

On this page
On launch week, Postscript had an agent that worked in staging yet felt risky in production. The prototype ran on the Assistants API. Production needed tighter control and predictable cost on the Completions API. Small edits to model, temperature, or prompt shifted behaviour in ways the team could not measure. They could deploy. They could not prove that quality would hold across thousands of merchant brands with different tone, catalogue quirks, and discount rules. Without a way to compare “new vs old” on representative data, rollout was guesswork.
They unblocked launch by building an offline eval suite large enough to mirror real customers. Domain owners and engineers co-defined checks for format, policy, voice, and correctness, then froze a baseline. Every change ran against that baseline. Diffs were reviewable before traffic moved. That eval layer absorbed a late API migration and later model swaps with confidence. The lesson: shipping agents is not about a clever prompt. It is about reproducible versions and comparable evaluations in a deployment workflow.
Zoom out. This is common. Even platform vendors call deployment the next hard hurdle for agents. Teams that do ship lean on tracing and offline evaluation because performance quality outranks cost and safety as the top blocker.
Everyone is excited about agents. The stall point is the jump from a single script — agent.run(...) — to something safe on real data. Without versioning, you cannot reproduce or roll back behaviour. Without lineage and tracing, you cannot explain why Tuesday differs from Monday. Without evals tied to versions, you cannot compare “new vs old” honestly. Without orchestration and a stable API contract, downstream consumers break. The result: brittle demos that never become products.
Some signals the problem is systemic:
- 51% of teams say they already run agents in production and 78% plan to addmore, yet performance quality is the top barrier ahead of cost and safety. (source)
- Teams favour offline evals (≈39.8%) over online evals (≈32.5%), which reflects the difficulty of live monitoring without strong tracing and baselines. (source)
- Tooling roadmaps now ship prompt version comparison and eval workflows as first-class features. Versioned evals are becoming table stakes. (source)
This is why an MLOps production backend is the natural home for agents: pipelines for structure, versioned prompts and tools for sanity, orchestration for scale, lineage for debugging, and run templates plus eval baselines so you can compare “new vs old” before customers ever see it.
ZenML as the Production Backend for AI Agents: An MLOps Approach
In production, an agent is a workflow of retrieval, tool calls, LLM invocations, and often human oversight. Modern frameworks express this complexity as graphs — nodes and edges routing data and decisions. ZenML is designed to orchestrate exactly such graphs. By modeling agents as pipeline steps within ZenML, teams gain reproducibility, scalability, and observability out-of-the-box.
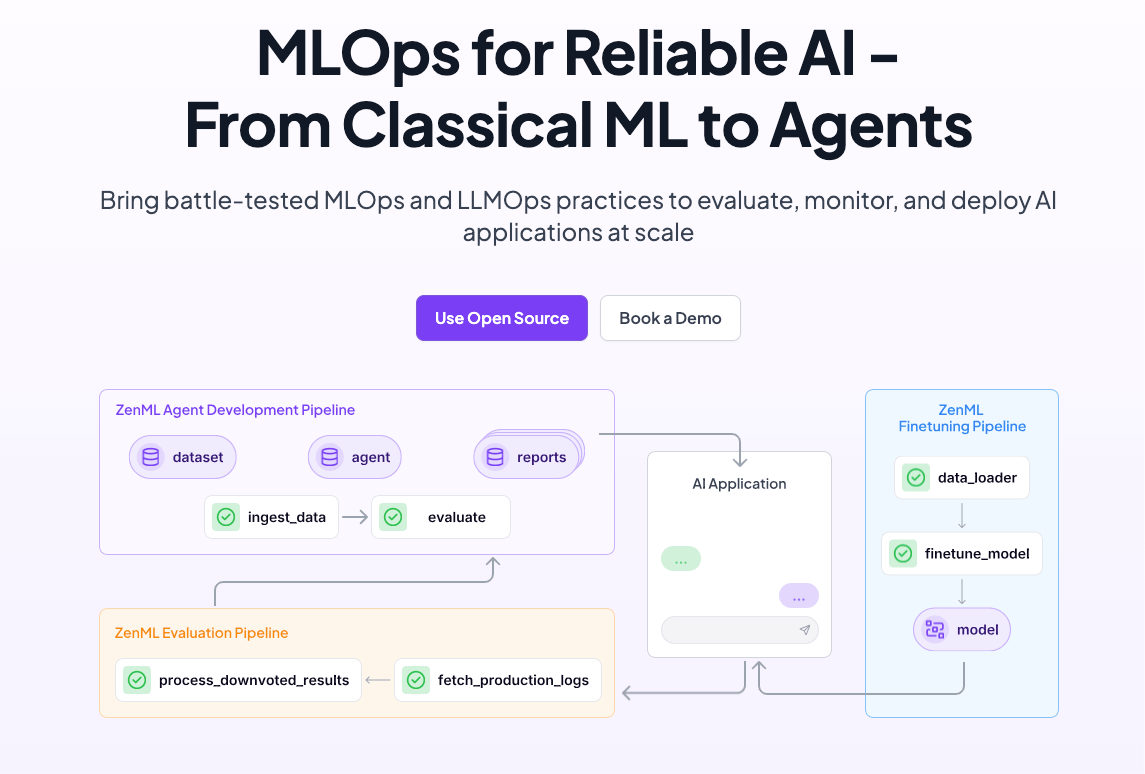
**Pipelines for structure.**ZenML pipelines inherently map to the multi-step logic of production agents, where each step generates clear, typed artifacts for downstream tasks. The ZenML model defines explicit input/output boundaries and deterministic execution flows, directly aligning with frameworks like LangGraph that conceptualize agents as stateful node-and-edge structures. Unlike notebooks or single-script solutions, ZenML visualizes and enforces agent execution clearly and consistently.
**Versioning for sanity.**In a production context, understanding precisely which code, prompts, tools, and configurations yield specific outputs is critical. ZenML addresses this by linking pipeline runs explicitly to Git commit hashes, artifact versions, and model registry entries. Teams can track code repository commits, version artifacts and prompts, and manage model versions systematically. This structured versioning allows accurate comparisons between different pipeline iterations, ensuring predictable updates and straightforward rollbacks.
**Orchestration for scale.**Deploying agents to production demands robust orchestration for workload isolation, autoscaling, and resilience. ZenML provides orchestration abstractions — such as the Kubernetes Orchestrator — that eliminate manual Kubernetes configuration. Teams define pipeline logic once and can flexibly deploy across diverse infrastructures without rewriting pipeline steps. ZenML stacks modularly separate orchestrators, artifact stores, and secrets managers, offering a composable deployment framework.
**Lineage for debugging.**When production agents deviate from expected performance, teams must pinpoint exact causes swiftly. ZenML captures detailed lineage metadata on pipeline executions, recording precisely which inputs, prompts, tools, and model versions contributed to each artifact. Tracing data across pipeline steps and external services dramatically reduces the troubleshooting burden.
**About “AgentOps.”**While the term “AgentOps” is increasingly popular, it describes existing MLOps disciplines — deployment automation, tracing, evaluations, and rollback processes — applied specifically to AI agents. ZenML adopts these proven MLOps practices, clarifying and concretely applying them to agent-based workflows rather than reinventing the concept under a new label.
To apply this approach practically:
- Implement your agent logic as individual ZenML pipeline steps.
- Clearly define upstream data processing, agent execution, and post-processing evaluation steps.
- Deploy pipelines using production-grade stacks (e.g., Kubernetes orchestrator, artifact store, and secrets management).
- Rigorously track pipeline versions via code repository commits and artifact lineage.
- Incorporate robust tracing and offline evaluation workflows, then expose pipelines as stable APIs through ZenML Run Templates.
Next, we illustrate these principles concretely by examining how the ZenPulse content agent utilizes ZenML in practice.
Case Study: Building the ZenPulse Content Agent
We built an agent-driven application feature as part of an internal tool called ‘ZenPulse’ to stop hand-curating Slack updates about “what’s shipping next.” Across repos and branches, people missed merges that mattered. We wanted a one-click summary that stayed accurate, used a consistent voice, and matched how we actually release. The core idea: move “write the update” from a brittle script to a versioned workflow with an API contract.
ZenPulse is a small web app (AIOHTTP + Jinja2, PostgreSQL) that lets us compose an announcement, trigger a pipeline, and post the result to Slack. The app never runs the agent code. It calls a ZenML Run Template, then waits for a webhook with the markdown. That boundary let us evolve models and prompts without touching the web container and gave us lineage, retries, and scheduling for free.
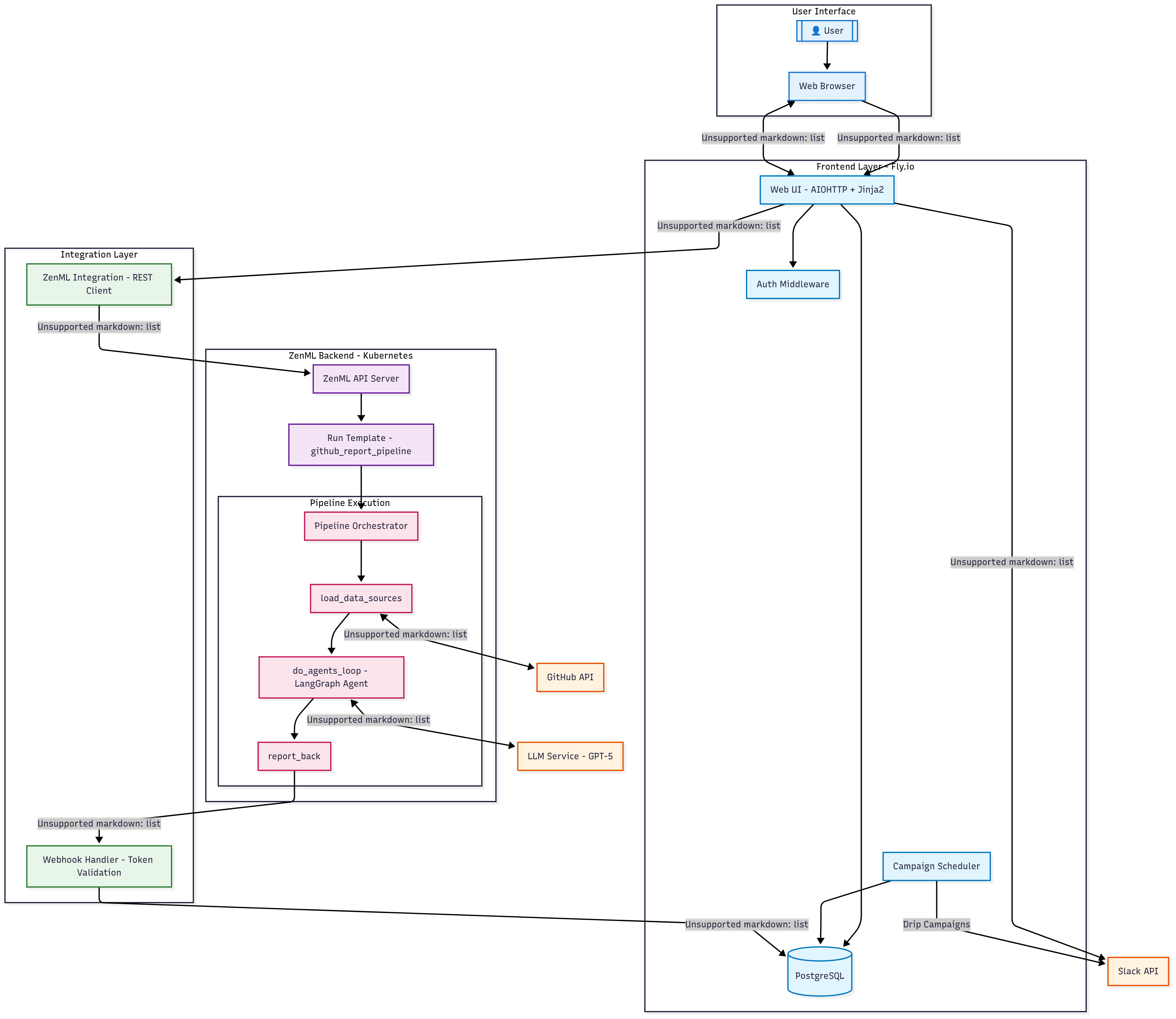
How we framed the problem
- Clear boundary. Frontend triggers. Backend (ZenML) runs. Results come back via webhook. This kept deployment clean and enabled isolated debugging.
- Fast “no-op” path. A preflight PR count short-circuits empty windows. We avoid cold-starting a model just to say “nothing happened.”
- Deterministic loop. The agent runs as a bounded LangGraph tool-use loop with an explicit recursion limit, so a stray tool call can’t spin forever.
- Clean output contract. The prompt wraps the report in
--BEGIN/END REPORT---. Downstream code extracts the block and never sees chain/tool chatter. This is a placeholder implementation which mainly works becausegpt-5is exceptional at following instructions, but going forward we'll have a structured output contract which guarantees clean results without this workaround. - Tunable style, stable schema. Inputs cover
repo,base_branch,date_range,analysis_type,tone/custom_prompt,ignored_prs,llm_model,max_iterations. Output is a small JSON withsummary_message,metrics, and the resolved timeframe.
The agent is a ZenML step
We implement the agent as a single ZenML step that wires LangGraph to GitHub MCPtools and a chat model. Details like imports, adapters, and logging are standard. The core is compact. A simplified version looks like this:
Why this shape: the preflight protects cost and latency; the loop gives the model tool access without losing control; the sentinels guarantee a clean payload; and the return schema is stable for the delivery step and the webhook.
The pipeline DAG
We kept the DAG small and legible. Responsibilities are explicit, and the ZenML UI makes runs debuggable by step.
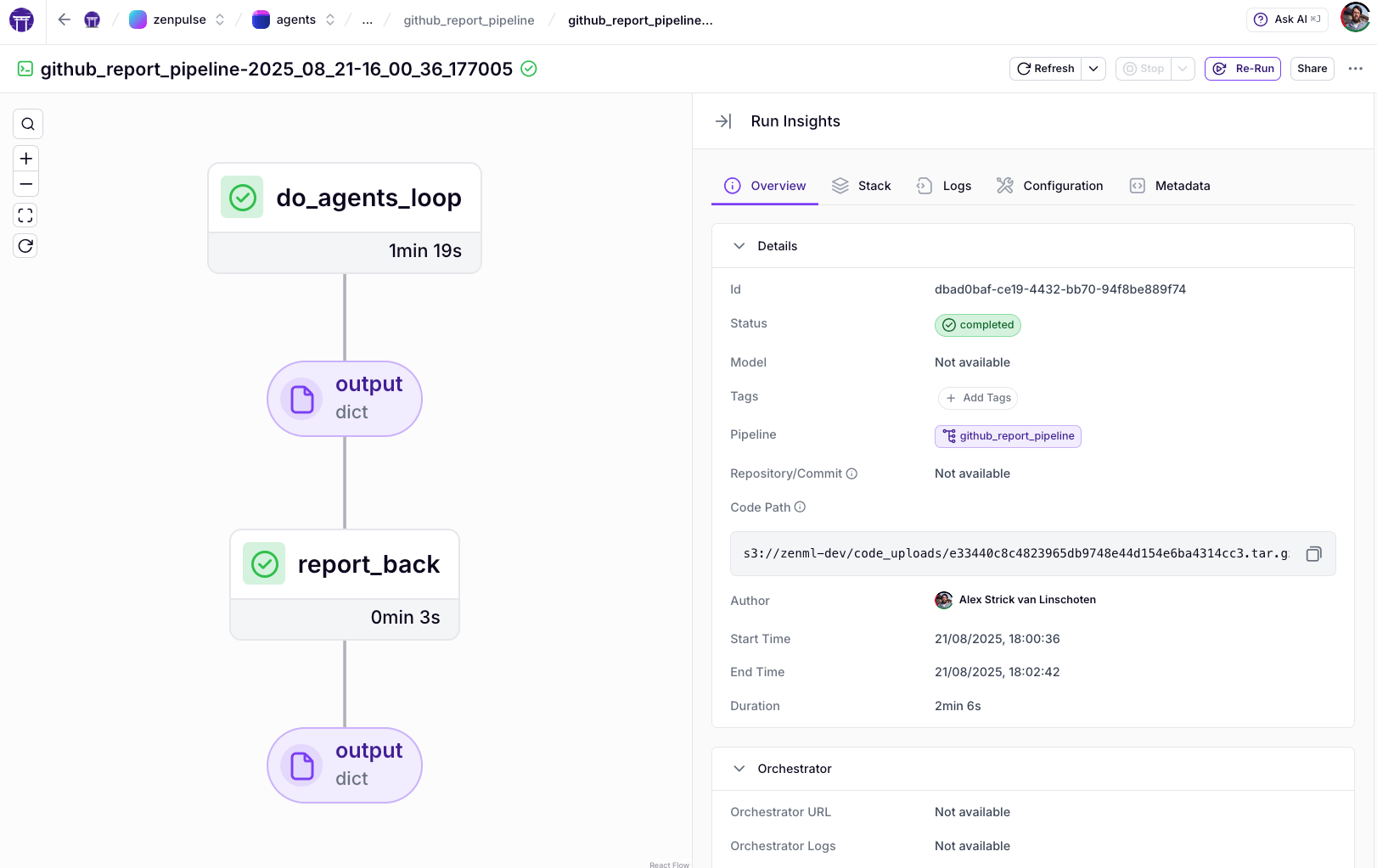
- do_agents_loop. Run the bounded LangGraph + MCP loop and emit markdown plus metrics like
preflight_merged_pr_countandreport_length_chars. - report_back. Attach run metadata and POST to the callback URL. The webhook payload is fully JSON-serialisable and includes
pipeline_run_idand the artifact URI for traceability.
In practice we’ve experimented with folding lightweight fetches into do_agents_loop to reduce build latency. The conceptual split above remains useful for tests, retries, and observability.
Frontend surface
The admin “Compose” screen accepts sources and style, triggers a run template, polls /status, then drops the returned markdown into the editor for a quick human pass before posting to Slack. The UI stays decoupled from prompt or model churn. That separation is why we can iterate on LangGraph graphs, prompts, or models without redeploying the web app.
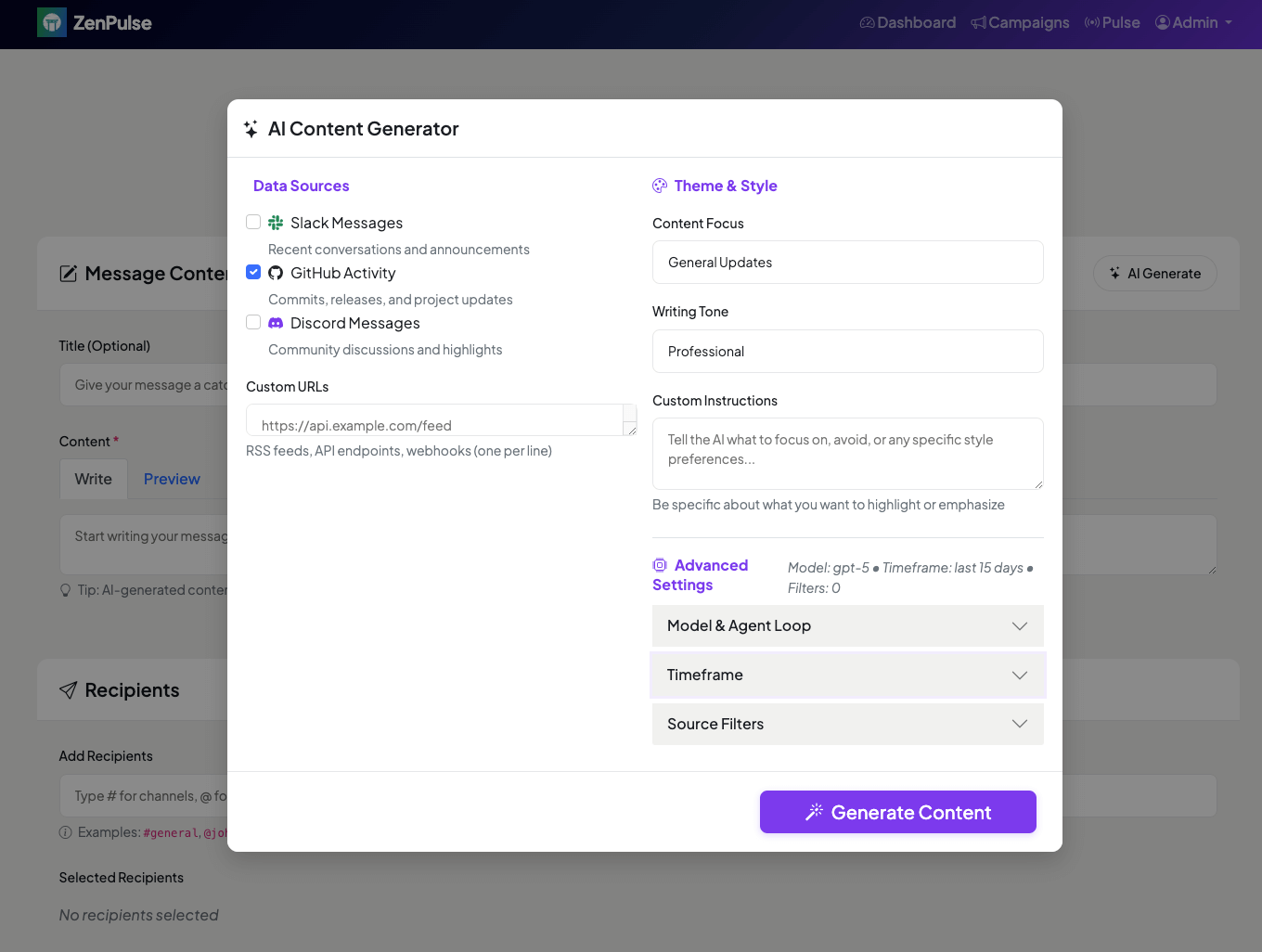
What changed as we iterated
- We migrated the inner loop from a minimal
mcp-useharness to LangGraphfor clearer routing and better control of recursion. We also enjoyed playingwith and getting to know the framework that's arguably the most used in real-world scenarios. - We added the sentinel output contract after early runs leaked intermediate “Action/Observation” traces.
- We tuned
compute_max_steps(max_iterations)so a friendly “3” maps to a safe upper bound, with a cap to prevent accidental long chains. - We added
ignored_prsbecause we occasionally revert or park changes that should not show up in release notes. - We kept caching off for this pipeline. Fresh time windows produce fresher reports and simpler mental models.
This pipeline is exposed through a Run Template, which turns a versioned pipeline into a stable HTTP endpoint. The template parameters are the API contract between ZenPulse and ZenML. Next, we define that contract, show the exact payload shape, and trace a single request from browser to webhook through each component.
Turning the Agent into an API: ZenML Run Templates
A Run Template turns a specific, versioned pipeline into a stable HTTP endpoint. We pin the pipeline version once, then trigger it by posting JSON. The run happens in ZenML’s environment. Our web app just composes the payload, persists state, and handles the webhook. That boundary is the contract. See Run Templates and the guide to triggering from external systems.
The contract is the template’s parameters
In this setup, the template’s step parameters are the API. Keys and types are the contract. If we rename a step or change a parameter shape, the contract changes. The payload we post looks like this (trimmed to what matters for ZenPulse):
Where these come from:
- Step names
do_agents_loopandreport_backare defined inzenml_pipelines/github_report_pipeline.py. Their parameter names are the API surface. - Required (for our use-case):
repo,base_branch,analysis_type. Optional:tone,custom_prompt,ignored_prs. Ifdate_rangeis absent we default to the last 7 days in the step. - We generate a one-time
webhook_tokenand store it with the row; pairingcallback_url+request_idlets the pipeline return results to the rightPulseMessage.
Environment and selection are wired via ZENML_STORE_URL, ZENML_API_KEY and ZENML_TEMPLATE_NAME in src/config/settings.py.
The webhook payload is the response contract
The pipeline’s report_back step uses build_webhook_payload / json_ready to send a stable, serialisable JSON (zenml_pipelines/utils/callbacks.py). ZenPulse treats this as the response contract and maps fields onto PulseMessage.
ZenML “owns” the shape under results; ZenPulse “owns” persistence and status. We set PulseMessage.content = summary_message and mark theme_config.status to completed/failed (src/models/pulse_message.py).
Request lifecycle (what actually happens)
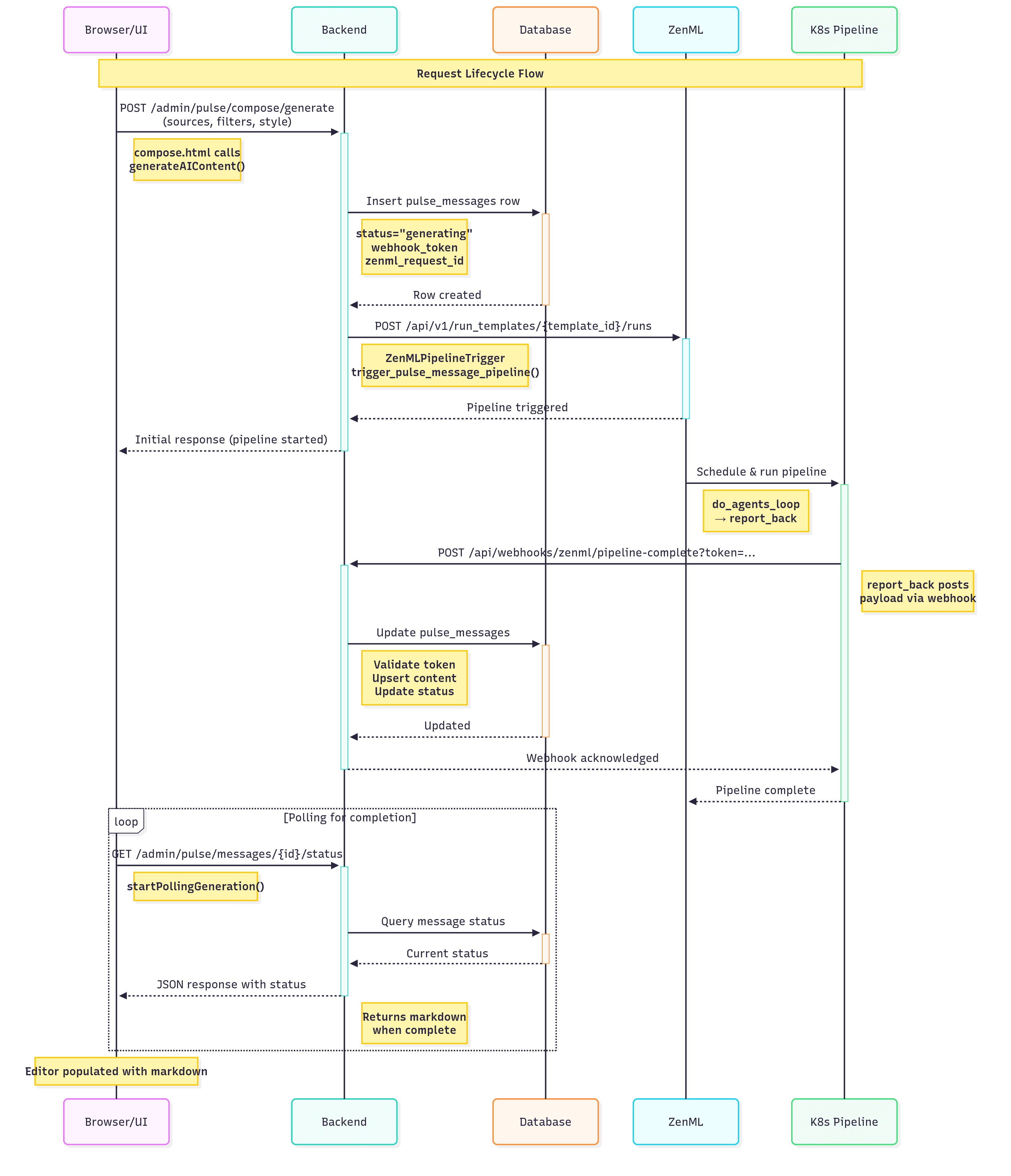
- Browser → Backend.
compose.htmlcallsPOST /admin/pulse/compose/generatefromgenerateAIContent()with sources, filters, and style. - Backend → DB. We insert a
pulse_messagesrow withstatus="generating", writetheme_config.webhook_tokenandtheme_config.zenml_request_id(src/web/routes.py:pulse_compose_generate). - Backend → ZenML.
ZenMLPipelineTrigger.trigger_pulse_message_pipeline(...)builds the run config andPOSTs to/api/v1/run_templates/{template_id}/runs(src/integrations/zenml_integration.py). - ZenML → Pipeline. ZenML schedules and runs
do_agents_loop→report_back(zenml_pipelines/github_report_pipeline.py). - Pipeline → Backend.
report_backposts the payload to/api/webhooks/zenml/pipeline-complete?token=...(utils/callbacks.py). - Backend → DB.
handle_zenml_webhookvalidates the token againstPulseMessage.theme_config.webhook_token, upsertscontent, and flips status (src/integrations/routes_integration.py). - Browser → Backend.
startPollingGeneration()hitsGET /admin/pulse/messages/{id}/status. - Backend → Browser. We return JSON; the UI drops markdown into the editor (
src/web/routes.py:pulse_message_status).
On contract drift and a “dry run” we wished we had
While building this, we kept thinking: it would help if ZenML exposed a validate-only path so we could preflight a trigger without running the full pipeline. We sketched three approaches:
- Server-side validator endpoint. Our backend would construct the exact run payload and call a ZenML “validate” route (or inspect template metadata) to confirm parameter names and types, returning
{compatible: true/false, details: ...}to the UI. - Pipeline
dry_run=True. A guarded path indo_agents_loopthat resolves dates and secrets, thenreport_backs immediately. This exercises the real container and stack, at the cost of a short run. - Shadow template. A minimal “schema check” template that asserts param compatibility and secret presence before enabling “Generate.”
We haven’t picked an approach yet, but I just included it here to give you a sense of some of the things we’re considering. For now, we keep payload assembly centralised (ZenMLPipelineTrigger), pin ZENML_TEMPLATE_NAME, and treat step parameter names as the sole contract. We may explore a validator in Part 2 if we make evals batch-driven from the UI.
Why this matters
This keeps a stable, versioned API between the UI and the agent runtime. We can change prompts, tools, and models inside the pipeline without redeploying the web app, and every change remains reproducible and observable on the ZenML side.
With the agent exposed as a versioned API and the contract pinned, the last step is operational discipline. We’ll close with what “operate your agent” looks like in practice and tee up Part 2, where we use baselines and evals to compare “new vs old” before anyone sees it.
Don’t Just Build Agents, Operate Them
Agents aren’t a file you run. They’re systems you operate. ZenML raises the work from “a clever script” to day-two engineering: pipelines that make flow explicit, versions that make behaviour reproducible, lineage that makes failures explainable, and Run Templates that turn a pipeline into a stable contract you can call from anything. The result is boring on purpose: controlled rollouts, easy rollbacks, and audits that stand up when a customer asks “what changed?”
If you want a short path to that posture, do this:
- Wrap the agent loop as a ZenML step with a strict input/output schema.
- Expose the pipeline via a Run Template and pin it to code, prompt, and tool versions.
- Emit tracing and metrics from every step, capture artifacts, and keep caching off where freshness matters.
- Keep the web app thin. Treat the template parameters as the API and return a single, clean payload for downstream use.
ZenPulse follows this pattern end to end. The UI composes a payload, ZenML runs the graph, the webhook returns a small JSON. We can change prompts, tools, or models at will because the runtime is versioned and observable, not interleaved with the frontend.
Up next: ZenPulse Deep Dive Part 2: On Evals. Operation isn’t complete without comparison and testing. We’ll wire baselines to pipeline versions, do error analysis, batch datasets through a template, and diff “new vs old” before anyone sees it. That includes dataset capture from traces, offline checks for format/voice/policy, regression gating, and a “validate-only” trigger to catch contract drift early. Same discipline, one layer deeper: measure first, then ship.


