On this page
Hey ZenML Community,
Whether you’re serving a classical scikit-learn model or a new multi-step AI agent, you eventually hit the same wall.
The “wrap it in a simple API” approach works for a single function but breaks down for complex RAG flows or agentic systems. Suddenly, you’re battling cold starts, losing all observability, and managing two completely different codebases for training and serving.
This month is all about unifying that stack. We’re launching a new feature that turns any pipeline—from complex agent to classical model—into a persistent, high-performance service.
To show you exactly what this unlocks, we’ve got a deep-dive blog post and a **live demo webinar this Wednesday**. We’ve also got fantastic community highlights on financial agents and RAG evaluation, plus a new case study on cutting a 1-week ML pipeline down to 2 hours.
Let’s get into it.
⚡ Unifying Batch and Real-Time: Introducing Pipeline Deployments
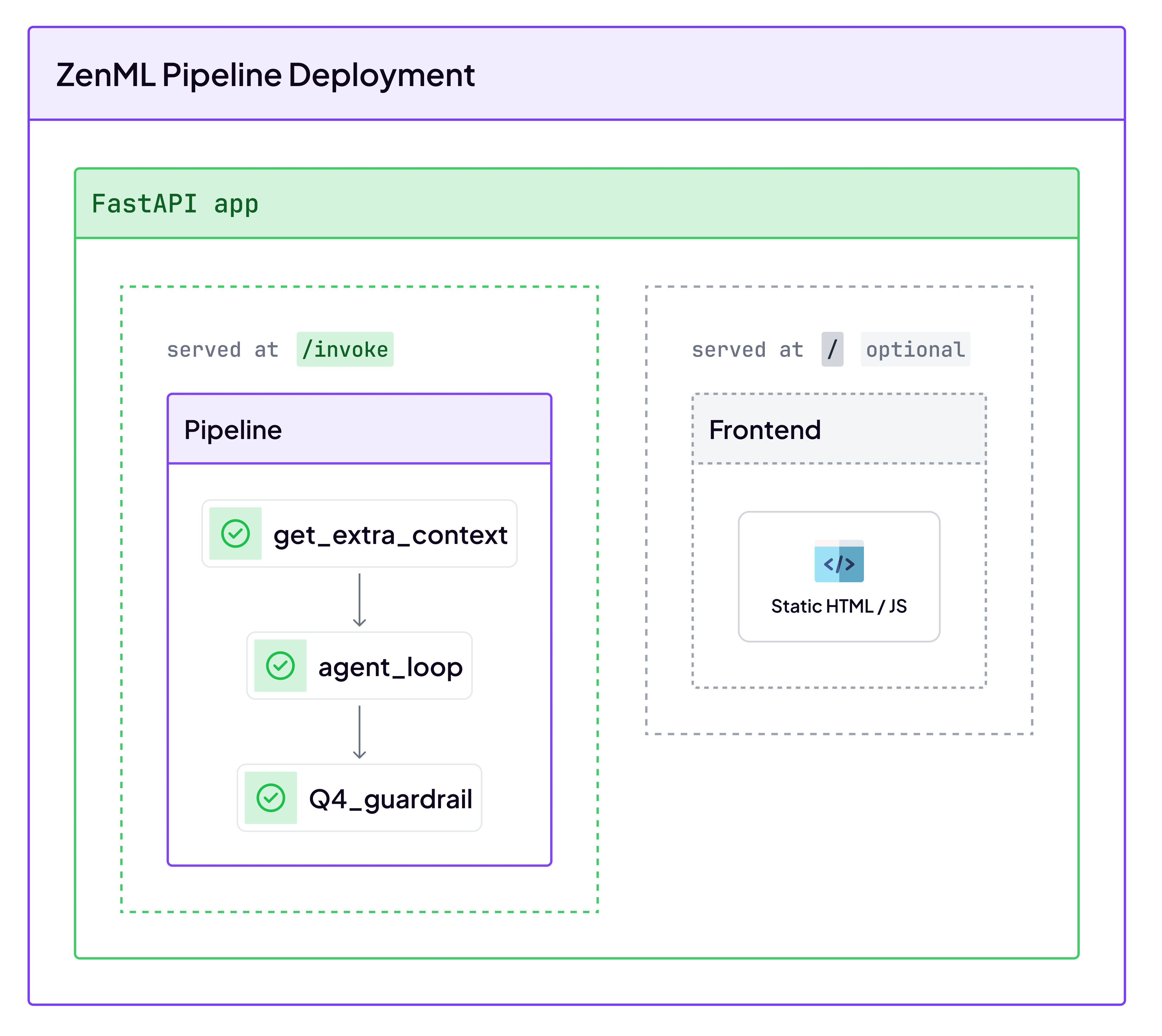
Pipelines have always been great for batch training, but what about real-time serving? The common approach—wrapping a model in FastAPI—works for simple inference, but it breaks down fast. As soon as you add multi-step logic, agentic orchestration, or stateful tools, you’re back to building custom infrastructure, dealing with 30-second cold starts, and losing all traceability.
We’re incredibly excited to launch Pipeline Deployments to solve this. This new feature transforms any ZenML pipeline (whether it’s a complex agent or a classical scikit-learn model) into a persistent, high-performance HTTP service.
It’s a single abstraction for your entire MLOps lifecycle. You get:
- Warm State (No Cold Starts): Models, tools, and vector stores are loaded once and kept in memory, cutting latency from seconds to milliseconds.
- Unified Stack: The same pipeline code you use for training can now be deployed for real-time serving. No more code drift.
- Full Observability: Every API request is a traceable pipeline run. You can debug production issues with the same tools you use in development.
- Instant Rollbacks: Deployments are immutable snapshots, letting you roll back to any previous version in seconds.
This unifies your classical ML and new agentic workflows under one reliable, observable, and scalable system.
Hamza wrote a blogpost about this new pipeline deployment feature and also below you can sign up for the Webinar we’re hosting this Wednesday to get a full deep-dive.
🧑💻 New from the Community

We’re excited to showcase two new blog posts from our community. First, Haziqa Sajid demonstrates how to build a multi-agent financial analysis pipeline using ZenML and SmolAgents. Her project tackles the complexity of analyzing dense financial reports by assigning specialized tasks to different agents—like a metrics agent, context agent, and risk agent—all orchestrated as a reproducible ZenML pipeline with LangFuse for observability.
Next, Satya Patel writes about building and, more importantly, evaluating a RAG system for clinical Q&A. He makes a strong case for why generic metrics aren’t enough in high-stakes domains like healthcare. Satya walks through his custom, domain-specific evaluation framework for both retrieval and generation, showing how ZenML was crucial for tracking experiments and proving the system’s reliability.
🚀 From 1 Week to 2 Hours: How Cross Screen Media Scaled
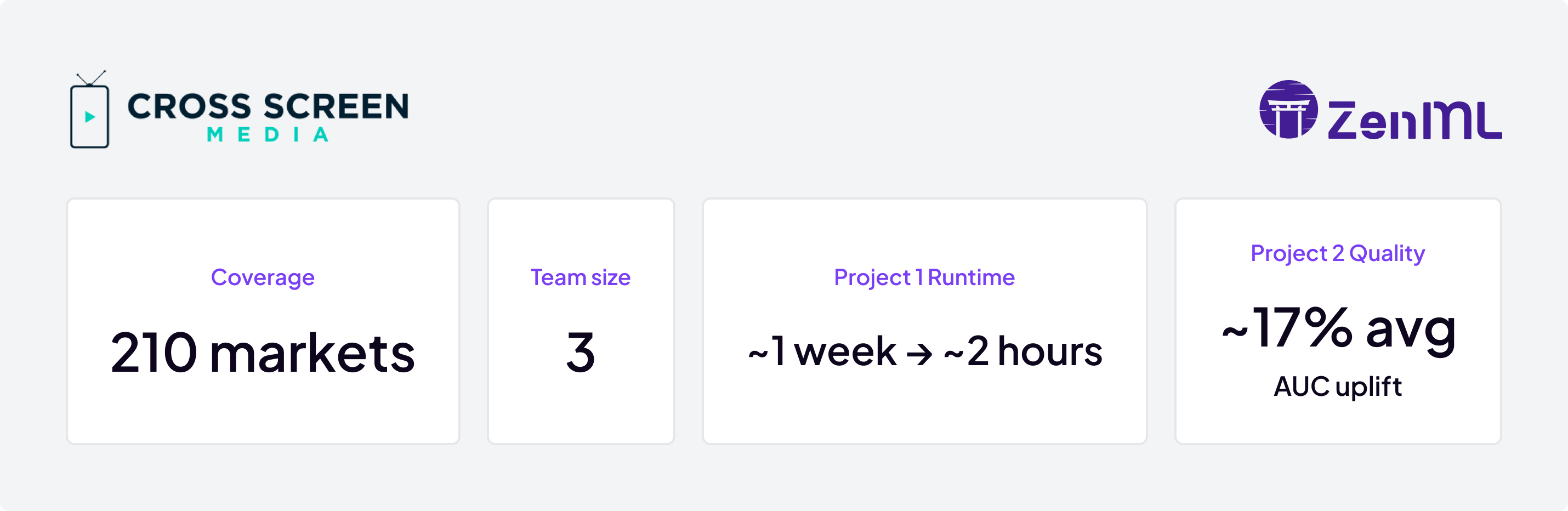
We just published a new case study detailing how Cross Screen Media’s 3-person data science team tackled a massive bottleneck. They manage ML workflows across 210 local markets on trillions of rows of data, and their core pipeline used to take over a week to run. This wasn’t just slow; it forced them to simplify models and sacrifice accuracy just to get the job done.
By implementing ZenML, they built a standardized, automated platform on Kubernetes. This eliminated their separate “notebook vs. production” codebases and empowered the team to manage their own infrastructure.
The results were transformative. That critical week-long pipeline now completes in just ~2 hours. Freed from this bottleneck, the team invested in more complex modeling, achieving a ~17% average AUC improvement across all 210 markets—a direct boost to their core product.
It’s a perfect example of how solid MLOps tooling doesn’t just save time, it unlocks new levels of model performance. Read the full Cross Screen Media case study to see their full architecture and workflow.
🍿 Live Demo: The Unified AI Stack

To show you exactly what Pipeline Deployments can do, Hamza and I (Alex) are hosting a live demo this Wednesday, October 29th, at 5:30 PM GMT+1.
We’ll walk through the new feature that transforms any ZenML pipeline into a persistent, real-time service. We’ll cover how it unifies classical ML and new agentic workflows, complete with full observability and instant rollbacks.
Save your seat on Luma and bring your toughest questions. We’re excited to show you this new way of building and look forward to seeing you there.
Until next time,
Alex (ML Engineer @ ZenML)