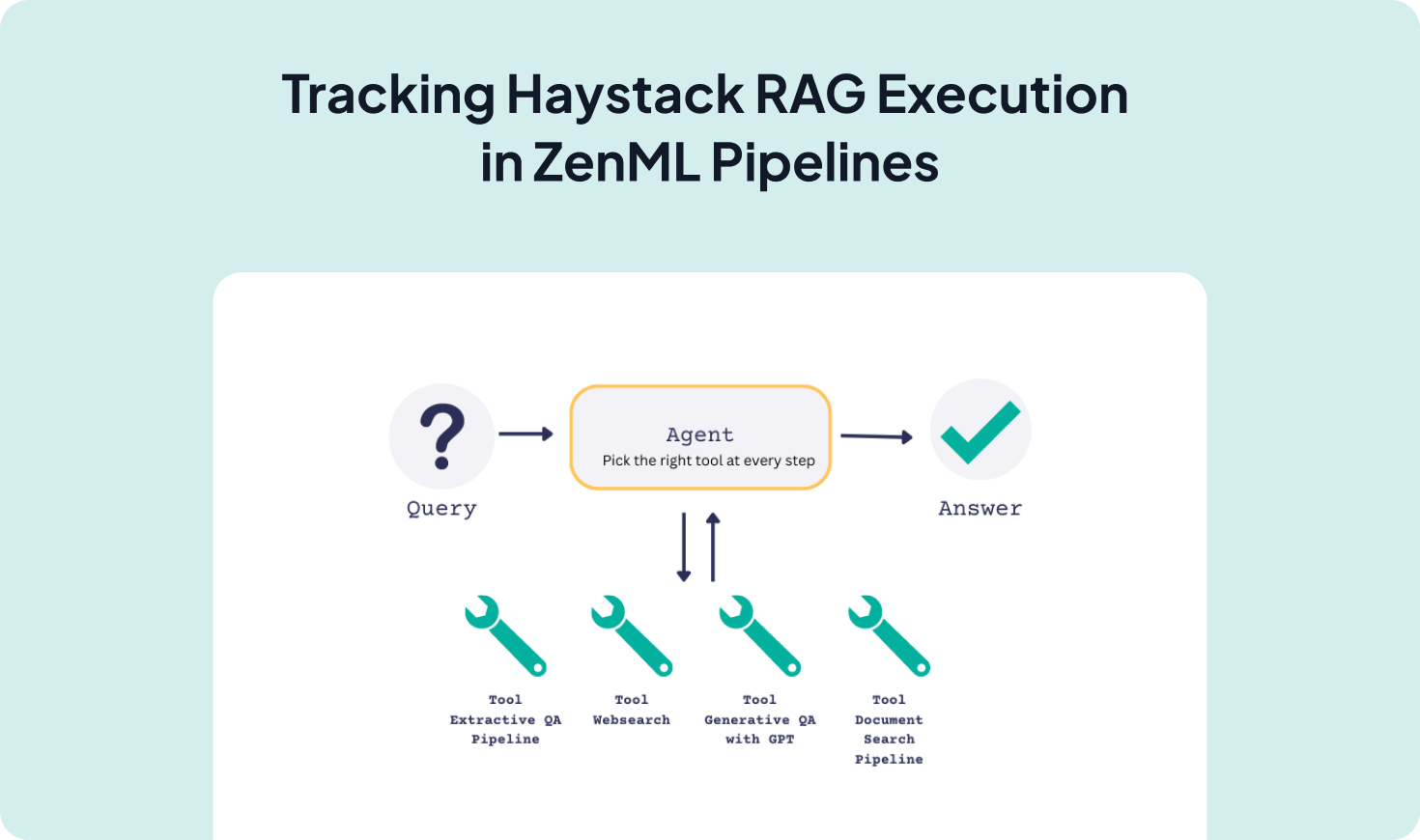
Haystack provides a component-based framework for Retrieval-Augmented Generation (RAG); integrating Haystack with ZenML wraps your retrievers, prompt builders, and LLM calls inside reproducible pipelines with artifact tracking, observability, and a clean path from local experiments to production.
from zenml import ExternalArtifact, pipeline, step
from haystack_agent import pipeline as haystack_pipeline
@step
def run_haystack(question: str) -> str:
# Execute the Haystack pipeline and extract the first LLM reply
result = haystack_pipeline.run(
{"retriever": {"query": question},
"prompt_builder": {"question": question}},
include_outputs_from={"llm"},
)
replies = result.get("llm", {}).get("replies", [])
return replies[0] if replies else "No response generated"
@pipeline
def haystack_rag_pipeline() -> str:
q = ExternalArtifact(value="What city is home to the Eiffel Tower?")
return run_haystack(q.value)
if __name__ == "__main__":
print(haystack_rag_pipeline())Expand your ML pipelines with more than 50 ZenML Integrations
