On this page
Embeddings are the backbone of Retrieval-Augmented Generation (RAG) pipelines. By turning text, code, or other inputs into high-dimensional vectors, they allow semantic search to surface information that traditional keyword matching would miss. This step is what makes RAG systems capable of grounding large language models in accurate, context-relevant data.
The embedding model you choose directly shapes retrieval accuracy and, by extension, the quality of responses your system produces. A weak model may overlook critical documents or misinterpret domain-specific language, while a strong one can unlock nuanced understanding across languages, formats, and contexts.
Today, teams can pick from a wide range of models, both open-source releases and commercial APIs, each offering different trade-offs in language coverage, instruction tuning, context length, and cost. Selecting the right model requires balancing these factors against your use case, whether you’re powering a multilingual chatbot, searching source code, or indexing millions of documents.
In this guide, we outline the key considerations for evaluating embeddings, then profile the top models worth testing this year.
What to Look for When Choosing an Embedding Model for RAG?
Selecting an embedding model is an MLOps infrastructure decision, not just an NLP one. The model you choose will influence your vector database costs, inference latency, and your ability to adapt the system to your specific domain. Here are the key factors to evaluate.
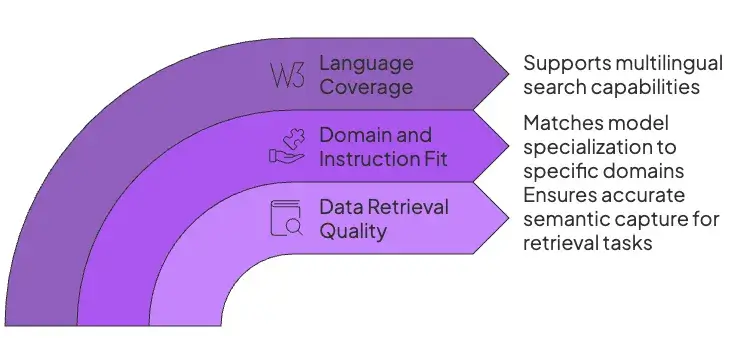
1. Data Retrieval Quality
Embeddings must capture the right semantic nuances for your retrieval task.
Models that top benchmarks, for example, MTEB, tend to yield better search results, but real-world accuracy depends on how well they handle your content.
Evaluate candidate models on a sample of your data using metrics like recall or NDCG to ensure high-quality retrieval. Beware that synthetic benchmark scores may not reflect your domain, so always test on in-domain queries and documents.
2. Domain and Instruction Fit
Models can be either generalists or specialists.
Generalist models like NVIDIA’s NV-Embed-v2 are trained on a wide variety of data and perform well across many tasks.
Specialist models are optimized for a specific domain, such as code retrieval, like Alibaba’s Qwen3-Embedding.
Additionally, many modern models are ‘instruction-aware,’ meaning they require a specific text prefix to be added to queries and documents to achieve optimal performance. For example, models from Nomic and Qwen perform best when you prepend inputs with tasks like search_query: or search_document:.
3. Language Coverage
If you need a multilingual search, ensure the model supports all target languages. Some models are English-only, while others cover dozens or hundreds of languages.
For example, Google’s Gemini Embedding-001 and Jina v3 are explicitly multilingual (100+ languages). Alibaba’s Qwen3 and Snowflake Arctic are also multilingual, excelling in cross-lingual retrieval.
If you only have English data, a monolingual model like ModernBERT or NV-Embed-v2 (English-only) may suffice.
What are the Top Embedding Models for RAG on the Market?
The embedding model landscape is divided between proprietary, API-based services that offer ease of use and open-source models that provide maximum control and customization.
The right choice depends on a strategic trade-off between managed convenience and operational flexibility.
The following table provides a quick comparison of the models we review in detail.
| Model | Type | License | Max Context | Key Strength | Fine-Tunable? |
|---|---|---|---|---|---|
| NVIDIA NV-Embed-v2 | Open Source | CC-BY-NC-4.0 | 4096 | Top MTEB Performance | No official Script |
| Voyage AI - voyage-3.5 series | Proprietary | Proprietary | 32K | Cost-Performance and MRL | Yes (Managed Service) |
| Google Gemini Embedding | Proprietary | Proprietary | 2K | Multilingual and Code | Yes (via GCP) |
| OpenAI text-embedding-3-large | Proprietary | Proprietary | 8192 | Ecosystem and Performance | Yes (Managed Service) |
| Cohere Embed v4 | Proprietary | Proprietary | 128K | Multimodality and Long Context | No (Adapters possible) |
| BAAI BGE-M3 | Open Source | MIT | 8192 | Multi-Functionality (Hybrid Search) | Yes |
| Alibaba Qwen3-Embedding | Open Source | Apache 2.0 | 32K | SOTA Code and Multilingual | Yes |
| ModernBERT-Embed | Open Source | Apache 2.0 | 8192 | Encoder Efficiency and Speed | Yes |
| Snowflake Arctic-Embed | Open Source | Apache 2.0 | 8192 | Multiple Sizes for Cost/Perf Trade-off | Yes |
1. NVIDIA NV-Embed-v2
NVIDIA’s NV-Embed-v2 is a high-capacity text embedding model (based on Mistral-7B) designed for top-tier retrieval performance. It outputs 4096-dimensional vectors and currently tops the MTEB benchmark for general and retrieval tasks.
Features
- Uses a novel pooling method that attends to latent vectors to create a more representative sequence-level embedding, moving beyond simple mean pooling.
- Employs a sophisticated two-stage instruction training process that first focuses on retrieval tasks with hard negatives and then incorporates non-retrieval tasks to improve overall versatility.
- Integrates an advanced hard-negative mining technique that improves the model's ability to distinguish between closely related documents.
- Produces high-quality embeddings with a dimension of 4096, capturing fine-grained semantic details.
Pricing
The model is open source and available on Hugging Face. However, it is released under a cc-by-nc-4.0 license, which prohibits any commercial use. For production applications, NVIDIA directs users to its commercial NeMo Retriever NIMs, which are priced separately.
Pros and Cons
This model’s top-ranked performance and 4096-d output make it extremely powerful for English retrieval. It handles long inputs and uses advanced training tricks (latent attention) for quality.
However, it is English-only and resource-intensive (large vectors and model size). The non-commercial license restricts commercial use, and there’s no turnkey fine-tuning support for end users.
2. Voyage AI - voyage-3.5 series
Voyage AI’s voyage-3.5 and voyage-3.5-lite are cutting-edge embedding models built for high retrieval quality at low cost. They significantly outperform previous generation models while charging only $0.06 and $0.02 per million tokens, respectively.
Features
- Supports a massive 32,000-token context window, making it ideal for processing long documents without extensive preprocessing or chunking.
- Matryoshka Representation Learning (MRL) allows developers to generate embeddings at multiple dimensions (from 2048 down to 256), providing flexibility to trade performance for reduced storage and compute costs.
- Offers multiple quantization options, including
int8and binary, which can reduce vector database costs by up to 99% compared to standard floating-point vectors. - Evaluation benchmarks show strong performance on both multilingual datasets (covering 26 languages) and code-related retrieval tasks.
Pricing
Voyage AI offers a paid API with per-token pricing. The voyage-3.5 model costs $0.06 per 1 million tokens, while the voyage-3.5-lite model costs $0.02 per 1 million tokens. A free tier is available for developers to get started.
Pros and Cons
Voyage-3.5 delivers state-of-the-art retrieval vs. cost, with customizable vector sizes for storage efficiency. It easily scales (32K context) and supports many languages.
The downside is vendor lock-in: you must use Voyage’s API (no local deployment) and rely on a proprietary service. There’s also no native fine-tuning or open weights.
3. Google Gemini Embedding-001
Google’s Gemini Embedding model leverages the powerful, multimodal Gemini family of LLMs to produce high-quality embeddings. It is designed to deliver state-of-the-art performance across a wide array of languages and text modalities, including natural language and source code.
Features
- The API allows you to specify a task type, for example,
RETRIEVAL_DOCUMENT,RETRIEVAL_QUERY,CODE_RETRIEVAL_QUERY, etc, to generate embeddings optimized for a specific use case. - Inherits the advanced capabilities of the Gemini foundation model, providing robust performance on multilingual and code-related tasks.
- Matryoshka supports variable output dimensions, allowing the default 768-dimension vector to be truncated for efficiency gains.
- The model is trained on data spanning over 250 languages, making it highly effective for cross-lingual retrieval applications.
Pricing
Gemini Embedding is a paid service available through the Google AI Studio and Vertex AI APIs. Pricing is based on the number of input tokens, with a free tier available for developers to experiment and build prototypes.
Pros and Cons
The model’s key advantages are its top-tier performance, particularly for multilingual and code retrieval, and its seamless integration into the Google Cloud Platform ecosystem. As a proprietary API, it offers less control than open-source alternatives.
However, Google does provide a supervised fine-tuning workflow within Vertex AI, giving enterprises a path to adapt the model to their specific data.
4. OpenAI text-embedding-3-large
OpenAI’s text-embedding-3-large is a high-end proprietary embedding model via the OpenAI API that produces 3072-dimensional vectors. It is designed for both English and non-English content. The model can ingest up to 8191 tokens (approximately 6,000 words) in a single call, making it suitable for processing long documents.
Features
- Natively supports shortening embeddings via the
dimensionsAPI parameter. This allows developers to reduce the vector size from its native 3072 dimensions to a smaller size while still maintaining high performance. - Achieves a strong performance score of 64.6% on the MTEB benchmark, making it one of the top-performing proprietary models.
- Handles a maximum input of 8192 tokens, allowing it to process moderately long documents effectively.
- The model was designed with a focus on improved performance on multilingual benchmarks, making it suitable for global applications.
Pricing
This model is available as a paid API, priced at $0.13 per 1 million input tokens. This is more expensive than its smaller counterpart (text-embedding-3-small) and older models like ada-002.
Pros and Cons
A major advantage of text-embedding-3-large is its strong performance and ease of integration for teams already working within the OpenAI ecosystem.
However, it is a closed-source, proprietary model. While it performs well, some open-source models like BGE-M3 have demonstrated superior performance on specific multilingual benchmarks. Fine-tuning is available as a managed service through OpenAI’s platform, which offers a path for customization but less control than self-hosting.
5. Cohere Embed v4
Cohere Embed v4 via Oracle Cloud’s Generative AI service is a multimodal embedding model producing 1536-dimensional vectors. It can embed text or single images via Base64 input. Text inputs up to 128K tokens per call are allowed via the API.
Features
- Can embed text, images, and interleaved text-and-image documents into the same semantic space, which is ideal for visually rich documents like PDFs and product manuals.
- Supports an exceptionally long context window of 128,000 tokens, enabling it to process entire reports or books in a single pass.
- Supports both quantization -
byteandbinary, and MRL, which can reduce vector storage costs by up to 83% while maintaining high retrieval accuracy. - The model is designed to be multilingual by default, retrieving relevant content in over 100 languages even when the query and document languages do not match.
Pricing
Embed v4 is a paid API service available through Cohere’s platform as well as cloud marketplaces like AWS and Azure. Pricing is based on the number of input tokens, with text priced at $0.12 per 1 million tokens.
Pros and Cons
The model’s unique strengths are its true multimodal capabilities and its massive context window, which can drastically simplify the data ingestion pipeline for complex, visually rich documents.
As a proprietary model, it lacks the transparency and control of open-source alternatives. Direct fine-tuning is not offered, though it is possible to use adapter-based methods to specialize closed-source models for specific tasks.
6. BAAI BGE-M3
The Beijing Academy of AI’s BGE-M3 is an open-source multitask embedding model (Apache 2.0) with a 1024-d output. It’s remarkable for multi-functionality: it supports dense, multi-vector, and sparse retrieval in one model.
Features
- Supports dense retrieval (standard semantic search), sparse retrieval (lexical matching similar to BM25), and multi-vector retrieval (like ColBERT) in one unified model.
- Provides strong support for over 100 languages, achieving the most efficient results on multilingual and cross-lingual retrieval benchmarks.
- Can process inputs ranging from short sentences to long documents up to 8192 tokens in length.
- Its ability to generate both dense and sparse vectors simultaneously makes it ideal for building sophisticated hybrid search systems that combine semantic and keyword relevance.
Pricing
BGE-M3 is fully open source under a permissive MIT license, making it free for commercial use. For teams that prefer a managed API, it’s also available through third-party providers at a low cost.
Pros and Cons
The model’s greatest advantage is its flexibility. The open-source license and multi-functional capabilities empower developers to build advanced, self-hosted search systems with full control. The model is well-supported by the FlagEmbedding library, which provides clear examples for fine-tuning.
The main drawback is that leveraging its full potential for hybrid search requires more complex infrastructure, like vector databases like Vespa or Milvus that support both dense and sparse vectors.
7. Alibaba Qwen3-Embedding
Alibaba’s Qwen3-Embedding models (0.6B, 4B, 8B sizes) are proprietary text embedding and reranking models built on the Qwen3 LLM family. They all support 100+ languages (including programming languages) and long contexts (32K tokens).
Features
- The 8B model has achieved the #1 rank on the MTEB multilingual leaderboard and also leads the MTEB-Code benchmark, making it an exceptional choice for code-based RAG.
- The model can follow custom instructions provided at inference time, allowing you to tailor its behavior for specific tasks or domains without retraining.
- Supports Matryoshka Representation Learning (MRL) that offers flexible embedding dimensions, enabling a trade-off between performance and efficiency.
- Can process long documents with a context length of up to 32,000 tokens.
Pricing
The Qwen3-Embedding models are open source under the permissive Apache 2.0 license, making them completely free for research and commercial use. They are also available as a managed service through Alibaba Cloud APIs.
Pros and Cons
The key advantages of this series are its exceptional performance, especially for code and multilingual RAG, and its commercially friendly open-source license.
However, the models are relatively new, so the surrounding ecosystem of tools and community support may still be maturing.
8. ModernBERT-Embed
ModernBERT-Embed is an open-source embedding model (Apache-2.0) from Nomic AI, derived from the ModernBERT language model. It produces 768-dimensional vectors by default, but supports Matryoshka truncation to 256-d. ModernBERT was trained on diverse English data, and this embedding variant brings those gains to retrieval.
Features
- Replaces traditional positional encodings with Rotary Positional Embeddings (RoPE) and uses Alternating Attention (a mix of local and global attention) to efficiently handle long contexts up to 8192 tokens.
- The model is trained to distinguish between different task types and requires a prefix (e.g.,
search_query:orsearch_document:) to be added to the input text for optimal performance. - Supports MRL, allowing its native 768-dimension embedding to be truncated to 256 dimensions, reducing memory usage by 3x with minimal performance loss.
- The model excels in programming-related benchmarks, demonstrating its suitability for code understanding and retrieval tasks.
Pricing
ModernBERT-Embed is open source under the Apache 2.0 license and is freely available on Hugging Face.
Pros and Cons
This model offers a highly efficient and performant open-source option, particularly for teams familiar with BERT-style architectures.
Its main limitation is its primary focus on English; a separate model, mmBERT, is available for multilingual tasks. The requirement to add prefixes is a minor inconvenience, but it is necessary to achieve the best results.
9. Snowflake Arctic-Embed (L and M variants)
Snowflake’s Arctic-Embed suite (v1.5 medium and v2.0 large) is Apache-2.0 licensed, multilingual embedding models tuned for high retrieval quality. The L v2.0 model has 1024-d vectors (303M parameters) and supports 74 languages.
Features
- The suite includes
xs(22M),s(33M),m(110M),m-long(137M), andl(335M) variants, allowing developers to select the best model for their specific performance and budget needs. - The latest v2.0 versions of the models are designed with multilingual workloads in mind, outperforming previous versions on benchmarks like MIRACL and CLEF.
- The
arctic-embed-m-longmodel supports a context length of up to 8192 tokens, making it suitable for longer documents. - The models are trained using a flexible contrastive data representation that generalizes across different types of training data (pairs, triplets) and improves training efficiency.
Pricing
All Arctic-Embed models are open source under the Apache 2.0 license and are free for commercial use. They are also integrated into the Snowflake platform as Cortex AI functions, where usage is billed based on consumption.
Pros and Cons
The primary advantage of the Arctic-Embed suite is the range of sizes, which provides an excellent pathway for developers to scale their RAG applications based on cost and performance requirements. The models are well-integrated with the Sentence Transformers library, which makes fine-tuning easy.
While the models are fully open, their tightest integration is within the Snowflake ecosystem, which might be a consideration for teams using other data platforms.
How to Fine-Tune with ZenML
ZenML is an open-source MLOps + LLMOps framework that provides the orchestration layer to manage the entire RAG and embedding fine-tuning lifecycle. It bridges the gap between the LLMOps world of building generative AI applications and the traditional MLOps world of training and versioning models.
The entire workflow can be defined as a reproducible ZenML pipeline, ensuring that every step is automated, versioned, and tracked :
- Synthetic Data Generation: The pipeline begins with a step that uses a tool like
Distilabelto automatically generate high-quality question-and-answer pairs from your raw documents. This is a crucial step for creating the training data needed for fine-tuning. - Data Curation and Annotation: The synthetically generated data is then pushed to an annotation tool like
Argilla. Here, human reviewers can inspect, clean, and refine the data to ensure its quality. ZenML's built-in annotator integration allows the pipeline to seamlessly pull the curated dataset back for the next stage. - Model Fine-Tuning: A dedicated training step loads the cleaned data and fine-tunes your chosen open-source embedding model. This step can be configured to run on specialized hardware, such as GPUs, to accelerate the training process.
- Evaluation and Versioning: After training, an evaluation step compares the performance of the new fine-tuned model against the original base model on a held-out test set. The results, along with the new model, the data it was trained on, and the pipeline that produced it, are all versioned and logged in ZenML.
This entire process is managed and made observable through ZenML’s core features. The Model Control Plane provides a unified dashboard that acts as a single source of truth, linking every model version to the exact data, code, and pipeline run that created it. This delivers complete lineage and governance for your RAG system.
What’s more, ZenML’s Stacks abstract away the underlying infrastructure, allowing you to run the exact same pipeline code on your local machine for development and then on a cloud provider like AWS or GCP for production without any changes.
📚 Related articles to read:
Wrapping Up: From Model Selection to Production-Ready RAG
Choosing the right embedding model is key to a successful RAG system. Across the 9 models above, you can see a spectrum from open-source to fully managed, from English-only to truly multilingual, and from moderate dims to ultra-large vectors.
We encourage benchmarking candidates on the MTEB leaderboard and on your own data to find the best fit.
ZenML offers a unique and powerful solution by providing a unified framework that manages both of these workflows within a single, cohesive project.
By orchestrating the entire lifecycle, from data ingestion and synthetic data generation to model training and evaluation, ZenML ensures that every component of your RAG system is reproducible, auditable, and ready for production.
This holistic approach is what transforms a promising prototype into a reliable, enterprise-grade AI application.
If you’re interested in taking your AI agent projects to the next level, consider joining the ZenML waitlist. We’re building out first-class support for agentic frameworks (like LangChain, LlamaIndex, and more) inside ZenML, and we’d love early feedback from users pushing the boundaries of what AI agents can do. With ZenML, you can seamlessly integrate whichever agent framework you choose into robust, production-grade workflows. Join our waitlist to get started.👇