOps relies on a mix of automated metrics, LLM-as-a-judge evaluations, and human feedback to judge an LLM’s performance.
💡 Best practice: For best results, consider 15-20 high-signal prompt-response examples (golden tests) that run on each change, so that a drop in answer quality or a new hallucination can be caught before deployment.
LLMOps also incorporates groundedness checks. It ensures the output is traceable to the provided context and other safety evaluations as part of testing.
Bottom line: MLOps measures performance, while LLMOps measures behavior.
ML models can be tested with fixed datasets and static metrics. LLMs can’t. Their outputs evolve with prompts, context, and model updates. Hence, they also incorporate human or LLM-based evaluation and groundedness checks.
4. Deployment and Monitoring
MLOps and LLMOps both offer unique deployment and monitoring features that align with the type of model they build. Let’s see how.
MLOps
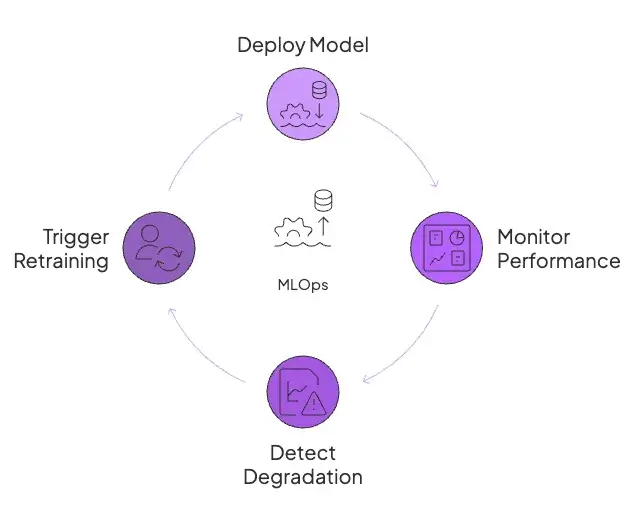
In a typical MLOps setup, the overall deployment architecture is fairly contained. You ship a model artifact to a model server behind an API, along with a feature service that supplies real-time features to the model.
Monitoring focuses on performance degradation, like accuracy drift, data drift (when input data changes), and latency. Teams track accuracy or prediction error on a rolling basis.
If model performance degrades or data drifts significantly, alerts are raised, and a retraining pipeline might be triggered.
LLMOps
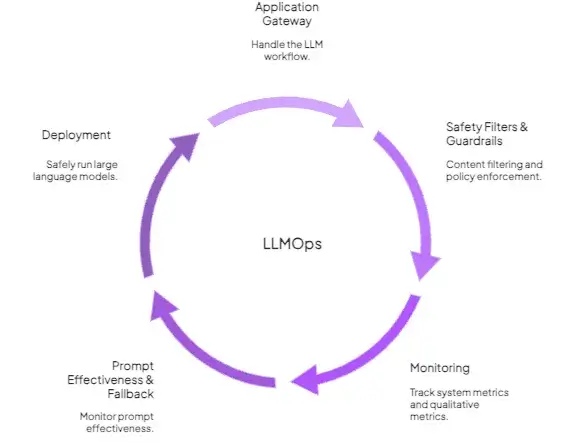
LLMOps introduces an application gateway to handle the LLM workflow. The gateway orchestrates multiple components: a router to direct queries, a vector database for RAG, tool-calling logic, and caching layers to reduce costs.
Before final deployment, LLMOps also incorporates safety filters and guardrails. For instance, you can include content filtering and policy enforcement in the request pipeline.
Monitoring in LLMOps is nuanced than MLOps. System metrics like latency are still tracked, but now with an eye on where time is spent. You track qualitative metrics like hallucination rates, quality scores from judges, safety flag triggers, and token/cost budgets.
Furthermore, because LLM behavior can change with model updates or even prompt tweaks, LLMOps often includes monitoring prompt effectiveness and fallback mechanisms.
Overall, LLMOps deployment is about managing a pipeline of components. It’s a more complex deployment, but it provides the necessary controls to safely run large language models.
Bottom line: In MLOps, deployment is a controlled endpoint that transitions into ongoing monitoring for data drift, model accuracy, and retraining needs.
In LLMOps, deployment is the start of continuous oversight, tracking model behavior, cost per request, hallucination rates, and prompt effectiveness, to maintain quality, safety, and trust across every user interaction.
5. Cost Monitoring
To train machine learning models is like hearing a ‘Ching-Ching!’ from your bank after every run. It’s important to know what’s adding to the bill.
MLOps
MLOps costs are skewed toward model development. It’s primarily driven by GPU hours used for training and serving models. The bigger the model and dataset, the higher the cost.
Serving costs (CPU/GPU for inference) also add up, but for many models, the inference cost per prediction is relatively low. So the big expenditure is retraining models as new data arrives or as you experiment with hyperparameters.
Once deployed, maintaining a model (apart from occasional retraining) is not usually as costly as the training process itself.
LLMOps
With LLMs, the cost equation flips. Inference is the main cost driver for large language models. Each call to a large model (especially via API) can be expensive. Costs scale with the number of tokens processed.
This means every user query incurs a direct cost proportional to prompt+response length, unlike in traditional ML, where a prediction is cheap after training.
On top of that, LLMOps stacks incur ancillary costs: for instance, generating embeddings for new data and performing vector searches are part of the runtime pipeline and can carry their own costs.
If the LLM integrates external tools or APIs, those also add to the cost per user query. Overall, operating an LLM-powered application tends to have higher ongoing operational costs because you essentially ‘pay per use’ of the model and associated service.
Bottom line: In MLOps, the expensive part was building the model (training).
In LLMOps, the expensive part is using the model at runtime. Therefore, LLMOps practices emphasize cost monitoring and continuously tuning the system to balance quality with affordability.
MLOps vs LLMOps: Use Cases
While MLOps and LLMOps share similar operational goals, their real-world use cases differ. Yet, both have too-good-for-real-world applications for businesses:
MLOps
MLOps underpins applications that learn patterns from historical, structured data to make a specific, defined decision. You can use MLOps for:
- Classification: One of the oldest and most common use cases for MLOps. Businesses use it all the time to build systems that categorize or structure data. A bank's fraud detection system is a prime example.
- Recommendation: Leverage MLOps to build recommendation engines to handle dynamic user behavior. Think of how streaming services like Netflix and marketplaces like Amazon show you exactly what you want to see or purchase next. These pipelines work on heavy data. You can say trained on at least a million data points about what you watched, what you clicked, how much time you binged, etc.
- Prediction: This is a classic problem that MLOps solves. From demand forecasting to churn analysis, MLOps can handle any type of prediction task. Retailers use MLOps to forecast inventory needs; finance teams predict loan defaults; manufacturers forecast equipment failure.
LLMOps
LLMOps manages applications that understand, generate, or act upon unstructured, natural language.
- Free-form interaction: The most common use of LLMOps is chat-based interfaces that can understand and respond in natural language. For instance, a company deploying a GPT-powered customer support bot relies on LLMOps to log every interaction, fine-tune prompts for accuracy, and track hallucination or latency rates.
- Content creation: LLMOps extends beyond text. It is the core of any app that supports content and media generation, from writing personalized marketing emails to creating images, code, or videos.
- Problem-solving: LLMOps are popular for open-ended problem-solving. You're not just asking a question; you're giving the LLM a multi-step job. For example, ‘Plan a 3-day trip to Paris for me, find the best-rated hotel near the Eiffel Tower, and book the flights.’
How to Use MLOps and LLMOps in Tandem
Let’s say you’re building a recommendation model for your e-commerce app. Over time, you might integrate an LLM-based assistant to explain recommendations or answer user questions. The ML model predicts what to show, while the LLM explains why.
Now, here’s the challenge: most MLOps tools don’t natively support LLM workflows, and vice versa. And manually mixing the two is not recommended. The lack of integration creates gaps. You start seeing untracked experiments, missing lineage between versions, or inconsistent deployment flows.
That’s exactly when we built ZenML.

ZenML is a unified MLOps + LLMOps framework that extends the battle-tested principles you rely on for classical ML to the new world of LLMs. It’s one platform for developing, evaluating, and deploying both Ops into a unified pipeline.
Whether you’re processing data for a predictive model or generating embeddings for a RAG system, you’ll be executing a series of steps in a single ZenML pipeline.
By standardizing on pipelines, you can:
Future Proof Your Stack
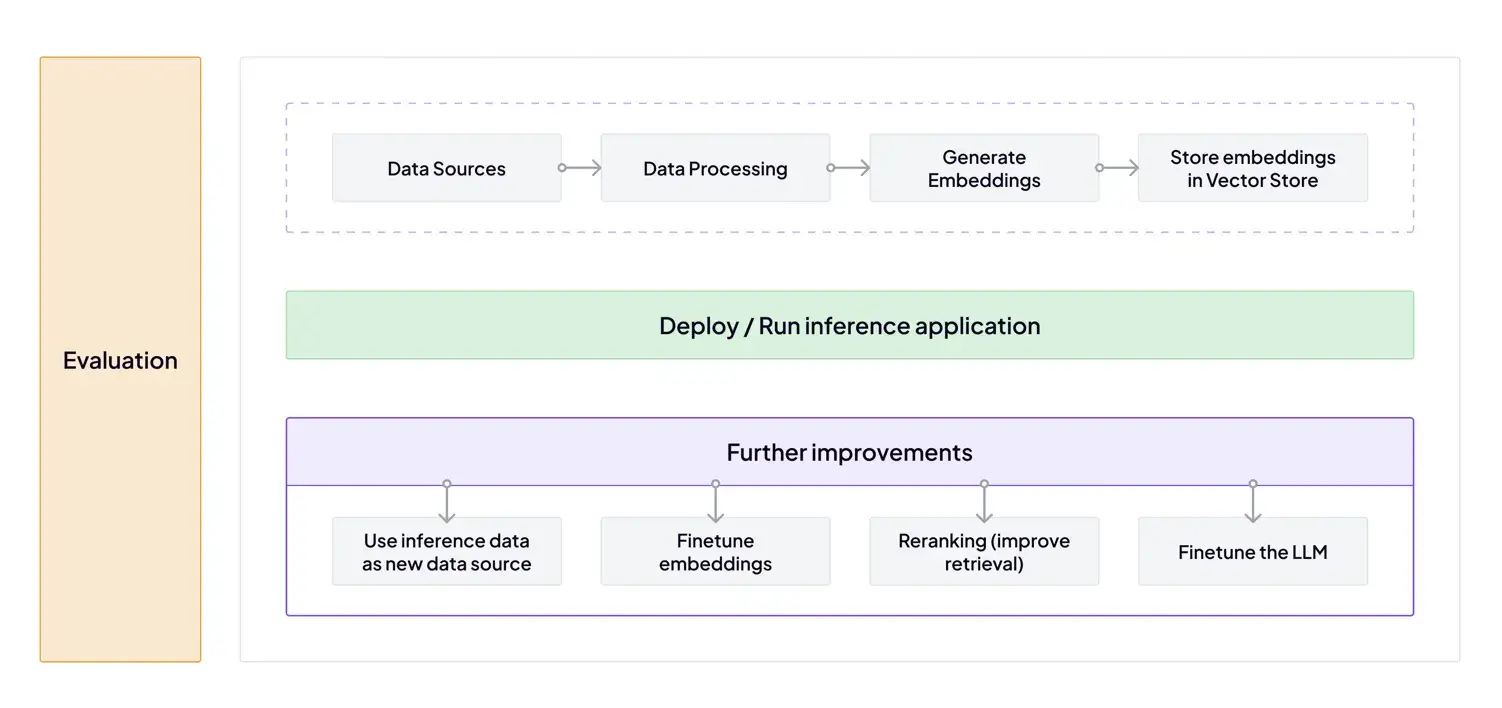
In ZenML, pipelines define every step. You can include steps for data preprocessing, model training, LLM prompt tuning, evaluation, and deployment. This abstraction makes it possible to mix and match workflows:
- A data scientist might train a churn prediction model (MLOps).
- A product team might fine-tune an LLM that explains churn reasons in natural language (LLMOps).
- Both run on the same orchestrator, with every artifact versioned and traceable.
Put simply, you can start with a simple pipeline today. When you need to add an LLM-based feature tomorrow, you can add it to your existing ZenML pipeline instead of starting from scratch.
With the recent pipeline deployment capability, teams can now push these workflows directly to production environments with controlled rollout and version tracking. The same deployment logic applies whether you’re updating a model binary or an LLM inference endpoint.
Collaborate
Machine learning pipelines often span multiple teams. ZenML’s central dashboard acts as a single pane of glass where technical and non-technical team members can track progress.
This transparency is especially important when MLOps and LLMOps overlap. For instance, prompt engineers may want to understand how model retraining affects downstream outputs, while ML engineers need visibility into how RAG corpus updates influence predictions. ZenML provides that shared visibility out of the box.
MLOps vs LLMOps: Which One’s Right for You?
So, how do you choose between MLOps vs LLMOps? If you ask us, it all comes down to your core application.
✅ If you’re building systems that rely on structured data to make predictions or classifications, you need MLOps. Your focus will be on feature engineering, model training, and monitoring for statistical drift.
✅ If you’re building applications that interact with users through natural language or generate novel content, you need LLMOps. Your focus will shift to prompt engineering, context management with RAG, and evaluating the quality and safety of generated outputs.
But as we said at the start, it’s a spectrum. The most powerful apps often combine both. Many real-world applications combine structured prediction and natural language understanding.


