Ensure data quality and guard against drift with Evidently profiling in ZenML
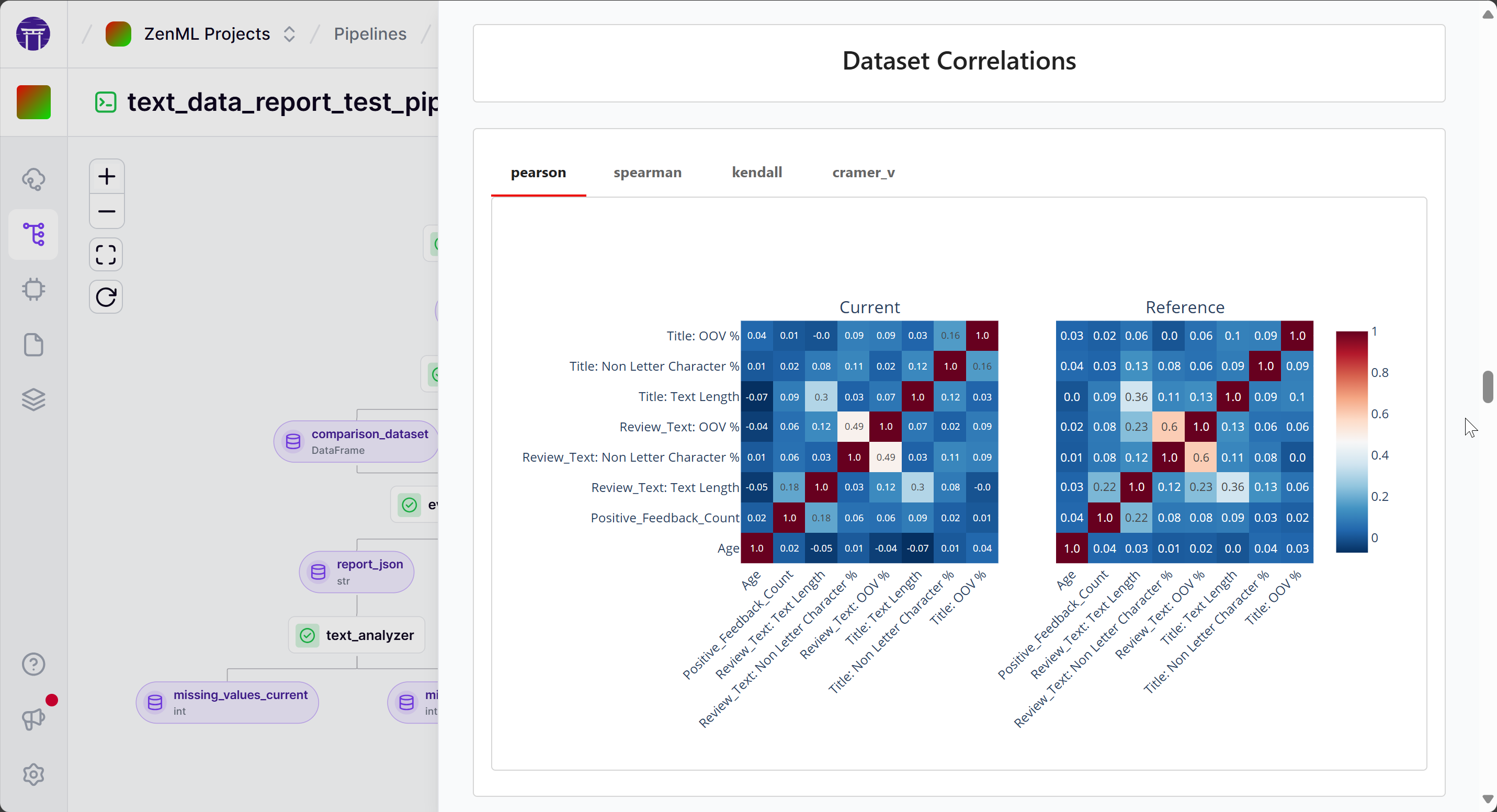
The Evidently integration enables you to seamlessly incorporate data quality checks, data drift detection, and model performance analysis into your ZenML pipelines. Leverage Evidently's powerful profiling and validation features to maintain the integrity and reliability of your ML workflows.
import pandas as pd
from zenml import pipeline, step
from typing_extensions import Tuple, Annotated
from zenml.artifacts.artifact_config import ArtifactConfig
import pandas as pd
from sklearn import datasets
@step
def data_loader() -> pd.DataFrame:
"""Load the OpenML women's e-commerce clothing reviews dataset."""
reviews_data = datasets.fetch_openml(
name="Womens-E-Commerce-Clothing-Reviews", version=2, as_frame="auto"
)
reviews = reviews_data.frame
return reviews
@step
def data_splitter(
reviews: pd.DataFrame,
) -> Tuple[Annotated[pd.DataFrame, ArtifactConfig(name="reference_dataset")], Annotated[pd.DataFrame, ArtifactConfig(name="comparison_dataset")]]:
"""Splits the dataset into two subsets, the reference dataset and the
comparison dataset.
"""
ref_df = reviews[reviews.Rating > 3].sample(
n=5000, replace=True, ignore_index=True, random_state=42
)
comp_df = reviews[reviews.Rating < 3].sample(
n=5000, replace=True, ignore_index=True, random_state=42
)
return ref_df, comp_df
from zenml.integrations.evidently.metrics import EvidentlyMetricConfig
from zenml.integrations.evidently.steps import (
EvidentlyColumnMapping,
evidently_report_step,
)
text_data_report = evidently_report_step.with_options(
parameters=dict(
column_mapping=EvidentlyColumnMapping(
target="Rating",
numerical_features=["Age", "Positive_Feedback_Count"],
categorical_features=[
"Division_Name",
"Department_Name",
"Class_Name",
],
text_features=["Review_Text", "Title"],
),
metrics=[
EvidentlyMetricConfig.metric("DataQualityPreset"),
EvidentlyMetricConfig.metric(
"TextOverviewPreset", column_name="Review_Text"
),
EvidentlyMetricConfig.metric_generator(
"ColumnRegExpMetric",
columns=["Review_Text", "Title"],
reg_exp=r"[A-Z][A-Za-z0-9 ]*",
),
],
# We need to download the NLTK data for the TextOverviewPreset
download_nltk_data=True,
),
)
import json
@step
def text_analyzer(
report: str,
) -> Tuple[Annotated[int, ArtifactConfig(name="missing_values_current")], Annotated[int, ArtifactConfig(name="missing_values_reference")]]:
"""Analyze the Evidently text Report and return the number of missing
values in the reference and comparison datasets.
"""
result = json.loads(report)["metrics"][0]["result"]
return (
result["current"]["number_of_missing_values"],
result["reference"]["number_of_missing_values"],
)
@pipeline(enable_cache=False)
def text_data_report_test_pipeline():
"""Links all the steps together in a pipeline."""
data = data_loader()
reference_dataset, comparison_dataset = data_splitter(data)
report, _ = text_data_report(
reference_dataset=reference_dataset,
comparison_dataset=comparison_dataset,
)
text_analyzer(report)
if __name__ == "__main__":
# Run the pipeline
text_data_report_test_pipeline()
Expand your ML pipelines with more than 50 ZenML Integrations