

On this page
Imagine spending weeks fine-tuning a large language model (LLM) for your app, only to watch it confidently spout outdated or incorrect answers.
ML engineers and Python developers often face this scenario when building agentic AI systems – those autonomous agents that need real-world knowledge and multi-step reasoning. The culprit is usually a lack of retrieval-augmented generation (RAG). Without robust RAG tools, even the smartest LLM hallucinates facts or misses context, leaving you with frustrated users and a pile of API bills.
Thankfully, a new generation of RAG tools is here to save the day. In this article, we explore 8 of the best RAG tools you should try this year – from open-source frameworks to enterprise-ready platforms.
What to Look for In A RAG Tool for Agentic AI?
Before diving into the tools, it is essential to establish a clear framework for evaluation. The choice of a RAG tool is no longer just an NLP or data science decision; it has become an MLOps infrastructure decision. Let’s look at some factors to look for when selecting a RAG tool for agentic AI.
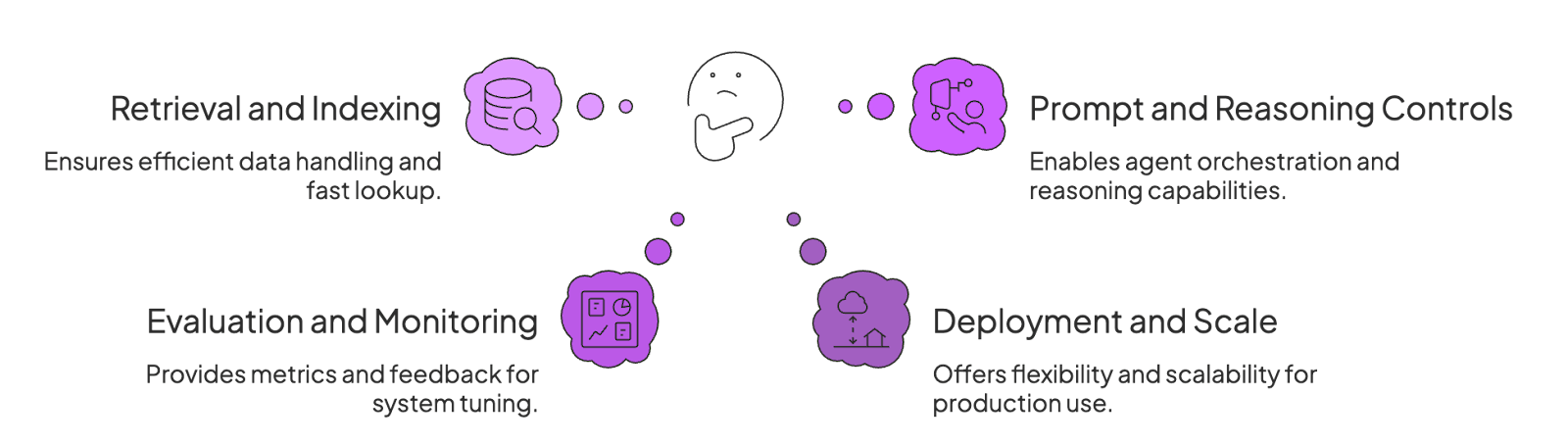
1. Retrieval and Indexing Functionality
How well does the tool handle ingesting and indexing your data for retrieval?
A good RAG tool should let you load documents, chunk them if needed, and create embeddings or indices for fast lookup. Look for support for vector databases and advanced indexing techniques.
For example, some tools support keyword, semantic vector, and even hybrid indexes.
What’s more, the tool should quickly retrieve relevant chunks based on a query – this is the backbone of grounding an agent’s answers in facts.
2. Prompt and Reasoning Controls
A RAG tool for agentic AI must empower the ‘agentic’ part of the system. This is where orchestration and reasoning come into play.
The tool should provide clear mechanisms for orchestration, allowing you to define multi-step workflows, implement conditional logic, and grant the agent the ability to use tools to interact with its environment.
It should also support common agentic patterns like ReAct (Reason+Act), where the agent can reason about a task, decide on an action, and execute it, often in a loop until the task is complete. This control over the reasoning process is what separates a simple Q&A bot from a true AI agent.
3. Evaluation and Monitoring
In production, you need to know your agent is working correctly. Top RAG tools provide evaluation metrics and logging for the retrieval process and the QA quality. For instance, some frameworks have built-in tracing and QA evaluation metrics.
Monitoring features might include logging of what documents were retrieved for each query, accuracy of answers (if ground truth is known), and support for human feedback (reinforcement learning or annotation).
This helps you tune the system and catch issues like poor retrieval results or hallucinated outputs.
4. Deployment and Scale
Finally, consider how the tool fits into your deployment scenario and scaling needs.
Does it offer an easy way to deploy as an API or microservice?
Can it handle large volumes of data and concurrent queries with low latency?
Some enterprise platforms emphasize real-time data access and data virtualization (querying live data without re-indexing).
If you expect to scale to millions of documents or high QPS, look for a tool with proven performance like an optimized retriever model, support for distributed indexing, or integration with cloud services for scale.
Also, check the open-source vs commercial nature: open-source tools give flexibility, but you manage infrastructure; commercial ones might handle scaling for you (at a cost).
What are the Best RAG Tools for Agentic AI Currently on the Market?
This section provides a detailed breakdown of 8 leading tools, evaluated against the production-focused criteria established above.
This analysis will help you identify the right tool for your specific use case, whether you are building a quick prototype or a large-scale, enterprise-grade agentic system.
| Tool | Key RAG Feature | Best For | Pricing Model |
|---|---|---|---|
| ZenML | Pipeline components for RAG within reproducible MLOps/LLMOps workflows. | Teams needing a unified platform for MLOps + LLMOps to ensure orchestration and reproducibility. | Open-source and free, with an upcoming commercial platform. |
| Dify | Visual no-code builder for managing knowledge bases and designing agent workflows. | Rapid prototyping with a visual interface, especially for teams with limited ML/LLM expertise. | Free “Sandbox” plan, with paid plans starting at $59/month. |
| Embedchain | Simplified data loading with a single .add() command and automatic pipeline management. | Beginners, rapid prototyping, and projects where development speed is the highest priority. | Fully open-source and free. |
| LlamaIndex | Advanced indexing (e.g., Knowledge Graph Index) and retrieval strategies for complex documents. | Developers needing deep customization and state-of-the-art retrieval capabilities. | Open-source is free (with 10k credits); paid cloud plans start at $50/month. |
| GraphRAG Toolkit | Automatically constructs a knowledge graph from text to uncover hidden relationships. | Answering complex questions that require synthesizing information from disparate sources. | Open-source and free. |
| R2R | Combines multimodal ingestion, hybrid search, and an integrated reasoning agent. | Companies that need to build and deploy production-grade RAG systems using an open-source solution. | Open-source and free. |
| Haystack | Modular, pipeline-based architecture for composing custom RAG and agentic systems. | Developers needing to build flexible, highly customizable RAG workflows with strong observability tools. | An open-source framework is free; a commercial platform is also available. |
| Squirro | Real-time data virtualization from enterprise sources with an “AI Guardrails” layer for compliance. | Enterprises with complex data, strict compliance requirements, and the need to integrate with existing systems. | Not publicly listed; custom enterprise pricing. |
1. ZenML
ZenML is an open-source MLOps + LLMOps framework that offers robust support for RAG pipelines – essentially giving you an end-to-end system for retrieval and LLM integration inside reproducible workflows.
The platform lets you build RAG-enabled AI pipelines with minimal fuss, so your autonomous agents can fetch knowledge as part of a structured ML workflow.
Features
- Pipeline Components for RAG: ZenML provides pre-built steps to handle data ingestion, embedding generation, and vector store integration. You just plug in a step to ingest documents and another to compute embeddings, then store them in a vector database.
- Orchestration & Reproducibility: Because ZenML is an MLOps framework, it treats your RAG process as a pipeline that can be orchestrated on various backends (local, cloud). This ensures reproducible agent behavior – every retrieval step and model call can be tracked and versioned. ZenML also tracks artifacts and metadata for your RAG pipeline, which is great for debugging and auditing
- Integration with Agents: While ZenML itself isn’t an agent framework, you can integrate it with agentic libraries (like LangGraph, LlamaIndex, CrewAI, and many more) by orchestrating those within ZenML pipelines. Essentially, ZenML can handle the RAG part and feed it into an agent’s prompt, or even manage a multi-step agent workflow via pipeline steps.
- Extensibility and Stack Support: ZenML supports multiple vector databases and LLM providers through its stack components. It’s designed to be agnostic – e.g., you could use FAISS or Weaviate for vector storage, and OpenAI or local models for generation. This means you’re not locked into one vendor.
Pricing
We are upgrading our platform to bring every ML and LLM workflow into one place for you to run, track, and improve. Think of processes like data preparation, training, RAG indexing, agent orchestration, and more, all in one place.
Pros and Cons
ZenML’s biggest advantage for agentic AI is that it brings mature MLOps and LLOps practices to your LLM workflows. You get experiment tracking, model/prompt versioning, data lineage, and deployment pipelines out of the box, which is excellent for maintaining reproducibility and observability in complex RAG systems.
It’s also highly extensible and tool-agnostic – you’re not locked into specific models or databases, since you can integrate your choices via ZenML’s stack components.
But remember, ZenML is not a specialized RAG UI or a one-click QA solution – it’s a framework. Using ZenML for RAG requires writing pipeline code and understanding its abstractions.
2. Dify
Dify is an open-source platform that combines a visual no-code builder for LLM applications with powerful RAG and agentic capabilities. The platform lets you build AI agents through a web interface, making it accessible to teams that don’t want to write a lot of code for prompt flows or knowledge base setup.
Features
- Provides an industry-first visual interface for managing your knowledge bases. You can upload documents or connect data sources, and Dify will handle indexing them into a vector database.
- You can design chatbots or agent workflows in a drag-and-drop fashion. It supports different orchestration modes – from simple single-turn prompts to multi-step assistant flows. There’s also an agentic workflow builder that uses nodes, which you can live-debug.
- Comes with a flexible RAG engine. It supports multiple indexing methods: keyword, text embeddings, and even an LLM-assisted snippet search.
- The platform provides templates and settings to build either simple chat-based assistants or more complex, agentic applications that can use tools to complete tasks.
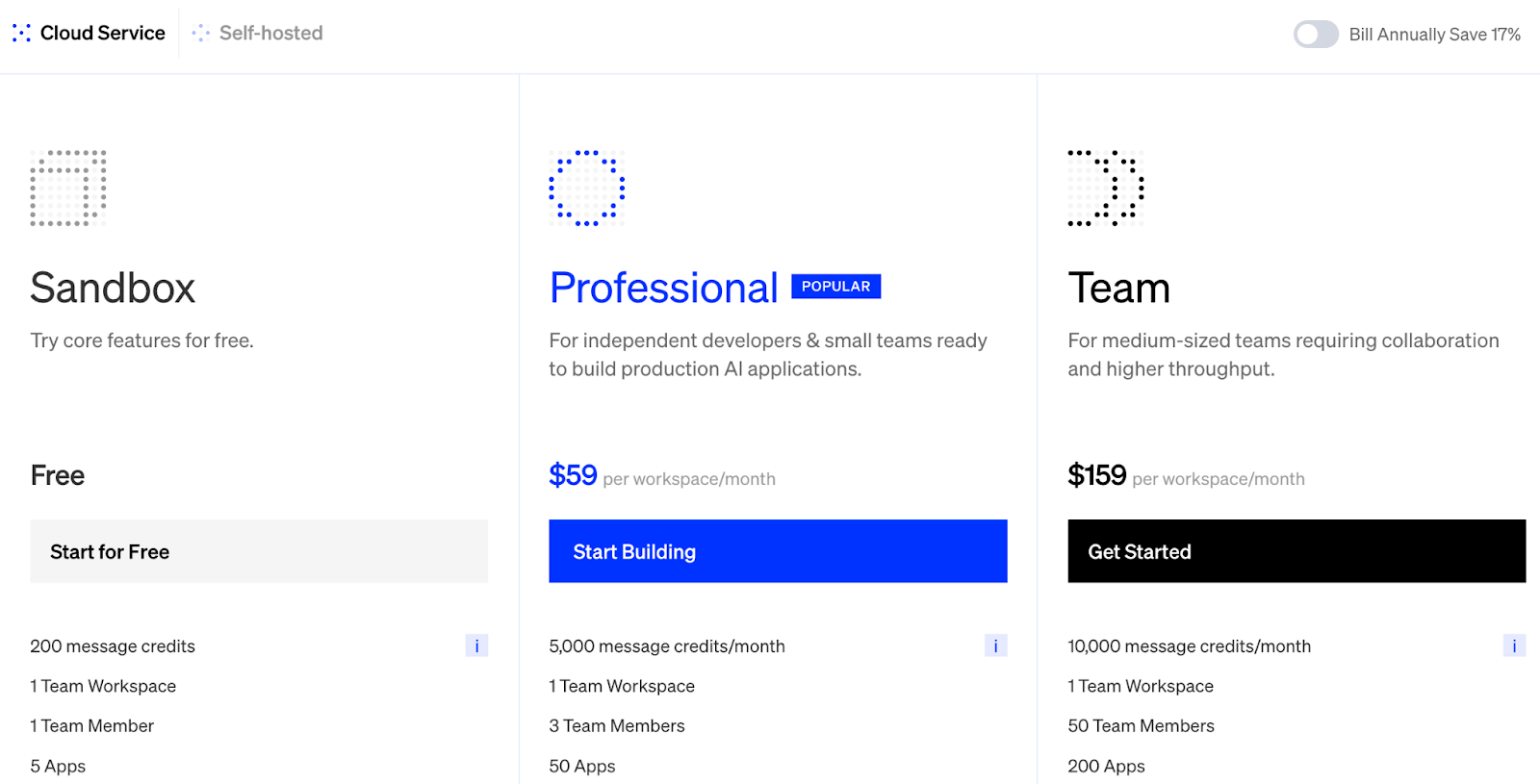
Pricing
Dify’s open source plan - Sandbox gives you access to 200 OpenAI calls for free, after which you have to upgrade to its paid version:
- Professional: $59 per workspace per month (5,000 message credits)
- Team: $159 per workspace per month (10,000 message credits)
Pros and Cons
The biggest pro of Dify is its user-friendliness. I’ve seen teams with limited ML/LLM expertise get a prototype agent running in a day using Dify’s GUI. It abstracts a lot of complexity – from prompt orchestration to vector DB ops – yet still allows advanced configurations when needed.
However, Dify doesn’t cover the whole production story. Doing all the work of monitoring and evaluations becomes a challenge with this framework.
3. Embedchain
Embedchain is an open-source framework that takes a developer-centric approach to RAG. It’s often described as ‘the Swiss Army knife of RAG’ for how it streamlines creating a chatbot or Q&A agent with your data.
Features
- Provides a single
.add()command to load data from various sources like web pages, YouTube videos, PDFs, and Notion. It handles data type detection and chunking automatically. - Allows for easy configuration and swapping of different components. You can integrate various LLMs from providers like OpenAI and Hugging Face, and connect to vector databases like ChromaDB, Pinecone, and Weaviate.
- Manages the entire RAG data pipeline, including loading, chunking, creating embeddings, and storing them in a vector database.
- Includes a
.chat()method that maintains conversation history. This feature makes it easy to create context-aware chatbots on top of your custom knowledge base.
Pricing
Embedchain is a fully open-source framework and is free to use. Any associated costs are determined by the third-party services you choose to integrate, such as paid LLM APIs from OpenAI or hosted vector database solutions.
Pros and Cons
Embedchain’s main advantage is its remarkable simplicity and low barrier to entry. This makes it an excellent choice for beginners, rapid prototyping, or projects where development speed is the highest priority. Its abstraction layers are well-designed, effectively hiding complexity without completely removing the option for configuration.
However, for complex, production-grade systems that demand fine-grained control over the RAG pipeline, Embedchain’s high level of abstraction might become a limitation. It is less focused on broader MLOps concerns like deployment and monitoring compared to more comprehensive platforms.
4. LlamaIndex
LlamaIndex is a powerful open-source data framework specifically designed for building context-augmented LLM applications and agents. It offers a comprehensive and flexible toolkit that covers all stages of the RAG pipeline, from data ingestion to advanced retrieval and agentic orchestration.
Features
- Through its LlamaParse component, LlamaIndex excels at parsing complex documents with nested tables, images, and challenging layouts.
- The framework moves beyond simple vector search, offering a wide array of indexing structures like Tree Index and Knowledge Graph Index, and advanced retrieval strategies.
- Provides robust abstractions for building agents that can use tools, plan tasks, and perform complex reasoning. It integrates with hundreds of tools via LlamaHub.
- For teams looking to reduce operational overhead, LlamaIndex offers a managed platform, LlamaCloud, to handle document processing, parsing, and indexing at scale.
Pricing
The LlamaIndex framework is open-source and free, but it will only give you 10K credits. If you want more credits, advanced features, and want to collaborate with the team, upgrade to one of its paid plans:
- Starter: $50 per month
- Pro: $500 per month
- Enterprise: Custom

Pros and Cons
LlamaIndex offers unparalleled depth and flexibility for building custom RAG systems. Its focus on advanced retrieval techniques and its rich ecosystem of connectors make it a top choice for developers who need granular control.
However, the framework’s vast number of features results in a steep learning curve. We’ve also found that for production use, it lacks the built-in orchestration and observability needed to manage complex pipelines, which is a key reason some developers seek alternatives.
5. GraphRAG Toolkit
GraphRAG, an open-source toolkit from Microsoft Research, enhances RAG by constructing a knowledge graph from unstructured data. This allows agents to reason about holistic concepts and hidden relationships, overcoming a key limitation of traditional vector search.
Features
- The toolkit automatically extracts entities and relationships from raw text to build a knowledge graph, creating a structured representation of the information.
- Uses graph clustering algorithms to identify semantic communities within the data and generates summaries for them, enabling a high-level understanding of the dataset.
- GraphRAG supports ‘global search’ for broad questions by leveraging community summaries and ‘local search’ for specific questions by traversing the graph.
- By leveraging the graph's structure, the toolkit can answer complex questions that require connecting disparate pieces of information, a task where baseline RAG often fails.
Pricing
GraphRAG is an open-source toolkit available under permissive licenses like Apache-2.0 or MIT. It is free to use, with costs coming from the LLM calls required for indexing and querying.
Pros and Cons
GraphRAG’s main advantage is its ability to perform deep, contextual reasoning and uncover synthesized insights that are impossible with standard RAG.
But a drawback we found was the significant upfront cost and complexity of building the knowledge graph. The indexing process is computationally expensive, and the resulting graph can be difficult to update, making it less suitable for use cases with highly dynamic datasets.
6. R2R
R2R is an open-source framework designed for building and deploying production-grade RAG applications. It simplifies the development process by providing a comprehensive set of tools for ingestion, embedding, and retrieval.
Features
- R2R can ingest a wide variety of file formats, including text, PDFs, and even audio and video files, allowing you to build a comprehensive knowledge base for your agent.
- It combines the strengths of semantic and keyword search to deliver more accurate and relevant results.
- R2R can automatically extract entities and relationships from your data to build a knowledge graph.
- The framework includes an integrated reasoning agent that can perform complex, multi-step queries.
Pricing
R2R is an open-source project and is free to use.
Pros and Cons
R2R’s support for multimodal ingestion, hybrid search, and knowledge graphs makes it a versatile tool for a wide range of use cases.
However, its extensive feature set may have a steeper learning curve, and it requires self-hosting and maintenance. Also, R2R doesn’t cover the full lifecycle of agentic AI.
7. Haystack (by deepset)

Haystack by deepset is a production-ready, open-source AI framework for building complex LLM applications. It features a modular, pipeline-based architecture that allows developers to compose and customize sophisticated RAG and agentic systems.
Features
- Build pipelines from components like retrievers, readers, and generators. Supports conditional nodes and loops for multi-step reasoning or fallback logic, making it adaptable for diverse agentic AI workflows.
- Lets you choose dense, sparse, or hybrid retrieval. Integrates with FAISS, Elasticsearch, and more, and supports re-ranking models to refine results for better context in agentic AI queries.
- Connects to LLM providers (OpenAI, Azure, HuggingFace) and document stores (Elasticsearch, Milvus, etc.). Includes utilities for PDFs, OCR, and multiple formats for seamless infrastructure fit.
- Offers a REST API, UI (Haystack Annotator), tracing, logging, and feedback loops. Monitor retrieval quality, track document context, and gather user feedback to improve agents in production.
Pricing
The Haystack framework is open-source and free. Deepset also offers a commercial ‘deepset AI Platform,’ which includes a free ‘Studio’ tier for prototyping and custom-priced Enterprise plans.
Pros and Cons
Haystack lets you build flexible, modular pipelines for custom RAG workflows and scales to millions of documents with strong observability tools for debugging and optimization.
However, it has a steeper learning curve due to code-first setup and a lack of a built-in GUI unless using Deepset Cloud.
8. Squirro
Squirro is an enterprise software company known for its Augmented Intelligence platform, which includes cognitive search, insights, and now generative AI capabilities. For RAG, Squirro positions itself as an enterprise-ready solution to build ‘Insight Engines’ that combine your disparate data sources with LLMs.
Features
- Connects to dozens of enterprise data sources like SharePoint, CRM, and databases. Supports real-time data virtualization for live queries without full ingestion, keeping knowledge bases fresh and up to date.
- Combines AI-powered search with RAG. Uses Squirro Retriever to pull indexed data, then LLMs to answer queries. Includes iterative feedback loops for improved relevance and accuracy.
- Provides an Agent Framework for chatbot actions, API access, and workflow triggers. Includes AI Guardrails and Privacy Layer to enforce compliance and prevent sensitive data exposure.
- Builds knowledge graphs to understand relationships in data, enabling contextual retrieval. Improves accuracy by linking related entities and surfacing relevant insights beyond the original query.
Pricing
Pricing for the core Squirro platform is not publicly listed. An app, ‘Squirro for Salesforce,’ starts at $10 USD per user per month. You can also check out the free version listed on the Azure Marketplace.
Pros and Cons
Squirro is built for the enterprise, with a strong focus on security, accuracy, and scalability. Its ability to integrate with existing enterprise systems makes it a powerful choice for organizations with complex data and strict compliance requirements.
However, Squirro is a heavy-duty, proprietary platform, which may be overkill for smaller teams. The learning curve can be steep, and the initial configuration is time-consuming.
How ZenML Helps In Closing the Outer Loop Around Your Agents
RAG tools help your agent find the right context and draft answers. The outer loop is everything that keeps this reliable in production: orchestration, lineage, evaluation, and day-2 ops. ZenML provides that layer around your RAG stack.
Orchestrate the Full RAG Flow
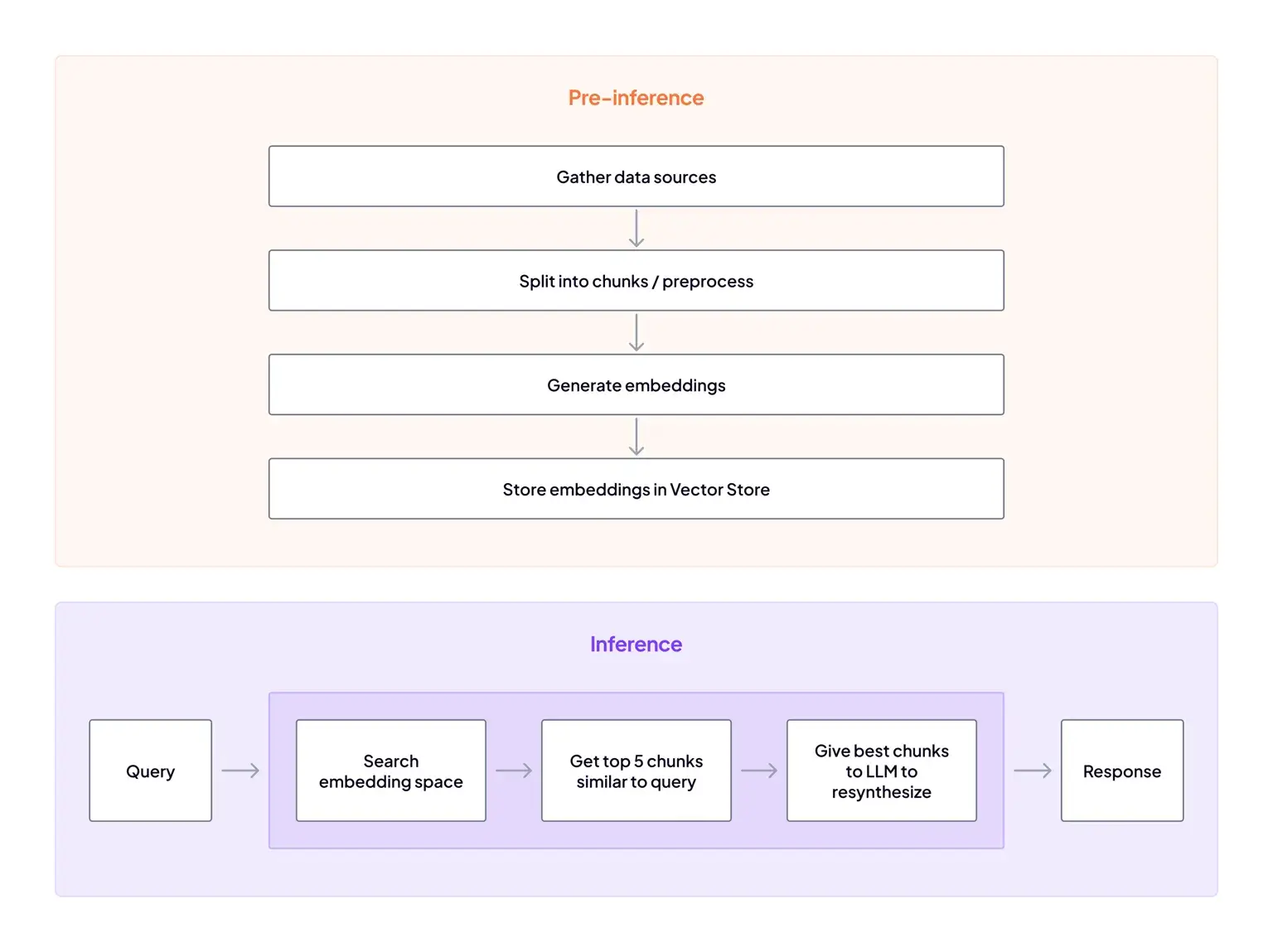
ZenML lets you define ingest, chunking, embedding, indexing, retrieval, answer generation, and post-processing as steps in a single pipeline. ZenML’s RAG guides cover index store management and tracking RAG artifacts, plus storing embeddings in a vector database for fast retrieval.
You can run the same pipeline on a schedule across supported orchestrators, or trigger runs from CI and even from other pipelines.
Parameters and YAML config let you switch models or retrievers without touching code, which is handy when you want to A/B a new embedder or a different retriever.
Unified Visibility and Lineage
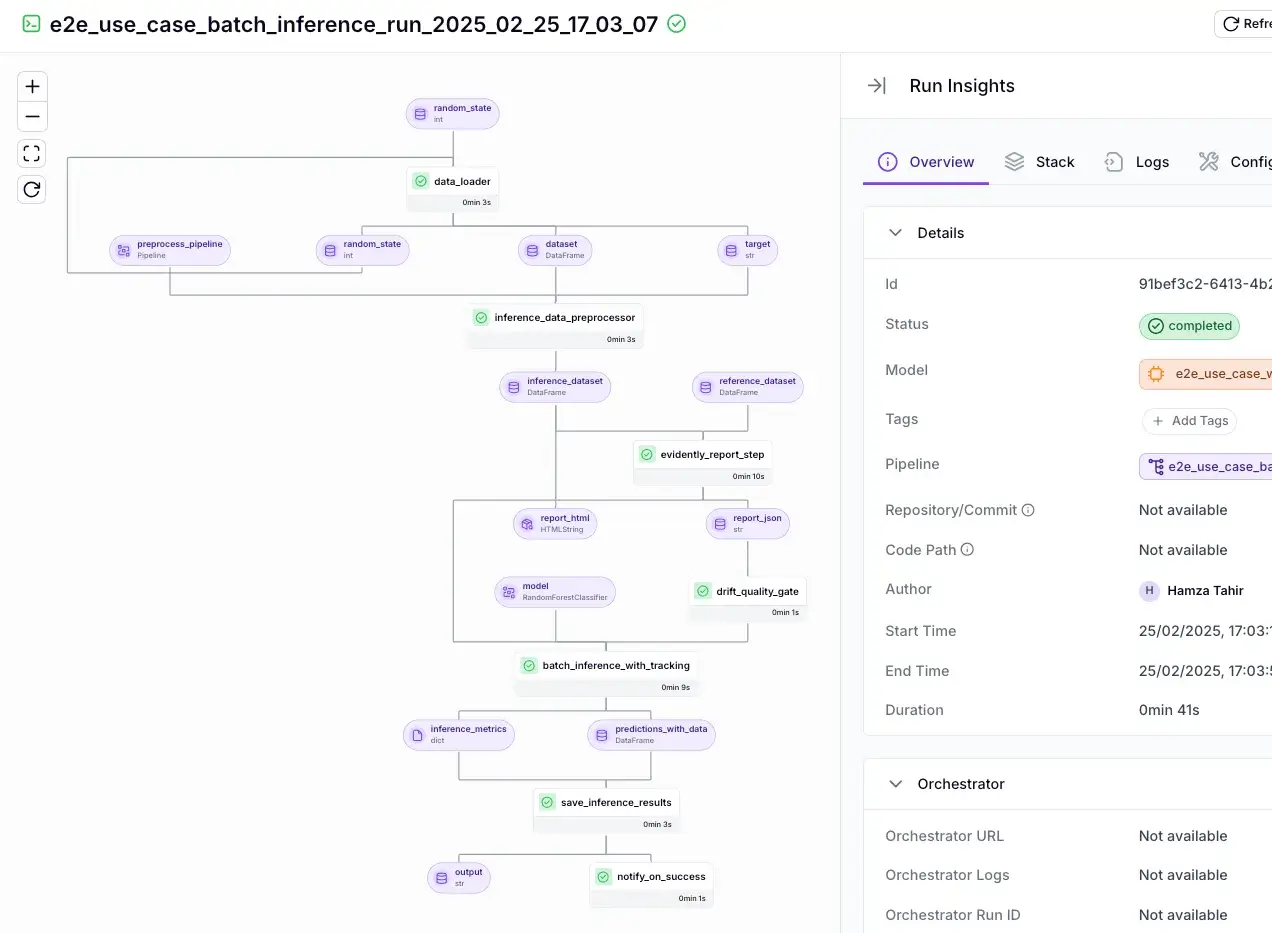
Every step in the pipeline produces versioned artifacts with full lineage, and you can attach run metadata for extra context.
The ZenML dashboard lets you browse runs, inputs, and outputs so you can follow an answer back to the data and code that produced it.
Our platform also records code repo commit hashes for runs, which helps when you need to compare behavior across revisions.
Continuous Evaluation and Feedback
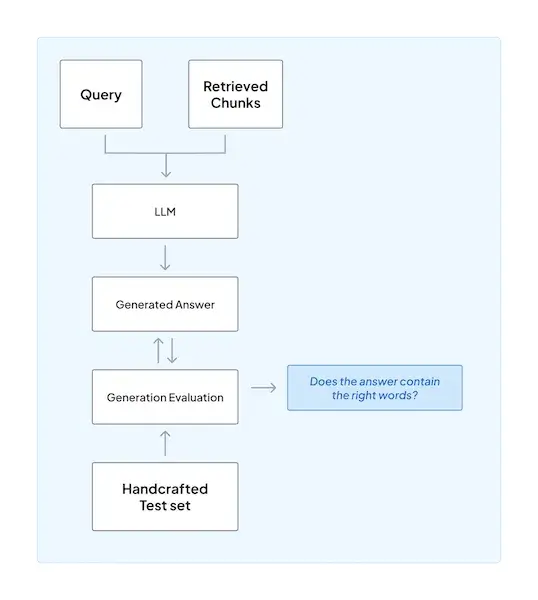
ZenML ships an evaluation workflow for RAG, including guidance for measuring both retrieval and generation.
You can use an LLM judge where it makes sense, and keep a human in the process.
You can also set up alerters that integrate with Slack or Discord so failures or review requests reach your team, and the Discord ‘ask’ step can pause a run until someone approves; practical human-in-the-loop for production.
Production Rollout and Scale
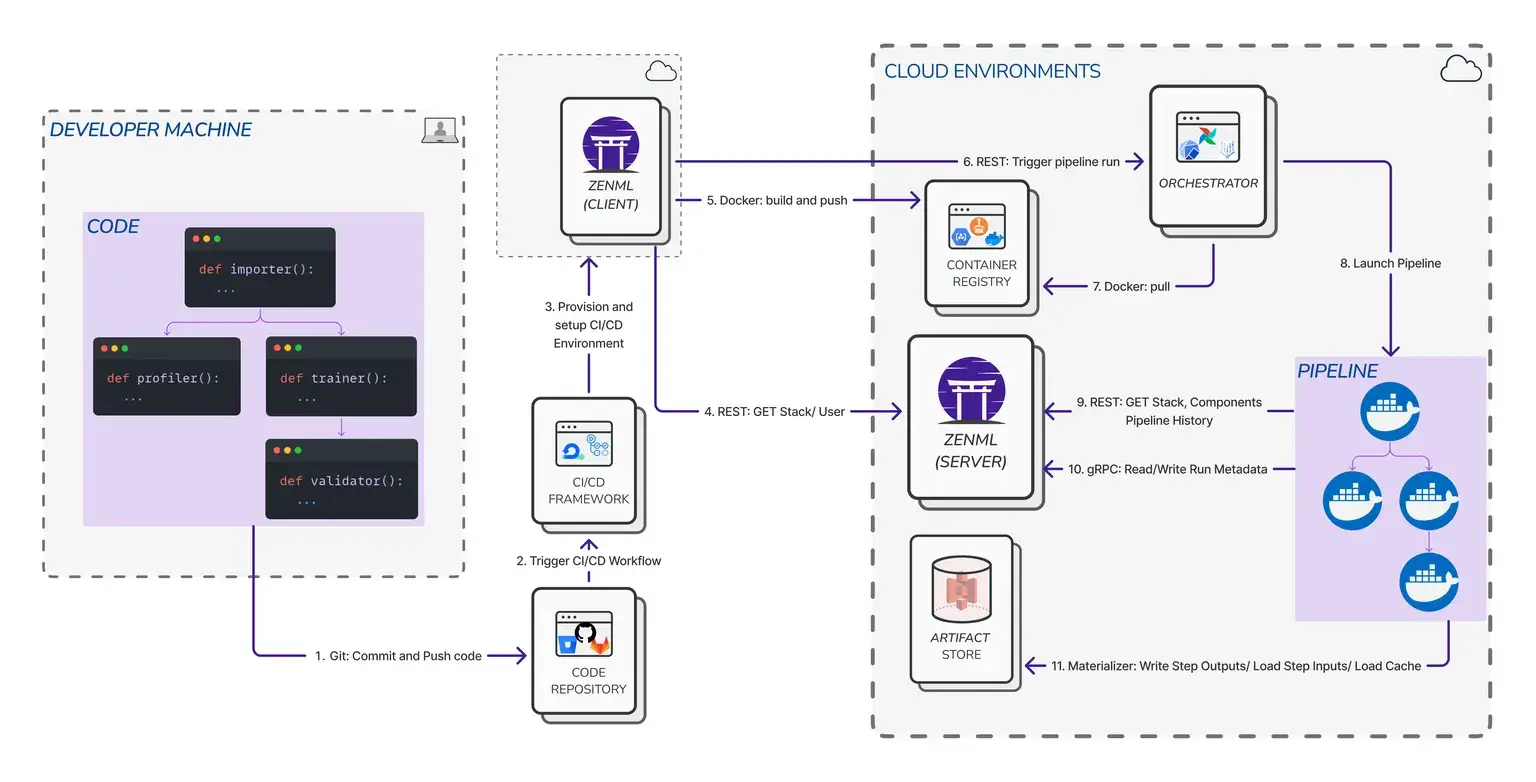
ZenML lets you choose an orchestrator that fits your environment – Kubernetes, Kubeflow, Airflow, Databricks, and more are supported for scheduled runs, and promote pipelines through CI/CD.
Secrets and cloud access are handled through ZenML’s centralized secrets store and Service Connectors, so your pipelines can reach vector DBs, storage, and clusters without hard-coding keys.
Need more compute? Request GPUs at the step level or fan out with distributed training patterns we offer.
ZenML does not replace your RAG tools. It wraps them. Use your preferred indexers, retrievers, vector stores, and evaluators. ZenML ties them into one repeatable, observable process and tracks every agent you run.
Which RAG Tool Should You Use for Agentic AI?
There is no single best RAG tool for every situation. The right choice depends on your project’s needs, your team’s expertise, and the required level of production readiness. The landscape is diverse, offering everything from lightweight libraries to full-scale enterprise platforms.
Based on our analysis, here are our recommendations:
- Teams that need a unified platform for MLOps + LLMOps: ZenML provides the ideal orchestration and reproducibility layer to build robust and maintainable RAG systems.
- For rapid prototyping with a visual interface: Dify offers the fastest path from an idea to a working application.
- For developers needing deep customization and state-of-the-art retrieval: LlamaIndex and Haystack offer unparalleled control and flexibility.
- For companies that need production-grade RAG systems: R2R comes with an open-source solution that lets you do it.
ZenML’s upcoming platform brings every ML and LLM workflow - data preparation, training, RAG indexing, agent orchestration, and more - into one place for you to run, track, and improve. Type in your email ID below and join the early-access waitlist. Be the first to build on a single, unified stack for reliable AI. 👇


