

On this page
Building an AI agent in 2025 takes about 20 lines of code. Deploying it reliably at enterprise scale? That’s where things get interesting.
While demos proliferate and frameworks multiply, a gap has emerged between agent development and production deployment—one that even sophisticated enterprises are struggling to bridge. After spending the past few months analyzing deployment patterns across dozens of organizations, I’ve noticed a recurring theme: the simplicity of agent creation masks a deployment complexity that catches most teams off guard.
The Beautiful Simplicity (That’s Also the Problem)
At its core, an agent is elegantly simple—just a loop with some tools and an LLM. Here’s the most basic definition:
while not task_complete:
thought = llm.think(context)
action = llm.choose_tool(thought, available_tools)
result = execute_tool(action)
context.update(result)This simplicity is both a blessing and a curse. It’s democratized agent development, allowing anyone to spin up a proof-of-concept in minutes. But it’s also created false expectations about what it takes to run these systems in production.
Why Agent Deployment Deserves Its Own Conversation
After years in the MLOps space, I’ve watched similar patterns play out before. But agent deployment brings its own unique challenges that make it particularly fascinating—and frustrating.
The stakes are different. We learned from DevOps and MLOps that having a smooth, ergonomic flow for developers to get things quickly into production isn’t just nice to have—it’s essential for innovation velocity. With agents, this need is amplified. You’re likely deploying not just one agent, but potentially dozens or hundreds. At enterprise scale, you might even be creating platforms for customers to deploy their own custom agents.
The failure modes are novel. Unlike traditional software or even ML models, agents can fail in ways that are both subtle and spectacular. A conversation that derails. A tool chain that creates infinite loops. Memory systems that leak context across users. These aren’t your typical 500 errors.
The architectural decisions compound quickly. Every choice—from how you handle state persistence to how you manage tool authentication—cascades into downstream complexity. And unlike traditional microservices where you can often refactor incrementally, agent architectures tend to calcify early due to their conversational nature and stateful interactions.
This is closely tied to the whole evaluation challenge (how do you even know your deployed agent is working correctly?), but that’s a rabbit hole for another post.
Related posts from our research:
- LLM Agents in Production: Architectures, Challenges and Best Practices
- Steerable Deep Research: Building Production-Ready Agentic Workflows
How People Are Deploying Agents in 2025
When you look at the data, some patterns emerge. There’s what people write about at conferences, and there’s what actually runs in production. The gap between these two realities tells us something important about where we are in the agent deployment journey.
The Tale of Two Architectures
On one end of the spectrum, you have the architectural marvels. Deutsche Telekom’s LMOS platform processes millions of customer queries through a custom Kotlin-based orchestration layer. Cognizant built Neuro AI, a sophisticated multi-agent system where specialized agents collaborate on complex business workflows. These are serious engineering efforts solving real problems at scale.
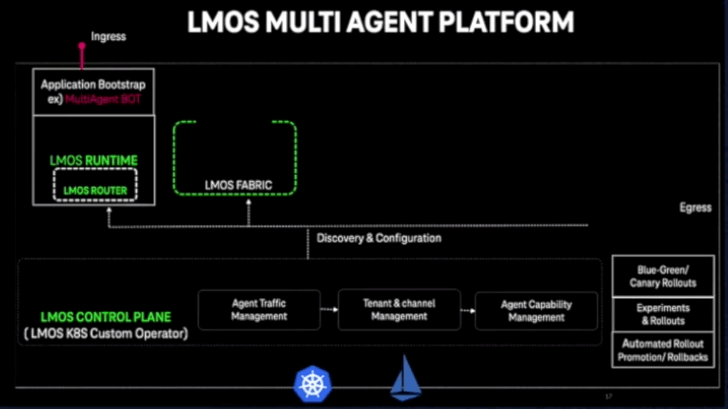
But when I surveyed practitioners about their actual deployments, the responses were much more mundane. “GitHub Actions to K8s,” one platform engineer told me. Another mentioned choosing Lambda because “saving like 10 dollars a month, why not?” A third simply said “docker compose is enough tbh.”
This isn’t a story of inadequacy. It’s a story of pragmatism.
The Deployment Reality Check
The majority of teams—somewhere between 60-70% as a rough anecdotal guess—deploy agents like they deploy any other service. They containerize the code, push it through their existing CI/CD pipeline, and run it on whatever infrastructure they already have. No special orchestration layers. No custom platforms. Just good old-fashioned Docker containers running on Kubernetes or ECS.
This makes complete sense when you think about it. Most agent workloads don’t require anything special. They’re API endpoints that happen to call an LLM. The conversation might take a bit longer than a typical request, but that’s a solved problem—you add a queue, return a job ID, and let the client poll or subscribe to updates.
A growing minority—maybe 20-30%—have discovered the appeal of serverless, especially when using managed LLMs. The entire “infrastructure” becomes a Lambda function that instantiates an agent and returns the response. When you’re paying for Bedrock or OpenAI anyway, why maintain servers?
When Simple Breaks Down
Of course, there’s a reason those complex architectures exist. Parcha’s journey is instructive here. They started simple—LangChain agents with websocket connections. But production revealed the cracks. Websockets dropped mid-conversation. Agents couldn’t recover from failures. The context window filled with noise as conversations progressed.
Their evolution followed a pattern I’ve now seen repeatedly:
First comes the realization that agents need state. Not just during a conversation, but across retries, failures, and system restarts. Dust.tt’s approach is particularly clever—they version every decision and action in PostgreSQL, creating an immutable audit trail that doubles as a recovery mechanism.
Then comes the async awakening. That simple request-response pattern breaks when agents start taking minutes instead of milliseconds. The teams who have this pain eventually seem to move to some form of asynchronous processing, whether that’s job queues, webhooks, or server-sent events.
Finally, there’s the framework abandonment phase. Almost everyone starts with LangChain or similar frameworks. Almost everyone eventually strips them out. “LangChain is great for demos,” one engineer told me. “Production is just FastAPI and the OpenAI client.” The frameworks aren’t bad—they’re just solving different problems than what production demands.
What Actually Matters
So what actually drives deployment decisions? It’s rarely technical elegance. The teams I talked to consistently prioritized:
Existing infrastructure wins. If you have Kubernetes, you’ll deploy to Kubernetes. If you’re all-in on AWS, you’ll use Lambda. The best agent deployment platform is the one you already have.
Developer velocity trumps architectural purity. That engineer who deployed 15 lines to Lambda? They had a working agent in production while others were still debating orchestration frameworks.
Cost consciousness is real. The “$10/month” comment wasn’t a joke. For many use cases, the difference between Lambda and a dedicated cluster is meaningful. Not because of the absolute cost, but because it reflects a mindset of appropriate engineering.
The Architecture Gap
This gap between conference talks and production reality isn’t necessarily bad. Those complex architectures solve real problems—just not problems most teams have. Yet.
But it does create a dangerous dynamic. Teams see talks about Deutsche Telekom’s multi-agent orchestration and think they need something similar for their customer support bot. Or they hear “agents are just loops” and don’t realize they’ll need state management until users start complaining about lost context.
The sweet spot is understanding both extremes. Know what the complex architectures solve so you can recognize when you need them. But start simple. Deploy that Lambda function. Use that job queue. Add complexity only when the simple solution breaks, because in production, simple solutions break in simple ways.
What Production Teams Actually Expect from Agent Deployment
Some clear expectations have crystallized. These aren’t nice-to-haves—they’re table stakes for serious deployments.
The Platform Paradox
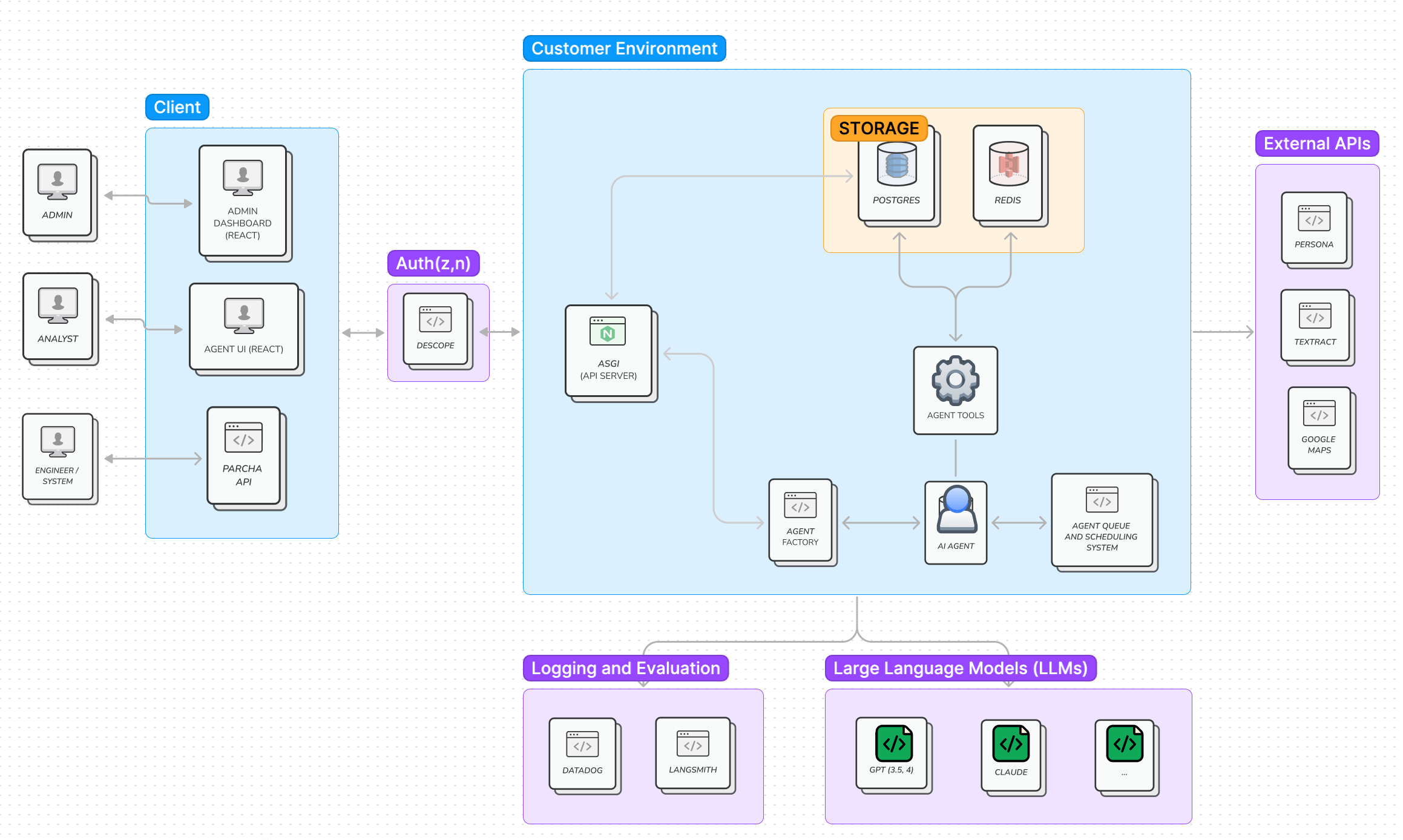
Teams want the power of a platform without the lock-in. This tension drives most architectural decisions. As the Rasgo team discovered, “security, data connectors, user interface, long-term memory, and evaluation” become the actual differentiators—not the agent itself.
The rise of standards like Model Context Protocol (MCP) and agent-to-agent (A2A) communication protocols reflects this desire for interoperability. Teams are betting on open standards because the landscape shifts too quickly to commit to proprietary platforms.
Reliability as a Feature
Production agents fail in ways that demos never reveal. Long-running agents need resumability—the ability to pick up from failure points without starting over. Anthropic’s recent multi-agent research emphasizes this: complex workflows can take minutes or hours, and losing progress to a network blip is unacceptable.
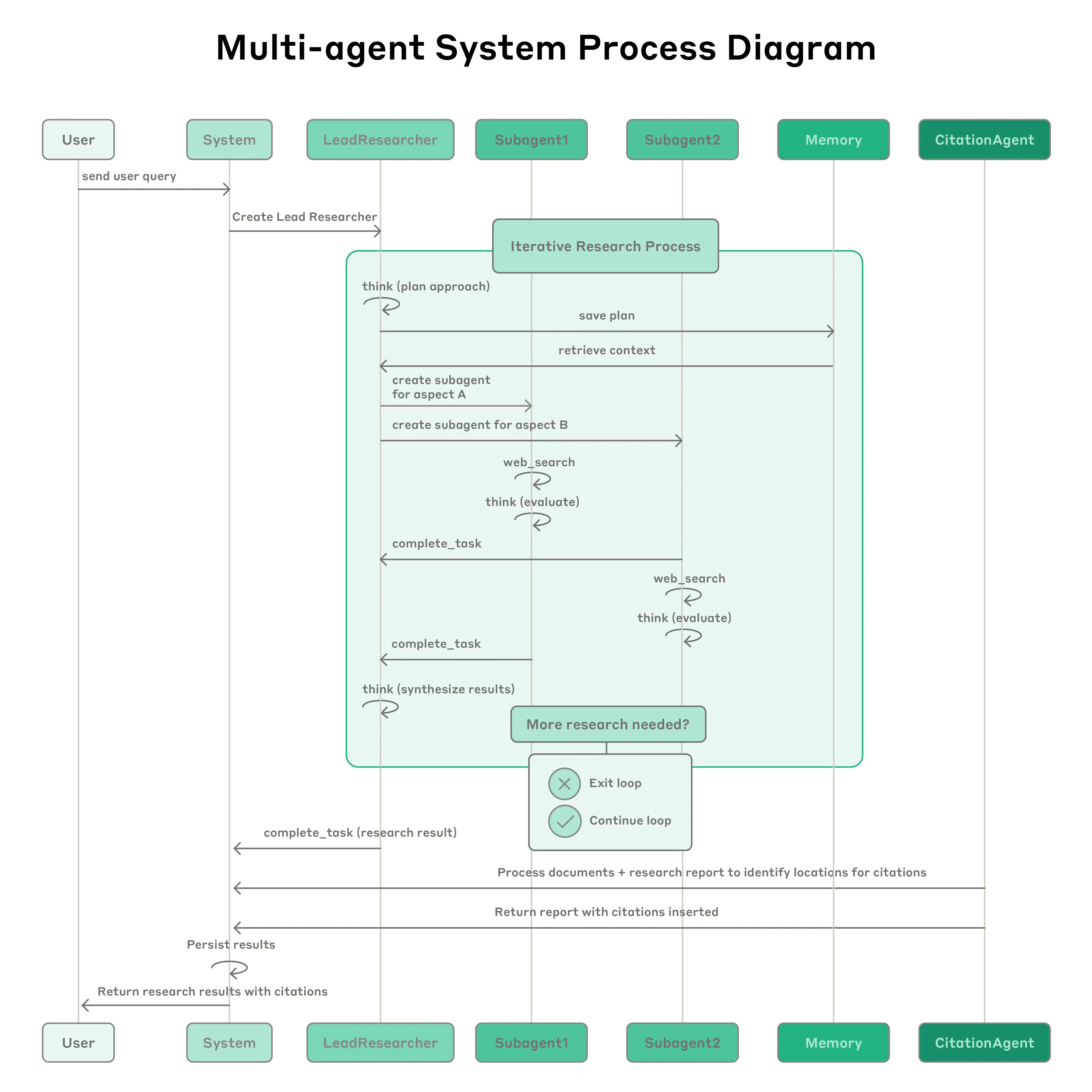
This drives specific technical requirements. Built-in tracing becomes essential—not just for debugging but for compliance and auditing. Teams expect observability baked in from day one. Memory persistence through PostgreSQL or Redis isn’t an afterthought; it’s architected upfront. The pattern is consistent: start with Redis for speed, add PostgreSQL when you need durability and queryability.
The Elasticity Imperative
Captide’s spreadsheet agents reveal another expectation: instant elasticity. When a user populates a spreadsheet, they might trigger hundreds of parallel agent invocations. The infrastructure must scale from zero to thousands of concurrent executions and back down just as quickly. This isn’t traditional autoscaling—it’s more aggressive, more dynamic.
Code sandboxes are becoming standard for agents that write and execute code. The security implications are obvious, but the user experience benefits drive adoption. Financial analysts want agents that can build models, not just talk about them. The expectation is shifting from “agents that can reason” to “agents that can do.”
The Integration Reality
Perhaps most telling is the rapid adoption of MCP tool plugins. Teams don’t want to rebuild integrations for every agent platform. They want to write a tool once and use it everywhere. This standardization pressure will likely intensify as the ecosystem matures.
So production teams expect agent deployment to feel like deploying any other service—with standard observability, reliability, and integration patterns. The novelty of agents doesn’t excuse primitive operational characteristics.
The Problems Nobody Talks About (Until It’s Too Late)
The real deployment challenges aren’t what you’d expect. It’s not about getting the LLM to reason better or choosing the right framework. The problems that keep engineers up at night are far more mundane—and far more critical.
The Self-Hosting Trap
Teams that choose to self-host agents often discover they’ve signed up for more than they bargained for. Toqan’s experience building their data analyst agent reveals the gap between prototype and production. Their agent could translate natural language to SQL and visualize results—showing what they described as “magical” moments during development. But production revealed severe reliability issues: infinite loops where agents ignored stop commands, repetitive responses (giving the same answer 58-59 times), and inconsistent behavior across runs.
The authentication and access control challenges compound quickly. Teams need OAuth integration, user-specific permissions for data access, and secure credential management across distributed systems. Each agent invocation potentially touches multiple external services, each with its own authentication requirements. Token refresh, rotation, and expiration handling at scale becomes a significant engineering burden.
Infrastructure complexity emerges in unexpected ways. Setting up reliable orchestration requires deep expertise in Kubernetes configurations, helm charts, and service meshes. Agent workloads create unpredictable scaling patterns—sudden bursts of parallel executions that traditional autoscaling struggles to handle. Managing stateful components like memory stores and conversation history adds another layer of operational overhead.
QuantumBlack’s perspective on data engineering in the LLM era highlights additional challenges around unstructured data processing and maintaining data quality. They emphasize the importance of deployment flexibility—from cloud to on-premises options—because enterprise clients have varying security and compliance requirements.
Slack’s recommendation system adds another dimension to the self-hosting challenge. They built their system with privacy as a fundamental design constraint, avoiding any use of customer message content in their models. This required careful feature engineering focused on interaction patterns rather than semantic content, demonstrating how privacy requirements can fundamentally shape system architecture.
The Managed Service Mirage
So teams turn to managed platforms—LangGraph Platform, AWS Bedrock Agents, various startups promising to handle the complexity. The initial experience often delights. Deploy with one command. Scale automatically. Let someone else worry about the infrastructure.
Then the constraints become apparent. Lock-in develops as you adopt platform-specific APIs and tools. Migration costs grow with each integration. Complex use cases hit platform limitations—workflows the platform doesn’t support, architectural patterns it can’t accommodate.
Cost unpredictability emerges at scale. Per-invocation pricing that seems reasonable for prototypes explodes when you’re running thousands of parallel agents or long-running workflows. The lack of infrastructure control prevents optimization—you can’t choose specific hardware, optimize runtime environments, or control resource allocation.
Data residency and compliance create hard blockers for many enterprises. Regulatory requirements often demand on-premises deployment or specific regional data storage. Security teams balk at shared infrastructure that doesn’t meet isolation requirements. The debugging experience deteriorates when you lose visibility into system internals, logs, and performance metrics.
The Missing Middle
What strikes me most is the gap between these extremes. Self-hosting demands expertise and resources most teams lack. Managed services impose constraints most teams can’t accept. The majority exist in an uncomfortable middle—cobbling together solutions, making compromises, hoping something better emerges.
Toqan’s solution involved implementing deterministic workflows to control agent behavior, expert-in-the-loop systems for documentation optimization, and careful balance between hard limits (to prevent resource abuse) and soft limits (to preserve agent flexibility). These aren’t exotic requirements—they’re table stakes for production systems. But the current tooling landscape forces teams to build much of this from scratch.
The patterns are fairly clear, however: start simple, hit authentication walls, struggle with scale, attempt managed services, recoil at constraints, end up building more infrastructure than intended. The solutions exist in pieces—we just haven’t assembled them into coherent deployment patterns yet.
What’s needed isn’t another framework or platform. It’s a recognition that agent deployment sits at an awkward intersection of established practices and novel requirements. Until we develop deployment patterns that respect both sides of this intersection, teams will continue navigating these challenges the hard way.
Some Tentative Lessons
Based on the case studies in the LLMOps Database as well as conversations with customers and colleagues, I’ve come to some tentative interim conclusions about where we are with agent deployment as of late July 2025. None of these are revolutionary insights, but taken together, they might be taken to form a pragmatic view of the current state of the field.
The Surface Area Problem
Agent deployment is a massive domain—far larger than most teams realize when they start. Just like MLOps before it, there’s tremendous complexity hiding beneath the surface. Every organization is a unique snowflake with its own infrastructure, security requirements, and operational constraints. You’re going to have to put in real work and thought to get this right.
The good news is we’re not starting from zero. The decades of investment in DevOps and MLOps give us solid foundations to build on. Container orchestration, CI/CD pipelines, monitoring systems—these patterns still apply. The challenge is adapting them to the specific quirks of agent systems: their non-determinism, their stateful nature, their bursty workloads, their complex authentication requirements.
The Moving Target
The field is changing at a pace that makes planning difficult. A year ago, persistent memory wasn’t seen as essential. Now everyone’s adding it, though I suspect it might go the way of vector databases—important for some use cases, overhyped for others. Next year, who knows what will be table stakes?
This volatility demands a specific architectural approach: modularity and composability. Your deployment system needs clean interfaces between components. When the next breakthrough comes—and it will—you need to be able to swap pieces without rebuilding everything. Lock-in isn’t just about vendors anymore; it’s about architectural decisions that assume the current state of the art won’t change.
The 80/20 Rule Still Applies
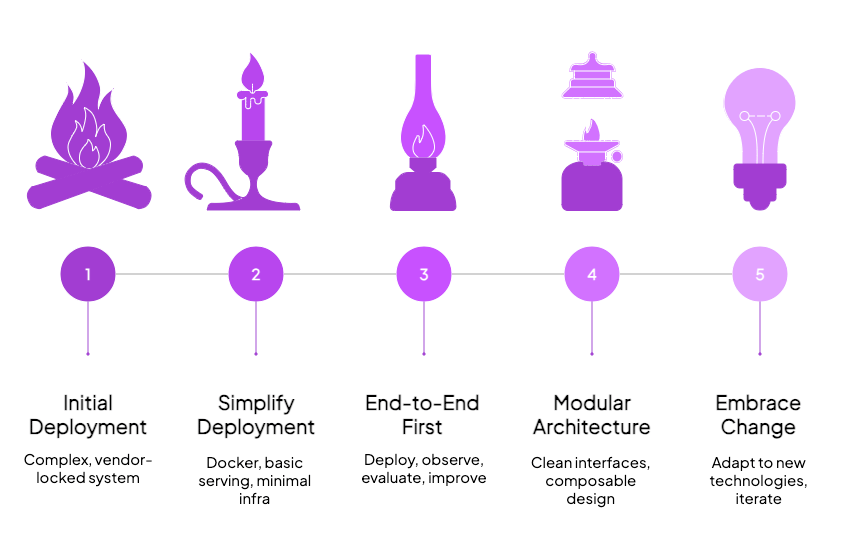
For most teams, the path forward is surprisingly simple: start simple. Don’t jump to multi-agent architectures before you’ve even figured out how to evaluate a single agent. This means your deployment can also be simple to start—Docker container, basic serving mechanism, minimal infrastructure.
Thomson Reuters discovered this the hard way. They found that their traditional focus on building the “minimal” in MVP led them down optimization rabbit holes. Building complete systems first, then optimizing, proved more effective than trying to perfect individual components in isolation. This insight challenges conventional wisdom but makes sense for agent systems where the interactions between components often matter more than the components themselves.
End-to-End Before Excellence
Get something deployed end-to-end before you start optimizing. Build the smallest viable agent, deploy it with basic infrastructure, add just enough observability to understand what’s happening. Then—and this is crucial—build your evaluation harness. Only once you can measure whether changes improve or degrade performance should you start iterating.
This outer loop—deploy, observe, evaluate, improve—is your path to greatness. It’s tempting to spend months perfecting your agent locally, but you learn different things from production deployment. Real users break assumptions. Real data reveals edge cases. Real scale exposes architectural flaws.
The Humility Factor
We are so early with this stuff. Anyone claiming to have all the answers is selling something. The best practices we’re discussing today will look quaint in two years. The frameworks we’re building will be replaced. The deployment patterns we’re establishing will evolve.
This isn’t discouraging—it’s liberating. It means we get to figure this out together. It means your weird solution might become the standard approach. It means there’s room for innovation at every layer of the stack.
The Deployment Democracy
Basic agent deployment should be much easier than it is today. More importantly, it shouldn’t lock you into a specific cloud provider or platform. You might want to host on Cloud Run today, but you shouldn’t be dependent on Google’s goodwill forever. The same code that runs on AWS should run on Azure, on-premises, or on that random Kubernetes cluster your ops team insists on maintaining.
This isn’t about avoiding cloud services—they offer tremendous value. It’s about maintaining optionality in a rapidly evolving landscape. The deployment abstraction layer needs to be thin enough to avoid constraining your choices but thick enough to provide real value.
Looking Forward
The gap between agent development and production deployment will close, but it’ll take collective effort. We need better patterns, better tools, and better shared understanding. Most importantly, we need more teams sharing their experiences—both successes and failures—as they navigate this new terrain.
At ZenML, we’re betting that the future of agent deployment looks a lot like the present of ML deployment: standardized patterns, reusable components, and tooling that gets out of your way. The specifics will evolve, but the need for reliable, scalable, observable deployment won’t.
The journey from that elegant 20-line agent loop to a production system serving real users remains challenging. But with pragmatic approaches, realistic expectations, and a willingness to learn from each other, we’re making it more navigable every day.


