Streamline your machine learning workflows by running ZenML pipelines as Amazon SageMaker Pipelines, a serverless ML orchestrator from AWS. This integration enables you to leverage SageMaker's scalability, robustness, and built-in features to manage your ML pipelines efficiently in production environments.
# Step 1: Register a new Sagemaker orchestrator
>>> zenml orchestrator register <ORCHESTRATOR_NAME> \
--flavor=sagemaker \
--execution_role=<YOUR_IAM_ROLE_ARN>
# Step 2: Authernticate Sagemaker orchestrator
# Option 1 (recomended): Service Connector
>>> zenml orchestrator connect <ORCHESTRATOR_NAME> --connector <CONNECTOR_NAME>
# Option 2 (not recommended): Explicit authentication
>>> zenml orchestrator register <ORCHESTRATOR_NAME> \
--flavor=sagemaker \
--execution_role=<YOUR_IAM_ROLE_ARN> \
--aws_access_key_id=...
--aws_secret_access_key=...
--region=...
# Option 3 (strictly not recommended): Implicit authentication
# Nothing needed, auth settings will be used from the running
# environment implicitely
# Step 3: Update your stack to use the Sagemaker orchestrator
>>> zenml stack update -o <ORCHESTRATOR_NAME>
from zenml import step, pipeline
from zenml.integrations.aws.flavors.sagemaker_orchestrator_flavor import (
SagemakerOrchestratorSettings,
)
@step
def preprocess_data() -> int:
return 1
@step
def train_model(data: int) -> str:
return str(data)
@pipeline(
settings={
"orchestrator.sagemaker": SagemakerOrchestratorSettings(
instance_type="ml.m5.large",
volume_size_in_gb=30,
),
}
)
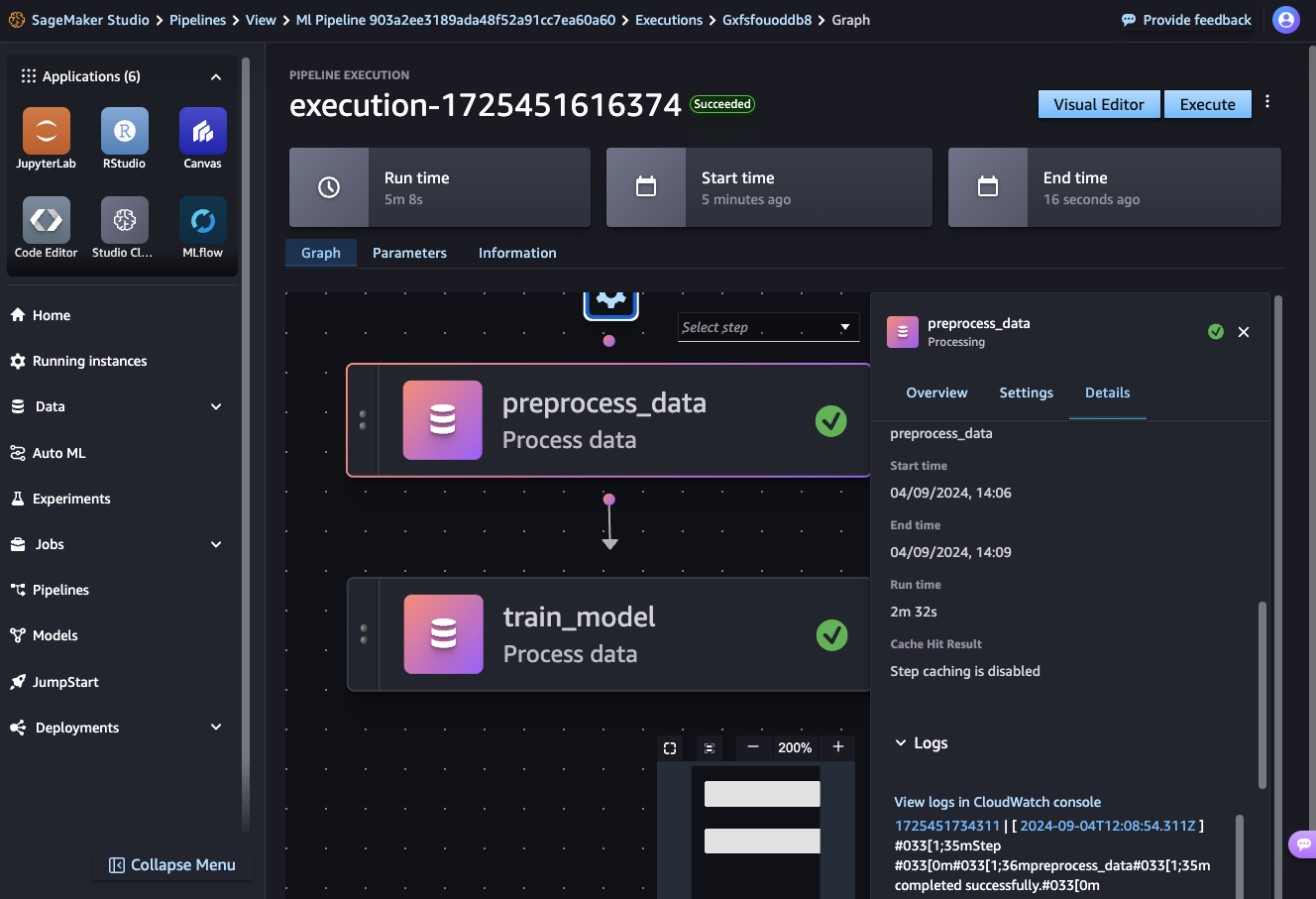
def ml_pipeline():
input_data = preprocess_data()
train_model(input_data)
if __name__ == "__main__":
ml_pipeline()
Expand your ML pipelines with more than 50 ZenML Integrations
